
非平行文本下基于变分自编码器和辅助分类器生成对抗网络的语音转换
2020-06-28 13:00李燕萍
复旦学报(自然科学版) 2020年3期
李燕萍,曹 盼,石 杨,张 燕,钱 博
(1. 南京邮电大学 通信与信息工程学院,江苏 南京 210023; 2. 金陵科技学院 软件工程学院,江苏 南京 211169; 3.南京电子技术研究所,江苏 南京 210039)
语音转换是在保持语音内容不变的同时,改变一个人的声音,使之听起来像另一个人的声音[1-2].在实际应用中,预先采集大量平行训练文本不仅耗时耗力,而且在跨语种转换和医疗辅助系统中往往无法采集到平行文本,因此非平行文本条件下的语音转换研究具有更大的应用背景和现实意义,同时具有很大的挑战性,是当前语音转换领域研究的热点和难点.
性能良好的语音转换系统既要保持重构语音的听觉质量,又要兼顾转换后的目标说话人的个性特征是否准确,近年来,为了改善转换后合成语音的自然度和说话人个性的相似度,非平行文本条件下的语音转换研究取得了很大进展,根据其研究思路的不同,大致可以分为3类.第1类是从语音重组的角度,在一定条件下将非平行文本转化为伪平行文本[3-4]进行处理,其代表算法包括两种: 一种是使用独立于说话人的自动语音识别(Automatic Speech Recognition, ASR)系统标记音素;另一种是借助文语转换(Text To Speech, TTS)系统将小型语音单元拼接成平行语音.该类方法原理简单,易于实现,然而这类方法很大程度上依赖于ASR或TTS系统的性能.第2类是从统计学角度利用背景说话人的信息作为先验知识,应用模型自适应技术对已有的平行转换模型进行更新,包括说话人自适应[5-6]、说话人归一化等,但是这类方法通常要求背景说话人的训练数据是平行的,因此并不能完全解除对平行训练数据的依赖,还增加了系统的复杂性.第3类方法利用分离语义和说话人的个性信息,转换过程是在语义信息上叠加目标说话人个性信息来实现语音重构,其代表算法包括基于条件变分自编码器(Conditional Variational Auto-Encoder, C-VAE)[7]的方法、基于变分自编码器和生成对抗网络(Variational Autoencoding Wasserstein Generative Adversarial Network, VAWGAN)[8]的方法、基于语音后验图(Phonetic Posteriorgrams, PPG)[9]的方法等.这类方法直接规避了非平行文本对齐的问题,提供了多说话人向多说话人转换的新框架,是目前非平行文本条件下语音转换的主流方法.
基于VAWGAN方法可以实现非平行文本条件下高质量的语音转换,在训练过程中不需要任何对齐过程,还可以将多个源-目标说话人对的转换系统整合在1个转换模型中,即实现多说话人对多说话人转换.然而Wasserstein生成对抗网络(Wasserstein Generative Adversarial Network, WGAN)[10]存在着一些不足之处,例如训练困难、收敛速度较慢等.如果能提升WGAN的性能或者找到性能更强大的生成对抗网络,则有望进一步提升语音转换系统生成语音的清晰度,从而生成具有更好音质的语音.
近年来,辅助分类器生成对抗网络(Auxiliary Classifier GANs, ACGAN)[11]在图像生成领域获得了很好的效果,本文将ACGAN结合到语音转换的应用中,提出利用ACGAN替代VAWGAN模型中的WGAN,由于ACGAN的鉴别器不仅能鉴别生成的频谱包络特征的真假,还能鉴别生成的频谱包络特征的类别,因此,生成的样本更加接近特定样本,从而进一步提升转换语音的质量.充分的主观和客观实验表明: 本文提出的将ACGAN应用于语音转换领域,在有效改善合成语音质量的同时进一步提升了说话人个性的相似度,实现了高质量的语音转换.
