
融合击键内容和击键行为的持续身份认证
2020-06-12 09:17宋礼鹏郑家杰
计算机工程与设计 2020年6期
王 凯,宋礼鹏+,郑家杰
(1.中北大学 大数据学院 大数据与网络安全研究所,山西 太原 030051;2.中北大学 大数据学院,山西 太原 030051)
0 引 言
击键动力学认证[1]作为一种不需要额外设备且不影响用户正常工作的认证方式被广泛应用于用户身份认证领域[2]。文献[3]中指出21%的数据泄露涉及到内鬼或网络间谍。因此,静态身份认证成功后需要持续监测计算机使用者的身份,这种认证方式为持续认证[4]。
针对击键动力学的持续身份认证研究,Alsultan A等[5]要求志愿者输入在线报纸中的内容;张得旭等[6]采集用户使用通讯软件聊天时的击键数据;李福祥等[7]规定志愿者输入较短的字符串。由于用户每天的击键状态受当天的工作要求或者身体的疲劳程度甚至情绪的影响[8],有一定的随机性,而以上工作均对用户的击键行为进行了限制,因此并不能完全反应出用户在现实生活中的击键习惯。何斯译等[9]考虑到击键时间特征随时间的变化,设计出双更新算法减小了误报率;Kim J等[10]采用8等级时间间隔特征为用户的持续身份认证建模,但这些研究仅基于时间维度提取击键特征,认证准确率存在可进一步提升的空间。
本文在数据的采集过程中并不对用户击键的时间和内容加以限制,考虑到连续击键事件更能反应出用户固有的击键习惯,提出将连续击键事件中各后置击键的频次作为击键内容特征,并在现有的击键时间间隔特征的基础上通过将其排序得到击键行为特征,最后采用融合算法结合击键内容域和击键行为域的子分类器。实验结果表明,比较于现有的认证模型,该方法将用户持续身份认证的准确率提高了3.7%至4.7%。
