
改进的CRNN模型在警情文本分类中的研究与应用
2020-06-13 07:11:22王孟轩
应用科学学报 2020年3期
王孟轩, 张 胜, 王 月, 雷 霆, 杜 渂
1.电信科学技术第一研究所,上海200032
2.迪爱斯信息技术股份有限公司,上海200032
现代警务处理依托大量的案件统计数据.在此背景下,公安机关对于警情数据分析处理能力的要求不断提升.近年来,公安行业利用大数据的各类技术,构建了包含各警种的公安大数据应用平台,通过多类信息汇聚平台完善了现有公安数据库和数据中心,使其能够在指挥、治安、刑侦等方面为公安干警提供更加方便、快捷的指导.在公安机关各类业务系统汇集的海量数据中,包含数量庞大的警情记录文本信息,这些文本信息可以为情报分析研判、串并案管理、案件侦办和指挥调度等提供数据支持.但是面对海量的文本信息,如何对其进行智能化分析一直是很棘手的问题.
本文基于某市公安局110 接处警的实际数据,从报警和反馈信息中提取大量刑事类警情样本,这些样本含有对相关警情的简要描述.警情描述信息中有各类案件的时间、案发地点、类型等要素.在刑事案件归属种类的判定过程中,首先需要接警员在短时间内根据报案人的描述初步判定警情类别,再由现场处置民警根据实际情况反馈分类之后对警情类型进行判定.因为上述流程复杂且很难保证时效性,所以警情分类精度和效率都不高.
为了提升接处警效率和提高案件类型判断的智能化,本文构建了基于深度学习的警情智能文本分类研判系统,通过对现有文本分类模型进行分析,改进其他行业现有应用的文本分类方法并引入公安行业,使其在警情文本处理场景中呈现出快速、高效、准确的结果,实现智能化提取警情和结构化处理信息,最后通过分析实现警情分类和串并案等警情研判的功能.
1 相关工作
1.1 文本分类调研
文本分类过程大体分为5 个步骤:数据预处理、特征选择、分类模型的训练、模型参数调整和模型评估.从本质上讲,文本分类模型是一个有监督学习模型,经过训练后,能够自动将文档归类到预定义的类别中.传统的文本分类所利用的机器学习算法有:K 近邻[1](K-nearest neighbor, KNN)、朴素贝叶斯[2](naïve Bayes)和支持向量机[3](support vector machine,SVM)等.但是这些方法都存在一定的局限性[4].随着深度学习方法的演进,研究人员不断提出新的网络结构并将其应用于在文本分类任务中,本文对几种典型的分类方法进行了分析,从而提出适合警情文本数据的文本分类网络,极大扩展了文本分类算法的应用场景.
1.2 常见文本分类模型介绍
1.2.1 Text-CNN
Text-CNN[5]模型是由Yoon Kim 在2014 年提出的,它将卷积神经网络(convolutional neural networks, CNN)应用在文本分类任务中,利用几种不同尺寸的卷积核(kernel)来处理句子中的关键信息,旨在从几个不同的维度捕捉一句话中的局部相关性.经过卷积后的数据再连接一个池化层,使其更加方便地提取文本的特征表示向量.常见Text-CNN 的网络结构如图1 所示.
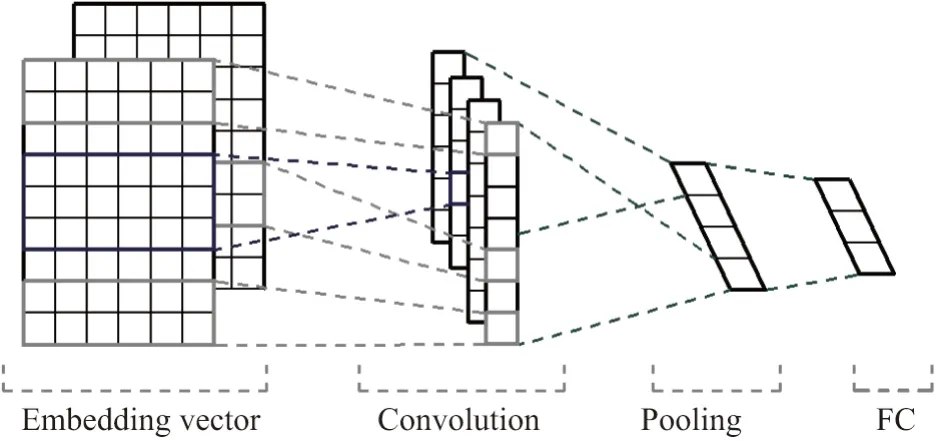
图1 多通道Text-CNN 网络结构[5]Figure 1 Multichannel Text-CNN model[5]
CNN 结构的优点是可通过简单网络结构抽取到局部特征信息,便于并行计算及提升计算速度.但是这样的网络结构在面对长序列文本时存在明显的问题,分析网络结构后可以看出,Text-CNN 主要通过卷积核的大小来提取不同长度的关键特征,但文本上下文存在明显指代关系的句子需要网络具有较大的卷积核来明确这种关系,这对CNN 网络来说显然是不合理的.因此需要改进网络结构并使其具有记忆性特点,以处理长序列文本所包含的指代关系.
