
Method for reducing cloud workflow completion time under the task interruption
2020-06-22 06:51YawenWANGYunfeiGUOWenyanLIUShuminHUO
网络与信息安全学报 2020年3期
Yawen WANG, Yunfei GUO, Wenyan LIU, Shumin HUO
Method for reducing cloud workflow completion time under the task interruption
Yawen WANG, Yunfei GUO, Wenyan LIU, Shumin HUO
National Digital Switching System Engineering and Technology Research Center, Zhengzhou, China
As more and more large-scale scientific workflows are delivered to clouds, the business model of workflow-as-a-service is emerging. But there are many kinds of threats in the cloud environment, which can interrupt the task execution and extend the workflow completion time. As an important QoS parameter, the workflow completion time is determined by the critical task path. Therefore, critical path redundancy method is proposed to create a redundant path having the interact parallel relationship with the critical path, which can provide the protection for the tasks in the critical path and reduce the probability of the critical path interruption. Computing instance allocation is an essential part of the cloud workflow execution, since only the tasks assigned the instance can begin execution. In order to further reduce the workflow completion time, computing instance allocation algorithm based on HEFT (heterogeneous earliest finish time) is proposed. The algorithm considers diverse task dependency relationships and takes full advantages of the critical path redundancy method, which can improve the efficiency of workflow execution. Experimental results demonstrate that the proposed method can effectively reduce the cloud workflow completion time under the task interruption.
cloud workflow, task interruption, resource allocation, fault tolerance
1 Introduction
In many scientific research fields, such as quantum physics, astronomy, bioinformatics and so on, the process of scientific computing often consists of tens of thousands of steps, requiring large-scale data analysis and processing. In order to properly manage, arrange, execute and track these steps, the concept of scientific workflows is presented[1-2]. As the improvement of the complexity of the scientific problems to be solved, the present large scientific workflows often need to be implemented on complex distributed computing envirnments, such as supercomputers, distributed cluster systems and grid systems, but constructing such a system requires extraordinary expensive costs.
With the development of virtualization technologies, the emergence of cloud computing provides a new deployment and implementation solution for scientific workflow applications. The cloud computing takes the resource renting, application hosting and service outsourcing as the core, builds the computing environments through the integration of distributed resources to meet a variety of service requirements. As cloud customers, they no longer need hardware purchase and software deployment, they just need to pay some fees to easily access the required computing and storage resources through the internet. Due to low costs and the convenient resource access, more and more large-scale scientific workflows are delivered to clouds to complete.
In the process of scientific workflow execution, resource failures or malicious attacks will lead to the workflow interruption. To avoid such problems, Wang et al[3]propose to implement checkpoint backup of the workflow by storing the workflow intermediate data. When the workflow is interrupted, the abnormal state can be fixed by backtracking to the most recent checkpoint. However, checkpoint backtracking will generate time overhead, resulting in a delay in workflow completion time. For this problem, a method to reduce the cloud workflow completion time under the task interruption is proposed. The main contributions of this paper are listed as follows.
1) A threat model for cloud workflows is proposed. In the model, tasks can be interrupted due to malicious attacks or resource failures, delaying the workflow completion. And the delay effects are related to the length of the path where the interrupted task is located, the longer the path, the greater the delay effects.
2) Critical path redundancy method is proposed, which creates a redundant path having the interact parallel relationship with the critical path to reduce the interruption probability of the critical path in the workflow.
3) A computing instance allocation algorithm based on HEFT algorithm is proposed, the algorithm takes into account diverse task dependency relationships and takes full advantages of the critical path redundancy method, which can improve the efficiency of workflow execution.
2 Related work
The workflow completion time is an important QoS parameter, since the consumers always specify deadlines when submitting the workflow execution requests to clouds. Therefore, many scholars have studied how to ensure that the workflow can be completed before the deadline. Abrishami et al[4]design a two-phase scheduling algorithm called partial critical paths to minimize the cost of workflow execution while meeting a user-defined deadline. Similarly, Wu et al[5]present a two-step list scheduling method, which will rank tasks firstly and allocate each task a service which meets the sub-deadline and minimizes the cost. Calheiros et al[6]use the available spare time and budget surpluses between leased cloud computing resources to replicate tasks, thereby ensuring that tasks are completed before deadlines. Considering the execution costs and transmission costs comprehensively, on the basis of genetic algorithm, Verma et al[7]present a deadline constrained scheduling method, which can minimize the cost of the workflow execution while meeting the deadline for delivering the result. Currently, multi-core processors are widely used in clouds, for this reason, Deldari et al[8]propose a deadline-constrained workflow scheduling algorithm for multicore resources in the cloud. Lin et al[9]propose an online-scheduling strategy for continuous submitted scientific workflows on hybrid clouds, aiming to complete the deadline-constrained applications as fast as possible at a lower price. Zheng et al[10]combine the DVFS (dynamic voltage and frequency scaling) technique and heuristic algorithm to reduce overall energy consumption of a workflow given an allocation of tasks to hosts and a deadline to complete the execution. Sahni et al[11]exploit the advantages offered by cloud computing while taking into account the virtual machine performance variability and instance acquisition delay to identify a just-in-time schedule of a deadline constrained scientific workflow at lesser costs. However, the above literatures do not consider the situation where the tasks are abnormally interrupted. The multi-tenant coexistence service mode of the cloud platform can easily introduce malicious attacks. Consequently, the task interruption during the workflow execution should not be ignored.
In order to avoid the task interruption during the workflow execution, Yao et al[12]consider that the process of rescheduling in cloud systems have great similarities to the immune system which kept the body stable by removing the intrusive antigens, so an immune system inspired failure-aware rescheduling algorithm for the workflow task in clouds is designed to improve the reliability of the workflow. Task redundancy method is often used for improving the workflow reliability. Ding et al[13]propose a primary-backup workflow scheduling strategy, which copies the same task into two replicas and schedules the two replicas to different computing instances. In reference[14], the authors propose cloud scientific workflow execution system based on mimic defense technology, in which each task is executed by three computing instances. Considering the cost and reliability together, Poola et al[15-16]propose to use spot instances to reduce the costs of the task redundancy method. In reference[17], the authors combine rescheduling algorithm and task redundancy together to design a fault-tolerant workflow scheduling algorithm. From the above literatures, it can be found that rescheduling and task redundancy are two common methods to improve the workflow reliability. However, if the task is interrupted, rescheduling will take some time to restore the workflow state, and the time spent will delay the workflow completion. Task redundancy can seamlessly restores abnormal task states, but if each task is replicated into multiple copies and dispatched to different computing instances, it will consume a lot of resources. In reference[18], the authors propose that redundancy method should be used for protecting the important components. Based on this idea, it is proposed to use task redundancy method to protect the important tasks in the workflow.
3 The workflow model
3.1 The analysis of the workflow completion time
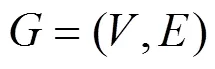


