
基于知识图谱的信息查询系统设计与实现*
2020-06-18 09:08翟社平王志文
计算机与数字工程 2020年4期
杨 荣 翟社平 王志文
(西安邮电大学计算机学院 西安 442000)
1 引言
随着大数据时代的到来,人们的日常生活已于互联网密不可分,人们在互联网上自由获取及发布信息的同时,使得网络上非结构化、半结构化数据量呈指数型增加,给用户检索有效信息带来了一定的困难。基于上述背景,领域内的信息查询系统逐渐走进人们的视野。
领域内的信息查询系统通过关键词匹配索引的方式进行信息检索,并将相关链接返回给用户。这种检索方法无法准确理解用户的需求,且返回的是与搜索关键词相关的链接列表,而非用户需要的准确信息。用户需要从链接的文档中筛选查询才能获得所需信息,这给用户的查询增加了额外的工作量。为了改善传统查询系统的弊端,张会会[1]提出基于ArcEngine的信息查询系统,赵琳[2]提出基于graph Info的城市公交信息查询系统。但由于自然界实体间关系的复杂性,上述系统仍存在查询结果不全、不准的缺陷。为了满足用户更加快速、准确、智能地获取所需信息的需求,知识图谱应运而生。
本文通过研究知识图谱的构建技术以及特定领域信息查询系统搭建的相关理论及实现方法,利用网络爬虫、数据索引、知识抽取等关键技术,设计并实现了基于知识图谱的信息查询系统[3]。该系统具有特定领域内的实体查询功能,即通过理解用户需求,从实体库中检索出相关实体返回给用户,用户可更加快速、准确、智能地获取所需信息。
2 相关理论
2.1 知识图谱及其构建
1)知识图谱定义
知识图谱本质上是语义网络,是一种基于图的数据结构,由节点(Point)和边(Edge)组成,如图1所示。在知识图谱里,每个节点表示现实世界中存在的“实体”,每条边为实体与实体之间的“关系”[4]。知识图谱是关系的最有效的表示方式。通俗地讲,知识图谱就是把所有不同种类的信息(Heterogeneous Information)连接在一起而得到的一个关系网络,它提供了从“关系”的角度去分析问题的能力[5]。
通过知识图谱查询系统将搜索结果进行知识系统化,用户搜索任何一个关键词都能获得完整的知识体系,从而使用户不必浏览大量网页,就可以准确定位和深度获取知识[6]。
2)知识图谱的构建
知识图谱主要有自顶向下与自底向上两种构建方式。自顶向下指的是先为知识图谱定义好本体与数据模式,再将实体加入到知识库。该构建方式需要利用一些现有的结构化知识库作为其基础知识库,其流程图如图2所示。自底向上指的是从一些开放链接数据中提取出实体,选择其中置信度较高的实体加入到知识库,再构建顶层的本体模式。

