
基于扩张卷积的图像修复
2020-06-06 02:07张晓龙
计算机应用 2020年3期
冯 浪,张 玲,张晓龙*
(1. 武汉科技大学计算机科学与技术学院,武汉430065; 2. 武汉科技大学大数据科学与工程研究院,武汉430065;3. 智能信息处理与实时工业系统湖北省重点实验室(武汉科技大学),武汉430065)
(*通信作者电子邮箱xiaolong.zhang@wust.edu.cn)
0 引言
图像修复一直是图像处理领域中的热点,是利用某种规则或方法,通过图片已知区域信息来推断缺失区域内容并将其修复补全的技术[1]。这一技术被广泛应用于消除场景元素[2]、文物艺术品保护、超分辨率重建和图像拼接等方面,具有重要的学术价值和应用价值。要做好图像修复工作,需要解决几个问题。首先,在图像修复过程中,要保持图像纹理结构的连续性,尽可能接近或达到原始图像的效果;其次,补全结果要真实自然,符合人们的视觉连贯性,让观察者认为这是一张真实的图像[3]。
传统图像修复方法适合补全背景较为单一的破损图片,通常做法是在已知背景区域中选取与缺失区域较为相似的块[4]来填充未知区域的内容,但是这种方法无法生成新的特征结构,而且当图片场景较为复杂、缺失区域较多的情形下会得到极差的修复效果。近期的深度学习方法虽然能够处理场景较为复杂的破损图片,但是当破损区域较大时,很难估计缺失区域的细节信息,从而导致修复结果出现结构扭曲[3]、纹理模糊和内容不连贯[5]等问题。
针对这些问题,本文提出了一种基于扩张卷积的图像修复方法。在本文的方法中,图像的纹理结构信息作为约束信息输入到网络中训练。该方法利用生成对抗网络的思想,构建了一个由全局到局部的网络模型来完成图像修复工作,网络模型主要由生成网络和对抗网络两大部分组成。生成网络包括全局内容修复网络和局部细节修复网络,首先利用全局内容修复网络获得一个初始的内容补全结果,之后再通过局部细节修复网络对获得的初始结果在局部上进行纹理细节修复。对抗网络由SN-PatchGAN 鉴别器构成,用于评判图像修复效果的好坏。
本文研究的问题是图像修复,主要工作如下:1)提出了一个从全局到局部的图像修复模型,先从全局角度上补全破损图片的缺失区域,再对补全的图片从局部上进行细节修正,解决了图像修复过程中可能会出现的纹理模糊及结构扭曲等问题;2)通过在生成网络中使用gated 卷积及扩张卷积,增大了卷积神经网络感受野的大小,解决了传统卷积神经网络无法较好地补全大面积不规则缺失区域的问题,并提升了图像修复的质量;3)在图像修复过程中,利用纹理信息作为图像修复的辅助信息,有效地解决了传统修复方法出现的纹理模糊问题。
1 相关研究
现有的图像修复方法分为以下三类:一类是基于偏微分方程的图像修复技术;一类是基于样本的纹理合成图像补全技术;最后一类是基于生成对抗网络的图像修复技术。
1.1 基于偏微分方程的图像修复
Bertalmio 等[1]首 次 提 出 基 于 偏 微 分 方 程 的BSCB(Bertalmio-Sapiro-Caselles-Bellester)模型。该模型通过延伸图像缺失边界的等照度线方向,以像素点为基本单位,向缺失区域扩散已知图像的拉普拉斯特征,通过不断的迭代修复,从而达到图像补全的目的。但是在图像修复的过程中,需要求解一个三阶非线性偏微分方程,这种计算就算放在电脑计算能力已经显著提升的今天也是非常耗时的,而且修复的图像边界有非常明显的模糊区域。Chan等[6]在BSCB算法上改进,提出了一种基于全变分模型的图像修复方法,但该模型并不能很好地从主观上满足图像视觉连通性[7]要求。Lu 等[8]在全变分模型的基础上,分析图片局部特征,提出了快速修复图片的ATV 模型。为加快算法修复速度,Telea[9]提出了快速进行算法(Fast Matching Method,FMM)。徐黎明等[10]提出了一种基于八邻域的自适应高阶变分图像修复算法,解决了传统偏微分方程图像修复算法信息利用不够充分的问题。
