
基于视觉关注模型与多尺度MSER的自然场景文本检测
2020-06-13 07:11:44王大千崔荣一金璟璇
应用科学学报 2020年3期
王大千, 崔荣一, 金璟璇
延边大学工学院,吉林延吉133002
在场景图像中通常包括较多的文本,这些文本信息具有比图像更丰富的语义信息,能够帮助理解场景内容.对场景图像中的文本进行检测是指在给定的图像中找出文本所在位置,并准确定位出文本区域即单词或文本行.文本检测技术在车牌定位、盲人辅助系统、图像搜索等领域有着广泛应用[1].虽然自然场景下的文本检测问题具有极大的研究价值,但自然场景本身具有很多复杂多变的因素,例如背景复杂、模糊、受到不同光照等情况;而且文字本身也具有多样性,例如不同颜色、大小、形状、方向以及不同语言混合的文本情况,这些都给文本检测增加了更多的技术难题.
目前,针对自然场景的文本检测技术主要分为3 类:基于滑动窗口的方法、基于连通域的方法以及深度学习的方法.基于滑动窗口的方法是指通过滑动窗口在文本图像上滑动,提取一系列如局部二值模式(local binary pattern, LBP)、方向梯度直方图(histogram of oriented gridients, HOG)等特征后再设计分类器,找到最有可能存在文本的区域.但滑动窗口的过程会带来很高的计算成本,从而影响检测效率;如果图像中存在不同大小的文本,则需要利用多尺度滑动窗口对图像进行处理,这进一步增加了计算的复杂度.基于连通域的方法是把文本看作是独立的字符区域,根据事先设计的颜色、边缘等特征形成大量的字符候选连通区域,再利用分类器得到最终结果[2].文献[3]提出利用最大稳定极值区域(maximally stable extremal region, MSER)方法来提取字符候选区域.MSER 方法具有较好的稳定性和仿射不变性.当阈值在一定范围内变化时,极值区域的面积不随阈值发生变化,并且能够提取到精细程度不同的区域,因此MSER 方法成为了传统的自然场景图像中文本区域检测领域使用最多的方法.目前许多研究者对MSER 方法进行了改进以提高文本区域检测的准确率.文献[4]提出将MSER和颜色聚类相融合并加入了图像的颜色信息,弥补了该方法只利用图像灰度信息的不足,提升了文本检测的准确性.文献[5]提出一种基于边缘增强的最大稳定极值区域EMSER 方法.该方法先采用Canny 算子提取图像边缘特征,然后对边缘提取后的图像采用MSER 进行连通域分析.MSER 的尺度在不同的阈值下检测精度几乎保持不变,但当图像模糊或者低对比度的情况下,其检测效果会下降.另外,改进MSER 算法大多从灰度值或连通区域模糊等问题入手,加入颜色特征或边缘约束来提高检测精度.文献[6]提出了适合文本特征的笔画宽度变换(stroke width transform,SWT),即通过计算笔画宽度值来提取字符区域,该过程不需要滑动窗口扫描,计算过程简洁、速度快且具有一定的鲁棒性.