
云计算技术应用下的流数据集成与服务研究
2020-06-17 01:30黄永生
信阳农林学院学报 2020年2期
黄永生
(合肥职业技术学院 继续教育学院,安徽 巢湖 238000)
随着便携式设备技术的进步,网络规模急剧增长,社交、视频等应用程序持续生成大量的流数据[1]。云计算是一种新的计算范式,通过虚拟化、动态可配置等技术将计算等服务按需通过互联网交付给客户[2-3]。因此,云计算技术为处理流数据提供了基础和平台。本文探讨了云计算技术应用下流数据集成与服务,设计基于云计算的流数据集成和服务框架,重点介绍了流数据集成和资源分配模块,设计有效的资源分配算法。
1 系统框架
流数据集成和服务的运行框架如图1所示。运行时框架由客户端和云端的软件模块组成。客户端监测CPU的工作负载和网络带宽。在客户端上启动应用程序时,会将请求发送到云中的资源管理器以执行。然后,资源管理器分配一个应用程序管理器来处理该请求。应用程序管理器首先向客户端询问其设备特征,例如CPU的处理能力、工作负载 和当前网络带宽。利用客户端设备的动态信息以及存储在云中的静态应用程序属性,应用程序管理器通过资源分配算法(第2章中介绍)生成资源分配结果。分配给客户端的组件在设备上作为线程启动,其他分配给云的组件被称为服务。应用程序管理器负责客户端和云之间的数据传输。
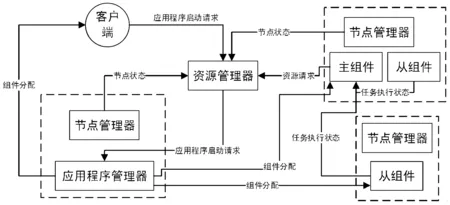
图1 流数据集成和服务的框架
1.1 资源配置交互模块
位于客户端和云组件中间的应用程序管理器具有两个功能。第一个是确定最佳资源分配结果并使资源适应客户端的变化环境,第二个是协调流数据应用程序的分布式执行。

图2 资源配置交互模块
客户端和应用程序管理器之间的交互模块如图2所示,该模块能支持自适应资源分配。假设双方之间存在两个逻辑通信连接,一个用来进行低速率的控制消息传输,另一个是用于客户端和云之间流数据的传输。客户端上的探查器会在启动时测量设备的特性,并持续监测CPU的工作负载和网络带宽。如果任何一个特性发生变化并超过阈值,更新资源分配结果的请求将发送到应用程序管理器上的控制器。应用程序管理器的控制器调用优化求解器以生成新的资源分配结果。基础模块执行器将结果作为输入,为流数据应用程序的分布式执行提供运行时支持。
在所设计的框架中,需要确保软件的运行不会给设备带来太多负担。因此,将优化求解器放在云上,而不是在客户端的设备上,以此减少本地资源的消耗。此外,可以将不同环境的资源分配结果备份到云中。当更新资源分配的输入参数与先前的输入参数相似,则将直接从云中查询资源分配结果,不需要优化求解器进行计算,以减少资源分配的等待时间。
在框架中,本地组件在设备上作为线程运行,而远程组件则通过调用云组件执行。在资源分配模型中,将分配到设备上的组件命名为本地组件,将卸载到云上的组件称为远程组件。应用程序管理器对每个远程组件都有一个线程,负责数据传输以及组件调用。由于线程充当远程组件的映像,因此将它们称为映像组件。
1.2 多租户组件服务
实现多租户的组件服务功能,以允许多个租户或应用程序实例共享组件。多租户组件服务采用主从架构,其中从属组件进行计算,而主组件负责将租户的负载调度到从属组件上。具体来说,主组件从资源管理器获取资源信息,并与节点管理器协同根据当前请求负载启动或者终止从属组件。多租户组件服务的目的是保证对基础资源的弹性利用,以适应动态的请求。
在框架中,即使用户运行相同的应用程序,也具有不同的应用程序实例。每个应用程序实例由一系列组件组成。云端的组件服务通常由多个应用程序实例共享。根据资源分配机制,应用程序实例在一个特定的组件服务上具有各种负载要求,即组件服务处理输入流数据所需的速度。
为了节省资源,需要解决负载调度问题,即将负载从应用程序实例调度到从属组件,使从属组件的数量最小化。假设从属组件都具有相同的容量。负载的调度问题可以被建模为在线的装箱问题[4]。
2 资源配置算法
在本节中,描述用于解决计算资源分配问题的模型、公式和算法。应用程序可以使用数据流图G+(V,E)表示,其中V={i|i=1,2,…,v}表示组件,E={(i,j)|i,j∈V}表示组件之间的依赖关系。si是组件i处理一个单位数据所需的平均CPU指令数。di,j表示需要为一个数据单元在信道(i,j)上传输的数据量。节点i上的权重wi代表计算成本,边上的权重ci,j表示通信成本。
将权重最大的组件/通道定义为关键组件/通道。流数据应用程序的吞吐量都由关键组件/通道确定,而关键组件/通道的计算/传输数据速度最慢。因此,有吞吐量TP=1/tp,其中
(1)
卸载决定主要取决于本地计算资源和网络质量。当CPU的处理能力为p,工作负载为η时,客户端设备上的可用CPU资源为pη。假设设备上同时运行的组件都被分配相等的CPU资源。当将组件卸载到云上后,由于CPU释放了资源,客户端上运行的其他组件将加速,则加速因子为N/(N-1),其中N是卸载前设备上组件的数量。云端有足够的资源来容纳卸载的组件,因此它们将不会成为数据流图中的关键组件。
对于流数据应用程序{G(V,E),si,di,j},资源分配问题是为资源分配数据流图的一系列v组件以及为交叉通道分配带宽,使流数据应用程序的吞吐量最大化。资源分配问题的最优化模型如下所示:
yi,j>0
(2)
x0=1
xv+1=1
xi∈{0,1}
其中,变量xi是组件卸载的决策变量:xi=1说明组件i在设备上执行,xi=0说明组件i在云端执行。yi,j是指分配给信道(i,j)的带宽。提出了一种遗传算法[5]来解决资源分配问题,如算法1所示。将不同的资源分配视为具有不同染色体的种群,具有较高适应性的个体更有可能生存和繁殖。在本研究中,具有较高适应性的个体即为具有较高吞吐量的群体。资源分配X由二进制字符串X={x1,…,xv}表示。

