
基于深度学习的刺网与拖网作业类型识别研究
2020-06-10 01:30汤先峰张胜茂裴凯洋
海洋渔业 2020年2期
汤先峰,张胜茂,樊 伟,裴凯洋
(1.中国水产科学研究院东海水产研究所,农业农村部东海渔业资源开发利用重点实验室,上海 200090;2.上海海洋大学信息学院,上海 201306)
我国渔船拥有量大,据2018中国渔业统计年鉴[1]报道,我国近海机动捕捞渔船超17万艘,作为典型近海捕捞作业方式的刺网和拖网捕捞渔船数占总船数的72.6%。目前捕捞渔船需提前申请捕捞许可证并登记作业类型,但实际作业过程中可能存在不遵守规则情况,导致网具使用比较混乱。违规作业会对渔业资源和海洋生态环境产生不利影响,因此准确的渔船作业识别可为渔船的有效管理带来帮助。
国内外对于渔船作业监控,主要有以下3种手段:传统现场监测、基于卫星遥感技术的渔船作业监测和基于渔船监控系统(vessel monitoring system,VMS)的渔船作业监测。传统的海上巡逻和登临检查准确度高,但监控难度大、成本高、风险高、检查数量有限,在管理上存在局限性。基于卫星遥感技术的渔船监测更多是对灯光作业渔船(灯光围网、秋刀鱼舷提网、鱿鱼钓和灯光罩网)进行监测[2],监测面较窄,并且遥感影像易受云层的干扰。而VMS能实时记录渔船的经度、纬度、航速、航向、发报时间等数据[3-4],可以快速获取大范围渔船作业信息[5-6],监控系统的船舶定位技术已经比较成熟, 从定位方式来看, 主要有北斗渔船定位、沿海CDMA网络定位、AIS船舶定位[7]等。以往利用VMS对渔船作业的监测多集中于对已知作业类型渔船不同捕捞作业阶段的识别,即区分同种类型渔船捕捞和非捕捞作业阶段;识别算法多集中于设置船速或航向阈值、统计推断、机器学习方法等[8-10],此种方法大部分用来计算捕鱼有关的指标,例如捕捞努力量[11]等,难以对未知(即未登记)作业类型的渔船进行监测。以上几种监测方式和监测算法都存在一定的局限性。目前国内外已有研究将渔船作业识别监测的重点转移至对渔船轨迹的研究,识别方法多是基于深度学习、机器学习等:HUANG等[12]利用XGBoost的特征工程和机器学习算法作为其两个关键模块构建了VMS渔船轨迹识别方案,对8种不同的渔船作业方式进行了监测识别;DE SOUZA等[13]针对拖网、延绳钓和围网渔船分别开发了不同的机器学习算法进行识别;KROODSMA等[14]利用卷积神经网络(convolutional neural network,CNN)算法将AIS渔船分为7类进行了识别研究[14-15]。
