
基于系统调用的智能终端恶意软件检测框架
2020-06-12 09:17陈怡西景小荣
计算机工程与设计 2020年6期
王 宁,王 丹,陈怡西,景小荣,2
(1.重庆邮电大学 通信与信息工程学院,重庆 400065;2.重庆邮电大学 移动通信技术重庆市重点实验室,重庆 400065)
0 引 言
Android智能终端在市场中占有率高[1]主要有以下几个因素:Android智能终端的开源性,生产商可以根据需求定制不同的系统,用户同样能编写自己喜欢的应用软件;硬件兼容性高,跨平台特性强,Android生产商不断推出各种设备来吸引顾客,比如平板、电视等,而且上层应用也可以向多种产品移植,用户体验丰富,性价比高。相比与其它操作系统的智能终端,在同样的价格下,Android智能终端具有绝对的性价比优势,应用丰富且开发门槛低。
然而智能终端产品质量问题被频频报道,特别是Android平台下的一些恶意应用给用户造成很多难以弥补的损失。这些恶意应用分为病毒类、木马类、后门类、僵尸类等多种类型,它们在使用者未授权的情况下执行违法行为,进而造成数据和信息泄露,财产损失等问题,极大地影响了消费者对智能终端产品的信心。根据调研,由于Android产品软件和硬件的各种质量问题,用户流失比例较高,严重制约了该产业的发展[2]。
1 相关工作
针对上述问题,学术界和产业界的研究者越来越重视Android的安全研究。安全软件商如360公司、腾讯公司等,以监控权限的使用、维护服务器建立恶意软件库等为切入点,来保护设备的安全,但这些方法都有着明显的不足:一方面,对于多数使用者来讲,它们没有足够专业的知识对当前软件的安全进行判断;另一方面,搭建恶意软件数据库这一方法已经很难对未知家族的恶意软件或已知家族恶意软件的变种进行检测。华为应用市场审核应用时,则采用人工与机器相结合的方法确保应用的安全,但是Android恶意软件一直层出不穷,没有妥善地解决该问题。学术界则把恶意软件检测技术主要分为软件代码的静态检测和运行时的动态检测两种。
静态检测技术的主要思想在于扫描软件的源程序或者二进制代码,通过直接分析被检测程序的特征,进而查询程序的异常状态。Wei W等[3]则通过计算单个权限(Permission)和恶意软件之间的关联度,分别从3方面系统地分析了以Permission为判断规则的有效性和局限性。Daniel A等[4]收集了大量安装包中的可获得信息(如请求的Permission、应用组件等),反编译后的信息(如API调用、网络地址等),并通过支持向量机(support vector machine,SVM)分类软件,然而此方法只在单个应用程序上性能较优。Manzhi Y等[5]对APK文件反编译后,将文件各个部分映射成图像,依据其产生的不同视觉特征,通过机器学习进行恶意代码分类。目前己形成的静态分析工具有androguard等。