文献[7-10]通过添加文本位置和人脸的显著图来改进文献[11]的模型,实验结果发现:与背景相比,自然场景中的文本区域更能吸引人眼注意.在设计标志牌或广告牌时,设计者会最大程度地将宣传对象与背景区(树、天空等)分开.对此类图像进行特征提取时,考虑目标区域与背景区域的差异性特点,学者们会根据颜色或亮度等特征设计不同的特征提取方法[12].在图像的视觉特征中,形状特征相比于颜色和纹理特征也更方便地从语义上描述目标图像[13],因此可以把视觉关注机制应用在自然场景的文本区域检测中,以区分自然场景中的文本区域与非文本区域.
基于深度学习的文本检测方法主要对目标检测框架进行了改进,包括针对SSD(single shot multi box detector)框架的改进和针对Faster-RCNN(faster-region convolutional neural networks)框架的改进.SSD 可以对不同大小和比例的候选框的位置进行预测及回归,该方法提高了检测速度及精度.基于Faster-RCNN 框架的CTPN (connectionist text proposal network)方法固定了生成框的宽度以生成细粒度的候选框,并结合长短期记忆模型(longshort term memory, LSTM)模型进行预测,该方法利用序列的思想对目标检测网络进行了改进,得到了一个高精度的文本检测网络模型.文献[16]利用Edge box 和训练好的聚合通道特征(aggregate channel features, ACF)[18]检测器构成单词候选区域,再利用机器学习方法训练基于HOG 特征的随机森林分类器以去除大量误检情况,从而实现文本定位.
基于上述文献的思想,本文提出一种结合改进的Itti 视觉关注模型与多尺度MSER 的文本检测方法.首先,采用改进的Itti 模型生成7 个不同尺度的区域特征图,融合各尺度特征图得到文本区域显著图;其次,将得到的文本区域显著图与提取的相应尺度的MSER 区域相结合确定候选区域,根据文字与生成文本框的几何规则合并文本候选区域得到文本行;再次,利用随机森林分类器除掉非文本区域从而得到最终的文本区域;最后,在ICDAR2013 数据集与KAIST 数据集上验证了本文方法的有效性.
1 基本原理
1.1 Itti 视觉关注模型
作为视觉关注模型中最经典的模型,Itti 视觉关注模型是Itti 和Koch 等人在1998 年根据Treisman 的特征整合理论[19]及Koch 和Ullman 的显著图模型[20]提出的.Itti 视觉关注模型在不需要任何先验信息的情况下,可以根据视觉场景图像中的底层数据分析视觉刺激.其主要步骤如下:
步骤1采用线性滤波器提取图像颜色、亮度、方向3 个维度的初级视觉特征.颜色特征维度包含的4 个子特征通道R,G,B,Y,亮度特征维度仅包含1 个特征通道I,公式分别为

