
硬件加速CNN实时图像处理方法
2020-06-12 09:17王威廉康立富
计算机工程与设计 2020年6期
张 强,孙 静+,王威廉,康立富
(1.云南大学 信息学院,云南 昆明 650500;2.云南师范大学商学院 数据科学与工程学院,云南 昆明 651701)
0 引 言
一个完整的卷积神经网络(convolutional neural networks,CNN)包括输入层、隐藏层和输出层。隐藏层的每个神经元只与前一层的局部神经元相连,并提取该局部域的特征,其每一个计算层都由多个特征映射组成,每个特征映射是一个平面,平面上所有神经元的权值相等,输出层接收来自隐藏层的向量,可设计为输出物体的中心坐标、大小和分类[1]。在现有的可参考文献中,CNN图像处理大多是在PC端进行训练和测试,基于中央处理单元(central processing unit,CPU)的算法只能顺序执行,在处理大量数据的计算时,会带来明显的时间延迟,即使是高性能计算机也不能完全保证低延时的实时图像处理。
现场可编程门阵列(field programmable gate arrary,FPGA)具备并行结构,可同时高速并行处理数据,提高图像处理的实时性,广泛应用于边沿检测、灰度转换、阈值检测等实时图像处理算法中。基于CNN隐藏层参数可共享的特点,利用FPGA进行CNN实时图像处理的硬件加速,即可解决CNN对PC资源的高依赖、高延时等缺陷[2,3]。本文对CNN图像处理算法的并行执行能力进行了研究,采用Vivado高层次综合(high-level synthesis,HLS)实现了将训练好的CNN模型隐藏层参数共享,并用FPGA加速CNN实时图像处理。实验结果表明,本文提出的方法达到了预期目的,该方法识别国家标注技术研究所(mixed national institute of standards and technology,MNIST)库中10 000例手写体样本仅需8.69 s,而传统PC端识别相同样本的时间为30 s。此方法具有设计周期短、设计封装为IP(intellectual property,IP)核后,易跨平台移植等优势。
1 CNN算法设计
为便于CNN算法的硬件加速实现图像实时处理的目的,将CNN算法的隐藏层进行了自定义设计,包括两个卷积层、两个池化层及一个全连接层,三者在隐藏层中的执行顺序如图1所示[4]。

图1 CNN隐藏层流程
本方法设计的CNN一共有两个卷积层,目的是将局部特征提取出来,leraning-rate_param包含权重值与偏置值的学习率,前者决定分割平面的方向所在,后者决定竖直平面沿着垂直于直线方向移动的距离,二者共同决定训练出的特征值与真实值之间的差距;激活函数负责将上一层网络上的输入映射到输出端,提供下一层网络的输入向量。在卷积层之间、卷积层与全连接层之间都需要激活函数实现向量映射;在两个激活函数之后皆有分别对应的池化层,目的是对提取的特征值做一次滤波,简化网络计算复杂度,提取主要特征;全连接层在整个卷积神经网络中起到“分类器”的作用,将学到的“分布式特征表示”映射到样本标记空间,使得输出层能有更好的图像视觉效果。
整个实验过程中可以根据自己的需要调整CNN隐藏层参数,如图1花括号内英文变量所表示,根据识别效果的收敛性,反馈到卷积层与全连接层中,修改leraning-rate_param、weight_filler、bias_filler等参数来调整CNN的训练模型以达到更好的训练与识别效果[5]。
2 CNN算法实现
2.1 数据集准备
卷积神经网络框架Caffe(convolutional architecture for fast feature embedding)是一种常见的深度学习框架,主要应用在视频、图像处理方面的应用上。目前深度学习的框架大多运行在高性能计算机上,以达到更快的训练与识别速度,在PC端搭建和配置Caffe是训练CNN模型的基础,得到训练好的CNN模型caffemodel.h5即可进行硬件加速CNN实时图像处理[6]。
在Caffe框架下,可以直接运行MNIST数据库中手写体数字数据集的下载脚本get_mnist.sh即可得到如图2所示的4个压缩文件,且解压后皆是以向量与多维度矩阵文件格式存储的文件。