目前深度学习方法发展迅速[15],可以将特征工程自动化,相比HUANG等[12]和DE SOUZA等[13]使用的机器学习方法,CNN无须研究手动设计特征。目前利用CNN算法对北斗VMS渔船轨迹数据进行监测的研究较少,本文提出一种利用CNN对刺网和拖网渔船轨迹进行识别分类的方法:首先利用航次提取方法提取出每艘渔船具体的航次信息,根据提取的航次信息将原始VMS数据进行划分,根据每个划分的数据里的经纬度点数据,批量画出每个航次的轨迹点图,以此生成刺网和拖网航迹图库;将刺网和拖网航迹图输入到深度卷积神经网络模型中,根据大量的图片训练、学习和验证,以此得到区分拖网作业和刺网作业的深度学习模型。
1 材料与方法
1.1 研究实验流程
研究实验整体流程如图1所示。
1.2 数据来源
刺网和拖网的北斗船位数据来源于北斗民用分理服务商,北斗VMS数据信息主要包括渔船的ID、经纬度、时间等信息,空间分辨率约为 10 m,时间分辨率约为 3 min。研究使用浙江省北斗VMS 2017年数据,其中包括刺网作业船1 566艘,拖网作业船2 504艘,渔船作业类型均为登记作业类型。根据本文航次图生成方法共生成刺网航迹作业图11 912张,拖网航迹图11 488张。
1.3 航次划分方法与航迹图生成
1.3.1 航次划分方法
航次是渔业生产管理中常用的统计量,渔船按照约定的捕捞计划从出发港到返回港为一个航次。渔船出海作业过程中,船载北斗终端发送渔船ID、船位经纬度、时间等信息,位置点记录的时间间隔约为3 min,每个航次由一系列时间序列船位点组成。首先按0.1°×0.1°把中国海岸线划分到每个格网中,生成格网信息图层,然后将格网图层与海岸线图层叠加,两者相交的格网即为港口格网,将省、地区、县行政区划图层与港口格网中心点图层叠加,计算出港口格网中心点经度和纬度,格网所属的行政区划为离中心点最近的行政区划。将渔船轨迹线与港口格网相叠加,相交的点即为渔船的出发港和返回港,根据出发港船位点和返回港船位点来提取出具体的每个航次信息[16]。
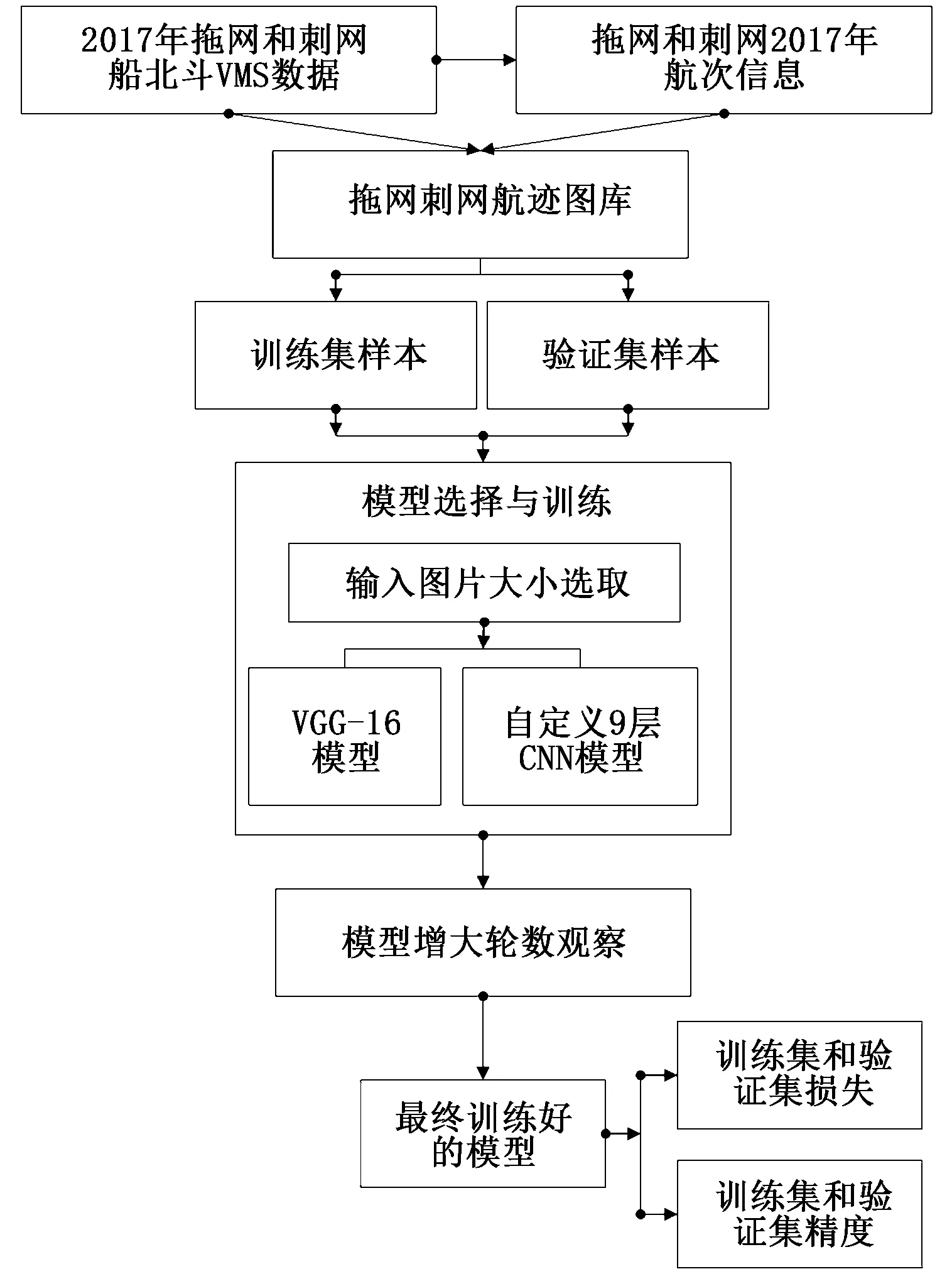
图1 研究实验流程图Fig.1 Research experiment flow chart
图2为渔船航次示意图,格网中心点为港口。图2中有2个航次,分别是航次1和航次2。航次1从港口格网A出发,经过海上捕捞作业,在港口格网C返港;航次2从港口格网D出发,经过海上捕捞作业,在港口格网D返港。

图2 渔船航次示意图Fig.2 Schematic diagram of fishing boat voyage
