
深度学习发展形势下计算机视觉教学内容革新
2020-06-17 08:11:04丁双惠
计算机与现代化 2020年6期
陈 川,陈 柘,丁双惠
(1.海军航空大学青岛分校,山东 青岛 266041; 2.长安大学信息工程学院,陕西 西安 710064)
0 引 言
本世纪初,深度学习理论取得了巨大突破,其理论和应用研究获得了广泛关注,不断有新的研究成果涌现出来,极大地推动了人工智能,特别是计算机视觉、自然语言理解等领域的研究进展,并在这些领域任务中取得了一系列标志性成果,使得机器在这些任务中的感知水平已经接近甚至超过了人类可以达到的水平。
目前,计算机视觉教学中广泛使用的课程教材多数是七、八年前编写的,反映的是当时的研究发展水平,尚未及时吸收近几年,特别是自2010年后开始兴起的深度学习等领域学术研究的最新成果。目前较有影响的计算机视觉教材包括:1)由D. A. Forsyth等人编写的《Computer Vision: A Modern Approach》(2012年,第2版);2)由Richard Szeliski编写的《Computer Vision: Algorithms and Applications》(2010年出版);3)由S. J. D. Prince等人编写的《Computer Vision: Models, Learning and Inference》(2011年出版)。相关领域中最新的研究成果没有被及时涵盖进来。2010年以来,机器学习,特别是深度学习的研究取得了长足发展,深层网络带来的强大的非线性映射能力使其在物体检测、物体识别、图像分割、3D重建等传统机器视觉任务中大幅超过一般机器学习算法或浅层神经网络的性能,并且仍在不断刷新记录,在计算机视觉研究领域受到了广泛关注。而现有的计算机视觉教学内容基本遵循Marr提出的理论框架,延续了人工特征+分类器的算法设计思想,与基于数据驱动的分析方法存在较大的区别,在一定程度上造成所学与所用脱节,不利于学生开展深入的科研活动,因此十分有必要对现有教学内容进行革新。
本文着力探讨深度学习理论及应用发展对计算机视觉教学所带来的影响,分析现有教学内容的不足之处,提出新形势下丰富和完善计算机视觉教学内容的构想。
1 深度学习理论在计算机视觉任务中的应用现状
