
基于深度学习的城市大气PM2.5 浓度预测研究
2020-06-08 08:04赵鹏飞魏宏安
现代计算机 2020年12期
赵鹏飞,魏宏安
(福州大学物理与信息工程学院,福州350100)
0 引言
二十一世纪以来,中国的城市化,工业化和经济的快速发展导致了中国主要城市PM2.5 浓度的持续升高,雾霾天气越发频繁地出现,空气质量也不停地下降,特别是空气中的PM2.5 已经对广大群众的日常性的生产和生活造成了恶劣干扰。PM2.5,也称为细颗粒物质,是指在环境空气中空气动力学当量直径为2.5 微米或更小的颗粒物质。他们的体积特别小,可以深深进入肺部,因此对人体健康危害较大[1],还会导致大气能见度下降[2]。它可以长时间悬浮在空气中,空气中的浓度越高,空气污染就越严重[3]。PM2.5 浓度居高不下,雾霾频发成为社会广泛关注的亟待解决的问题。提前掌握空气中未来时刻的PM2.5 浓度,可以使人们更好地安排出行活动,提前准备防护装备,保护人身健康,还可以为雾霾污染治理工作提供科学的数据支持[4],更好地研究造成污染的因素,以便及时进行污染源管控。
1 研究现状
国内外的研究者不断地利用更优化的神经网络对PM2.5 浓度进行预测。Patricio Perez 等人[5]使用多层神经网络和线性回归方法分别对城市PM2.5 小时浓度进行预测,研究证明神经网络方法比线性回归方法预测效果更好。张怡文等人[6]利用神经网络对PM2.5 进行预测,该模型可以达到较高的准确率和召回率,但因为没有反向传播机制导致耗费大量时间调整参数,并且数据量少。王敏等人[7]采用BP 人工神经网络模型对城市PM2.5 进行预测,但BP 神经网络是机器学习预测方法,是浅层神经网络,不能学习数据之间的深度特征关系,并且存在预测精度不足的问题。
本文以北京市为研究区,依据越来越被认可的深度学习知识,使用TensorFlow 深度学习平台、深度循环神经网络GRU 和Attention 注意力机制,采用大样本数据进行模型训练,深入挖掘出PM2.5 与各气象因子间存在的本质性联系,建立基于Attention+GRU 的PM2.5预测模型。
2 数据来源与概述
本文所用数据集为从机器学习数据集网站UCI Machine Learning Repository 下载的气象数据集。该数据集提供了2010 年1 月1 日0 时-2014 年12 月31 日24 时北京市的PM2.5 浓度数据及相关环境数据。数据集中每小时有一个节点(记录),每条节点(记录)都有12 种数据:年、月、日、小时、PM2.5 浓度、露点、温度、气压、风向、风速、累积小时雪量和累积小时雨量等。本文选择以上除日期信息和PM2.5 外的其他7 个当前时刻气象因子作为PM2.5 预测模型的输入特征,选择当前时刻PM2.5 浓度作为输出特征。
北京市2010 年-2014 年间的PM2.5 浓度、露点、温度、气压、风速、累积小时雪量和累积小时雨量的数据分布情况如图1 所示。

图1 数据集各特征分布图
从图1 可得到以下信息:PM2.5 浓度分布比较均匀,在冬季数值比夏季略高;露点、温度、气压随季节呈现出类似正(余)弦曲线的波动;风速和降雪量冬天比较大,夏天比较小;降雨量冬天比较小,夏天比较大。
3 基于Attention+GRU的PM2.5预测模型
3.1 GRU
GRU(门控循环单元)是RNN(循环神经网络)的一种,是LSTM(长短时记忆单元)的一种效果很好的变体[8],它比LSTM 网络的结构更加简单,训练完成时间也更短,而且效果也很好。相较于普通的神经网络,RNN 的特点在于,RNN 可以处理时间序列数据,能够建立历史输入信息和当前输入信息之间的时间相关性。GRU 是由Cho 等人[9]在2014 年提出,通过门控机制使循环神经网络不仅能记忆过去的信息,同时还能选择性地忘记一些不重要的信息,在保留长期序列信息的情况下减少梯度消失问题。GRU 在语音识别、机器翻译、语言建模等自然语言处理领域有应用,也常被用于各类时间序列预测或者结合CNN(卷积神经网络)后处理计算机视觉领域问题。
LSTM 的历史信息通过控制三个门(输入门、遗忘门、输出门)进行更新[10-11]。而在GRU 中只有两个门:更新门和重置门。GRU 的记忆单元的示意图如图2 所示。重置门确定是否遗忘先前的状态信息,这可以看做是将LSTM 中的遗忘门和输入门合二为一。更新门决定是否要将隐藏状态更新为新的状态,相当于LSTM中的输出门。更新门则可以确定隐藏状态是否有必要转换为新状态,具有和LSTM 中的输出门一样的作用。