然而,静态检测中无法对混淆代码、加壳代码进行分析,动态检测技术则弥补了此缺陷,该技术是通过实时追踪软件在模拟器中运行时的行为特征,然后对其进行处理的过程。在所有动态检测工作中最为著名的是Enck W等[6]提出的污点标记追踪技术,在该方法中,当软件的目标代码在Dalvik虚拟机中运行时,标记相关污点数据,进而对敏感数据的流向进行跟踪。但本地代码中的隐私泄露问题无法得到解决。Tam K等[7]提出了一款名为CopperDroid的框架,将应用软件放置在沙盒测试环境中,一边与外部系统交互,一边利用操作系统中的系统调用(system call,SC)等信息,以达到还原应用行为的目的,缺点是该框架只适用于离线分析。Stephan H等[8]综合了API监控、内核系统调用监控、污点标记追踪等动态分析方式,通过多种技术以触发应用行为,从而在隐私泄露等方面的分析中取得了较好的效果,但是它对于计算资源和电量并不充裕的移动设备来说是不小的开销。Mayank J等[9]提出了以系统调用为分析对象的动态检测系统,并分析了良性和恶意软件系统调用之间的相似性和差异性,该系统使检测恶意应用程序的资源消耗更小,但是没有考虑系统调用之间的关联性。Xi X等[10]提出了一种基于系统调用序列的马尔可夫链反向传播神经网络,该方法把一个系统调用序列看作一个齐次平稳的马尔可夫矩阵,通过应用反向传播神经网络,比较矩阵中的转移概率来检测恶意软件,但复杂度较高。因此,动态检测时间较长,实时性不高,效率低,系统资源消耗较多。文献[11]则提出一种基于系统调用频率的新型恶意软件检测方法,但此方法并未考虑系统调用之间的相关性和整体性。相较之下,文献[12]提出的自动分类框架将系统调用之间的相关性考虑在内,但该框架容易导致过拟合。目前已形成的动态分析工具有Droidbox等。
通过上述对恶意软件的检测研究现状的分析发现,静态检测和动态检测均存在着大量亟待解决的问题,动态检测技术能由于能够实现对加密恶意软件进行分析,因此,更具研究价值。但是,目前基于动态检测的恶意软件检测方案存在检测准确率低等问题;其次,Android的恶意软件检测技术一般基于特征提取,而提取的特征种类和维度对检测效率起着决定性的作用。考虑到这些因素,本文通过对智能终端中的恶意软件样本进行动态分析,提出了一种基于系统调用的恶意软件动态检测框架。该恶意检测框架不但能丰富这一研究领域,而且根据仿真结果,显示其具有很强的实用性。