1 持续身份认证模型
本文研究用户在连续击键状态下的击键习惯,在特征构造阶段分别处理击键内容域和击键行为域,然后为这两个域训练子分类器,最后根据改进的Yager证据合成理论[11]在决策阶段融合各域的子分类器得到用户的持续身份认证模型。具体过程如图1所示。

图1 持续身份认证模型
1.1 特征提取
1.1.1 击键内容特征
本文创建包含所有键值的击键表KeyTable={key1,key2,…,keyD},D为键值种类的个数。从用户击键序列中取出n个连续击键事件组成的序列L,记录各连续击键事件中后置击键的键值(例如击键事件A→B,记录键值B),得到长度为n的键值序列
Key={k1,k2,…,kn}
统计各按键在Key中出现的次数
(1)
其中,keyi∈KeyTable,对应击键表中位置i处的键值,i=1,2,…,D。函数I为指示函数,即kj=keyi时为1,否则为0。由此得到连续击键序列L上的击键内容特征
Keyf={c1,c2,…,cD}
1.1.2 击键行为特征
击键行为特征考虑用户在时间维度上所反应的击键习惯。
(1)现有的击键行为特征:现有的方法根据击键按下和抬起时的时间戳计算单个击键的持续时间间隔(Duration)和连续击键的时间间隔(DD_time、DU_time、UD_time、UU_time),如图2所示。从这些时间属性上可以反应出不同用户在击键速度上的差异。文献[6]把键盘分为不同区域,考虑用户在各区域中的击键顺序将击键序列上的5种时间间隔分别排序,并分为8个速度等级,将各等级的均值组成5×8的特征样本。