图2 GRU记忆单元结构
更新门zt、重置门rt、本单元状态和本单元输出ht依次按照下式(1-4)计算。

其中:rt表示重置门,zt表示更新门。σ 是sigmoid函数;tanh 是双曲正切函数;·表示点积。是t 时刻以及之前时刻本单元存储的所有有用信息的隐状态向量,ht是经过处理后,最终被保留的当前单元的信息,并被传递到下一个单元中。当rt趋于0 时,前一个时刻的状态信息ht-1会被遗忘,隐藏状态会被重置为当前输出信息ht。
3.2 Attention机制
Attention 机制的灵感来自人类观察行为。人在观察一张图片时,首先会快速扫描全局图像,获得图片中需要重点关注的目标区域,并作为注意力焦点。然后对注意力焦点投注全部注意力,进而获得更多所需要的细节信息,并摒弃其他无用信息。
Attention 模块从经过GRU 模型的序列中学习到每条序列的重要程度,分别生成不同的权重参数,将各序列加权求和。从而使重要信息获得更多关注,并不同程度抑制其他价值小的信息。Attention 机制既有全局联系又有局部联系,可以更好地捕获长期依赖关系,提高PM2.5 浓度的预测精度。
Attention 机制的公式如下所示。

hi为经过GRU 模型输出的数据,W1和W2为两个参数,Zt为隐状态,tanh()为双曲正切函数,用于非线性变换,softmax()函数用于将输入归一化,将得到的权重
3.3 数据预处理
在现实世界中,直接获取的数据通常会是缺失某些值,单位不一致的脏数据。因此,我们不可能直接使用它们进行模型训练,挖掘数据关系。为了提高模型预测的精度,降低实际训练所需要的时间,必须要对气象数据实行预处理操作。
对本数据集的具体操作为,将数据集中的年月日时信息修改为索引,删除PM2.5 数据集中出现连续空值的时间段数据、将其余少量缺失数据填充为前一数据、修改数据集格式以便神经网络读取、将以小时为单位的数据每24 小时的数据求平均值转换为以天为单位的数据、采用小波变换模极大值去噪法去除数据集的无用信息和异常值、对风向特征进行独热编码、进行归一化处理。经过预处理的数据集前五条数据如表1所示。

表1 预处理后前五条数据
从表1 中能得知,数据经过预处理后,各值处于0到1 之间,无空值,避免了由奇异样本数据导致的模型训练不良的影响,有利于进行模型训练和测试。再按照季节将五年时间长度的数据集分为春、夏、秋、冬四个数据集,依据留出法从每个季节数据集中随机抽取20%的数据,将抽取出的数据合并为测试集,其余的数据合并为训练集,打乱训练集和测试集的样本排列顺序。再通过数据平移操作将时间序列数据集转化为监督学习数据集。
3.4 模型构建
深度学习通过堆叠多层神经网络和依靠随机优化,将数据的低层特征转换为更抽象的高层次特征,并以次保留数据间的分布式特征关系。基于Attention+GRU 的预测模型由输入层、隐藏层、输出层组成,如图3 所示。
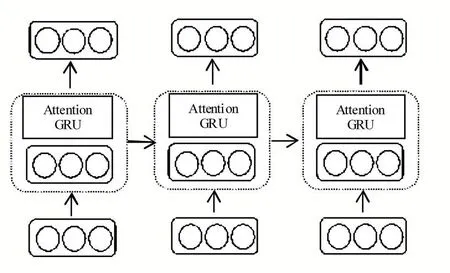
图3 基于Attention+GRU的PM2.5预测模型
深度学习模型最核心的设计是位于模型中间的隐藏层,设置了3 层GRU 神经单元,每层包含256 个神经元,通过向前操作,将之前的历史信息选择性地不断向后传递。每个新输入数据的和神经网络中保留的信息经过处理形成每个阶段的输出。将经过3 层GRU神经网络处理后的数据输入到Attention 机制,对每个输出序列数据分别计算权重后加权求和,再传递到输出层。输入层的输入特征为当前时刻的7 个特征(露点、温度、气压、风向、风速、累积小时雪量和累积小时雨量)。输出层的输出特征为PM2.5 浓度。
本文采用深度学习框架TensorFlow 中的GRUCell函数创建神经元,再通过MultiRNNCell 函数将包含GRU 神经元的三个神经网络层进行线性叠加,构建多层GRU 神经网络。Attention+GRU 模型具体设置如下:
(1)模型隐藏层设置
构建3 层GRU 网络模型,且每层具有256 个神经元;神经层间的激活函数皆为tanh 函数;使用Dropout函数配置每一层网络节点的输入舍弃率设置为0.1,输出舍弃率设置为0.2,避免过拟合情况的发生;隐藏层连接Attention 机制,再用dense 函数添加全连接层,再连接输出层,并将linear 函数设置为该层的激活函数。
(2)Attention 机制设置
权重向量采用随机常数函数初始化;将输入数据经过tanh()函数进行非线性变换;使用softmax()函数将数据归一化处理得到参数;用矩阵乘法操作进行加权求和;再次使用tanh()函数进行非线性变换;使用Dropout 函数进行防过拟合措施,舍弃率设置为0.2。
(3)模型参数设置
模型结构属性设置好之后还需要进行另一些必要设置,模型的学习率、优化器、损失函数、权重和偏置。经过多次试验后,本模型选择设置学习率为0.00001,将损失函数设置为绝对值均差(MAE)损失函数,将优化器设置为Adam 优化器,选择xavier 函数为权重初始化,将偏置设为常数0。
(4)模型训练设置
将batchsize(同批次训练的样本数)设置为128,batchsize 过大容易使loss 陷入局部最低点,模型准确性也会下降;epoch(训练轮数)设置为1000,过小会造成模型学习不充分;将训练集数据分配给占位符X 和Y;输出每一轮训练的损失函数值。
(5)模型预测
将测试集X 输入训练完成后的模型,输出测试集的loss 值,并将预测结果和测试集Y 进行比较,计算他们的均方根误差RMSE。
4 实验结果及分析
数据集包含北京市2010 年-2014 年的43824 条逐小时气象数据,经预处理后为1825 条有效数据。再按照留出法,随机选择其中20%的数据组合为测试集,共328 条数据,剩余80%数据组成训练集,共1497 条数据。
将上述数据输入到Attention+GRU 模型和GRU 模型中进行对比预测。图4 为Attention+GRU 模型训练集每轮的损失值图,图5 为GRU 模型训练集每轮的损失值图。可以看出,Attention+GRU 模型的损失曲线下降更快,损失值最小值更小,预测精度更高。

