
知识库问答系统中实体关系抽取方法研究
2020-06-09 07:22张芳容
计算机工程与应用 2020年11期
张芳容,杨 青
武汉理工大学 计算机科学与技术学院,武汉430063
1 引言
随着信息技术的飞速发展,出现了以搜索引擎为代表的信息过滤机制。传统的搜索引擎基于关键字检索,难以理解问句的语义信息。知识库问答(Knowledge-Based Question Answering,KBQA)系统以自然语言问句为输入,对问句进行分析理解后检索知识库,输出简洁、准确的自然语言答案。知识库(Knowledge Base,KB)是一个存储事实类信息的结构化系统,典型的知识库用三元组(主体,谓词,对象)来存储事实。常见的知识库问答包括单一关系问答和多关系问答,前者指的是答案只涉及一条三元组,后者则涉及多条三元组。
现有的知识库问答方法主要分为三类:(1)基于语义分析的方法。该类方法将问句转换为可在知识库中进行检索的逻辑表达式,如谓词逻辑(λ)表达式[1]、依存组合语义(DCS)表达式[2]、λ-DCS表达式[3]等。该类方法可用于多关系问答,但是逻辑符号与自然语言之间存在语义鸿沟。(2)基于信息检索的方法。该类方法首先从问句中抽取实体和关系,然后检索知识库。如Yao 等人[4]从问句中抽取主题词,构建问句的关系图,与知识库匹配;Bast等人[5]提出基于排序模型的自动问答方法;王玥等人[6]提出基于动态规划的问答方案。该类方法可以实现多关系问答,但是不能借助实体的上下文信息对实体消除歧义。(3)基于深度学习的方法。该类方法将问句和知识库映射到同一向量空间,将问答过程转换为问句向量与知识库向量进行相似度计算的过程[7]。如Bao等人[8]提出一种基于机器学习的类翻译模型;Hao等人[9]利用TransE[10]模型训练实体和关系的向量表示。该类方法只能获得一条与问句最相似的三元组,仅适用于单一关系问答。
在英文知识库问答领域,多关系问答已经取得了很好的成就,但在中文领域,大部分研究都是针对单一关系问答[11-13]。因此,本文基于NLPCC-ICCPOL 2016 年提供的知识库,对中文开放领域知识库问答做进一步探索。上述三种方法各有优劣,本文拟采用深度学习、信息检索和语义分析相结合的方法,对多关系问答进行探索。本文提出将知识库问答分为实体识别、实体关系抽取和答案检索三个子任务。在实体识别阶段,获取问句中的实体并将其与知识库中的术语对应,得到实体集合。在实体关系抽取阶段,抽取问句中的关系词,将关系词与知识库中的谓词对应,得到关系集合,然后将问句对应的实体集合和关系集合转换为具有语义信息的三元组集合。在答案检索阶段,将三元组转换为查询语句,然后应用查询语句在知识库中检索。本文重点讨论实体关系抽取的实现方法。
2 问题定义与知识库问答整体流程
2.1 问题定义
考虑到自然语言问句理解的复杂性,本文对问句q进行了以下限定:
(1)限定问句q 中只包含一个疑问句,如问句“姚明的妻子是谁?”。
(2)限定问句q 中不包含代词作为主语的成分,如问句“姚明的妻子是谁,她有多高?”。
2.2 知识库问答整体流程
本文的知识库问答系统包括两大模块,一是知识库的整理与存储;二是自然语言问句理解与答案检索。前者为知识库问答提供数据基础,后者为问答的具体过程。整体流程如图1所示。
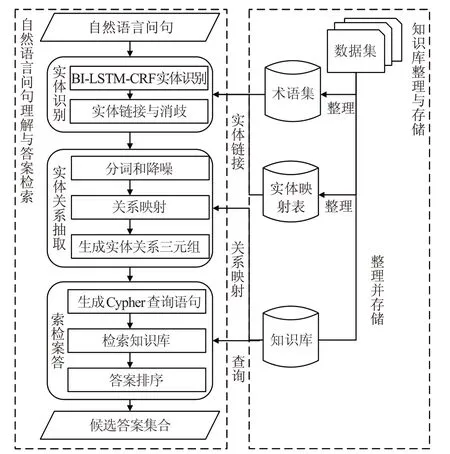
图1 KBQA系统整体结构图
图1 中,知识库的整理与存储的目的是对知识库进行降噪处理,然后将三元组形式的知识库存储在图形数据库Neo4j中,为答案检索提供支持。术语集为知识库中独立存在的主体和对象构成的集合;实体映射表中存储的是术语别名与术语之间的对应关系。
自然语言问句理解与答案检索的目的是分析理解自然语言问句并检索知识库得到候选答案,主要包括以下三个步骤:
