
基于文献计量的国内LDA主题模型研究进展分析
2020-06-01 08:23:08王鹏飞
图书情报研究 2020年2期
王鹏飞 张 斌
(黑龙江大学信息管理学院 哈尔滨 150000)
1 引言
随着计算机网络的迅猛发展和自媒体终端的快速普及,计算机网络上文本数据的容量也以惊人的速度增长,由此带来的困难就是寻找一种合适快速的对文本进行相似性分析,对文本内容进行分类的方法,并且快速、高效的对文本内容所蕴含的深层次意义进行挖掘和探索。从1969年出现的经典向量空间模型(VSM)[1],到20世纪90年代出现的潜在语义分析(LSA)模型[2],再到21世纪初期出现的概率隐性语义分析(PLSA)模型[3],分析工具在一步步发展,同时需要分析的文本的规模也在不断增长。一直到2003年,Blei根据PLSA 模型的缺陷,对该模型进行了贝叶斯改进,得到了潜在狄利克雷分布(Latent Dirichlet Allocation,LDA)模型[4]。LDA 主题模型的提出为解决文本内容的分类和深层次信息挖掘带来了新的思路,从而提高了文本内容分类有效性和文本内容相似性分析的速度以及效率。该模型将词、主题、文档三层结构都进行贝叶斯概率分布,认为每个文档都包含若干个主题,每个主题都包含若干个特征词,文档中的每个词是通过“以一定的概率选择了某个主题,并从该主题中以一定的概率选择了某个词语”来获得的,重复上述步骤得到了整个文档。
虽然LDA 主题模型的产生已经有十几年的历史,但是尚缺乏从文献计量的角度来对该模型的使用情况做一个简要的综述和分析。因此本文拟从文献计量学的角度,综合利用各种可视化分析方法和工具,系统的梳理自该模型提出以来所产生的相关文献,总结该领域的发展趋势,为以后更好的利用该模型进行研究提供借鉴和参考。
2 数据来源和研究方法
2.1 数据来源
为确保数据来源充分合理,本次研究拟在中国知网(CNKI)进行相关文献的检索。具体检索条件为:在“中国知网”启用“高级检索”功能,选择“期刊全文数据库”进行专业检索,为尽量全面的查询相关文档,检索表达式按照如下方式 书 写:SU=' LDA Theme Model' OR SU='Latent Dirichlet Allocation Theme Model' OR SU='LDA 主题模型' OR SU=‘LDA 模型’ OR SU=’lda 主题模型‘ OR SU=’lda 模型‘ OR SU=’潜在狄利克雷分布模型‘,因为LDA 主题模型的提出时间是2003年,所以发表时间设置为从2003年到2018年,来源类别勾选“全部期刊”,其余条件默认,检索实施时间为2019年6月4日,共计得到符合要求的文献475 条。将符合要求的文献的题名、作者、单位、文献来源、关键词、发表时间数据导出,输出为电子表格形式,借助Microsoft Excel 2019 进行数据的归并与分类处理等。
