
基于稀疏轨迹聚类的自驾车旅游路线挖掘
2020-06-01 10:54杨奉毅马玉鹏包恒彬韩云飞
计算机应用 2020年4期
杨奉毅,马玉鹏,包恒彬,韩云飞,马 博
(1. 中国科学院新疆理化技术研究所,乌鲁木齐830011; 2. 中国科学院大学,北京100049;3. 新疆民族语音语言信息处理实验室,乌鲁木齐830011)
(∗通信作者电子邮箱ypma@ms.xjb.ac.cn)
0 引言
随着国民经济水平提升,私家车保有量迅速增加,自驾车旅游逐渐成为人们旅游出行的热门选择。通过对游客的自驾轨迹进行分析,可以发现流行的自驾车旅游路线,为旅行者的旅行路线的规划提供支持。然而,自驾车游客的活动具有较高的自主性,导致行程轨迹数据难以收集,数据的代表性和覆盖性不足。
本文采用覆盖新疆的加油数据集,挖掘流行的新疆自驾车旅游路线。该数据集记录了用户在新疆的所有加油行为,其中同样包含了所有自驾车游客的加油记录。按照时间先后将加油站点组成序列就可以得到一条加油轨迹,加油轨迹是游客旅游路线的某种采样,能够真实反映游客的时空移动轨迹,可以作为新疆自驾车旅游路线挖掘的重要数据来源。然而,利用加油数据挖掘流行的自驾车旅游路线主要面临两个挑战。首先,原始数据中人员数量众多,加油行为复杂多样,难以准确识别出自驾车游客群体;其次,相比全球定位系统(Global Positioning System,GPS)轨迹数据,加油记录产生的频率非常低,数据十分稀疏,导致同一条加油轨迹中的两个连续轨迹点之间的路径不确定,从中还原出具体的路线十分困难。如图1 所示,图中的线条为某游客自驾游的确切轨迹,圆点表示该游客实际的加油地点。可以看出,依靠单一游客稀疏的加油轨迹点数据,并不足以推断出游客实际的旅游路线。
本文的主要工作如下:针对游客群体识别的问题,通过分析已知的游客加油行为,总结出游客加油的基本特征,进而从大量原始加油记录中识别出游客群体。针对轨迹点稀疏问题,受word2vec[1]的启发,提出一种基于语义表示的稀疏轨迹聚类算法:将每个加油站看作一个单词,每条加油轨迹看作一个句子,通过word2vec学习加油站点的分布式表示,然后使用每条轨迹中站点向量的平均值表示该加油轨迹,最后通过k均值算法完成轨迹聚类,根据聚类结果挖掘流行的自驾车旅游路线。图2为本文方法的总体流程。