(1)实体识别。引入BI-LSTM-CRF(Bi-direction Long Short-Term Memory Conditional Random Field,双向长短时记忆网络-条件随机场)序列标注模型[14]对问句q进行标注,通过对标注序列进行进一步解析,产生实体集合TE={te1,te2,…,tek} 和非实体集合OTHER={o1,o2,…,on},tei和oi中保存了实体或非实体的字符串和位置索引。针对每个实体tei,在知识库中找到若干术语与其链接,为了减少冗余,将问句与候选实体进行相似度计算,取得分最高的3个术语作为最终的候选实体集合Ei={e1,e2,…,em}( )m ≤3 。最后,实体识别步骤的输出为问句中与知识库术语对应的实体集合E={E1,E2,…,Ek},以及非实体集合OTHER={o1,o2,…,on}。
(2)实体关系抽取。引入确定有穷自动机(DFA)算法,对非实体集合OTHER进行降噪处理,找到OTHER中描述关系的词语P={p1,p2,…,pd}。针对每个词语pi,在知识库中找到与pi相似度最高的谓词ri作为最终的关系,从而得到关系集合R={r1,r2,…,rc}。然后结合集合E 和R 生成实体关系三元组集合T 。
(3)答案检索。根据实体关系三元组集合T 中三元组之间的关系或者三元组内部元素之间的关系,将三元组转换为结构化查询语句,应用查询语句检索知识库,得到候选答案。
3 支持多关系问答的实体关系抽取
3.1 实体关系抽取整体流程
在实体识别步骤中,获取了问句中的实体集合E和非实体集合OTHER。实体关系抽取指的是从集合E 和OTHER 中抽取实体之间的关系,是支持多关系问答的关键步骤。本文将实体关系抽取分为关系词提取、关系映射和生成三元组三个主要步骤,具体流程如图2所示。

图2 实体关系抽取流程
3.2 关系词提取
为了避免与用户意图无关的词语对关系词提取造成影响,首先采用DFA 算法对OTHER 进行噪音词过滤;然后对剩余部分进行分词、词性标注和去停用词处理;最后,根据词性特征提取关系词。
本文采用哈工大语言云平台LTP[15]进行分词和词性标注,LTP使用的是863词性标注集。一般而言,问句中的关系词多为名词和动词,因此,本文在进行词性标注后,保留名词(如词性为n,nd,nh,ni,nl,ns,nt 等)、动词(如词性为v)、其他词语(如词性为ws,i,j,a,q,d,m,z,b 等)以及疑问代词作为候选关系词。
在自然语言问句中,既可以用一个词语表达查询意图,也可以通过由多个词语构成的短语表达查询意图。即关系词可能只包含一个词语,也可能包含多个词语。因此,本文定义了关系词合并规则,如表1所示,将提取出来的关系词进行合并,在合并过程中同时更新关系词的索引,如果合并的关系词包含疑问代词,则将疑问代词的索引更新为关系词后面的索引。最终得到关系词序列P={p1,p2,…,pd}。

表1 关系词合并规则
3.3 关系映射
上述步骤得到了一组关系词序列P={p1,p2,…,pd}。关系词与知识库中的谓词在字符串上可能不完全匹配。因此,需要将关系词pi(pi∈P)与知识库中的谓词进行映射,得到最终的关系ri,对ri进行筛选,获取关系集合R={r1,r2,…,rc},称为“关系映射”。
问句中的关系词与知识库中的谓词通常在字符串或者语义上高度匹配。因此,关系映射中的相似度得分采用字符串相似度和语义相似度相结合的度量方式。字符串相似度采用编辑距离相似度[16]实现,如公式(1):
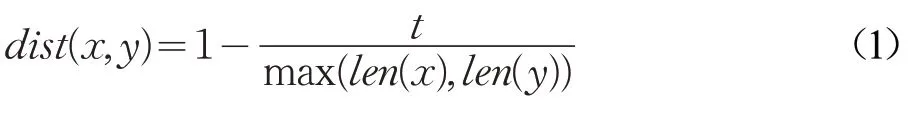
其中,x 和y 分别表示关系词和候选谓词字符串,t 表示x 经过删除、替换、增加后转换为y 所需要的步数,len(⋅)表示字符串的长度,max(⋅)表示求最大值。
