
基于特征和关联关系的社交平台欺诈检测
2020-06-03 07:58:24李旭伟
四川大学学报(自然科学版) 2020年3期
郭 琦, 李旭伟
(四川大学计算机学院, 成都 610065)
1 引 言
海外版“抖音”TikTok是目前世界上最受欢迎的短视频APP之一,极大地丰富了我们的精神生活.但是同时也存在一些黑产团伙,他们通过注册大量账号进行作弊行为,比如刷粉、刷赞、色情投稿等.类似的作弊行为也广泛存在于微博、Twitter和Facebook[1-2].本文主要针对在用户关注场景下的刷粉的作弊行为,结合用户特征和用户之间的关联关系,提出一种新的解决方案.
早期的反作弊算法主要使用个体的特征信息[3-7].而随着深度学习理论的完善和神经网络强大的拟合性能,出现了一些图算法利用根据图上的关联关系进行建模[8-14].近几年也有使用图卷积神经网络[15](Graph Convolutional Networks,GCN),同时利用节点信息和网络拓扑结构进行建模.但是现有的方法不能很好地解决该场景下的问题.原因包括:(1) 无法对新个体进行预测; (2) 超大的数据量,对实时性和算力要求极大.
基于上述分析,本文利用个体特征信息和个体之间的关联关系,构建用户关系网络,同时特征信息和网络拓扑结构信息进行训练和预测;并且根据个体特征相似程度,对图上节点的邻居抽样进行训练及预测;通过学习生成节点低维表示的函数,而不是节点的低维表示,从而实现对新个体进行预测.
2 相关工作
早期的反作弊算法仅利用个体特征信息,通过k-Nearest Neighbors(KNN)[3], decision trees[4],artificial neural networks[5]或者内容和行为特征[6]等方式构建模型.这种方式只考虑了节点的特征,但对于很多场景而言,各个节点之间的关系也蕴含着大量的信息.节点和关系可以构成图,是指数学(图论)中的用顶点和边建立相应关系的拓扑图.随着深度学习的发展和图算法的完善,将图上的拓扑结构信息加入到了网络.
基于图上的拓扑结构建模的主要思想是,将网络中的每个节点转换为低维度的潜在表示,两个点在图中共有的邻近点(或者高阶邻近点)越多,则对应的两个低维向量之间的距离就越短;Adam等人[7]提出的PyTorch-BigGraph模型;Yu 等人[8]提出的NetWalk模型均是仅利用图上的拓扑信息得到节点的低维表达,之后再通过其他算法进行训练和预测.这种方式对于特征丰富的样例来说,不能充分挖掘特征中存在的信息;Kipf等人[9]提出GCN模型,同时对节点特征和节点网络拓扑结构进行建模和训练.关键步骤是采用全图的拉普拉斯矩阵与原始特征矩阵相乘,作为一次卷积操作,得到的输出隐层继续迭代进行该卷积操作;如刘凯等人[10]提出的恶意代码同源性分析模型.但是随着互联网的繁荣发展,我们所关注的实体数动辄都是上亿级别,卷积操作会耗费大量的时间和内存.Hamilton等人[11]将采样的思想进行应用其中,提出了GraphSAGE模型,在一定程度上缓解了之前方法的缺陷.
因此,本文在GraphSAGE的基础上提出带权采样的GraphSAGE方法.根据节点之间的特征相似程度进行采样,从而使模型得到的信息更有针对性,收敛更快.
3 带权采样的GraphSAGE模型
3.1 提出问题
在用户关注场景下,作弊主要分为刷量作弊和导流作弊.刷量作弊是黑产团伙用大量的账号关注某些用户,使这些用户拥有大量的“僵尸粉”.导流作弊是作弊账号关注大量的正常用户,正常用户出于好奇心会查看这些关注者具有导流信息的头像或者个性签名,从而达到导流的目的.两种作弊手段不仅干扰后台推荐算法等其他算法的应用,同时也对短视频创作环境产生了恶劣的影响.
本文分别从行为、时间和内容三方面选取特征.行为特征是该用户一段时间内行为分布的统计,比如近1 h关注其他用户次数、观看视频个数等.根据特征重要度仅选择一部分行为分布统计作为特征.时间特征是该用户发起关注时间和注册时间的时间差.内容特征是个性签名的长度、是否含有某些特殊字符等特征.特征的维度见表1.