1.2 基于样本的纹理合成图像补全
Criminisi 等[4]于2003 年提出的Criminisi 算法是最为经典的纹理合成方法,随后Criminisi 等[11]于2004 年对该算法进一步改善。这种算法的核心思想是先计算缺失边缘样本块的修复优先级,然后在图像已知区域中寻找与当前修复优先级最高的样本块最为匹配的块作为填充,之后再更新其余缺失边缘样本块的优先级,通过不断的迭代填充,从而实现图像的修复补全;但由于它是以一种贪婪的方式对已知样本块进行搜索,与目标样本块进行匹配,修复结果可能会出现结构断裂、修复效果模糊等情况。由于该方法以样本块为基本修复单位,大大地提升了图像的修复速度,因此引起专家的广泛关注,许多国内外研究专家开始基于该算法进行改进。Cheng等[12]改进了计算破损边缘样本块修复优先级的方法;Xu等[13]引入图像结构稀疏算法,达到了较好的修复效果;Le Meur等[14]用结构张量确定样本块的修复优先级;Sun 等[15]采用人工交互的方式,使得补全结果边缘更加清晰和平滑,视觉效果更为连贯;在相似性度量上,Xue 等[16]根据颜色比率梯度直方图构建了一种新的相似度量规则,提高了搜寻匹配块的精确度。
1.3 基于深度学习的图像修复
最近,随着深度学习的迅猛发展,基于卷积神经网络的图像处理方法[17]得到越来越广泛的应用。
Pathak 等[18]于2016 年提出一种上下文编码器(context encoders)结构的神经网络用来修复图片。该方法虽然能够很快地生成修复结果,但是结果缺乏纹理细节,在孔洞边缘会产生明显可见的痕迹,而且当修复高分辨率图像时,很难去计算训练时的生成对抗损失,因此具有局限性。为解决这个问题,Yang等[19]引入图像风格迁移[20]的思想,提出了一种联合图像内容和纹理约束的图像修复算法。该方法虽然能取得较好的修复效果,但是当图片场景复杂时,修复结果会不连续甚至违背真实。
Liu 等[21]在类似U-Net 结构的网络模型上引入部分卷积的思想来修复破损图片。虽然该方法能够修复任意破损区域的图片,但是当缺失区域较大时,修复的结果会带有明显的边界信息,同时缺失区域中央可能带有模糊的灰度特征,并不能很好地捕获原图的全局和局部特征。Iizuka 等[3]将缺失图片和对应的掩码作为网络的输入,引入扩张卷积的思想增大感受野,分别定义全局和局部鉴别器来计算补全结果和原图的整体一致性和局部一致性。该方法可以补全图片的任意缺失区域,但是网络训练周期过长,有些结果的补全区域可能会与原图不协调,无法满足观察者的视觉连贯性,需要对修复结果进行后处理,而且当未知区域细节信息缺失过多时,会得到一个极差的补全结果。
受全局和局部鉴别器启发,Yu 等[5]提出了由粗到精的网络模型,该模型首先通过粗网络补全图片的缺失区域,再通过细网络细化修复结果的纹理。该方法可以较好地补全图片多个矩形缺失区域的内容,但是当扩展到修复图像不规则缺失区域的工作上时,会得到较差的补全结果。
2 图像修复系统架构
2.1 网络结构
本文设计的图像修复网络模型如图1 所示,主要包括生成网络和对抗网络两部分。生成网络包括全局内容修复网络和局部细节修复网络,用来修复图片缺失区域的内容。其中,全局内容修复网络主要用于获得一个初始的内容修复结果x1,局部细节修复网络的目的是对获得的初始结果在局部纹理细节上进行修正,以期得到更加自然的修复结果x2。对抗网络由SN-PatchGAN 鉴别器组成,以最终修复结果、掩码和纹理信息作为网络输入,用于评判图像修复效果的好坏。