1.2.2 RNN
循环神经网络(recurrent neural network, RNN)用于文本分类任务时常常利用其两种改进算法:长短时记忆(long-short term memory, LSTM)[6]和门控循环单元(gated recurrent unit, GRU)[7].LSTM 网络是由Sepp Hochreiter 等人在1997 年首次提出的,该网络通过引入相应的控制门,解决了传统的RNN 面对长序列信息处理后保留较多冗余信息以及传统RNN 训练时出现的梯度爆炸的问题.该算法能够模拟人处理信息的过程,通过遗忘不重要的信息,保留关键信息,从而达到控制当前记忆状态的目的.
GRU 网络结构同LSTM 类似,如图2 所示,也是通过引入控制门达到和LSTM 相同的效果.不同之处在于,GRU 网络相比LSTM 因为减少了控制门的数量,使得GRU 网络的参数减少很多,训练速度更快,如果有充足的训练数据,它的模型表达能力会更强.

图2 LSTM 和GRU 单元对比Figure 2 Compare cell of LSTM with GRU
虽然LSTM 和GRU 模型在解决长序列文本处理过程中能够体现出很好的效果,但是它们需要的网络结构十分复杂,从而导致多层的LSTM 计算速率比其他模型慢.单纯使用LSTM 和GRU 模型需要综合考虑模型计算速度、资源消耗等问题,以避免因模型复杂导致分类效率差的情况出现.
1.2.3 Attention 模型
在对长序列文本编解码过程中,模型要求特征信息统一结构编码,使得模型权重参数量大幅增长,为了减少模型对输入形状结构的依赖,2015 年文献[8]提出了注意力机制,该机制对于网络输入序列的不同位置赋予不同的权重,并保持输入与输出的对应关系[9],减少了结构问题,这也使得网络具有了“聚焦”不同位置的关键字特征的能力.图3 为注意力机制在RNN中应用的一种结构图.
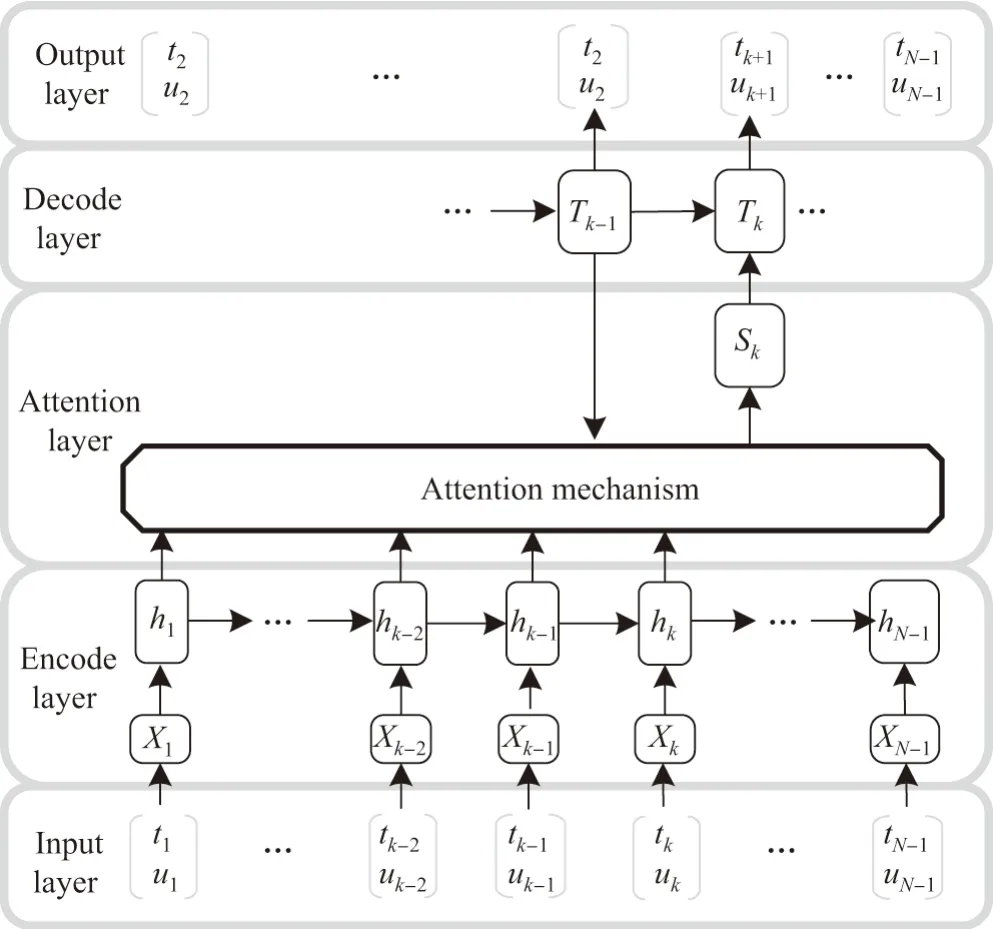
图3 注意力机制在RNN 模型中的应用示意Figure 3 Application of attention algorithm in RNN model
Attention[10]机制常常可与LSTM 模型一起使用,该组合网络在处理上下文信息时体现出了优异的效果.
分析上述主流的基础模型后可知,每种模型都有其适应的处理范围和各自特点.在使用时应该根据待分类文本的特点和分类性能的要求选择合适的分类模型.
1.3 数据预处理
1.3.1 文本获取
在为某市公安局建设110 接处警平台和警情分析研判平台过程中,首先对警情数据进行脱敏处理,然后对警情文本描述信息进行文本筛查.对原始文本要逐条核查警情类别是否与警情描述一致,同时对重复报警、无效报警进行删除,按照不同的案件类型进行存放.
