
基于深度Q网络的垃圾邮件文本分类方法
2020-06-17 08:10:22景栋盛薛劲松冯仁君
计算机与现代化 2020年6期
景栋盛,薛劲松,冯仁君
(国网江苏省电力有限公司苏州供电分公司,江苏 苏州 215004)
0 引 言
电子邮件是一种便捷的交流工具,在人们的日常生活中起着重要的作用,具有使用成本低廉、信息传播迅速等优点。但电子邮件的这些特点却被垃圾邮件的制造者所利用来传播垃圾邮件。广义上讲,垃圾邮件是指含有虚假或不良信息、恶意链接以及营销广告等内容的电子邮件。垃圾邮件中可能包含木马、病毒,因此垃圾邮件会浪费社会资源,泄露隐私信息,造成无法挽回的损失[1],对互联网的发展带来不利影响[2]。
研究人员提出了各种识别和过滤垃圾邮件的方法,主要包括:基于黑白名单的过滤、基于规则的过滤以及基于邮件内容的过滤方法[3]。基于黑白名单的过滤方法虽然简单、快速,内存消耗低,并在邮件发送成功之前就可识别出邮件是否为垃圾邮件,但是这种过滤方法不能识别所有的邮件,并且需要耗费大量的人力建立黑白名单,也可能会错误地将正常邮件拦截[4]。基于规则的邮件过滤方法需要人工挖掘邮件的特征,而垃圾邮件的特征词库会随着邮件数量的增多而不断改变,这需要花费大量的人力建立特征词库[5],然而仍然会在很多情况下识别不出垃圾邮件。基于邮件内容的过滤方法是对已经标记好的邮件文本使用机器学习方法进行训练[6]。常用的机器学习算法主要有支持向量机[7]、朴素贝叶斯[8]和逻辑回归[9]等算法,机器学习算法可以根据历史数据进行主动学习和预测,这使得垃圾邮件的识别成为主动的预防识别[10]。
基于邮件内容的垃圾邮件过滤方法不再局限于邮件的协议和网络,而是根据邮件的内容来过滤垃圾邮件。王青松等人[11]更改以词为文本的特征项单位的方式,采用短语作为正文文本的特征项单位在朴素贝叶斯模型上进行分类,提出了基于短语的贝叶斯中文垃圾邮件过滤方法,该方法提高了垃圾邮件的分类精度;于洪霞[12]提出了基于支持向量机的中文垃圾邮件过滤方法,该方法采用分词方法对特征提取方法进行改进,然后在支持向量机分类器中对邮件进行分类,该方法提高了邮件分类的精度和速度;李培国[13]在人工神经网络的基础上设计了中文垃圾邮件过滤器,该方法采用ICTCLAS系统进行中文分词,在BP分类器中对邮件进行分类,该方法提高了垃圾邮件分类的精度和稳定性;Wang等人[14]采用卷积神经网络和支持向量机来提取垃圾邮件中图像的特征,在邮件分类中取得了良好的效果;李艳涛等人[15]提出了一种采用动态函数使Dropout随着迭代次数而逐渐减小的方法,并在堆叠式降噪自编码中应用该方法,以及在英文邮件上进行实验,实验结果表明该方法有效地提高了邮件的分类精度,分类效果具有更好的稳定性。
