
基于ARIMA模型与BP神经网络算法的水质预测
2020-06-10 01:30:00邓俊晖王荣昌
净水技术 2020年6期
顾 杰,王 嘉,邓俊晖,王荣昌
(1. 浙江嘉科信息科技有限公司,浙江嘉兴 314000;2. 同济大学环境科学与工程学院,长江水环境教育部重点实验室,上海 200092)
对水质预测,目前普遍是根据现在值和某一变量对未来值进行预测。两种主要工具,一是根据时间序列方法进行预测,二是利用灰色系统原理进行预测[1]。这两种方法预测结果相比,精度更高的是时间序列方法[2]。由于ARIMA模型的灵活性、简单性以及可行性,在时间序列预测方法中已经成为主要的时间预测方法[3]。在现实中绝大多数时间序列含有非线性的因素,但是,ARIMA模型中时间序列变量的未来值被认为是变量过去观测值和随机误差值的线性函数。因此,单独使用该模型进行预测会产生较大的误差。通过大量数据的训练,神经网络模型能够挖掘数据背后复杂的非线性关系,具有较强的学习能力,已经在数据预测领域得到广泛的应用,并成为一种主要的预测方法[4]。实际研究中总是或多或少地含有非线性因素,当非线性因素影响较小,或在某一范围内影响较小时,尚可采用线性模型来描述或逼近。但是,非线性影响较大或用线性逼近也得不到较好结果时,非线性时间序列模型的运用就显露了其特有的优势。神经网络模型为非线性模型预测提供了新思路。由于是具备自动学习、逼近能够反映样本数据规律的最优函数,且当函数形式越复杂时,神经网络预测的效果越好[5],其在预测高复杂度的非线性时间序列方面明显优于传统的线性预测方法。为了规避单个预测模型无法充分捕获时间序列中所包含的信息缺陷,通过组合不同预测模型的优势,尽可能多的获取时间序列数据中的信息[6]。有学者将上述方法集成进行时间序列预测研究,以提高模型的预测效果,例如,赵成柏等[2]基于ARIMA和BP神经网络组合模型的我国碳排放强度预测。因此,本文提出了一种基于ARIMA方法和改进的BP神经网络组合模型对水质进行预测,提高预测的精度。采集的待预测流域水质时间序列数据可能包含多种季节性等特点,线性数据使用ARIMA自回归积分滑动平均模型预测,对于非线性数据,使用BP神经网络预测。考虑到水质数据中大部分是非线性数据,在BP神经网络中加入气象因素对模型进行训练[7]。最后,将ARIMA自回归积分滑动平均模型预测值与BP神经网络模型误差值结果在待预测各时间点的值进行相加,得到最终的水质预测结果。本文采用2019年1月1日—2019年11月19日嘉兴市某站点水质历史数据和嘉兴周边气象数据,建立ARIMA和BP神经网络组合预测模型,并分别利用单个ARIMA模型和ARIMA-BP组合模型对2019年11月20日—2019年12月7日该站点水质电导率、溶解氧、总磷、总氮、高锰酸盐、氨氮进行预测。
1 预测方法原理
1.1 ARIMA方法
