
基于邻域信息的代价敏感三支决策文本情感分析模型
2020-06-15 06:47:32计博婧余静莹
宿州学院学报 2020年4期
计博婧,余静莹,陈 洁
1.安徽大学计算机科学与技术学院, 安徽合肥,230601; 2.池州学院数学与计算机学院,安徽池州,247000
文本情感分析研究是对一段短文本(如评论等)进行情感分析,将文本中包含的情感划分为两类:积极和消极。文本情感分析是自然语言处理的热门研究之一,具有重要的实际意义。例如,互联网上的各类社交媒体平台facebook、微博、论坛及淘宝评论等均存在大量的关于事件、新闻、产品以及他人等有价值的评论信息,现实中很多人通常会通过阅读这些评论信息作出决策。比如,人们在购买一部手机前,通常会先去相关论坛上查看其他用户的评论,再决定是否去下单购买。
文本情感分析方法一般可分为早期基于词典的方法、传统的机器学习方法以及目前主流的深度学习方法等。基于词典的方法为首先从文本中建立词典,计算词典中情感词的权重来对整句或整段文本进行情感极性的分析。Zhang等人对中文微博进行主题侦察,建立和扩展了新的情感词典,再据此计算情感分数进行分类[1]。Cui等人运用并行计算技术构建情感词典,提升了情感分析的速度[2]。这类方法很大程度上依赖于建立的情感词典,没有分析文本的语义信息及词的上下文关系,通常效果一般。传统的机器学习方法也广泛应用于文本情感极性的分析。周燎明等人基于bag of words模型将文本转为向量,再应用传统的机器学习模型来进行分类[3]。Pang等人综合多种机器学习模型(NB,SVM,ME)进行文本的情感分类[4]。Catal等构建了一个利用多种机器学习算法进行大多数投票的系统,以便侦察TripAdvisor上假的酒店负面评论[5]。这类学习方法弥补第一类过于依赖词典的缺点,明显提升了精确度。近年来,深度学习技术的飞速发展,使其在文本情感分析中表现出更好的性能。RNN(Recurrent Neural Network)适合建模有序数据,但因为现存的梯度消失问题,一般RNN直接学习远程依赖性仍然有难度。与RNN相似,LSTM(Long Short-Term Memory)的输入是谈话序列里单词的嵌入表示,LSTM通过递归转变当前词向量与先前的隐藏输出向量能够映射词序列和可变长度到一个固定长度向量[6]。LSTM网络被用于自然语言处理的众多领域,如外文翻译、文本分类以及情感分析等,取得了很好的效果,因此选取LSTM模型作为本文预处理文本工具,将文本转化为机器学习模型可直接处理的向量形式。