1 基于VAWGAN的语音转换基准方法
针对C-VAE解码器输出趋于过平滑的问题,基于VAWGAN的语音转换框架利用WGAN提升了C-VAE的性能,VAWGAN网络由3部分构成: 编码器、生成器和鉴别器,其中C-VAE的解码器部分由WGAN中的生成器代替,完整的语音转换模型可以表示为
(1)
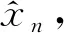
为了实现语音转换,WGAN使用Wasserstein目标函数[8]来替代生成对抗网络(Generative Adversarial Network, GAN)中的JS散度(Jensen-Shannon divergence, JS)来衡量生成数据分布和真实数据分布之间的距离.由于VAWGAN模型是由C-VAE和WGAN结合而成,因此模型完整的目标函数可以表示为
JVAWGAN=L(x;φ,θ)+αJWGAN,
(2)
其中:L(x;φ,θ)表示C-VAE模型部分的目标函数,通常使用随机梯度下降法来更新C-VAE中的网络型参数;α是调节WGAN损失的系数;JWGAN表示WGAN的目标函数.定义如下:
L(x;φ,θ)=-DKL(qφ(z|x)‖pθ(z))+Eqφ(z|x)[lnpθ(x|z,y)],
(3)
(4)
其中:DKL表示KL散度(Kullback-Leibler divergence, KL);qφ表示编码网络;pθ表示解码网络;pθ(z)为潜在变量z的先验分布,该分布为标准多维高斯分布;Gθ表示WGAN中的生成器;Dψ表示鉴别器;θ和ψ分别是生成器和鉴别器的相关参数.
综上分析可知,VAWGAN利用潜在语义内容zn和说话人标签yn重构任意目标说话人的语音帧,实现了非平行文本条件下多对多的语音转换.此外,WGAN通过Wasserstein距离在一定程度上改善了GAN训练不稳定的问题,而WGAN为了实现稳定的训练,通常将权重剪切到一定范围内,如[-0.01,0.01],但该方法容易导致权重集中在-0.01和0.01上,造成梯度爆炸或梯度弥散,从而导致训练相对困难,收敛速度较慢等,所以WGAN在数据生成能力上仍存在一定的改进空间.基于此,本文从提升WGAN的性能或者找到生成性能更加强大的GAN对转换方法进行改进,以期望进一步获得更好质量的语音.
2 改进的基于VAACGAN语音转换方法
2.1 ACGAN的原理
为了进一步提升VAWGAN的性能,通过找到生成性能更加强大的GAN替换WGAN是本文的研究出发点.2017年,Odena等[11]提出的ACGAN是1种用于图像合成的生成对抗网络的方法,对于图像生成的性能提升很大.与WGAN结构不同,ACGAN的鉴别器中包含辅助解码器网络,该辅助解码器网络输出训练数据的类标签或生成样本的潜在变量的子集,另外,辅助解码器网络可以利用预训练的鉴别器来进一步改善生成样本的质量.
在ACGAN框架中,除了噪声z之外,生成的每个样本都具有对应的类标签c~pc,生成样本的类别标签用one-hot编码表示,以区分不同的生成样本.在生成器G使用噪声z和类标签c来生成样本Xfake=G(c,z).鉴别器D会输出判别样本真假来源的概率分布和类标签上的概率分布:
P(S|X),P(C|X)=D(X),
(5)
其中:P(S|X)表示鉴别器D判别数据源是否为真实数据的概率分布;P(C|X)表示鉴别器D判别数据源属于类标签的概率分布.
