
多源信息融合的微服务化电网事故追忆
2020-06-09 01:19韦洪波叶桂南韦昌福何伊妮
电力大数据 2020年4期
韦洪波,曹 伟,叶桂南,韦昌福,何伊妮
(广西电网电力调度控制中心,广西 南宁 530024)
事故追忆是电网调度自动化系统的重要组成部分,是电网调度运行人员进行事故分析、调整系统运行方式和保障电网安全经济运行必不可少的工具[1],也可以为调度员培训仿真提供培训案例。
事故追忆系统由事故信息记录和事故反演两个部分组成:
(1)事故信息记录:它通过记录事故发生前后电网的各类事件顺序,例如开关断开、重合、保护动作,以及事故发生前后一段时间内的遥信和遥测数据,为事故分析提供信息基础;
(2)事故反演:在事故信息记录的基础上,结合事故发生时的网络拓扑以及其他系统记录的信息等,将当时的事故情景进行重演[1],直观的展示故障发生前后电网的运行情况。
受限于自身的存储容量和数据处理性能,事故追忆系统一般从事故发生前某一时刻开始记录电网变化的数据,而不会记录事故发生前后的所有断面数据和网架模型。这种数据记录方式可以大大减少存储资源,提高系统响应效率,但是容易造成网架模型与记录的数据不匹配,无法准确反映事故发生时的情况。采用多态思想构建的事故追忆系统,解决了事故断面与记录数据的匹配问题,但是无法有效应对大规模数据的检索与识别,系统扩展性能和响应用户操作速度有待进一步研究。
微服务(microservice)架构继承自面向服务架构(service-oriented architecture,SOA),旨在将大型复杂应用解耦为多个具有特定功能、松散自治的微服务[2]。目前,结合云计算和容器等技术,微服务架构已经在电力行业得到广泛应用,并逐步发展为新的研究热点[3]。文献[4]通过分析电力云平台的业务需求,提出采用微服务架构理念构建电力云平台的设计方案,并对平台的各个组件进行分析。文献[5]设计并实现了含微服务的分布式实时数据库,解决传统调度自动化系统实时数据库响应慢、不易扩展的问题;为了有效利用容器资源,在云计算平台上设计了一种基于微服务架构的EMS系统,将系统程序部署在容器后,提出了基于MILP的容器资源调整策略;文献[6]基于卡尔曼滤波法对突发负载进行预测,提升资源弹性供给效率。为了提高容器中应用软件的运行稳定性,采用长短期记忆神经网络(long short-term memory,LSTM)和卷积神经网络算法,从容器原始数据中自动提取恶意软件的攻击特征,用于检测及发现容器中存在的恶意软件,提前阻断潜在的攻击行为;采用深度学习中的无监督时间序列算法,通过比较当前预测流量与当前实际流量的差值,实现网络异常检测。这些工作较好的提升了容器环境下的资源利用效率,以及容器环境的网络安全性和各类应用运行稳定性,为建设微服务化的事故追忆系统提供了新的思路。
基于上述分析,应用云计算技术和容器技术,提出一种构建微服务化的事故追忆系统的方法。在云计算平台上,依据事故追忆系统的功能需求,构造了电网模型、事故记录、操作记录和人机交互四个功能独立的微服务对事故追忆系统进行重构,各服务运行在独立的Docker容器中,并通过API网关与其他服务或应用进行交互;提出了基于LSTM算法的容器资源预测调度策略,对突变负载进行预调度,有效提升系统响应性能。实验结果表明,所开发的事故追忆系统可靠性达到99.999 980%,在用户响应、扩展性和稳定性等方面具有较大的提升。
1 系统结构
1.1 微服务
微服务架构由Martin Fowler与James Lewis于2014年提出,是面向服务架构(service oriented architecture,SOA)的继承和发展。两者的区别在于:SOA架构侧重于将多个单体应用注册至企业服务总线(enterprise service bus,ESB),各应用通过ESB进行数据交互,常用于粗粒度大型企业应用系统的集成和开发[7];而微服务的核心思想是将大型应用系统按照业务逻辑和功能需求解耦为多个离散可复用、只完成单一特定的业务需求的小型服务,实现去中心化[8]。微服务运行在单独的进程中,与其他服务完全隔离,具有高度的自治性,便于搭建轻量级应用,具有很高的灵活性和可扩展性。
1.2 容器技术