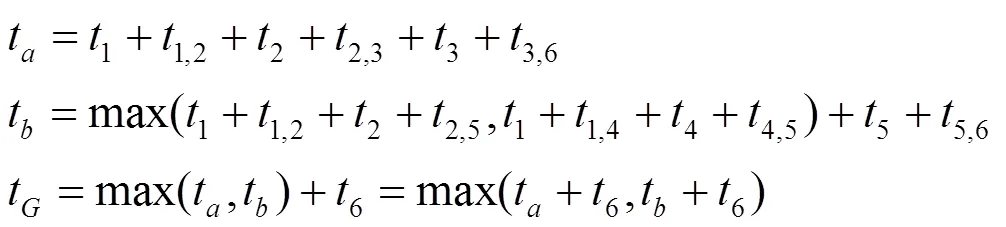
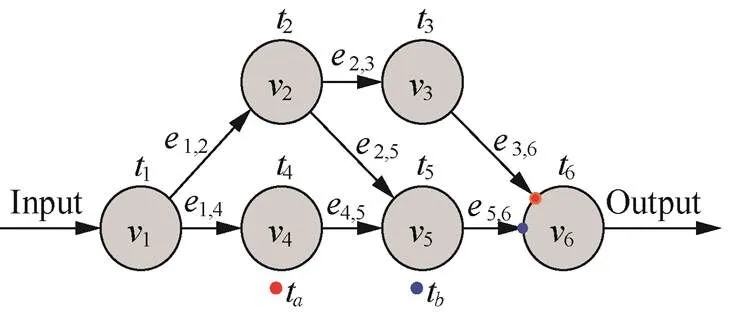
Figure 1 A sample workflow
3.2 The definition of the path length in the workflow



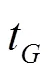

Therefore, the workflow completion time is decided by the longest path in the workflow, the longest path is called the critical path in the workflow.
Figure 2 The path division in the workflow
3.3 The identification of the critical path in the workflow
There are many kinds of computing instances on the cloud platform, different kinds of computing instances have different computing ability, so if the same task is assigned to different computing instances for execution, the required execution timewill be different. Therefore, in practical applications, the path length can not be used directly to identify the critical path since each task execution time is uncertain before computing instance allocation. For this problem, an algorithm proposed by Topcuoglu[19]to achieve the critical path identification is adopted.