1.3.2 词嵌入方法与Word2vec 模型
自然语言模型中的词语通常被认为是具有表达能力的基本单元,因此在进行自然语言处理时常常以词语为基本单元将句子拆分成一组有序排列的词组向量,以方便计算机进行处理,这个过程称为词向量表示.目前构造词向量的方法有两种:一种是独热(one-hot)表示,不包含任何语义;另一种是分布式表示,基于上下文相似的词语在文中表达的语义也相似,因此也包含语义信息.本文使用词嵌入方法,通过神经网络利用统计语言模型对中心词及其上下文进行建模,该方法的优点在于生成的词向量维度可控,并且包含了丰富的语义信息.
Word2vec 是Google 2013 年发布的一个开源的词向量训练工具,它可以将单词映射成实数值向量.其模型的核心思想是:利用深度学习模型训练出指定维度的词向量,这些词向量之间的相似度即词语之间的距离,表示了词语之间的相似度.Word2vec 主要有跳字模型(Skip-Gram)和连续词袋(continuous bag-of-words,CBOW)模型.
1)Skip-Gram 模型
Skip-Gram 模型通过给定的输入词wi来预测其上下文swt= (wt−k,wt−k+1,··· ,wt−1+k,wt+k),其中k为上下文窗口的大小,即左右选取词的个数.Skip-Gram 可以计算出周围词ci基于中间词wt的条件概率,利用Skip-Gram 计算语句s为自然语言的概率P(s),其公式为
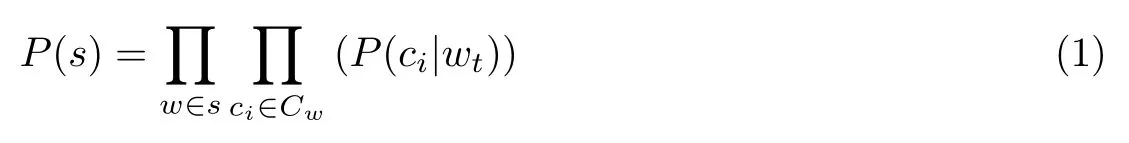
式中,Cw为wt的上下文语境.模型的训练目标就是使P(s)最大化.对于整个文本T,可以得到文本的概率表示模型P(T),即

为了得到最大条件概率,模型的最大似然函数表示为
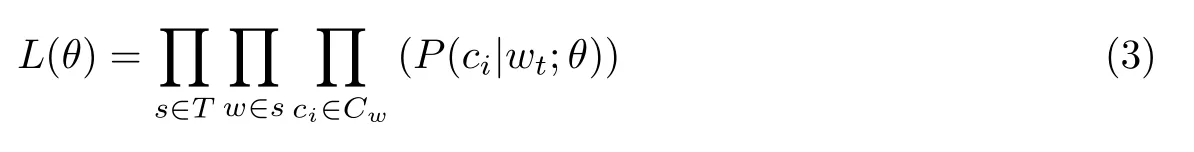
取对数后为
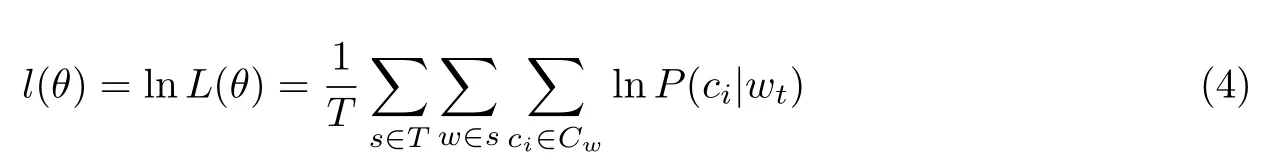
Skip-Gram 的训练目标就是使式(4)最大化.模型如图4 所示.
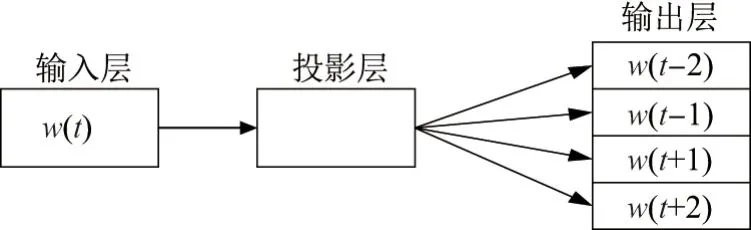
图4 Skip-Gram 模型Figure 4 Model Skip-Gram
2)CBOW 模型
与Skip-Gram 模型不同,CBOW 模型具有隐藏层且它是利用单词的周围词来预测中间词概率的模型.利用上下文swt= (wt−k,wt−k+1,··· ,wt−1+k,wt+k)来计算中间词wt属于词典中某个词的概率.