2.2 研究方法
为充分达到本文的研究目的,拟将文献研究法、社会网络分析法、统计分析法等各种可视化分析方法综合应用。各方法在本研究中所发挥的作用如下图1所示。
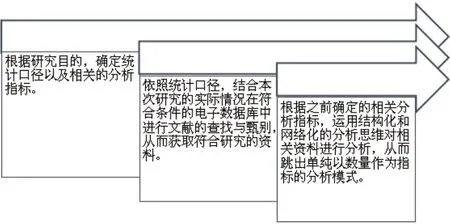
图1 技术方法图
由图1可知,统计分析法贯穿整个研究的始终,从开始的确定统计口径和指标一直到最后的社会网络分析法都离不开统计与分析,文献研究法负责基础的资料搜集与处理,为下一步的研究提供符合要求的材料,社会网络分析法在本次研究中起主要作用,从系统的角度对文本进行分析,从而揭示“LDA 主题模型”在不同领域之间的研究趋势发展情况。
3 数据分析
3.1 年度发文量分析
发文量的高低反映了使用该模型进行研究热度的大小。在导出的全部数据之中提取发文时间,并抽取出其中表示年份的四位数字,之后进行分类汇总统计即可以得到在2003年到2018年之间各个年度之间的发文量如表1所示,趋势如图2所示。

表1 各年度发文量统计
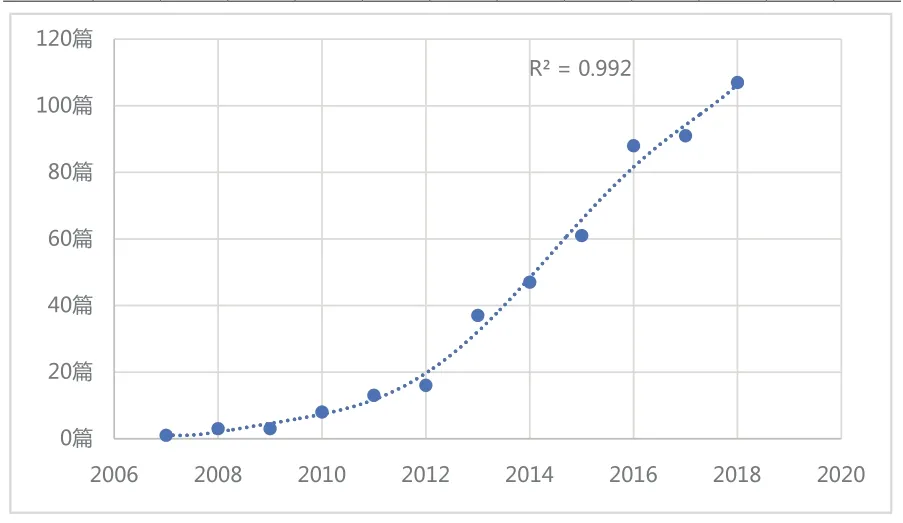
图2 各年度发文量趋势图
结合图1和表1可知,符合要求的文章发文数目从2007年开始呈现出递增的趋势,其中2008年和2009年的发文数量持平,均为3 篇。在2012年之后递增幅度明显增大。从2007年发表相关文章1 篇,到2018年的107 篇,趋势如图1虚线所示,该趋势可以用一个R2=0.9 928 的一元回归模型来进行表示,且该趋势线可以拟合12个年份中的10 个年份,能够较好的同论文的发文数量趋势相拟合。该趋势可以用y=0.0 012×x6-14.796×x5+74 437×x4-2×108×x3+3×1 011×x2-2×1 014×x+8×1 016 来表示,其中y 代表年度发文数目,x 代表从2007年开始直到2018年的每一年,利用上述一元回归模型进行计算,可知2018年的发文数目将近是2014年的2.27 倍,说明使用该模型进行研究仍然是一个热点,使用该模型的上升趋势较为明显。
3.2 高产作者分析