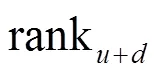
4 The threat model for the workflow
In the cloud computing system, many methods can be used to break the execution of cloud workflows. For example, adversaries can bypass logical isolation between VMs via side channels to attack the VMs performing the workflow[20]. A kind of vulnerabilities called VM Escape can be employed to help attackers access privilege domain of Hypervisor, then all the VMs supported by this Hypervisor[21]will be compromised easily. A malicious user can perform guest denial of service attack by starving there sources of the server, the VM applications running on the same server will be slowed down or even interrupted[22]. Furthermore, there are some attacks targeting hardware of the cloud[23], if the hardware of the physical machine on which the cloud workflow is executed fails, the cloud workflow will inevitably be interrupted.
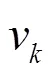





It demonstrates that the workflow completion time under the task interruption is related to the length of the path in which the interrupted task is located. The length of the path where the interrupted task is located longer, the delay effect is greater.
5 The proposed method
From (11) it can be found that there are two ways which can reduce the workflow completion time under the task interruption. One way is reducing the probability of the interruption of the tasks on the longest path. The other is reducing the length of the longest path in the workflow, i.e.in (11).
In this section, firstly the critical path redundancy method will be presented, which can reduce the probability of task interruption occurring on the critical path. Then computing instance allocation algorithm is proposed to improve the overall workflow execution efficiency, reducingin (11).
5.1 Critical path redundancy method
It has been discussed that reducing the interruption probability of the tasks on the critical path is a way to shorten the workflow completion time under the task interruption. Based on this idea, critical path redundancy method is proposed to provide the protection for the tasks in the critical path.


Figure 3 The independent parallel relationship and the interactive parallel relationship between between the critical path and the redundant path

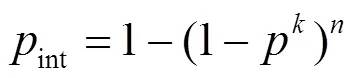
Figure 4 The security comparison between the independent parallel relationship and the interactive parallel relationship
Figure 5 The illustration of critical path redundancy method
5.2 Computing instance allocation algorithm
In the workflow, only the tasks that have been assigned computing instances from the cloud platform can be executed, so computing instance allocation is an essential part of cloud workflow execution.
三是水安全的层次性或尺度性。水安全的不同尺度,产生了国家水安全、流域水安全、区域或地区水安全,以及群体水安全和个体水安全等衍生概念。
It has been discussed that another way to reduce the workflow completion time under the task interruption is shortening the length of the longest path in the workflow, i.e.in (11), which can be realized by designing reasonable computing instance allocation strategy, since the interdependent tasks in the same instance do not need to transfer dependent data through network, which can save the time spent on the data transmission.
At the stage of computing instance allocation, a computing instance allocation algorithm is proposed. The proposed algorithm is improved from HEFT algorithm[19]which has proven to be one of the most effective task scheduling algorithms in distributed environments.
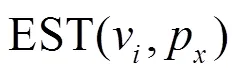
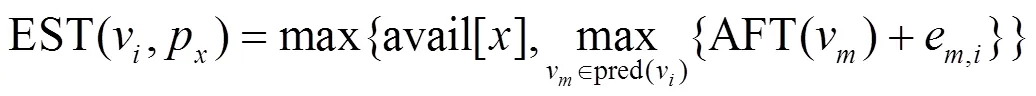

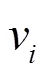



The proposed computing instance allocation algorithm is shown in Algorithm 1.
3) while there are unscheduled tasks in the list
8) end
10) end
5.3 The procedure of the proposed method
In this section, a workflow shown is used in Figure 1 to illustrate the procedure of the proposed method. It is assumed that there are 3 computing instances, the time required for each task execution on different computing instances is shown in Table 1. The communication time of each edge is shown in Table 2.