图2 MNIST手写体数据集压缩包
前两个压缩文件分别是CNN训练时使用的60 000例图像文件与对应的标签文件;后两个压缩文件分别是测试CNN模型caffemodel.h5时使用的10 000例图像文件与对应的标签文件,图像文件共由5个部分组成,见表1,标签文件由3个部分组成,见表2。

表1 数据集图像文件的组成

表2 数据集标签文件的组成
由于上述4个文件为二进制原始数据文件,不能在Caffe中直接使用,可以直接运行Caffe环境下自带的create_mnist.sh脚本文件,将原始数据制作成为Caffe可以识别的lmdb格式文件,即可在Caffe中直接使用。
2.2 多分类模型实现
Caffe环境下新建两个脚本,一个是训练用的CNN网络结构脚本two_conv_train.prototxt,另一个是训练用的CNN参数脚本two_conv_train_solver.prototxt,前者按照图1所示流程编写,后者主要设置训练次数、模型参数、最大迭代次数及模型输出参数等,具体参数设置参照表3[7]。
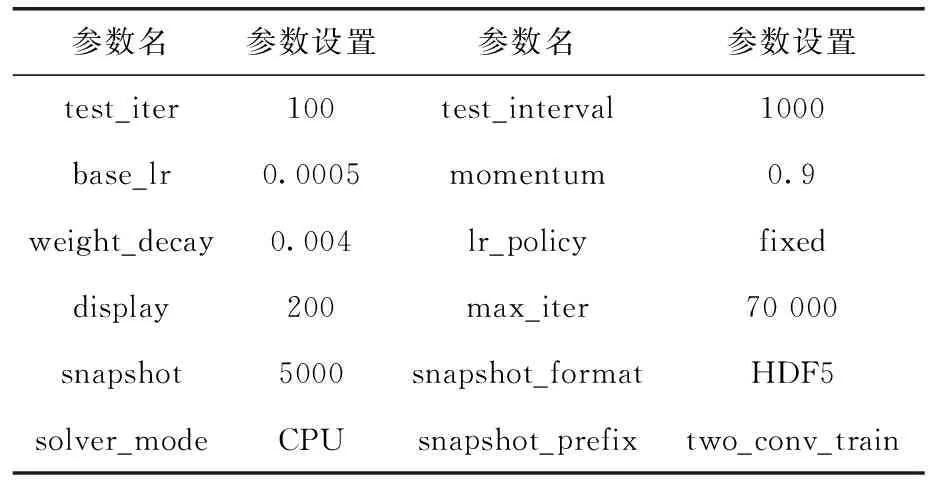
表3 CNN网络训练参数
设置完成后,可直接运行two_conv_train_ex_solver.prototxt脚本,经过多次调参并训练完成后,可得到two_conv_train_iter_70000.caffemodel.h5。在PC端利用Intel i7-8700 CPU测试训练好的CNN网络模型,可达到0.99的准确率,耗时30 s。如图3所示,此caffemodel.h5模型即为优化后的CNN模型文件,可以在硬件加速CNN实时图像处理中得以应用[8]。

图3 PC端CNN识别手写体结果
2.3 模型参数提取
根据上述得到的caffemodel.h5模型,编写提参脚本直接提取模型参数的权重值和偏置值,并与卷积核数保持对应一致,各卷积层与全连接层的权重值与偏置值的个数见表4。

表4 隐藏层内各子分类的权重值
将caffemodel.h5模型读取出的权重值和偏置值参数保存为conv1p.txt、conv2p.txt、FC.txt3个文档,分别对应卷积层1、卷积层2、全连接层的模型参数,在Vivado HLS中以C++语言读取模型参数的文本文档,供硬件加速CNN实时图像处理使用。
3 硬件加速实现
3.1 卷积层的硬件化
本方法设计的CNN网络具有两个卷积层、两个池化层、一个全连接层、两次激活函数,包含6个5*5的卷积核,所以在每一个卷积层内采用6个循环遍历卷积核行、卷积核列、图像通道、图像高度、图像宽度、卷积核的点,可用图4所示代码表示[9]。