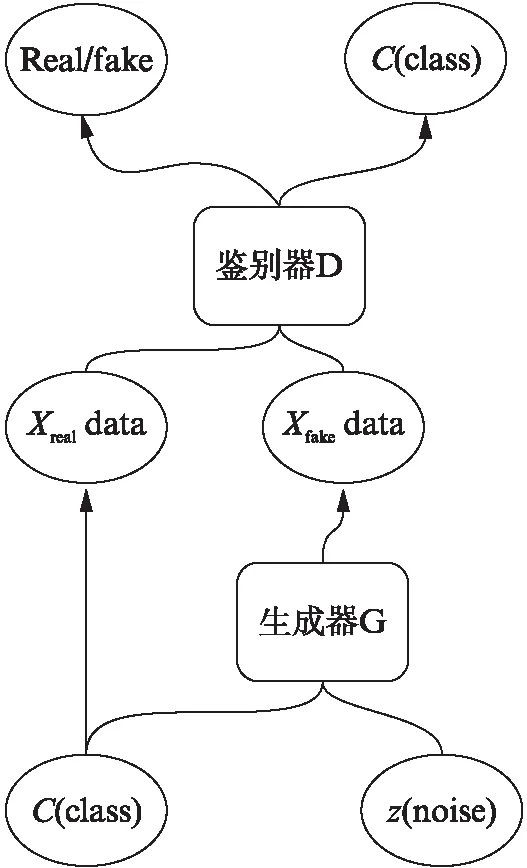
图1 ACGAN的结构示意图Fig.1 Structure diagram of ACGAN
ACGAN的结构如图1所示,其中,ACGAN的鉴别器不仅能判别样本的“真假”,还能判别样本所属的类别.ACGAN的鉴别器D仅将样本作为输入,输出为预测的样本的“真假”和预测的样本所属的类别,因此,ACGAN鉴别器的目标函数分为两部分: 正确来源的对数似然LS和正确类的对数似然LC,即
LS=E[lnP(S=real|Xreal)]+E[lnP(S=fake|Xfake)],
(6)
LC=E[lnP(C=c|Xreal)]+E[lnP(C=c|Xfake)].
(7)
训练过程中,鉴别器D的训练目标是使LS+LC最大化,同时训练生成器G使LS-LC最大化.
2.2 基于VAACGAN的语音转换
从2.1节的分析可知,ACGAN将特征样本的类别标签作为辅助信息,其鉴别器不仅能预测样本真假,还能预测样本所属的类别,理论上提高了生成对抗网络的生成性能,同时使得训练过程更加稳定,在图像领域的实验[11]证明了ACGAN强大的生成能力.
若将ACGAN结合到语音转换应用中,其鉴别器不仅能鉴别生成的频谱包络特征的真假,还能鉴别生成的频谱包络特征的类别,使得生成的样本更加接近特定样本,从而提升语音质量.因此,本文提出基于VAE和ACGAN的语音转换模型(Variational Autoencoding Auxiliary Classifier GAN, VAACGAN),利用ACGAN替换VAWGAN模型中的WGAN.
基于VAACGAN的语音转换模型框图如图2所示,该模型分为训练阶段和转换阶段.
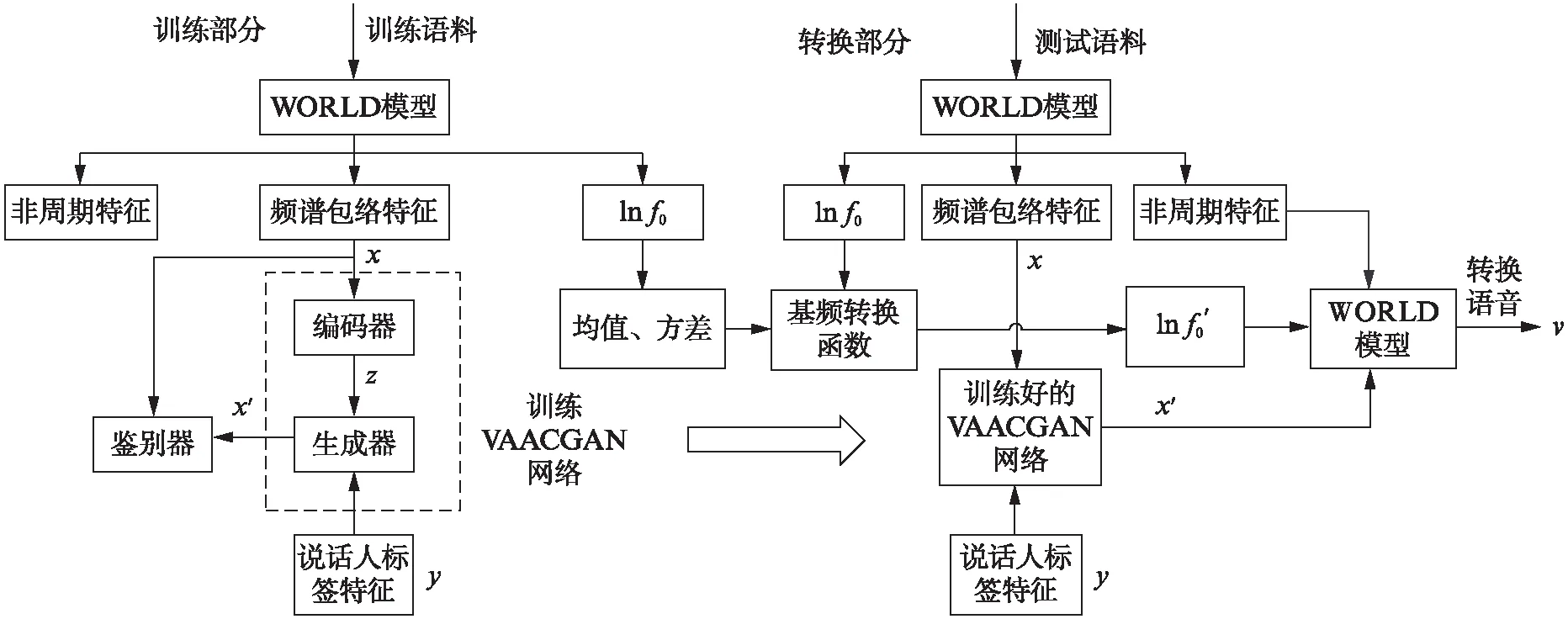