1982年,由Pawlak提出的粗糙集理论,采用上近似集和下近似集将论域分为三个域,姚一豫教授对这三个域进行了合理解释,将其称为正域、负域和边界域。其中属于正域的样本即为正类,属于负域的样本即为负类。而边界域中的样本则暂时没法决策,需二次处理。由此理论所得模型可用于处理不确定性决策,即三支决策模型(Three-Way Decision model,TWD)[7]。三支决策模型相较于二支决策模型的优点即体现在边界域上。当模糊数据无法决策时,可暂存于边界域中。当获得更多决策信息时,可对边界域进行二次划分,最终获得二支的决策结果。三支决策理论越来越受到众多学者的关注,各种有关三支决策的模型和应用纷纷涌现。2017年,Xia等提出了犹豫模糊集的一些基本运算和性质[8]。Zhang等将三支决策和随机森林相结合,建立了推荐系统[9]。Dai等提出了一种序列三支决策模型用于代价敏感的人脸识别问题[10]。Sun等人利用三支决策与决策支持系统来解决应急决策问题[11]。Jia等设计了一个新的多准则决策问题的三支决策模型[12]。Liang利用粒度计算的思想,将损失函数集合表示为区间数,建立了三支群决策模型[13]。Qian等人提出了一种基于多个不同阈值的广义多粒序列三支决策模型[14]。Yang等人提出了一种基于粗糙模糊集的顺序三支决策模型,并基于该模型提出了代价敏感粒度选择优化机制[15]。Yu等人讨论了代价敏感属性约简问题[16]。Jia等人建立了基于粗糙数的三支规则群体决策模型,用于解决流感应急管理问题[17]。
三支决策理论认为不承诺选择也是一种决策,这与人类处理决策问题的方法一致。另外,在实际分类问题中,不同分类错误所造成的误分类损失往往是不相同的,例如,对于商品评论的分类,如果将积极的评价为差的等级,会让其他用户少了一个良好的选择对象,如果将消极的评价为优良的等级,这可能给其他用户带来巨大的损失。因此,在处理边界域问题中,根据不同的分类对象进行代价敏感分析是很有效的手段。
本文提出一种基于邻域信息的代价敏感三支决策情感分析模型(Emotion Analysis algorithm based on cost-sensitive Three-Way Decision model,EATWD)来识别文本中的情感极性。该算法在数据预处理时首先借助Word2Vec工具将文本词向量化,并利用长短期记忆网络模型LSTM将词向量转换成64维特征向量,作为分类器的输入。本文基于最小构造性覆盖的三支决策模型(MinCA)将数据划分到正/负域和边界域,针对边界域中的数据采用基于邻域信息的代价敏感方法进一步划分,从而获得较高的精确度、更少的分类损失,同时减少高代价样本误分类数。
1 相关工作
1.1 MinCA模型
MinCA模型由张燕平教授[18]等于2013年提出,是依据样本集自身的物理特征构造覆盖,形成三个域,无需参数,避免了人为设置的相关参数对分类结果产生的影响。
假设给定一组训练样本集合X={(x1,y1),(x2,y2),…(xq,yq)},X是n维欧氏空间的点集,共有q个样本,分为w类,其中(xi,yj)表示样本xi的类别属性是yj,i=1,2,…,q,j=1,2,…,w。所有样本均需归一化处理后再构造覆盖。覆盖是由某一样本xk作为圆心再选取合适的半径θ形成的球体,被球体包含的节点称为被覆盖。构造覆盖形成三支决策过程中选取覆盖半径的方法是计算圆心样本与离圆心最近的异类点,即这一样本的类别与圆心样本的类别不同,之间的距离d1。MinCA模型中构造覆盖的半径是最小的,获得的覆盖中的样本是最精确的。