容器(container)是一种轻量级、灵活的虚拟化方式。如图1所示,与传统的虚拟机不同,容器创建在操作系统层面上,本质上是宿主机上的一个进程,共享下层操作系统的硬件资源,具有独立的IP地址和操作系统管理员账户,重启单一容器不会对其他容器造成影响[9],并且内存、CPU 和存储效率得到大幅度提高。容器具有轻量级、低成本和可移植等优点。运行在不同容器中的服务实际上处于相互隔离的环境之中,可快速实现单个服务的热升级,满足负载突变的需求。
1.3 微服务化的电网事故追忆
云计算是虚拟化、分布式和负载均衡等多种计算机技术的混合体,它通过虚拟化技术将多种硬件资源抽象到计算资源池,为用户提供快捷简单的计算能力支持。与传统的计算模式相比,具有存储容量大、异地灾备和负载均衡的优势[10]。
目前云计算及其相关技术已经在电力系统得到广泛的应用[11-13],为事故追忆系统在云平台上部署奠定了良好基础。系统涉及从多个应用系统调取数据,是一个多源信息交互的系统。由于开发方式、部署环境等方面存在差异,各应用系统的数据接口和运行效率不尽相同。
本文根据实际功能需求,采用图2所示系统结构,将系统解耦为电网模型、事故记录、操作记录和人机交互四个服务,各服务只需响应与之相关的业务活动和数据交互,不需要所有服务联动,从而降低对基础平台资源的要求。此外,所有的服务均部署在云计算平台的Docker容器中,使容器中每一个独立的服务单元都能够共享云平台提供的软硬件资源环境,由于各服务之间不存在耦合关系且存在多个备份,因此服务升级过程中系统仍然可用,也不会对其他服务造成影响,保障了系统的可用性和易维护性,同时确保系统拥有充足的动态冗余资源及良好的灾备性能。通过统一API网关聚合各类服务接口,为各类终端访问提供统一的服务入口,动态调控终端用户的访问流量,实现访问入口侧的负载均衡。
2 系统实现
2.1 开发环境
所述方法在Windows 通信技术平台(windows communication foundation,WCF)上,采用Visual Studio2017作为开发工具,通过C#和JavaScript编程语言,在阿里云(alibaba cloud apsara stack)上开发和测试了微服务架构下的事故追忆系统。所开发的系统部署在Docker容器,通过IIS8.0对服务进行发布。
2.2 服务构建
用WCF具体实现了事故追忆系统下的电网模型、事故记录、操作记录和人机交互四个服务,分别对应于PNMService、ARService、ORService、HCIService四个标准的服务接口,并在接口中封装了读写信息源数据和云平台RDS、OSS的方法,各服务间的交互关系如图3所示。
事故记录服务:在触发源被启动后,从事故追忆信息源处读取预置时间段内的数据,存储在云平台的OSS中,并在RDS中对应生成一条新的记录。
电网模型服务:在事故触发源启动时,从前置系统获取当前的电网模型,并生成cim文件保存在OSS中;在事故反演时,将cim文件返回给服务消费者。
操作记录服务:读取事故发生时段的调度日志、网络发令、保护投退等调度运行人员记录的内容,并进行筛查,分析事故相关的设备操作。
人机交互服务:响应用户端的访问,生成图形界面参数,并返回显示。用户端访问时,API网关动态分配流量至人机交互服务。界面显示的内容分为“图形”和“数值”两类,人机交互服务仅提供装载图像、数据的外壳及界面交互逻辑功能,服务本身不带有数据或图形,图形和数值字符串由其他服务返回。
其他服务消费者经过API网关的审核后,可访问服务注册中心,并与上述服务建立连接关系,获得服务内定义的各类功能的返回值,完成数据交互交互。初期实现的事故追忆涉及到从前置系统、网络发令、调度日志等9个系统获取故障信息,这些系统采用SOA架构进行开发和集成,其接口注册在统一的服务总线供服务消费者检索和引用,将其接入单独的容器后,可被检索和调用。在Visual Studio 2019开发平台下添加人机交互服务引用示例如图4 所示。
2.3 服务交互
当用户端访问系统时,服务响应如图5所示。
step1:“外壳”加载。当用户链接到系统时,调用人机交互服务,响应用户端的访问请求。服务将Highcharts的底层js文件内容嵌入到网页,并发送到用户浏览器,从而搭建起显示图形的“外壳”,此过程仅在用户连接时进行一次,步骤如图5中的①-②。
