
基于混合神经网络的协同过滤推荐模型
2020-06-13 07:11:42鹿泽光
应用科学学报 2020年3期
马 鑫, 吴 云, 鹿泽光
1.贵州大学计算机科学与技术学院,贵阳550025
2.中科国鼎数据科学研究院,北京100089
随着“互联网+”时代的到来,物联网技术、5G 技术、无人驾驶技术等逐步兴起.这些新技术的发展使社会进入信息爆炸的时代[1-2].在互联网中,每天都会产生大量图像、文字、视频等各种各样的信息,如何有效地分析用户的行为反馈信息和项目的隐藏描述信息,为用户进行个性化推荐已经成为当下的研究热点[3-5].推荐系统在一定程度上解决了“信息过载”的问题[6].推荐系统中最具代表性的推荐算法就是近邻的协同过滤推荐算法[7].传统的近邻算法包含基于用户的协同过滤推荐算法和基于项目的协同过滤推荐算法,这两种算法都是利用用户-项目的评分数据进行相似度计算,找到用户的近邻集合或者项目的近邻集合,然后进行推荐[8-10].然而,基于用户的协同过滤推荐算法要求用户-项目评分数据具有较高的饱和度,才能产生更加准确的推荐结果.但用户不可能对所有产生行为的项目进行评分,所得到的用户-项目评分数据异常稀疏.因此如何有效解决数据稀疏性问题、提高推荐结果是本文研究的重点.
随着深度学习技术的飞速发展,其在计算机视觉、自然语言处理和语音识别等领域取得了巨大成功,这也为个性化推荐技术的研究提供了新机遇和挑战[11-13].其中最具代表性的卷积神经网络(convolutional neural network, CNN)是一种非线性前馈神经网络,其卷积层能更好计算深层次的隐藏特征.在个性化推荐中,卷积神经网络可以深层次挖掘用户和项目的隐藏特征[14-16].本文针对数据稀疏性问题,提出了基于卷积神经网络和降噪自编码(denoising auto-encoder, DAE)神经网络混合的神经网络评分预测模型(convolutional-denosing autoencoder collaborative filtering, CDAECF),该模型有效地结合了用户的显性反馈数据和隐性反馈数据,深入挖掘了用户的隐含特征向量.
1 相关技术介绍
协同过滤推荐算法可应用于各个领域,随着用户和项目数量的急剧增加,用户不会对所有产生行为的项目做出评价,只有极少数用户会对部分项目做评价[17-18],因此就会使用户-项目评分数据异常的稀疏.传统的基于用户协同过滤推荐技术借助用户-项目评分数据进行相似度的计算,找到相似用户邻居集进行推荐.如果用户-项目评分数据十分稀疏,将严重影响相似度计算的准确性,进而影响最终的推荐结果[19-20].
针对数据稀疏性问题,国内外研究者进行了大量的研究工作.文献[21]将关联规则思想与加权分析的方法相结合,提出了基于关联规则策略加权的Slope One 算法,从用户评分和项目特征两个角度对算法进行了改进.文献[22]认为基于Slope One算法的填充解决数据稀疏性问题的方法没有考虑用户相似度和项目相似度,填充结果过于单一,于是在此基础上融合了用户相似度和项目相似度权重函数.文献[23]提出了一种新型协同过滤推荐模型CDA-MF(卷积去噪自动编码器-矩阵分解),将卷积神经网络和降噪自编码神经网络结合起来并集成到矩阵分解算法中,挖掘上下文特征得到用户-项目预测评分,从而降低数据稀疏性.上述方法虽然在一定程度上可以解决数据稀疏性问题,但均未将用户的显性反馈数据和隐性反馈数据结合起来.
本文针对数据稀疏性问题,提出了融合卷积神经网络和降噪自编码神经网络混合的神经网络协同过滤推荐模型,能够有效地结合显性反馈数据和隐性反馈数据.首先通过卷积神经网络训练得到用户特征向量矩阵,然后结合用户-项目评分数据通过降噪自编码神经网络训练得到用户-项目的预测评分,从而解决数据稀疏性,提高推荐结果.
2 混合的神经网络评分预测模型设计
混合的神经网络协同过滤评分预测模型由卷积神经网络和降噪自编码神经网络组成.在该模型中,将通过卷积神经网络训练得到的用户特征向量矩阵作为降噪自编码的神经网络初始权重,然后将用户的评分数据作为输入,通过DAE 模型训练得到用户预测评分.混合神经网络评分预测模型总体模型结构如图1 所示.