对于语句s,利用CBOW 模型计算其为自然语言的概率P(s),计算公式为
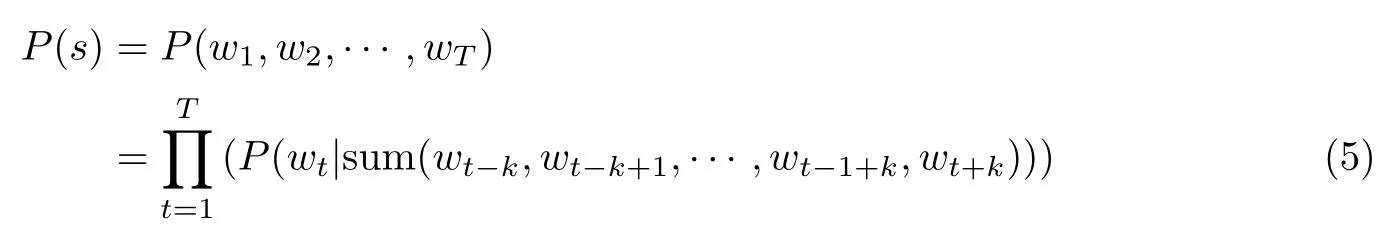
式中,P(w1,w2,··· ,wT)为文本中单词的联合概率.同理,对于整个文本T,构建如下似然函数

模型训练的目的就是使目标函数P(s)最大化,因此得到模型的对数似然函数为
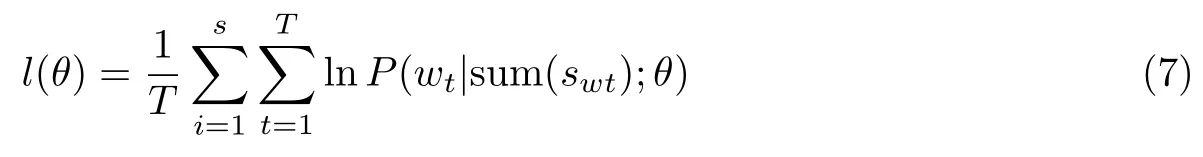
CBOW 模型的训练目标就是使得该函数取得最大值.模型的主要结构如图5.
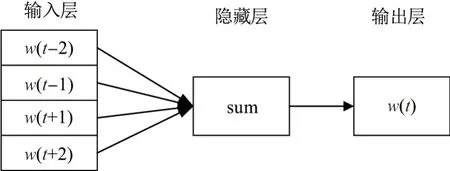
图5 CBOW 模型Figure 5 Model CBOW
2 模 型
2.1 建立网络模型
本文研究的警情描述文本多以短小文本形式出现,而且这些文本包含大量的指代关系以及地名、人名、时间信息等命名实体,在特征提取过程中要尽量减少命名实体对分类准确性的影响,需要合理地组合基本模型,使之能够更加准确地区分案件类别.本文提出引入由多种网络组合的卷积循环神经网络(convolutional recurrent neural network, CRNN)模型,该模型在单一的CNN、RNN 模型的基础之上加入SelfAttention 和MLP 层以改善分类效果,构成了CNN+BiLSTM+SelfAttention+MLP 的混合模型.如图4 所示,下文对每层的功能进行具体阐述.
2.1.1 CNN 层
通过在前文中的介绍可以知道,CNN 模型在提取局部信息特征的时候能够体现出不错的效果,局部信息的提取对于分类任务来说非常重要,所以用CNN 模型作为分类网络的第1 层.经过词嵌入的特征向量可以表示为xi ∈Rd,它表示词向量中第i个特征的d维向量,输入的句子用X ∈RL×d表示,其中L表示句子长度.根据CNN 要求可以定义k ∈Rm×d用来表示卷积所用的卷积核,其中m为卷积核窗口尺寸.定义卷积操作

加入激活函数f以及偏置项b后,卷积操作得到卷积结果

式中,激活函数f选用修正线性单元(rectified linear unit,ReLU),i ∈[1,L −m+1].一般情况下,对通过卷积网络得到的特征向量进一步进行池化操作,其目的是使特征矩阵变得稀疏,以降低特征序列的连续性[11-12].
2.1.2 BiLSTM 层
如图6 所示第2 层为BiLSTM 网络,它是在LSTM 网络的基础上扩展的,且由前向LSTM 与后向LSTM 组合而成,利用双向的LSTM 模型能够提取文本的下文关联关系和指代关系等特征,图2 给出的LSTM 网络结构,它在传统RNN 的基础上引入输入门、遗忘门、输出门,解决了RNN 对长序列信息处理保留较多冗余参数的的问题.各个控制门和状态之间的公式为

式中,it为输入门控制函数,ft为遗忘门控制函数,ot为输出门控制函数,σ为sigmoid 激活函数,ht表明了LSTM 的隐藏状态,和Ct是指在时间步长t时的单元状态,Wi,Wf,Wo表示模型要训练的权重参数,xt为CNN 提取到的特征向量,其维度和CNN 输出维度保持一致.正向LSTM 和反向LSTM 组合构成BiLSTM 作为模型的第2 层,可有效保持长序列“远程依赖关系”.