图2 基于VAACGAN的语音转换模型的框图Fig.2 Block diagram of voice conversion model based on VAACGAN
2.2.1 训练阶段
获取包含多名源说话人和目标说话人的训练语料,将上述训练语料通过WORLD语音分析/合成模型[12],提取出各说话人语句的频谱包络、对数基频lnf0和非周期特征,将提取的频谱包络x和说话人标签y输入VAACGAN模型进行训练.VAACGAN模型由编码器、生成器和鉴别器组成,VAACGAN模型的目标函数为
JVAACGAN=L(x;φ,θ)+αJACGAN,
(8)
其中:L(x;φ,θ)表示编码器部分的损失函数,该损失函数的计算和VAWGAN模型相同;α是ACGAN的损失系数,在训练过程中,设置α为50.0;JVAACGAN表示ACGAN的部分损失函数,且
(9)
其中:Dψs(·)为鉴别器对输入样本真假判别的输出;Dψc(·)为鉴别器对输入样本类别判别的输出;loss(·) 为鉴别器预测的样本类别和真实类别之间的交叉熵损失,样本类别损失记为
(10)
在ACGAN中,生成器的损失函数为
LG=-Eqφ(z|x)[lnpθ(x|z,y)]-βEz~qφ(z|x)[Dψc(Gθ(z,y))]+Lc,
(11)
优化目标为
(12)
在ACGAN中,鉴别器的损失函数为
(13)
优化目标为
(14)
在ACGAN的训练过程中,要使生成器损失函数LG尽量小,同时使鉴别器损失函数LD尽量大,训练语料的频谱包络特征x在经过VAACGAN模型的编码器后,得到与说话人无关的语义特征z,将z和说话人标签y送入VAACGAN模型的生成器得到“假样本”,将其和真实频谱包络特征一同送入鉴别器,得到鉴别器对输入样本真假判别的输出以及输入样本类别标签的输出.