MinCA模型根据样本相似性特征和样本的类别属性等来构造覆盖C,覆盖内的样本即为正域/负域,覆盖外的样本属于边界域。所有样本训练完毕后将得到一组覆盖集合
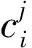
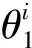
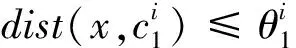
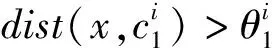
(3)其他,则x∈BND(C1)。
由此可以分析出,如果样本被包含在覆盖C1中,则划分到正域;如果样本被包含在覆盖C2中,则划分到负域;如果样本没有被任何覆盖包含,则划分到边界域。
1.2 LSTM模型
LSTM模型中引入3个门,即输入门、遗忘门和输出门,以及与隐藏状态形状相同的记忆细胞,从而实现对远距离信息的处理,LSTM记忆单元结构如图1所示。
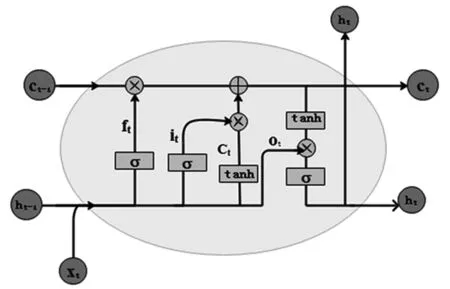
图1 LSTM示意图
LSTM模型的工作过程分为4个阶段:
(1)由遗忘门ft确定丢弃哪一部分的信息;
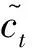
(3)将旧细胞状态ct-1更新成新细胞状态ct;
(4)输出门ot和tanh层确定最终输出值ht。
上述步骤[19]中公式如下。
遗忘门:ft=σ(Wf×[ht-1,xt]+bf)
输入门:it=σ(Wi×[ht-1,xt]+bi)
输出门:ot=σ(Wo×[ht-1,xt]+bo)
最终输出:ht=ot×tanh(ct)
其中,σ(z)是sigmoid函数,经过其作用后,输出的函数值落在0~1之间,表示可以通过的量。
2 EATWD模型分析方法
本文针对文本情感分类问题,提出一种基于邻域信息的代价敏感三支决策情感分析模型。
2.1 数据预处理
鉴于计算机无法直接处理文本,首先需要将文本转为计算机可以处理的向量形式。本文采用Word2Vec工具和LSTM神经网络模型对原始文本进行数据预处理,结果生成一个64维的特征向量。预处理的详细步骤如下:
(1)首先运用Jieba分词工具对文本进行分词,再去除停用词等;
(2)然后基于Word2Vec工具将分词所得词语向量化;
(3)最后将得到的词向量依次送入LSTM模型,从而得到该文本的句子特征向量。
由于中文不同于英文具有现成的词语分隔符,需要使用一定的分词算法对其进行预处理。词向量化工作是自然语言处理任务中基本的处理步骤,为了便于计算机处理文本类型数据,一般是将文本映射为向量空间中的点,从而进一步进行后续处理。
2.2 基于代价敏感的边界域处理