ARIMA (auto regressive integrated moving average) 方法可对时间序列进行预测,常被用于需求预测和规划中。博克思(Box)和詹金斯(Jenkins)于70年代初提出这一著名的时间序列预测方法,又称box-jenkins模型、博克思-詹金斯法[8],可用来对随机过程的特征随着时间变化而非固定、导致时间序列非平稳的原因是随机而非确定的问题。为了得到一个平稳的序列,假设从平稳的时间序列开始,首先应当做差分。模型的思想就是从历史的数据中学习到随时间变化的模式来预测未来。其中ARIMA(p,d,q)称为差分自回归移动平均模型,d是差分的阶数,用来得到平稳序列[9];AR是自回归,p为相应的自回归项;MA为移动平均,q为相应的移动平均项数。
建立ARIMA时间序列模型包括3个步骤。
(1)数据的平稳性处理
判断样本的平稳性,需对一个时间序列进行ARIMA(p,d,q)模型建模,如果不是平稳序列,需利用一次或多次差分将其转化为平稳序列。原序列值相距一期的两个序列值之间的减法运算是一阶差分;相距K期的两个序列值之间相减是k阶差分;差分平稳序列表现为一个时间序列经过差分运算后有平稳性,可以使用ARIMA模型进行分析。
(2)确定模型参数
参数估计主要有3种方法:矩估计、最小二乘法和极大似然法。3种方法各有利弊,为达到最佳的模型拟合效果,需对这3种方法进行尝试,最后根据样本数据选取最优估计方法[10]。
(3)模型验证
验证所拟合的时间序列模型的参数估计值是否有显著性和验证所拟合的时间序列模型的残差序列是否是白噪声序列,即残差序列的独立性检验。
1.2 BP神经网络算法
BP神经网络是一种通过BP算法实现的人工神经网络。人工神经网络是受自然神经元静息和动作电位产生机制启发而建立的一个运算模型。神经元大致可以分为树突、突触、细胞体和轴突,神经元通过位于树突上的突触接受信号[11]。当信号量超过某个阈值时,细胞体就会被激活,产生电脉冲。电脉冲沿着轴突并通过突触传递到其他神经元,且可能激活别的神经元,神经元生理结构如图1所示。

图1 神经元生理结构Fig.1 Physiological Structure of Neuron
人工神经元模型已经把自然神经元的复杂性进行了高度抽象的符号性概括。神经元模型基本上包括多个输入(类似突触),这些输入分别被不同的权值相乘(收到的信号强度不同),然后被一个数学函数用来计算决定是否激发神经元,该函数被称作激活函数[12],如图2所示。人工神经网络把这些人工神经元融合一起用于处理信息。
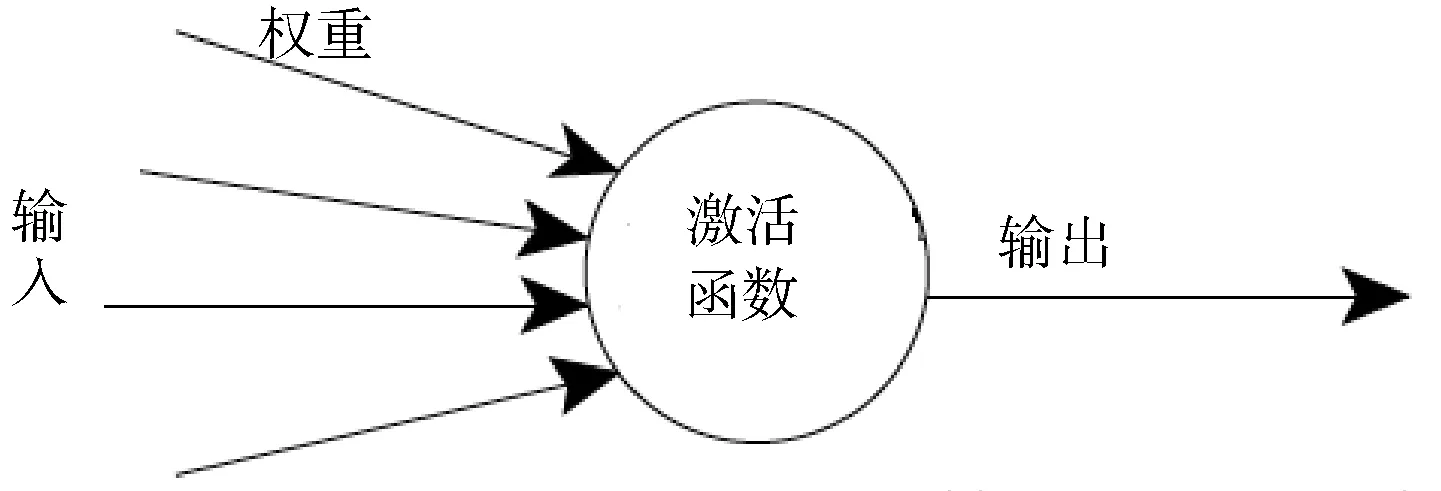
图2 人工神经网络激活函数Fig.2 Activation Function of Artificial Neural Network