Table 1 The time required for each task execution on different computing instances

Table 2 The communication time of each edge in the workflow
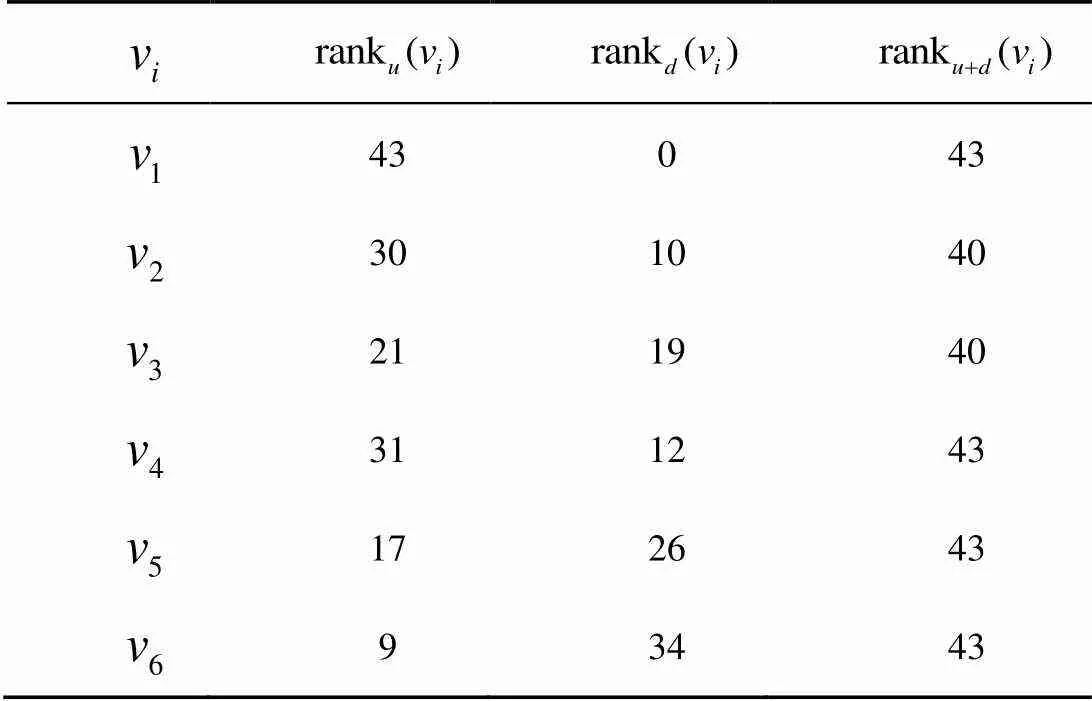
Table 3 ranku, rankd and ranku+d value of each task in the workflow
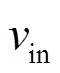
4) Performing computing instance allocation algorithm.
6 Experiment
In this section, three experiments are designed. ①Evaluating the workflow completion time of the critical path redundancy method. ② Evaluating the workflow completion time of the proposed computing instance algorithm. ③ Evaluating the resource requirements of the proposed method.
The experiments are conducted with the Workflow Sim toolkit[24], which is an open source software designed for workflow scheduling simulation in clouds. In this software, workflows are described in XML language, which contains the information about tasks and links. The proposed method in this paper mainly includes two steps: the critical path redundancy and computing instance allocation. Similarly, critical path redundancy module is constructed and computing instance allocation module. Critical path redundancy module firstly reads in the original XML file representing workflows. Afterwards it will find the tasks contained in the critical path and build a new redundant path by the proposed method. Then the module will output the new generated workflow in the format of XML. After that computing instance allocation module will be read in the new generated XML file, then it will perform the proposed computing instance allocation algorithm and output the results.
The workflows used for experiments are CyberShake, Epigenomics, Montage and Inspiral, which are published by Pegasus project[25-26]and widely used to measure the performance of scheduling algorithms. For each type of workflow, four kinds of DAG with different number of jobs and edges are introduced. For example, CyberShake workflow has 4 kinds with 30, 50, 100and 1 000 tasks, respectively. In this experiment, each kinds of workflow with maximum tasks is used for evaluation. The DAG characteristics of these workflows, including the number of nodes and edges, average data size and average task runtime are given in Table 4, the structures of them are shown in Figure 6.
6.1 Evaluating the workflow completion time of the critical path redundancy method
In this experiment, the number of available computing instances is 120, the computing ability of each instance is randomly generated from 800 to 1 200 MIPS. It is supposed that each task in the workflow has the same probability of interruption and the time of task interruption is equal to the average task runtime. The probability of task interruption is regarded as the variant to record the average workflow completion time. For comparison, 3 types of workflows are created, which are the original workflow, the workflow with non-critical path redundancy and the workflow with critical path redundancy. The original workflow adopts HEFT algorithm to allocate computing instances and the others employ the proposed computing instance allocation algorithm. The evaluation results are shown in Figure 7. From the figure it can be found that the starting and ending points of the three curves are roughly the same. The starting point represents that the tasks will never be interrupted and the ending point represents that the task must be interrupted. At these points, the length of the critical path in these workflows are the same, so the three curves share the same starting and ending points. Between the starting point and the ending point, the average completion time of path redundancy method is shorter than the original workflow, since the redundant path can reduce the impact of task interruption on workflow completion time to some extent. Compared with the non-critical path redundancy, critical path redundancy method has the better result, because the workflow completion time is decided by the length of the critical path in the workflow, the protection for the critical path will bring the greatest security gain.