计算机视觉的研究目标是使机器具备类似人类的视觉感知和认知能力,类似物体检测、物体识别、3D重建、运动估计与目标跟踪、图像分割、图像分类等典型视觉任务,是计算机视觉需要具备的核心任务能力。近年来,深度学习理论有了很大发展,被广泛应用于计算机视觉的典型任务当中,有力地促进了计算机视觉的研究发展。本章对深度学习理论在不同视觉任务中的应用现状做一简要介绍。
1.1 图像分类
物体识别、图像分类是计算机视觉的基本任务之一,也是对事物认知的基础能力。人类所生存的世界,物体种类繁多,类别不下几十万种,这些物体外观形态各异,大类间差别明显,易于辨识,但小类间可能只有细微的差别,不易分辨。
传统的物体识别方法需要在限定类别数量的前提下进行,依靠提取具备辨识能力的显著特征,在特征空间上使用机器学习的方法找到类与类之间的分隔面,从而将不同的物体分辨出来。这种方法受限于物体种类数量,特征的好坏往往决定了物体识别和图像分类的性能。如何找到区分力强的人工特征成为困扰物体识别的重要瓶颈。依靠SIFT、LBP、HOG等特征,在深度学习出现前,在测试集ImageNet[1]上物体识别的错误率可以限制在30%以内。2012年Krizhevsky等人[2]提出了AlexNet,在ILSVRC挑战赛上取得了15.3%的Top-5错误率,获得第一名,性能比传统方法(第二名)高出40%多。第一次在图像分类任务上显示了深度学习的强大威力。随后,VGGNet[3]、GoogLeNet[4]、ResNet[5]被相继提出,并被用于图像分类,分类的错误率逐步下降,从VGGNet的7.32%下降到ResNet的3.57%,已经接近了人类的图像分类能力。
1.2 物体检测
物体检测的目标是对视频图像中感兴趣的物体进行定位。由于受复杂背景、光照变化、遮挡、旋转、尺度变化及物体形变等多重因素影响,物体检测一直是计算机视觉任务中的难点问题。
传统的物体检测方法依靠人工特征及使用滑动窗口搜索目标,其性能同样受制于人工特征的表达能力,并且计算复杂度高。深度学习的出现为物体检测提供了新的途径,自2014年提出的RCNN[6]后,不断有新的模型被提出,如SPPNet[7]、Fast RCNN[8]、Faster RCNN[9]、SSD[10]、YOLO及其演化模型[11]、FPN[12],以及RefineDet[13]等。