权值越大表示输入的信号对神经元影响越大。通过调整权值可得到固定输入下需要的输出值。调整权重的过程称为“学习”或“训练”[13]。
以最简单的一维线性函数y=wx+b为例,通过调整w和b两个参数可以使该函数左右上下移动,在引入激活函数σ(wx+b)后,线性函数即可变成更复杂的非线性函数[14],如图3所示。
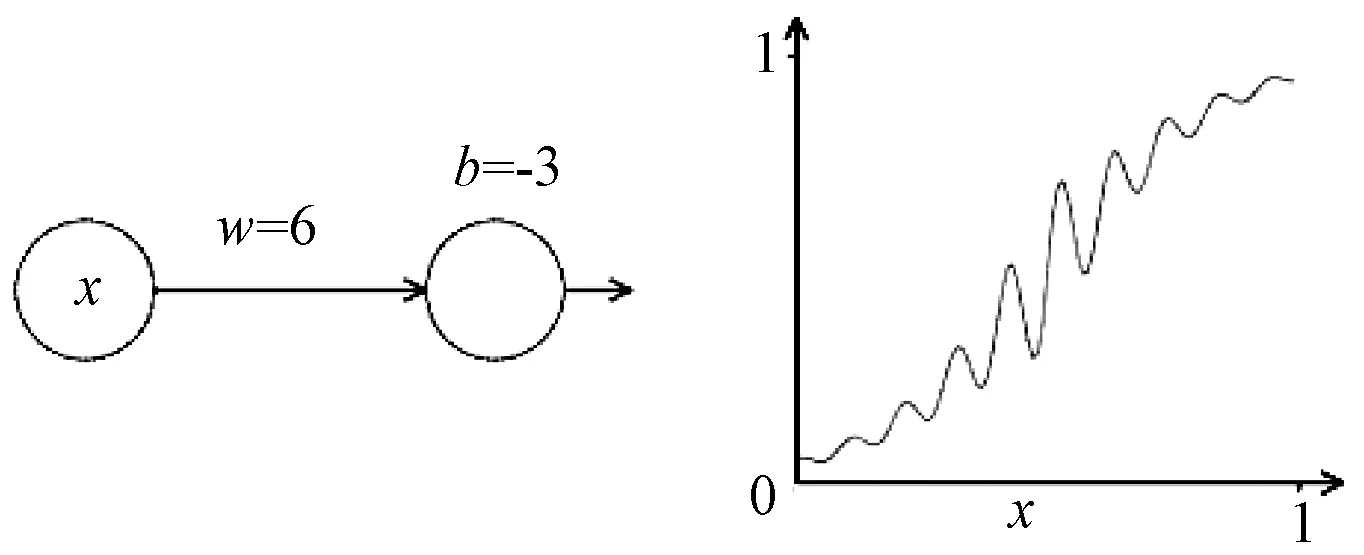
图3 神经网络模型及对应的函数1Fig.3 Neural Network Model and Corresponding Functions 1
在神经网络神经元上运行的函数即为激活函数,主要负责将神经元的输入映射到输出端。常见的激活函数包括TanHyperbolic(tanh)、Sigmoid、TanHyperbolic(tanh)、ReLu、 TanHyperbolic(tanh)以及softmax函数[15]。非线性函数作为这些函数的的共同点,引入非线性函数作为激励函数,神经网络就可以逼近任意函数。
基于神经网络算法可以构造出任意复杂函数的理论依据[16],可以建立一个特定的神经网络模型,使用前几天水质误差数据和气象数据作为特征值,对应当天水质误差数据作为特征标签,进行训练并不断调整网络模型的权重,拟合出一个对应的函数,然后使用该函数做校准[17]。
本文使用的BP神经网络训练数据包括水质误差数据和气象数据,每个维度之间的数量级差别较大,直接训练会导致每一维的梯度下降不同,使用同一个学习率也很难迭代到代价函数最低点。经过归一化处理后,易进行梯度下降,便于提高训练速度[18]。常用归一化方法有最大-最小标准化、Z-score标准化、函数转化等[19]。使用最大-最小标准化对原始数据进行线性变换,设minA和maxA分别为A的最小值和最大值,将A的一个原始值x通过最大-最小标准化映射到区间[0,1]的值x′,如式(1)。
(1)
其中:x——(-∞,+∞)的实数值;
A——原始数据值。
2 预测模型的实现
2.1 ARIMA模型建模
本文只描述水质电导率指标的建模过程,其他几个指标的建模过程类似,不再描述。整个建模过程采用R语言实现,建模流程如图4所示。
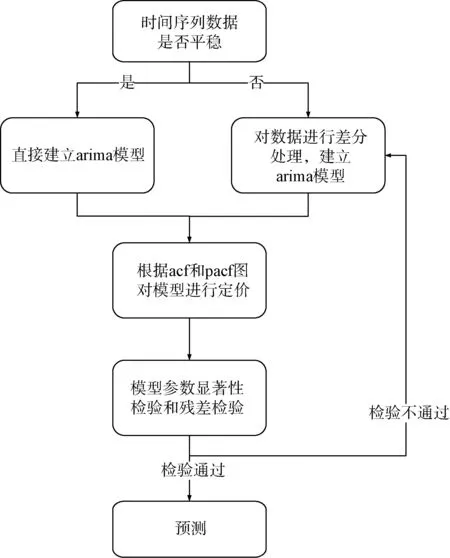
图4 建模流程图Fig.4 Flow Chart of Modeling
(1)数据准备
本次观测对象为嘉兴市某水质站点采集的水质电导率时间序列日均指标,时间为2019年1月1日—2019年11月19日,时间序列有323个数据。
(2)数据导入
data<-read.xlsx("水质电导率数据.xlsx",sheetName=“Sheet1”,header=T,encoding="UTF-8")
(3)平稳性检验
根据以上信息,运用R语言中的绘图程序,绘制水质电导率指标随时间的趋势图(图5)。