1.3.2 航迹图生成方法
根据提取的每个2017年浙江省北斗VMS拖网和刺网所有航次信息,将原始VMS数据划分为每个航次数据;根据每个航次数据里的经纬度数据,依次生成每个航次的航迹图。航迹图生成流程如图3所示(图中为拖网航迹图生成流程示例,流程图中使用的航次和船位数据图片不代表最终使用的数据,仅提供数据格式和过程示意),航迹图为每个航次的所有船位经纬度点的轨迹点图。将不清晰、数据点太少和航次不完整的图人工观察剔除掉,共生成刺网航迹图11 912张,拖网航迹图11 488张,图片高×宽为288像素×432像素(以下统一简写为432×288),以此形成拖网和刺网的航迹图数据库。
1.4 深度卷积神经网络
CNN通过监督学习,能够直接从原始图像中识别出图像特征[17-18]。CNN[19]模型一般由卷积层、池化层、全连接层、Softmax分类层等堆叠组成[20],可根据需要自定义不同层的结构和组成。卷积操作用于特征提取,卷积核相当于一个过滤器,提取我们需要的特征。卷积运算具体公式如下:
式中,m的取值范围为(0,m),n的取值范围为(0,n),i、j为卷积核w的尺寸;f为激活函数;b为附加偏执量;Yconv为其输出。
池化层 (pooling)可以看作是模糊滤波器, 起到二次特征提取的作用,其中最常用的是最大池化(maxpooling)。最大池化具体公式如下:
fpool=Max(xm,n,xm+1,n,xm,n+1,xm+1,n+1)

图3 航迹图生成流程示意图Fig.3 Schematic diagram of fishing boat voyage track
fpool为最大池化后的结果。
ReLU 激活函数能够加快大型网络训练速度,并且为常见框架提供了实现方案,使用非常便捷[21]。模型所选择的激活函数基本上都是 ReLU 激活函数,其函数表达式为:
f(x)=max(0,x)
在全连接层之前,卷积神经网络卷积层和池化层所提取的特征仍处于局部抽取的层面,要想正确分类, 必须将局部信息进行展开,因此在最后一个池化层之后紧接一个全连接层,将池化层的特征综合起来并利用Softmax分类器进行分类[22]。Softmax函数表达式为:
Softmax函数类似于概率分布,输出结果总和为 1,每个节点得到的结果代表某种可能性概率[21]。
2 结果与分析
2.1 模型设计与搭建
构建深度卷积神经网络的结构和方法非常多,不同的网络模型在公开数据集以外的图片分类任务中表现并不一定相同,模型中可对比的参数和调整的地方也非常多,不同的结构设计和方法选择会影响分类的效果,本文选择使用网络结构比较复杂的VGG-16模型与相对简单的自定义10层CNN模型作实验,同时仅对图片输入大小做筛选实验。