语义相似度采用归一化后的余弦距离相似度实现[17],如公式(2):

其中,x 表示关系词的向量表示,y 表示候选谓词的向量表示。
最后,结合编辑距离相似度和语义相似度,度量关系词与谓词之间的相似度,如公式(3):
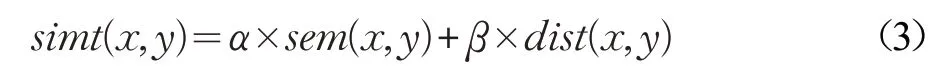
其中,x 和y 分别表示关系词和候选谓词。为了防止在提取关系词的过程中提取了与查询意图无关的关系词,设置阈值δ,当相似度小于δ 时,直接将二者的相似度值设为0。最终的相似度计算公式如式(4):
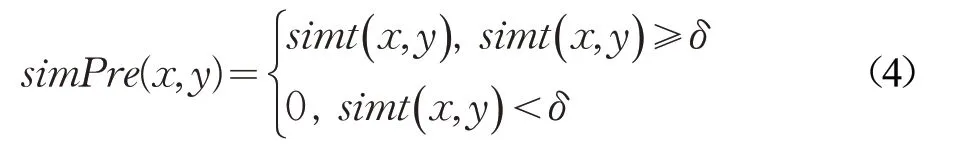
由于自然语言问句的复杂性,多个连续关系词可能同时表达一个查询语义。为此定义“舍弃与保留”规则。即对于关系映射得到的关系r ,如果r 与关系集合R 中的最后一个关系相等,并且在问句中二者连续出现时,舍弃r;否则,保留r。
关系映射的具体过程如算法1。
算法1 关系映射算法
输入:实体E={E1,E2,…,Et},关系词P={p1,p2,…,pd}
输出:映射后的关系词集合R={r1,r2,…,rc}
1. E 在知识库中前后|P|步范围内的关系集合S={s1,s2,…,sk}
2. last=null #(pos,old,new)
3. for each a ∈P do:#(value,index,tag)
4. max=(‘’,0) #(value,score)
5. for each s ∈S do: #S 为知识库中的谓词
6. temp=simPre(s,a.value)#计算关系词与谓词的相似度
7. if temp >max.score then:
8. max=(s,temp)
9. end if
10. end for
11. if max.score ≠0 then:
12. if last==null then:
13. R ←R ⋃{(max.value,a.pos)}
14. else if max.value!=last.new or last.pos+len(last.old)!=a.pos
15. then:
16.R ←R ⋃{(max.value,a.pos)}
17. end if
18. last=(a.pos,a.value,max.value)
19. end if
20. end for
21. return R
3.4 三元组生成
中文开放领域问答中,根据问句中包含的实体和关系的个数分为单一关系问句和多关系问句。其中,单一关系问句中包含一个实体和一个关系(SS)。多关系问句分为三种情况:包含一个实体和多个关系(SM)、包含多个实体和一个关系(MS)、包含多个实体和多个关系(MM)。结合实体集合E 和关系集合R,针对这四种类型定义生成三元组的规则,三元组中未知元素用'X'、'Y'等符号表示。
(1)SS生成三元组
问句中仅出现一个实体和一个关系,即实体集合为E={ E1} ,关系集合为R={r1} ,对于实体e(e ∈E1,根据e、r1和疑问代词的相对位置生成三元组。若r1出现在e 之后,则生成三元组(e,r1,'X');否则生成三元组('X',r1,e)。
(2)SM生成三元组
问句中包含一个实体和多个关系,即实体集合为E={ E1} ,关系集合为R={r1,r2,…,rc} 。此时实体与候选答案之间可能存在级联关系或者并列关系。对于实体e(e ∈E1,针对这两种情况生成三元组集合{(e,r1,'A'),…,(e,rc,'A'+c-1)}和{(e,r1,'A'),('A',
r2,'B'),…,('A'+c-2,rc,'A'+c-1)}。
(3)MS生成三元组