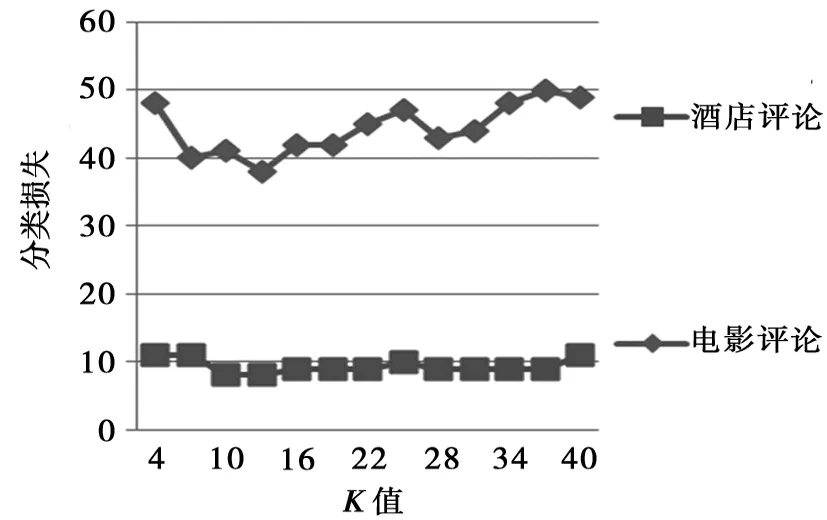
本文利用MinCA模型对预处理得到的64维特征向量数据集进行处理,将向量空间中的样本点划分为三个域。然后采用基于邻域信息的算法思想进一步对边界域中的样本进行分类,目标是在提高分类准确率的同时降低分类损失。基于邻域信息的算法是找出该样本周围K个最近的邻居,统计K个邻居中最多属于哪个类别,再将该样本划为同一类别。该算法利用了样本之间的邻居关系,充分考虑了样本的局部性特征,可以最大程度地降低分类过程中的误差。但是为了保证基于邻域信息的代价敏感算法能达到较好的分类效果,在利用该算法进行分类时必须采用一定的方法找出合适的K值。
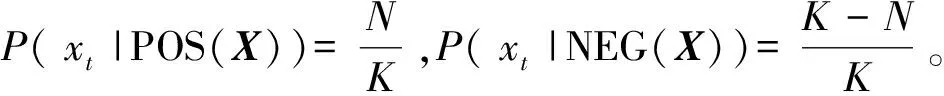
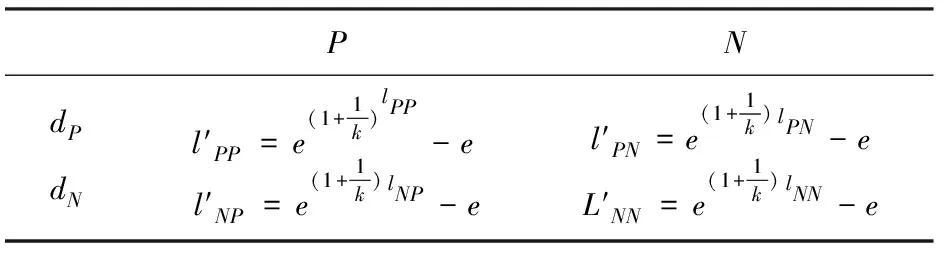
表1 损失函数矩阵
Cost(dP|[xt])=lPPP(xt|POS(X))+lPNP(xt|NEG(X))
(1)
Cost(dN|[xt])=lNPP(xt|POS(X))+lNNP(xt|NEG(X))
(2)
(3)
(4)
基于上述描述,基于EATWD的具体步骤如下:
输入:此处假定有文本集合,其中一句文本T为“新电影感觉还不错。”
输出:类别y(T)。
Step1:利用Jieba分词工具和Word2Vec工具将文本T分词后的每个词语表示成词向量;再将得到的Embedding向量依次送入LSTM模型,得到表示文本T的64维句子特征向量。按照同样的方式将文本数据集中的所有文本均转换为特征向量,得到了向量空间中的点集X;假设训练文本向量为:
X={(x1,y1),(x2,y2),…(xq,yq)}

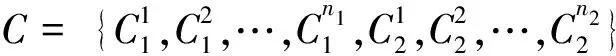
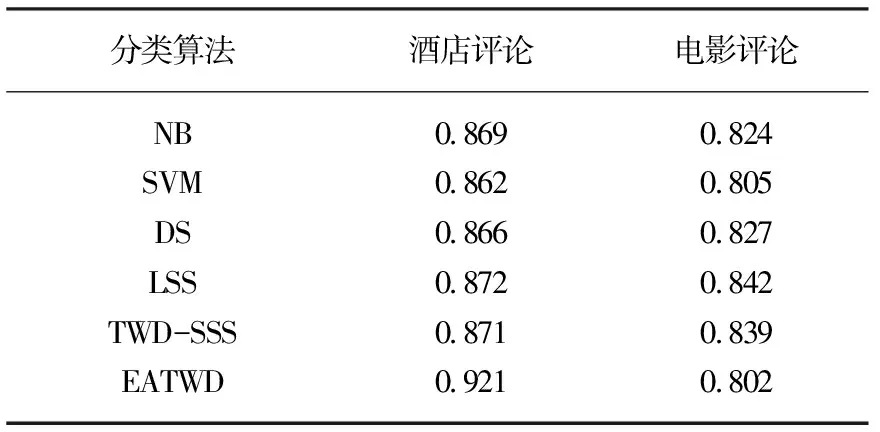
Step3:根据数据集自身的特征给定K值的取值区间为[a,b](a Step4:针对lNP>lPN的数据集,若 将xt划分到负域,否则xt被划分到正域;针对lNP 则将xt划分到正域,否则xt被划分到负域。针对lNP=lPN的数据集,若Cost(dN|[xt])-Cost(dP|[xt])≥0,则将xt划分到正域,否则xt被划分到负域。划分结束后,若xt被划分到正域,则执行POS=POS∪xt,Ct=Ct-xt;若xt被划分到负域中,则执行 NEG=NEG∪xt,Ct=Ct-xt。 Step5:若集合Ct非空,则转Step4;若集合Ct为空且K Step6:计算不同K值下的文本分类损失,分类损失最小的K值即为选取的Kmax。测试时,基于Kmax计算,对边界域中的样本再次决策,直到所有样本均被分类,返回类别属性。 为了验证本文提出的EATWD模型对情感分析问题求解的有效性,选择两个语料库进行实验。英文语料库polarity dataset v2.0选择来自康奈尔大学的电影评论,包括已被标记为积极的电影评论1 000篇和标记为消极的电影评论1 000篇。