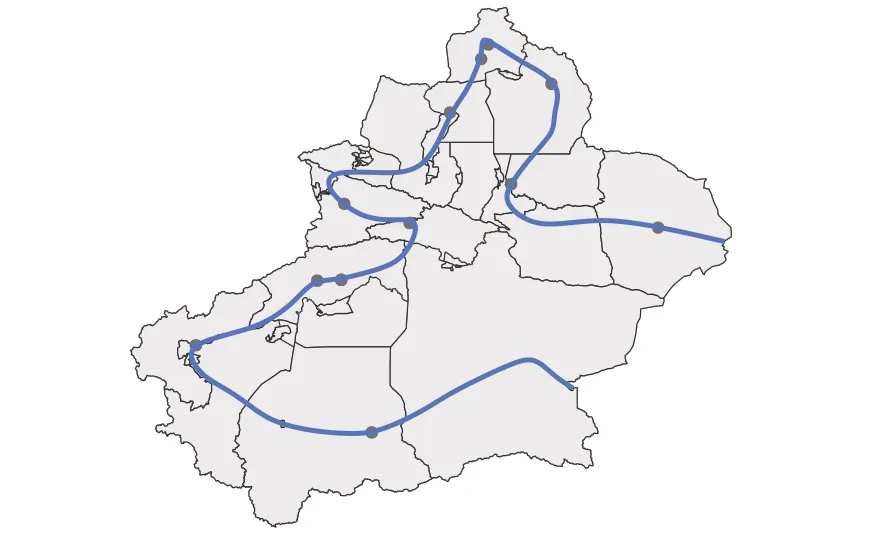
图1 某游客旅游路线与加油轨迹对比Fig. 1 Comparison between tour route and refueling trajectory of a tourist

图2 本文算法的总体流程Fig. 2 Overall flow of the proposed algorithm
1 相关工作
1.1 旅游路线挖掘
近些年来出现了大量旅游路线规划和推荐的相关研究。目前研究采用的数据主要是用户分享的GPS 轨迹数据、带地理标签的照片数据和签到数据[2]。Zheng 等[3-5]基于GPS 轨迹数据做了一系列的旅游路线挖掘和推荐的工作,取得了优秀的成果。Cui等[6]基于用户的GPS 轨迹信息,考虑用户的个性化信息,基于协同过滤技术提出了两种旅游路线推荐算法,提高了推荐结果的个性化程度。然而,GPS 轨迹虽然可以反映游客的具体旅行路线,但是相对难以获得。随着基于位置服务的发展,利用社交媒体数据进行旅游路线挖掘和推荐成为新的研究热点。文献[7]提出了一种基于主题模型的协同过滤方法,利用旅游照片进行旅游推荐。文献[8]基于游客签到数据,提出一种基于集体知识的路线推理框架,从不确定轨迹中挖掘流行的旅游路线。目前,采用这些用户分享数据进行自驾车旅游的研究较少,主要原因在于这些数据难以区分普通游客与自驾游客,其中能够完全确定为自驾游客数据的数量很少。文献[9]基于自驾游客分享的924 条GPS 轨迹,结合路网信息与旅游景点信息,以季节强度指数、多维缓冲区、核密度等方法分析自驾车游客的时空行为特征。
上述数据大多来自于用户的分享,这些用户仅仅占全部游客的一小部分,因此分析结果带有较大的偏差。与上述研究采用的数据不同,本文采用加油轨迹数据进行自驾车旅游路线的挖掘,数据集本身包含全部自驾车游客在新疆的加油行为,对于分析新疆自驾游的整体情况具有重要作用。
1.2 轨迹聚类
为了发现不同移动对象轨迹中的代表路径或共同趋势,通常将相似的轨迹进行聚类[10]。传统的轨迹聚类方法一般先使用一定的度量方法比较轨迹之间的相似性,之后采用一些经典的聚类算法进行聚类。Lee 等[11]提出了一个轨迹聚类框架,首先将每个轨迹划分为多个子轨迹,然后采用基于密度的聚类方法对这些子轨迹进行聚类。Tang 等[12]提出了出行行为聚类算法,使用结合采样的密度聚类算法解决轨迹数据中的噪声问题。Besse等[13]定义了一种新的距离度量方法,实现了基于距离的轨迹聚类。
