
区块链增强型轻量级节点模型
2020-06-01 10:54赵羽龙牛保宁
计算机应用 2020年4期
赵羽龙,牛保宁,李 鹏,樊 星
(太原理工大学信息与计算机学院太原030600)
(∗通信作者电子邮箱niubaoning@tyut.edu.cn)
0 引言
区块链技术由于其不可篡改、可追溯、去中心化等特性逐渐得到广泛的关注。它最早起源于中本聪的比特币白皮书[1],在数字加密货币[1]、供应链金融[2]、数据公证[3]、资源共享[4]等领域有许多的应用场景。区块链使用链式的结构和一致性协议保证区块数据不可篡改和可追溯,但无休止的数据追加对单个节点的存储造成很大压力。采用完全副本(每个节点保存一份)的数据存储方式,对系统存储空间也造成很大浪费。
以比特币为例,截至2019 年3 月27 日,共产生569 001 个区块、17 612 496个比特币,总交易量395 438 152笔,数据总容量196.15 GB,链上认证地址49 245 944,市值近5 000 亿[5]。据BitNodes[6]统计,全网使用70001 协议(>=Satoshi:0.8.x)同时在线的全节点有近10 000个。单个节点需要的磁盘空间约200 GB,每个节点保存一份,那么保守的估计整个系统需要2 PB 的存储容量来存储区块数据,而且每年还以线性的速度增长。
SPV(Simplified Payment Verification)节点模型[1]不存储区块链交易数据,只具有钱包功能,可以减轻存储压力;但减弱节点间的对等性,使得系统日趋中心化。全节点存储全部的区块数据,可以验证交易(挖矿),为其他节点提供数据,具有完备的节点功能。针对存储资源较少的设备,比特币白皮书中介绍了SPV节点,它在初始化同步过程中只下载区块头,然后根据自身需要从全节点请求数据。这种节点所需的存储大小只与区块高度成线性关系,与区块大小无关。每个区块头80 B,一年仅需4.2 MB 的空间,极大地减轻了存储压力。但这种节点完全依赖于全节点,无法验证交易,容易遭受拒绝服务攻击[7]、女巫攻击[8]等安全性问题。随着数据量的增加,SPV 节点增多,全节点个数减少,区块链系统的去中心化程度减弱,数据安全性、稳定性下降。SPV 节点减少了数据存储,但是增大了网络带宽压力,在数据存储和数据共享方面对系统没有贡献。
本文提出一种增强型轻量级节点模型ESPV(Enhanced SPV):采用完全副本方式保存新区块(最近产生的n个区块),让轻量级节点具有交易验证功能;同时把旧区块(新区块之前的区块)进行分片存储,降低数据的冗余度;并且创建分级区块分区路由表,加快数据检索的速度,保证数据的可用性。
本文的主要工作为:
1)提出增强型轻量级节点模型ESPV,使轻量级节点可以验证交易,具有完整的节点功能,增强节点间的对等关系,保障区块链系统的去中心化、稳定性和安全性
2)在确保数据的可靠性和可用性的前提下对旧区块进行分片存储,减少存储空间浪费,增强系统的可扩展性;保存完整的区块头数据,保障系统中区块数据的真实性。
3)提出适合ESPV 存储特征的路由表,既提高了数据查找效率,又达到负载均衡的作用,避免全节点压力过大的问题。
1 相关工作