文章的作者因为其专业背景不同,教育经历各异等种种因素,从而产生出对同一个问题会有不同的见解,会从自己所掌握的各种知识的角度来分析问题,从而得到不同的结论。通过分析高产出的作者有哪些,可以得到该模型的有关研究更加倾向于哪个方向、哪个领域,从而可以更好的利用该模型指导自己的研究。
因为大部分论文都是由若干个作者合作而成,所以本文将出现某位作者署名的论文都定义为该作者的研究成果,以此为统计标准进行作者产出成果数目的统计。
普赖斯曾指出,将某一领域的全部科学家人数进行开平方,得到的人数撰写了全部论文数量的50%。经统计,在本文研究的491 篇文献之中,共计出现作者1 178 位,根据普赖斯的观点,将作者出现次数降序排列,前34 位作者为高产出作者,同时结合本文的实际情况,将成果数量大于等于3 的作者确定为高产作者,则高产作者统计表如下所示。
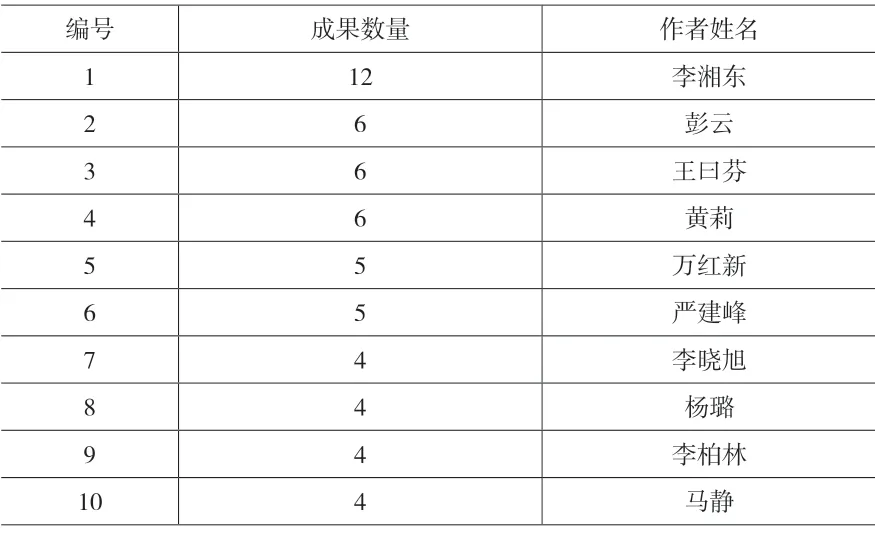
表2 高产作者统计表(部分)
在上表中,发文量最高的是李湘东,共计12篇(共计出现1 次),最低的大部分为3 篇(共计出现34 次),二者之间相差为9 篇,说明该领域的研究尚未形成一个合理的结构,“中间层”的科研力量匮乏,从而导致缺乏动力推动该领域出现更多的高水平研究者。而根据“中国知网”的数据显示,李湘东关注“计算机软件及计算机应用、图书情报与数字图书馆、互联网技术”领域;彭云关注“计算机软件及计算机应用、互联网技术、自动化技术”领域;王曰芬关注“图书情报与数字图书馆、新闻与传媒、计算机软件及计算机应用”领域;黄莉关注“计算机软件及计算机应用、水利水电工程、图书情报与数字图书馆”领域。由此可见,LDA 主题模型主要借助计算机领域的相关方法和手段,如通过编程以及算法实现等方法,在其他文本内容挖掘领域发挥相关作用。李湘东等将LDA 主题模型作为书目信息的表示模型,通过不同的特征加权策略规避因为文本内容短小而产生的问题,提出了复合加权LDA分类方法[5];王曰芬等利用JGibbs 软件对国内知识流领域的相关研究进行了探讨,从学科分类主题抽取的角度进行探究,认为该方法可以合理有效的挖掘学科结构和研究热点[6]。所以继续探索“计算机软件及计算机应用”领域的相关模型、方法等工具,亦或是继续挖掘该模型在计算机领域中的应用,从而更好的指导相关研究。
3.3 高产机构分析
不同的机构由于性质、层次等属性不同,从而造成了科研实力的强弱之分。“双一流”高校、“985”高校、“211”高校等比一般院校的平台要宽广,能掌握的科研资源更加丰富,相对来说科研实力要强,如果该领域的研究机构中一般院校数量居多,那么说明该领域的发展速度还有待于继续提高;如果高水平院校较多,那么说明该领域的发展潜力巨大,发展势头良好。