data1<-data[-1]
ddl<-ts(data1,start=2019-01-01)
dev.off()
plot(ddl)

图5 水质电导率趋势Fig.5 Trend Diagram of Water Quality Conductivity
如图5所示,水质电导率指标围绕一个常数上下波动,是一个平稳序列。因此,不需要对时间序列进行差分,确定d=0。
(4)自相关图和偏自相关图
确定好阶数d的选择后,再确定ARIMA模型中的参数p与q。时间序列的自相关系数(ACF)与偏自相关系数(PACF)可以判断参数p与q。 对平稳后的时间序列绘制自相关图与偏自相关图(图6)。
自相关图显示自相关值基本没有超过虚线边界值,虽然有个别介数自相关值超出边界,但很可能属于偶然出现,其他均没有超出显著边界。偏自相关图显示,基本上也没有超过边界值。可以考虑p=2,q=0,即ARIMA(2,0,0)模型。
(5)白噪声检验
Box.test(arima200$residual,type="Box-Pierce",lag=5)
对残差序列进行白噪声检验,得出p值=0.457 2>0.05,残差序列白噪声检验说明,模型显著成立,ARIMA(2,0,0) 模型对该时间序列拟合成功。
(6)模型预测
运用上述得到的 ARIMA(2,0,0)模型,调用forecast函数预测2019年11月20日—2019年12月7日数据。
predict.fore<-forecast(arima200,h=20)
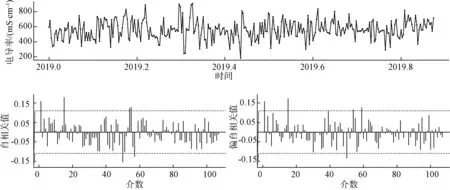
图6 水质电导率自相关图和偏自相关图Fig.6 ACF Diagram and PACF Diagram of Water Quality Conductivity
predict.fore
(7)模型拟合
使用auto.arima函数自动生成拟合参数进行拟合:
auto.arima(ddl)
auto.arima给出的建议参数是(2,0,0)(1,1,1)[12]
fit<-arima(data,order=c(2,0,0),seasonal=list(order=c(1,1,1),period=12)) #
拟合结果如图7所示,实线为真实值,虚线为拟合值。

图7 水质电导率真实值和拟合值Fig.7 Real Value and Fitted Value of Water Quality Conductivity
2.2 BP神经网络建模
本文只描述了水质电导率指标误差的BP神经网络建模过程,其他几个指标的建模过程类似不再描述。
(1)准备数据
通过ARIMA模型的拟合结果,可以生成323个由原始值减去拟合值的误差数据以及对应每日嘉兴市的气温、气压、降雨量作为训练样本数据。
(2)构建模型