2.1.1 自定义的10层CNN结构
自定义的10层CNN网络由3个卷积层、两个池化层(maxpooling层)、两个dropout层、一个flatten层、两个全连接分类层(dense层和softmax层)组成。其中卷积层均采用 3×3 的卷积运算,前两个卷积层的核数量均为32,第三个卷积层的核数量为64;池化层均采用2×2 的卷积运算,第一个池化层卷积核数量均为32,第二个池化层的卷积核数量为64。为防止过拟合,模型采用 dropout 正则化。本文选择添加速率值等于0.5 的 dropout层用以防止过拟合,最后使用2标签softmax分类层,自定义CNN网络结构见图4所示。

图4 自定义CNN模型结构示意图Fig.4 Schematic diagram self-defined CNN
2.1.2 调整后的VGG-16结构
迁移学习即将网络中每个节点的权重从一个训练好的网络迁移到一个全新的网络里,VGG-16网络权重由ImageNet训练而来,具备较强的深度特征学习能力[23]。本文研究的数据集较小,数据跟ImageNet数据相似度不高,为使VGG-16更符合本文数据要求,又避免训练整个网络,减少网络训练时间和提高网络训练效率,研究使用迁移学习和模型微调的方法,在编译和训练模型之前将网络冻结第二层到最后一层,同时重新定义密集连接分类器,用2标签Softplus分类器替换原有的Softmax分类层,最后使用Adam优化器优化网络。调整后的VGG-16刺网和拖网航迹图识别流程框架如图5所示。
2.2 图片集预处理
根据1.3.2航迹图生成方法生成拖网和刺网航迹图。图6~图7为刺网和拖网航迹作业轨迹示意图。
图片在训练前首先会把每张图片的每个像素值乘以放缩因子1/255,把像素值放缩到0和1之间,将所有的图片统一归一化为模型指定大小(图8中的示意图已统一处理成224×224大小);因数据集较小,实验利用Keras的内置ImageDataGenerator图像增广技术在模型训练时来随机扩充数据集。本文在不影响图片语义的基础上选择2种方式对数据集扩充:1)将图片进行错切变换,即让点的x坐标(或者y坐标)保持不变,而对应的y坐标(或者x坐标)则按比例发生平移,且平移的大小和该点到x轴(或y轴)的垂直距离成正比,错切变化系数设置为0.2;2)将图片随机放缩到宽/高×(0.8~1.2)范围内;通过以上操作实现对图像的增广。图8为同一张图片进行以上操作效果图。