2 基于系统调用序列的动态检测框架
2.1 恶意软件动态检测框架描述
基于以上分析与研究,本文提出的基于系统调用序列的恶意软件动态检测框架,如图1所示。该框架的内容主要分为3个阶段:第一阶段为特征提取:搭建沙盒测试环境,自动化安装待检测样本,模拟和激发待测样本的动态行为,同时使用检测工具记录动态行为的日志,进而提取出待测样本信息;第二阶段为特征预处理:将动态行为的日志信息进行预处理,该阶段包括数据降维,特征标签化处理和去冗余3个步骤;第三阶段为机器学习分类处理:在学习前构建系统调用的马尔可夫矩阵,并将结果转化为SVM能够识别的格式,进而将训练集输入进行有效实验,得出训练好的分类模型用于判断。最后对恶意样本和正常样本的混合测试集进行检测,得出检测结果。
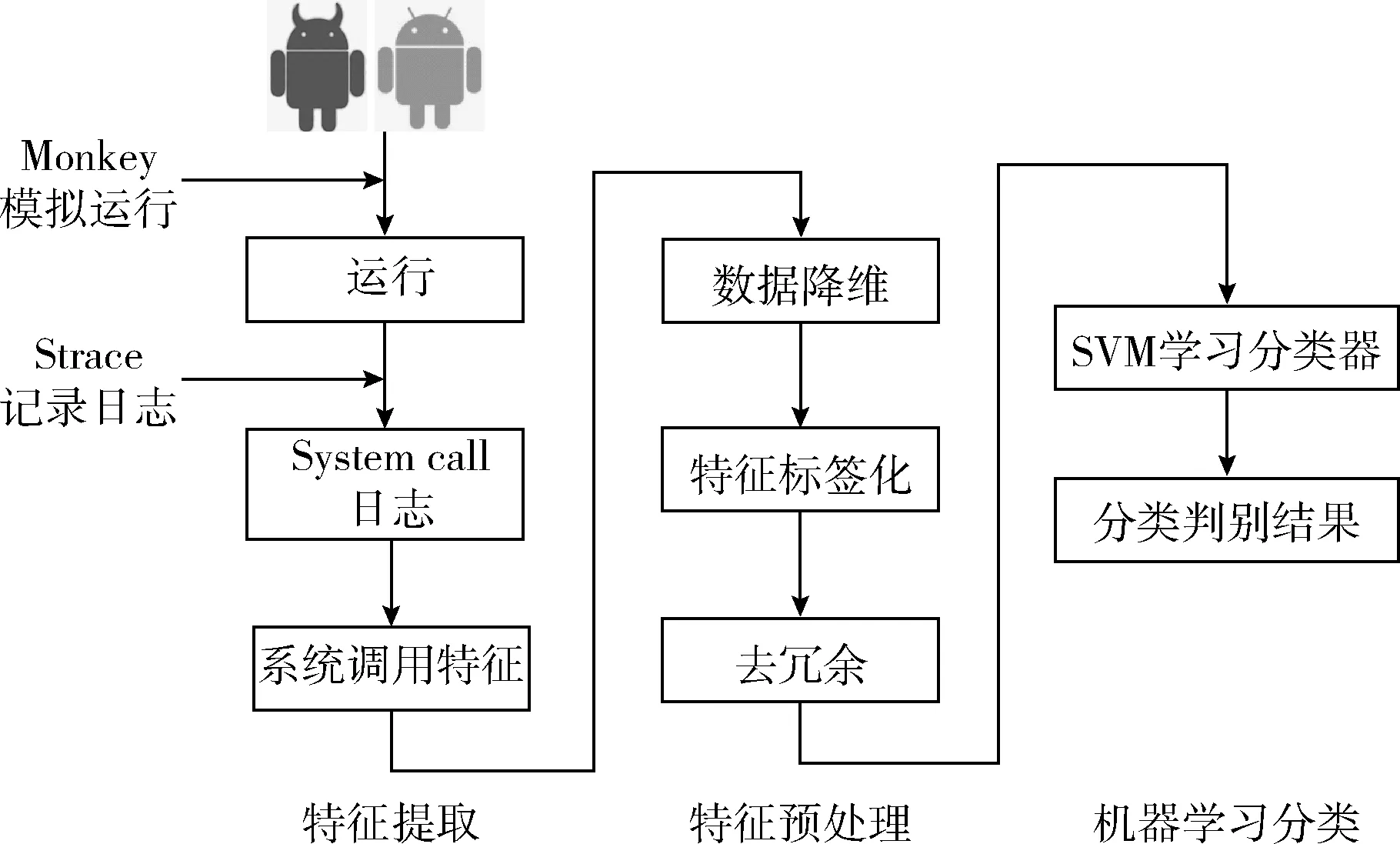
图1 动态检测框架
2.2 动态特征提取
在恶意软件的动态检测框架中,如何提取特征是整个流程的重点工作。本文通过监控并记录系统调用完成特征提取,原因有二。其一,Android操作系统采用了分层的架构形式,其底层为Linux内核层,系统调用是Android系统与软件之间交互的底层接口,能够充分反映应用程序执行过程中的行为;其二,某些系统调用在恶意软件和正常软件的使用频率和使用规则中存在明显差异,例如,名为read的系统调用在样本中的概率转移特性和调用频率与在正常软件中明显不同时,那么这一样本是恶意样本的可能性就越高。
其具体步骤如下:首先获取模拟器或者Android设备的超级管理员(Root)权限,下载并安装超级管理员软件(Android debug bridge device,ADBD)并开启超级管理员模式,否则设备在启动系统用户空间跟踪器(Strace)命令时会警告并提示未获得权限(permission not allowed);其次获取待测样本的进程身份编号(personal ID,PID),进而利用Strace命令提取系统调用的动态特征,如果设备中没有Strace命令,则需要使用调试工具(Android debug bridge,ADB)命令将相应版本的Strace可执行文件放置于设备系统程序集缓存(bin)下,若有权限问题,则进行重新挂载,并使用命令增加工具的可执行权限即可;然后利用模拟人工操作工具(Monkey)在样本软件上模拟人工操作,等待程序自动运行一段时间后,杀死进程,此处需要保证每个待测样本运行时间一致;最后将样本日志文件以文本(TXT)格式记录保存后,去除掉乱码部分,同时把系统调用的参数部分全部去除,进而得到按时间顺序输出的系统调用序列。上述过程的流程如图2所示。在实验实施过程中使用了多个调试监控工具,表1对这些工具进行了汇总。