虽然垃圾邮件过滤方法取得了一定的成绩,但是在准确率的提高上依然有很大的上升空间,同时也存在着很多问题。例如,现有的垃圾邮件过滤方法人工标注成本高,并且效率低下,垃圾邮件的内容、形式更新快,传统的人工方法无法与之匹配。近几年,深度Q网络被提出并在实验和应用中取得了更好的效果,深度Q网络应用在垃圾邮件的过滤上通过“试错式”学习对邮件进行分类。由于特征提取影响识别效果,甚至会降低垃圾邮件的过滤准确率,为避免这一问题,本文充分利用Word2vec中的CBOW模型得到邮件文本分词集对应的词向量集,再训练深度Q网络对邮件分类,可以有效地忽略特征提取这一步骤,解决了邮件文本特征提取困难的问题,进而降低成本。并且强化学习是终生学习,可以边学习边改进,能有效地应对垃圾邮件的更新问题。为解决垃圾邮件过滤过程中遇到的问题,本文提出基于深度Q网络的垃圾邮件文本分类方法。该方法需要首先对原始邮件文本数据预处理和分词,并采用Word2vec方法对文本进行向量化处理,实现在深度Q网络上的垃圾邮件文本的分类。通过比较正确率、精确率、召回率和F1值可知,本文所提出的基于深度Q网络的垃圾邮件文本分类方法能提高垃圾邮件过滤的高效性和精确性。
1 相关工作
1.1 文本预处理和分词
文本预处理是指将原始数据处理成实际应用所需要的文本格式[16]。因为数据集的来源不同,导致数据源中可能含有大量非法或无意义的字符,这些字符可能是标点或乱码等非文本分类需要的字符,需要将其去除。并且在邮件文本分类中,需要把文本编码方式统一转换成可以识别的编码方式。
分词是指按照一定的规则将句子切分成一组词的过程[17]。在英文文本中,空格是词与词之间的分割符号,然而,在中文文本分词中,句子包含的词与词之间没有明确的分割符号,因此,比较而言中文分词具有一定的困难性[18]。中文分词中最常见的几类分词算法有基于字符串匹配的分词方法[19]、基于理解的分词方法[20]、基于统计的分词方法[21]和基于词与词性相结合的分词方法[22],基于词与词性相结合的分词方法考虑了词还具有词性的问题[23]。基于统计的分词方法是目前最常用的中文分词方法,该方法在分词的过程中将词的词性进行人为标注并统计了中文词出现的次数这一统计特征,通过模型学习标注的文本数据,得出各种情况下每个词出现的概率,选择最可能出现的分词结果。该方法考虑到了词出现的频率和文本词的上下文的含义,在中文分词中展示了很好的效果[24]。
1.2 Word2vec模型
因为计算机只能识别数学符号,所以邮件中的邮件文本必须转化为数学的形式才能够被识别。因此,需要将文本中的词转化为数学中向量的形式。文本向量化表示是指将文本中的词转化成实数向量,并用于后续模型的计算。将邮件文本中的词转化为数学向量形式的主要方法有独热表示(One-hot Representation)和词向量表示(分布式表示(Distributed Representation))[25]。