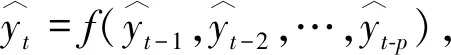
(3)训练模型
模型训练部分R语言代码片段如下。
# 读取训练数据
input <- read.csv("水质电导率误差训练样本数据.csv",header=TRUE,sep=",")
# 设置训练参数
dataCol <- “ddl_error_day1_before”
labelCol <- “ddl_error_now”
inputCols <-c(dataCol,“ddl_error_day2_before”,“ddl_error_day3_before”,“temperature”,“pressure”,“rainfall”)
# 设置训练数据样本比率
trainingSetRatio <-0.9
# 归一化
Maxs <- apply(input,2,max)
Mins <- apply(input,2,min)
# 训练神经网络模型
net<-Training(input,trainingSetRatio,dataCol, labelCol,inputCols, 0.0111)
# 读取验证数据
ca_input <- read.csv("水质电导率误差验证数据.csv",header=TRUE,sep=",")
# 使用训练好的模型验证数据
predict<-Calibrate(net,ca_input,inputCols,Maxs,Mins,labelCol)
# 计算性能指标
label<-as.data.frame(ca_input[labelCol])
r2<-RSquare(predict,label)
mse<-Mse(predict,label)
2.3 数据分析方法
运用模型预测统计分析方法,对比水质指标预测数据与实际水质指标监测数据,分别计算平均百分比误差值[式(2)]、均方根误差值[式(3)]、平均偏差值[式(4)],对水质预测数据准确率进行分析。
(2)
其中:MRE——平均百分比误差;
Gi,o——实测值;
Gi,m——预测值;
n——数量。
(3)
其中:RMSE——均方根误差;
Gi,o——实测值;
Gi,m——预测值;
n——数量。
(4)
其中:MBE——平均偏差;
Gi,o——代表实测值;
Gi,m——预测值;
n——数量。
3 基于ARIMA模型的水质预测试验结果
分别利用建立的ARIMA模型预测嘉兴某个水质站点2019年11月20日—2019年12月7日各项水质参数的值,得出某个水质站点电导率、溶解氧、总磷、总氮、高锰酸盐指数、氨氮的预测数据分析结果,如图8~图13所示。
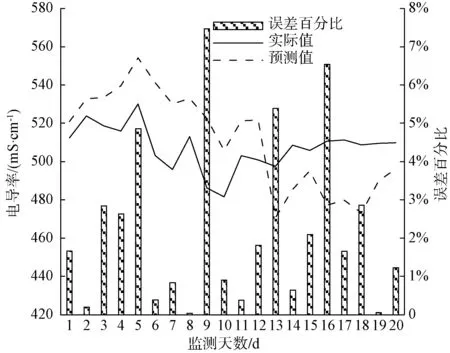
图8 电导率预测分析预测结果对比Fig.8 Comparison Chart of Prediction Results of Conductivity Prediction Analysis