Table 4 The parameters of workflows used for experiments[12]

Figure 6 The structures of workflows used for experiments
6.2 Evaluating the workflow completion time of the proposed computing instance allocation algorithm


Figure 7 The evaluation results of the critical path redundancy method
6.3 Evaluating the resource requirements of the proposed method
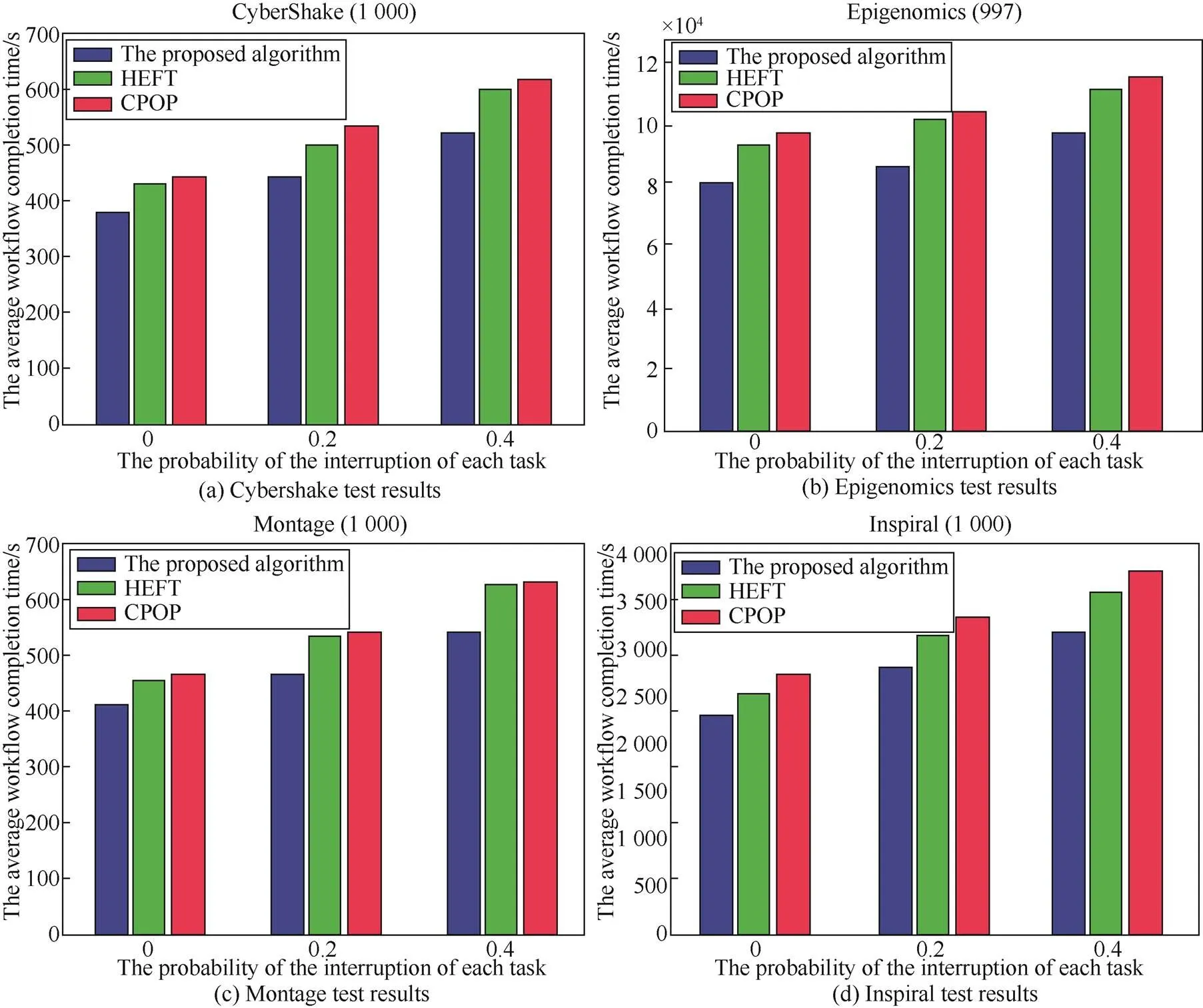
Figure 8 The evaluation results of computing instance allocation algorithm
7 Conclusion
The task interruption in the workflow will delay the workflow completion. For the problem, we firstly analyze and conclude that delay effects caused by the task interruption is related to the length of the path where the interrupted task is located, the longer the path, the greater the delay effects. Then we present the critical path redundancy method to create a redundant path having the interact parallel relationship between the critical path, reducing the interruption probability of the critical path. Furthermore, since only the tasks assigned the instance can begin execution, a computing instance allocation method based on HEFT algorithm is proposed, which takes into account diverse task dependency relationships and takes full advantages of the critical path redundancy method, improving the efficiency of workflow execution. The experiment is conducted on WorkflowSim, four real world workflow models are used for tests. Test results demonstrate that the proposed method can effectively reduce the workflow completion time under the task interruption.