借鉴3.2 节中确定“高产作者”的方法,将“高产机构”确定为出现次数在3 以上的机构,若同一个机构下分别出现多个二级机构,则以二级机构分别计算。同一篇文章出现n 个相同机构的,按该机构出现n 次计。相关统计结果如表3所示。
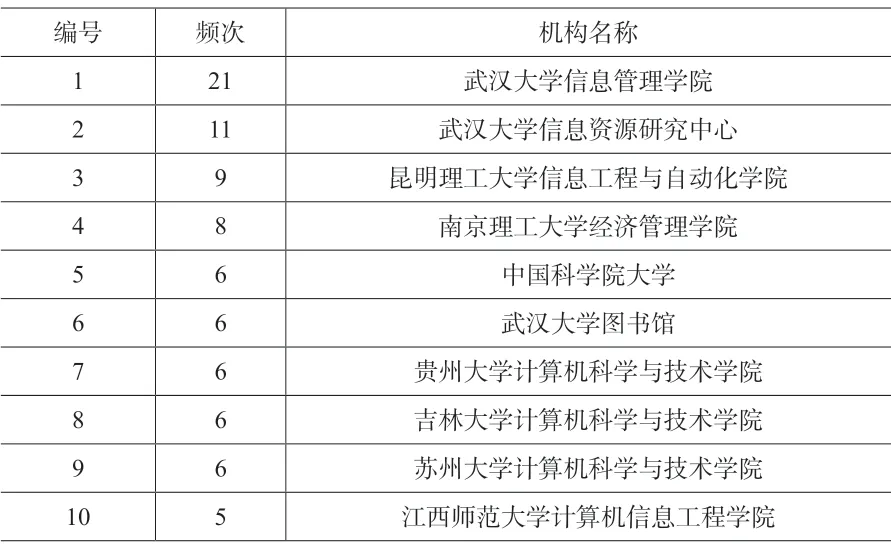
表3 高产机构统计结果(部分)
由表3可知,武汉大学信息管理学院出现频次21,居第一位,其次武汉大学信息资源研究中心出现频次11,居第二位。上表排名前十位的机构之中,除了“昆明理工大学信息工程与自动化学院”和“江西师范大学计算机信息工程学院”来自一般院校之外,其余机构均属于“高水平科研院所”。说明LDA 主题模型的相关研究在国内属于研究热点,相关领域内的高水平研究机构越多,越能够使得该领域的研究处于国内外领先位置,产出的学术成果质量也较高,同时也能够帮助领域内的更多机构提升科研水平,使得LDA主题模型的有关研究慢慢走向成熟。
3.4 高产作者之间的合作分析
将表3之中所列的高产作者导入Bibexcel软件构建作者之间合作关系的矩阵,结合ucinet和NetDraw2.084 可以得到作者之间的合作关系图,如图3所示。
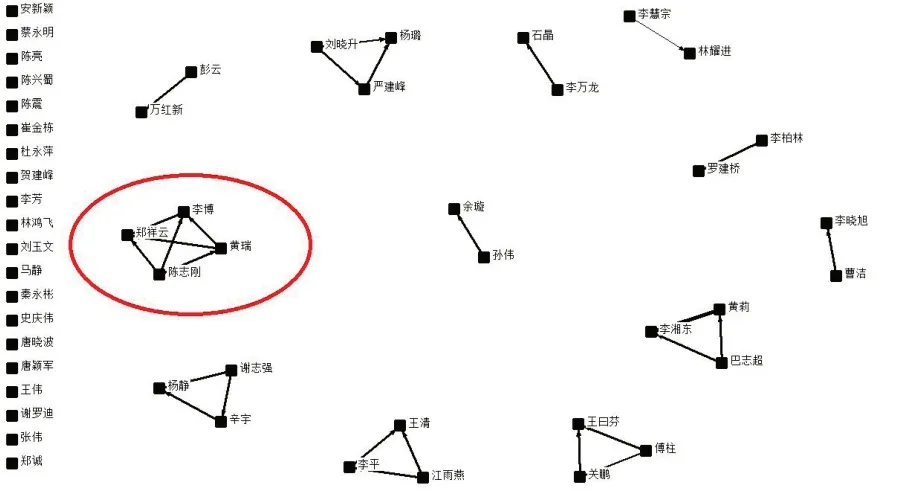
图3 高产作者合作关系图
从图3可以看出,该领域的高产作者之间合作关系比较分散,在ucinet6.0 中可以得到该网络(高产作者共现矩阵)的密度为0.033 3,远远小于1,标准差0.333 8,尚未形成比较集中的合作趋势,合作研究在LDA 主题模型领域未形成主流态势。同时得到的还有点度中心度(degree),该数值的大小表示节点在该网络中的重要程度高低。经计算,点度中心度的最大值为6.000,最小值为0.000,平均值2.118。点度中心度数值最大的有陈志刚、黄瑞、李博、郑祥云,上述四位作者的关注领域存在都关注计算机相关领域的特点,这与之前的高产出作者共同关注的领域是一致的,都在图2中的红色圆圈内部。结合表3可知,上述几位作者的发文数量并非排列在前几名,但是仍然具有比较高的重要性。说明关注某个领域的研究趋势发展情况,不仅要根据作者的发文数量来进行分析,同时还应该关注该领域内重要程度较高的作者,进而来作出综合的分析和判断。
3.5 高产科研机构之间的合作分析