构建从源说话人语音对数基频lnf0到目标说话人语音对数基频lnf′0的基频转换函数:
(15)
其中:μ和σ分别表示源说话人的基频在对数域的均值和均方差;μ′和σ′分别表示目标说话人的基频在对数域的均值和均方差.
2.2.2 转换阶段
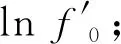
3 实验与分析
本实验采用VCC2018[13]中的语音库,本文选取其中4名女性说话人和4名男性说话人的语音,即VCC2SF3、VCC2SF4、VCC2TF1、VCC2TF2、VCC2SM3、VCC2SM4、VCC2TM1、VCC2TM2.每个说话人在训练阶段均选取81句训练语音,在转换阶段选取35句测试语音进行转换,一共有16组转换情形.本实验使用WORLD分析/合成模型提取语音参数,包括频谱包络、非周期特征和基频,其中频谱包络和非周期特征均为513维.本文主要利用VAACGAN模型实现频谱包络的转换,基频采用传统的高斯归一化的转换方法转换对数基频,非周期特征不变.
在VAACGAN模型中,所述编码器、生成器、鉴别器均采用2维卷积神经网络,激活函数均采用LReLu函数.图3为VAACGAN模型网络结构图,其中,编码器由5个卷积层构成,5个卷积层的过滤器大小均为7×1,步长均为3,过滤器深度分别为16,32,64,128,256.生成器由4个反卷积层构成,4个反卷积层的过滤器大小分别为9×1,7×1,7×1,1025×1,步长分别为3,3,3,1,过滤器深度分别为32,16,8,1.鉴别器由3个卷积层和1个全连接层构成,3个卷积层的过滤器大小分别为7×1,7×1,115×1,步长均为3,过滤器深度分别为16,32,64.VAACGAN相比于VAWGAN的改进主要在鉴别器部分,其中多了1层输出语音数据类标签的网络层.
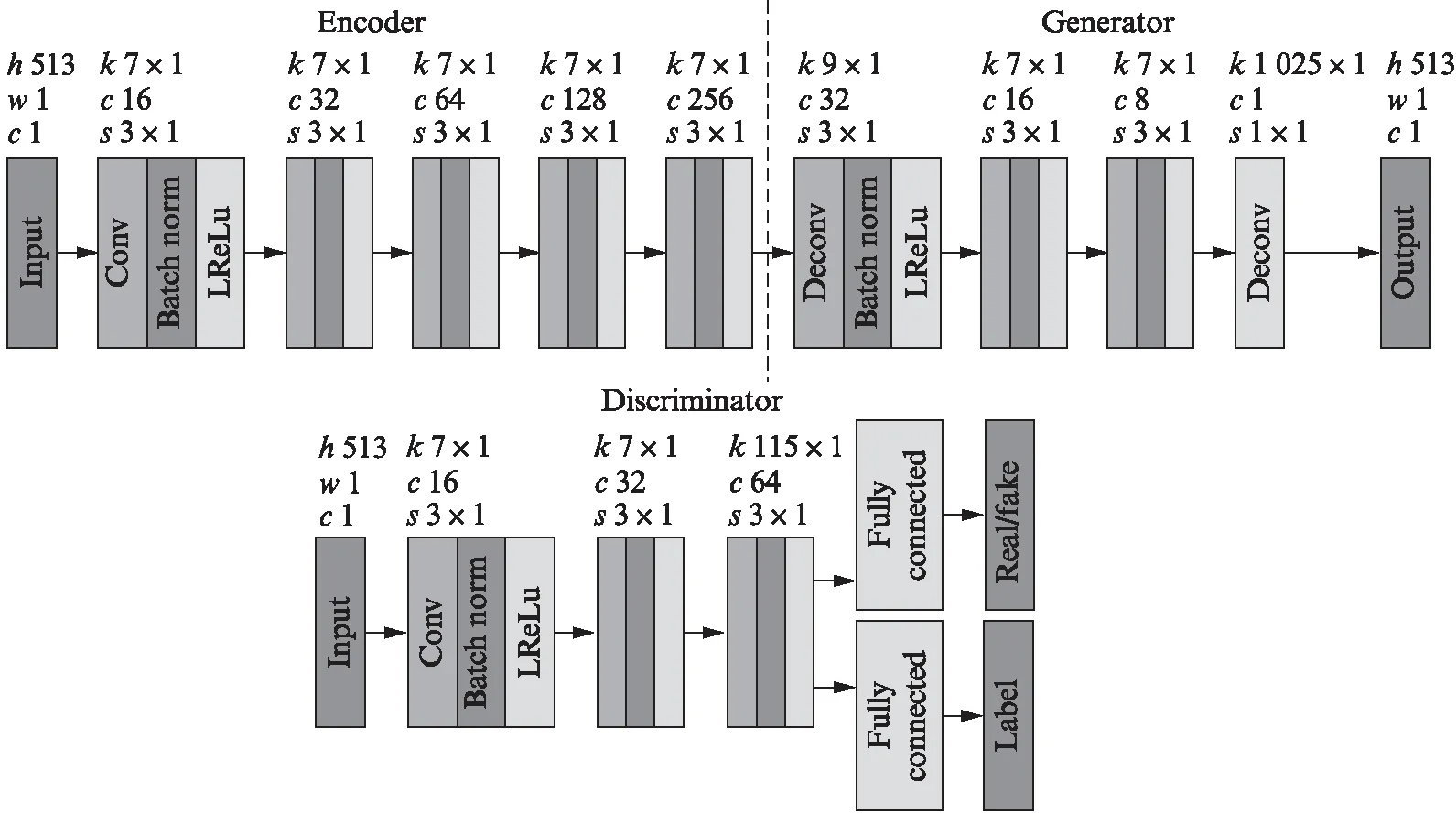