问句中包含一个实体和多个关系,即实体集合为E={E1,E2,…,Em} ,关系集合为R={r1} 。对E 中元素进行组合,得到集合TS,即对于U ∈TS,U 中的每个元素ei,分别来自于Ei。将U 中的每个实体e(e ∈U分别与r1组合生成三元组,得到一组三元组集合,每个三元组的形式为(e,r1,'A')。
(4)MM生成三元组
问句中包含多个实体和多个关系,即实体集合为E={E1,E2,…,Em} ,关系集合为R={r1,r2,…,rc} 。对E中元素进行组合,得到集合TS,对于集合U(U ∈TS),根据U 和R 的长度关系,可以分为以下三种情况:
① ||U =2, ||R =0,表示查询两个实体之间的关系,生成三元组(e1,'X',e2)。
② ||U =2, ||R =3,表示两组实体关系确定一个中间实体,候选答案与中间实体的关系已知,生成三元组{(e1,r1,'M'),(e2,r2,'M'),('M',r3,'X')}。
③ ||U >1, ||R >1,表示查询每个实体的|R|个关系,生成三元组集合{(e1,r1,'A'),…,(e1,rc,'X')},…,{(en,r1,'A'),…,(en,rc,'X')}。
4 实验结果及分析
4.1 数据集与实验环境
本文使用的数据集为NLPCC-ICCPOL 2016KBQA子任务发布的知识库和问答对(NLPCC[18])和多关系问答对(NLPCC_MH[6])。根据问答对反向查找对应的三元组,构造知识库问答的数据集。去掉未找到三元组的问答对,将剩余数据集划分为训练集、验证集和测试集,如表2所示。

表2 数据集划分
本文的实验平台运行在配置3.5 GHz、八核处理器、12 GB 运行内存的笔记本上,编译环境为PyCharm Community Edition 2018,操作系统为64 位的Windows 10。知识库采用Neo4j 3.4.0进行存储。采用Google提供的word2vec工具利用中文维基百科语料库训练词向量,词向量的维度为300,窗口大小设置为5,最小出现次数为5。
4.2 关系映射阈值选择
在关系映射阶段,公式(3)中的编辑距离相似度和语义相似度的权重均为0.5,在此基础上选择阈值δ 。若δ 设置过小,则引入了与查询意图无关的关系;设置过大,则遗漏了用户的查询意图。首先,根据实际情况为δ 估计一个合理的区间[a,b],然后在区间[a,b]内进行实验。考虑到极端情况下,公式(3)中编辑距离相似度为0,但是语义相似度接近1,综合相似度得分接近0.5。因此,设置区间上限b 为0.5,区间下限a 为0。将δ 在区间[0,0.5]上取值,然后进行实验,计算训练集、验证集和测试集上进行关系映射的准确率。实验结果如图3所示。

图3 不同阈值下的关系映射的准确率
由图3 可知,当δ ∈[0.25,0.35]时,关系映射的准确率较高。因此,本文将δ 取值为0.3,δ=0.3 时,在NLPCC 测试集和NLPCC_MH 测试集上的准确率分别为91.17%和87.4%。
4.3 问答结果及分析
将以上结果应用于知识库问答系统。在答案检索阶段,将实体关系抽取中获得的三元组集合,根据三元组之间的关系,或者三元组内部元素之间的关系,以及三元组中的已知元素和未知元素,生成Cypher 查询语句。如问句“我想知道王思聪的爸爸有什么成就?”经过上述步骤生成的部分三元组集合T={{(王思聪,父亲,'A'),('A',主要成就,'B')}}。首先根据三元组中主体、谓词和对象的个数,生成的MATCH子句,其中包含3个实体和2 个关系,即“MATCH(a:entity),(b:entity),(answer:entity),(a)-[r1]->(b),(b)-[r2]->(answer)”;根据三元组中的已知元素,生成的WHERE 子句,其中包含1 个实体和2 个关系,即“WHERE a.name='王思聪'and r1.relation='父亲' and r2.relation='主要成就'”;最后,返回查询的内容,即“RETURN answer.name;”。将查询语句在知识库中执行,得到候选答案。