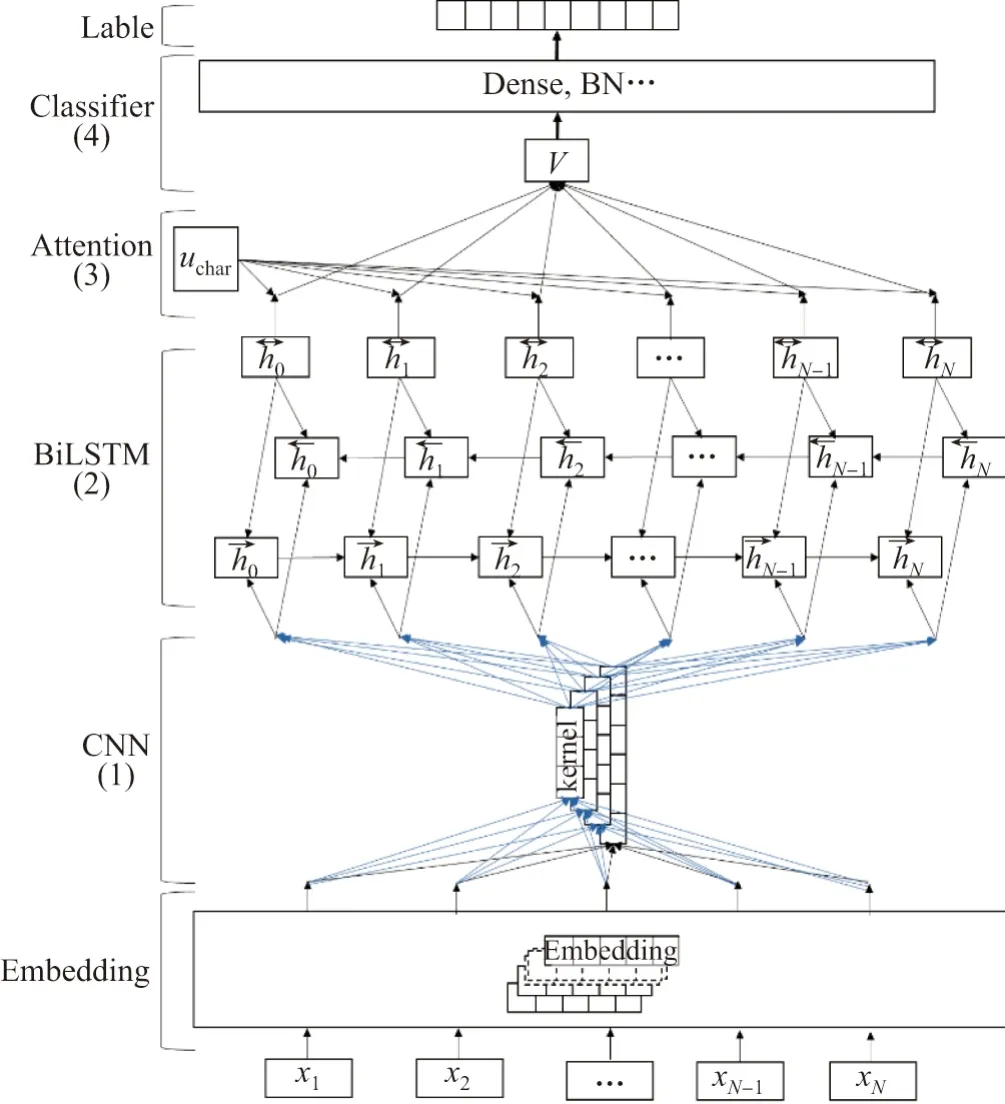
图6 模型结构示意Figure 6 Model structure diagram
2.1.3 Attention 层
注意力机制又称内部注意力,通常叠加在BiLSTM 层之后,采用向量拼接方式将注意力机制模型和BiLSTM 输出的特征向量拼接到一起.对应公式为

式中,hs是一个随机初始化的上下文向量,其具体含义可以认为是对输入特征的一种语义表示.引入注意力机制计算分布概率,突出了输入各部分对输出的影响程度[8],已达到优化LSTM 模型效果.
2.1.4 Dropout 层
在图6 中的Classifier 层由Dropout[13-14]、MLP[15]、批量标准化(batch normalization,BN)[16]功能层组成.深度学习过程中,当训练样本较少而模型参数过多时,模型在训练时很容易出现过拟合现象.有效的解决办法是使用Dropout 层,其内部机制可以参考文献[14]的阐述.
2.1.5 MLP 层
MLP 层由Dense(全连接层)和其他附加层组成[15],作用是汇聚网络信息得到输出结果.不过在连接到Dense 层之前要将上一层输出的多维向量转变为一维向量[17],这里使用Keras中自带的展开层(Flatten)作为前级输出和Dense 之间的连接.
通常情况下,网络搭建过程到此已经完成,但是在实际训练过程中发现学习率的值设置较大会导致模型的训练速度过慢.文献[16]表明,解决该问题的有效手段是在全连接层后加入BN 层,因此本文模型添加了BN 层.
BN 层能改善正则化策略,并把训练数据彻底打乱,改善流经网络的梯度,也正因为此,BN 层成为了在进行深度网络训练时最常采取的算法.
网络的结构最终确定后通过文本中具体的句子长度、单词数量等信息,设定网络参数,开始模型训练及参数定型过程.
3 实验结果及分析
3.1 数据集准备
本次实验选取了刑事类警情中9 类常见的案件种类,数据共18 000 条,数据集被划分为训练集、验证集、测试集,数据集的划分情况如表1 所示.

表1 数据集划分信息Table 1 Data set partitioning information 条
3.2 模型训练及实验设置
实验环境设置:操作系统Windows 10 专业版,内存16 GB,处理器为IntelCore™i7-8700 CPU@3.20 GHz×4,在Keras 框架下使用Python 语言.网络模型在训练时优化器选择Adam 优化器,网络参数设置如表2.