比特币网络中的节点模型主要包括全节点和SPV 节点,它们具有不同的功能和机制。全节点[1]是第一个也是最安全的节点模型,它通过下载和验证从创世块到最近发现的区块来确保区块链的有效性,可以独立地共享数据和验证交易。SPV 节点只保存区块头数据,仅可以验证支付,不能验证交易(挖矿)。验证支付时,SPV 节点需要依赖从全节点拉取符合布隆过滤器条件的MerkleBlock 消息[9],通过其中的Merkle 树的哈希认证路径,判断目标交易是否在该块中;同时,利用区块头检测该块是否在链中已被压入足够的深度,来确认交易是否成功。Delgado-Segura 等[10]对比特币的UTXO(Unspent Transaction Output)数据进行了分析,发现大部分UTXO 产生于最近的少部分区块中。
在简化单节点数据存储方面,目前主要有区块修剪、副本策略、纠删码技术、共识单元等解决方案。Bitcoin-core[11]提出一种区块修剪策略,下载的区块数据构建完UTXO 集后就可以删除,极大地减少节点所需的存储空间。但随着修剪策略的流行,系统中区块数据的可靠性会下降。Jia 等[12]提出一种存储可扩展性模型,将区块链中的区块数据保存在一定比例的网络节点中,增加了额外的两条链,在减少存储空间的同时也增加了系统复杂性。Dai 等[13]提出一种低存储要求的区块链存储框架,使用纠删码技术[14]对区块数据进行分块存储,降低单节点的存储和带宽压力,增加了节点的计算量。Xu等[15]提出共识单元的方法,让节点形成社区,在社区内自治式分片存储区块数据,但仅针对私有链,对公有链存在查询开销太大的问题。本文仅在单节点中维护分片信息,建立路由表,采样处理数据,系统复杂度和计算量都比较小,且适用于公有链。
P2P(Peer-to-Peer)网络[16]中节点具有不同的类型和数据存储状况,为了加快数据的检索,通常会建立集中式或基于DHT(Distributed Hash Table)[17]的分散式路由表。集中式的路由表适合于网络节点数目较少的情况[18],网络中的节点在搜索数据时首先向路由中心请求数据所在位置,在得到目标节点的位置后它与目标节点单独进行联系。系统的响应时间短,数据可用性强,但中心服务器压力较大,存在单点故障问题。基于DHT技术的路由表查找算法性能为log N[19],进行了负载均衡,适用于较大规模的节点网络,不存在单点故障问题。它是基于内容的查找方式,可以直接找到每个小数据分片的位置,同时也都需要维护一份索引数据,导致整个索引表很大,数据更新维护的成本高。
2 增强型轻量级节点模型
由前两章内容可知,完备的节点功能包括交易验证(挖矿)、数据存储和数据共享。为了让节点功能完整,增强型轻量级节点模型的设计也从这三部分出发。SPV 节点为减少数据存储不再保存完整的区块数据,也不能进行挖矿,致使其对全节点产生严重的依赖,节点之间的关系不再对等。同时,比特币中每一笔交易的输入为历史交易的输出或者为coinbase交易,即挖矿奖励。在进行交易验证时需要追溯到交易输入中的每个交易,而且大部分的交易输入都集中在后面生成的区块中。于是我们构想是否可以通过保存最近生成的部分区块数据(新区块),让轻量级节点可以验证大部分交易,具有挖矿功能。而对于旧区块,主要用途是构建完整的UTXO 库,请求量较少且不会发生更改,因此,不需要全部冗余保存,可以采用数据分片技术,降低数据的冗余度,减少存储空间浪费。旧区块分片保存后,为了保证数据可用性,可以通过设计适当的路由机制,加快数据检索速度。