方向特征维度包含4 个子特征通道,即θ等于0◦、45◦、90◦、135◦时4 个方向的特征.利用Gabor 滤波器构建方向金字塔O(σ,θ),共3 个特征维度的9 个子特征通道[21],并在每个子特征通道内构建9 个不同尺度的特征高斯金字塔.
步骤2对于每个子特征通道中不同尺度的特征图像使用中央周边差操作Θ 提取特征图.计算公式为

式中,c为感受野中心信息尺度,且c ∈{2,3,4},s为感受野周边区域背景信息尺度,且s=c+δ(δ ∈{3,4}),I表示亮度特征图,RG 和BY 表示利用“颜色双对立”理论产生的颜色特征图,O表示方向特征图.7 个子特征通道中共产生42 幅中央周边差图(中央周边差图在该模型中被称为特征图).
步骤3采取特征合并策略将不同维度的多幅特征图进行归一化处理,合并形成一幅对应该特征的突起图,再将不同特征的突起图进行归一化处理得到视觉显著图.
步骤4最后根据得到的显著图定位关注焦点的区域,使注意力能够以显著性降序关注图像的不同区域[22].
1.2 MSER 算法
MSER 算法[23]最早是由Matas 等人在研究鲁棒性的宽基线立体重建时提出的,该算法借鉴了分水岭算法的思想,即在0∼255 范围内取不同阈值(水位高低代表图像像素的强度)逐渐淹没图像.随着水位的增高会形成盆地,并且在一段时间内会有相对稳定的形状,这些稳定的盆地就是MSER.
MSER 算法使用不同灰度阈值对图像进行二值化,区域面积即为二值化阈值变化上升时图像所达到的稳定区域.MSER 自身具有良好的稳定性、仿射不变性和多尺度检测等特点,可以作为字符区域的特征检测算子.对于文本与背景对比度较高的情况,文本内部结构稳定且灰度变化小,满足最大极值稳定区域的特征,因此MSER 可以有效检测出文本区域.
1.3 随机森林分类器
随机森林(random forest, RF)是一种基于Bagging 的集成学习方法,该算法首先随机且有放回地从原始训练数据集中抽取M个训练样本.其中随机抽取训练样本能使从森林里的每棵树中抽取的训练集不一致,保证了每棵树的分类结果不同;而有放回地抽取训练样本能确保每棵树的无偏性.对M个训练样本进行N次采样得到N个训练集和N个决策树模型,选取最优特征对数据集进行迭代训练,直到所在节点的训练样例都属于同一类;N棵决策树组成随机森林分类器,按照投票原则决定最终分类结果.
这种训练方式提升了分类器的训练速度,在训练过程中可以高度并行处理,相比其他强分类器,RF 分类器实现简单且泛化能力强,在特征维度较高的情况下也可以训练得到高效的模型,在文本特征提取及字符分类等方面可以取得很好的效果.
2 结合Itti 视觉关注模型与多尺度MSER 的文本检测算法
Itti 视觉关注模型利用显著性检测方法获取候选文本区域.MSER 算法是相对传统的与文本无关的候选文本生成方法.本文方法结合改进的Itti 和多尺度MSER 两种算法提取文本候选区域,并根据几何信息及连通域规则初步生成候选文本区域;然后根据候选文本区域的HOG 特征,利用随机森林分类器进行训练剔除部分背景区域,得到最终的文本区域.
2.1 文本候选区域提取
2.1.1 改进的Itti 视觉关注模型
自然场景中的文本信息在视觉上虽然具有较高的显著性,但不一定是Itti 模型所检测出的最显著的目标.针对自然场景中的文本检测,文献[24]提出了一种改进的Itti 模型[25],实验通过计算场景文本图像的不同特征图发现,强度特征图作为显著图时和文本区域相关,而颜色特征图与方向特征图对文本区域不敏感,并且会产生背景干扰,从而使最终得到的视觉显著图不适合文本区域检测.改进的Itti 模型只利用强度特征图作为最终视觉显著图.在生成的显著图中,文本区域是被凸显出来的,因此该方法对文本是非常敏感的,即所提取出的候选区域中很大一部分是文本区域,从而大大减少了文本候选区域的数量.
显著图反映了不同维度在图像不同位置上的显著性.重要目标可能在一个特征通道相应的图像区域引起了强烈的反应,而在另一特征通道中受较大的噪声影响而消失.因此,需要采用适当的策略对特征图进行合并,以突出不同特征维上的真实显著目标(即文本区域),有效抑制噪声.鉴于此,本文仅提取Itti 模型中的亮度特征通道并采用7 个尺度的高斯金字塔,代表中心信息的图像尺度c={1,2,3},代表周边背景信息的图像尺度s ∈{4,5,6}.高斯金字塔中大尺度图像包含更多的细节信息,而小尺度图像反映局部图像的背景信息,将两种尺度间作差能得到周边与目标间的反差信息[21].通过实验分析发现,在生成的6 张特征图中,I(3,7)所生成的特征图由于包含噪声较多不适合提取文字部分,所以本文方法仅提取亮度通道的5 个尺度对,得到I(1,4)、I(1,5)、I(2,5)、I(2,6)、I(3,6)5 幅文本特征图,如图1 所示.合并策略是每一相同中心尺度的特征图直接进行合并,即将c= 1,c= 2,c= 3 的特征图融合得到3 幅文本显著图,分别对应图2 中的(a)∼(c).由图(2)可以看出,结合特征图后所形成的显著图的文本区域特征明显增强.