表1 特征维度
根据用户之间的关注关系构建无向图 G,G可定义为G={V, E, A}. 其中,V={v1, v2, v3,…} 是用户集合; E={eij, epq, exy,… } 是无向边集合;A={a1, a2, a3,…}是节点属性集合.当用户i对用户j发起关注,则eij存在于集合E.这样,图G能清晰地用户的特征和用户之间的关联关系.网络结构示意图如图1,每个节点具有属性,节点和节点之间存在关联关系.

图1 网络结构示意图Fig.1 Network structure diagram
3.2 建模思路及算法详细设计
3.2.1 思路及总体设计 针对用户关注场景下的作弊问题,本文提出建模思路:某用户所关注的用户大部分都是其他已被识别为作弊的用户所关注的用户,则该用户有很大的作弊嫌疑.
GraphSAGE的核心操作是不断根据节点的邻居节点进行采样和聚合操作.但是在很多场景下,随机采样不是一种很好的方法.本文提出带权的GraphSAGE方法,即在采样阶段,根据邻居节点和本节点的特征相似程度进行采样,如算法1.
算法1Weighted GraphSAGE embedding generation algorithm
Input: Graph G{V,E,A}; depth K; weight matrices Wk,∀k∈{1,…,K}; non-linearity σ;differentiable aggregator functionsAGGREGATEk,∀k∈ {1, …, K}; neighborhood sample functionNs()
Output: Vector representations zvfor all v∈V
2) for k=1…K do
3) for v∈V do

Ns(v)});
6) end
8) end
算法1的大体思想是,每一次迭代,节点都会从它们的邻居节点获取信息.随着迭代次数的增加,节点会根据其在图中的位置,获取越来越多位于图远端的信息.

由于用户关注场景的特殊性,当k为偶数的时候,节点与其k阶邻居才同属关注者或者被关注者.所以根据特征相似度对邻居进行采样的操作当且仅当k为偶数,其他情况采用随机采样.
3.2.2 信息聚合 由于采样后的节点邻居并不具有顺序,所以聚合函数对特征的操作必须是可适用于无序向量的.目前广泛使用的有3种聚合函数,分别是平均聚合、LSTM聚合和pooling聚合[11].本文实验部分采用的是平均聚合方式,取抽样邻居的隐藏层向量的平均,定义如下.
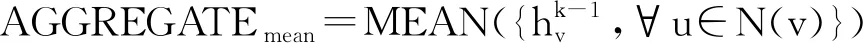
4 实 验
本节主要展示本文提出的模型和其他模型的对比实验.
4.1 数据集描述
本文使用TikTok关注场景下真实数据集进行实验.取2019年10月12日到2019年10月16日期间的用户特征和用户关注关系数据,共涉及110 991 678 个用户和1 488 455 647条关注关系.对数据集进行随机采样并分成3部分,前3天的数据用于训练,第4天的数据作为验证集,最后一天的数据用作测试.标签有两类,分为正常用户和作弊用户,其中作弊用户为已被后台识别的作弊用户.采样后进行训练和预测的数据集描述见表2,可以看到正负样例比例为1∶26.76.
在正常用户和作弊用户中各随机抽取了20个,并以这20个用户作为关注者,绘制用户关注关系图,如图2.

表2 采样后数据集描述
从图2可以看出,(1) 作弊用户关注的关注行为要远远多于正常用户;(2) 不同作弊用户所关注的用户之间会有一些重叠.