这些模型的性能在主要的公开数据集上获得了验证,如PASCAL VOC 2007[14]、VOC2012[15]和MSCOCO[16]等。表1列出了自2012年以来提出的几种具有代表性的深度网络模型,给出了其在3种公开数据集上完成目标检测任务时的性能表现。从表1可以看到,从2014年提出RCNN之后,随着深度网络结构的改进,其目标检测精度逐年提升,已由2014年的58.50%提升到了现今的83.80%,性能提升了约42%。表1中使用的评价指标mAP(mean Average Precision)表示平均精度均值。
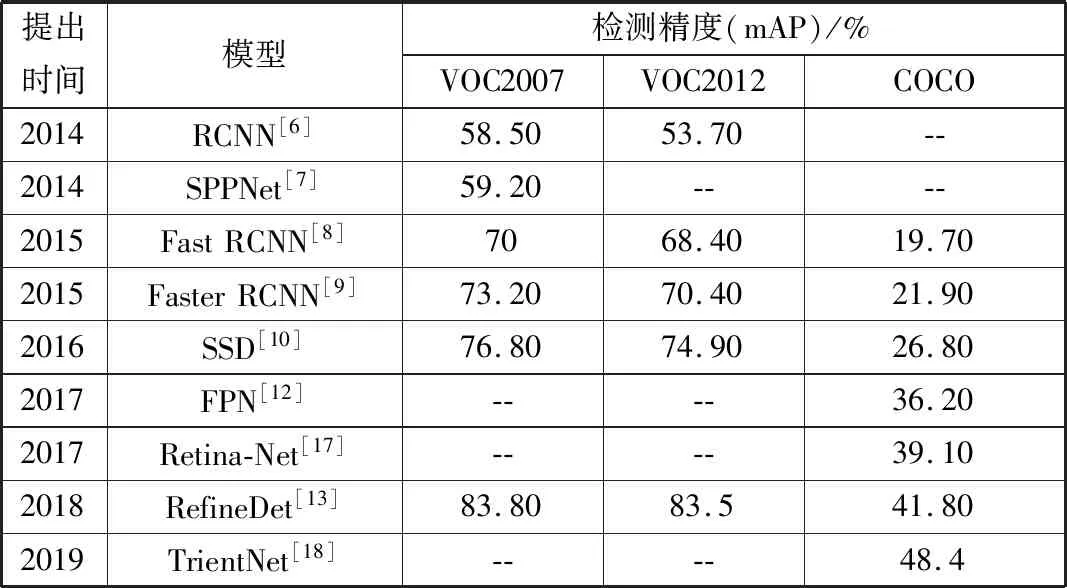
表1 深度学习在目标检测任务中的性能表现
1.3 图像分割
图像分割属于视觉信息处理的底层问题,目的是在图像中区分出不同物体所在的区域。依据分割所要求的精细程度,可以将图像分割归为3类:语义分割、实例分割和全景分割。语义分割要求对图像中的每个像素区分其所属的类别,实现像素级别的分类;实例分割不但要求进行像素级别的分类,还需区分不同类的实例,即类的具体对象;全景分割将语义分割和实例分割结合起来,实现对图像中所有物体,包括背景进行分割,而不仅仅只对感兴趣物体类的实例进行分割。
目前,深度学习理论在图像分割中的应用研究主要集中于图像的语义分割。主要利用CNN、FCN、RNN等基础网络结构提取区域或像素的特征及语义信息,并依靠分类器进行分类。具体地,可以将现有的方法分为基于区域分类的图像语义分割方法及基于像素分类的图像语义分割方法[19]。表2和表3分别列举了2种类型的方法中部分典型网络结构在图像语义分割中的性能表现。表中使用的评价指标mIoU(mean Intersection over Union)是指平均交并比,AR(Average Recall)表示平均召回率。
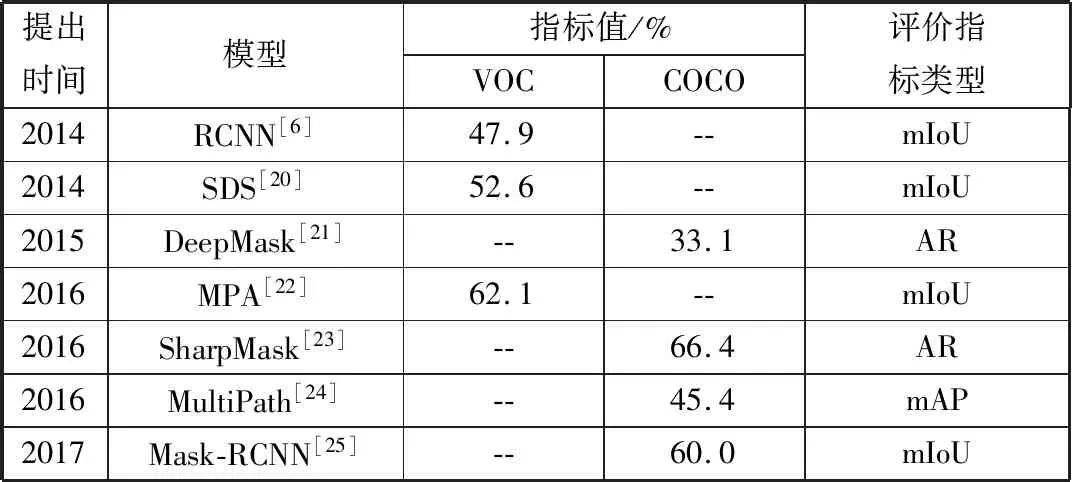
表2 基于区域分类的图像语义分割方法性能
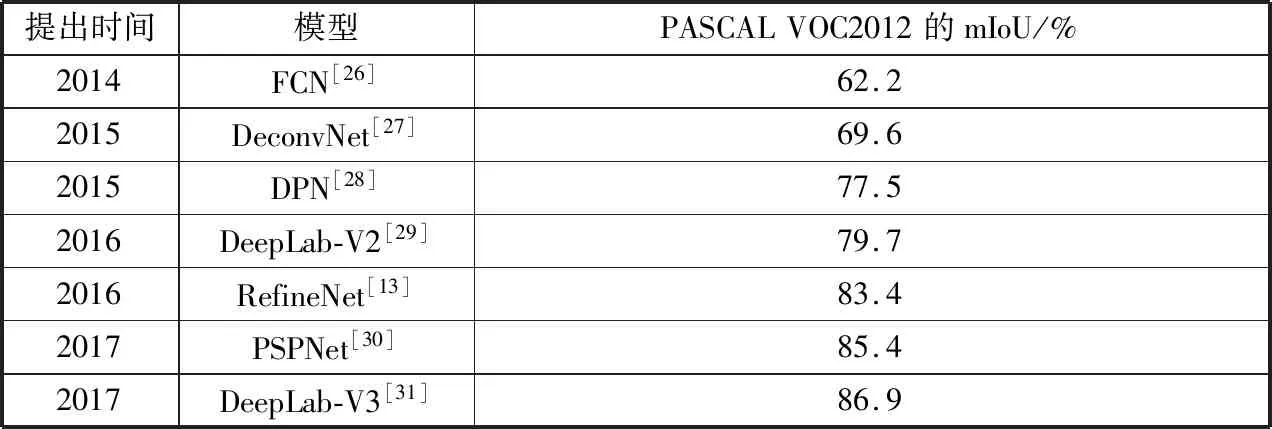
表3 基于像素分类的图像语义分割方法性能
从表2和表3可以看到,基于像素分类的图像语义分割方法性能要优于基于区域分类的图像语义分割方法。
1.4 目标跟踪