算法1资源分配遗传算法输入:N,Λ,Ω输出:最优资源动态资源分配方案1: Pop←RandomSelectPop(N); //生成初始种群2: g←0;3: whileg<=Ωdo4: Fitness←EvalFitness(Pop); //评估适应性5: NxtPop←RW(Pop,Fitness,Λ);6: i←1;7: whilei<=Pop∗Λdo8: Crossover(); //交叉操作9: i←i+2;10: endwhile11: foreachcinNxtPopdo12: NxtPop[c]←Mutate(); //突变操作13: endfor14: OptFitness←EvalFitness(NxtPop);15: Pop←Select(Pop,NxtPop,Fitness,OptFitness);16: g←g+1;17: endwhile18: returnPop;
遗传算法首先随机产生初始种群。N代表种群中个体的数量。在每一代中,评估种群中每个个体的适应性。根据其适应性从当前种群中随机选择个体进行繁殖。在算法中使用轮盘赌轮选择策略。每个个体被选中的概率与其适应度成正比。控制参数Λ代表所选个体的数量占当前种群数量的比例。通过交叉和突变对所选个体进行操作,然后将其添加到当前种群中。该算法会评估所有个体的适应性,选择最佳个体,然后将最佳的个人加入到下一代的种群中。当进化的代数达到其最大值Ω时,算法终止。在最后一代中,选择吞吐量最高的资源分配方案作为最终资源分配方案。
在每一轮中,资源分配遗传算法都会使用交叉和变异来对个体进行进化操作。交叉通过组合两个随机选择的个体来生成新个体(假设两个个体为A和B)。在交叉过程中,算法随机将基因A和B分别分为两部分。基因A的第一部分和B的第二部分组成一个新个体。变异则是随机更改基因上的一个或多个值。
3 性能评估
首先介绍种群大小N和控制参数Λ如何影响吞吐量和遗传算法。图3显示了在不同N的情况下算法的吞吐量。可以看到,在N值较高的情况下,该算法只需进行较少的迭代即可收敛到最终吞吐量。图4显示了Λ对性能的影响。Λ值越大,收敛速度和吞吐量就越高。它表明,如果在每次迭代中从种群中选择更多个体进行繁殖,则遗传算法将花费较少的迭代来找到最佳个体。
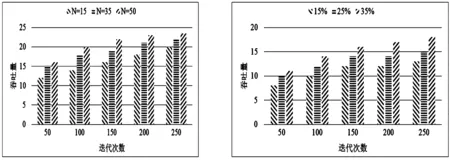
图3 种群大小和吞吐量的关系 图4 控制参数 和吞吐量的关系
图5和图6分别表示出了网络带宽和设备有效计算资源的影响。由结果可知,随着网络带宽的增加,本研究的方法能够获得越来越多的吞吐量。但是计算资源的增加并不一定带来更好的性能。对于最佳资源分配来说,应用程序的总吞吐量会受到计算和通信资源的限制。可以通过将计算移动到云端来减少本地设备的计算开销,但该操作可能会增加通信的开销。因此,随着带宽的增加,可以把更多的计算迁移到云端,这样一来,系统的吞吐量就会增加(如图3所示)。但是,若仅增加设备可用资源,由于带宽不变,本地的计算无法被迁移到云端。在这种情况下,系统吞吐量的变化并不明显。

图5 带宽和吞吐量的关系图 6 可用资源和吞吐量的关系
4 结论
本文研究了云应用程序的流数据集成和服务问题。首先设计了流数据集成与服务框架,该框架支持自适应资源分配和分布式执行。然后设计了基于遗传算法的资源配置算法,以解决资源分配问题。实验结果表明,该流数据集成与服务框架可以有效提高网络的吞吐量和资源利用率。在后续的工作中,将该框架部署到真实的应用环境中,进一步验证框架的有效性。
猜你喜欢
计算机与网络(2021年22期)2021-01-13
英语文摘(2020年10期)2020-11-26
电脑爱好者(2020年10期)2020-07-28
数码世界(2018年2期)2018-12-21
计算机系统应用(2018年7期)2018-07-18
智富时代(2018年3期)2018-06-11
智富时代(2018年3期)2018-06-11
集装箱化(2017年4期)2017-05-17
计算机应用(2016年10期)2017-05-12
集装箱化(2016年11期)2017-03-29
