
橡胶树叶片钾素含量高光谱估算模型研究
2020-06-22 02:35黎小清陈桂良许木果丁华平刘忠妹杨春霞
西南农业学报 2020年4期
黎小清,陈桂良,许木果,丁华平,刘忠妹,杨春霞
(云南省热带作物科学研究所,云南 景洪 666100)
【研究意义】钾是橡胶树生长和胶乳生产所必需的养分,具有提高光合作用强度、促进淀粉和糖的形成、增强橡胶树的抗逆性和抗病能力以及产胶和排胶能力的作用[1]。叶片营养诊断是当前较成熟的简单可行的橡胶树营养诊断方法[2-3]。传统的叶片化学分析,虽然具有较高的检测精度,但从样品采集、制备到分析测试需要消耗大量的时间、人力和物力,测试结果时效性差。通过建立橡胶树营养高光谱估算模型,能够快速获得橡胶树营养状况,并节约大量实验室资源。【前人研究进展】国内外有关植物生化组分的高光谱估算研究大多集中在氮素[4-17],氮素含量估算做了大量的研究工作并取得了较好的效果。部分学者也开始尝试建立植物叶片其他元素含量估算模型。郭澎涛等利用高光谱技术结合BPANN模型对橡胶苗叶片磷含量进行了预测[18]。刘延等采用多元逐步回归分析的方法建立了基于光谱特征单变量估测云烟97号叶片钾含量模型[19]。李园等通过光谱参数组合有效地估测了香梨叶片铁元素含量[20]。偏最小二乘法(PLS)和支持向量机(SVM)是常用的回归建模方法,大量用于构建植物生化组分的估算。笔者采用PLS建立了橡胶树叶片氮素高光谱估算模型,取得了良好的效果[21-22]。黄双萍等基于敏感特征波段建立柑橘叶片钾素含量预测模型,结果显示,PLS和SVM模型效果差异不大,但明显优于多元线性回归(MLR)[23]。Zhai等通过比较PLS和SVM,认为SVM结合可见光/近红外光谱数据在估算植物生化组分含量方面具有较大的潜力[24]。【本研究的切入点】目前,有关橡胶树叶片钾素含量高光谱估算的研究未见报道,基于可见光/近红外光谱数据能否准确估算橡胶树叶片钾素含量还有待研究。【拟解决的关键问题】PLS能够很好地消除光谱数据的共线性,但它是一种线性模型,而SVM能用于非线性建模。文章尝试将PLS与SVM结合用于估算叶片钾素含量。以云南西双版纳为研究区,采集了2个不同品种、涵盖6个割龄的橡胶树叶片样品,并测定其反射率和钾素含量。通过比较偏最小二乘法(PLS)和偏最小二乘-支持向量机法(PLS-SVM),确定最优的建模方法,构建橡胶树叶片钾素含量高光谱估算模型,以实现橡胶树钾素营养的快速检测。