step2:形成图形字符。此过程如图5中的③-⑦所示。作为服务消费者,人机交互服务通过AJAX[14],向服务提供者电网模型服务、事故记录服务和操作记录服务传递检索数据所需的关键词。服务收到关键词后,从云计算平台的OSS和RDS获取绘图的基础数据,并将绘图基础数据整理成可以在界面上直接显示的图形字符,再发送至用户端。
step3:图形显示。如图5中的⑧-11,用户端的浏览器收到图形字符后,在HTML网页上加载图形框架,再将图形字符填充在图形显示区内。完成后,按照预定义的曲线颜色和背景颜色对图形进行渲染,最终实现图形字符在用户浏览器的“外壳”中显示。
用户操作时,人机交互服务结合刷新区域,从API网关选择性的调用已注册的服务,获得可显示的字符,有针对性的对页面中响应用户操作并发生变化的部分进行更新,而不是对整个HTML页面进行刷新。这种方式可有效减少用户操作过程中的流量消耗,提升界面响应速度。
3 LSTM预测的容器调度策略
为了使事故追忆系统中各微服务具备较高的并发能力和应对突变负载能力,从云计算平台的监控系统采集各容器存储空间、网络用量、访问数,采用LSTM算法预测节点的内存使用量、CPU利用率等负载参数,提前做好预调策略,在保证系统正常运行的同时,提升资源利用率。
3.1 LSTM算法
LSTM是一种循环神经网络(recurrent neural network,RNN),相较于普通的RNN网络,LSTM能更好的消除长时间序列训练过程中存在的梯度消失和梯度爆炸问题,可高效获取历史时序数据的特征信息,在长时序预测方面具有良好的效果[15]。LSTM的结构如图6所示,由输入门(input gate)、遗忘门(forget gate)和输出门(output gate)构成[16-17],各个部分采用式(1)-(6)进行计算。
(1)
ft=σ(Wf·[xt,fht-1]+bf)
(2)
ot=σ(Wo·[xt,oht-1]+bo)
(3)
ct=ft⊗ct-1+it⊗tanh(Wc·[xt,ht-1]+bc)
(4)
ht=ot⊗tanh(ct)
(5)
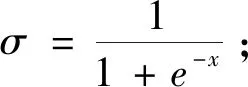
预测结果为:
yt=ht
(6)
LSTM神经网络的训练包括四个步骤:
(1)根据实际需求以及训练数据结构,确定LSTM网络的深度和神经元数量;
(2)前向计算每个神经元的输出值。即结合训练数据,通过(1)-(5)式,分别计算it、ft、ot、ct、ht五个向量的值;
(3)反向计算每个神经元的误差项。在训练过程中, LSTM的误差项反向传播存在于两个方向:一个是从当前时刻开始,沿时间的反向传播,另一个是将误差项向上传递给下一个[18-19]。
(4)根据上述步骤计算出来的神经元误差项,重新计算每个权重的梯度。依此类推,完成整个LSTM网络的训练。
2.3 容器调度策略
云计算平台监控系统采集的容器负载数据包括磁盘使用量、网络使用量、访问数、内存使用率和CPU利用率,这些数据是一种典型的非线性、动态长时间序列数据。采用LSTM算法进行动态预测时,将容器集群中磁盘使用量、网络使用量和访问数作为输入特征变量,内存使用率和CPU利用率作为输出变量,通过LSTM算法挖掘特征变量与输出变量之间的对应关系,经模型训练后,获得预测模型的网络参数,供实时调度使用。其步骤如图7所示。
Step1:从云平台监控系统中采集每个容器的内存、CPU、访问数、磁盘、网络等系统资源使用率(量);
Step2:构造数据集。访问数、磁盘、网络为输入X={x1,x2,…,xn},CPU、内存为输出Y={y1,y2,…,yn},按照8:2将其划分为训练集和测试集,并采用式(7)进行归一化;
(7)
式中:x'表示参数归一化后的值,x表示原始值,xmax、xmin分别表示序列中x的最大值、最小值。
Step3:训练LSTM模型。设置LSTM网络的窗口和预测步长,将输入数据x、ht-1和ct-1输入隐层单元,获得经过遗忘门产生的[0,1]状态值;
Step4:采用tanh函数处理step3的输出值,产生t时刻元胞的状态ct;
