
可重构的SHA-3 算法流水线结构优化及实现
2020-06-08 08:04周雍浩董婉莹李斌陈晓杰冯峰
现代计算机 2020年12期
周雍浩,董婉莹,李斌,陈晓杰,冯峰
(1.郑州大学电气工程学院,郑州450001;2.郑州大学信息工程学院,郑州450001;3.中国人民解放军信息工程大学数学工程与先进计算国家重点实验室,郑州450001)
0 引言
安全散列算法(Secure Hash Algorithm,SHA)是由美国NIST 发布的一种密码散列函数,其作用是对不定长的消息计算出一个固定长度的消息摘要[1]。SHA 具有单向性和抗碰撞性,是密码学中的一个重要工具,被广泛应用于数据完整性校验、数字签名、消息鉴别和密码协议等信息安全领域[2]。但是,随着计算机技术的快速发展和破解技术的增强,MD5 和SHA-1 相继被成功破解,变得并不安全。因此,NIST 制定了新的SHA3 标准,并将Keccak 算法选定为SHA3 标准的单向散列算法[3]。由于SHA3 算法本身的复杂性且在应用中经常被多次迭代使用,所以如何实现更快速的SHA3 算法,成为了亟待解决的问题。FPGA 作为可重构硬件,凭借着高性能、低功耗的特性成为了实现密码算法的首选平台。国内外众多学者也在FPGA 上对SHA3 算法进行了优化、实现,但是很少涉及全流水线结构和并行的设计方案。
综上,本文通过分析SHA3 算法的关键路径,使用可重构硬件FPGA 和流水线技术,并以展开结构的方法进一步优化算法,达到了增加工作频率和并行化的目的,以实现高效能的SHA3 算法。
1 背景知识
1.1 SHA3简介
Keccak 算法是SHA3 标准选定的算法,采用不同于MD(如MD5)类结构的海绵结构。海绵结构如图1所示。
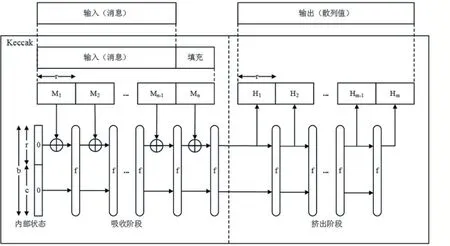
图1 海绵结构
其中,压缩函数Keccak-f 是海绵结构的计算引擎,它封装了海绵结构的主要计算逻辑。内部状态是海绵结构计算操作数的载体,内部状态在海绵结构中作为压缩函数Keccak-f 的输入输出。b 代表内部状态的比特长度,b 的具体数值必须满足公式(1):

因此,b∈{25,50,100,200,400,800,1600}。海绵结构由b 还定义了两个分量,比特率(bitrate,用r 表示)和容量(capacity,用c 表示),且b、r 和c 满足关系b=r+c,三者的具体值均由使用者决定。图1 中{M1,...,Mn}是对填充后消息的分组,分组长度等于r;{H1,...,Hm}是分步提取的散列值,每个散列值的长度等于r,提取步数m 由使用者决定,所有散列值按提取顺序排列合并成最终的输出散列值。