图1 采样点分布Fig.1 Distribution of sampling sites
1 材料与方法
1.1 数据统计
1.1.1 叶片样品采集 2018年8-9月,综合考虑不同的品种、割龄、营养状况和地理位置,确定了6个采样点(图1)。在每个采样点随机选择橡胶树采样,采集主侧枝顶蓬叶中无病虫害成熟复叶的中间叶作为1个样品,共采集到298个叶片样品。采集的样品涵盖了2个品种、6个割龄(表1)。

表1 橡胶树叶片样品信息
1.1.2 叶片反射率测定 叶片反射率测定在实验室进行。测定仪器为ASD FieldSpec4(Hi-Res),波长范围350~2500 nm,其中350~1000 nm采样间隔1.4 nm,光谱分辨率3 nm;1001~2500 nm采样间隔2 nm,光谱分辨率8 nm,输出光谱数据间隔为1 nm,因此,每个叶片样品的光谱数据输出的总波段为2151个。测定光源由植物探头提供,测量前先进行参考白板校正,测量时利用叶片夹持器将叶片固定,以叶片的主叶脉为界,选取叶片上中下部共6个无病斑区域,测定叶片正面的光谱反射率。每个区域连续扫描3次,每个叶片样品的反射率由18条光谱曲线取平均而得。
1.1.3 叶片钾含量测定 采用H2SO4-H2O2消煮、火焰光度计法测定叶片钾含量。将已测定反射率的叶片样品去除叶柄和主叶脉,在105 ℃烘箱中进行杀青,然后在60 ℃下烘干,最后碾钵捣碎。称取叶片样品0.08~0.10 g于100 mL消化试管中,沿消化管内壁加浓H2SO43 mL,在380 ℃下消化1 h,取下消化管稍冷却,加H2O2至清亮,继续加热5 min,取下冷却后转移至50 mL容量瓶,蒸馏水定容,同时做空白对照。将待测液于原子吸收分光光度计(AA-6300C)测定钾含量,每组叶片样品重复分析2次,取平均值作为叶片钾含量。
1.2 建模方法