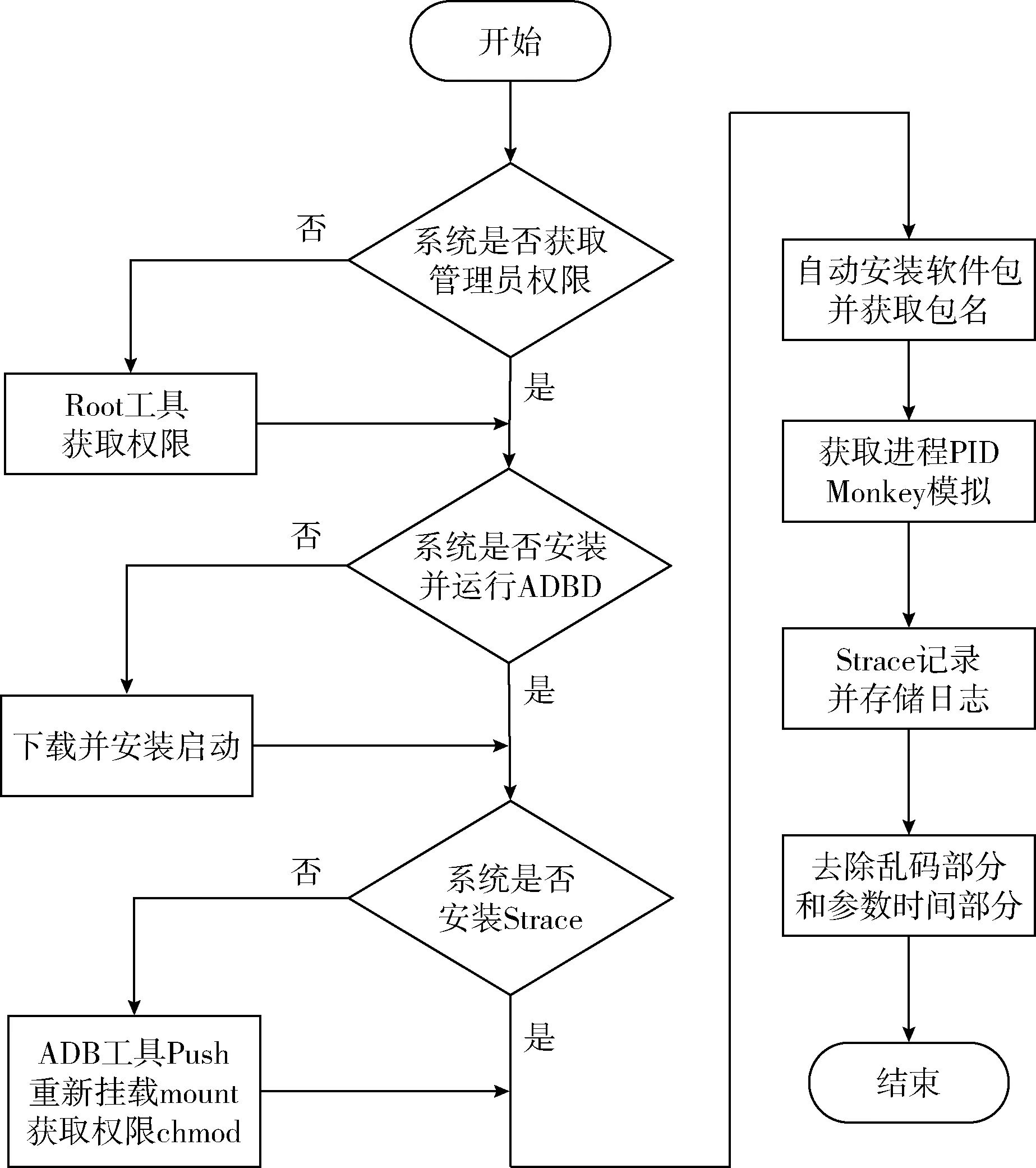
图2 特征提取流程

表1 工具汇总
2.3 特征预处理
特征预处理阶段的目的是小幅度降低检测率的同时大幅度降低检测复杂度,该阶段主要包含数据降维、特征标签化和去冗余3个步骤。在数据降维和去冗余时需要选取合适的阈值,本章后续章节将具体介绍,下面将详细描述特征预处理过程。
2.3.1 数据降维
恶意软件检测一般基于特征提取,而提取的特征种类和维度起着决定性的作用,特征维度过多会导致检测时间过长,特征提取少又会导致检测准确率下降。目前,研究人员通常以牺牲效率为代价,提取出多维度特征,换取检测准确率的提升,如何对多维度特征筛选和降维并达到同等检测准确率是一大难点。
本文实验中的操作系统包含196个系统调用,由于后期需要针对系统调用构建马尔可夫矩阵,如果不降维处理维度将高达196的平方。信息增益(information gain,IG)法是在决策树算法中用来选择特征的方法,它能够很好地衡量特征为分类系统带来信息量的多少,因此本文采用信息增益法对系统调用按照不同重要程度进行量化评分,并按评分高低对系统调用进行分类处理。定义待分类系统调用集合C的熵H(C)与某系统调用T的条件熵H(C|T)之差为系统调用T给系统带来的信息增益IG(T),即
IG(T)=H(C)-H(C|T)
(1)
其中
(2)
(3)

(4)
(5)
将式(2),式(3),式(4)和式(5)带入式(1),则
(6)
根据IG方法,得到全部系统调用的评分见表2,IG(T)越大,特征T对分类结果越重要。然后根据评分选择合适的阈值(阈值的选择在下一节我们将通过数值仿真给出),将196个系统调用分为“重要”和“无用”两个部分,将“重要”部分作为主要特征。例如,表2中flock的评分高于rename,那么flock这一系统调用在恶意软件和正常软件之间差异较大,比rename更适合作为评价指标,即更“重要”。但“无用”部分也会对检测带来影响,由于系统调用数量较多,对于“无用”部分,属于同一类别的系统调用合并为一类,本文将其按照属性不同划分为文件类,进程类,网络管理类,内存类,系统类,进程通信类和用户管理类7个类型,实现数据降维。

表2 工具汇总系统调用评分(部分)
2.3.2 特征标签化