Figure 9 The evaluation results of resource requirements of the proposed method
[1] LIU L, ZHANG M, BUYYA R, et al. Deadline-constrained coevolutionary genetic algorithm for scientific workflow scheduling in cloud computing[J]. Concurrency and Computation: Practice and Experience, 2017, 29(5): 1-12.
[2] RODRIGUEZ M A, BUYYA R. A taxonomy and survey on scheduling algorithms for scientific workflows in IaaS cloud computing environments[J]. Concurrency and Computation: Practice and Experience, 2017, 29(8): 1-23.
[3] WANG M, ZHU L, Chen J. Risk-aware checkpoint selection in cloud-based scientific workflow[C]//2012 Second International Conference on Cloud and Green Computing. 2012: 137-144.
[4] ABRISHAMI S, NAGHIBZADEH M, EPEMA D H J. Deadline-constrained workflow scheduling algorithms for infrastructure as a service clouds[J]. Future Generation Computer Systems, 2013, 29(1): 158-169.
[5] WU Q, ISHIKAWA F, ZHU Q, et al. Deadline-constrained cost optimization approaches for workflow scheduling in clouds[J]. IEEE Transactions on Parallel and Distributed Systems, 2017, 28(12): 3401-3412.
[6] CALHEIROS R N, BUYYA R. Meeting deadlines of scientific workflows in public clouds with tasks replication[J]. IEEE Transactions on Parallel and Distributed Systems, 2013, 25(7): 1787-1796.
[7] VERMA A, KAUSHAL S. Deadline constraint heuristic-based genetic algorithm for workflow scheduling in cloud[J]. International Journal of Grid and Utility Computing, 2014, 5(2): 96-106.
[8] DELDARI A, NAGHIBZADEH M, ABRISHAMI S. CCA: a deadline-constrained workflow scheduling algorithm for multicore resources on the cloud[J]. The journal of Supercomputing, 2017, 73(2): 756-781.
[9] LIN B, GUO W, LIN X. Online optimization scheduling for scientific workflows with deadline constraint on hybrid clouds[J]. Concurrency and Computation: Practice and Experience, 2016, 28(11): 3079-3095.
[10] ZHENG W, HUANG S. An adaptive deadline constrained energy‐efficient scheduling heuristic for workflows in clouds[J]. Concurrency and Computation: Practice and Experience, 2015, 27(18): 5590-5605.
[11] SAHNI J, VIDYARTHI D P. A cost-effective deadline-constrained dynamic scheduling algorithm for scientific workflows in a cloud environment[J]. IEEE Transactions on Cloud Computing, 2015, 6(1): 2-18.
[12] YAO G, DING Y, REN L, et al. An immune system-inspired rescheduling algorithm for workflow in cloud systems[J]. Knowledge-Based Systems, 2016, 99: 39-50.
[13] DING Y, YAO G, HAO K. Fault-tolerant elastic scheduling algorithm for workflow in cloud systems[J]. Information Sciences, 2017, 393: 47-65.
[14] WANG Y, WU J, GUO Y, et al. Scientific workflow execution system based on mimic defense in the cloud environment[J]. Frontiers of Information Technology & Electronic Engineering, 2018, 19(12): 1522-1536.
[15] POOLA D, RAMAMOHANARAO K, BUYYA R. Fault-tolerant workflow scheduling using spot instances on clouds[J]. Procedia Computer Science, 2014, 29: 523-533.
[16] POOLA D, RAMAMOHANARAO K, BUYYA R. Enhancing reliability of workflow execution using task replication and spot instances[J]. ACM Transactions on Autonomous and Adaptive Systems (TAAS), 2016, 10(4): 30.