如图1 所示,本文对高度为567 301~568 201 的区块进行固定间隔采样,查询向前追溯一定块数范围时可以验证当前区块中交易的比率,即通过向前遍历区块,查找其中是否包含该区块中交易的输入。可以发现仅需保存少量最新的区块就可以验证较高比例的交易。于是本文针对比特币的交易特性和现有节点模型存在的问题,提出增强型轻量级节点模型。模型的核心思想是区别对待新区块和旧区块,对新区块进行完全副本存储,对旧区块进行分片存储,采用不同的存储策略,为轻量级节点增加交易验证的功能,提高系统在存储方面的可扩展性,维护节点之间的对等性,保障系统的去中心化程度和稳定性。
2.1 新区块存储
网络中的节点对于新区块的请求量较大,为网络带宽型。网络中的全节点需要同步最新的区块数据,参与挖矿的节点也想尽早获取最新的区块数据,在它之上开始挖矿以更大概率地获取区块奖励。SPV 节点需要同步其区块头来完成支付验证。这是因为比特币采用链式的追加模式,每笔交易的成功需要确保其被打包在区块中,连接上链,且在该区块之上有不小于6块新区块的确认。
根据新区块的网络特性,ESPV采用完全冗余的存储策略来保存新区块数据,即保存一定窗口大小的新区块数据。这样可以为其他节点提供数据共享服务,减少全节点带宽压力,增加系统的稳定性。
节点在初始化时首先查询最新的区块高度h,然后从网络中下载区块高度为h - 3 000 到h 的区块数据,同时构建UTXO 库。在进行交易验证时如果未在UTXO 库中发现交易的输入,那么将此交易转发给全节点。由图1 可知这样可以验证大部分的交易,当已验证的交易数目足够多时,对应的区块大小会达到系统设定的最大阈值进而可以将它们打包成块开始挖矿计算。
目前区块交易数目正以线性的速率增长,为保证系统的可用性,ESPV 设计了相应的动态调整策略。从图1 可知,交易的验证率随着新区块数的增长而增长,据此我们展开相应的设计。与挖矿难度值调整周期相同,ESPV 也采用每2 周进行一次调整。比特币系统平均10 min 生成一个区块,则每2 016 块区块就需要进行一次调整。节点需要记录上次调整的区块高度,并以此为起点直到之后产生2 016块数据。在这2 016 块中随机采样40 块区块,如果这些区块在其前3 000 块区块中可验证交易数低于80%的区块数大于4,则为新区块存储区块数n 加32;如果可验证比率超过95%的区块数大于32,则n减32;否则n不发生改变。这里的32是由现有区块数和能保证较高比例交易验证率时所需的最新区块数按时间增长比率得出,较为合适。这些具体的参数都可以进行自定义配置,以适应不同节点的硬件环境和需求。
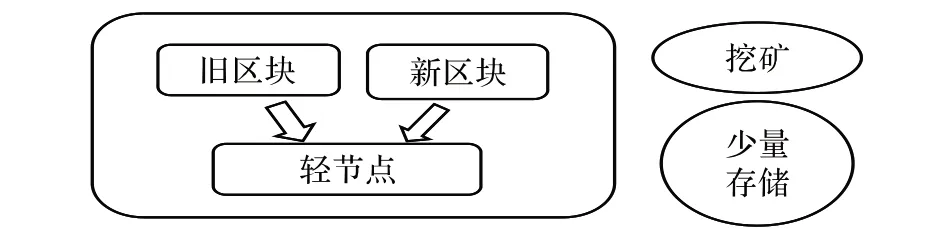
图2 增强型轻量级节点模型Fig. 2 Enhanced lightweight node model
2.2 旧区块存储
系统对旧区块的请求量较小,为非带宽型。只有当网络中有新的全节点加入或者重新构建全节点时,才需要拉取它们。这是因为其使用类似日志的形式,一旦生成就已经成为不会发生更改的历史数据,节点无须重复获取它们。在全节点进行验证交易时,需要从创世区块到最新产生的区块之中构建出完整的UTXO 集,从中查找交易的输入,确保它是未花费的,余额大于等于支出花费,且验证签名确认资产所属权,所以旧区块的可靠性和可用性对于整个系统来说是十分重要的。
考虑到旧区块的访问特性,ESPV对其采用分片存储的方式,即每个节点保存部分历史区块数据。这使得每个节点的存储压力变小,减少系统对存储空间的浪费,增加系统的可扩展性。