1.2.1 光谱反射率预处理 由于400 nm以下的光谱反射率噪声较大,将其剔除,剩余的400~2500 nm光谱反射率数据用于文章的建模研究。根据杠杆值和学生残差判定异常样品[25],共剔除4个异常样品。将剔除异常样品后的294个叶片样本用于建模分析,按钾含量从小到大排序,每5个样本中选取第3个为验证样本,其余为校正样本,最后得到校正样本235个,验证样本59个。
模型校正前,首先将全部光谱反射率重采样为10 nm间隔(405、415、425…2485、2495 nm)。为了消除光谱数据无关信息和噪声,提高建模精度,采用以下方法或方法组合对重采样后的原始光谱反射率R进行预处理[26]:多元散射校正(MSC)、标准正态变换(SNV)、Savitzky-Golay平滑 (SG)、一阶导数(FD)和二阶导数(SD)。
1.2.2 偏最小二乘法 偏最小二乘法(PLS)目前在可见光/近红外光谱定量分析中应用相当广泛。应用Unscrambler 9.7软件的偏最小二乘法(PLS1)和留一交叉验证的方式进行PLS建模[27]。
1.2.3 偏最小二乘-支持向量机 支持向量机(SVM)通过核函数将低维非线性问题转换成高维的线性问题,将复杂的非线性问题进行线性化,广泛应用于分类与回归模型的构建[28-29]。
偏最小二乘-支持向量机(PLS-SVM)方法是将PLS与SVM相结合的一种建模方法。PLS-SVM的基本思想是用PLS提取主成分,用主成分得分变量代替初始输入变量,然后利用SVM进行模型校正和验证。其中PLS主成分得分矩阵T可以由式(1)计算而得[30-31]:
T=X0W(PTW)-1
(1)
式中,成分得分矩阵T=[t1,…,tr],X0是原始自变量矩阵X经中心化处理后得到的矩阵,P=[p1,…,pr]为负载矩阵,W=[w1,…,wr]为系数矩阵。
模型验证时,验证集的PLS主成分得分矩阵由式(1)计算而得,其中X0是验证集原始自变量矩阵X经中心化变换得到的矩阵,负载矩阵P和系数矩阵W从PLS校正模型中提取得到。
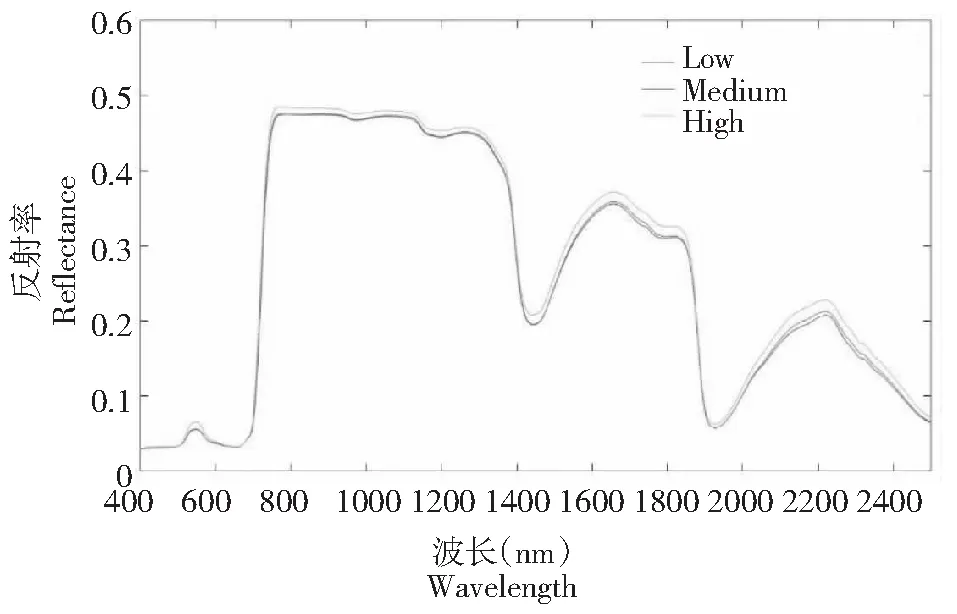
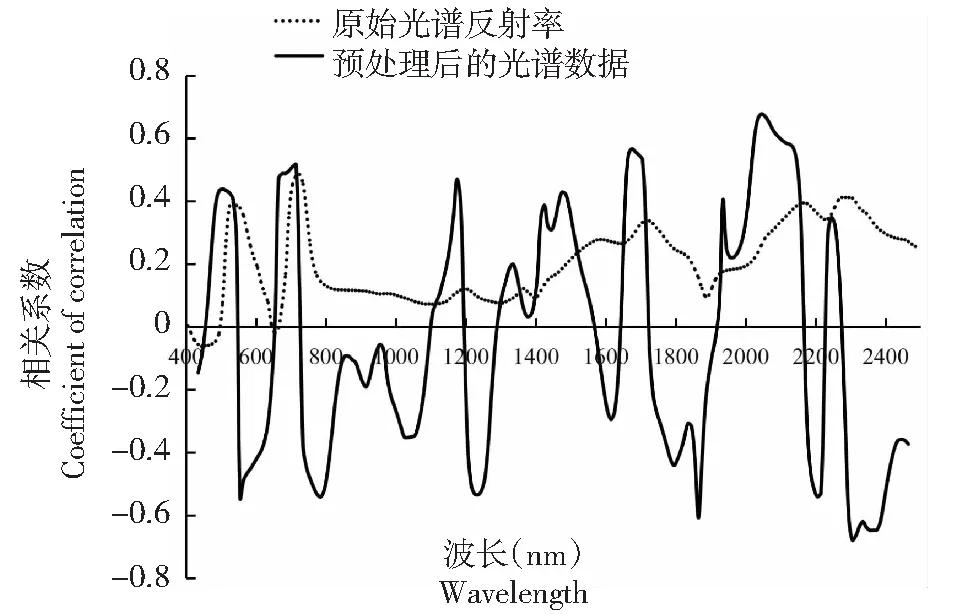
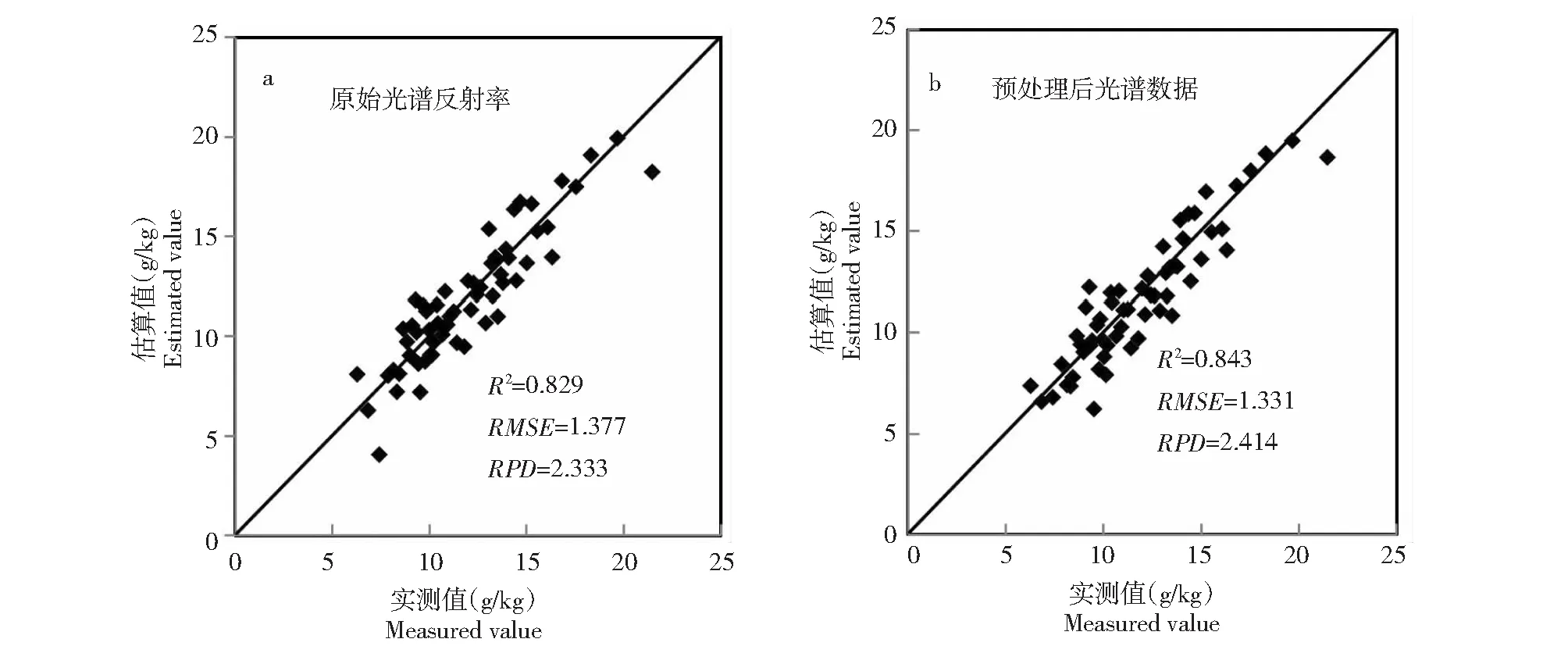
