
基于ELM 实现对聚酯纤维工业数据质量的提高
2020-06-08 08:04周玲郝矿荣
现代计算机 2020年12期
周玲,郝矿荣
(东华大学信息科学与技术学院,上海201620)
0 引言
目前,虽然对数据质量的定义有很多,但依然缺少统一的定义[1]。表1 从多个维度对数据质量进行定义与评判[2]。
如果按照对采集数据的来源进行分类,单一来源的数据存在的质量问题称为单数据源问题,多个来源的数据存在的质量问题称为多数据源问题。
按照数据质量问题所在的层次来分类,如果数据质量问题出现在模式层,那么造成这种情况的主要是因为缺少完整性约束、设计模式不合理、结构冲突和命名冲突,称为模式层数据问题[3];如果发生在实例层,主要原因是在录入数据的过程中出现拼写错误、冗余或缺失、数据冲突和不一致,称为实例层数据问题。具体见图1[4]。

图1 数据质量问题的分类
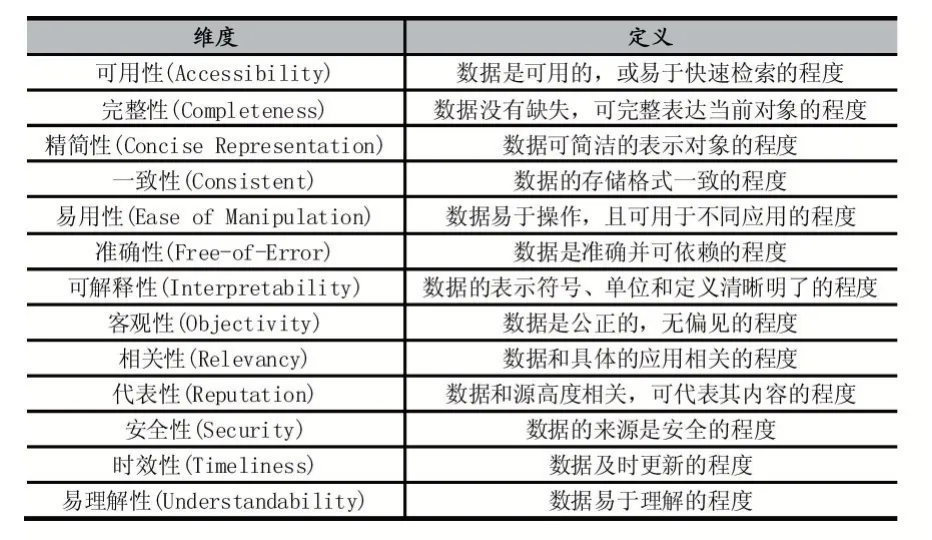
表1 数据质量维度及其定义
上述对数据质量的定义或相关描述是基于信息系统或数据库中的静态数据,即数据已从数据源获取并存储到了相应的位置,并不适用于聚酯生产从数据源实时获取数据这个过程[5]。本文根据聚酯生产的特点通过对数据质量的度量与应用进行定义,并利用ELM算法填补缺失数据,从而对聚酯纤维数据质量进行提高。
1 聚酯生产数据质量评估
1.1 数据质量在聚酯生产实时数据流中的度量与应用
目前,聚酯生产实时数据流中关于数据质量的定义、度量及应用的相关研究很少。基于数据质量的聚酯生产过程的数据采集和传输技术应用于无线传感器网络,主要是为了在有限的网络资源和庞大的数据量的约束条件下,能够最大化多任务并行的无线传感器网络中总体数据的可靠性。图2 是并行执行三个任务的传感器网络示意图[6],S1,S2,…,S5分别表示聚酯生产工艺过程其中的5 个源数据节点,它们获取数据并将其传输给聚合、熔体输送和纺丝各个工业过程的接收器节点d1,d2,d3。sink 节点对应任务,在源数据节点中,某些感知节点可以为不止一个任务提供数据,例如节点S3提供数据给任务1,2 和3,节点S4提供数据给任务2 和任务3。节点S6,…,S10不采集数据,它们是数据传输节点。线当中的数字为任务代号。可以看出,同一条链路可以服务于不同的传输任务。
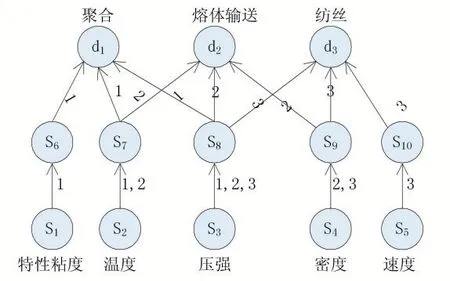
图2 有三个并发任务的传感器网络说明图
在聚酯纤维工业现场的无线传感器网络中有大量的关于现场参数的连续查询操作,将对聚酯生产现场参数的查询结果的准确性和时延性组合定义为关于聚酯生产数据质量的目标函数[7]。查询到达时,首先查找符合条件的结果是否存在于高速缓存中,若有符合条件的结果,返回结果值,若没有,请求无线传感器网络更新数据并提供查询结果。
面向聚酯生产的数据流应用系统构建了聚酯生产工业数据的数据质量框架,该框架是基于聚酯生产数据的,具体见图3。聚酯生产数据是框架的核心,其中存储与数据质量有关的所有元数据,如衡量聚酯生产工业数据质量的维度以及相关的判定方法等[8]。在对聚酯生产数据流进行处理时,对数据质量基于聚酯生产数据进行处理。该质量框架为聚酯生产数据流应用系统提供基于内容、查询以及应用的数据质量模块服务。
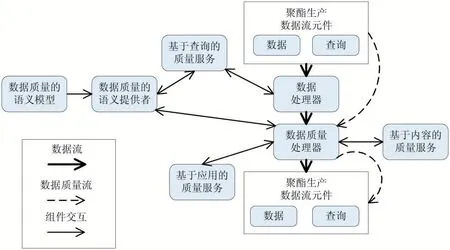
图3 基于聚酯生产数据的数据质量框架结构图
1.2 聚酯生产数据质量的判定规则
(1)准确性度量
在聚酯纤维工业生产中,数据的准确性是指数据准确、不存在异常或错误以及可依赖的程度[9]。常见的影响数据准确性的错误有乱码、过大的异常值或过小的异常值等[10]。假设:

则数据的准确性定义为:

(2)完整性度量
在聚酯纤维工业生产中,数据的完整性是指数据没有缺失、可完整表达当前对象的程度[11]。若t 时刻数据流中共有N 个属性值,其中有Nt个属性值为空,利用单源多模态数据元组中缺失数据占整体的比例来衡量数据流D 的完整性,则数据的完整性定义为:

(3)一致性度量
在聚酯纤维工业生产中,数据一致性是指数据的数列间相似的程度[12]。设数据流D 中各时刻采集到的数据相似度集合为ψi={ψi1,ψi2,…,ψiL},数据与对应的比较数列间的相似度应满足∀ψj∈Ψi。设对于ψj≥σ,有:

则数据的一致性定义为:

2 ELM填补聚酯生产的缺失数据
ELM 的算法原理如下:
算法 ELM(D)
输入: 训练数据集D
输出: 隐层输出权重矩阵β
1.for(i=1 to l)do
2.assign input weight ω randomly;
3.assign hidden layer bias b randomly;
4.calculate hidden layer output matrix H;
5.calculate output weight β;
6.return β;
用极限学习机完成聚酯生产缺失数据填补的步驟如下:
(1)选取聚酯生产数据集,构建缺失数据集;
(2)将聚酯生产数据集随机分为两组,分别作为测试集和训练集;
(3)分别用缺失的聚酯生产训练集和完整的聚酯生产数据集对极限学习机进行训练,从而求出隐含层输出权值矩阵β;
(4)利用缺失的聚酯生产测试集及经上述训练所得模型进行测试。
结合极限学习机的特点,用极限学习机对缺失数据进行填补的优势如下:
(1)隐含层节点参数无需调节,可以大大缩短训练时间;
(2)隐含层映射h(x)满足通用的近似条件,具有良好的泛化性能,无需对特定数据进行分析;
(3)激活函数是任何无限微分的非常数函数,可以得到零误差的估计输出值,大大减小了数据填补的误差,具有良好的填补效果。
3 实验结果与分析
为了检验极限学习机(ELM)是否会提高数据的质量,以聚酯纤维生产过程中纺丝过程和聚合过程的数据为样本,进行了验证实验。
(1)实验中,输入参数是纺丝速度、温度、吹风速度、温度,输出参数是EYSCV 伸长率不均匀率,对应的ELM 神经网络如图4 所示。样本数为10000。实验前对数据进行预处理,分别使输入参数出现5%、7.5%、15%、20%的缺失,进行了四组填补实验。图5 为完整数据集的实验结果,图6(a)~(d)是对输入数据缺失率分别为5%、7.5%、15%、20%进行填补实验的实验结果。表3 和图7 是通过极限学习机(ELM)对聚酯生产纺丝数据质量的准确率、完整率、一致率的提高结果。
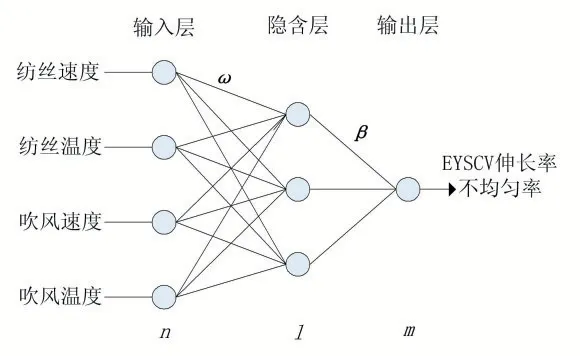
图4 纺丝数据对应的ELM神经网络图