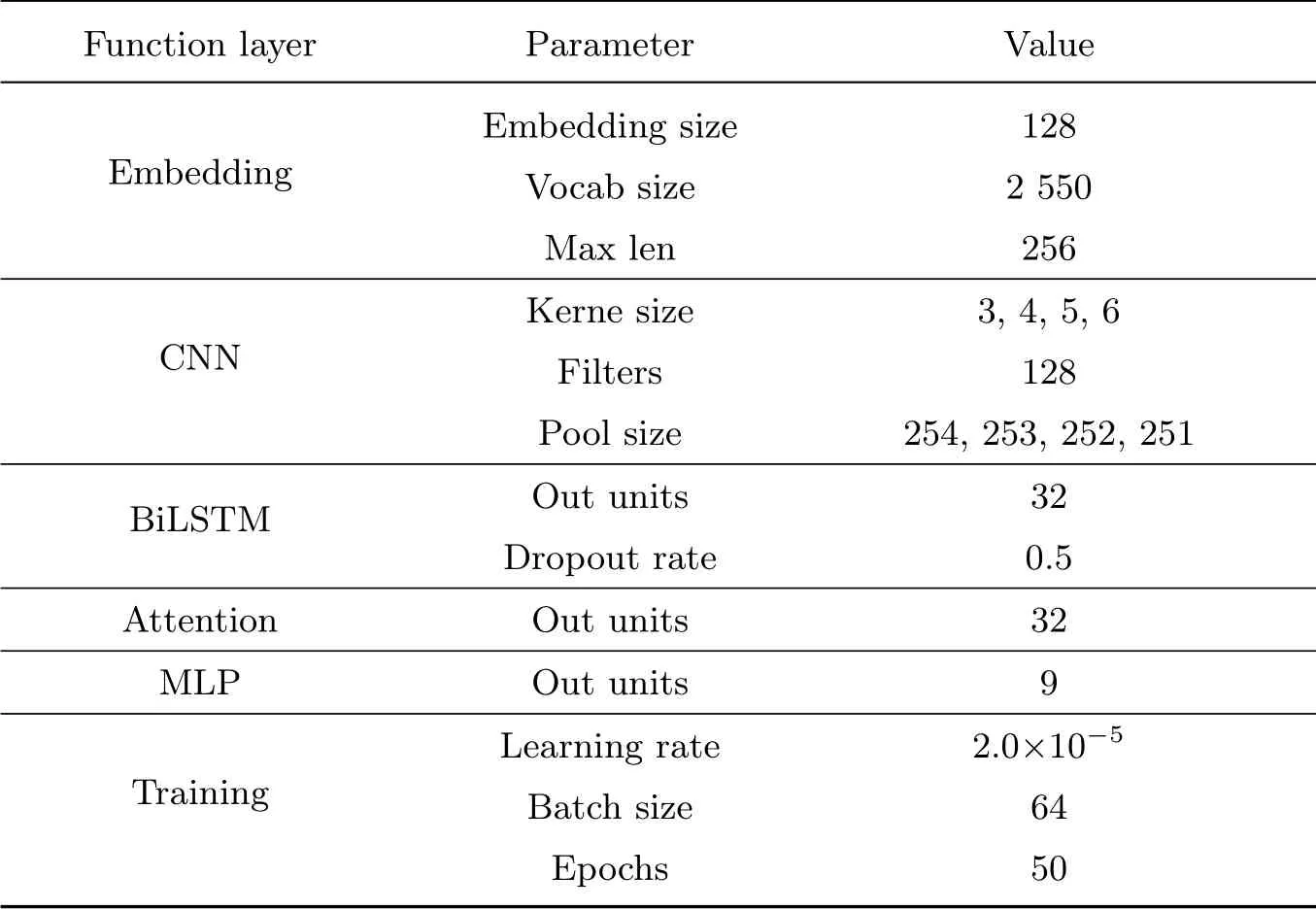
表2 实验参数信息Table 2 Experimental parameters information
训练警情数据时,文本序列的编码长度统一设定为256.由于不同的学习率会极大影响网络优化的整体性能,如何合理地设定学习率一直是深度学习过程中的难点.本文通过多次尝试发现,将学习率设定为2.0×10−5时能达到一个比较理想的效果.实验中的损失函数利用了Keras 模型中的交叉熵损失函数(Categorical crossentropy),批次尺寸(Batch size)设定为64,迭代次数(Epochs)设定为50.
3.3 模型测试结果
训练模型在测试集上的预测准确率达到97%.鉴于原始数据的专业性和特殊性,需要用交叉验证的方法对模型进行评估.对于公安数据来说有些案件因其特殊性致使相关报警描述十分稀少,因此本文采用适合原始数据不充足情况下的交叉验证方法对模型进行评估,能够有效地体现模型对于不同种类案件的分类效果.在本次实验中的交叉验证效果见图7.
交叉验证结果显示了模型能够有效避免相似案件的错误分类.由于原始文本纵火案件(图5 标签010300)和损坏财物案件(图5 标签011900)中都存在“纵火”“烧毁财物”等描述,原始数据中的案件类别界定本身就很模糊,这也是“纵火”“烧毁财物”交叉验证结果准确率较低的原因.团队后续会和公安部门配合,根据原始数据质量评估的情况对警情类型做出更明确的判定.
为了更加直观地验证文本分类效果,我们向文本分类器输入单条警情描述文本进行测试,结果如表3 和4 所示.
输入内容:2015 年8 月7 日15 时00 分,某市公安局某派出所民警接张某报警,称其被骗了1.8 万.经初查,2015 年7 月张某认识一名游戏名叫“余某”的男子,后来张某以1.8 万元买下“余某”的游戏账号,现在“余某”将游戏账号密码改回.目前张某无法登陆账号,也联系不上“余某”.
测试结果:分类概率最大值是改为9.25×10−1,对应标签为011100(诈骗案件代码).