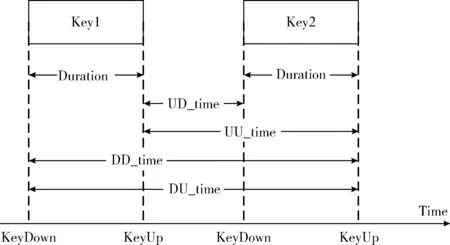
图2 击键时间间隔的5种类型
(2)本文的击键行为特征:考虑到从不同长度的击键序列中提取固定等级的时间间隔特征会丢失掉用户在较长的击键序列中击键速度上的细节,因此本文并未采用划分速度等级的方式对击键序列进行压缩。
首先从用户击键序列中提取出n个连续击键事件组成的序列L,由于Duration为单键的持续时间间隔,因此只考虑连续击键事件的后置击键按下至抬起的时间差,通过计算得到Duration的击键时间间隔序列
Dur={t1,t2,…,tn}
然后将Dur从小到大排序得
同理可得到其它的击键时间间隔序列,即Dd*、Du*、Ud*、Uu*。最后,将这5种时间间隔序列组成连续击键序列L上的击键行为特征
Timef={Dur*,Dd*,Du*,Ud*,Uu*}
1.2 子分类器
本文引入集成学习中的极端梯度提升(extreme gra-dient boosting,XGBoost)算法[12]分别为用户的击键内容域和击键行为域训练子分类器。该子分类器为二分类模型,类别为用户本身(正常用户)和其他用户(异常用户)。
XGBoost分类器由T棵最优的CART树(分类回归树)组成,每棵CART树的训练数据为上轮迭代后产生的模型预测值与真实值之间的残差,该树的目标函数为
(2)
其中,t表示当前迭代的步数,函数L为损失函数,函数Ω为正则项,C为前t-1棵树的复杂度之和,在训练第t棵CART树时,它为常数。通过不断地迭代增加新的CART树,模型的准确率逐渐提高。可设置最高迭代次数T或错误率小于σ时停止迭代。
1.3 融合子分类器