图3 VAACGAN模型的网络结构示意图Fig.3 Network structure diagram of VAACGAN model
图3中,h,w,c分别表示高度、宽度、通道数;k,c,s分别表示卷积层的内核大小、输出通道数、步长;Conv表示卷积;Deconv表示反卷积(转置卷积);Fully connected表示全连接层;Batch norm表示批归一化.潜在变量z的维度设置为128,训练的批次大小设置为16,训练周期为200,学习率为0.0001,最大迭代次数为150000.
为了验证本文提出方法的性能,本文将VAWGAN模型作为实验的基准模型,采用充分的客观评价和主观评价来评测基于VAACGAN的语音转换模型和基准模型的性能.
3.1 客观评价
本文选用梅尔倒谱失真距离(Mel Cepstral Distortion, MCD)作为客观评价标准,通过MCD来衡量转换后的语音与目标语音的距离[1-2],MCD(单位为dB)的计算公式如下:
(16)
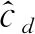
从图中分析可知,16种转换情形下VAWGAN基准模型和VAACGAN模型的转换语音的平均MCD值分别5.690和5.350,VAACGAN的平均MCD值比基准模型低5.98%,验证了本文提出的改进模型得到的转换语音的频谱相似度优于基准模型,表明了ACGAN能够显著改善转换语音的质量,提高合成音质.
3.2 主观评价
本文采用反映语音质量的平均意见得分(Mean Opinion Score, MOS)值和反映个性相似度的ABX值来评测转换后的语音.主观评测人员为20名有语音信号处理研究背景的老师及硕士研究生,本实验共有16种转换情形,每种情形有35句转换语音,为了避免主观倾向以及减少评测人员的工作量,在模型置乱的转换情形下,选择从每种情形的转换语音里面为每个人随机抽取1句,其中在ABX测试中,评测人员还需同时测听转换语音相对应的源和目标说话人的语音.