图5 VGG-16刺网和拖网航迹图识别框架Fig.5 VGG-16 gill and trawl track picture identification frame
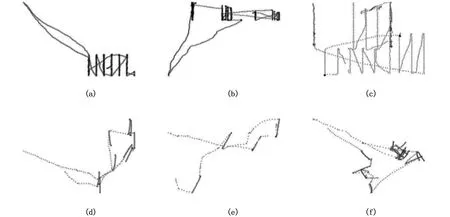
图6 刺网航迹图 Fig.6 Gill track 注:a、b、c:定置刺网;d、e、f:流刺网Note:a, b, c: set gillnet ;d, e, f: drift gillnet

图7 拖网轨迹图Fig.7 Trawl track注:a、b、c: 拖网Note:a, b, c: trawl net
2.3 训练精度和损失
实验在ubuntu16.04操作系统下搭建Keras框架进行,使用NVIDIA Tesla v100加速训练网络。将数据集划分为训练集和验证集,训练集由刺网9 999张航迹图、拖网9 436张航迹图组成;验证集由刺网1 911张航迹图、拖网2 142张航迹图组成,在训练集上训练模型,在验证集上评估模型。本文的实验过程顺序为:1)对输入图片大小进行选取;2)对自定义的10层CNN和调整过后的VGG-16做比较,选取较优的模型;3)增大轮次epoch(即训练的轮数),观察模型能达到的精度是多少,即模型在迭代多少轮可以达到最优的精度。因轮数(epoch)设置过大训练时间太长,并且模型初实验在第10轮左右时就已经达到87%的准确率,故在实验1)、2)步骤中将epoch设置为100,确定模型结构和图片输入大小后,再将epoch调大观察。
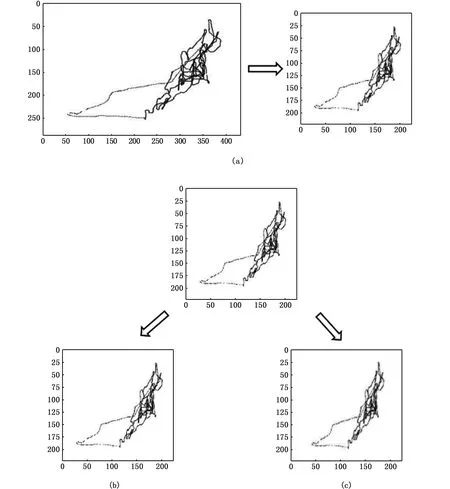
图8 图片增广操作效果图 Fig.8 effect picture after image augmentation 注:a. 432×288原图归一化为224×224效果图; b. 归一化为224×224的图片进行系数为0.2的错切变换; c. 归一化为224×224的图片进行系数为0.2的放缩Note: a. original 432×288 picture normalized to 224×224; b. 224×224 picture after shear transformation by coefficient 0.2; c. 224×224 picture after zoom by coefficient 0.2