图4 硬件化的CNN模型设计
每一层卷积层内一共使用了5个乘法器并行实现,在CNN的硬件加速中,将乘法器固化成硬件的核,以方便后续调用,每一个乘法器的核心代码如图5所示[10]。乘法器可固化为硬件核,本质上是将输入的数据直接以寄存器的方式赋值,从上至下使用了4个for循环进行矩阵的转换,且添加了两个#pragmaHLSPIPELINE一级流水的约束关键字,通过允许并发执行操作来减少函数或循环的启动间隔。整个卷积层使用6个for循环实现卷积核与图像的卷积运算,再使用5个乘法器核并行实现累加得到该卷积层的结果,并输出到激活函数[11]。

图5 基于Vivado HLS的乘法器原型设计
3.2 CNN的硬件加速实现
在Vivado HLS中用C++编写读取caffemodel.h5模型参数文档,用于输入图像在卷积层中的调用,从输入层导入MNIST手写体数据集之后,各层间的流程如图6所示。
将28*28大小的输入数据用卷积层1的参数进行卷积,并作为结构体c1输出;将结构体c1的输入向量经过Relu函数处理,得到大于0的数据再通过池化层1处理得到结构体s2。
同理再一次将结构体s2输入到第二层卷积层卷积、激活函数Relu处理及池化层2处理,得到的结果数据保存为结构体s4;将s4输入到全连接层进行全局变量提取,再经过输出层处理即可得到识别出的手写体数字[12]。

图6 硬件加速CNN的模型设计
3.3 基于Vivado HLS测试CNN的硬件加速
硬件加速CNN的TestBench文件的编写,遵从Vivado HLS格式规范,按照如图7所示的流程进行编写。
图7中,输入层的数据集是来自MNIST的手写体测试数据集,分别是t10k-images-idx3-ubyte与t10k-label-idx1-ubyte两个二进制数据文件,读取的数据集参数即可直接进入硬件加速CNN算法中运算[13]。测试数据集在硬件加速CNN算法中的运算,是将卷积层的各个卷积核利用FPGA并行实现的方式,在相同时钟周期到来时,全部卷积核同时与测试数据集参数执行完卷积运算,得到的卷积结果也可以在相同时钟周期内完成激活函数、池化层的运算,进而在下一个时钟周期来临时,可继续进行再一次的卷积、激活函数、池化的循环运算,直到输出结果并结束运算。将经FPGA并行实现CNN图像处理得到的输出结果进行标签判断,将正确的识别结果与错误的识别结果及数量输出,完成整个硬件加速CNN的图像处理。