科学技术的发展变化使得以往靠单独某个科学家或者单独某个科研机构独立完成科学研究的时代已经一去不复返了,从而越来越凸显出团队协作的重要性。各个机构之间通过组成科研团队来扬长避短,从而产生“1+1 >2”的作用。通过分析某个领域内涉及到的高产科研机构之间的合作关系,可以更好的了解促使该领域向前发展的科研动力,并对该领域的发展趋势作出一定的分析、预测和判断。
利用Bibexcel、ucinet6.0 以及NetDraw2.084软件,结合表4中的“高产机构统计结构”生成合作关系矩阵,进而绘制出合作关系图,如图4所示。
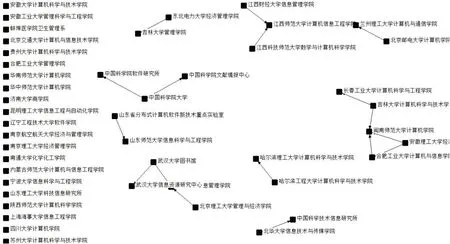
图4 高产机构合作关系图
经计算,高产机构合作关系矩阵的密度为0.016 7,密度较小,反映到图4上的趋势即点与点之间的联系较为分散,无法形成比较紧密的联系。同时部分高产机构同一般机构合作,或者是独立完成科研任务,因此在图4中单独一列。在ucinet6.0 中计算点度中心度和出度中心度,如下表4和表5所示,来寻找在该网络中重要性最高的科研机构,以及影响力较强的科研机构。该矩阵的点度中心度最高值为5.769,最低为0.000,平均值1.306。最高值出现在“闽南师范大学计算机学院”、“武汉大学信息管理学院”,其次重要性程度较高的科研机构还有“安徽理工大学经济与管理学院”、“合肥工业大学计算机与信息学院”、“吉林大学计算机科学与技术学院”等。从表4可以看出,科研机构大部分都同“计算机”以及“信息管理”相关,说明对于“LDA 主题模型”的研究同这两个领域有着紧密的联系。随着数据的爆发式增长,各种非结构化和半结构化的数据随之越来越多,这种数据结构有别于传统的数据形式,在分析起来有相当的难度[7],应用传统的直观统计或者分析方法往往难以完成相应的分析任务。因此借助计算机领域的相关编程手段,如R 语言和Python 语言等来帮助对上述数据进行分析成为大多数研究人员进行文本挖掘,主题探究,文档相似性检测等活动的选择。
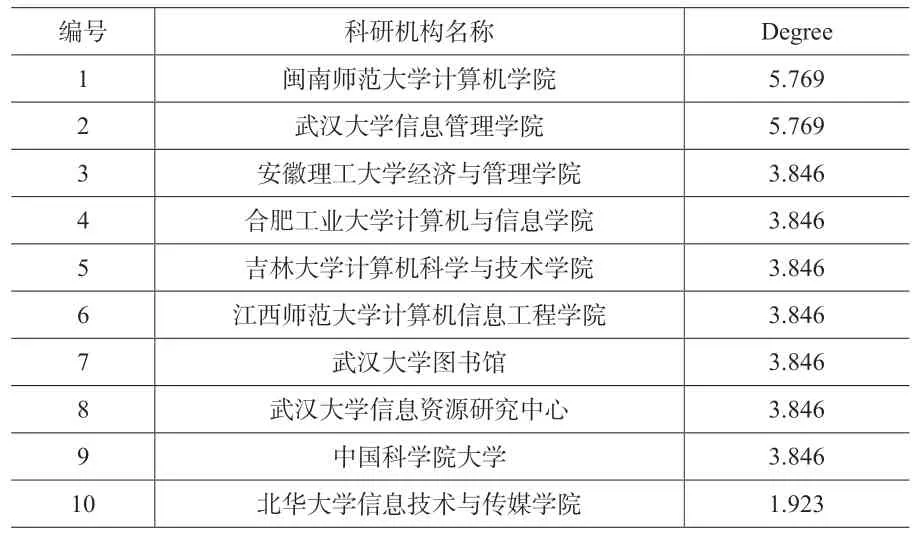
表4 点度中心度计算结果(部分)

表5 出度中心度统计结果(部分)
出度中心度最高值为10,根据表6的统计结果,“武汉大学图书馆”、“武汉大学信息管理学院”、“吉林大学计算机科学与技术学院”位居前三位,说明上述三个单位在该领域更可以对其他机构产生影响。如通过信息管理领域,或者是图书馆、情报学相关领域,将“LDA 主题模型”与文本挖掘、潜在主题分析等相结合起来,对其他机构的研究起到相关的示范性作用。