在MOS测试中,评测人员根据听到的语音的质量对该语音进行打分,评分分为5个等级: 1分表示完全不能接受,2分表示较差,3分表示可接受,4分表示较好,5分表示非常乐意接受.本文将16种转换情形划分为4类: 男-男,男-女,女-男,女-女.这4类转换情形下两种模型的转换语音MOS值如图5所示,本文提出的方法在4种转换情形下的MOS值均高于基准模型,从实验结果对比分析可得,基准模型和本文提出模型的平均MOS值分别为3.36和3.59,相比基准模型,本文提出模型的平均MOS值提高了6.85%,表明转换合成语音的自然度优于基准模型,再次验证了本文提出的利用ACGAN改进基准模型的方案能够有效地改善合成语音的音质,提高听觉质量.
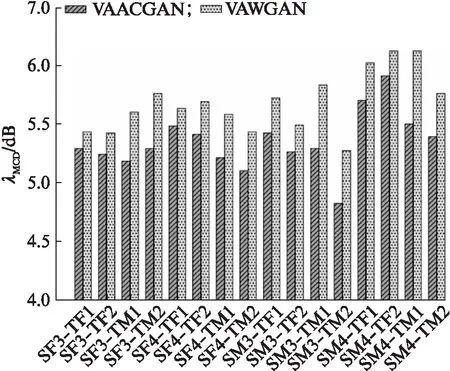
图4 16种转换情形下两种模型转换语音的MCD值对比Fig.4 Comparison of the MCD values of the speech converted by two models in 16 kinds of conversion cases
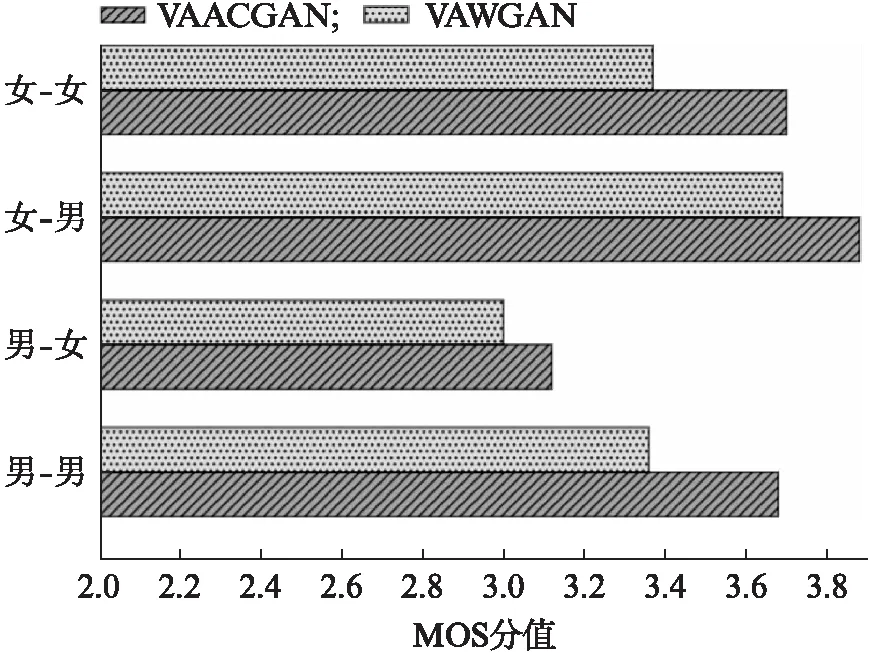
图5 两种模型在不同转换类别下的MOS值的对比Fig.5 Comparison of MOS values of two models under different conversion categories
在ABX测试中,评测人员评测A、B、X共3组语音,其中: A代表源说话人语音,B代表目标说话人语音,X为转换后得到的语音.评测人员判断转换后的语音更加接近源语音还是目标语音,在实际评测时,通常将相似度分为4种等级: A(sure)表示转换语音完全确定是源说话人;A(not sure)表示转换语音像源说话人但不完全确定;B(not sure)表示转换语音像目标说话人但不完全确定;B(sure)表示转换语音像目标说话人且完全确定.在评测结果分析中,将B(not sure)和B(sure)的百分比之和作为衡量转换语音更像目标说话人的评价标准,即ABX值.