图7 硬件加速CNN仿真文件编写流程
4 实验结果与分析
在Vivado HLS中编译C++编写的硬件加速CNN图像处理的算法,可以直接转换成RTL级硬件电路,同时封装为可以在Vivado中直接调用的Verilog IP核,方便日后硬件加速CNN图像处理算法移植到高性能处理平台Zynq片上系统(system on chip,SOC)中。
4.1 结 果
在Vivado HLS中利用C++语言编写硬件加速CNN图像处理算法,通过运行硬件加速CNN算法识别MNIST数据库中的手写体数字,得出如图8所示的结果,同时Vivado HLS串口打印出实现本方法的时间消耗见表5,FPGA模块资源消耗见表6。
从识别结果中可以看出,标签数一共有7种,识别正确的也是7种,错误识别的标签是0个,与CNN在PC端的测试准确率0.99基本吻合,可见本方法在识别效果上与PC端的效果几乎一致。
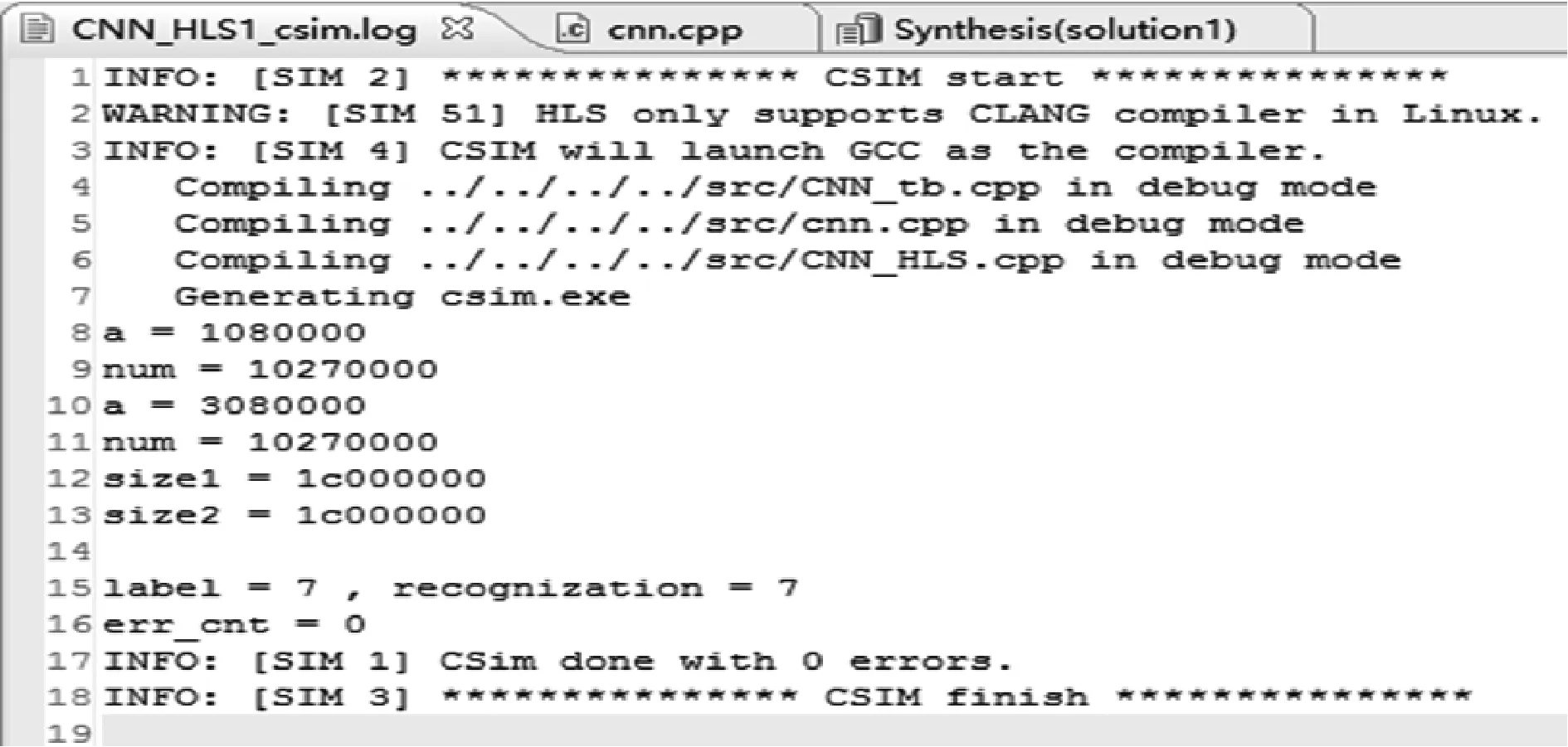
图8 硬件加速CNN识别手写体数字结果
4.2 结果分析
从本方法识别MNIST数据库中10 000例手写体数据样本所消耗的时间来看,PC端利用Intel i7-8700 CPU测试训练好的网络耗时30 s,本次实验结果产生的8.69 s耗时降低了77.7%的时长,单例样本的识别时长为0.87 ms,低于人眼舒适放松时长1/24 s[14]。此外,表6所示块状RAM和FF模块占用率达到20%左右,数字信号处理器模块、显示查找表占用率达到了67%左右,而本方法在Vivado HLS中选择的芯片是Zynq 7020,所以均在Zynq 7020可编程逻辑(progarmmable logic,PL)承受范围内,较好的实现了硬件加速CNN实时图像处理。