时空轨迹聚类的核心在于衡量轨迹之间的相似性,常用的轨迹相似性度量方法包括动态时间扭曲(Dynamic Time Warping,DTW)[14]、最 长 公 共 子 序 列(Longest Common Subsequence,LCSS)[15]和编辑距离方法EDR(Edit Distance on Real sequence)[16]。
上述度量方法主要考虑了轨迹点的空间位置信息,适合用于采样频率高的GPS数据。然而,游客的加油频率非常低,通常在2~3 d,加油轨迹十分稀疏,两个连续访问的加油站点之间甚至相隔数百公里。因此,上述方法并不适用于极其稀疏的加油轨迹数据。
1.3 分布式表示
在自然语言处理领域,传统的将单词表示为高维、稀疏向量的方法基本上被基于神经网络的语言模型所取代。神经网络语言模型通过考虑词序和单词的共现来训练,其概念基于分布式假设,即在句子中经常出现在一起的单词具有更高的统计相关性。Mikolov 等[1]提出的word2vec 是其中的突出代表,它可以简单高效地学习到单词的低维向量表示,在包括机器翻译、情感分析等传统的自然语言处理任务上取得了优秀的表现。
最近,分布式表示的概念逐渐扩展到网页搜索、电子商务、推荐系统等其他领域。研究人员意识到可以将用户的行为序列视作句子,进而学习商品或用户的嵌入表示,如用户的点击、查询或购买序列。分布式表示被用于各种类型的网络推荐中,包括淘宝推荐[17]、求职推荐[18]、应用推荐[19]、房源推荐[20]等。同样,类似的方法也被提出用于社交网络分析,利用网络中节点的随机游走序列学习网络节点的嵌入表示[21]。本文同样利用这一思想,将加油轨迹中的加油站看作单词,整条轨迹看成句子,运用word2vec学习加油站的语义向量表示,用于加油轨迹聚类,还原游客的旅行路线。
2 自驾车游客群体识别