使用Python 自编程序,将出度中心度统计结果前10 位的科研机构在地图上予以显示,并通过不同的出度中心度数值进行区分,结果如图5所示。
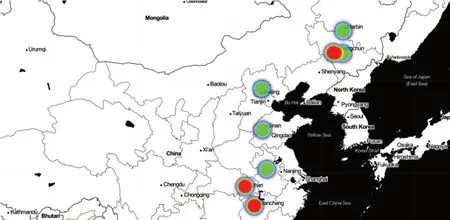
图5 出度中心度前10 位所在地理位置分布
在图5中,每一个科研机构通过各自的经纬度在地图上进行标注,光圈的大小表示其出度中心度的高低,红色光圈所表示的机构出度中心度较高,其次是绿色光圈,如果两个机构的地理位置较近,那么光圈会发生重叠现象。根据图5的结果,在LDA 主题模型相关研究与应用领域,从地理位置的角度来看,我国东部地区的科研机构明显走在中部、西部科研机构的前列,即图上光圈多分布于东部,而南方的科研机构又明显走在北方科研机构的前列,红色光圈南方多于北方;从机构的角度分析,以武汉大学为平台,“武汉大学图书馆”、“武汉大学信息管理学院”代表的科研机构明显对该领域的其他机构可以产生影响。东部地区凭借区位优势、地理优势等方面可以较之于其他区域更为快捷方便的掌握国外先进的技术、获得较为前沿的信息,说明地理环境的不同以及经济发展水平的差异同LDA 主题模型的研究有着密不可分的联系,作为国外首先提出的主题模型,快速而及时的对国外的研究动态有所掌握也可以对国内有关研究起到积极的促进作用;而武汉大学作为我国老牌的“985”、“211”以及“双一流”高校,自身的科研实力不可小觑,因此以其为平台的相关科研机构也可以发挥更大的作用。
3.6 关键词分析
关键词是一篇文献的浓缩,通过阅读一篇文章的关键词,可以对该文章产生一个大体的了解,而对关键词之间的共现情况进行分析,则可以了解这些文章所对应的科研领域的研究情况,分析得出其研究热点。
对全部491 篇文献的关键词进行提取,首先对同义词进行数据的预处理,比如“潜在狄利克雷分布模型”、“LDA 模型”、“LDA 建模”、“LDA 主题模型”等表述含义相同或者相近的词语统一替换为“LDA”。经过BIBXECEL 软件统计,共有关键词501 个,全部进行统计反而不利于展示整体趋势,因此按照出现频次的降序进行排列,取前100 位关键词进行共现分析,结果如图6所示。
图6中各点之间的沟通较为紧密,不同关键词之间有较为频繁的联系。图谱中各个节点之间的平均距离为2.051,即每个节点只要通过2 个节点左右即可以同其他节点之间产生联系,符合“小世界理论”,且呈现出明显的集团化特征。之后继续计算高频关键词之间的出度中心度(OutDegree)、入度中心度(InDegree)等数据,部分结果如表6所示。