图1 CDAE 模型结构图Figure 1 CDAECF model structure diagram
2.1 用户特征向量提取模型的设计
用户特征向量模型提取原理如图2 所示.
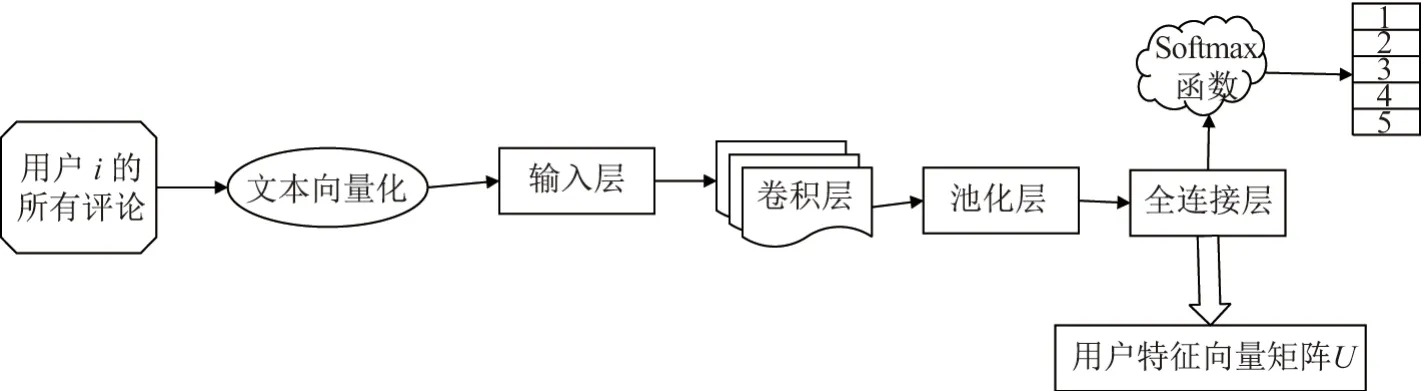
图2 基于卷积神经网络的用户特征向量提取模型Figure 2 User feature vector extraction model based on convolutional neural network
在图2 中,将用户Ui的所有评论合并起来经过文本向量化技术处理后得到的文本向量化矩阵作为卷积神经网络x值的输入,然后将Ui的所有评分值的均值作为卷积神经网络中y值的输入.
1)文本向量化
本文使用的文本向量化技术是Google 在2013 年提出的基于神经网络的word2vector 语言训练工具中的Skip-gram 模型[24].定义用户的数据形式为用户-评论-评分模式用R表示,即

式中,Ui为用户i,Cij为用户i对项目j的评论集合,Rij为用户i对项目j的评分集合,⊕表示用空格连接,整理式(1)得



2)输入层
本文将用户-项目评论数据表示成二维矩阵.用户Ui评论数据经过Skip-gram 模型训练得到的长度为w的一维文本向量化数据然后将纵向重复w次堆叠,得到大小为w×w二维词向量矩阵.
3)卷积层
假设卷积层一共有m个神经元,每个神经元t通过滑动卷积核Ft对输入的样本数据作卷积计算获得卷积后的特征图.假设卷积核窗口尺寸大小为l×h,即Ft ∈Rl×h,其中l表示词向量的长度,h表示词向量的维度.假设ei表示用户第i个特征图,如式(5)所示.

式中,* 表示卷积计算,bi为偏置向量,f为非线性的激活函数ReLU,即

每次滑动卷积窗口都会对局部进行卷积操作并以此获得局部特征值,这些特征组成了1 个一维特征组E为

假设共有G种不同的卷积核,每个卷积核对输入数据进行卷积计算都可以得到一幅特征图,这些特征图可以组成一个n×G的特征矩阵H,即

式中,G为卷积核数目,n为文本长度.
4)池化层
本文采用最大池化操作来保留特征图中的主要特征.假设Mt={m1,m2,··· ,mn}表示第t个卷积层卷积计算得到的特征图,那么采用最大池化层操作就是保留Mt中的最大值,则第t个卷积层的池化结果为
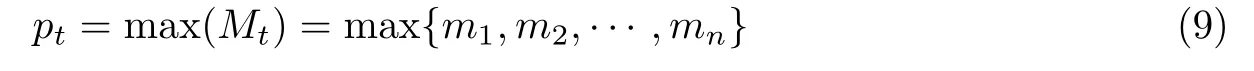
5)全连接层和输出层
假设全连接层的神经元数目为m,经过全连接层的非线性激活函数ReLU()激活后,得到1 个固定特征一维用户的隐含特征向量ui