本文使用开源项目Bitnodes 对比特币网络中的全节点数据进行了统计分析。截至2019 年4 月10 日,近两年内比特币使用70001 版本协议的全节点同时在线的个数中最大值为12 770,最小值为6 671,平均值为9 931[6];并且同时在线的节点个数具有一定的稳定性。由此本文对节点的可靠度进行了统计,可得图3。在P2P系统中,可靠性关系[20]为:
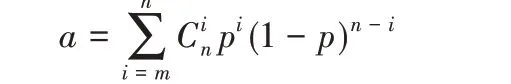
其中:a为系统可靠度;p为节点可靠度;r为副本数。可解得:
r = log(1- a) log(1- p)
根据Borel 定律[21]定义低于10-50的概率都是不可能的。故设
a = 1- 10-50
根据图3可以保守估计节点可靠度p=0.1,由此可以计算出r约为1 000。

图3 节点可靠性Fig. 3 Node reliability
由于比特币系统中区块大小是分布不均匀的[5],且节点通常需要获取连续的区块数据,所以进行分片时采用连续、固定存储空间大小的方式较为合适。根据现有数据存储情况进行分析,可设置一个分片的大小为5 GB。为更好地适应节点间不同的存储空间差异,对旧区块制定不同的初始分片大小,即小、中、大3 种,对应的分片个数为4、8、12。节点在接收到区块时需要统计其大小,并记录系统区块分片的起始和终止区块高度,将这些高度值添加入到一个数组中,定义为分片锚定高度集,这些值将不会发生改变。每个节点在加入P2P 网络或者进行数据的扩充和删减时都以这些固定的区块高度为界限。在节点加入网络时,节点产生一个从0 到最新区块高度的随机数,以分片锚定高度集中离这个随机数最近的高度值作为其数据存储的起始高度,根据其可用空间的大小保存对应级别的分片数目。
假设整个系统中种子节点和矿池等性能良好、存储空间充足、稳定性强的节点运行全节点,其他硬件等条件受限的节点运行ESPV 节点,这样系统中区块数据的可靠性和可用性具有基础的保障。目前完整的区块数据量在线性地增长,为保障系统的可用性每年需要将初始分片大小加1,已经加入的节点向后延伸一个分片。
为了激励节点尽可能多地保存区块数据,ESPV对存储量不同的节点请求设置不同的优先级,在节点内部通过获取节点分片属性进行请求队列排序,存储数据较多的节点优先得到请求回复。
2.3 分级区块分区路由表和链信息
结合旧区块的存储策略,ESPV 设计了新的路由机制:分级区块分区路由表。根据节点存储分片的大小,构建4 个区块分区路由表,分别为小、中、大、全节点路由表。路由表以Map 形式存储,key 为分片起始块号,value 是节点数组,每个节点为ip:port。

查找指定高度区块所在节点时,需要在分片锚定高度集中找到离它最近的分片起始块号h。之后依次按小、中、大、全节点路由表查询key 为h 的节点列表。根据获取的节点列表长度L,产生从0~L 的随机数N。把节点列表中第N 个元素作为起始节点依次尝试连接节点:如果在小路由表中未找到连通的节点则继续向下,从中路由表中进行查找;如果找到目标节点则终止查询,向目标节点发起请求。为加快查询,将小、中、大路由表尝试节点数的最大值分别设置为8、4、2,全节点路由表不作限制。采用直接定位的方式避免请求数据的洪泛广播,减少系统带宽压力,提高数据检索速度,保障数据可用性。根据节点存储数据量的大小,采用分级的方式从小到大进行节点访问,可以尽可能地利用不稳定节点,减少全节点和存储数据较多节点的带宽压力,进行负载均衡,避免局部热点产生。ESPV在节点加入路由表时设置了审核机制,其持续在线时长需要超过30 min,由此得到的节点相对稳定,防止数据频繁更新对系统网络带宽造成压力。节点在加入网络后可以从其他节点获取路由表信息,并且定期检测节点的连通性,更新路由表。