原 始 加 油 数 据 集 中 的 记 录r ={u,v,s,t,area},其 中:u、v、s、t 分别代表司机、车辆、加油站和加油时间戳;area 代表加油站所属的行政区划。从中选取数据构建人员加油轨迹数据集,选取时间范围是2016 年1 月1 日至2018 年12 月31 日。将加油记录按照人员进行重组,每个用户的所有加油记录可以组成一条加油轨迹tra ={s1,s2,…,sn},它是一个用户按时间顺序访问过的加油站点集合。
经过调查可发现自驾车游客通常具有3 个特征:1)只来过新疆一次且停留时间不超过30 d;2)具有连续加油行为,相邻两次加油时间间隔小于5 d;3)加油地点不固定且分散在各个地州市,通常不少于3 个地州市。同时,为了避免轨迹过于稀疏,本文只对加油次数大于8 次的轨迹进行分析。根据以上特征,定义了四条规则,用以自驾车游客群体的识别。对于加油轨迹数据集中的任意一条轨迹tra ={s1,s2,…,sn},如果满足:
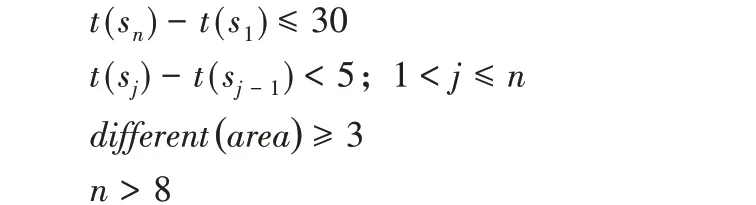
则认为轨迹tra为自驾加油轨迹,对应人员为自驾游客。
根据以上规则,从加油轨迹数据集中提取出20 646 条加油轨迹。为了验证这些轨迹确为自驾游人员所产生,本文对轨迹对应人员的基本特征做了统计分析。首先,这些人员的男女比例高达21∶1,远远高于原始数据集中3.5∶1 的男女比例,这符合长途自驾旅游中司机绝大多数为男性的实际情况。其次,游客的主要来源省份与整体情况也有着很大差异,如图3所示。
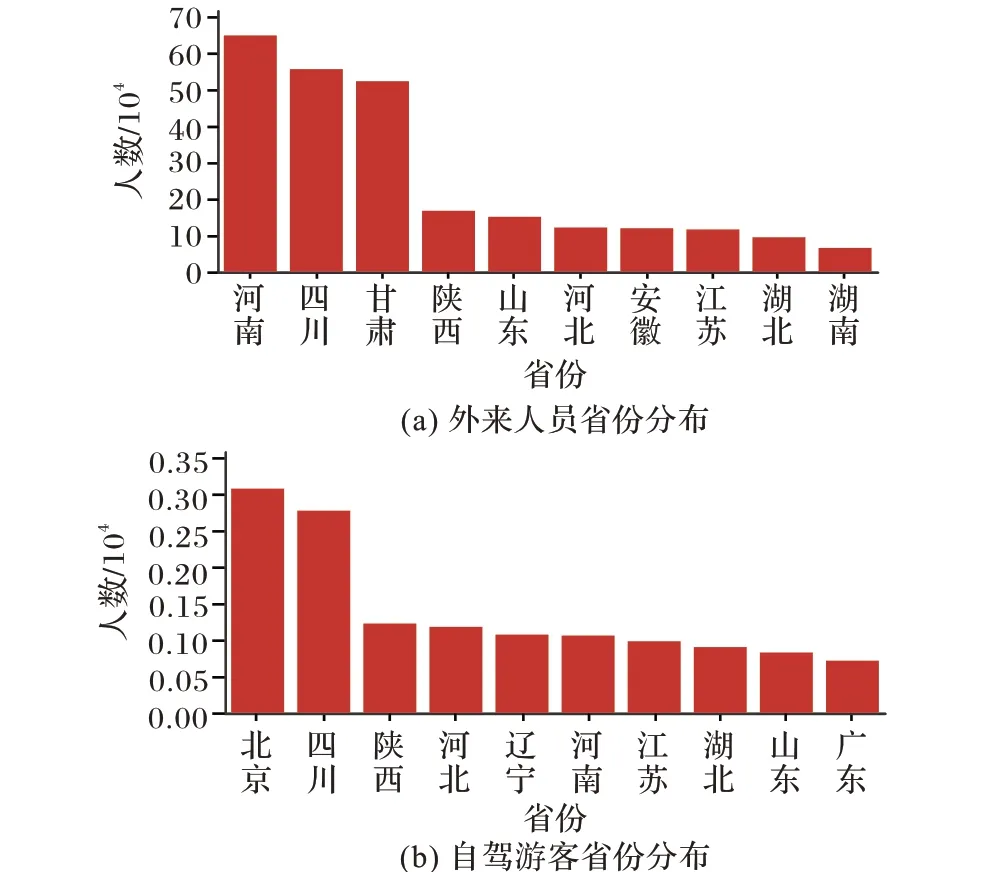
图3 外来人员与自驾游客的省份分布Fig. 3 Provincial distribution of migrants and self-driving tourists
图3(a)为原始数据集中外来人员的主要省份分布,这在很大程度上体现了外地人在新疆生活及工作的情况,可以看到,四川、甘肃和陕西等距离较近的省份,与新疆的人员交流比较密切;同时,河南、山东等省份由于人口总量大,在新疆也有大量的人员活动。如图3(b)所示,游客的来源省份发生了很大的变化,较发达省份的人员占比明显增加,来自北京的人员数量最多,而来自甘肃的游客数量很少,这体现了居民收入及消费水平对自驾车旅游的重要影响。最后,对自驾游人员的月份分布做了统计,如图4 所示。结果显示,游客的数量受季节变化十分明显,主要集中在7、8、9 三个月,与此同时,几乎没有游客选择在冬季进行自驾游,这与新疆的气候条件有着密切的关系,符合新疆旅游市场的基本情况。