Word2vec模型是一个n元语法模型,目的是使计算机理解自然语言,方法是通过对自然语言进行假设和建模[26]。Word2vec模型在语义维度上推动了文本分析的进程,该模型主要包括连续词袋模型(Continuous Bag-of-Words, CBOW)和Skip-gram模型[27]。
连续词袋模型是根据输入的相关n-1个词预测中心词本身,在训练的过程中,首先给出中心词的一个邻域半径内的所有单词,然后预测输出单词是给出的中心词的概率[28]。Skip-gram模型将CBOW的因果关系进行颠倒,根据给定的当前中心词预测上下文的内容[27]。Word2vec模型的网络结构包含输入层、投影层和输出层3个层次。Word2vec的2种模型又各有2种策略,故一共有CBOW加层次的网络模型、Skip-gram加层次的网络模型、CBOW加抽样的网络模型和Skip-gram加抽样的网络模型[26]。使用Word2vec模型得到的词向量会考虑上下文,通用性强。
1.3 强化学习
强化学习(Reinforcement Learning, RL)是指智能体处于一个未知的环境中,通过与环境不断交互的试错式学习来获得最大回报,并学得最优策略的过程,强化学习是一种机器学习方法[29]。强化学习是基于马尔可夫决策过程的。在强化学习中,智能体周期性地根据观察到的随机动态系统做出序贯决策,这个过程连续执行,一直到智能体得到最大回报值后结束。Q-learning[30]是一种异策略(off-policy)强化学习算法,在状态s下根据Q值择优选择并执行动作a,从环境中获得奖赏r,进入下一个状态s′。Q值的更新方式为:
Q(s,a)←Q(s,a)+αδ
(1)
其中,s表示智能体所处的状态,a表示智能体在状态s下所采取的动作,α是学习率,δ是时间差分误差(Temporal Difference Error, TD-error)[31],计算方法为:
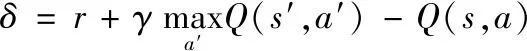
(2)
其中,r表示奖赏,γ是折扣因子。Q-learning算法学习得到的动作值函数Q直接逼近最优动作值函数,并不依赖于智能体选择的策略,简化了算法的分析。
1.4 深度Q网络
深度强化学习(Deep Reinforcement Learning, DRL)是将深度学习和强化学习相结合,融合了二者的感知能力和决策能力来解决系统中的感知决策问题[32]。深度Q网络(Deep Q-network, DQN)作为第一种深度强化学习算法,高效地缓解了用非线性函数逼近器表示值函数时算法的不稳定性问题[33]。