本文将击键内容域和击键行为域上的子分类器进行决策融合。使用1.2节中的两个子分类器分别对击键内容和击键行为样本进行检测,得到的概率向量作为这两个域的mass函数。由改进的Yager证据合成理论得到证据框架(或假设空间)为Θ={o1,o2},其中o1={用户本身},o2={其他用户}。
证据的整体冲突因子为
(3)
其中,mi(Aj)表示证据i中事件为Aj的概率,n为证据的个数。
证据i与j之间的冲突因子为
(4)
证据的可信度为
(5)
其中
(6)
由此可以得到事件o1的合成概率为
m(o1)=p(o1)+kεq(o1)
(7)
其中
(8)
(9)
同理得事件o2的合成概率m(o2)。若m(o1)>m(o2),则最终决策判定当前计算机的使用者为用户本身,否则为其他用户。
2 实验结果与分析
本文采集内网中19名用户的击键数据,为每个用户训练持续身份认证模型。当使用XGBoost算法训练子分类器时,本文提出的击键行为特征在现有击键行为特征的基础上提高了认证模型的准确率。融合击键内容域和击键行为域的子分类器后,认证模型的准确率得到进一步提高。此外,实验还比较了其它集成学习算法训练子分类器时,现有认证方法和本文提出的认证方法下持续身份认证模型的准确率,结果表明本文提出的认证方法具有一定的适用性。
2.1 数据采集分析
本文采集用户的击键信息包括击键内容、击键时间戳、击键窗口名、ASCII码等。实验主要使用击键内容和击键时间戳信息。数据采集的周期为2018年12月至2019年2月,共计19名用户。