海绵结构在工作过程上分为吸收和挤出两个阶段,吸收阶段是将输入消息根据分组依次“搅拌”进它的内部状态的过程,挤出阶段是分步提取输出散列值的过程。在吸收阶段,初始时将内部状态的所有比特位置0,接下来反复进行以下过程,直到消息分组耗尽。该过程是,先将消息分组Mi(1 ≤i ≤n)与内部状态的前r 个比特异或,然后将内部状态输入压缩函数Keccak-f,最后压缩函数Keccak-f 处理后输出内部状态。在挤出阶段,根据使用者选择的步数,分步重复以下过程。该过程是,先获取内部状态的前r 个比特,然后将内部状态输入压缩函数Keccak-f,最后压缩函数Keccak-f 处理后输出内部状态。
对于压缩函数Keccak-f。内部状态在输入压缩函数Keccak-f 后和压缩函数Keccak-f 输出前都需要经过格式转换,即压缩函数Keccak-f 处理过程中内部状态为函数可操作的格式。压缩函数Keccak-f 中轮计算的轮数由公式(2)计算得到,其中变量l 来自于公式(1),因此间接取决于使用者的选择。

在SHA3 标准下Keccak 算法具有以下特点:
(1)在输入上,采用Keccak 算法的SHA3 没有长度限制。
(2)在输出上,Keccak 算法本身可以生成任意长度的散列值,但为了配合SHA2 的散列值长度,SHA3 标准中规定了SHA3-224、SHA3-256、SHA3-384、SHA3-512 这4 种版本。本文实现的是SHA3-256,即最终输出的散列值长度为256 比特。
(3)在参数选取上,SHA3 标准选定了b 的取值为1600,从而压缩函数Keccak-f 的轮计算轮数为24。
1.2 FPGA简介
现场可编程门阵列(Field Programmable Gate Array,FPGA),是一种拥有高密度逻辑、大量计算和存储资源的高性能计算平台。FPGA 的本质是无指令、无需共享内存的体系结构,通过编程可定义其中的单元配置和链接架构进行计算。FPGA 以查找表和寄存器实现复杂的组合逻辑操作,且片上内存BRAM 属于各自的逻辑区域,无需不必要的仲裁和缓存。因此FPGA的运算速度足够快,具有很强的计算能力和灵活性,使得FPGA 可重构计算系统成为加速科学计算的一种重要选择[4]。如图2 所示,给出了一般的FPGA 芯片的逻辑结构。
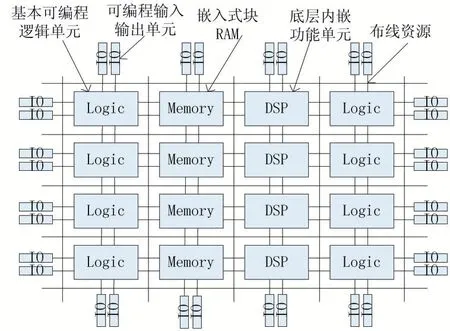
图2 FPGA内部逻辑结构