深度学习(Deep Learning, DL)是基于人工神经网络(Artificial Neural Network, ANN)的,基本算法是反向传播(Back Propagation, BP)算法,深度学习模型的经典范例是多层感知器(Multi-layer Perceptron, MLP),其由多层隐藏层构成,与浅层网络相比较,多层感知器具有更强的特征表达能力[34]。
Mnih等人[35]在Q-learning算法和深度卷积神经网络的基础上提出了深度Q网络算法,该算法使用了经验回放机制和目标网络方法,DQN的结构示意图如图1所示。
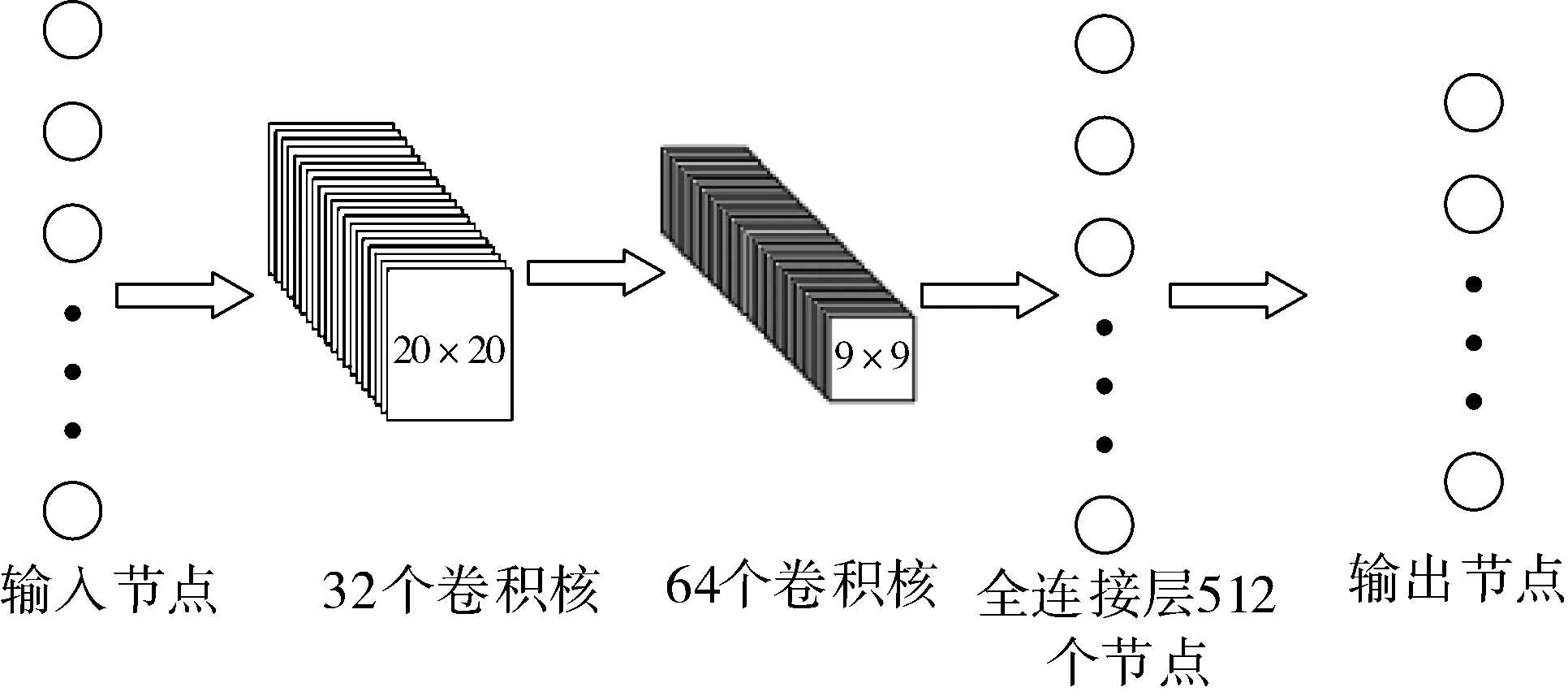
图1 深度Q网络结构示意图
深度Q网络使用当前值网络和目标值网络这2个独立的Q网络,用θ表示当前值网络的参数,该参数是实时更新的,θ-表示目标值网络的参数,该参数在每过L步后由θ复制得到[36]。当前值网络的输出表示为Q(s,a;θ),目标值网络的输出表示为Q(s,a;θ-),损失函数由目标值函数和当前值函数的均方误差决定:
L(θ)=E[(Y-Q(s,a;θ))2]
(3)
Y=r+γmaxa′Q(s′,a′;θ-)
(4)
其中,s代表当前智能体所处的状态,a代表智能体在状态s下执行的动作,s′表示智能体所处的下一个状态,a′表示智能体处于下一状态时执行的动作。式(4)作为监督学习的标签,近似地表示了值函数的优化目标。为了求解得到最小化损失函数,对式(3)中参数θ求导得到:
(5)
在上述公式中,参数θ的更新采用随机梯度下降法(Stochastic Gradient Descent, SGD)方式进行。
深度Q网络通过贪心策略更新动作值函数,用ε-贪心策略(ε-greedy)方法选择动作。
2 数据处理与算法描述
2.1 数据描述与处理
本文使用的数据来自于ECML/PKDD 2006 Discovery Challenge[37]中任务A的数据,数据分为带标签的培训数据和测试数据。其中,带标签的培训数据一共有4000条,包括50%的垃圾邮件和50%的非垃圾邮件。测试数据来自不同的多个邮箱,每个邮箱有2500条数据。提供的数据不是电子邮件的原始文本,而是用向量空间表示的向量并采用SVMlight使用的稀疏数据格式存储数据。属性是单词的词频,并且删除了数据集中计数少于4的单词,最终数据集中大约有150000个单词。数据集中每一行代表一封电子邮件,每一行的第1个标记是类标签,+1表示垃圾邮件,-1表示非垃圾邮件,0表示没有标签的测试数据。标签之后的每一对标记表示单词的ID和其词频,词频按升序排列。