目标跟踪指单目标跟踪,是在已知目标在首帧视频中的初始状态(如位置、尺寸)的前提下,自动估计目标在后续帧中的状态。场景中存在的目标外观变形、光照变化、快速运动、背景干扰等因素使得目标跟踪问题不能够用简单的方法加以解决。传统的目标跟踪方法,如卡尔曼滤波、粒子滤波、Mean-shift等生成式方法,以及人工特征+分类器的判别类方法,如HOG+SVM等,在应对这些挑战时,跟踪性能会受到较大影响。
与深度学习在图像分类、物体检测中应用的环境不同,目标跟踪任务中仅仅提供了首帧中的目标边界作为训练数据,在很大程度上限制了深度学习的应用。因此,使用深度学习技术进行目标跟踪的研究目前仍处于探索阶段,但已经出现了许多有益的尝试,如DLT[32]、SO-DLT[33]、FCNT[34]、MDNet[35]等。其中,DLT作为首个将深度网络运用于目标跟踪的算法,在CVPR2013 OTB50数据集上的29个跟踪器中排名第5;SO-DLT提出时,在OTB50数据集上的OPE准确度绘图(Precision Plot)达到了0.819,OPE成功率绘图(Success Plot)达到了0.602;FCNT在OTB50数据集上的OPE准确度绘图达到了0.856,OPE成功率绘图达到了0.599,准确度绘图有较大提高;MDNet在TPAMI2015 OTB100数据集上的OPE准确度绘图从一开始的0.825提升到0.908,OPE成功率绘图从一开始的0.589提升到0.673。这些显示了深度学习理论在目标跟踪方面具有的潜力。
1.5 3D重建
3D重建是计算机视觉研究的核心问题之一,其在机器人导航、环境理解、三维建模等领域有着重要应用。传统的3D重建方法多基于多视图几何原理以及基于多线索恢复3D结构,如各种SFX。基于几何的重建方法通常需要进行相机标定和使用多视角拍摄的图像,并基于特征匹配和三角关系在3D坐标系中进行重建。同样,基于阴影、运动等线索的三维重建也需要相机标定,限制了其在多种环境下的应用。