图5 完整数据集

图6 缺失数据集
表3 和图7 为极限学习机(ELM)对聚酯生产纺丝数据处理前后的实验对比结果,从中可以看出,缺失数据经过极限学习机(ELM)的填补处理,数据的准确率、完整率和一致率都得到了提高。据此可以得出结论,用ELM 算法处理缺失数据可有效提高数据的准确率、完整率和一致率。
(2)将聚合过程EG 灌内的压力、温度、密度和流量作为输入参数,将EG 灌内的液位作为输出参数,样本数为10000。对应的ELM 神经网络如图8 所示。实验前对数据进行预处理,分别使输入参数出现5%、7.5%、15%、20%的缺失,进行了四组填补实验。图9 为完整数据集的实验结果,图10(a)~(d)是对输入数据缺失率分别为5%、7.5%、15%、20%进行填补实验的实验结果。表4 和图11 为极限学习机(ELM)对数据质量准确率、完整率、一致率的提高结果。
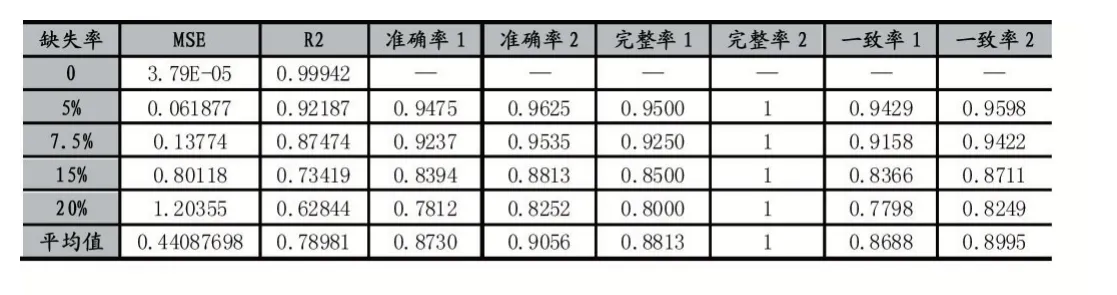
表3 实验对比结果

图7 实验对比结果

图8 聚合数据对应的ELM神经网络图

图9 完整数据集
表4 和图11 为极限学习机(ELM)对聚酯生产聚合数据处理前后的实验对比结果,从中可以看出,缺失数据经过极限学习机(ELM)的填补处理,数据的准确率、完整率和一致率都得到了提高。据此可以得出结论,用ELM 算法处理缺失数据可有效提高数据的准确率、完整率和一致率。
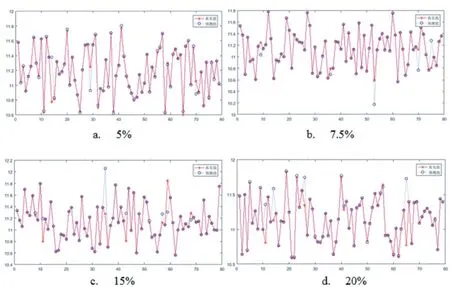
图10 缺失数据集

表4 实验对比结果

图11 实验对比结果
4 结语
聚酯纤维工业现场的硬件资源有限、抗干扰性差,又由于聚酯纤维的工业数据流是实时数据流,本文定义了聚酯纤维实时数据流的数据质量,主要包括数据的准确性、完整性和一致性。为了提高数据的质量,本文使用极限学习机(ELM)对缺失数据进行填补,实验结果表明,用极限学习机(ELM)对缺失数据进行数据填补可以有效提高数据的准确性、完整性和一致性。
猜你喜欢
纺织标准与质量(2022年3期)2022-08-10
包装工程(2022年9期)2022-05-14
保健与生活(2022年10期)2022-05-06
文萃报·周五版(2021年30期)2021-09-05
中国纤检(2017年2期)2017-03-16
中国纤检(2017年2期)2017-03-16
纺织服装周刊(2016年7期)2016-03-07
中国纤检(2015年13期)2015-11-16
纺织导报(2014年2期)2014-03-17
微电脑世界(2009年3期)2009-04-03