图4 Attention+GRU模型训练损失值图

图5 GRU模型训练损失值图
为了显示预测效果,用测试集的PM2.5 实际浓度值减模型预测值得到差值,图6 为Attention+GRU 模型预测的PM2.5 浓度差值散点图,图7 为GRU 模型预测的PM2.5 浓度差值散点图。可以看出,实际值和预测值数据重合度很高,绝大部分差值分布在0 值附近。Attention+GRU 模型和GRU 模型都可以较好预测PM2.5 浓度值。Attention+GRU 模型预测的差值比GRU 模型预测的差值点更集中于0 值,Attention+GRU模型比GRU 模型对PM2.5 浓度预测更精准。

图6 Attention+GRU模型预测的差值图

图7 GRU模型预测的差值图
Attention+GRU 模型训练集数据的最后一轮损失值为0.0737,测试集数据的损失值为0.0722,测试集数据的均方根误差为8.5616。GRU 模型训练集数据的最后一轮损失值为0.1031,测试集数据的损失值为0.1019,测试集数据的均方根误差为10.9736。根据实验结果数据可知,两个模型都可以准确预测PM2.5 浓度,但Attention+GRU 模型对PM2.5 浓度的预测精度比GRU 模型的预测精度高很多。
5 结语
本文首先获取了大量气象因子和PM2.5 数据,选择了7 个气象因子作为预测PM2.5 浓度的输入特征,满足了深度学习模型训练的需要。在数据预处理过程中,修改数据集数据格式以便模型输入、对各特征数据进行异常值处理、对风向进行独热编码、对各数据归一化处理,按照留出法以8:2 的比例划分训练集、测试集。然后搭建三层Attention+GRU 模型,设置学习率、训练轮数、损失函数及优化器。最后,将分割好的训练集输入构建的Attention+GRU 模型,不断调整参数优化模型,并在测试集进行模型性能评估,并与GRU 模型进行对比。结果表明,基于深度Attention+GRU 的PM2.5 预测模型预测性能良好,预测值与实际值相近,比GRU 模型预测精度更高。该结果具有重要的实际应用价值,可以及时提醒人们,免遭雾霾侵蚀健康,为空气污染的治理工作提供数据支持。接下来,可以改进模型结构、调整训练轮数、调整学习率、加快模型训练速度、增加输入特征、提高模型预测准确度等方面进行深入研究。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
煤气与热力(2022年2期)2022-03-09
教育周报·教研版(2021年47期)2021-12-19
北京航空航天大学学报(2021年4期)2021-11-24
科学与财富(2021年33期)2021-05-10
电脑爱好者(2020年21期)2020-11-09
天津中德应用技术大学学报(2018年5期)2018-09-10
软件(2017年6期)2017-09-23
中学生数理化·高三版(2016年9期)2016-05-14
中学生数理化·高一版(2009年6期)2009-08-31