图1 本文设计的图像修复网络模型Fig. 1 Image inpainting network model designed in this paper
网络模型的输入包含两个内容:破损图片以及图片对应的纹理信息。其中,图像纹理信息作为轮廓约束用于缺失区域的内容估计。在网络模型训练时,本文使用OpenCV 中的canny边缘检测器生成对应的纹理特征图作为纹理约束信息;在测试时,本文使用Nazeri 等[22]已训练好的纹理估计模型生成缺失区域的纹理特征图作为纹理约束信息。
为了与生成网络输入保持一致,并方便后续计算损失函数以及重构修复结果,本文将全局内容修复网络和局部细节修复网络补全结果的像素矩阵都归一化到[-1,1],同时生成网络中所有卷积都采用gated卷积[23]的方式。
网络的输入和各阶段修复结果如图2 所示。其中,(a)为破损图片,(b)为破损图片对应的纹理信息,(c)为利用破损图片和纹理信息重构的网络输入,(d)为全局内容修复网络的补全结果,(e)为局部细节修复网络的补全结果。

图2 网络的输入和各阶段修复结果Fig. 2 Input of the network and inpainting results at different stages
2.2 全局内容修复网络
全局内容修复网络主要用于获取图片的全局特征,修复缺失区域的内容信息,生成一个初始的修复结果。由于使用普通卷积的思想无法修复图片不规则缺失区域[3]的内容,这也是图像修复领域的难点。为解决这个难题,Liu等[21]提出了部分卷积的思想,只响应网络中的有效输入,使得网络在每一次卷积之后自动更新掩码。但这种方法只是单纯地把所有像素分为有效像素和无效像素两种,当前过滤器中有一个有效像素和多个有效像素对于更新下一层的掩码并没有什么差别,而且由于它无法与额外的用户输入兼容导致其没有可扩展性。
为解决这个问题,在构建生成网络时,本文使用gated 卷积[23]代替传统卷积方式。该方法能够从数据中自动学习掩码,可以针对每个通道和每个空间位置,使得网络可以学习一种动态特征选择机制。gated卷积[23]定义如式(1)所示:
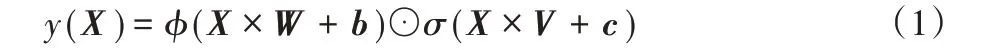
其中,W、V为两个不同卷积核的权重,b、c分别为对应卷积核的偏置,φ可以是任意激活函数,σ是sigmoid激活函数。
全局内容修复网络包括13个卷积层、4个扩张卷积层和2个反卷积层,其具体参数如表1所示。网络中使用到4层扩张卷积,通过逐层增大感受野大小的方法来获得更好的修复结果。

表1 全局内容修复网络参数Tab.1 Global content inpainting network parameters
通常,卷积核个数越多,提取的图片特征信息越多,图像修复的效果越好,但网络的复杂度也在增加,容易出现过拟合的问题。本文通过实验比较,最终将生成网络的卷积核基数设置为48。
2.3 局部细节修复网络
与全局内容修复网络对应,局部细节修复网络中同样使用4 层扩张卷积用于增大感受野的范围,从而显著地提升图像修复质量。不同的是,在局部细节修复网络模型中,还引入了内容感知层[5]用于保证图片的局部一致性。其核心思想是,从图片已知背景区域中提取多个3×3 大小的块作为前景区域(补全区域)的卷积核,通过并行地计算余弦相似度选取比较像前景区域的若干个块,再使用softmax 的方法对这些块打分,选取评分最高的块,并以此反卷积出前景区域的内容,从而精细模糊的修复结果。
全局修复网络用来把握图片的全局特征,主要包括6 个卷积层和4个扩张卷积层,其具体网络参数如表2所示。局部修复网络用来把握图片的局部特征,主要包括8个卷积层和1个内容感知层,其具体网络参数如表3所示。通过一个concat函数将这两者提取的特征信息融合在一起,以此细化全局内容修复网络的结果,最后通过反卷积的方法得到局部细节修复网络补全结果。concat 连接部分主要包括7 个卷积层和2个反卷积层,其具体网络参数如表4所示。