深度学习技术在3D重建中的应用源于Eigen等人[36]在2014年所做的工作,首次提出了利用卷积神经网络对单目图像进行深度估计。此后,研究人员在Eigen等人工作的基础上,设计出了不同的神经网络结构,如3D-R2N2[37]、Octree[38]、Voxnet[39]、3DShapeNet[40]以及Matryoshka Networks[41]等。统计结果表明,从2014年Eigen等人首次使用深度学习对单目图像恢复场景深度开始,在不到5年的时间里,获得的深度精度与最初相比提高了一倍左右。借助于深度学习方法,对于本质上病态的(ill-posed)单目图像的深度估计问题,可以得到精度较高的深度估计结果,说明了深度学习方法在这一问题上的适用性[42]。
2 深度学习理论对计算机视觉教学内容的影响
以上简要介绍了深度学习理论在几种典型计算机视觉任务中的应用现状,可以看出深度学习技术推动了传统计算机视觉任务的突破,对计算机视觉的研究发展产生了重要影响,同时也对现有计算机视觉课程的教学内容带来了一定的冲击。
现有的计算机视觉课程强调视觉信息处理的层次化,将视觉问题分解为低层、中层和高层这3个层次来解决。低层处理负责图像的增强、复原等工作,使图像更适于上层分析。中层处理的任务是从图像中提取各种特征,形成图像的表达和描述。高层处理完成物体识别与场景理解等任务。而深度学习具有端到端的特点,具备自动提取特征的能力,在有监督条件下可以完成图像分类、物体识别等任务,从某种程度上弱化了视觉信息层次化处理的过程。这种弱化使得传统教学中有关特征提取及分类器设计的内容被淡化,应用中更加注重数据标注及增强、深度神经网络的结构设计和模型训练。
除了跨层信息处理的特点外,深度学习理论在单个层次中的应用也十分广泛。例如,在底层信息处理中,深度学习理论在图像去噪、去雾、去雨雪,以及图像复原等方面都有应用出现。在中层信息处理中,如前文所述,深度学习被用于图像语义分割及图像表达中。高层中的应用最为活跃,体现在物体检测、识别和3D重建等多个方面。
这种单层及跨层应用表现出了深度学习在视觉信息处理技术中的广泛渗透,是对计算机视觉研究的有力促进。同时,也对计算机视觉现有的教学内容提出了革新要求。
3 应对深度学习发展的计算机视觉教学内容革新
为应对深度学习理论及应用发展,反映其在计算机视觉研究中的促进作用,可在以下方面对现有的教学内容体系进行革新。
3.1 引入深度学习基础理论
为充分理解深度学习在计算机视觉中的应用机理,将计算机视觉应用中广泛涉及的深度学习基础理论融入计算机视觉教学内容中。