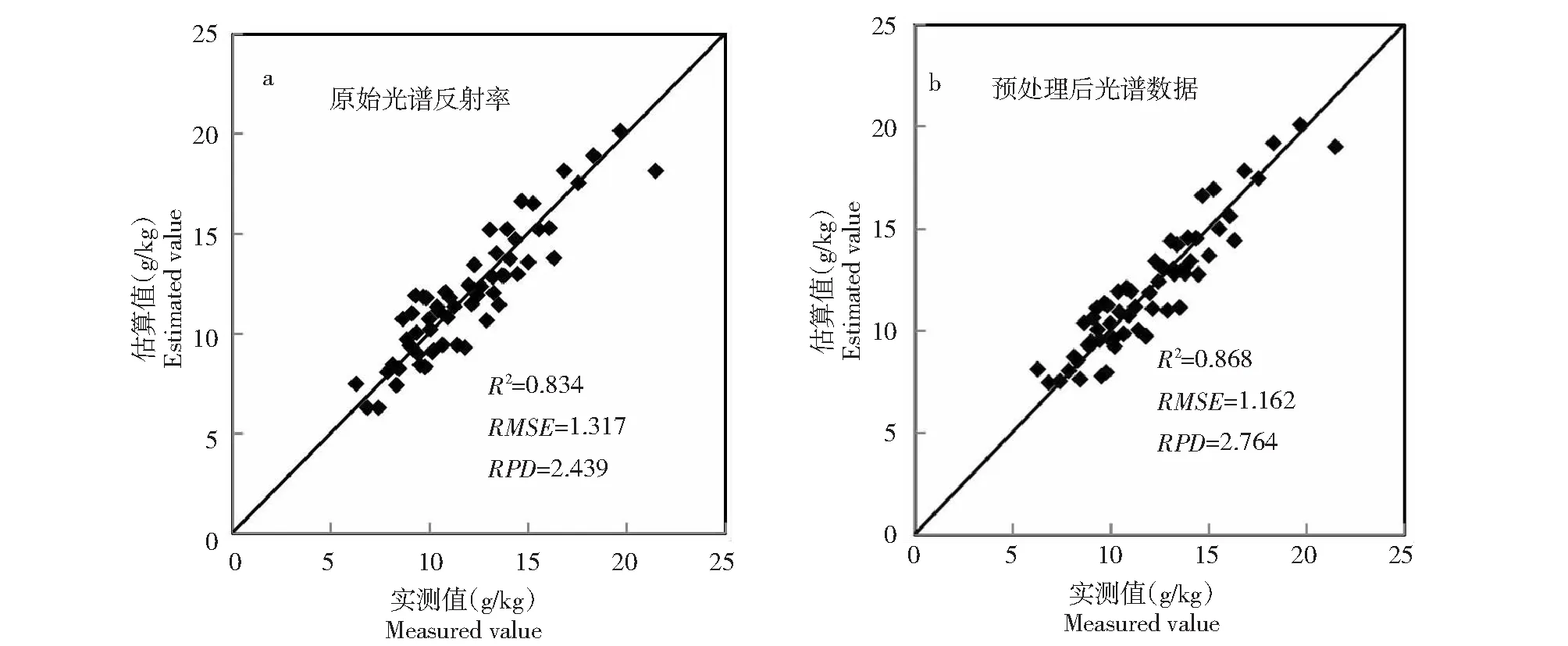
1.2.4 模型验证 采用决定系数(R2)、均方根误差(RMSE)和相对分析误差(RPD)进行模型验证。R2和RPD越大,同时RMSE越小,说明模型具有较高精度。RPD≥2.25,说明模型估算效果良好;1.75 从表2可见,由于采集了不同区域、不同品种和不同割龄的叶片样品,样品钾含量变异程度较大,有利于建模研究。将所有样本按钾素含量高低划分为高(>13 g/kg)、中(10~13 g/kg )、低(<10 g/kg)3种营养水平,并计算每种营养水平叶片样品的平均反射率光谱,发现绝大部分波段的反射率与钾素含量成正相关,且不同钾素营养水平橡胶树叶片的反射率光谱曲线有相似的反射特征(图2)。在400~700 nm波段,叶片的反射率总体较低,是因为色素对该波段能量的强烈吸收。在550 nm附近,由于叶绿素吸收作用较小,形成1个反射峰。在700~750 nm波段,反射率急剧上升。在750~1300 nm波段,受叶片细胞结构的影响,出现1个高反射平台。在1450和1950 nm附近受水分强烈吸收的影响,形成2个吸收峰。 表2 用于模型校正和验证的橡胶树叶片样品钾含量描述性统计 图2 3种钾素营养水平叶片的平均原始反射率光谱Fig.2 The average raw reflectance spectra of leaves from three levels of potassium nutrition 应用不同预处理方法或方法组合(MSC、SNV、SG、FD、SD)对重采样后的原始光谱反射率进行预处理,基于预处理后的光谱数据与钾素含量数据,采用PLS及留一交叉验证方法建模,其中,SG平滑模式的平滑点数在3~101的奇数中筛选,多项式次数1~9中筛选,按照预测均方根误差选择最优的光谱预处理模式。MSC和SNV变换在unscrambler 9.7中实现,SG平滑和PLS模型的建立通过MATLAB 2015编程实现。 通过筛选,SNV、SG和FD组合方法是最佳的预测处理方法,其中,SG平滑点数为7,多项式次数为1或2。图3为叶片原始光谱反射率及预处理后的光谱数据与叶片钾含量的相关系数。