本文将16种转换情形划分为同性转换(男-男,女-女)和异性转换(男-女,女-男),两种模型在同性转换下的ABX测试结果如图6(见第328页)所示,异性转换下的ABX测试结果如图7(见第328页)所示.在两种模型的评测中,没有评测人员认为转换后的语音确定是源说话人,因此A(sure)没有得分,即在图中没有比例显示.如图6所示,在同性转换情形下,VAWGAN模型和VAACGAN模型的ABX值的比例分别为70.2%和83.1%,与VAWGAN模型相比,VAACGAN模型提升了18.4%.在异性转换情形下,VAWGAN模型和VAACGAN模型的ABX值的比例分别为84.6%和88.7%,与VAWGAN模型相比,VAACGAN模型提升了4.8%.两种模型在异性转换情形下的说话人个性的相似度均优于同性转换情形下的说话人个性的相似度,分析认为: 这是因为在ABX的测试中异性转换情形下,人耳对说话人倾向性的测听更加明显.同时,VAACGAN模型在同性转换情形下转换语音的相似性提升较大,可见该模型更多地改善了同性转换情形下转换语音的相似性.在同性和异性两种情形下,VAACGAN模型的平均ABX值提升了10.98%,分析认为: VAACGAN模型不仅有效地改善了语音的合成音质,而且说话人个性相似度方面也有明显提高,进一步验证了本文提出的改进点能够显著提升转换合成语音的效果.
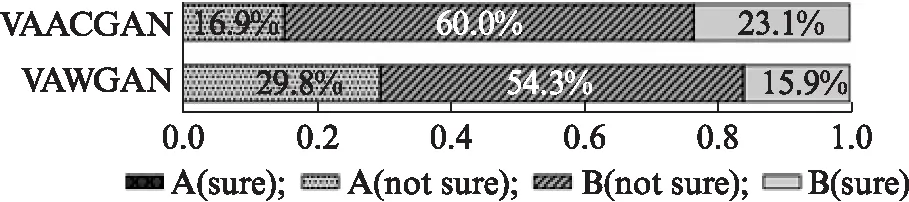
图6 同性转换情形下VAWGAN和 VAACGAN转换语音的ABX图Fig.6 ABX test results of VAWGAN and VAACGAN for intra-gender

图7 异性转换情形下VAWGAN和 VAACGAN转换语音的ABX图Fig.7 ABX test results of VAWGAN and VAACGAN for inter-gender
综上分析可得,VAACGAN模型相比VAWGAN模型,平均MCD值降低5.98%,平均MOS值提高6.85%,平均ABX值提高10.98%,表明本文通过ACGAN提出的改进模型显著提升了合成语音的质量和说话人个性的相似度.
4 结 语
本文提出1种基于变分自编码器和ACGAN的语音转换框架,可以进一步提升非平行文本条件下多对多语音转换的性能.该方法利用ACGAN的鉴别器增加了对样本分类的输出性能,使得鉴别器不仅能鉴别生成的频谱包络特征的真假,还能鉴别生成的频谱包络特征的类别,因此,ACGAN能够提升生成样本的质量,使得生成的样本更接近特定样本.充分的客观和主观实验表明: 本文提出的方法明显优于基准模型,在有效改善转换语音的合成质量的同时也显著提升了说话人个性相似度.下一步的工作将考虑d向量[14]、x向量[15]等更好的说话人表征向量在语音转换中的应用,以进一步提升转换合成语音的说话人个性的相似度.
猜你喜欢
传感器世界(2022年4期)2022-08-05
防爆电机(2022年3期)2022-06-17
传感器世界(2022年3期)2022-05-24
数字技术与应用(2021年1期)2021-03-24
——编码器
演艺科技(2020年7期)2020-08-13
读者(2019年18期)2019-09-11
新高考·高二数学(2017年8期)2018-03-13
通信产业报(2018年40期)2018-01-22
移动通信(2017年3期)2017-03-13
福建中学数学(2016年9期)2016-12-14