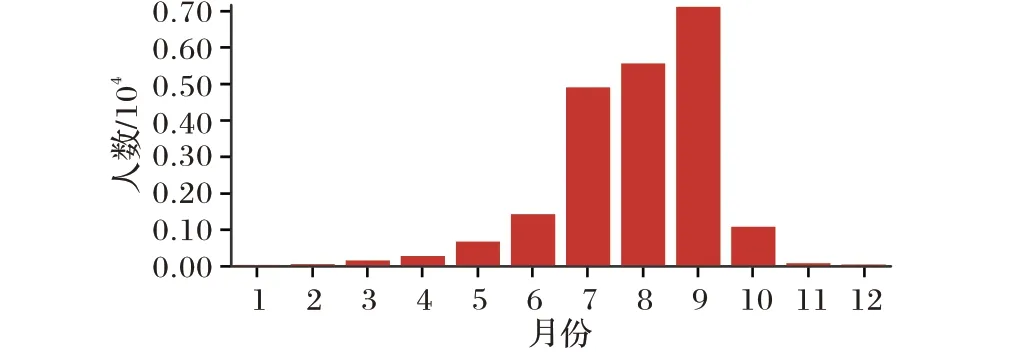
图4 自驾车游客人数随时间变化的统计Fig. 4 Histogram of self-driving tourist number variation with time
由此可见,本文定义出的规则有效识别出了自驾车游客群体,能够支撑进一步的研究工作。
3 基于语义表示的加油轨迹聚类
3.1 问题定义及分析
定义1 自驾路线。游客实际的自驾路线是一个连续的空间曲线,是游客驾车自驾的确切移动路径。
定义2 加油轨迹tra。每条加油轨迹都是按照时间先后排序的游客加油的站点序列,是自驾路线的一种采样,形式化表示为tra ={s1,s2,…,sn}。加油轨迹tra 和加油站s 对应的向量表示分别为traj和st。
定义3 加油轨迹聚类。给定游客加油轨迹集T,我们的目标是将轨迹集T划分为k个不相交的簇C ={C1,C2,…,Ck},同一个轨迹簇的加油轨迹对应同一条自驾路线,T ={tra1,tra2,…,traf}。
同一条自驾路线上会有数量众多的加油站,游客的加油行为具有极大的自主性,每条加油轨迹都可以看作是对路线上的所有加油站的随机采样。因此,虽然游客的旅游路线相同,最终的加油轨迹依然有着很大的差别。这些轨迹都反映了旅游路线的部分信息,将这些轨迹进行聚类可以得到完整的旅游路线信息。然而,加油轨迹的高度稀疏性导致基于轨迹点空间相似性的传统轨迹聚类算法无法得到理想的效果,因此本文将自然语言处理中语义相似性的概念引入加油轨迹聚类,用以更好地衡量加油站点之间的相似性。
在自然语言处理领域,语义相似的单词拥有相似的上下文。同样,在加油轨迹中,加油站的上下文通常是同一路线上的加油站,这些站点具有更高的语义相似性。使用word2vec学习站点的语义信息,得到站点的向量表示,之后取所有站点向量的平均值作为加油轨迹的向量,最后使用经典的k 均值算法实现轨迹聚类。本文算法的整体框架描述如下。
算法1 基于语义表示的加油轨迹聚类。
输入 加油轨迹数据集T,聚类簇数k,skip-gram 模型窗口大小m,嵌入向量维度d。
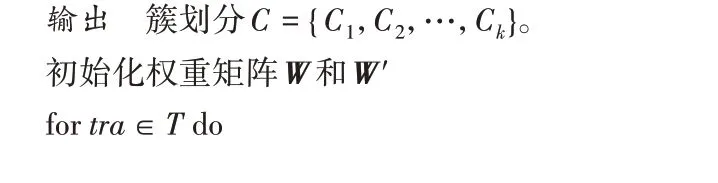