图2 自顶向下构建知识图谱
2.2 信息检索
信息检索是指将信息按一定的方式组织起来,并根据信息用户的需要找出有关信息的过程和技术。狭义的信息检索是指从信息集合中找出所需要的信息的过程。信息检索经历了手工检索、计算机检索、网络化检索、智能化检索等多个发展阶段。检索的工具也由通用的搜索引擎如Google,Yahoo发展到如今应用领域高度专业化的检索工具。
信息检索是以信息的存储为基础的,要存储的信息不仅包括原始文档数据,还包括图片、视频和音频等。首先要将这些原始信息进行计算机语言的转换,并将其存储在数据库中,否则无法进行机器识别。待用户根据意图输入查询请求后,检索系统根据用户的查询请求在数据库中搜索与查询相关的信息,通过一定的匹配机制计算出信息的相似度大小,并按从大到小的顺序将信息转换输出,信息检索的原理如图3所示。
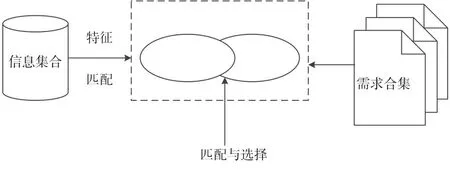
图3 信息检索的原理
3 原型系统设计
3.1 系统逻辑结构
系统的逻辑结构可分为四层,如图4所示,分别为网络数据获取层、数据预处理层、数据存储层、查询应用层。具体流程如下:网络数据获取层利用爬虫技术从图书百科类网站、垂直类网站,比如:“豆瓣读书”、“当当读书”,获取网页文本资源。数据预处理层作为接口层,为下层模块提供输入数据的入口,为上层模块提供优质的数据来源。利用解析器抽取出其中的非结构化、半结构化的数据、之后利用NLPIR对这些数据进行分词、词性标注预处理操作,从而将这些数据转化为结构化的数据。数据存储层依照固定的格式存入CSV文件中,同时利用Cypher语言将实体及其关系文件导入Neo4j数据库中,完成知识的存储以及可视化展示。查询应用层通过搭建出信息查询系统,为用户提供知识检索,满足用户的信息查询需求。
3.2 主要功能模块
1)数据获取模块
由于垂直类网站“豆瓣读书”实体数量较大且网页布局规范,因此抽取规则的制定较为简单。首先,本文通过利用爬虫技术获得网页文本资源,利用Jsoup API对网页文本进行解析,然后利用该API中所提供的select方法找到class=“info”的
标签,该方法返回的是泛型为“Emelents”的List集合,调用foreach迭代方法就可以得到
中的所有孩子标签,同时调用HTML方法就可以得到中的HTML字符串,该字符串就可定义为图书实体的一个属性,最后使用条件判断语句获取到每个标签后紧跟的Text文本,该文本就是对应属性的值,从而完成实体抽取工作。
基于图对比注意力网络的知识图谱补全 分词在英语教学中的妙用 结巴分词在词云中的应用 结巴分词在词云中的应用 图表 对大学案理研讨课学生信息检索意识若干问题的思考 主动对接你思维的知识图谱 中外档案网站信息检索功能比较研究 公共图书馆信息检索服务的实践探索——以上海浦东图书馆为例 中国知名官方智库图谱
2)数据预处理模块
(1)分词与词性标注
本文中所使用的分词以及词性标注的方法都是通过调用NLPIR系统的用户词典功能[9]。分词方法的基本原理是将待分词的字符串与系统已存在中的词典逐一比较,划分词语的关键在于能否可以从词典中找到相同的字符串。具体识别流程如下:倘若词典中的最长词条的长度为x,则取出待分词字符串中前x个字符,与词典中的词条进行比较,若比较成功,返回该字符串作为一个新的词划分出来,若失败,则取出前x-1个字符进行比较,重复上述步骤。
词性标注方法首先对于依靠爬虫技术爬取出的网页文本进行分词操作,之后对分出的单词作词性标注,同时对名词进行实体分析,从而识别到对应的实体。
(2)相似度计算
本文中的相似度计算方法:基于余弦定理的相似度计算,即利用两个向量夹角余弦值来表示两个字符或字符串的差异[7]。若文本向量分别为x1x2x3x4…x1000,y1y2y3y4…y1000,则可以得出余弦公式如式(1)。
(3)文本分类
文本分类采用KNN邻近算法(K-Nearest Neighbors)[8],其给定待分类文本之后,根据选择出的特征词计算出与该文本比较相似的K篇文本,然后根据与其相似的文本类别确定出所属的类别。算法代码如下所示。
KNN算法伪代码
#输入:A[n]为N个训练样本在空间中的坐标,k为近邻数
#输出:x所属的类别
1.取A[1]~A[k]作为x的初始近邻,计算与测试样本x间的欧式距离d(x,A[i]);
2.按d(x,A[i])升序排序;
3.取最远样本距离D=max{d(x,a[j])|j=1,2,…,k};
4.for(i=k+1;i<=n;i++)#继续计算剩下的n-k个数据的欧氏距离
计算a[i]与x间的距离d(x,A[i]);
5.if(d(x,A[i])) then用A[i]代替最远样本#将后面计算的数据直接进行插入即可; 6.最后的K个数据是有大小顺序的,再进行K个样本的统计即可; 7.计算前k个样本A[i],i=1,2,…,k所属类别的概率; 8.具有最大概率的类别即为样本x的类; 3)知识存储模块 本文中使用的存储工具为Neo4j图数据库,该数据库底层会将用户定义的节点及其关联关系以图的形式存放,因此可以实现高效率的查找操作[10]。通过图中任意节点可以找到与该节点有关联关系的节点,如图5显示出该种数据库最为重要的功能便是存储实体节点和关系。 4)图谱构建模块 知识图谱的构建流程包含六个模块,分别为知识获取、知识融合、知识存储、查询式的语义理解、知识检索和可视化展现[11]。其中知识库的构建是知识图谱实现的核心,知识库中存储的内容需要经过广泛的知识获取及充分的知识融合。当用户进行查询检索时,用户的自然语言查询式经过语义分析处理后进入检索系统,然后和知识库中的内容进行匹配,整合后的反馈结果以可视化的形式展现给用户。 本系统搭建的硬件环境是Intel处理器、6G内存、互联网;软件环境为Windows 7操作系统、Eclipse开发平台;所选用的面向对象开发语言为Java以及汉语分词工具为NLPIR、利用Tomcat搭建Http服务器。实验采用的结构化数据集如表2所示。 表2 实验数据 本系统是针对图书领域的JavaWeb项目,具体实验流程如下: 1)确定系统开发的技术,包括编程语言为Java语言,数据库为Neo4j图数据库,开发工具为Eclipse,Web服务器为Tomcat。 2)从垂直类网站“豆瓣读书”抽取出实体,存入CSV实体文件,将实体之间的关系按照相应的格式存入CSV实体关系文件,最后将这两份文件导入数据库,从而完成图谱的构建。 3)确定软件开发架构为MVC中的JSP+Servlet+JavaBean模式,从而提高开发效率[12],该模式的响应流程如图6所示。 图6 MVC控制流程 查询系统可以快速响应用户的查询需求,系统通过研究查询内容背后语义信息,给用户全面准确地结果。如图7所示当用户输入“活着的作者”,查询到的不仅是作者余华的信息,还包括余华的其他作品相关信息以及分析出的实体。当用户点击详细信息时便可得到相应书的出版社、作者、简介等信息。 图7 查询结果 本文以Web数据为主要数据源,使用知识图谱相关技术,构建一个完善的领域知识图谱,实现查询、检索该领域内的相关知识的功能,可以快速、精准地帮助用户定位到他们感兴趣的Web知识。不足之处在于知识抽取的规则较为单一,只能针对于某一类特定的网站,今后可以通过规则与自动实体识别相结合的方法完成知识抽取。4 实验分析
4.1 实验环境及数据

4.2 实验结果及可视化展示


5 结语
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
校园英语·月末(2021年13期)2021-03-15
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
新城乡(2018年6期)2018-07-09
湖北函授大学学报(2016年13期)2017-01-03
领导科学论坛(2016年9期)2016-06-05
科技视界(2016年12期)2016-05-25
图书馆界(2013年5期)2013-03-11
中国报道(2009年12期)2009-01-15