原始光谱反射率最高相关系数为0.486出现在725 nm处,预处理后最高相关系数达到-0.679,出现在2305 nm处。相比原始光谱反射率,预处理后的光谱数据与叶片钾含量的相关系数有了显著地提高。 图3 叶片原始光谱反射率及预处理后的光谱数据与叶片钾含量的相关系数(n=235)Fig.3 The correlation coefficients between leaf potassium content and raw reflectance and preprocessed spectral data(n=235) 基于校正集的叶片钾含量与原始光谱反射率及预处理后光谱数据,应用Unscrambler 9.7软件,采用PLS1及留一交叉验证方法建立PLS模型,模型校正效果如表3所示。利用验证集对所建模型进行精度验证,模型的预测效果如图4所示。 从表3的PLS模型中,按照最佳PLS因子数确定主成分个数,分别提取原始光谱反射率与预处理后光谱数据的主成分得分向量,作为SVM的条件属性,叶片钾素含量作为决策属性。利用LIBSVM软件[33]进行SVM的参数优选、建立模型及模型验证。建模前,利用LIBSVM软件的svm-scale对光谱数据进行归一化缩放。 文章选取SVM类型为epsilon-SVR,核函数类型为radial basis function,通过网格搜索和10折交叉验证,得到的最优参数如表4所示。利用验证集对所建模型进行精度验证,模型的预测效果如图5所示。 通过剔除异常波段和光谱反射率重采样,获得了采样间隔为10 nm(405、415、425…2485、2495 nm)的原始光谱反射率。采用多元散射校正(MSC)、标准正态变换(SNV)、SG平滑(SG)、一阶导数(FD)和二阶导数(SD)等预处理方法或方法组合对叶片原始光谱反射率进行预处理,通过筛选得到最佳预处理模式为SNV+SG+FD的组合方法,其中,SG平滑点数为7,多项式次数为1或2。相比原始光谱反射率,预处理后的光谱数据与叶片钾含量的相关系数有了显著地提高,最高相关系数从0.486增加到-0.679。 