深度学习基础理论涉及的知识点如表4所示,主要涵盖深度网络基础模型、网络训练与优化等基础理论,另外需要介绍常用的深度网络模型构建框架。
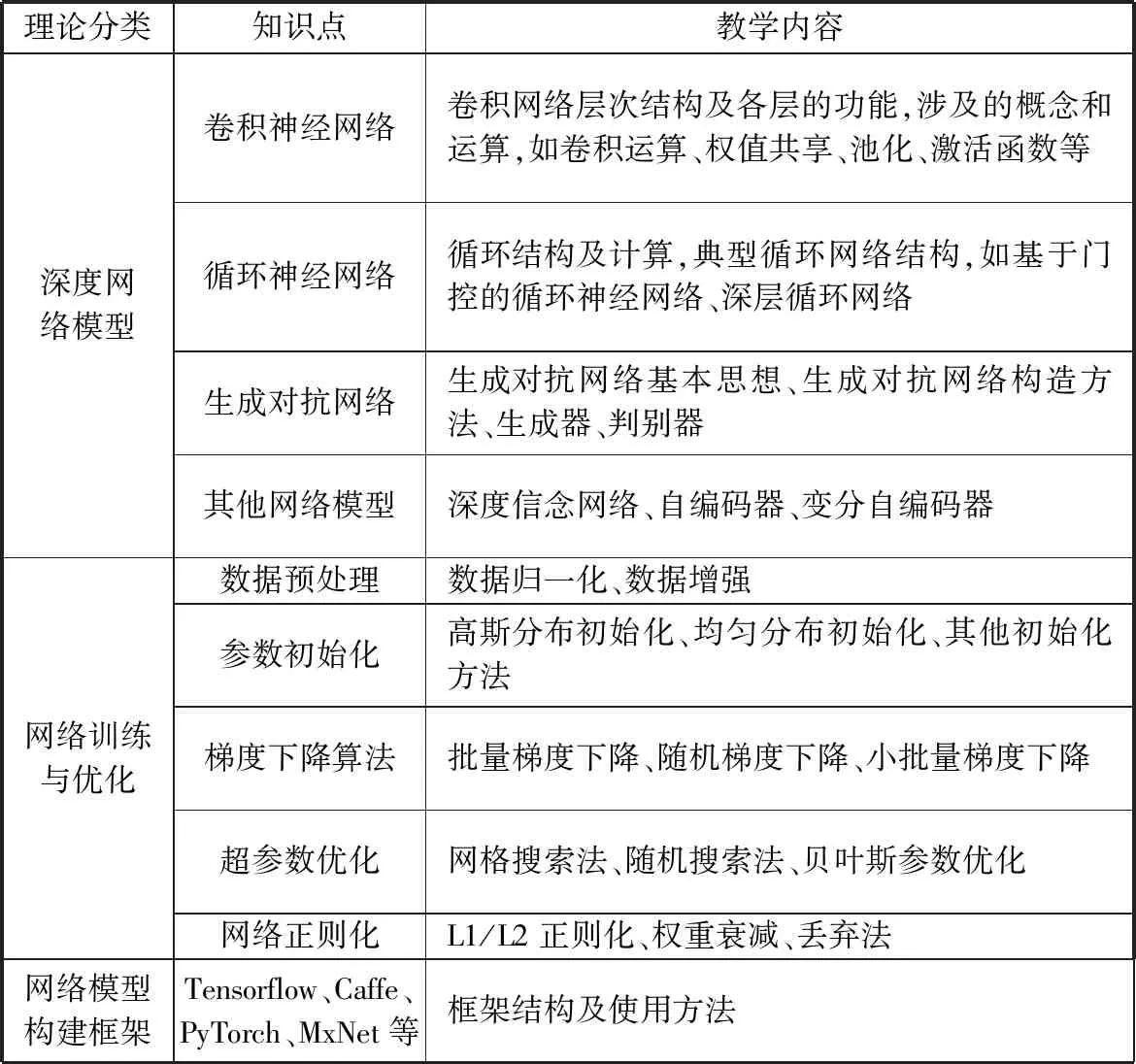
表4 深度学习基础理论
在教学内容中注重对有重要应用价值的基础网络模型的介绍,如卷积网络、循环网络、生成对抗网络,强调网络原理学习,包括涉及的基本概念和运算。同时,需要较深入地学习网络的训练与优化方法,因为深度网络的训练相较浅层网络对训练数据、网络参数设置、学习方法有较高的要求,设置不当往往会引起网络模型过拟合或训练失败。
3.2 深度学习与计算机视觉任务的融合
深度学习理论向计算机视觉教学内容的融合需要从现有教学内容改造和深度学习理论融入2个方面展开。
一方面,现有教学理论中部分以人工特征+分类器为中心的教学内容可适当压缩,以Szeliski编写的《Computer Vision: Algorithms and Applications》教学内容为例,涉及的内容如表5所示。

表5 部分可压缩的教学内容
在压缩以上知识点的过程中,可以保留对这些知识点的理论思想的介绍,算法的实现过程可压缩。
另一方面,以深度网络模型理论为基础,在教学中将深度学习作为解决传统计算机视觉任务的一种解决方案,重点学习针对各层次视觉任务如何构建训练数据集、选择恰当的网络模型和训练方法,以及如何对网络模型进行适应性改造以更好地提升求解结果的准确性。
为了能够充分展开深度学习与计算机视觉的融合教学,除了教学内容革新,同时要求在教学过程中充分利用网络化教学手段,开展线上和线下的混合式教学,弥补教学内容多、教学课时少的矛盾,同时通过实验设计,增强学生对深度学习应用的感性认识和实践能力。这里给出一个计算机、人工智能专业本科高年级或研究生课程教学内容、课时及教学形式的示例说明,如表6所示。
表6的课程安排适合总学时为46学时的教学,其中实验占10学时。在课程教学中安排了课程讨论、实践与练习和专题项目,其中专题项目需要在课外完成,实践与练习可利用实验课时完成。对于基于深度学习的专题项目需安排实验环节,用以解决专题项目实施过程中出现的共性问题。
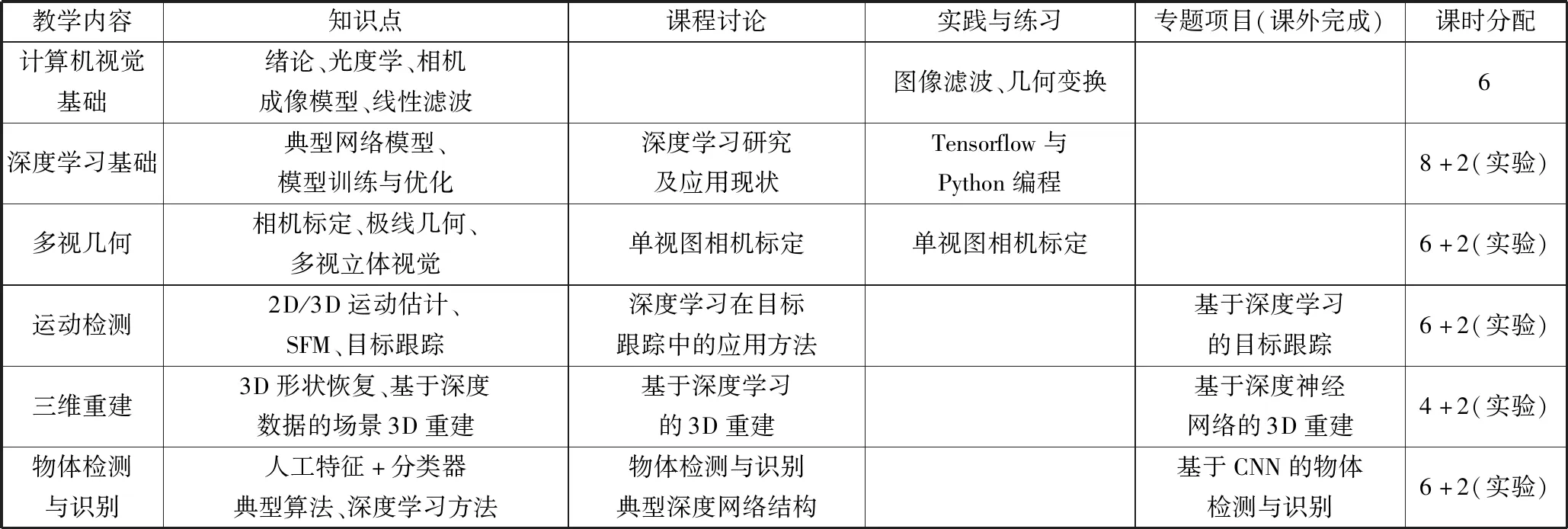
表6 深度学习与计算机视觉融合教学课程安排