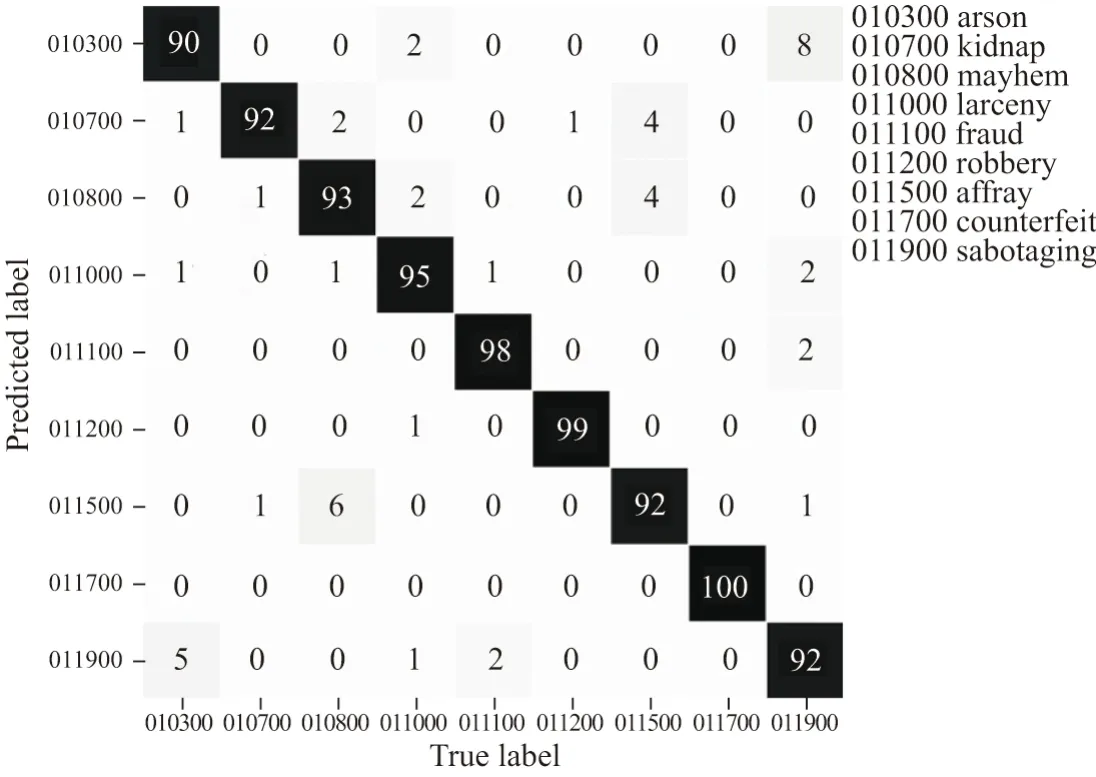
图7 交叉验证结果Figure 7 Cross-validation result
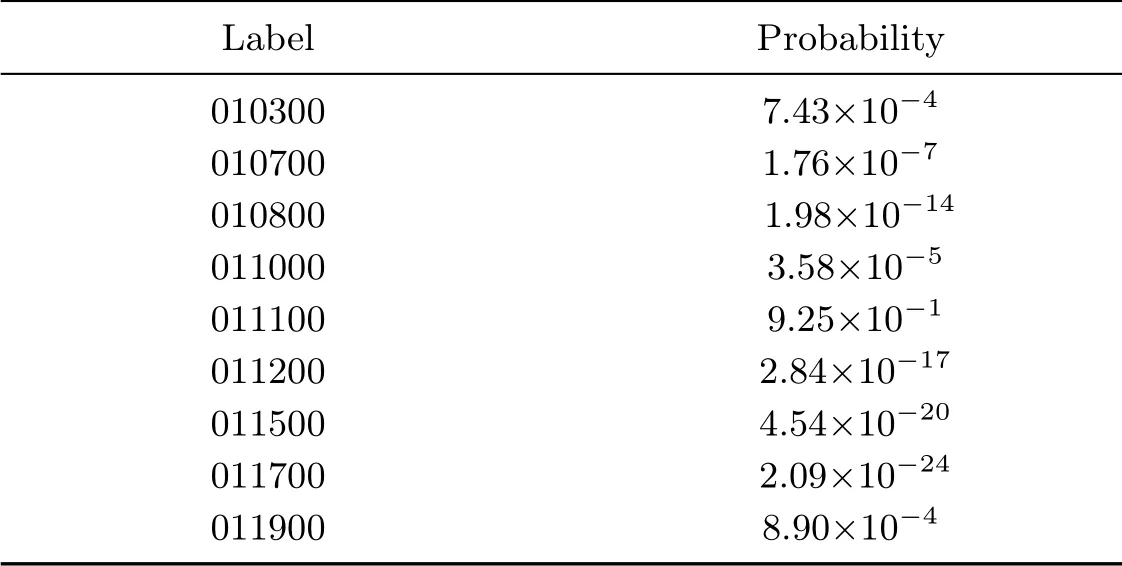
表3 单条较长警情测试结果Table 3 Single longer alarm test results
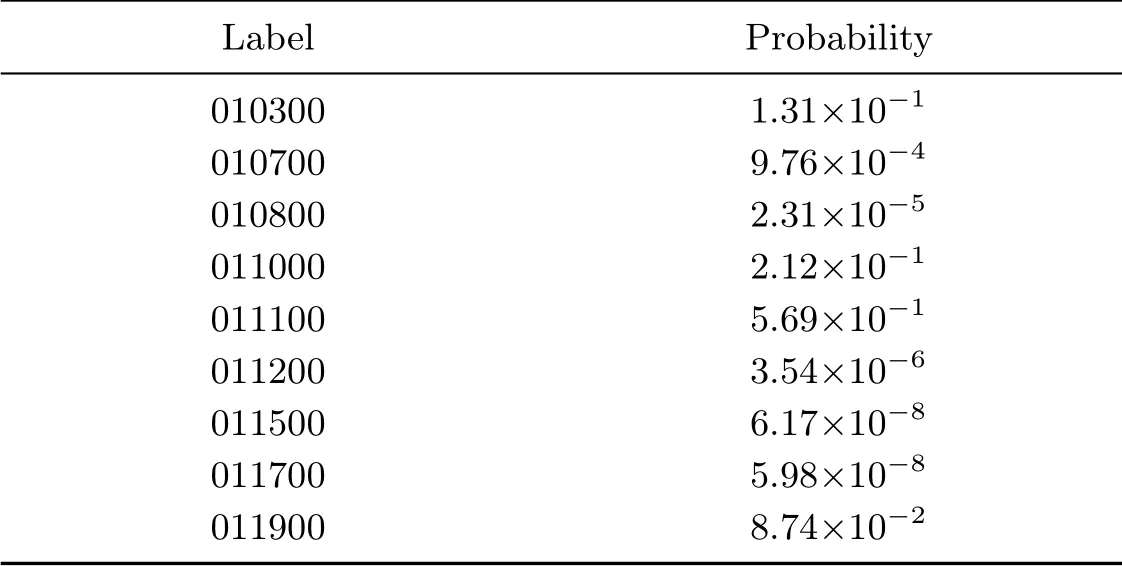
表4 单条较短警情测试结果Table 4 Single shorter alarm test results
输入内容:报警人称钱被骗.