式中,ui ∈Rm,pui为池化层的输出值,wui为全连接层的权重值,bui表示偏置量.
2.2 降噪自编码神经网络评分预测型的设计
假设输入层有n个神经元,输入数据是用户-项目评分矩阵中的每一行,隐藏层有h个神经元,输出层神经元数目与输入层神经元数目保持一致,其训练过程如图3 所示.

图3 降噪自编码神经网络训练过程Figure 3 Denoising auto-encode neural network training process
在该模型中,分别将用户-项目评分矩阵中的每一行作为输入数据,将用户特征向量矩阵U作为初始权重,从已经存在的评分数据中学习隐含规律.用户-项目的预测评分计算过程为
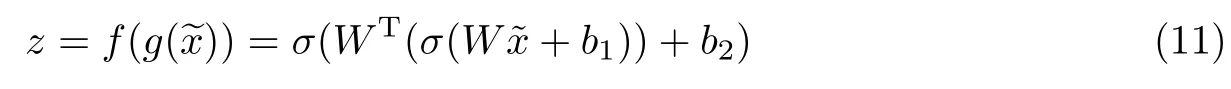

3 实验分析
3.1 实验数据集
本文使用的实验数据Movielens-1M 数据集[25]包含了6 040 个用户对3 900 多部电影的100 多万条评论,其中每个用户至少包含了20 条评分记录,评分数值范围为1~5.在本文的实验中,将实验数据集随机分成20%的测试集和80%的训练集.
3.2 实验评价标准
为了验证本文提出算法的有效性,使用F1 值作为评价标准.
1)准确率(Precision):推荐准确率是指推荐的项目中,用户喜欢的项目数与总的推荐项目数的比值.
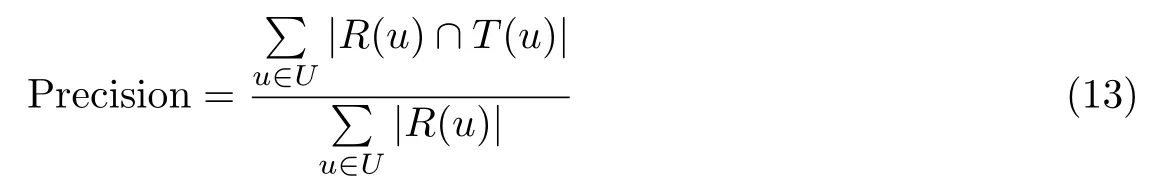
式中,R(u)表示根据用户u在训练集上行为给用户u推荐的项目的列表,T(u)表示用户u在测试集上的喜欢的项目列表
2)召回率(Recall):推荐系统的召回率表示推荐的项目中用户喜欢的项目数与用户所有喜欢的项目数之间的比值,召回率的计算过程为