表2 全局修复网络参数Tab.2 Global inpainting network parameters

表3 局部修复网络参数Tab.3 Local inpainting network parameters
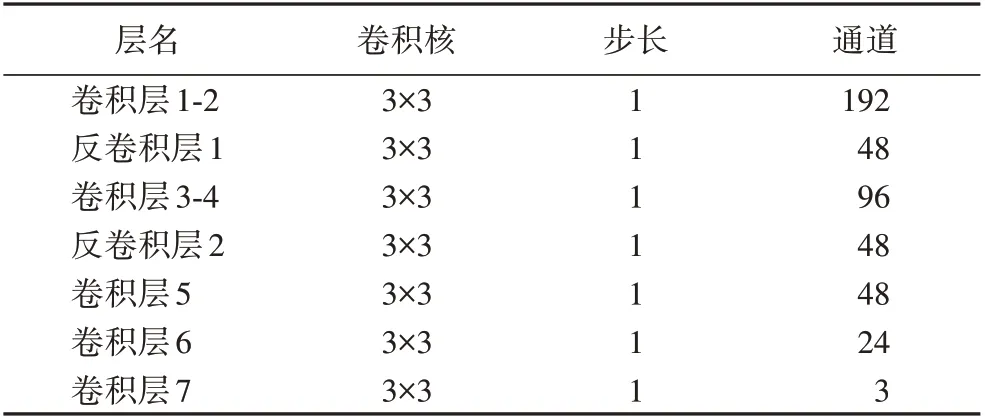
表4 concat层网络参数Tab.4 Network parameters of concat layers
2.4 SN-PatchGAN鉴别器
SN-PatchGAN 鉴别器以修复结果、掩码和边缘信息作为网络输入,由6 个卷积核大小为5×5,步长为2 的卷积层构成,输出维度为(输入图像长度/32)×(输入图像宽度/32)×256 的特征图,其网络具体参数如表5 所示。通过这6 层卷积,输出特征图上感受野的大小已经可以覆盖整个输入图片,因此不再需要一个全局鉴别器来评判图像修复效果的好坏。

表5 鉴别器网络参数Tab.5 Network parameters of discriminator
本文使用Adam 优化器来训练生成对抗网络。其中设置alpha 的值为0.000 2,设置beta1 的值为0.0,设置beta2 的值为0.9。
2.5 损失函数
给定一张破损图片,由于缺失区域的不确定性,只要修复效果足够平滑,可能会生成多个可行的结果。但是用户想要的不仅仅是符合人们整体视觉连贯性的补全结果,更重要的是获得和原图内容尽可能一致的修复结果。因此需要定义损失函数来约束补全结果,让其尽可能朝着原图的方向靠拢。
整个网络的损失函数包括l1重构损失和生成对抗损失。通过超参数搜索的方法,最终确定这两大损失在整个损失函数中的权重占比为1∶1。
l1重构损失包含原图与全局内容修复网络及局部细节修复网络补全结果的l1损失,其定义如式(2)所示:

其中:Igt代表原图,Ix1表示全局内容修复网络生成的结果,Ix2表示局部细节修复网络补全的结果;α是权重因子,通过超参数搜索的方法确定其值为1.2。
本文受SN-GAN 启发,发现使用光谱归一化[24]的方法,不仅可以迅速稳定地训练生成对抗网络,还能够获得更为精细的修复结果。为鉴别补全结果的真实性,实验使用生成对抗损失用于评判图片修复效果的好坏,其定义如式(3)所示:
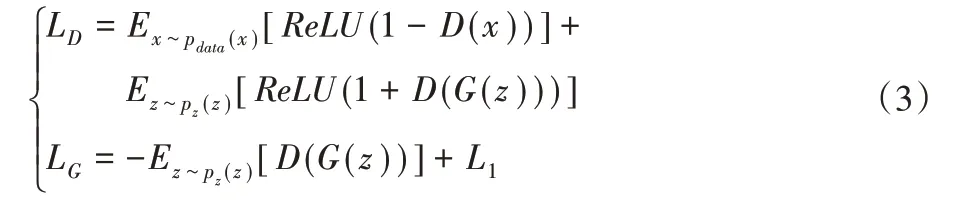
其中:D表示对抗网络,G代表生成网络,LD代表网络的对抗损失,LG表示网络的生成损失,z表示破损图片,x是原图。
2.6 算法流程
本文在Places2[25](256×256)训练集上训练图像修复模型,在Places2验证集上进行测试。网络具体的训练流程如算法1 所示。每次训练时,从训练集中随机抽取batchsize张图片,为这batchsize张图片生成黑白掩码,将这batchsize张原图和batchsize张黑白掩码重构组合生成破损图片。掩码中的黑色区域作为破损图片的已知区域,保留原图对应区域的像素信息,掩码中的白色区域成为破损图片的缺失区域,重构的掩码图片即为破损图片。掩码的生成过程如算法2 所示。其中maxVertex、maxLength、maxBrushWidth、maxAngle是控制掩码生成的4个超参数。