据此,文献[5]提出了一种流水线硬件架构,该架构支持4 种SHA3 操作模式,以及可同时支持多块和多消息处理的FPGA 器件的高性能实现,在不同FPGA器件上的实验结果证明提出的设计实现了吞吐量的显著提高。文献[6]通过流水线、子流水线和展开的方法,优化实现了SHA3 的五种方案,其中方案五在吞吐量和面积效率上取得了平衡。文献[7]根据SHA3 的结构特点和FPGA 内部逻辑,主要采用折叠的方式对其进行了优化,减少了所需的面积资源并获得了更短的数据路径,算法效率至少提高了50%。文献[8]采用SoC设计,在FPGA 端实现了SHA3 算法,并通过AHB 接口与ARM 端互连,提高了算法应用范围。文献[9]采用基于锁存器的时钟门控技术优化了SHA3 算法,并有效降低了功耗。但是这些方案本质上仍是串行计算,只是局部使用了流水线技术,仍有提升空间。
综上,本文通过深入分析SHA3 算法,以全流水线结构,优化设计适合FPGA 的数据通路,以提高算法速度。
2 SHA3在FPGA上的优化及流水线实现
2.1 关键计算分析
从SHA3 的算法流程中可以看出,Keccak-f 计算是关键。想要提高算法的性能,必须对Keccak-f 深入分析。当b=1600 时,将输入数据转换为5×5×64 的三维结构,并用元素为64 位的二维数组A 表示,则有A[x、y],其中x、y∈[0,4]。Keccak-f 每轮总共有5 个计算步骤[10],分别用θ,ρ,π,χ,ι表示,每个计算步骤的具体运算如下所示:
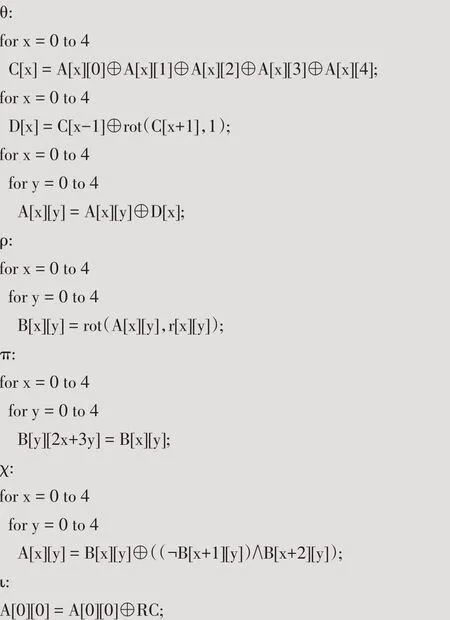
上述运算步骤中,⊕代表按位异或运算,¬代表按位取反运算,∧代表按位与运算。rot 函数表示循环移位。r[x][y]和RC 分别是移位位数和轮常数。
θ的处理过程较复杂,可预先循环展开,对操作的数据进行计算,并确定需要操作数据的位置,从而方便后续的实现。ρ是对θ的输出进行移位,π的功能是对ρ的输出进行位置交换,因此可通过预先计算出交换的位置以及需要的移位,从而将ρ、π进行合并。χ是对π的输出进行运算,ι对χ的输出进行一次常量的异或运算,因此可将χ与ι进行合并。通过对这五个步骤进行预计算、合并等预处理,从而简化了Keccak-f 的计算且降低了实现复杂度。
2.2 全流水线实现
SHA3 算法中Keccak-f 包含24 轮重复的运算,且每一轮的输入、输出仅与相邻的轮具有依赖关系,因此可将SHA3 算法通过流水线技术实现为并行算法,从而降低时间复杂度。
流水线是一种通过增加空间的利用来减少时间消耗的时空映射技术。通过前述的预处理,每轮的五个步骤变为了θ、ρπ、χι三步,可以采用24 级流水线结构实现。具体的,每一级流水线都包含三步运算,并压缩在一个子模块中,共24 个子模块,对应24 轮运算。同时,为了在一个时钟计算出一轮运算结果,将θ、ρπ实现为线网型的组合逻辑,而χι实现为依赖于时钟信号的时序逻辑,算法在FPGA 中实现的时序结构如图3所示。

图3 SHA3算法FPGA实现流水线结构