首先对输入图片大小进行选取,分别对输入图片大小为150×150、224×224和438×288的数据集进行迭代100轮,统一使用上述调整后的VGG-16网络,模型训练采用批处理方式,batch大小设置为32,不同输入图片大小的训练集精度和损失性能如图9所示。不同的输入图片大小在训练集的表现有一定的差距,根据精度和损失变化(图9),可以认为224×224大小的图片整体上比其他两种大小的图片训练精度要高,并且在刚开始迭代时就能达到比较高的精度。因此实验把输入图片的大小确定为224×224。
本研究涉及的两种模型中,CNN刚开始迭代精度比VGG-16低,第10轮左右开始CNN的精度要高于VGG-16,在模型损失上也呈现出相同的情况(图10)。本文设计的CNN和调整过的VGG-16相比,自定义的CNN精度要高于调整后的VGG-16,CNN模型迭代100轮最终的精度为94.07%。故实验最终选择自定义的10层CNN模型。
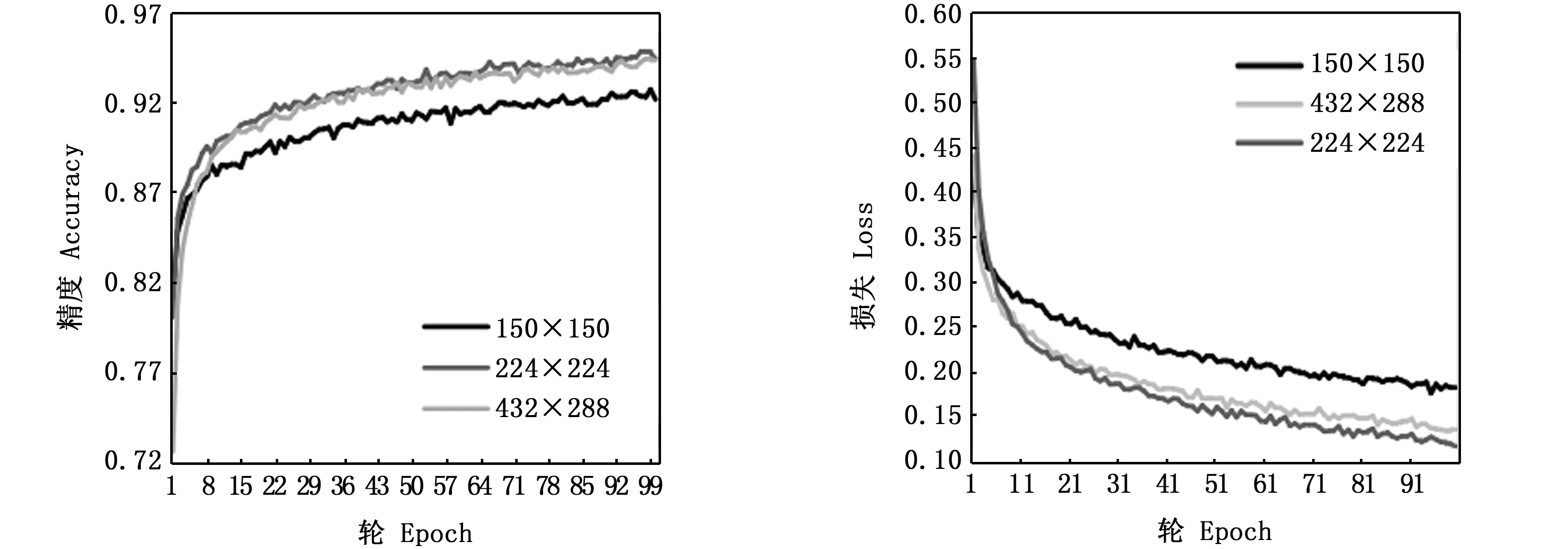
图9 不同图片大小训练集精度和损失Fig.9 Train accuracy and loss of different input image sizes
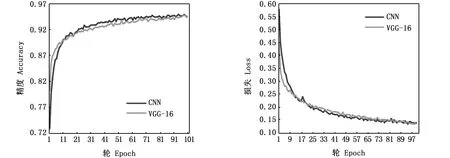
图10 VGG-16和自定义CNN训练集精度和损失对比Fig.10 Accuracy and loss comparison of train data between VGG-16 and self-defined CNN
在一定程度上,迭代次数越多,模型的训练集精度越高(图11),超过80轮左右,模型验证集的精度不再继续提高,损失也开始上升(图12),所以模型迭代80次便可以停止,迭代80次自定义的10层CNN模型训练集最终的精度为94.3%,验证集最终精度为93.6%。
3 讨论
3.1 刺网和拖网轨迹特征
刺网大体可分为流刺网和定置刺网。图6 中(a)(b)(c)为定置刺网,(d)(e)(f)为流刺网。流刺网作业一般先是航行,作业区域轨迹点比较笔直,图中表现为一段黑且直的直线,放大后可以看到直线的端点有个密集的点。定置刺网和流刺网轨迹点图的区别为:定制刺网作业区域的轨迹线条一般比流刺网直,直线段更密和黑,放大后直线端点大部分没有密集的点。相比刺网轨迹点图,拖网的轨迹点图没有突出的特征,拖网的轨迹点图特征可归结为:乱、多、密,一般不会形成像刺网一样简洁有规律的线条。

图11 自定义CNN精度Fig.11 Accuracy of self-defined CNN
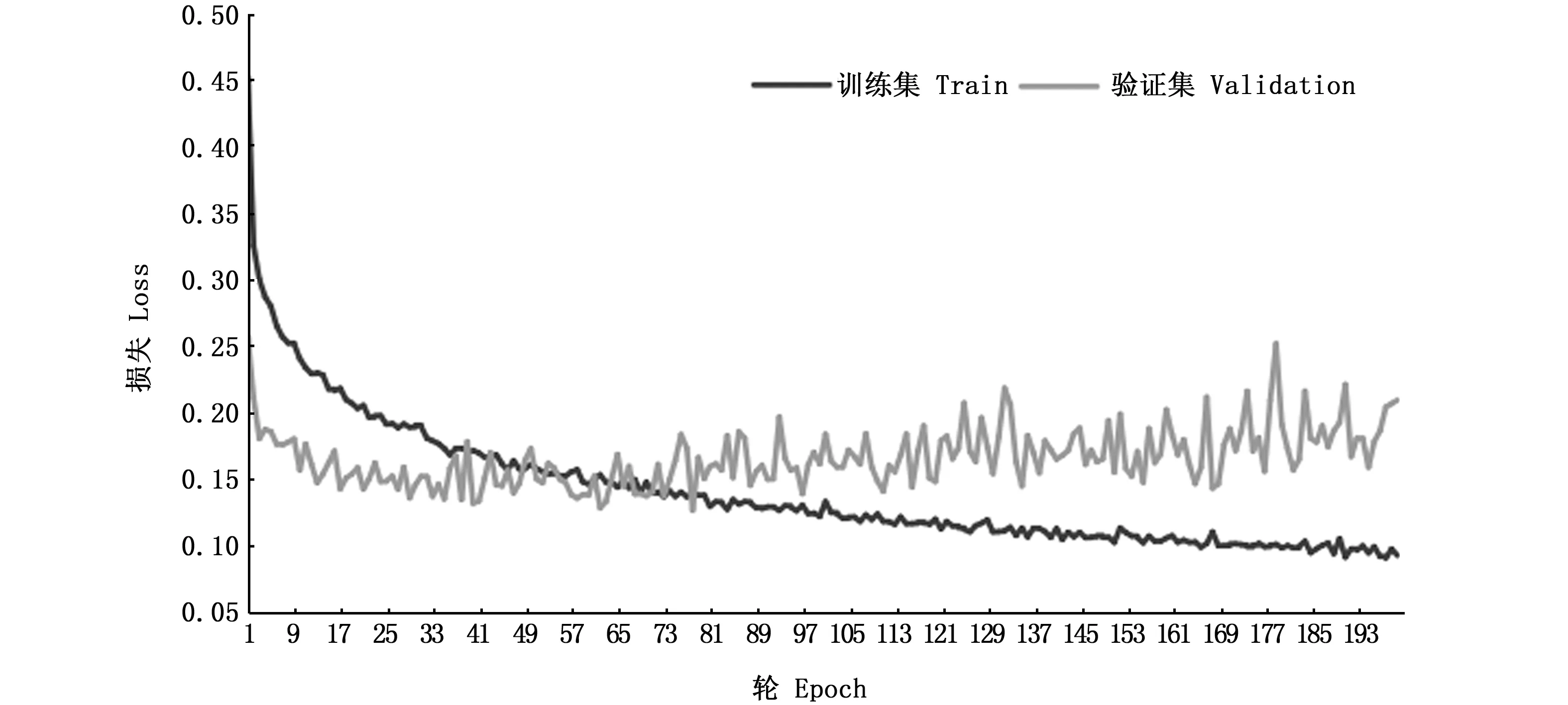