图2 抽样数据关系图Fig.2 Network structure diagram
4.2 评价指标
由于场景的特殊性,正负样例数量极不平衡,本文采用精确率(Precision)、召回率(Recall)和f1分数(F1-measure)来衡量模型的表现.
其中,TP是真正例;FP是假正例;FN是假反例. 精确率表示被模型分为正例的样例中实际为正例的比例.召回率度量实际为正例的样例被模型分为正例的比例.f1分数是精确率和召回率的加权调和平均.
4.3 实验环境及参数设置
在表3中列出了实验中一些重要的超参数.使用交叉熵作为损失函数,用精确率和召回率来评价模型.在本文所研究的场景下,因为样例是极不平衡的,取交叉熵损失函数的类权重为[0.037, 1].采用ADAM优化器作为模型的优化函数,ReLU作为激活函数.所有模型基于Pytorch框架搭建,采用单卡Tesla V100进行训练.

表3 重要超参数描述
4.4 实验结果
4.4.1 线下结果 本文对比了在各种场景下应用很广的两种分类模型,同时选取了近几年基于图的几种算法作为Baseline.
Logistic Regression:根据表1所列出的特征,训练一个线性分类器对样例进行预测;Random Forest:同样地,根据表1中的特征,训练一个树分类器;DeepWalk:通过训练DeepWalk[12]模型获取图上节点的低维表示.之后将节点低维表示作为输入,训练一个LR模型进行预测;Ensemble Method:同时考虑节点特征信息和网络拓扑结构信息.对每个节点,将其特征和由DeepWalk得到的低维表示拼接作为新特征.之后训练一个LR模型进行预测;GraphSAGE:是一种可以泛化到未知节点的模型.通过训练聚合节点邻居的函数(卷积层),使GCN扩展成归纳学习任务,对未知节点起泛化作用.
本文提出的带权采样的GraphSAGE方法是在GraphSAGE方法上进行改进.通过改变抽样方式是模型有了更好的效果,同时加快了模型的收敛.由于占用线上环境内存过大和时延等原因,并未将传统的GCN作为Baseline.对比实验结果见表4.

表4 对比实验结果
为了进一步将本文提出的模型和GraphSAGE做对比,取前40个epoch模型在验证集上的损失函数值,绘制模型训练收敛曲线见图3.本文提出的weighted GraphSAGE方法收敛的更快.

图3 验证集损失函数收敛曲线Fig.3 The loss on validation set
4.4.2 线上结果及样例分析 本文提出的模型结合一些已有规则上线后,在线上精确率到99.9%,日召回8万余作弊样例.另外发现两个之前未知的黑产作弊团伙,两个团伙均为真人众包平台作弊,日作弊量级在4万左右.
随机找一个独立召回的样例进行分析,线上根据行为序列进行判断的模型给出的分数为0.006,即模型认为极大概率这是正常用户,而本文提出的模型给出的分数为7.83,即认为该样例作弊嫌疑很大.由此,结合用户行为信息和关系信息进行作弊检查有很大的必要.
5 结 论
本文提出带权GraphSAGE模型,将GraphSAGE模型创新性地应用于社交平台的反作弊场景,并对GraphSAGE模型的采样算法进行改进.在真实大数据集上进行了线上线下的测试,均有较大程度的提升.未来可尝试将该模型用于视频点赞作弊、虚假评论作弊等其他相关场景.
猜你喜欢
苏州科技大学学报(社会科学版)(2023年4期)2023-03-03 05:37:43
机械工业标准化与质量(2022年6期)2022-08-12 02:07:42
心理学探新(2022年1期)2022-06-07 09:15:40
汉字汉语研究(2021年4期)2021-11-26 10:24:04
国际眼科杂志(2021年9期)2021-09-15 03:24:42
装备制造技术(2020年2期)2020-12-14 03:09:16
广东教学报·教育综合(2020年15期)2020-03-23 05:58:29
小学阅读指南·低年级版(2018年5期)2018-11-02 10:19:50
中国卫生(2015年12期)2015-11-10 05:13:34
学苑创造·A版(2015年9期)2015-11-04 08:39:46