特征标签化处理是为了使数据能够被机器学习处理。首先,将降维后的系统调用映射为标签值,一个标签代表一个向量维度,映射函数表达式如下
Label=QSC
(7)
其中,Q表示从系统调用到标签值的映射函数,Label为输出的标签值,一个Label代表一个维度,SC表示系统调用。在该映射函数中,“重要”部分的系统调用与标签值一一映射,而对于“无用”部分,属于同一类别的系统调用映射为同一个标签值,实现多对一映射,并将所得系统调用与标签值之间的映射关系存储到数据库。
其次,样本根据数据库中的映射关系,将按时间顺序输出的系统调用映射成Label依次输出,从而得到标签化的系统调用序列,如图3所示。

图3 标签化的系统调用序列
2.3.3 去冗余
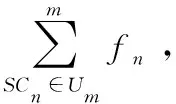
针对以上问题,本文提出了改进的TF-IDF算法和N-gram平滑算法相结合的方案对软件中的冗余信息进行去除。在该方案中,首先使用N-gram算法,将文本划分为多个子序列,然后用改进的TF-IDF算法评价子序列,选择合适的阈值去除评分低的子序列,将评分高的子序列重新连接即可。具体内容如下:
首先对图3所示的序列进行N-gram处理,根据文献[13],N取值为3时性能较优,具体方法示例如图4所示,Si表示系统调用,每3个相邻的系统调用构成一个子序列,每次平滑一个单位,获取下一个子序列,直至遍历完样本,并将N-gram得到子序列的顺序与出现的次数保存在数据库中待用。
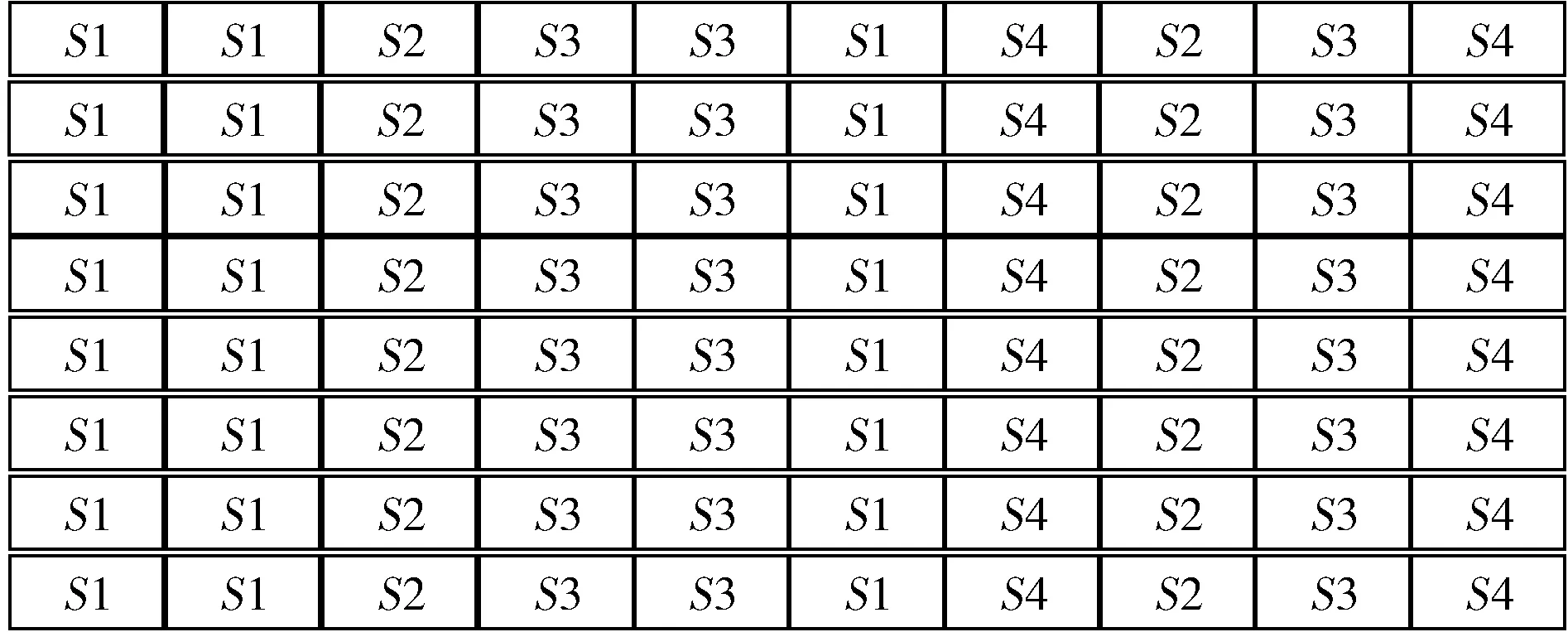
图4 标签化的系统调用序列
传统的TF-IDF算法用以评估一个词对于一个文件的重要程度。本文采用改进的TF-IDF算法对N-gram算法得到的子序列进行量化评分,以评估子序列对样本库的重要程度。TF是某个子序列出现的频率,即某个子序列在样本库中的频率,其计算公式如下
(8)
其中,TFj为子序列tj在样本库中出现的频率;nj为子序列tj在样本库中出现的次数。IDF,即“反文档频率”,其计算公式如下
(9)
其中,IDFj表示子序列tj的反文档频率;|D|表示样本库中的样本总数;|i:tj∈di|表示出现子序列tj的日志总数;tj∈di表示子序列tj在动态行为日志di中出现;+1是防止分母为0。最后子序列tj的评分为:TFj*IDFj。