连续击键事件大多在很短的时间内发生,“思考”和“生活作息”所产生的时间间隔并不与连续击键的时间间隔处于同一量级,因此需要排除过长的时间间隔数据。1000 ms和2000 ms内的击键时间间隔分布如图3所示。单键的持续时间间隔(Duration)分布上近似于正态,双键的时间间隔(DD_time、DU_time、UD_time、UU_time)分布上具有明显的“长尾效应”,这5种时间间隔分布都在500 ms内达到峰值。由于用户快捷键(如Ctrl+c、Ctrl+v等击键组合)的使用,导致双键的第二个击键按下和抬起有可能发生在第一个击键抬起前,因此UD_time和UU_time会有负值出现。时间间隔在1000 ms和2000 ms内的击键事件占总击键事件的比例见表1。1000 ms内占比最少的UD_time达到80.2%,由此可见,时间间隔在1000 ms内的击键信息已经涵盖了用户的大多数击键行为。2000 ms内占比最少的UD_time达到88.7%,本文在实验中分析时间间隔在2000 ms内的用户击键信息。
所有用户连续击键的后置击键频率如图4所示,其中Back键发生的次数最多,占总击键次数的10.79%,其次为空格键,占总击键次数的7.87%。也有一些击键极少出现,如F3、F4、F5等。图5展示了5名用户在击键时间间隔限制为2000 ms时连续击键的后置击键频率。从图中可看出不同用户在击键频率上所反应出的击键内容差异。Numpad0至Numpad9为键盘右侧的数字键,用户1和用户3几乎不使用这些击键,而用户5使用的相对较多;用户2和用户4偏向于使用上下左右的控制键;用户3使用Back键的频率相对其它击键而言要高很多;尽管各用户对A、I、N、U、Space、Back键的使用较多,但他们各自使用的频率也有差异。无论从整体还是局部,每个用户都可以从击键频率中反应出他们在击键内容上的独特性。
2.2 实验及方案对比