如训练数据集中的某一条数据为:1 9:3 94:1 109:1 163:1,这表示是一条垃圾邮件数据,有4个单词,第1个单词的ID是9,该单词在这封邮件中出现了3次。
2.2 算法描述
在深度Q网络被训练之前,通过对数据进行预处理,过滤掉文本中的非法字符和无意义字符等,并通过对邮件文本分词来获得数据长度统一的邮件文本,每一封邮件对应一个有顺序的分词集,最后用Word2vec中的CBOW模型得到邮件文本分词集对应的词向量集。处理后的每一封邮件的文本内容对应一个词向量集,词向量是数值向量的形式,不需要对邮件进行特征提取,词向量集作为深度Q网络的输入状态。为提高垃圾邮件过滤的效率和精确度,本文提出基于深度Q网络的垃圾邮件文本分类方法。用于垃圾邮件检测的深度Q网络学习算法中,状态s是词向量集,s={词向量集|用Word2vec中的CBOW模型得到邮件文本对应的词向量集}。在当前状态下,智能体执行分类动作a,a={是垃圾邮件,不是垃圾邮件},判断词向量集是否属于垃圾邮件,若判断正确,则得到奖励值,该奖励值设置为一个正数,若判断错误,则得到惩罚值,惩罚值设置为一个负数。智能体依次从状态空间S中选择状态词向量集,一直到训练结束。网络训练好后可以用于垃圾邮件的文本分类。在应用的过程中,首先对获得的邮件文本预处理,过滤掉文本中的非法字符和无意义字符等,并通过对邮件文本分词来获得数据长度统一的邮件文本,最后用Word2vec中的CBOW模型得到邮件文本对应的词向量集。词向量集作为训练好的深度Q网络的输入状态,输出结果为该邮件是否为垃圾邮件。基于深度Q网络的垃圾邮件文本分类方法示意图如图2所示。
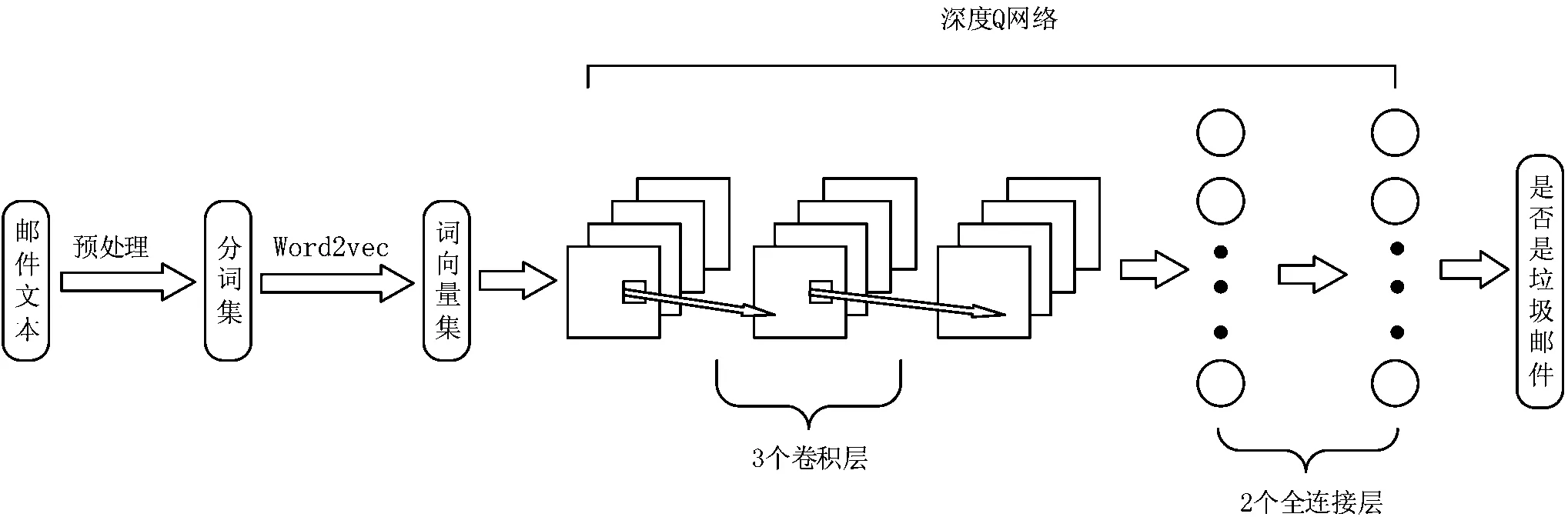
图2 基于深度Q网络的垃圾邮件文本分类示意图
用于垃圾邮件检测的深度Q网络学习算法(Deep Q-network for Spam Detection, DQNSD)描述如算法1。
算法1用于垃圾邮件检测的深度Q网络学习算法。
输入:迭代轮数T,状态特征维度n,动作集A,步长α,衰减因子γ,探索率ε,Q网络结构,批量梯度下降的样本数m。
输出:Q网络参数。
1.对邮件文本进行预处理,用分词软件对邮件文本进行分词,每封邮件对应一个词按顺序排列的分词集
2.用Word2vec中的CBOW模型得到分词集对应的词向量集s
3.随机初始化Q网络的所有参数ω
4.基于ω初始化所有的状态和动作对应的Q值
5. 清空经验回放集合D
6. forifrom 1 toT
7. 初始化s为当前状态序列的第1个状态
8. 在Q网络中使用s作为输入,得到Q网络的所有动作对应的Q值
9. 用ε-贪婪法在当前Q值输出中选择对应的动作a