最后根据评分从大到小选取合适的阈值(阈值的选择在下一节我们将通过数值仿真给出),去除评分小的冗余信息,仅保留评分大的“重要数据”,并对这些子序列重新进行合并,某一样本合并流程的伪代码见表3,在程序执行过程中由于Index的值不同而会影响子序列的连接方式,因此在设置子序列的连接方式中,样本首尾的两个系统调用会直接保存,不做去冗余处理,从而得到去冗余后的系统调用序列。相比于将标签化后的系统调用序列直接分类处理,去冗余能够在一定幅度上提高检测结果。

表3 子序列连接方式
2.4 机器学习分类
通常情况下,在SVM中,用样本点与超平面之间的距离来表示分类的准确率。最大化该距离的平均值则是SVM的目的。如图5所示,黑点和白点分别代表不同类别的样本,通过两条虚线之间的超平面以完成分类,但仅仅实线部分所表示的超平面能够取得最大的区分间隔,使分类器达到最优的分类目的,即实线代表的超平面为决策最优超平面。SVM的边界为两条虚线上的3个样本,它们是找寻最优分类超平面的重要依据,被称为支持向量。本文中Android恶意软件的检测判别是一个二分类问题,而SVM正是一种特殊的二类分类模型,并且该模型在解决样本量较小以及高维度识别问题方面具有优势,因此适用于软件检测领域。
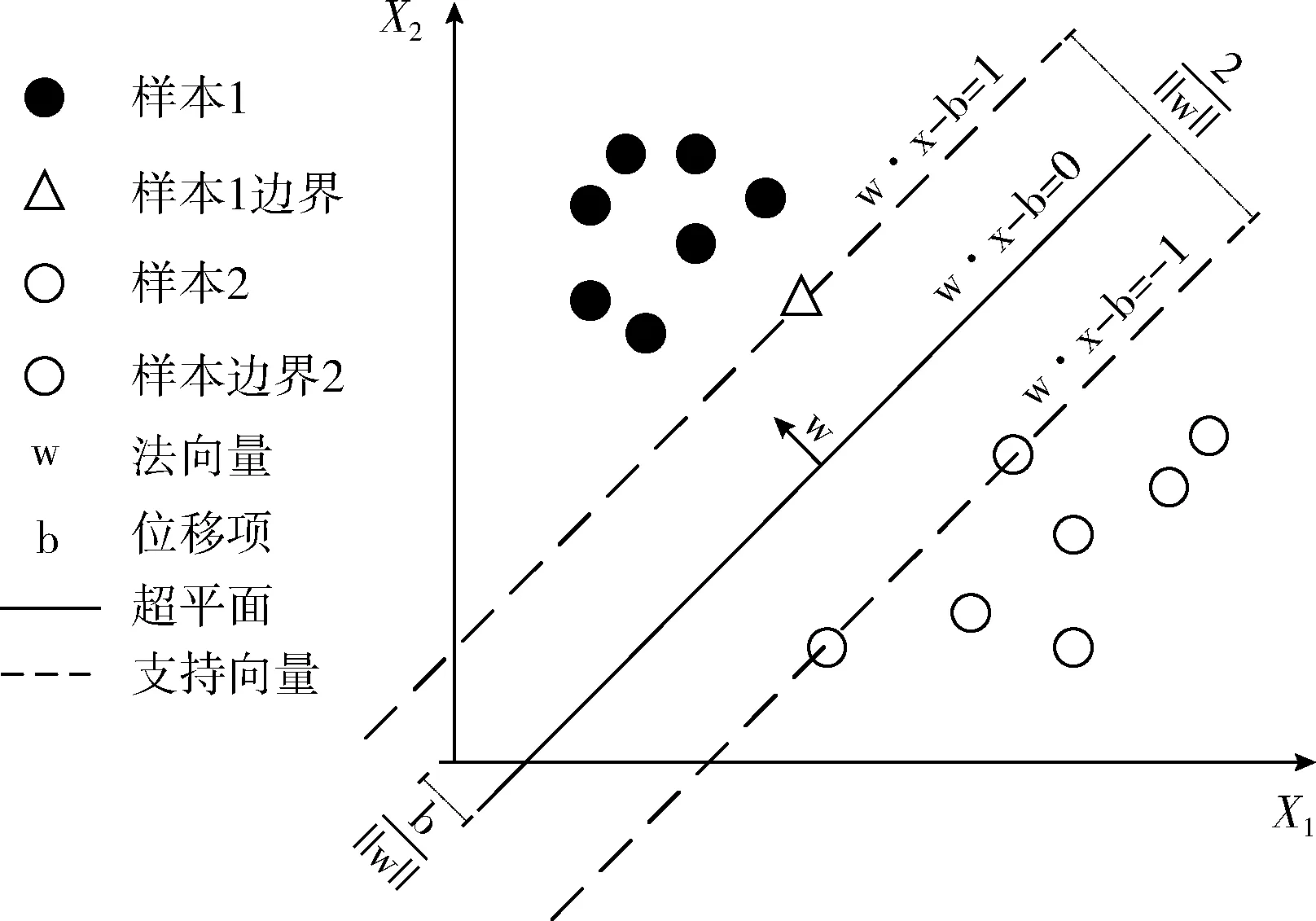
图5 SVM原理
由于直接训练样本会导致复杂度过高,每个应用程序的系统调用序列都可表示为一个离散的马尔可夫矩阵,因此在训练测试样本之前首先构建马尔可夫矩阵以最大程度地还原系统调用序列的原始结构。假设预处理阶段得到M个标签值,在标签化后的系统调用序列中,则每个样本中的系统调用之间的概率转移关系可以用一个M*M的矩阵表示为
(10)
其中,pl,q是指样本调用标签l对应的系统调用后,再调用标签q对应的系统调用的概率,pl是标签l对应的系统调用转移到其它系统调用的概率矢量。接着将数据转化为SVM能够识别的格式,即p1…pl…pM,将其作为支持向量机的输入,最后把正常软件和恶意软件的混合训练集部分导入到系统中,恶意样本标记为1,正常样本标记为0,进行有效性实验训练,从而得出训练好的分类模型用于判断;最后样本检测,进而得出检测结果。
3 实验结果及分析
3.1 数据集和评判指标
本文实验数据集中的非恶意软件来源于小米官方网站,其Android安装包通过Scrapy爬虫获取得到;而实验数据集中的恶意软件来源于国外开源网站VirusShare。用到的分类模型工具包为LIBSVM。
根据学术界的规则,在恶意软件的判别标准中,主要包括以下几个度量:判别准确率ACC(accuracy),真阳性率TPR(true positive rate),假阳性率FPR(false positive rate)。其中ACC定义为
(11)