为验证数据的真实性,ESPV保存全部的区块头数据。节点每次从网络中获取到区块数据后将链上的区块哈希值与计算出的该区块哈希值进行比对就可以验证区块数据的真实性,维护系统数据的安全性。区块头的数据量很小,不会对节点的存储造成压力。
2.4 ESPV模块架构
ESPV 使用不同的端口与网络中的节点进行数据共享。用端口1进行交易的接收和转发,端口2进行区块的请求和发送,端口3获取和共享路由信息,端口4发送和接收区块头。
各模块都有相应的功能。新旧区块的获取都需要由区块分区路由表取得目标节点地址,以快速从网络中拉取数据。通过得到的新区块构建UTXO 库,用于交易的验证。为加快检索速度为UTXO构建缓存机制,将一部分最近产生的UTXO加载到内存中。旧区块为系统中的其他节点提供数据服务。区块头信息可以校验从其他节点得到的区块的真实性,保障系统安全。
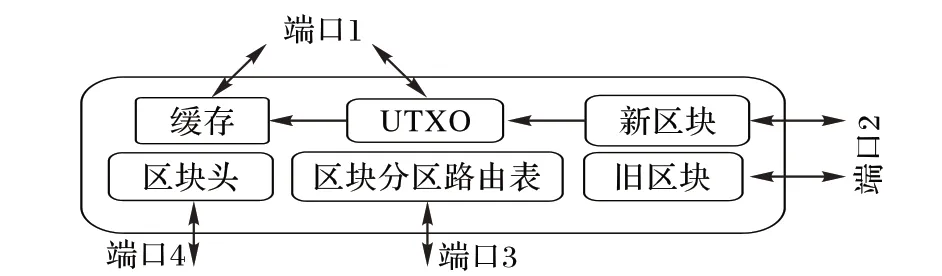
图4 ESPV模块架构Fig. 4 ESPV module architecture
3 实验与结果分析
实验的开发环境为Intel Xeo E5-2609 v4 1.70 GHz CPU和16 GB 内存的服务器。利用比特币现有区块数据进行模拟实验。
通过搭建真实节点,使用BitcoinETL[22]开源工具,对区块数据进行处理,只保留所需字段信息,获得了实验所需数据。实验过程中使用BloomFilter 算法解决了超大数据量的关联查询问题。
首先,以10 万块为一组,从中随机抽取100 个区块,从目标区块开始向前追溯3 000块区块,查询这些区块中包含该区块交易的输入的比率,即可验证交易的比率,求均值可得图5。
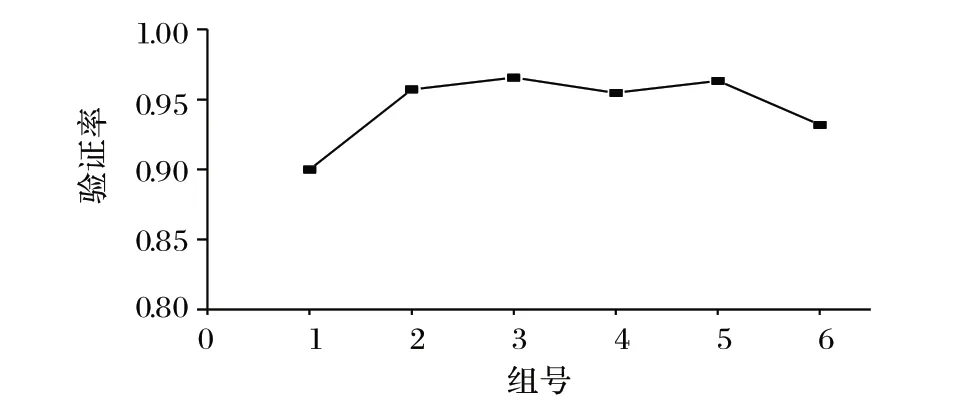
图5 总体交易验证率分布Fig. 5 Overall transaction verification rate distribution
从图5 可以看出,ESPV 适用于整个比特币现有生命周期。比特币总体的交易特征是类似的,在得到数字货币后较大可能会在近期进行交易。
其次,使用最新的区块数据测试ESPV 的交易验证功能。实验从高度为568 201块开始,每2 016块为一个周期,随机抽取其中10%的区块进行采样处理,计算交易验证的平均比率值,可得图6。

图6 交易验证率Fig. 6 Transaction verification rate
由图6 可知,ESPV 对新区块采用的策略可以验证较高比率的交易,动态调整策略有效。
然后,ESPV 与全节点在568 201 块时的存储空间对比如图7所示。
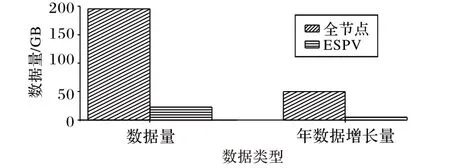
图7 存储空间对比Fig. 7 Storage space comparison
通过分析图7,可以得出下面的结论:
1)ESPV节点比全节点所需的存储空间明显减少;