[17] YAO G, DING Y, HAO K. Using imbalance characteristic for fault-tolerant workflow scheduling in cloud systems[J]. IEEE Transactions on Parallel and Distributed Systems, 2017, 28(12): 3671-3683.
[18] ZHENG Z, ZHOU T C, LYU M R, et al. Component ranking for fault-tolerant cloud applications[J]. IEEE Transactions on Services Computing, 2011, 5(4): 540-550.
[19] TOPCUOGLU H, HARIRI S, WU M. Performance-effective and low-complexity task scheduling for heterogeneous computing[J]. IEEE transactions on parallel and distributed systems, 2002, 13(3): 260-274.
[20] VERMA A, MITTAL M, CHHABRA B. The mutual authentication scheme to detect virtual side channel attack in cloud computing[J]. International Journal of Computer Science and Information Security (IJCSIS), 2017, 15(3).
[21] GROBAUER B, WALLOSCHEK T, Stocker E. Understanding cloud computing vulnerabilities[J]. IEEE Security & privacy, 2010, 9(2): 50-57.
[22] MISHRA P, PILLI E S, VARADHARAJAN V, et al. Intrusion detection techniques in cloud environment: A survey[J]. Journal of Network and Computer Applications, 2017, 77: 18-47.
[23] STEWIN P, BYSTROV I. Understanding DMA malware[C]// International Conference on Detection of Intrusions and Malware, and Vulnerability Assessment. 2012: 21-41.
[24] CHEN W, DEELMAN E. WorkflowSim: a toolkit for simulating scientific workflows in distributed environments[C]//2012 IEEE 8th International Conference on E-Science. 2012: 1-8.
[25] JUVE G, CHERVENAK A, DEELMAN E, et al. Characterizing and profiling scientific workflows[J]. Future Generation Computer Systems, 2013, 29(3): 682-692.
[26] DEELMAN E, VAHI K, JUVE G, et al. Pegasus, a workflow management system for science automation[J]. Future Generation Computer Systems, 2015, 46: 17-35.
10.11959/j.issn.2096−109x.2020018
2019−05−29;
2019−08−09
Yawen Wang, 15738321455@163.com
The National Key R & D Program of China (2018YFB0804004), The Foundation for Innovative Research Groups of the National Natural Science Foundation of China (61521003)
Yawen WANG, Yunfei GUO, Wenyan LIU, et al. Method for reducing cloud workflow completion time under the task interruption[J]. Chinese Journal of Network and Information Security, 2020, 6(3): 113-125.
Yawen WANG (1990− ), born in Henan. He is working on his Ph.D degree at National Digital Switching System Engineering and Technological Research Center. His research interests include cloud security and scientific workflow scheduling.

Yunfei GUO (1963− ), born in Henan. He is a Ph.D supervisor and professor at National Digital Switching System Engineering and Technological Research Center. His research interests include cloud security and telecommunication network security.
Wenyan LIU (1986− ), born in Henan. He is a lecturer at National Digital Switching System Engineering and Technological Research Center. His research interests include cloud security.

Shumin HUO (1985− ), born in Shanxi. He is a lecturer at National Digital Switching System Engineering and Technological Research Center. His research interests include cloud security.
猜你喜欢
成都信息工程大学学报(2021年3期)2021-11-22
甘肃教育(2021年10期)2021-11-02
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
人大建设(2017年6期)2017-09-26
新课程·小学(2016年10期)2016-12-12
考试周刊(2016年94期)2016-12-12
散文百家·下旬刊(2016年9期)2016-11-23
中国科技术语(2016年4期)2016-11-19
太空探索(2016年5期)2016-07-12
时代英语·高三(2014年5期)2014-08-26