3 实验结果与分析
3.1 数据集
本文在Places2[25](256×256)数据集上训练图像修复模型并基于该数据集和现行的其他图像修复方法做了对比实验。该数据集包括3 个独立的场景图像数据集:训练集(1 800 000幅)、测试集(328 500 幅)和验证集(36 500 幅)。Places2 数据集最初用于场景分析,但由于其细节信息丰富,最终被广泛应用于图像修复领域。
3.2 实验过程
实验基于Chainer V6.0.0rc1 框架,CUDNN V7.0,CUDA V9.0,单块Tesla V100-SXM2 GPU 的环境训练网络模型。网络迭代训练250 000步,设置batchsize的大小为8。
训练阶段在Places2训练集上进行。本文使用canny边缘检测器提取图像的纹理特征作为纹理信息,设定canny 函数阈值1的大小为100,阈值2的大小为300。如图3所示,(a)为随机抽取的训练集图片,(b)为canny 边缘检测的结果,(c)为破损图片,(d)为使用Nazeri等[22]边缘预测模型估计的缺失区域纹理。

图3 提取图像的纹理特征Fig. 3 Extracting texture features of images
测试阶段在Places2 验证集上进行。给定一张破损图片,首先利用Nazeri等[22]预训练好的边缘预测模型为图片缺失区域生成边缘信息,再将带有边缘信息的图片输入到本文设计的网络模型中进行修复。
3.3 实验结果
本文基于Places2 验证集和其他现有的图像修复方法做了一些对比实验,如图4 所示。部分卷积方法在Places2 数据集上进行训练,训练过程中使用的掩码基于Liu 等[21]提出的不规则掩码数据集。内容感知[5]方法是基于矩形掩码在Places2 数据集上训练。从图4 可以发现,本文方法要优于部分卷积[21]和内容感知[5]的修复结果,一方面因为使用gated 卷积[23]学习一种动态的特征选择机制;另一方面因为引入边缘信息作为缺失区域的轮廓约束。使用部分卷积[21]方法修复的结果往往会带有明显的边界信息,出现修复效果模糊的问题,产生这一问题的根本原因在于部分卷积对掩码的更新类似于腐蚀的操作,当前过滤器中有一个有效像素和多个有效像素对于更新下一层的掩码没有什么差别。使用内容感知[5]方法修复的结果同样也带有明显的边界信息,不能够很好地捕捉已知区域的全局和局部信息,原因在于该模型的主要用途是补全多个矩形缺失区域的内容,当它扩展到修复图片不规则缺失区域内容的工作上时,就会出现上述问题。

图4 Places2验证集上的比较Fig. 4 Comparisons on validation dataset Places2
由于实验使用的图片分辨率较低,用户可能无法从视觉上观察到补全区域与原始图片对应区域之间的细节差异,且用户评判图像修复效果的主观性过强,因此需要一些指标作为评判图像修复效果好坏的客观标准。为此,使用峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)、结构相似性(Structural SIMilarity,SSIM)和Inception 分数(Inception Score,IS)指标作为评价标准,在Places2 验证集上测试本文提出的模型,同时和其他现有的图像修复方法做对比,其比较结果如表6所示。