测试结果:分类概率最大值是5.69×10−1,对应标签为011100(诈骗案件代码).
可以看出,对于较长的警情描述文本,本文构建的网络有较好的分类性能,但是对于较短的警情描述文本,分类器输出的最大分类概率远远低于较长警情描述文本的分类概率.为使系统能够有效分类,在实际使用中给分类器设置阈值,当分类最大概率大于阈值时,分类结果认为准确;否则就将分类结果判定为“其他警情”.设置阈值时可根据现场使用情况做适当调整.
3.4 模型对比实验分析
为了测试网络的有效性,本文选取了几种目前常见的文本分类方法在相同数据集上进行对比,选取的文本分类算法包含:Text-CNN,FastText、Attention-based BiLSTM[18]、层次注意网络(hierarchy attention network, HAN)[19].对比结果如图8 所示.
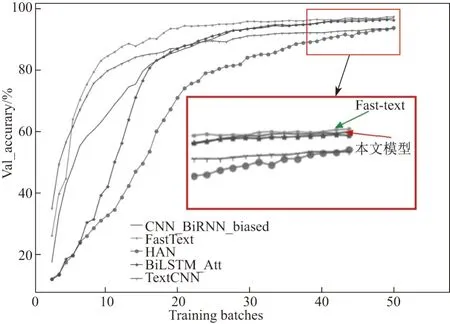
图8 多模型准确率对比Figure 8 Multi-model accuracy comparison
由图8 可知,含有Attention 层的网络能够明显提升文本分类准确度,本文所述模型的分类准确率为97%,分类效果比较理想.需要说明是,虽然图8 中FastText 模型的准确率可以达到98%以上,是所有分类模型中准确率最高的,但由于FastText 重点关注了词语出现的频率,利用了词频特征对句子进行分类,所以在模型的训练过程中存在严重的过拟合现象,在实际使用中泛化性能较差,主要体现在如下测试场景.
各地方警情数据大多数是人工录入的,警情数据书写风格在很大程度上取决于各地方警员的风格.为了保证实验所述模型在实际使用场景中能更好地适应现场环境,我们利用其他城市公安警情语料对该模型进行了测试.例如同样是诈骗类案件,上述测试集中警情短文本出现次数相对较少.但另选某城市警情数据,该数据集缺少精确详细的案件描述过程,类似上述文本中的短文本反而经常出现,此时测试数据中的短文本数量远超于长文本,所测得的FastText 文本分类诈骗案件准确率仅有76%,而本文所述模型的准确率仍有94%.实验结果进一步表明虽然FastText 在上述实验中的表现优于本文所述模型,但是在实际使用过程中该算法并不能适应现场情况,存在运行结果不稳定的现象.
多种实验结果表明,本文采用的多重网络组合形式能够有效地对接处警文本进行案件分类.在实际工程部署中也得到了较为满意的效果.
4 结 语
本文利用改进的文本分类网络对词向量化后的警情文本进行警情类型分类.其中,模型网络针对较短文本进行了优化,减少了特征提取过程的历史信息冗余,弥补了单一模型对于文本分类准确率低的不足.实验分析可以看出,本文的分类模型在警情文本分类任务中取得了较好的效果.基于警情文本分类算法研发的系统实际应用于某市公安局110 接处警系统和警情分析研判系统中,为当地公安局对警情的分析和研判提供了可靠的数据支撑,对于警情串并案整理也起到了积极作用.
由于公安警情文本分类任务是专业领域的特殊需求,警情文本的描述规范在各个地区存在一定的差异,对于特殊的、复杂的警情类型判定还需要参考相应的法律法规等专业知识,因此对于警情文本分类模型的优化是一个持续的过程,后续工作会根据更多的警情类型丰富和优化本文模型.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
派出所工作(2017年9期)2017-05-30 10:48:04
派出所工作(2017年9期)2017-05-30 10:48:04
派出所工作(2017年9期)2017-05-30 10:48:04
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