本文为连续击键数据量达到5万的19名用户建立单独的持续身份认证模型,以下实验结果中的准确率为所有用户的准确率均值。实验将用户的击键数据以8∶2的比例分为训练数据和测试数据。考虑到正负样本不均衡的情况,本文随机选择其他用户的击键样本为负样本,设置训练数据和测试数据的正负样本比例为1∶1,结果展示10次实验的均值。由于持续击键身份认证总希望在较短的时间或较短的击键序列中判断出计算机使用者的身份,过长的击键序列并不会达到及时认证的效果,因此本文只分析了击键序列长度在500以内的情况。
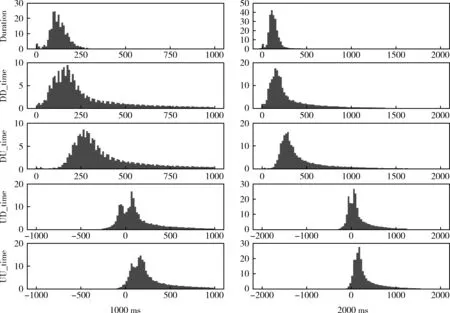
图3 击键时间间隔分布(单位:万次)
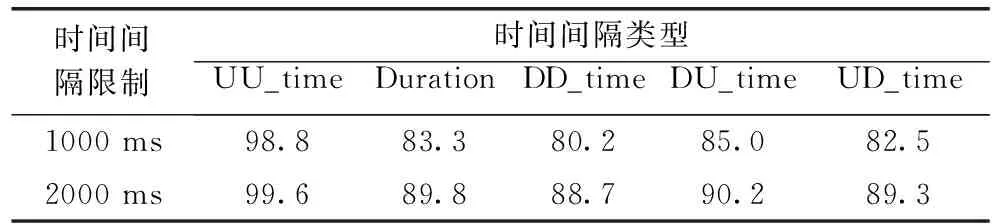
表1 用户击键事件占比/%
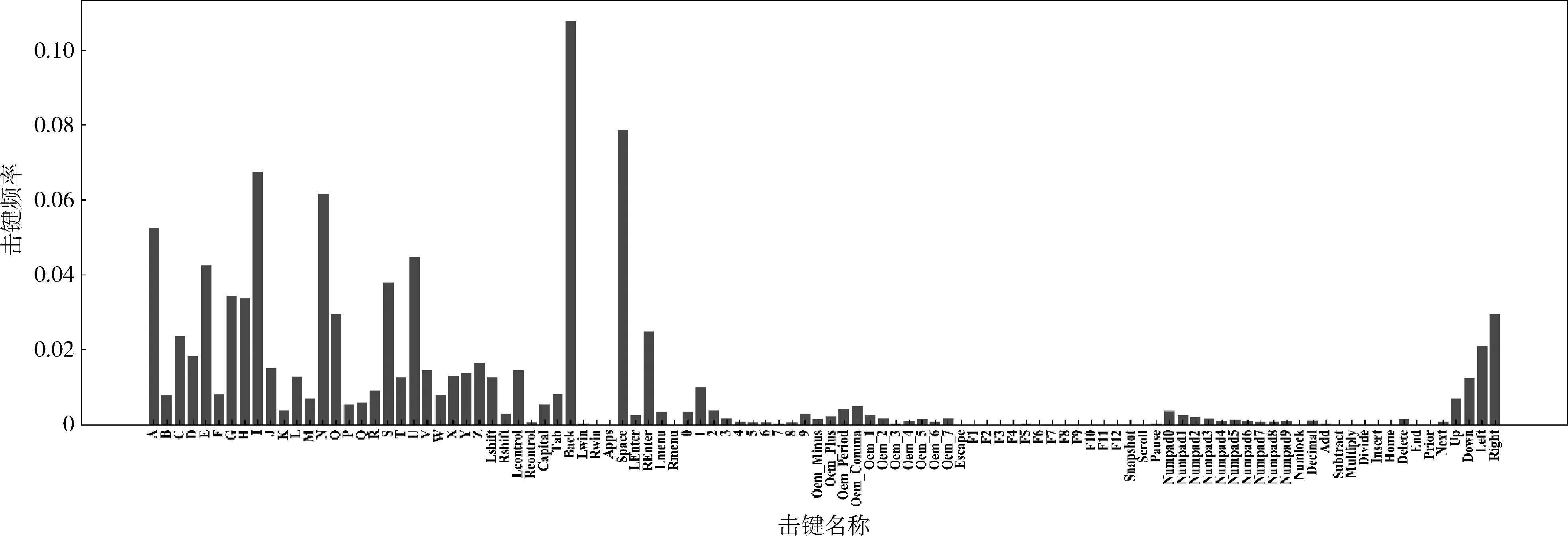
图4 用户的击键频率
图6展示了在不同长度的击键序列下,击键行为域的XGBoost子分类器的准确率。可看出,本文采用的击键行为特征在该分类器下的效果要优于现有的击键行为特征,身份认证的准确率提高了1.2%至2.3%。击键序列长度为200时,准确率最高,达到了92.8%。
图7展示了融合击键内容域和击键行为域的子分类器后的持续身份认证模型的准确率。对于不同长度的击键序列,该模型的准确率在现有击键行为分类器的基础上提高了3.7%至4.7%。其中,击键序列长度为100时,提升效果最为明显。表明本文提出的认证方法可提高用户持续身份认证的准确率。