图3 中一个时钟周期的每级流水线内三个计算步骤串行执行,而24 个子计算模块并行运行,图中的箭头指向表示数据的传递方向。当有一组数据需要进行Keccak-f 处理时,需经过24 个时钟周期处理完毕,而当有n 组数据需要进行Keccak-f 处理时,只需要n+23 个时钟周期,时间复杂度为Ο(n)。因此,在满负荷的情况下,一组数据仅需要一个时钟周期即可产生结果,从而通过算法的并行化,减少了计算的时间,提升了运行效率。
2.3 展开再优化
通过对Keccak-f 的分析可知,其每轮运算包含76次异或运算,25 次位非运算,50 次位与运算以及49 次移位运算。虽然FPGA 对于位运算具有较好的性能表现,但是在一个时钟周期内将200 次运算串行执行结束,会存在较大的延时。在全流水线结构中,算法的执行效率由频率决定,因此,提高算法的频率,减少算法的延时是一种有效的优化方法。
Keccak-f 每轮运算的计算步骤间数据是依次传递的,因此可将每个时钟周期内串行执行的三步进行时钟展开。由于ρπ仅包含移位运算,结构特殊,因此可将ρπ独立进行一个时钟周期的运算,而将θ和χι在另一个时钟周期内串行运行,即由原来的一个时钟展开为两个时钟,加上最后输出消耗的一个时钟,最终采用的是49 级全流水线结构进行实现,该优化结构如图4 所示。
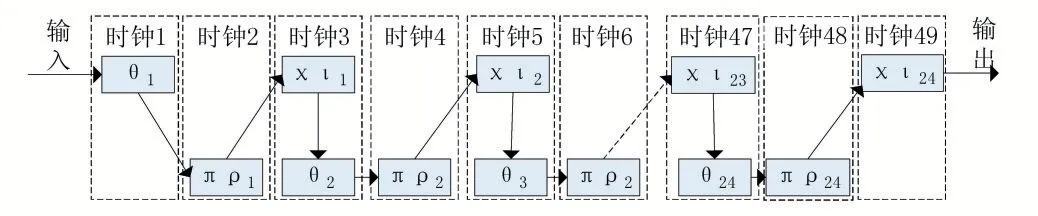
图4 SHA3算法流水线优化结构图
图4 中算法的实现结构与图3 相比,虽然时钟周期数增加了一倍,但是时间复杂度仍为Ο(n),即在相同频率下,两种结构性能相同。但是,由于每一级流水线上的计算延时降低,使得该实现在FPGA 的综合编译结果中可以获得更高的频率表现,从而使SHA3 算法的性能得到进一步提升。
3 实验结果与分析
本实验中的一块FPGA 加速卡包含四颗FPGA 芯片,该芯片型号为Xilinx 公司的xcku060,其查找表LUTs 资源是331680,FlipFlops 寄存器资源是663360,软件为Vivado 2018.2。实验对优化后的SHA3 算法流水线进行了仿真分析;并对比了SHA3 串行和两种流水线资源使用情况;然后与GPU 在性能和功耗方面进行了对比;最后与其他方案进行了对比,说明本文方案的有效性。
3.1 仿真分析
优化后的SHA3 算法流水线仿真如图5 所示。其中in_valid 为输入有效信号;in_data 为输入数据;out_valid 为输出有效信号;out_data 为输出数据;其他为中间结果信号。

图5 SHA3算法仿真图
从图5 中可以看出,对于优化后的SHA3 算法,当连续输入50 个数据后,在4866.191ns 连续产生50 组输出,充分发挥了流水线并行的优势。
3.2 资源占用
这里分别采用串行和两种流水线实现了SHA3,其资源占用对比如表1 所示。