图12 自定义CNN损失Fig.12 Loss of self-defined CNN
以上是刺网和拖网理想的轨迹点图规律特点。剔除的图片如图13,包含:a) 航次不完整,即航次轨迹点出现断层;b) 轨迹点过于稀疏混乱不清晰;c) 没有特征点的轨迹图。同时结合以上刺网和拖网的作业特点,剔除可能证业不符、存在问题的图(即登记作业为拖网,图片明显为刺网;登记作业为刺网,图片明显为拖网;或明显既不是刺网也不是拖网的图)。
3.2 误差分析
关于数据集,可能存在以下几点影响模型的最终精度:1)渔具使用混杂。存在改变注册作业类型的情况,即一艘船在不同的渔汛期使用不同的渔具进行生产,不完全按照注册渔具生产,使得训练数据中可能存在记录是刺网或拖网但实际上是其他渔具作业的情况;2)航次提取存在误差。航次记录分为两种情况,一种是起航、海上作业、返航过程完整,另一种是航次信息不完整,即只记录了3个阶段的某一、两个阶段。航次不完整的原因主要是北斗卫星数据受信号干扰、信道占用、供电不足或断电等影响,导致船位数据丢失,或者统计时间段出现一些航次被分割到不同时间段,同时航次提取中数据处理不够精细可能会导致结果有些误差[24];3)人为剔除数据存在误差。即批量出图后需要人为剔除一些质量不佳的图片数据。1)和2)中的问题可以根据人工剔除图片操作解决,即只选取数据质量好的航次图片进行学习训练,可能存在有些船位点太少使图片本身反映不出具体是哪种捕捞作业的图片未被剔除,或存在1)和2)中问题的图片未被剔除,从而混入模型中影响精度。3)中人工剔除图片操作的误差很小,基本不影响本文根据深度学习对刺网和拖网作业分类识别的可行性。
3.3 模型优化
CNN主要的经典结构有很多,不同的网络在本数据集上的表现可能不同,本文仅讨论了两种网络,可以尝试研究其他的网络,对比分析不同网络在刺网和拖网分类上的性能。卷积神经网络中,有大量的预设参数,例如卷积层的卷积核大小、卷积核个数、激活函数的种类、池化方法的种类、网络的层结构等,可以尝试改变以上参数,如本文自定义的CNN模型可以尝试增加或减少相应的层数或改变卷积核大小,VGG-16可以尝试冻结前k个层,然后重新训练后面的n~k个层等;也可以改变与训练有关的参数,如batch的大小、学习率等,后续研究可以根据以上结果对模型进行优化。
3.4 渔船作业类型的分类研究分析