3.2 站点向量表示
本节将介绍使用word2vec进行站点表示的方法。给定加油轨迹数据集T,目标是学习到每个站点的d维向量表示。实际上,word2vec 包括两个模型,分别为连续词袋模型(Continuous Bag-of-Words model,CBOW)和skip-gram 模型。其中,CBOW 的目标是根据上下文预测中心词的概率,skipgram 模型则相反。一般而言,skip-gram 模型的效果会更好,因此本文选择使用skip-gram模型学习站点的向量表示。
skip-gram 虽然是一种无监督的方法,但它仍然在内部定义了一个辅助的预测任务。如图5 所示,首先选定中心词si,在它的前后各m 个词距内选定上下文,组成训练的单词对(si,si-m),…,(si,si-1),(si,si+1),…,(si,si+m)。在训练期间,使用包含当前中心词及其上下文的滑动窗口在语料库中移动,得到所有的训练样本,目的是借助中心词预测上下文出现的概率。构造这个监督学习的目标并不是想要解决这个监督学习问题本身,而是想要借助这一问题来学习一个好的词嵌入模型。
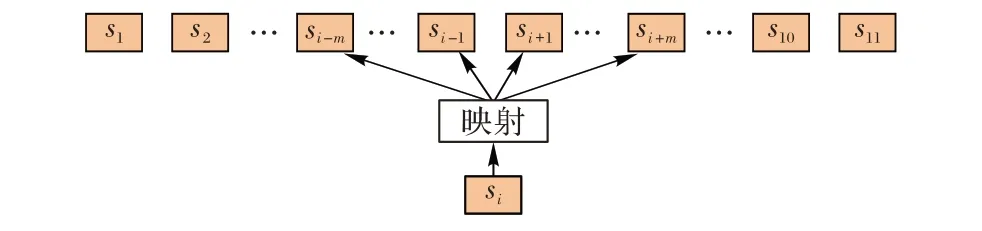
图5 基于skip-gram模型的站点嵌入表示Fig. 5 skip-gram model based station embedding representation
skip-gram 模型的结构如图6 所示,是一个简单的神经网络模型,仅拥有输入层、隐藏层和输出层三层结构。
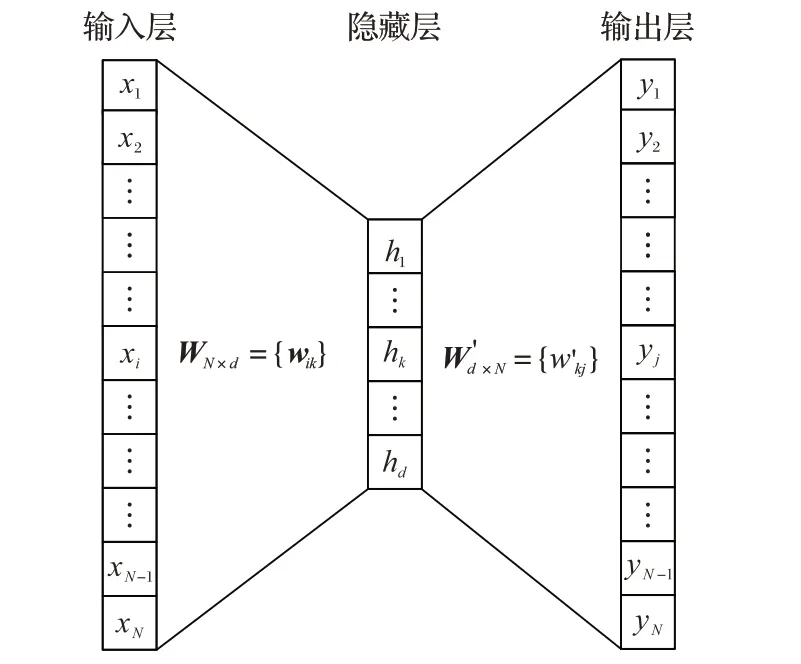
图6 skip-gram模型结构Fig. 6 skip-gram model structure
输入层和输出层都由一个N 维的one-hot 编码向量表示,N代表加油站的总数,隐藏层由维度为d的向量表示。权重矩阵WN×d和W′d×N,分别位于输入层与隐藏层之间和隐藏层与输出层之间。隐藏层没有使用任何激活函数,输出层使用softmax作为激活函数。模型的具体的训练过程如下。

3)通过反向传播算法及随机梯度下降来更新权重矩阵W 和W′,最小化损失函数。整个训练样本集上的损失函数为