3.3 实验设计
教学中,为加强对深度网络模型的理解,以及掌握模型的应用方法,可设计若干实验,如表7所示,将深度网络模型应用其中。
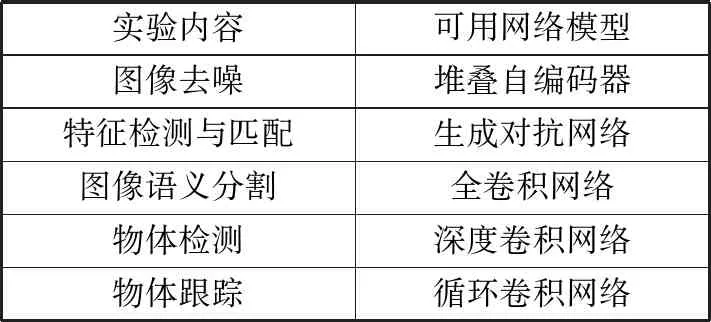
表7 基于深度网络的参考实验
实验中,需在数据预处理、深度网络模型设计、参数设置与优化等方面进行探究,充分理解深度网络的构建、训练和优化方法,同时重视与传统方法的对比分析。
以图像语义分割实验为例,图像语义分割的目标是实现逐像素分类,即将图像中的每个像素归为背景或前景中的不同物体。实验目的在于探究基于深度网络的图像语义分割模型原理、构建及训练方法。实验选用全卷积网络构建语义分割模型,示例模型如图1所示。
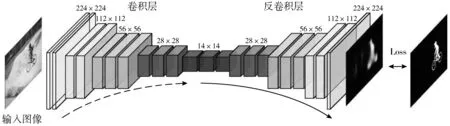
图1 全卷积网络语义分割模型示例[26]
实验中,选用Tensorflow框架和Python编程语言,可以选择PASCAL VOC2012、MSCOCO、ILSVRC等公开数据集作为样本数据集,实验过程可分为以下步骤:
1)数据预处理。
数据预处理主要完成数据集的划分、数值归一化、图像尺寸调整及数据增强等任务。数据集划分指将数据集划分为训练集、验证集和测试集;数值归一化的目的是使利用的特征数值归一化到同一数值区间,使其在数值上具有可比性;图像尺寸调整主要是为了适应硬件处理设备的处理性能,如受GPU卡显存的约束;数据增强的目的在于增强样本数据的多样性,在模型训练中避免出现过拟合问题,常用的方法如随机翻转、比例缩放、平移、旋转、模糊、加噪等方式。
2)模型构建。
模型构建过程在于确定模型的结构,在实验中涉及众多超参数的调整,例如卷积层的层数、各个卷积层神经元数量、卷积核的大小等。通常可以基于现有网络结构,在其基础上进行构建。例如,全卷积网络的前半部分可以分别尝试应用多种经典网络结构,如Alexnet、VGG16和GoogLeNet,模型的后半部分采用反卷积方法完成上采样以恢复图像尺寸。
3)损失函数设计。
损失函数用于评价模型的预测值和真实值的相符程度,损失函数设计的好坏直接影响模型的性能。在图像语义分割任务中,可以将分割问题转化为像素的分类问题来解决,损失函数主要体现对像素分类的准确性。实验中,可以设计不同的损失函数,观察不同的损失函数对模型性能的影响,例如,可以考虑0-1损失、对数损失、平方损失、交叉熵损失或绝对值损失。