捕捞渔船作业种类较多,分类方式根据不同的标准也有多种,本文获得的VMS数据将渔船作业分为了7种,分别是刺网、拖网、张网、围网、钓具、笼壶和杂渔具。因获得的数据不均,差距较大,对于本文3.2中讨论的渔具混杂问题,这7种类型数据前期人工处理的难度较高,处理的误差将会变大,使得训练集误差增大,同时其他类型船位点特征不如刺网和拖网船位点特征明显,利用CNN方法能否对所有的渔船作业类型轨迹图进行区分识别还有待进一步研究;刺网和拖网作为典型的捕捞作业方式,现有的数据量大且质量较好,后续可通过细致的处理提高数据本身的精度,扩大分类种类,改变全连接层的分类个数,利用本文实验的模型对几种不同的作业方式进行识别研究。
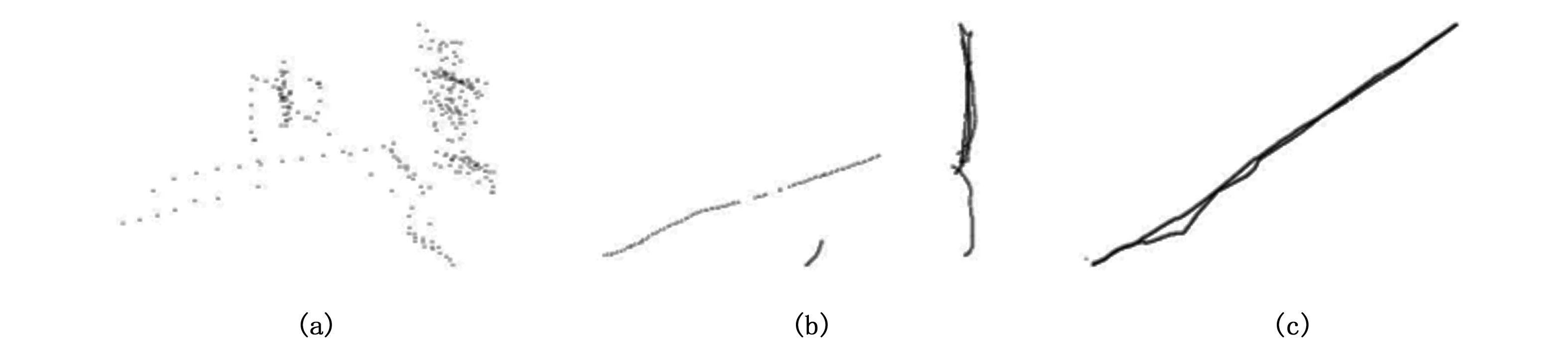
图13 剔除的航迹图示例Fig.13 Eliminated track picture注:a. 船位点过于稀疏混乱; b. 航次不完整; c. 没有特征点Note: a. sparse and chaotic position points; b. incomplete voyage; c. no characteristic point
4 小结
本文根据拖网和刺网北斗VMS数据生成了拖网和刺网多个航次的航迹点图,然后将航迹点图输入到自定义的10层CNN模型以及利用迁移学习和模型微调方法调整后的VGG-16模型中,经过对比实验,自定义的CNN模型精度整体上要高于调整后的VGG-16模型,最终自定义的10层CNN模型训练集精度为94.3%,验证集精度为93.6%,证明了本文方法的可行性,使用深度学习方法对刺网和拖网VMS航迹点识别分类具有较高的准确率,为渔船作业的识别分类提供了新思路,本文仅对两种作业类型进行了识别研究,后续可细致区分不同作业类型之间的区别,提高研究数据的准确度,对所有的作业类型进行区分识别。北斗VMS可以大范围快速的获取渔船信息,现有的研究并没有完全挖掘出VMS信息的价值,仅集中于对VMS几种数据进行研究,研究方法尚较固定单一,今后的研究可以改进研究方法和思路,进一步提高数据的准确性,挖掘出VMS数据更多有价值的信息,为渔业发展提供科学有效的参考。
猜你喜欢
北京航空航天大学学报(2022年7期)2022-08-06
舰船科学技术(2022年11期)2022-07-15
测绘地理信息(2022年2期)2022-04-02
农业科技与信息(2020年18期)2020-12-18
雷达科学与技术(2020年4期)2020-09-11
华东师范大学学报(自然科学版)(2019年2期)2019-06-11
导航定位学报(2017年2期)2017-06-10
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27
集装箱化(2014年10期)2014-10-31