问答结果的评测标准为NLPCC-ICCPOL 2016 指定的平均F1值(Averaged F1),即所有问句的F1值之和的平均值。每个问句的F1值可以通过精确率和召回率计算得到。精确率和召回率的计算公式分别如下:

其中,A 为给定的答案集合,C 为知识库问答系统检索得到的答案集合,|A| 和|C| 分别表示集合的大小,|A ⋂C|表示两个集合的交集的大小。F1 值由公式(5)和(6)计算可得,如公式(7):
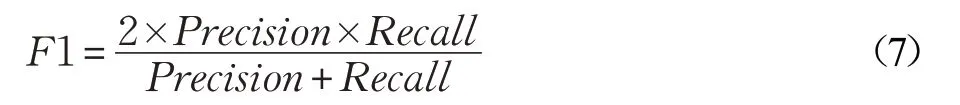
最后,平均F1值的计算公式如式(8),其中,Q 表示问句集合,|Q|为问句的总个数。

知识库问答系统在NLPCC 和NLPCC_MH 测试集上的评测结果如表3所示。
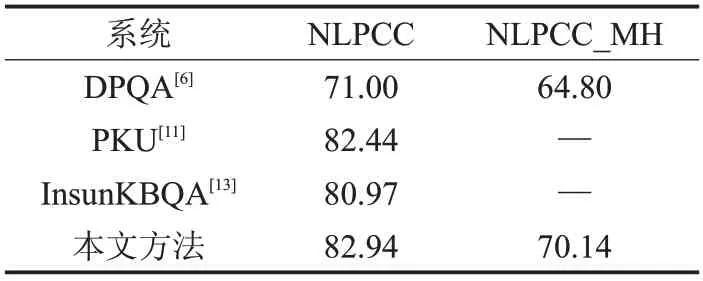
表3 知识库问答Averaged F1 %
表3 中,PKU[11]是NLPCC-ICCPOL 2016 年评测结果最佳的系统。InsunKBQA[13]是周博通等人在相同数据集下进行探索的系统。DPQA[6]是王玥等人在2018年的全国知识图谱与语义计算大会(CCKS)上使用与前者相同数据集对知识库问答进行探索的系统,王玥等人还构建了多关系问答对数据集,研究了中文领域的多关系知识库问答。
本文的知识库问答方案与PKU 相比,达到了与其相近的效果,但是PKU专注于单一关系问答,在多关系问答中则不具备有效性。同样,InsunKBQA 系统也专注于单一关系问答,并且无法识别选择型疑问句的关系,如“TCL 是国企还是私企呀”这一类问句,本文的方案在此有所提升。虽然DPQA可以支持多关系问答,但存在一定的局限性,该系统只适用于实体出现在所有关系之前,且候选答案与已知实体具有级联关系的问句。而对具有并列关系的问句并不适应,如“姚明和叶莉的身高分别是多少?”这一类问句。本文提出的方案在多关系问答方面与其相比有所提升。
5 结束语
本文提出将知识库问答分为实体识别、实体关系抽取和答案检索三个主要步骤,重点讨论了实体关系抽取的实现方法。在实体关系抽取步骤中,引入DFA 算法对非实体部分进行降噪,提出基于规则的方法从问句中提取关系词序列,然后利用相似度得分将关系词与知识库中的谓词进行映射,得到关系集合,最后将问句中的实体集合和关系集合转换为具有语义信息的三元组集合。实验结果表明,本文提出的方法支持多关系问答,在NLPCC 和NLPCC_MH 测试集上具有较高的平均F1值。
本文的方法虽然解决了多关系问答,但是在实体关系抽取过程中,关系映射的准确率较低,对问答结果产生了影响。因此,下一步的研究重点是结合深度学习的方法构建一个端到端的实体关系抽取模型,以提高问答的准确率,从而提升问答结果。
猜你喜欢
山西大学学报(自然科学版)(2021年1期)2021-04-21
——论胡好对逻辑谓词的误读
现代哲学(2020年5期)2020-11-30
西夏研究(2020年2期)2020-06-01
现代哲学(2019年4期)2019-12-14
五邑大学学报(自然科学版)(2019年3期)2019-09-06
制造技术与机床(2019年6期)2019-06-25
计算机技术与发展(2018年12期)2018-12-20
中国交通信息化(2016年9期)2016-06-06
图书馆研究(2015年5期)2015-12-07
现代防御技术(2014年6期)2014-02-28