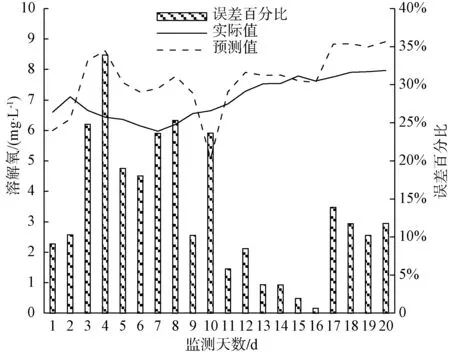
图9 溶解氧预测分析预测结果对比Fig.9 Comparison Results of Dissolved Oxygen Prediction Analysis
将嘉兴某个水质站点2019年11月20日—2019年12月7日各项水质参数(溶解氧、总磷、总氮、高锰酸盐指数、氨氮)的实际监测数据和模型预测数据进行对比,分析MRE(平均百分比误差)、RMSE(均方根误差)、MBE(平均误差)3个误差统计参数,如表1所示。

图10 总磷预测分析预测结果对比Fig.10 Comparison Results of Total Phosphorus Prediction Analysis
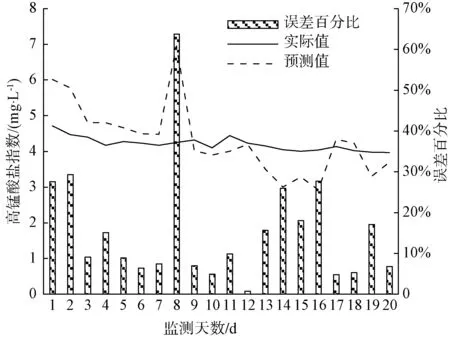
图12 高锰酸盐指数预测分析预测结果对比Fig.12 Comparison Chart of Prediction Results of Permanganate Index Prediction Analysis

图11 总氮预测分析预测结果对比Fig.11 Comparison Results of Total Nitrogen Prediction Analysis
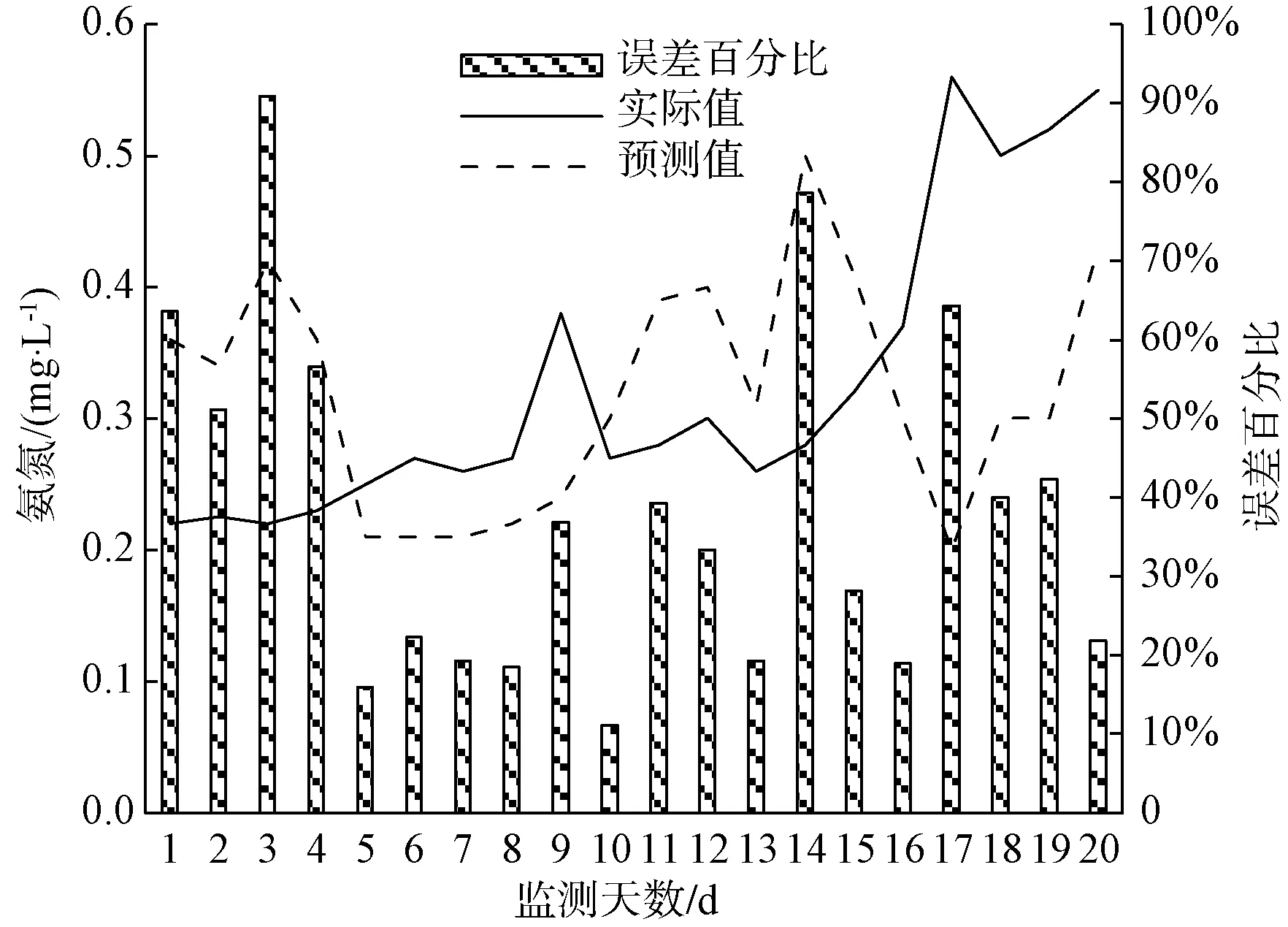
图13 氨氮预测分析预测结果对比Fig.13 Comparison Chart of Prediction Results of Ammonia Nitrogen Prediction Analysis
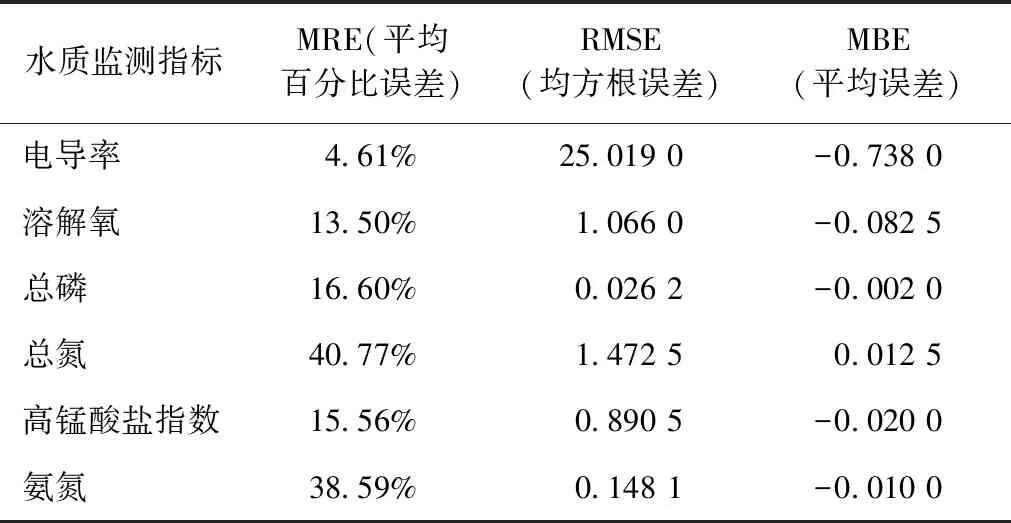
表1 ARIMA水质预测数据模型统计分析Tab.1 Statistical Analysis of ARIMA Water Quality Forecast Data Model
分析各项水质监测指标的平均百分比误差[式(2)],得出电导率、溶解氧、总磷、总氮、高锰酸盐指数、氨氮对应指标的平均百分比误差,分别为4.61%、13.50%、16.60%、40.77%、15.56%、38.59%。其中,总氮的平均百分比误差最大,其次为氨氮、总磷、高锰酸盐指数、溶解氧,电导率平均百分比误差最小。
分析各项水质监测指标的均方根误差[式(3)],得出电导率、溶解氧、总磷、总氮、高锰酸盐指数、氨氮对应的均方根误差,分别为25.019、1.066 0、0.026 2、1.472 5、0.890 5、0.148 1。其中,电导率的均方根误差最大,其次为总氮、溶解氧、高锰酸盐指数、氨氮,总磷的均方根误差最小。