中文语料库ChnSentiCorp-Htl-ba-600,选自携程网站上谭松波采集的酒店评论,其中包括积极、消极的酒店评论各3 000篇。详情如表2所示。 表2 语料库信息 为了保证实验结果的稳定性,利用十交叉验证方法对文本数据集先后进行10次训练,最后将所有结果取平均值作为最终实验结果。 在对边界域样本进行分类时,存在两个参数:误分类损失函数和K值。误分类损失函数lNP、lPN的大小关系是人为设置的。比如,对于酒店评论的分类,如果将优秀的酒店评价为差的,会让其他用户少了一个良好的选择对象,如果将服务水平差的酒店评价为优良的等级,这可能给其他用户带来巨大的损失。因此,对于酒店评论数据集来说,可以设置误分类损失函数满足lNP 图2 测试分类损失 本文所提EATWD算法和NB、SVM、DS以及LSS等模型的分类方法进行对比,评价指标是分类的准确率。所有实验对文档的处理均是相同的,其对比结果如表3所示,其中部分结果来源于文献[20-24]。 表3 不同方法在中英文语料库中的准确率 由表3可知,EATWD模型在这两个语料库上总体准确率均超过80%,说明该模型能够从大量文本中提取到有用的信息。其次,通过与各种机器学习算法进行对比,EATWD模型的准确率更高,尤其在中文酒店评论数据集上的准确率高达90%以上,充分说明该模型在文本情感分类上的优势。 本文提出了一种基于邻域信息的代价敏感三支决策情感分析模型,运用Word2Vec工具和LSTM网络模型对文本进行预处理,形成64维特征向量,并采用最小构造性覆盖模型MinCA将样本集划分为正/负域和边界域,最后利用基于邻域信息的思想可以进一步对边界域样本进行划分。实验证明,该方法可以获得更高的分类性能,和较低的分类损失代价。然而,该分类算法需要明确不同类别的代价比例,针对复杂的分类问题时间开销比较大,这也是下一步研究的重点方向。3 实验与结果
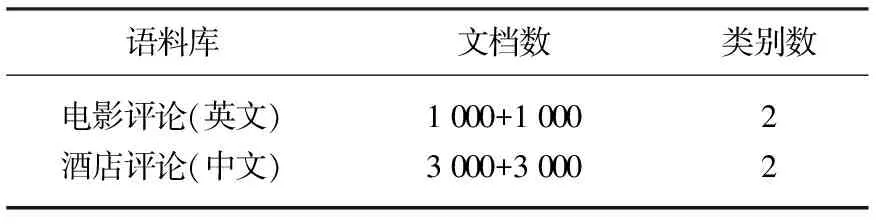
3.1 数据集
3.2 实验设置
3.3 结果对比
4 结 语
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46纺织科学研究(2021年9期)2021-10-14 08:52:10数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36中学生数理化·七年级数学人教版(2019年6期)2019-06-25 01:01:34中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06初中生世界·七年级(2017年9期)2017-10-13 22:27:46高中生学习·高三版(2016年9期)2016-05-14 09:12:05新高考·高二数学(2015年11期)2015-12-23 18:17:44