3)F1 值(F1 score):是准确率和召回率的综合指标.其中,F1 取值越大,表明算法的性能越好.F1 值定义为
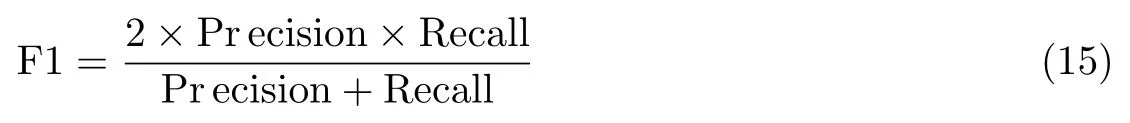
3.3 实验分析
从图4 可以看出,当迭代次数小于50 时,F1 值整体随卷积核数目G值的增大而缓慢增大.当迭代次数大于等于50 时,F1 值随卷积核数目增大先缓慢增加后逐渐下降,当迭代次数为50,卷积核数目为40 时F1 值最大,此时推荐效果最好.
实验1降噪自编码神经网络隐藏层神经元数目h对推荐结果的影响
实验2卷积核数目对F1 值的影响.
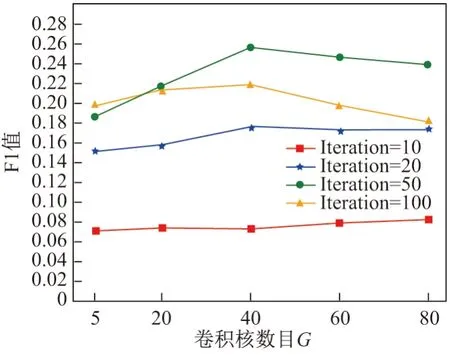
图4 卷积核数目对F1 值的影响Figure 4 Influence of the number of convolution kernels on F1 score
在图5 中,当迭代次数小于50 时,F1 值整体随隐藏层神经元数目增加而增加,此时推荐准确率不高.当迭代次数为100 时,F1 值整体比迭代次数为50 时低,提升速度变慢,最后下降.此种情况说明训练过程出现“过拟合”现象.当迭代次数为50 时,F1 值先增大后减小,当隐藏层神经元数目为60 时,F1 值最大,推荐效果最好.
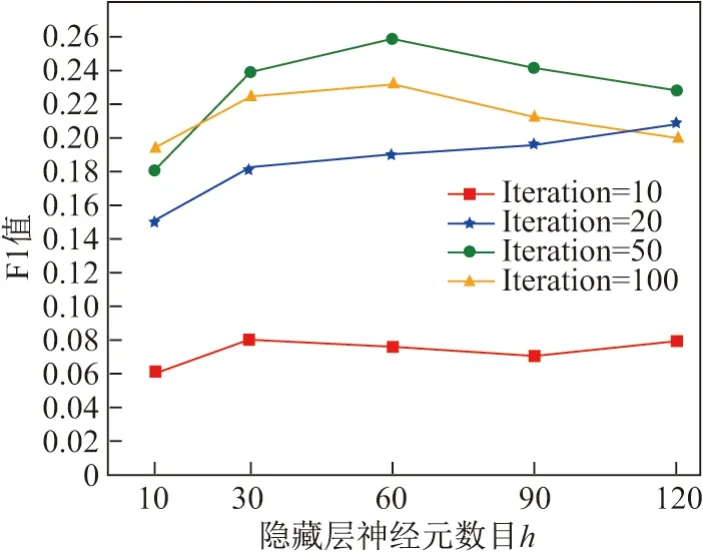
图5 DAE 中隐藏层神经元数目h 取值对F1 的影响Figure 5 Influence of the value of the number of hidden neurons h in DAE on F1 score
实验3降噪自编码神经网络的噪声比对推荐结果的影响
本文中噪声比是指在原始数据中加入噪声的数据与原始数据之间的比例,用4 种不同比例的噪音进行训练,其结果如图6 所示.
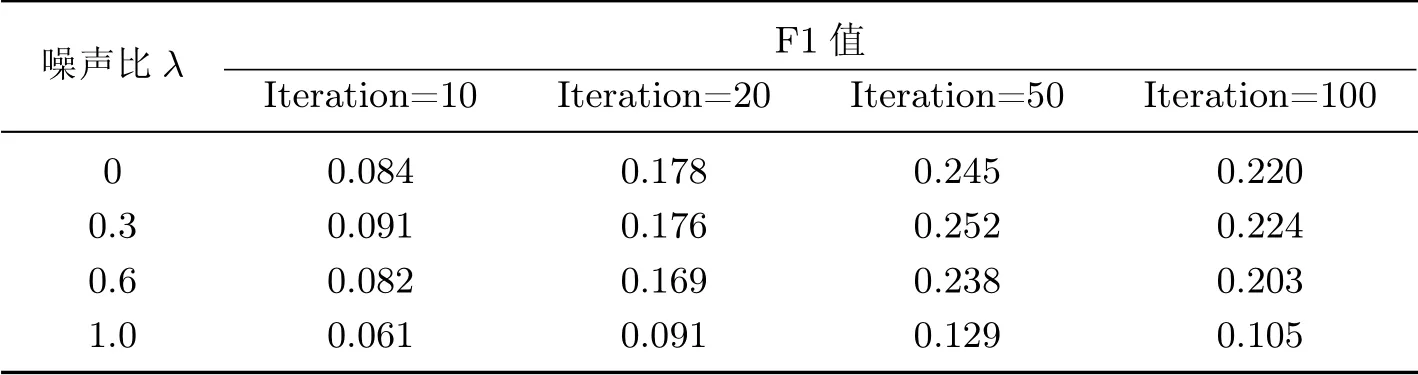
表1 不同噪声比对F1 值的影响Table 1 Effect of noise ratio on F1 score
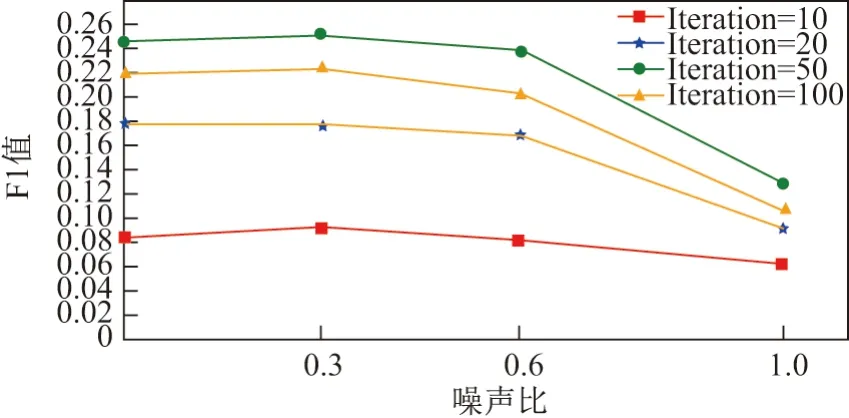
图6 噪声比对F1 值的影响Figure 6 Effect of noise ratio on F1 score