TPR定义为
(12)
FPR定义为
(13)
在上述公式中,TP(true positive)表示是恶意软件且分类判别正确的样本数量;FN(false negative)表示是恶意软件但分类错误的样本数量;TN(true negative)表示是正常软件且判定正确的样本数量;而FP(false positive)表示是正常软件但分类错误的样本数量,所有的待测应用都可以归属为以上4类之一,ACC表示所有被分类正确的样本占总样本的比例,TPR表示恶意样本的分类准确率,而FPR表示正常样本的分类错误率。TP与TN越大,FN与FP越小分类效果越好。其次当TPR相等时,FPR越小检测效果越好;当FPR相等时,TPR越大检测效果越好;ACC越大,分类的准确率越高;这些度量可以完善衡量本文方法的优越性。
3.2 实验结果
本实验从1026个恶意样本和1034个良性样本分别随机选取800个样本组成训练集,剩下的部分组成测试集。
在阈值选择方面,保留的系统调用数量越多,检测准确率越高,但复杂度也会随之增高。本文同时兼顾复杂度和检测准确率,以牺牲小幅度检测准确率为代价,换取复杂度的大幅度降低。具体而言,本方案根据评分高低,从高到低分别选取数量为20、40、60、80、100、120和140的系统调用进行标签化处理,未被选取的部分不做处理,从而得到系统调用和检测准确率之间的关系如图6所示。

图6 系统调用数量-检测率关系
根据图6,可发现系统调用数量在40时检测准确率超过90%,故本文以此为转折点,选取数量40为阈值,对应的检测准确率为92.1%,接着按照属性的不同合并“无用”命令组成文件类等7种类型的系统调用,因此通过特征映射后共有47个标签用以检测,从而进一步提高检测准确率,可达到96.9%。
在去冗余的阈值选择方面,根据评分高低,子序列可划分为“重要”与“冗余”两个部分,但两部分的临界点未知。在本文中,评分越高数据越重要,评分低的子序列为冗余量,因此按照评分从低到高进行系统调用去除,最后得到去冗余后的系统调用序列。冗余数据的去除量和检测准确率之间的关系如图7所示。

图7 冗余数据的去除量-检测准确率关系
根据图7,冗余数据的去除量,即数据库中的子序列较少时对检测准确率无影响,接着检测准确率会随着冗余数据去除量的增加而提高,在去除3000个冗余子序列时检测准确率达到峰值,之后,检测准确率会随着冗余数据去除量的增加而降低,这是因为去除的数据包含了重要信息而非冗余,所以检测率会下降。因此选取阈值为3000。实验得到的分类结果中,ACC为97.8%,TPR为97.4%,FPR为1.7%。