图1 Itti 特征图Figure 1 Itti feature map

图2 文本显著图Figure 2 Text saliency map
2.1.2 多尺度MSER
在不同的自然场景图像甚至同一个自然场景图像中文本之间的尺度变化较大.虽然MSER 在一定程度上具有尺度不变性,但对同一个连通区域而言,不同尺度下连通区域内的灰度值变化存在一定的差异性,当图像模糊或低对比度时其检测性能将会下降.因此,本文采用了3 种不同尺度(Scale 分别取1.00, 0.50, 0.25)对原始图像进行缩放变换,得到3 种不同尺度下的MSER 区域分别表示为Im(1.00)、Im(0.50)及Im(0.25),检测结果如图3 所示.

图3 多尺度下的MSER 区域Figure 3 Multi-scale MSER Region
2.1.3 文本候选区域的生成
上述所提取的不同尺度下的文本显著图分别与对应尺度下的MSER 区域相结合,根据连通规则生成文本框,形成3 种文字候选区域图.在这3 种候选文本区域中,利用文字的先验信息即真实文字区域的大小及连通域高宽比等信息,设定在每一个连通区域中得到的文本框面积不得大于总面积的2/3,同一文本区域文本框面积大小相差0.1 以下取最大值映射到原图像.最后根据得到的几何信息在一定的范围区域进行约束,判定符合文本区域的文本框得到最终文本候选区域,结果如图4 所示.
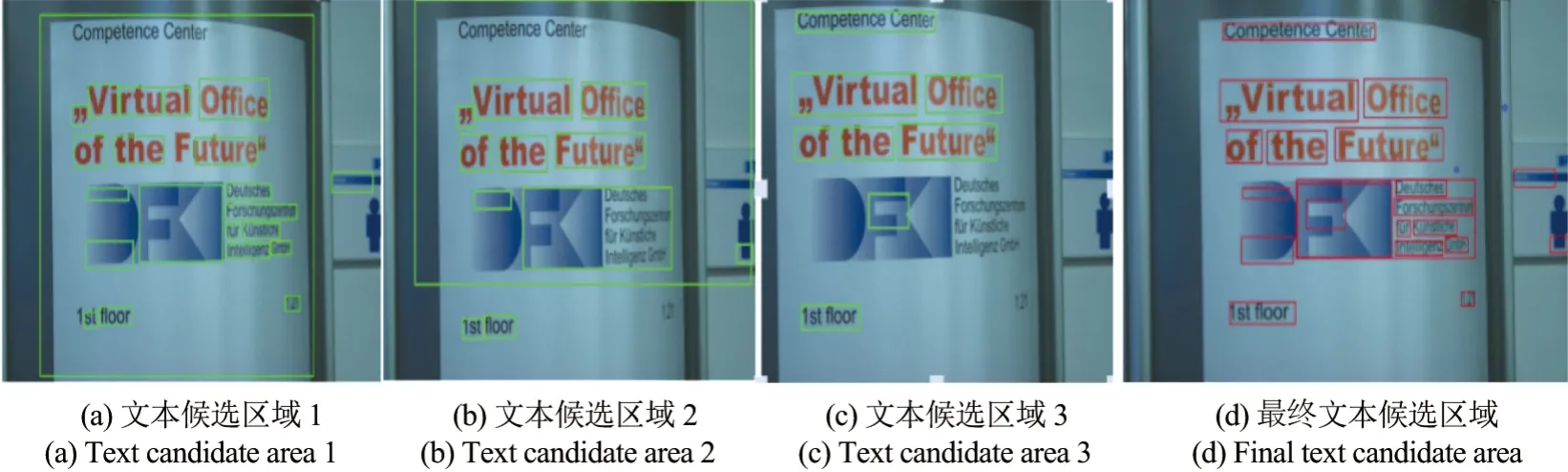
图4 文本候选区域图Figure 4 Text candidate area map
2.2 文本候选区域特征提取和分类
上述生成的文本候选区域中还包含大量的背景区域,因此需要提取HOG 特征并训练一个RF 分类器用来除掉无法利用几何信息剔除的非文本区域.提取HOG 特征时,首先将本文方法提取出来的不同大小的文本区域图片统一预处理为32×32 像素大小.每幅图片分为8×8 像素大小的cell,使用滑动窗口将每组2×2 个cell 组成一个block(可重叠),然后计算梯度值,每个单元格中将梯度方向分为9,统计9 个方向的梯度直方图,共生成324 维特征[25].
训练样本采用从KAIST 数据集中选取的762 幅图像,在本文方法提取的文本候选区域中人工标注文本区域与背景区域,包含2 842 个正样本和1 999 个负样本,训练分类器准确率为87.8%;从ICDAR 数据集中收集2 012 个正样本,1 108 个负样本,分类器准确率为91.2%.测试样本以同种方法提取特征,输入到随机森林分类器后再根据分类器的分类结果得到文本区域.最后将结果返回到原图像中生成最终的文本区域,如图5 所示.

图5 最终文本区域图Figure 5 Final text area map
3 实 验
在实验算法评价时选用ICDAR 2013 Robust Reading Competition以及KAIST Scene Text Database 中的图像库进行算法有效性验证.ICDAR 图像库中包含常见的自然场景文本图像,其中包括广告牌、杂志封面、标志牌、街景商店名等.KAIST 图像库中包含的是复杂场景图像,其中包括英语、韩语、数字等多语种混合,且存在阴影、光照强度变化,文字存在畸变、艺术字及文字非水平方向排列等情况.
实验评估方法采用国际会议ICDAR 提出的文本区域提取准确率p和召回率r来衡量算法的优劣,即