10. 在状态s执行当前动作a,得到新状态s′及其对应的奖励r和是否是终止状态is_end
11. 将五元组{s,a,r,s′, is_end}存入经验回放集合D
12.s=s′
13. 从经验回放集合D中采样m个样本{sj,aj,rj,sj′, is_endj},j=1,2,…,m,计算当前目标Q值yj
14. 使用均方差损失函数,通过神经网络的梯度反向传播来更新Q网络的所有参数ω
15. 如果s′是终止状态,当前轮迭代完毕,否则转到步骤6
Return Q网络参数
3 实验及分析
基于深度Q网络的垃圾邮件文本分类方法首先对邮件文本进行预处理、分词,然后用Word2vec模型得到邮件文本的词向量集表示,最后用深度Q网络对垃圾邮件进行过滤,提高了垃圾邮件过滤的效率和精确率。实验的对比方法有朴素贝叶斯、决策树、支持向量机、TextCNN和TextRNN。
3.1 评价标准
本文实验的评价标准有正确率、精确率、召回率和F1值。当分类类别是二分类时,TP的含义是真正类(True Positives),表示在所有正样本中,分类器可以正确识别为正样本的样本个数;FP的含义是假正类(False Positives),表示在所有的负样本中,被分类器误分类为正样本的样本个数;FN代表的是假负类(False Negatives),表示在所有的正样本中,分类器把正样本错误地识别为负样本的样本个数;TN表示的是真负类(True Negatives),表示在所有的负样本中,分类器把负样本正确地识别为负样本的样本个数[38]。
正确率[38](accuracy)也称作准确率,代表在正确分类的情况下,正样本和负样本占所有样本的比例,也就是在所有的样本中被分类器正确识别的正负样本数所占的比例,准确率越高越好,计算公式如下:
(6)
精度[38](precision)也称作精确率,代表被分为正样本的数据中同时也是正样本的样本个数占所有被分为正样本的比例,计算公式如下:
(7)
召回率[38](recall)是用来度量覆盖面的,等同于灵敏度(sensitive),代表所有被分为正样本的数据中被正确识别的样本个数占所有正样本的比例,计算公式如下:
(8)
F1值[38]亦称为平衡F分数,同时反映了模型的精确率和召回率,其取值范围在0~1之间,是精确率和召回率加权平均的一种评价标准形式。计算公式如下:
(9)
3.2 实验结果及分析
深度Q网络以词向量集作为输入,在训练的过程中,如果将每封邮件分类正确,可以得到10的奖励值,分类错误得到-10的奖励值。Q网络在追求长期累积回报值最大化的过程中不断更新计算得到最大Q值,并用梯度的反向传播更新神经网络的参数ω,不断地减小通过经验回放得到的目标Q值和通过Q网络计算的Q值。ω收敛后,得到近似的Q值计算方法和贪婪策略,训练结束。