表3 PLS模型的校正效果 图4 PLS模型预测结果Fig.4 The partial least squares regression model prediction 图5 PLS-SVM模型预测结果Fig.5 The partial least squares-support vector machine model prediction 分别采用偏最小二乘法(PLS)和偏最小二乘-支持向量机法(PLS-SVM)建立了橡胶树叶片钾素含量的高光谱估算模型。采用验证集对PLS模型和PLS-SVM模型进行验证,结果显示,决定系数R2分别为0.843和0.868,均方根误差RMSE分别为1.331和1.162 g/kg,相对分析误差RPD分别为2.414和2.764,2种模型均具有良好的估算效果,但PLS-SVM模型具有更高的估算精度。 表4 最优PLS-SVM模型的参数 为了得到更具有代表性和钾含量变异程度较大的橡胶树叶片样品,本次样品的采集综合考虑不同的品种、割龄、营养状况和地理位置,但由于各类型样品较少,并未按品种和割龄分别建模。一般而言,在作物养分高光谱估算模型研究中,应考虑品种间差异[11,22]。同时橡胶树又是多年生的经济作物,割龄可能也会对高光谱估算养分产生影响。今后可开展分品种和割龄建模研究,看是否能够提高模型的估算精度。 从文章研究来看,将不同品种和割龄的叶片样品混合用于构建橡胶树叶片钾素含量高光谱估算模型也能够取得理想的估算效果。2 结果与分析
2.1 钾素含量与光谱反射率

2.2 钾素含量与光谱反射率及其变换光谱的相关分析
2.3 PLS 模型
2.4 PLS-SVM模型
3 讨 论


4 结 论
猜你喜欢
作物学报(2022年1期)2022-11-05
冶金能源(2022年5期)2022-10-14
——缺陷度的算法研究
条码与信息系统(2022年3期)2022-07-05
汽车电器(2022年6期)2022-07-02
热带生物学报(2022年1期)2022-03-09
中国马铃薯(2021年5期)2021-12-21
农业科技与信息(2021年9期)2021-12-07
农业科技与信息(2021年8期)2021-12-06
汽车文摘(2018年2期)2018-11-27
湖北农业科学(2017年15期)2017-09-09