分析各项水质监测指标的平均误差[式(4)],得出电导率、溶解氧、总磷、总氮、高锰酸盐指数、氨氮对应的平均误差,分别为-0.738、-0.082 5、-0.002 0、0.012 5、-0.020 0、-0.010 0。其中,电导率的平均误差绝对值最大,其次为总氮、溶解氧、高锰酸盐指数、氨氮,总磷的平均误差绝对值最小。
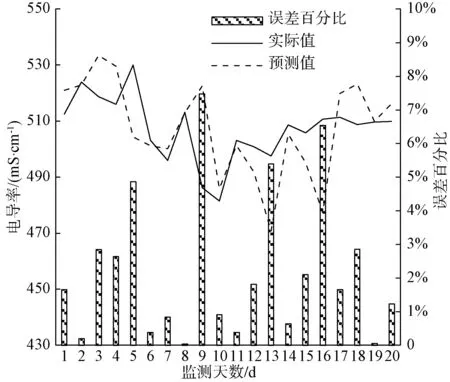
图14 电导率预测分析预测结果对比Fig.14 Comparison Results of Conductivity Prediction Analysis
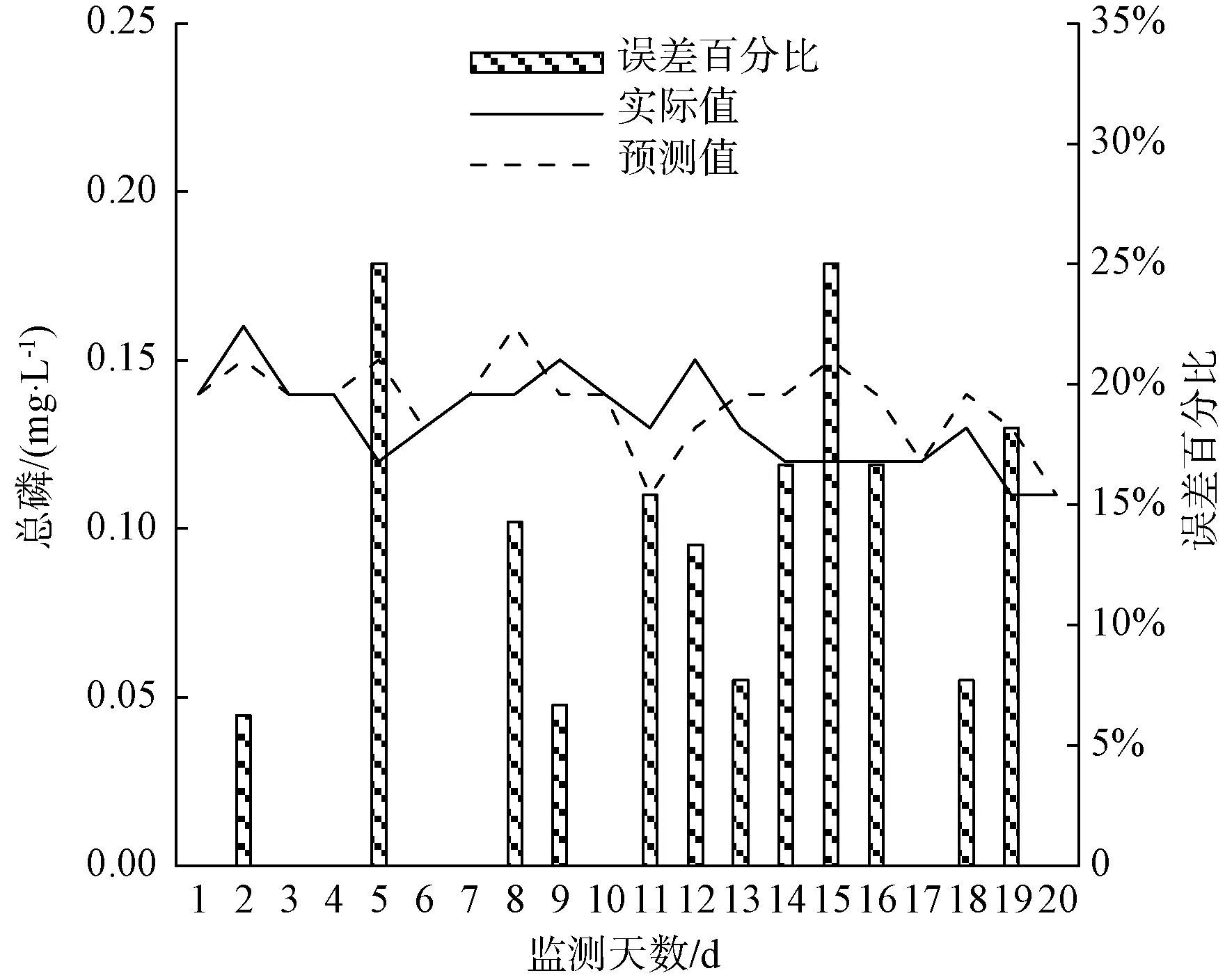
图16 总磷预测分析预测结果对比Fig.16 Comparison Results of Total Phosphorus Prediction Analysis
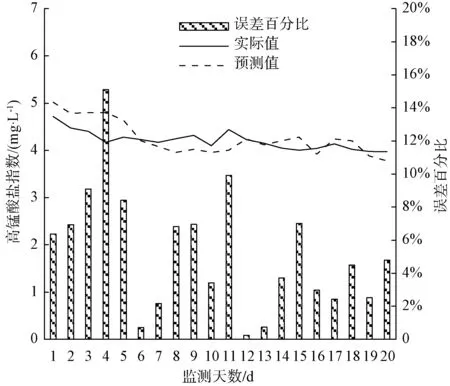
图18 高锰酸盐指数预测分析预测结果对比Fig.18 Comparison Results of Permanganate Index Prediction Analysis
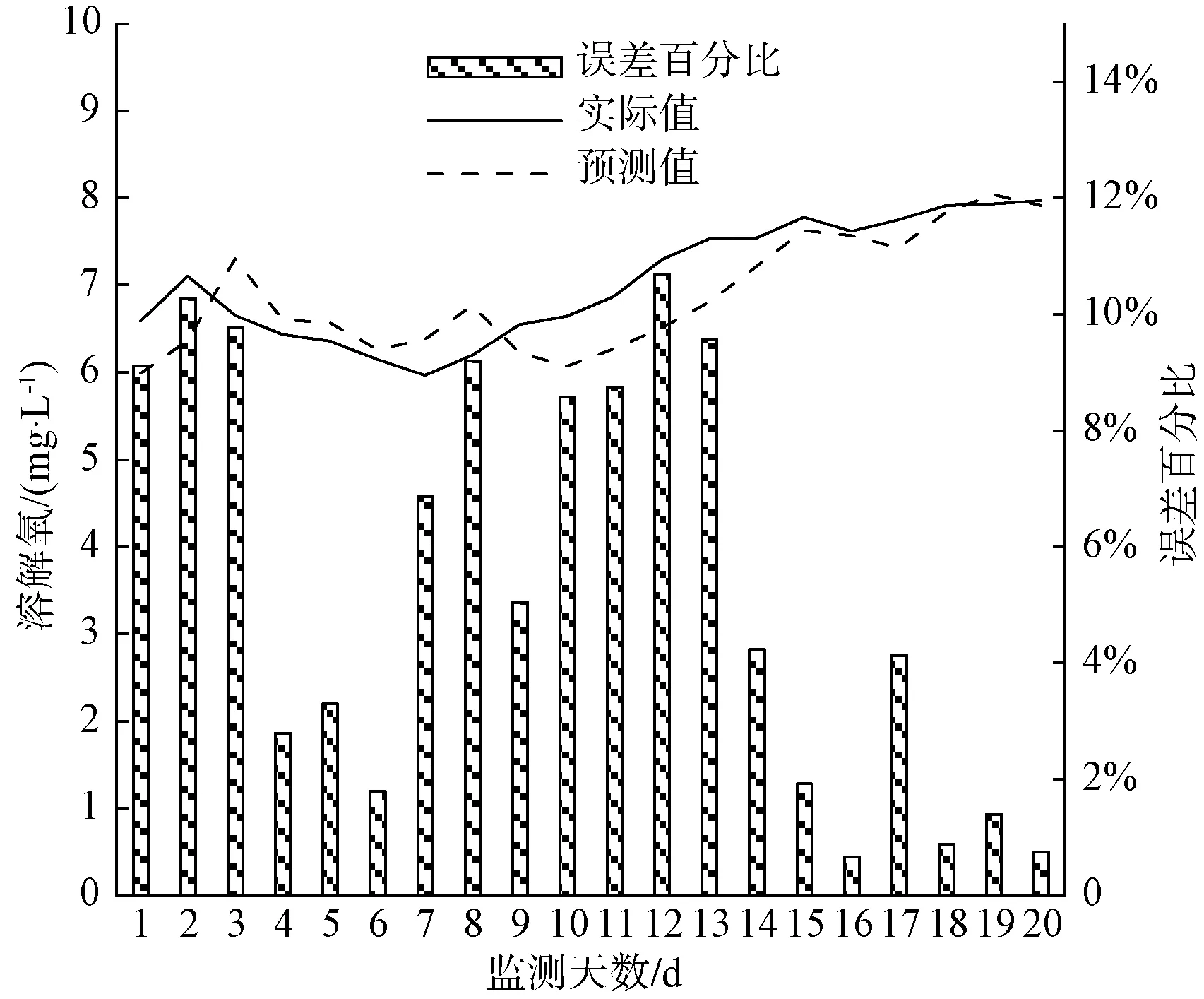
图15 溶解氧预测分析预测结果对比Fig.15 Comparison Results of Dissolved Oxygen Prediction Analysis

图17 总氮预测分析预测结果对比Fig.17 Comparison Results of Total Nitrogen Prediction Analysis
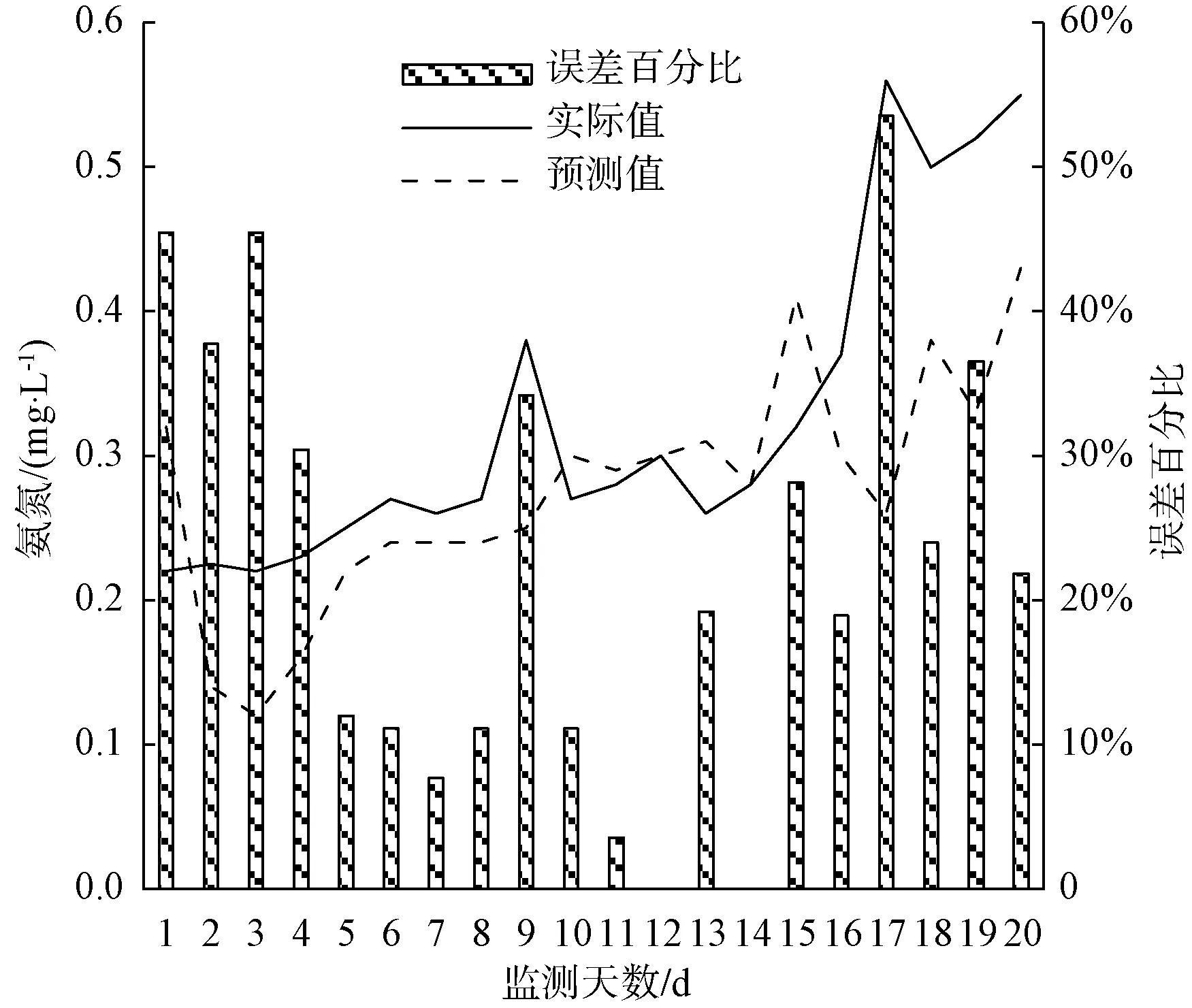
图19 氨氮预测分析预测结果对比Fig.19 Comparison Chart of Prediction Results of Ammonia Nitrogen Prediction Analysis
4 基于组合模型水质预测试验结果
利用建立的ARIMA模型和改进的BP神经网络模型组合方式,预测嘉兴某个水质站点2019年11月20日—2019年12月7日各项水质参数的值,得出某个水质站点电导率、溶解氧、总磷、总氮、高锰酸盐指数、氨氮的预测数据分析结果,如图14~图19所示。
将嘉兴某个水质站点2019年11月20日—2019年12月7日各项水质参数(溶解氧、总磷、总氮、高锰酸盐指数、氨氮)的实际监测数据和模型预测数据进行对比,分析MRE(平均百分比误差)、RMSE(均方根误差)、MBE(平均误差)3个误差统计参数,如表2所示。

表2 水质预测数据模型统计分析Tab.2 Statistical Analysis of Water Quality Forecast Data Model