表5 硬件加速CNN图像处理所消耗的时间
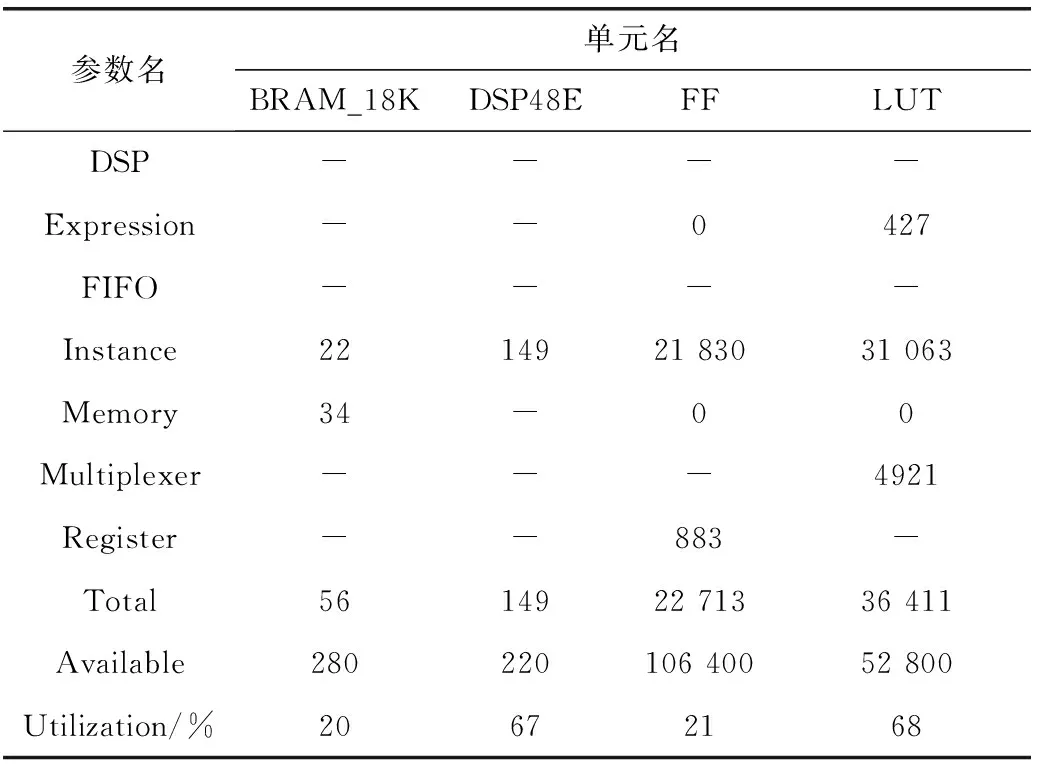
表6 硬件加速CNN图像处理的各模块资源消耗情况
5 结束语
本方法实现了CNN图像处理的硬件加速,8.69 s的耗时、Zynq 7020芯片硬件模块占用率在20%至68%之间,相比PC端30 s的时间消耗、PC端资源的高依赖,硬件加速CNN图像处理具有高实时性、低成本的优点。同时将硬件加速CNN图像处理的C++程序封装打包为Verilog IP,方便以后移植到Zynq SOC中去,应用到更多的领域。
本文在Vivado HLS中,设计实现了硬件加速CNN图像处理,通过测试验证得到与PC端相似的识别效果,弥补了CNN图像处理对PC资源高依赖、高延时的缺陷,为CNN图像处理的硬件加速推广应用提供了可参考的方法。
猜你喜欢
现代临床医学(2022年2期)2022-04-19
科技创新与应用(2021年23期)2021-08-30
无线互联科技(2020年15期)2020-11-10
科技传播(2020年6期)2020-05-25
科技风(2020年3期)2020-02-24
中国篆刻(2019年6期)2019-12-08
制造技术与机床(2018年12期)2018-12-23
电子制作(2018年18期)2018-11-14
雷达科学与技术(2018年3期)2018-07-18
电脑知识与技术(2017年3期)2017-03-27