深度Q网络在训练时利用的邮件样本数量mini-batch设置为32,由3个卷积层提取特征,最后经过2个全连接层处理得到输出,网络更新的学习率α被设置为0.05,奖赏折扣率γ被设置为0.99,探索因子ε设置为0.1。表1给出了朴素贝叶斯、决策树、支持向量机、TextCNN、TextRNN和深度Q网络的性能对比。
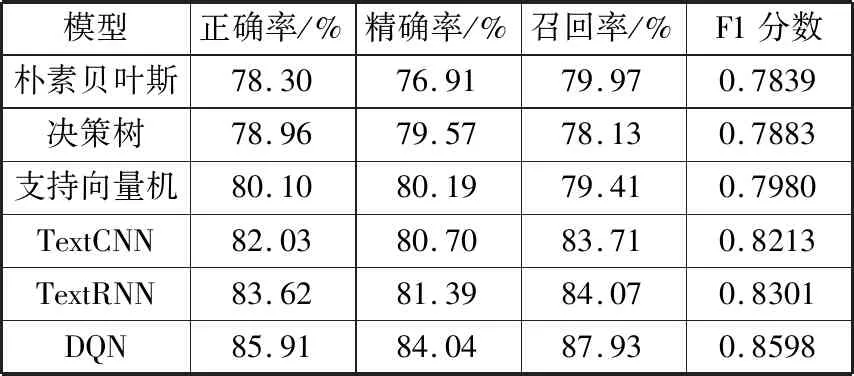
表1 不同模型与深度Q网络的性能对比
决策树方法采用分类与回归树(Classification and Regression Tree, CART)方法,支持向量机采用的是高斯径向基函数分类器,对应的核函数是高斯核函数,公式如下:
(10)
其中,z是核函数中心,σ为函数的宽度参数,控制函数的径向作用范围。
由表1可知,基于深度Q网络的垃圾邮件文本分类方法与以往的方法相比较效果有所提高,但仍然存在误分类的情况,这是由于深度Q网络在分类的过程中仍然会有一个很小的概率选择其他的行为,探测是否有可能获得更大回报值的行为。实验结果表明基于深度Q网络的垃圾邮件文本分类方法提高了垃圾邮件的识别正确率,可以避免由于误分类造成不必要的影响和损失,提高了垃圾邮件过滤的效率。
4 结束语
垃圾邮件的传播降低了人们办公的效率,占用和浪费了网络公共资源,危害了信息安全,是亟需清除的“毒瘤”。传统的垃圾邮件过滤方法需要依赖大量的人力,且效果并不理想,可能会不能正确地区别正常和垃圾邮件。为解决上述问题,本文提出了基于深度Q网络的垃圾邮件文本分类方法。该方法首先对原始邮件文本数据预处理和分词,得到邮件文本对应的分词集,然后采用Word2vec方法对文本的每个分词进行向量化处理,最后在深度Q网络上实现了垃圾邮件文本的分类。实验结果验证了该方法有效地提高了垃圾邮件过滤的效率和精确率。
猜你喜欢
承德医学院学报(2022年2期)2022-05-23 13:01:44
英语文摘(2021年10期)2021-11-22 08:02:36
潍坊学院学报(2020年2期)2021-01-18 07:01:56
疯狂英语·新阅版(2020年11期)2020-12-21 03:36:56
智富时代(2019年6期)2019-07-24 10:33:16
车迷(2018年12期)2018-07-26 00:42:32
高中生·天天向上(2016年9期)2016-11-22 09:10:34
现代计算机(2016年11期)2016-02-28 18:35:19
家教世界·创新阅读(2013年9期)2013-04-29 00:44:03
青苹果·教育研究版(2013年2期)2013-04-29 00:44:03