图8为本文提出的击键内容域和击键行为域的子分类器与融合后的持续身份认证模型的准确率对比图。随着连续击键序列长度的增加,击键内容分类器的准确率也在增加。在连续击键序列长度相同的条件下,击键行为分类器要优于击键内容分类器,融合子分类器后的认证模型要优于单独域下的认证模型。
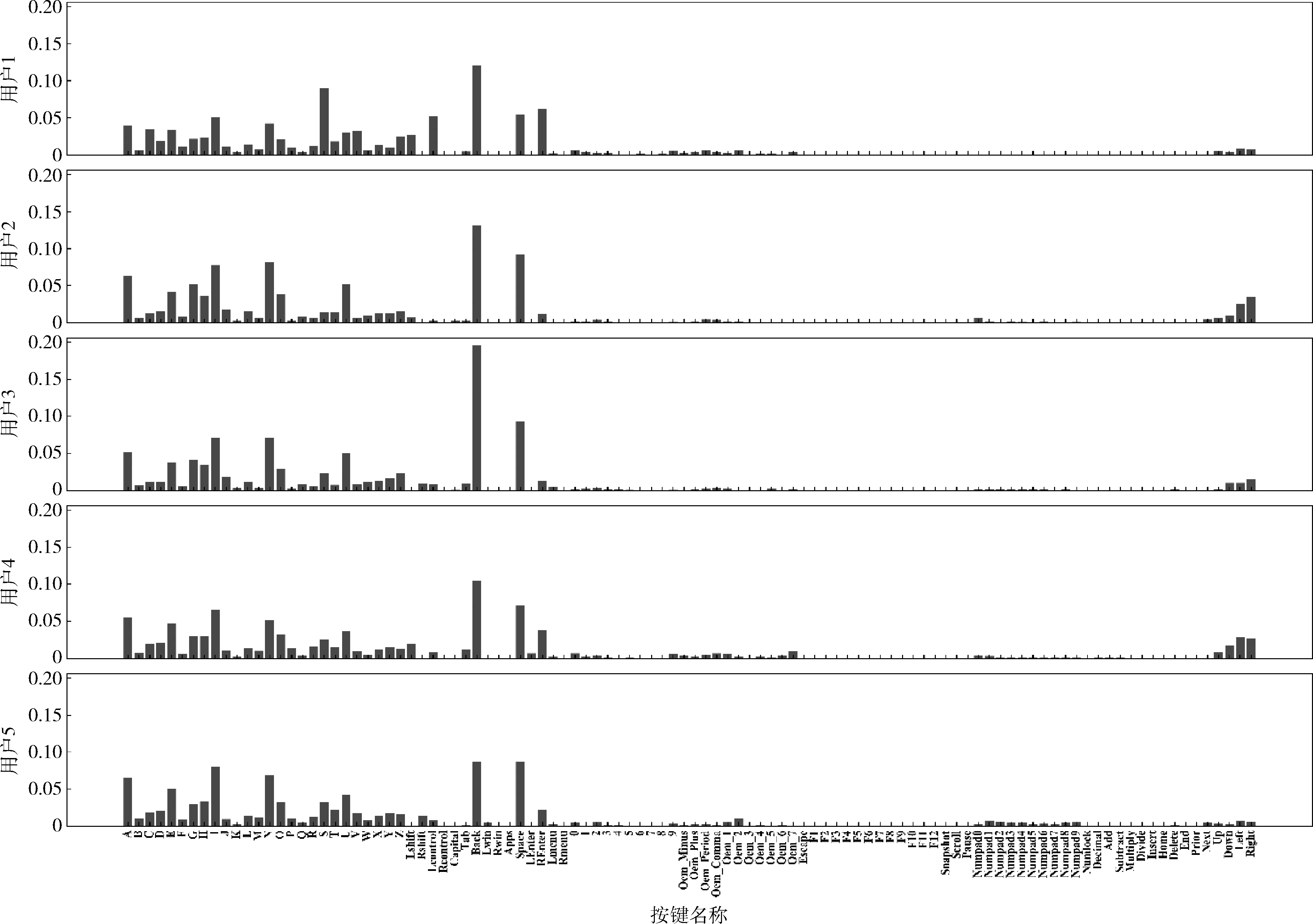
图5 5名用户的击键频率
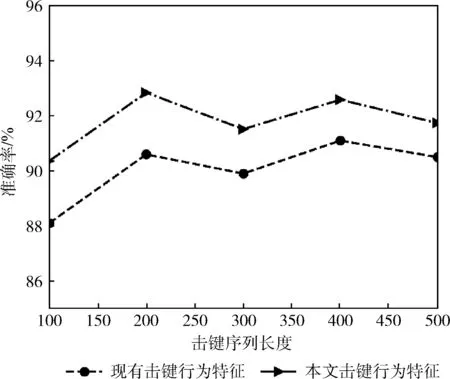
图6 击键行为域的XGBoost子分类器
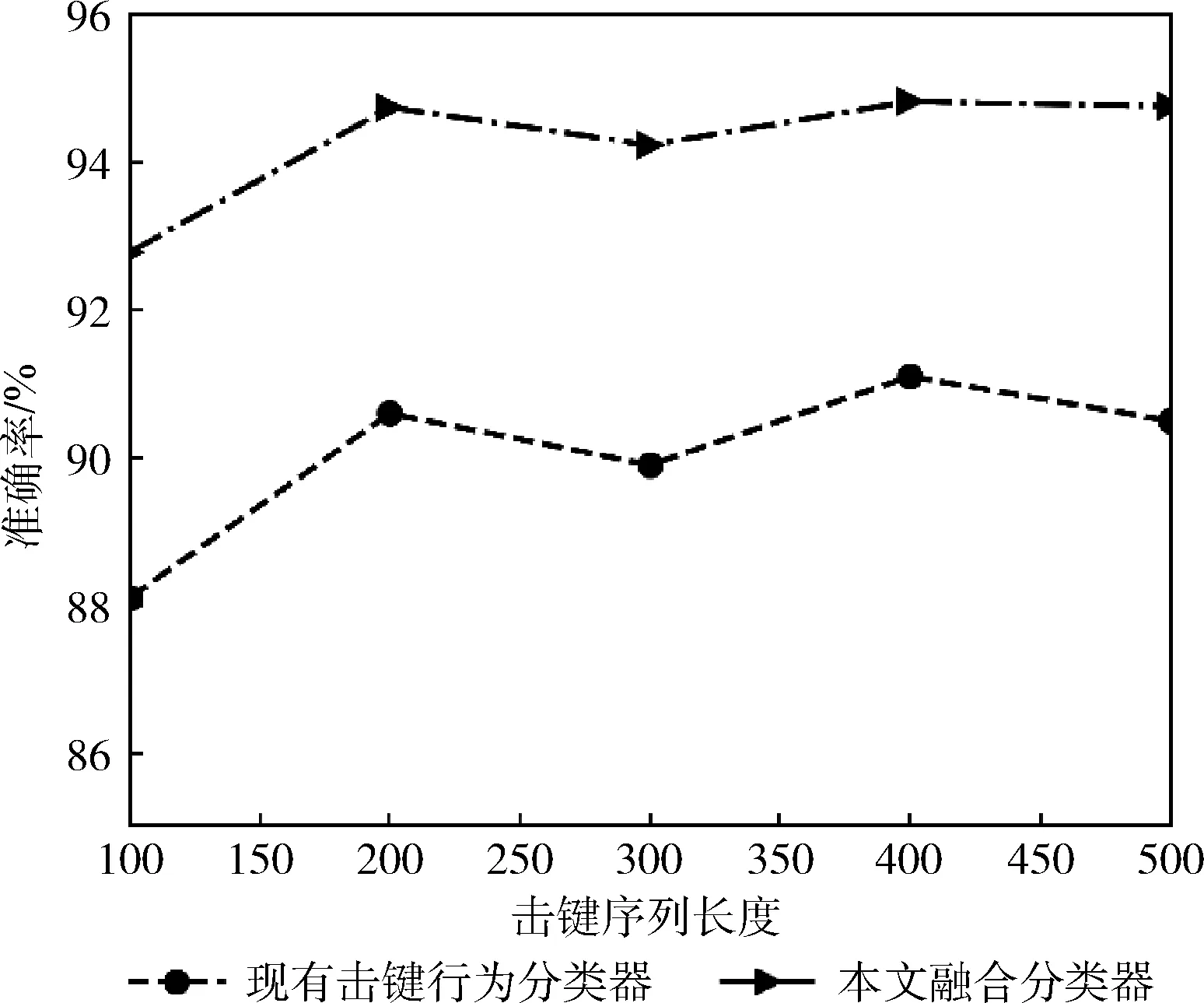
图7 现有分类器与融合分类器
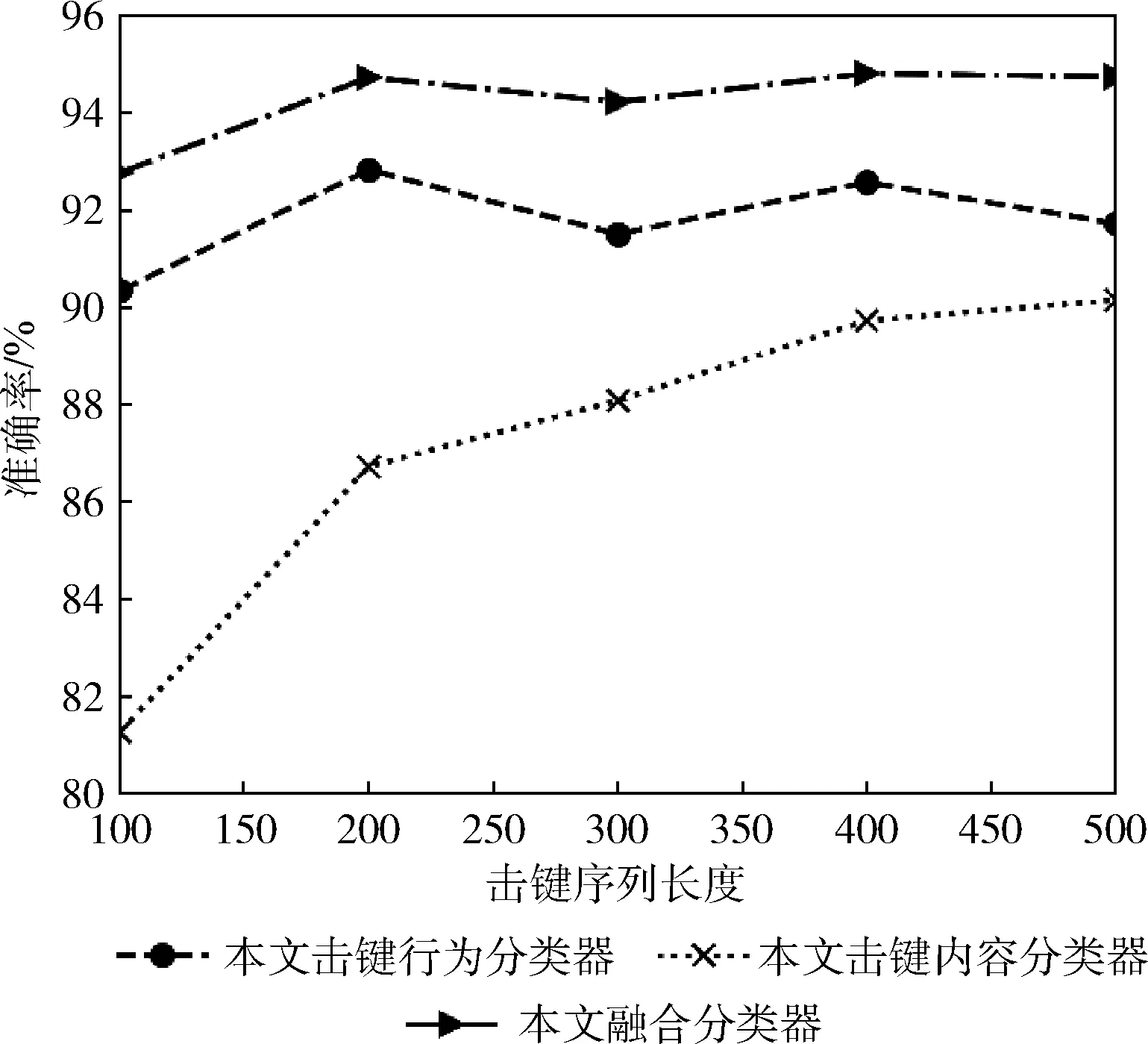
图8 子分类器与融合分类器
融合后的身份认证模型的详细评估指标见表2,其中展示了FRR(错误拒绝率)和FAR(错误接受率)信息
(10)
(11)
FRR较大时,认证系统会给计算机的正常用户带来不便;FAR较大时,认证系统可能无法有效阻挡异常用户的入侵。击键序列长度为100时,持续身份认证系统检测的周期较短,可及时反馈计算机使用者的身份,但准确率相对较低,FRR值和FAR值相对较高;击键序列长度为200时,较高的准确率和较短的认证周期具有很好的实用价值;击键序列长度为400时准确率最高,达到94.83%;击键序列长度为500时,模型的FAR值仅为0.79%,具有很高的安全性。
此外,实验测试了使用RF(随机森林)和自适应增强(adaptive boosting,AdaBoost)[13]算法训练子分类器时认证模型的效果。从表3和表4中可看出,与现有认证方法相比,采用本文的认证方法后,持续身份认证模型的准确率都得到了不同程度的提升。表明本文提出的基于击键行为和击键内容的认证方法有较强的适用性。