经计算,出度中心度最大值为422,出现的节点是“LDA”,出度中心度越高,说明该节点“影响”别的节点的能力越强,即该领域均是以“LDA”为研究主干开展的,在图5中“LDA”节点也是出于中间地位,同各个节点的联系非常密切,将“LDA”应用到图示节点的各个领域中,同时节点“LDA”的入度中心度为30,说明“LDA”在同其他领域的研究过程中自身也在慢慢发生改变,提高了适应性;而“Gibbs 抽样”出度中心度为70,但是入度中心度为0,说明该抽样方法在“LDA”的相关研究中居于本质地位。入度中心度最大值为166,出现在节点“主题模型”,入度中心度的高低反映的是该节点被其他节点所影响程度的大小,具体到本文中,即“主题模型”、“文本分类”、“微博”、“主题挖掘”等领域主要被“LDA”所影响,这些领域也是“LDA 主题模型”目前主要发挥作用的领域。
李昌亚等鉴于在LDA 主题模型建模的过程中,使用Gibbs 抽样只考虑高频词而忽略词语对文章本身的重要性,所以将词语的权重值也纳入考虑范围中,提出了一种改进的LDA 建模方法,并将该方法在社科文献领域进行了实证研究,证明该方法的有效性[8];李湘东等将LDA 模型用于书目信息分类系统之中,采用Gibbs 抽样对模型的隐含变量进行推断,快速高效的在大规模数据集中提取有效信息,之后通过采集有关实验数据,实例验证了提出方法科学有效,有较好的分类效果[9]。
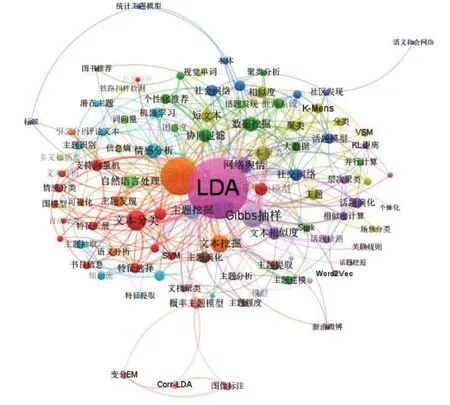
图6 关键词前100 名共现图谱
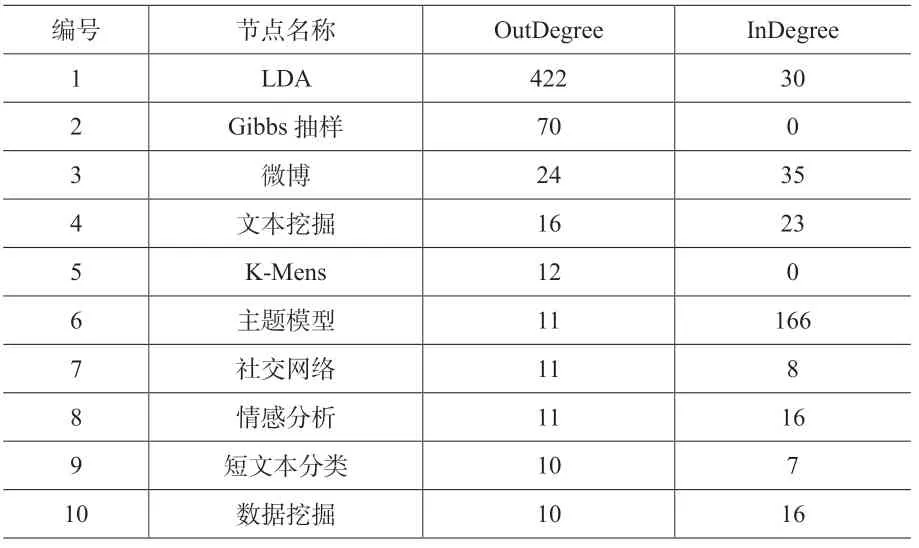
表6 各个节点的出度中心度和入度中心度(部分)
3.7 文献来源情况分析
将上文中提到的全部491 篇文献来源情况进行排序,分类汇总之后,共计得到来源期刊180种。按照出现频次进行降序排序,部分统计结果如表7所示。
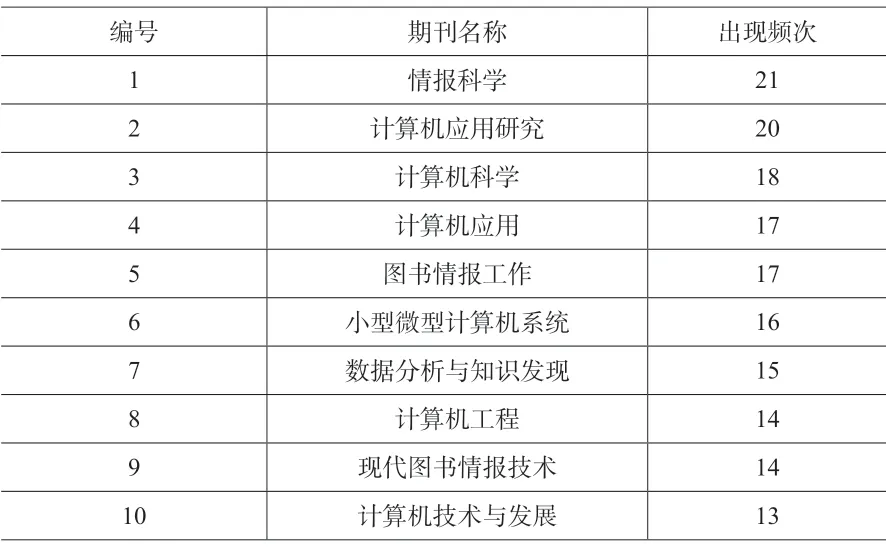
表7 文献来源情况统计结果(部分)
从期刊级别来看,在全部180 种期刊之中,有96 种期刊来自“核心期刊”和“CSSCI 期刊”,占比53.33%。高质量期刊占据大多数,说明有关该领域的研究成果价值较高,针对该领域的相关研究处于一个比较成熟的阶段,从中可以利用和继续研究的内容和方向也比较多。