综合分析图6 和表1 可以看出,当没有加入噪声,迭代次数为50 时,F1 值最大.随着噪声比逐渐变大,不同迭代次数的F1 值均先升高后降低.当噪声比为0.3,迭代次数为50 时,F1值最大,此时推荐结果最好.
实验4不同推荐算法推荐结果的比较
为了验证本文提出的CDAECF 算法推荐结果具有更高的准确性,此次在相同的试验集条件下,与传统的协同过滤推荐算法(User-ItemCF)、单纯使用基于降噪的自编码器的推荐算法和基于奇异值分解的推荐算法(singular value decomposition, SVD )的F1 值进行对比,其结果如图7 所示.
从图7 分析可以看出,本文提出的CDAECF 算法的F1 值均高于另外3 种算法,说明本文提出的CDAECF 推荐算法推荐准确度明显高于另外3 种算法.从表2 分析可知,本文提出的CDAECF 模型准确率比DAE 算法的准确率高了将近6%.这表明本文利用卷积神经网络对用户-项目评论数据进行特征提取后,结合降噪自编码神经网络可以有效提高推荐准确率.本文提出CDACF 推荐算法和CDE 推荐算法性能高于User-ItemCF 算法和SVD 算法,说明基于深度学习的非线性学习模型与传统的线性学习模型相比更能深层次全面地挖掘用户-项目评分数据的隐含特征,从而提高推荐准确率.
4 结 语
在协同过滤推荐算法中,数据的稀疏性是影响推荐结果最重要的因素之一,针对数据稀疏性问题,本文提出了一种基于卷积神经网络和降噪自编码神经网络混合的评分预测模型.首先将用户的评论数据和向量化通过卷积神经网络训练得到用户特征向量矩阵U,然后分别将U作为降噪自编码神经网络的初始权重参数,最后将用户的评分数据作为输入数据,经过DAE 训练后得到用户-项目预测评分,从而解决数据稀疏性问题.与其他算法对比表明,本文提出的模型具有更好的推荐准确性,为后续的推荐算法的研究提供了参考.
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09 06:12:12
汉字汉语研究(2020年2期)2020-08-13 07:52:48
电子制作(2019年22期)2020-01-14 03:16:24
电子制作(2019年19期)2019-11-23 08:42:00
电子制作(2019年11期)2019-07-04 00:34:38
疯狂英语·新读写(2018年3期)2018-11-29 22:37:11
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