表1 SHA3 串行和两种流水线资源占用
从表1 中可以看出,串行SHA3 每24 个时钟处理1 组数据,而流水线SHA3 可连续处理n 组数据,两种流水线结构分别从第25 个时钟和第50 个时钟开始依次输出它们的结果。由于优化后的全流水线SHA3 算法通过增加流水线的级数来降低单个时钟周期的延时,因此从实验结果也可以看出优化后的实现与未优化的相比具有更高的频率。对应的,SHA3 串行的处理速度为13 M 次/秒,而展开流水线为415 M 次/秒,在处理速度上SHA3 流水线是串行的31.92 倍,具有明显优势。
3.3 与GPU对比
描述SHA3 计算部件性能的指标有速度、功率、能效比。其中能效比表示计算部件性能与功率之比,简记为EER(Energy Efficiency Ratio),计算公式3 如下:

表2 给出了本实验中的FPGA 加速卡与GPU 在各方面指标上的对比。其中,单颗FPGA 芯片内放置了4 个优化后的SHA3 流水线模块,工作频率为200 MHz;GPU 型号为NVIDIA GeForce GTX 1080。
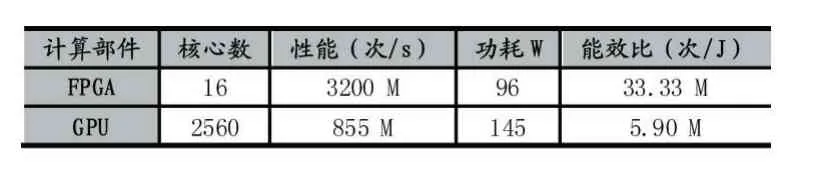
表2 FPGA 与GPU 指标对比
从表2 中可以看出,FPGA 不仅性能较高,且功耗较低,具有很高的能效比,是GPU 的5.65 倍,更具有应用价值。
3.4 与其他方案对比
与其他方案的对比如表3 所示。
通过对比可以发现,除文献[3]外,本文实现的频率优于大多数方案。同时由于采用了全流水线结构,本文实现的吞吐量高于其他方案,充分发挥了FPGA 的计算优势。
4 结语
本文提出了可重构的SHA3 算法流水线结构及其优化、实现。通过对SHA3 算法的深入分析,使用高效能的FPGA 硬件计算平台,缩短了SHA3 关键路径,并以全流水线结构和展开的实现方式,有效地提高了工作频率和计算速度,具有很高的实际应用价值。
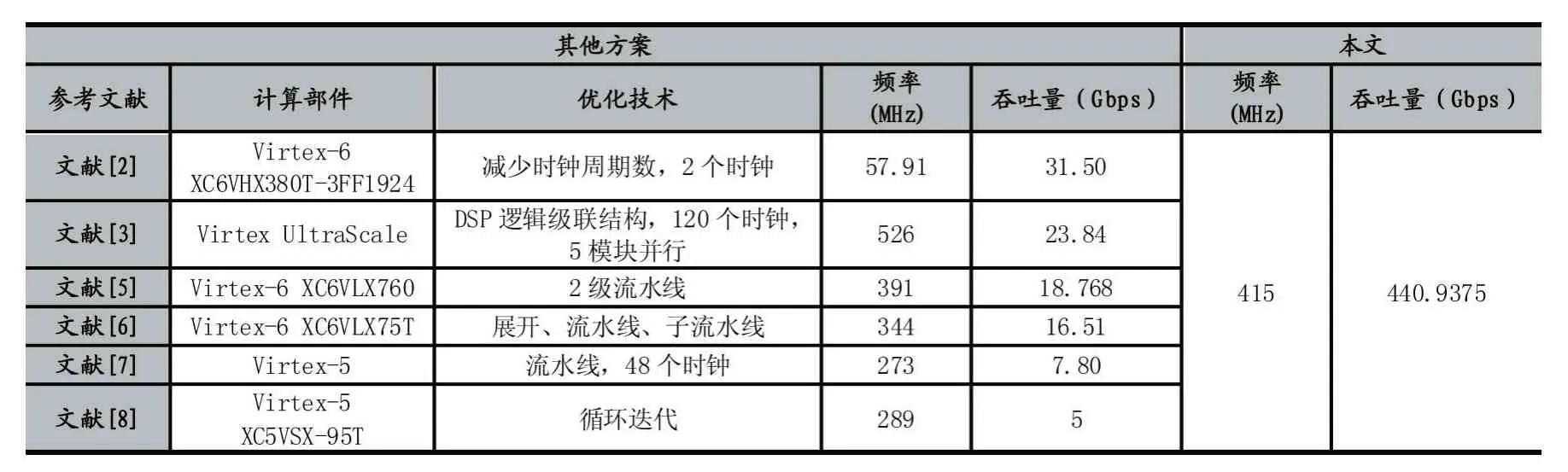
表3 与其他方案对比
猜你喜欢
少儿科学周刊·儿童版(2021年19期)2021-12-10
少儿科学周刊·儿童版(2021年19期)2021-12-10
学苑创造·A版(2021年9期)2021-09-16
当代工人(2020年4期)2020-05-11
儿童故事画报(2019年8期)2019-08-14
数学大王·低年级(2018年9期)2018-10-24
永善文学(2017年1期)2017-07-18
中国信息技术教育(2017年11期)2017-07-01
数学大王·中高年级(2017年2期)2017-02-08
学苑创造·A版(2016年4期)2016-04-16