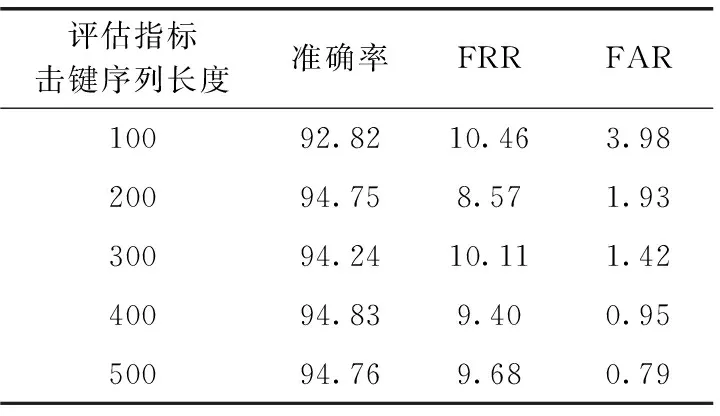
表2 融合后的持续身份认证模型/%
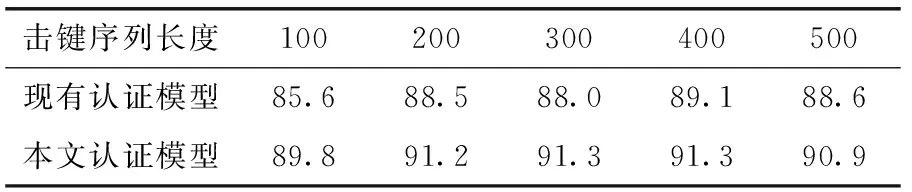
表3 RF准确率/%
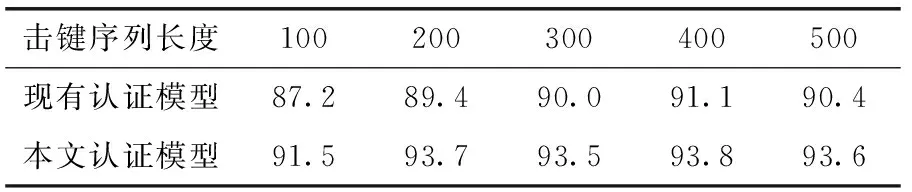
表4 AdaBoost准确率/%
3 结束语
针对现有击键特征下用户持续身份认证的准确率较低的问题,本文在完全自由的内网环境中采集数据,提出了基于击键内容域和击键行为域的特征提取方法,使用XGBoost算法训练子分类器,并根据改进的Yager证据合成理论在决策上融合了各域的子分类器。实验结果表明,该方法可以提高用户持续身份认证的准确率,增强了内网的安全性。
在未来的研究中将扩大击键数据采集的用户范围,并延长采集周期,分析各域的击键特征在时间上的稳定性。此外将尝试结合新域的数据,以进一步提高用户持续身份认证的准确率。
猜你喜欢
数学小灵通(1-2年级)(2020年11期)2020-12-28
小学生学习指导(低年级)(2019年3期)2019-04-22
电子技术与软件工程(2017年14期)2017-09-08
时代英语·高二(2017年4期)2017-08-11
计算机应用(2017年4期)2017-06-27
学生天地·小学中高年级(2017年5期)2017-06-09
红领巾·成长(2016年10期)2017-05-10
航天返回与遥感(2014年5期)2014-07-31
读写算·小学低年级(2014年4期)2014-07-24
今日教育(2014年1期)2014-04-16