2)ESPV的数据量增长速度远小于全节点,可以符合普通PC的硬件条件,增加系统的可扩展性。
假设全网70%的节点使用ESPV 节点,30%为全节点,同时在线节点约1 万个,那么保守估计整个系统可以节省约1 PB数据存储空间。
最后,测试ESPV的可靠性和可用性。本文使用Java语言设计了节点对象,它具有节点类型、可靠度、IP、端口、区块段和网络带宽属性。通过创建1 万个节点对象来模拟P2P 节点,建立分级区块分区路由表;同时,创建1 万个全节点对象,作对比实验。分别从两组节点中随机获取长度为10、100、1 000和10 000的区块数据。

根据现有网络节点的分布和可靠性情况设置节点属性。200 个种子节点(全节点)的可靠度为0.9,网络带宽为10 MB/s;剩余30%为全节点,70%为ESPV 节点,可靠度都为0.1,网络带宽为0.2 MB/s~5 MB/s 的随机数。在创建节点对象时给区块段属性随机赋予由真实比特币数据得到的分片锚定高度集中的值,区块大小采用现有比特币中区块的大小数据。每试错一个节点需要延时10 ms。遍历节点,为节点建立路由表。用于对比的1 万个模拟全节点的带宽和可靠度与非种子节点相同,建立路由表。由实验结果可得图8。
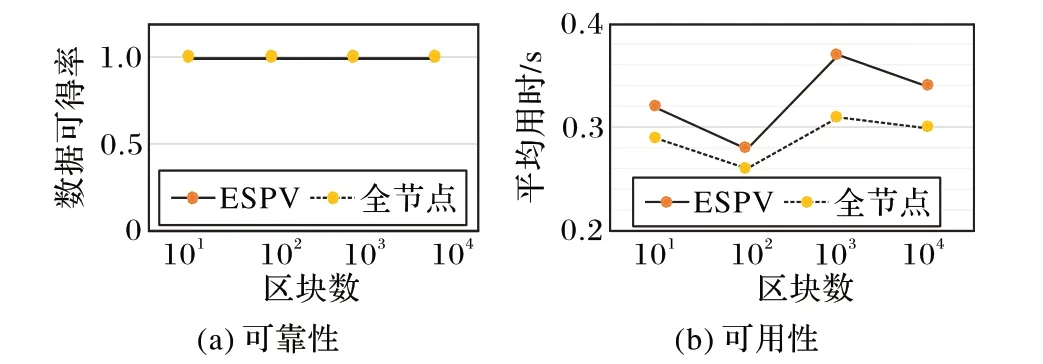
图8 数据可靠性和可用性Fig. 8 Data reliability and availability
从实验结果可以看出,ESPV节点模型和全节点的数据可得率相同都为100%,可靠性有保障。在获取区块数据的平均用时上,ESPV 节点模型略高于全节点,这是因为系统尽可能地利用不稳定节点造成延时;但P2P网络本身不稳定,较低的延时差对于单个节点的影响很小,还可以满足应用需求,能够应用于实际生产环境中。
4 结语
区块链的数据量呈线性增长模式,对单个节点的存储造成很大的压力。SPV 节点模型解决了存储问题,但它们完全依赖于全节点,使得全节点压力增大,系统的去中心化程度减弱。本文提出一个功能完备的增强型轻量级节点模型。通过对区块数据进行分析,发现保存最近的少量数据就可以验证一定量的交易,让节点具有挖矿功能。通过对网络中全节点数据进行统计分析,在保障数据可靠性和可用性的前提下,对旧区块进行随机分片存储,降低单个节点的存储压力,增加系统存储可扩展性、安全性和稳定性。为加快数据查找,设计出分级区块分区路由表,防止数据请求进行洪泛广播对网络带宽造成压力。使用链信息保证数据的真实性。为适应区块数据线性增长的模式,提出动态调整策略,保证增强型轻量级节点模型的可用性。
增强型轻量级节点模型在数据存储空间和交易验证之间进行了折中,对早期旧区块产生的UTXO 支持性较差,还需要全节点进行验证和打包,未来还需要进一步优化。
猜你喜欢
词学(2022年1期)2022-10-27
电子科技大学学报(2022年3期)2022-05-28
智能计算机与应用(2021年6期)2021-12-17
现代计算机(2021年14期)2021-11-20
综艺报(2020年21期)2020-11-30
中国科技纵横(2020年24期)2020-11-28
计算机技术与发展(2020年3期)2020-04-09
电脑爱好者(2019年17期)2019-10-30
中国教育信息化·基础教育(2016年4期)2016-05-30
卷宗(2015年12期)2015-01-07