表6 不同方法修复效果对比Tab.6 Comparison of inpainting effects of different methods
PSNR是使用最为广泛的一种图像客观评价指标,是基于对应像素点间的误差。给定一个大小为m×n的干净图像I和噪声图像K,均方误差(Mean Squared Error,MSE)的定义如式(4)所示,PSNR的定义如式(5)所示。其中为图片可能的最大像素值,如果每个像素都由8 位二进制来表示,那么该值就为255。
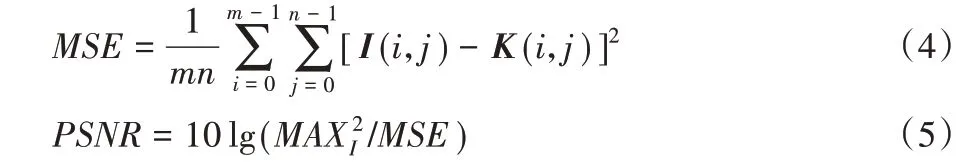
结构相似性(SSIM)指标基于样本x和y,分别从亮度l(x,y)、对比度c(x,y)和结构s(x,y)三方面度量图片的结构相似性。l(x,y)的定义如式(6)所示,c(x,y)的定义如式(7)所示,s(x,y)的定义如式(8)所示,SSIM的定义如式(9)所示。将α,β,γ设为1,SSIM 的公式如(10)所示。其中,μx为x的均值,μy为y的均值,为x的方差,为y的方差,σxy为x和y的协方差,c1,c2,c3是3个不为0的常数。
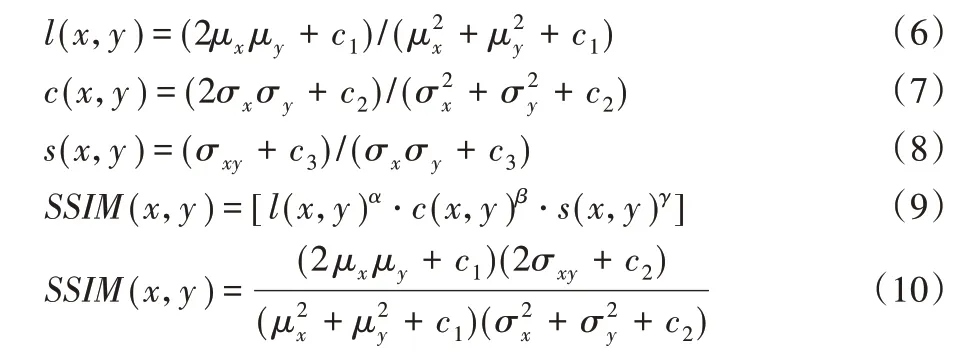
IS(Inception Score)是利用google 的inception 模型来评估GAN 生成图像的多样性评估指标。的定义如式(11)所示,DKL(P‖Q)的定义如式(12)所示,IS的定义如式(13)所示。将生成器生成的N张图片x输入到Inception V3 中,将输出1 000维的向量y。其中,P(y|x)表示x属于各个类别的概率分布。

PSNR 的值越大,图像失真越小;SSIM 的值越高,图像结构信息保持得越完整;IS 的值越低,图像质量越高。从表6 可以发现,用本文方法修复的结果要明显优于部分卷积[21]方法和内容感知[5]方法修复的结果。
在Places2 验证集上测试对比后,本文还做了用户调查,一共邀请10 名用户来评判补全结果的真实性。只有这10 名用户都认为补全结果是真实图片,图片才被判定为真实的,否则会被判定为虚假图片。由本文方法修复的图片,33.6%的图片被用户认为是真实的;由部分卷积[21]方法补全的图片,10.4%的图片被用户判定为真实的;由内容感知[5]方法修复的图片,4.8%的图片被用户评判为真实的。由此可见,使用本文方法得到的修复结果能更好地满足人们的视觉连贯性。
4 结语
本文提出了一种基于扩张卷积的图像修复方法,网络模型由生成网络和对抗网络两大部分组成。在开展图像修复工作时,首先利用其他方法获取缺失区域的纹理信息,之后将获得的纹理信息作为纹理约束放入到生成网络中训练图像修复模型。生成网络引入扩张卷积的思想,通过增大感受野的方法来显著提升图像修复的质量;通过引入gated卷积[23]和内容感知[5]的思想,确保图片的全局和局部一致性;对抗网络由SN-PatchGAN 鉴别器组成,用于评判图像修复效果的好坏。最后,通过在Places2验证集上和其他现有图像修复方法做对比实验,证明了本文方法的可行性和有效性。
后续会借鉴Nazeri 等[22]的思想,将获取缺失区域纹理信息和修复缺失区域内容这两个过程联系在一起,使之成为一个连续的过程,并将该技术应用于消除图片多余场景上。此外,由于本实验缺少UI 界面,后期会通过搭建PyQt5 平台,动态地模拟和展示破损图片的修复过程。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2022年8期)2022-08-31
中国医院院长(2022年13期)2022-08-15
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
软件(2020年3期)2020-04-20
现代计算机(2019年19期)2019-08-12
保健与生活(2019年7期)2019-07-31
金桥(2018年4期)2018-09-26