Step5:在输入门处,经σ函数可以得到初始输出,结合tanh函数对输出进行[-1,1]的数据缩放并与其相乘得到预测输出ht;
Step5:计算预测输出ht与实际标签的损失,采用BP算法反向调整模型的权重矩阵。
Step6:训练完成后,将实时采样数据输入最终的LSTM预测模型,输出预测值yn+1(即下一时段的内存和CPU使用率)。
Step7:将预测值返回监控系统,若上述两个指标中的任一预测值达到当前值的高于80%或低于20%,则执行容器的扩展或收缩。
4 性能分析
4.1 可靠性分析
为了不失一般性,假设各子系统、传输通道和主机可靠性相同,对所述事故追忆系统的可靠性进行分析,并与传统系统进行对比。
传统事故追忆系统的架构简图8所示,其本质是一个单体应用,整个系统的程序逻辑耦合在一起,各程序模块互相关联,任何一个环节出现问题,系统将无法使用。
虽然各个程序模块的程序逻辑不同,但是它们的可靠性指标基本一致。因此,可将其抽象为一个可修复元件。传统系统由多个程序模块组成,采用双机冗余配置,其可靠性逻辑框图可用图9表示:
所提系统架构简图如图10所示。每个系统程序模块相互独立,并由多个微服务构成,数据库被RDS取代。
所述系统可进行应用服务级别的横向拓展,其可靠性逻辑框图可用图11表示:
其中,m大于等于2。
对于任意一个可修复元件或系统,其可靠性可根据式(8)进行计算。
(8)
其中,MTBF为平均无故障时间(mean time between failure,MTBF),MTTR为平均故障恢复时间(mean time to repair,MTTR)。λ为失效率(失效次数/年),μ为修复率(修复次数/年),其定义如下:
(9)
(10)
对于n个可修复元件,若采用串联方式,有:
(11)
(12)
若2个元件为并联方式,有:
(13)
μ=μ1+μ2
(14)
由阿里云性能测试和业务实时监控服务测试可知,上述各元件的MTBF和MTTR如表1所示。
结合可靠性框图,将表1数据代入式(8)~(14)中,可得传统系统应用的可靠性及年故障时长(分钟):
(15)
所提系统的可靠性及年故障时长(分钟):
(16)
可见,所提系统的年故障时长较传统架构相比,减少了约14倍。
4.2 承压能力分析
系统部署在阿里云计算平台(alibaba cloud apsara stack)上,基础配置为3台服务器,4核8G内存,4M带宽。考虑到事故追忆系统在电网正常运行时很少使用、故障时多个用户在短时间内登陆的情况,对系统进行压力测试时,上限用户设为20个,测试结果如表2所示。
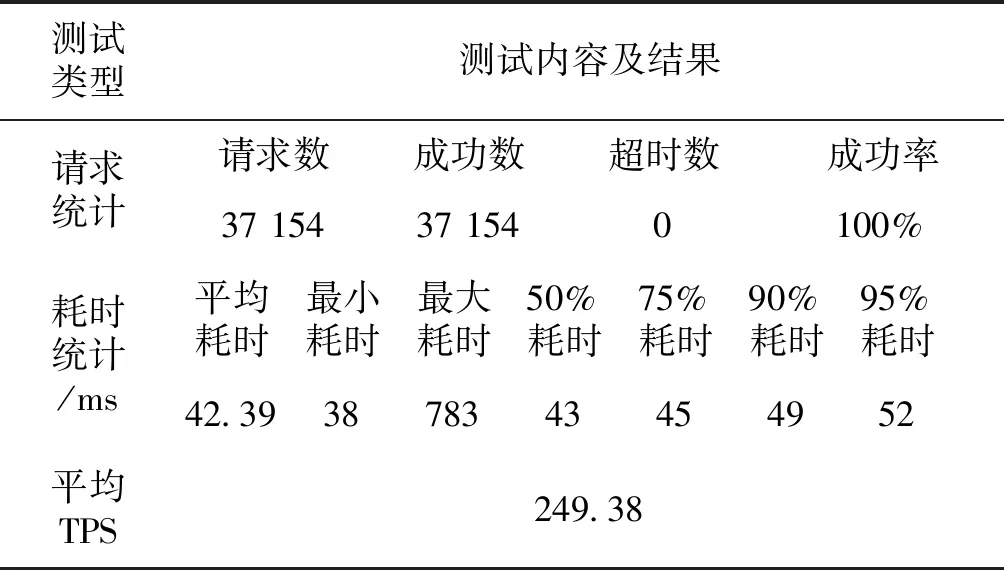
表2 系统压力测试结果Tab.2 Results of system pressure test
由表2可知:系统处理的请求数为37154,平均响应时间为42.39 ms,成功率达到100%。在多系统数据交互的情况下,无响应超时,每秒处理的事务数(TPS)达249.38,保证系统的可用性,同时具有较高的数据访问效率。
3 结论
本文提出一种大数据环境下支持多源信息融合的微服务化电网事故追忆系统设计方法。将事故追忆系统重构为电网模型、事故记录、操作记录和人机交互四个细粒度微服务,并部署在云计算平台的容器中运行,通过LSTM算法对容器资源进行预测调度,提高了系统的响应速度、处理效率和资源利用率;从前置系统、调度日志、网络发令等系统获取事故时间段内的多种事故信息,丰富了追忆信息源,为运行分析人员分析事故成因提供更好的服务,也为新一代事故追忆系统设计提供参考。实际测试效果表明,采用该方法设计的事故追忆系统可靠性高、实时性强、运行稳定可靠。
猜你喜欢
中国交通信息化(2022年9期)2022-10-28
北京航空航天大学学报(2021年6期)2021-07-20
汽车工程(2021年12期)2021-03-08
科技传播(2019年23期)2020-01-18
读者·校园版(2019年24期)2019-12-10
北京航空航天大学学报(2019年9期)2019-10-26
当代陕西(2019年16期)2019-09-25
计算机测量与控制(2019年6期)2019-06-27
考试周刊(2016年82期)2016-11-01
互联网天地(2016年1期)2016-05-04