分析各项水质监测指标的平均百分比误差[式(2)],得出电导率、溶解氧、总磷、总氮、高锰酸盐指数、氨氮对应的平均百分比误差,分别为2.23%、5.49%、8.64%、31.86%、5.23%、22.61%。其中,总氮的平均百分比误差最大,其次为氨氮、总磷、溶解氧、高锰酸盐指数,电导率平均百分比误差最小。
分析各项水质监测指标的均方根误差[式(3)],得出电导率、溶解氧、总磷、总氮、高锰酸盐指数、氨氮对应的均方根误差,分别为15.607 6、0.451 0、0.015 2、1.305 5、0.271 4、0.105 7。其中,电导率的均方根误差最大,其次为总氮、溶解氧、高锰酸盐指数、氨氮,总磷的均方根误差最小。
分析各项水质监测指标的平均误差[式(4)],得出电导率、溶解氧、总磷、总氮、高锰酸盐指数、氨氮对应的平均误差,分别为0.137 5、0.153 0、-0.005 0、0.008 5、-0.049 5、0.050 8。其中,溶解氧的平均误差绝对值最大,其次为电导率、氨氮、高锰酸盐指数、总氮,总磷的平均误差绝对值最小。
5 结果分析
从试验结果看,使用ARIMA-BP组合模型预测的各项指标的平均百分比误差和均方根误差比单独使用ARIMA模型预测的各项指标的平均百分比误差和均方根误差有显著的减小。因此,采用ARIMA模型预测水质的线性规律,用改进的BP神经网络预测水质的非线性规律,形成的组合模型预测水质指标,达到优势互补。相对于单一模型,该模型不但预测精度高、结果也更为可靠、合理,是实现科学分析水质监测数据的重要依据。
6 结语
(1)使用ARIMA、BP神经网络对嘉兴某个水质站点2019年11月20日—2019年12月7日的水质各项参数进行预测。试验结果表明,与传统的ARIMA预测模型相比,ARIMA-BP组合模型相结合的方法对水质的预测达到了更好的趋势和精度。
(2)未来的研究方向:可以考虑使用集成算法将ARIMA算法和更加复杂的神经网络算法进行结合,使用组合模型;同时,提取水质数据的线性和非线性规律,达到更好的预测效果。
猜你喜欢
云南化工(2021年6期)2021-12-21 07:31:16
中国测试(2021年4期)2021-07-16 07:49:04
科学与信息化(2020年11期)2020-06-19 08:50:42
浙江工业大学学报(2017年5期)2018-01-22 02:03:40
现代园艺(2017年23期)2018-01-18 06:57:46
水利技术监督(2017年6期)2017-12-19 13:28:18
计算机测量与控制(2017年6期)2017-07-01 16:24:28
水利科技与经济(2017年6期)2017-04-28 08:30:14
电镀与环保(2016年3期)2017-01-20 08:15:31
技术与教育(2014年2期)2014-04-18 09:21:33