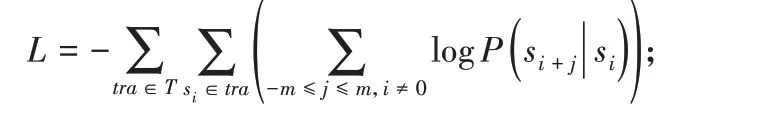
4)取权重矩阵W的每一行作为站点的向量表示。
3.3 轨迹聚类
当获得了站点的向量表示之后,就可以利用站点向量得到轨迹的向量表示。在自然语言处理中,句子向量表示的一种简单有效的方法是将句子中所有词向量进行平均[22]。类似地,对于轨迹tra,它的向量表示traj 为其包含的所有加油站s1,s2,…,sn向量表示的平均值,公式表示为:
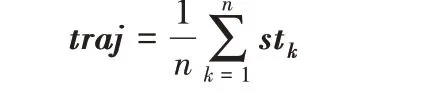
至此可以得到每条轨迹的向量表示,然后使用经典的聚类算法进行轨迹聚类。本文采用k均值(k-means)算法进行轨迹聚类。给定样本集D 和聚类簇数k,k 均值算法将样本集划分为k个不同的聚类簇C1,C2,…,Ck,最小化平方误差:

1)从样本集D 中随机选择k个样本作为初始聚类簇的均值向量;
2)计算每个样本与各个簇均值向量的距离,选择距离最近的簇,作为样本的簇标记;
3)依据新划分的簇,重新计算簇均值向量;
4)若簇均值向量未发生变化,算法终止,返回聚类簇;否则,重复步骤2)~3)。
4 实验与结果分析
4.1 实验配置
为了挖掘新疆自驾车旅游路线,采用覆盖新疆全区的加油数据集作为原始数据集,该数据集记录了2016 年1 月1 日至2018 年12 月31 日3 年时间内,所有人员在新疆的加油记录。首先对原始加油数据集进行预处理(详见第2 章),挖掘出20 646 名自驾车游客的加油轨迹作为实验数据集,涉及到全新疆1 856个加油站。实验机器系统为Ubuntu 18.04,CPU型号为Intel Core i7-3770 CPU@3.4 GHz,内存12 GB,Python版本3.6。
本文的主要参数包括:窗口大小m,站点向量维度d 和聚类簇数k。其中,m 和d 设置为默认值,分别为5 和100。新疆的自驾游路线主要分为北疆线和南北疆大环线,因此将k 值设置为2。
4.2 站点分布式表示结果分析