从相关期刊的名称来看,LDA 主题模型所涉及到的不仅仅是计算机相关领域,“图书情报”领域(《情报科学》、《图书情报工作》、《数据分析与知识发现》等),“机械制造”领域(《机械设计与制造》、《铁道标准设计》),甚至是“食品工程”(《微生物学报》、《食品与发酵工业》等)相关领域。涉及到的相关领域之广,说明LDA 主题模型具有相当强大的生命力和较高的普适性,从一个侧面也反映了继续进行该模型有关研究的价值。
4 结论
本文综合采用文献计量、文献研究和社会网络分析法,对国内LDA 主题模型的研究进展进行了分析,通过梳理高产作者、高产机构、作者之间的合著、机构之间的合著以及关键词之间的联系,可以得出如下结论:
国内LDA 主题模型的研究呈现出“对LDA主题模型进行自身完善”和“扩展LDA 主题模型的应用领域”三方面的特点。第一,在“对LDA 主题模型进行自身完善”方面,主要是针对目前出现的各种“非机构化”以及“半结构化”的数据,传统的LDA 主题模型在处理这些内容方面捉襟见肘,无法完全满足要求,因此不同的研究人员基于各自不同的角度来对该模型进行完善和增补,如将词语的权重值纳入LDA主题模型的考虑范围之内,或者是对隐含的变量信息通过各种方法进行推断,对文本的分析从表面深入到了文字内部,探究文本内部隐含的主题,从而增加LDA 主题模型的准确性;第二,在“扩展LDA 主题模型的应用领域”方面,将LDA 主题模型从传统的文本分类拓展到文本挖掘领域、计算机领域、图书情报领域甚至食品工程领域,改变了主题的表达方式,以定量的方式进行展现,让计算机可以理解主题的特点并进行计算,在不同领域产生了巨大的影响,并且已经取得了一系列成果;第三,地理位置较好、经济发展水平较高的地区的科研机构较之于其他地区的科研机构更容易接触到LDA 主题模型的前沿研究,同时机构自身水平的高低也是推动LDA 主题模型研究的重要内部原因,“985”、“211”以及“双一流”等高校更容易产生科研成果。
国内LDA 主题模型的相关研究趋势呈现出同整个外部社会环境息息相关紧密联系的趋势。随着大数据在各行各业中发挥越来越重要的作用,发现越来越多的社会现象背后蕴含的本质内容成为情报学所亟需解决的问题之一,尤其是最近学术界开始考虑将“数据”作为情报学的研究对象的问题,充分挖掘数据本身的对已有内容的描述和对未来内容的能力。更是凸显了“数据”的重要价值和作用。而LDA 主题模型作为一种非监督机器学习算法,本身具有的灵活性和较好的适应性,能够更好的在大量的数据中挖掘出符合要求的信息,进而为更好的体现情报本身“耳目、尖兵、参谋”的特点。