4)模型训练。
深度网络模型的训练是实验中较难掌握的部分,方法不当经常会碰到梯度消失/爆炸、模型不收敛或收敛慢等问题,涉及参数初始化、学习率、Batch Size等参数选择,以及采用合适的优化方法,如SGD或Adam算法等。实验中,可设定不同的参数+算法组合,以观察其对网络训练的影响。
5)对比实验。
除探究以上参数对模型性能的影响外,实验中可选择恰当的评价指标,如mAP或mIoU,与传统的机器学习算法进行对比,如K均值、SVM、MLP等方法。
以上实验过程基本可以体现深度神经网络在图像语义分割中应用的原理、模型构建、训练及优化方法,有助于学生较快掌握深度学习的原理和应用方法。
4 结束语
本文从深度学习理论在计算机视觉任务中的研究现状入手,揭示了深度学习理论和应用发展对计算机视觉教学带来的影响,指出了深度学习理论发展形势下,计算机视觉教学内容的适应性改革的必要性,从3个方面给出了计算机视觉教学内容适应性改革的方法措施,给出的实验设计、教学内容及教学方法示例,体现了在计算机视觉教学中融合深度学习理论的理念。
猜你喜欢
中学生数理化·七年级数学人教版(2020年11期)2020-12-14 06:59:52
开放教育研究(2020年2期)2020-03-31 01:54:14
中学生数理化·高一版(2020年1期)2020-02-20 13:24:32
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14 01:14:28
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08 02:44:26
中学生数理化·八年级物理人教版(2018年10期)2018-12-06 09:33:16
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26 06:03:48
现代语文(2016年21期)2016-05-25 13:13:44
科普童话·百科探秘(2015年4期)2015-05-14 07:06:42
大连民族大学学报(2015年2期)2015-02-27 08:28:11