实验结果表明本文经过预处理后的检测结果既能保证较优的检测效果,又能大幅度降低检测复杂度。
3.3 对比分析
现有的文献提出了多种不同的检测软件的框架,表4解析了以系统调用为特征的检测结果,下面将具体进行比较分析。
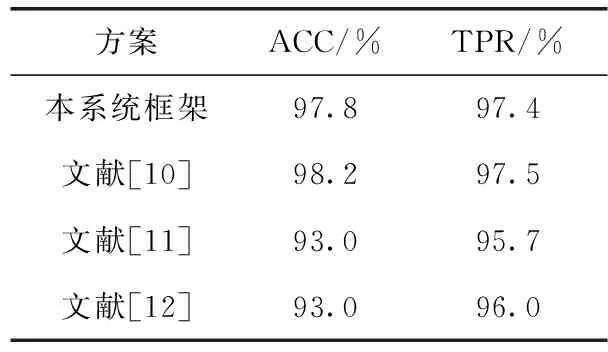
表4 本方案与其它方法的比较
文献[11]提出的基于系统调用频率的新型恶意软件检测方法检测率达到93%,但此框架由于未考虑系统调用之间的相关性和整体性,无法充分保证分类的准确性。文献[12]提出的自动分类框架虽然提高了TPR,但该框架仍未考虑整体性,特征向量冗余量太大,容易导致过拟合,故检测率并未得到提高。文献[10]所提框架构建了系统调用的马尔可夫矩阵,考虑到了系统调用的整体性,因此检测和TPR均有所提高。但文献[10]使用了196个系统调用,构建马尔可夫链矩阵训练复杂度高达196的平方,增加了机器学习过程中的训练时间。本文的检测框架相较于文献[10]提出的数据降维方案在降低检测复杂度的同时,仍可以达到与未降维近乎一致的检测准确率,表4直观反映出本文所提出的方案优于其它检测方案。
4 结束语
本文通过对Android恶意软件样本进行动态分析,进而提出了一种动态检测框架。在该检测框架中,首先模拟运行智能终端的样本提取系统调用特征,然后使用信息增益的方法筛选系统调用,对系统调用进行数据降维和标签化处理,最后将系统调用序列构建为马尔可夫矩阵并利用SVM对样本进行分类。系统调用可以最根本地反映应用软件的行为,将其构建为马尔可夫矩阵可以挖掘出系统底层中系统调用之间的联系。
实验结果表明,本文给出的检测框架对恶意软件的检测效果明显优于现有的几种检测方法。但在特征提取过程中,monkey工具向系统发送伪随机用户事件流不能挖掘全部的软件行为,因而存在一定的局限性,将来还需研究其它可能的方式挖掘其行为,以提高检测效果。
猜你喜欢
小资CHIC!ELEGANCE(2022年1期)2022-01-11
数学物理学报(2020年3期)2020-07-27
商品与质量(2019年34期)2019-11-29
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
信息安全研究(2016年4期)2016-12-01
燕山大学学报(2015年4期)2015-12-25
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
信息安全研究(2015年3期)2015-02-28