式中,E为算法提取出来的区域数量;T为图像中人工找出的文本区域数量;C为E、T的交集.为方便算法性能对比,给出其综合性能F值,公式为

式中,α为p、r的权重因子,用来设定这两个参数对文本提取效果的影响程度,一般取α=0.5.
表1 和2 将本文方法同其他方法的文本检测结果进行对比.可见本文方法在准确率、召回率及F值均优于其他几种方法.对比两种不同数据集中的性能指标可看出:在多语种文本的复杂场景条件下,本文方法的检测性能指标相较文献[26]有所提升,这说明了本文方法的有效性.
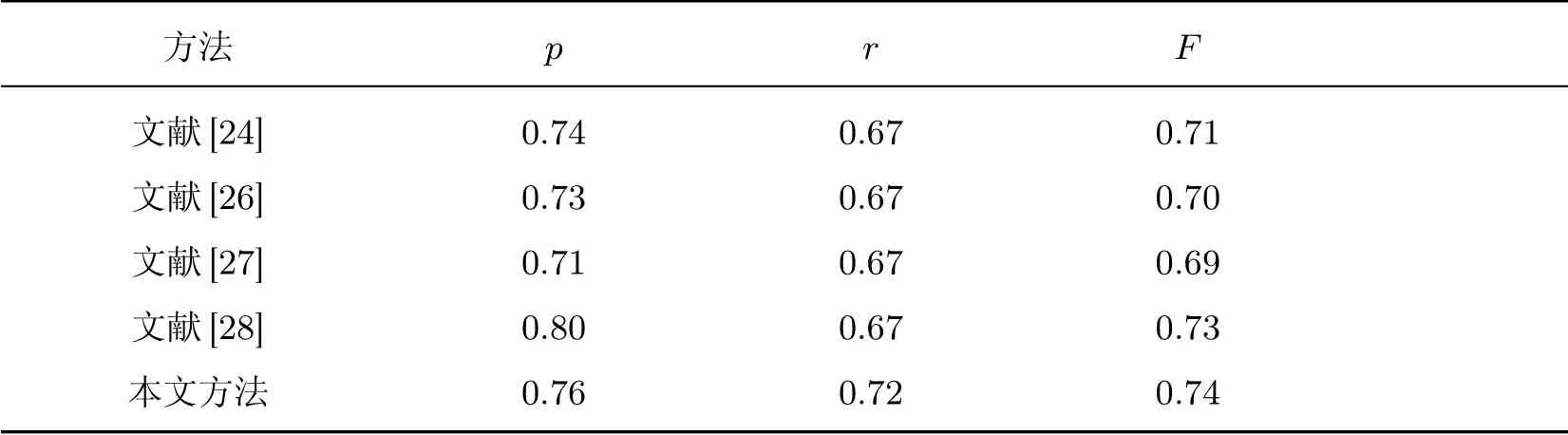
表1 ICDAR 数据集上不同算法进行文本区域检测结果比较Table 1 Comparison of text area detection results of different algorithms on ICDAR data set

表2 KAIST 数据集上不同算法进行文本区域检测结果比较Table 2 Comparison of text area detection results of different algorithms on KAIST data set
表3 与4 对比了单独使用MSER 进行场景文本检测与多尺度下的MSER 结合后进行的文本区域检测结果.表5 和6 对比了不同的结合方法的文本检测结果.单独使用改进的Itti 模型与边缘密集度的方法虽然可以提取出大多数文本区域,但背景区域也相对较多,而直接结合Itti 与MESR 的方法在文字大小多尺度变换时效果较差,会出现较多漏检区域.相比之下采用文本方法结合的策略,检测效果有很大提升.部分数据集实验结果如图6 所示.

表3 ICDAR 数据集上MSER 与多尺度MSER 文本区域检测结果对比Table 3 Comparison of text area detection results between MSER and multi-MSER on ICDAR data set

表4 KAIST 数据集上MSER 与多尺度MSER 文本区域检测结果对比Table 4 Comparison of text area detection results between MSER and multi-MSER on KAIST data set

表5 ICDAR 数据集上不同结合方法的文本区域检测结果对比Table 5 Comparison of text area detection results of different combination methods on ICDAR data set

表6 KAIST 数据集不同结合方法的文本区域检测结果对比Table 6 Comparison of text area detection results of different combination methods on KAIST data set

图6 本文方法部分检测结果Figure 6 Part of text detection results by the proposed method
4 结 语
本文提出了一种基于改进的Itti 视觉关注模型与多尺度MSER 结合的文本检测方法.该方法首先根据改进的Itti 视觉关注模型的不同结合策略生成文本显著图,再与多尺度的MSER 结合生成文本候选区域,然后根据文本框的几何规则滤除部分非文本行,最后使用随机森林分类器区分背景与文本得到最终文本检测结果.本算法将视觉关注机制应用到文本检测中,并与传统文本检测方法相结合,有效解决了自然场景下文本检测受背景复杂度、文字多尺度、多语言等因素影响较大的问题.本文算法在ICDAR 数据集及KAIST 数据集上分别进行了测试,并与不同方法进行了对比,实验结果显示其综合性能达到76%.由于本文方法属于基于连通域的方法,有其自身局限性,人工设置规则较多,还不能完全适用于复杂场景.如何在更复杂的场景中提高文本检测性能还需做进一步研究.
猜你喜欢
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
当代陕西(2019年10期)2019-06-03 10:12:04
电子测试(2018年1期)2018-04-18 11:52:35
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
太空探索(2016年5期)2016-07-12 15:17:55
时代英语·高三(2014年5期)2014-08-26 17:01:17
电测与仪表(2014年15期)2014-04-04 12:05:20