为了验证算法是否学习到了有效的站点嵌入表示,本文文使用余弦相似度衡量站点向量之间的相似性,观察相似的站点之间具有怎样的关联关系。本文选择阿勒泰地区的喀纳斯加油站作为目标,该站点位于著名景区喀纳斯附近,适合分析游客的加油行为。表1展示了与喀纳斯加油站最相似的10个站点。其中的1号、2号、4号、6号和8号站点同样位于喀纳斯景区附近,表明站点的向量表示有效学习到了站点的空间位置特征。除此之外,还发现10 个站点均位于著名旅游景点附近,3 号、5 号和10 号加油站位于白沙湖景区附近,7 号和9号加油站位于那拉提景区附近。这种结果表明站点向量有效地包含了站点的语义信息,将游客旅行中访问过的景点信息包含在内,有利于进一步的路线挖掘。
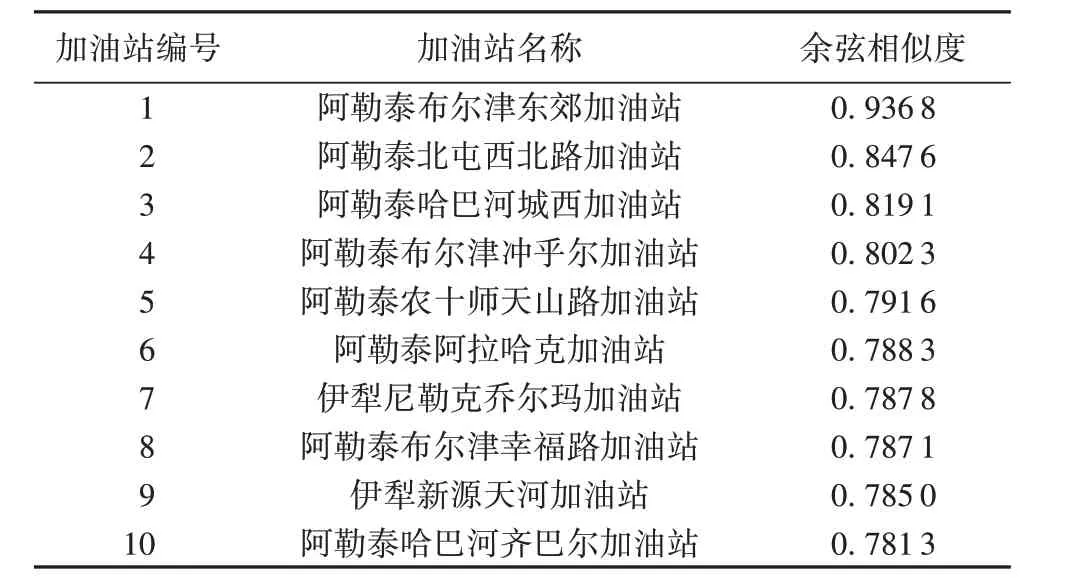
表1 与喀纳斯加油站最相似的10个站点Tab. 1 Ten most similar stations to Kanas gas station
4.3 聚类可视化结果分析
由于数据本身完全无标注,因此选择通过聚类结果的可视化,人工验证结果的有效性。如图7 所示,图中的圆点代表每个聚类簇中加油次数前100 的站点,三角形代表新疆的12个5A级景区,线条代表流行的旅游路线。
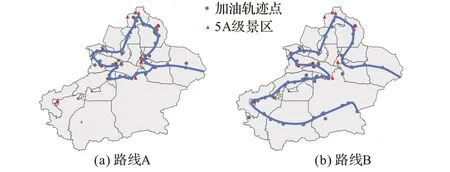
图7 聚类结果可视化Fig. 7 Visualization of clustering results
可以看出,北疆的旅游资源更为丰富和集中,几乎所有游客都会前往北疆进行游览,因此两条路线都涉及到了北疆景点的游览,二者在北疆地区的行程几乎一致,包含了北疆的10 个5A 级景区。相比北疆,南疆的旅游景点集中在喀什地区,与其他景点相隔较远,因此一部分游客在游览完北疆后选择直接返程(路线A),其余的游客则继续前往喀什地区游览,最终经由巴州的若羌县前往青海省(路线B)。图8 为马蜂窝旅游网推荐的新疆自驾游路线,可以看出该路线与图7 中的路线A 有着很高的重合度,不同之处在于马蜂窝推荐路线以乌鲁木齐市为起止点,这是因为旅游网站通常将乌鲁木齐作为游客的集结地点。
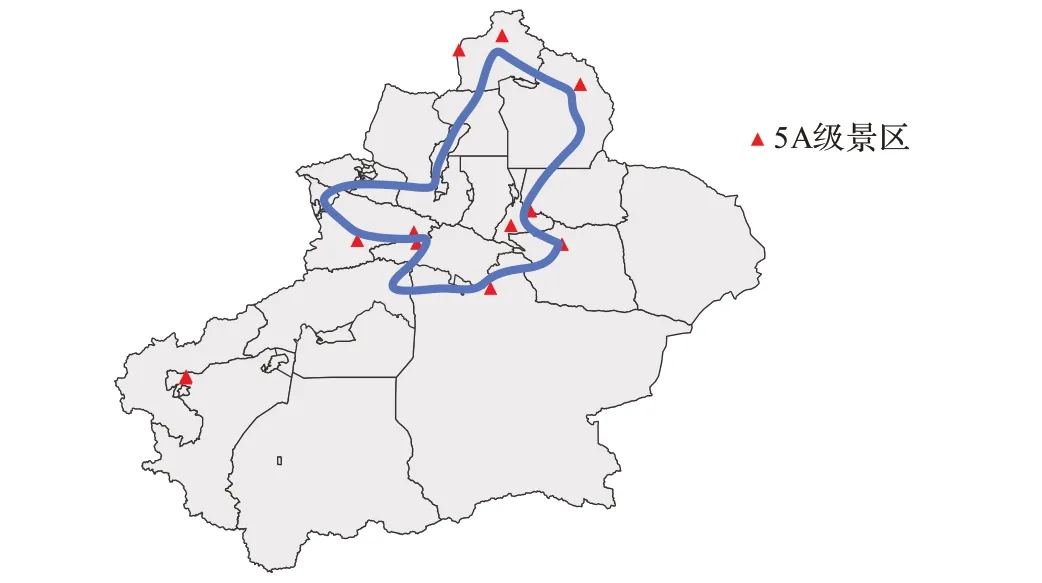
图8 马蜂窝旅游网推荐的一条自驾游路线Fig. 8 A self-driving tour route recommended by Mafengwo website
5 结语
本文利用用户在新疆的加油数据,成功挖掘出两条流行的新疆自驾车旅游路线。首先,根据自驾车游客的行为特征从全疆加油数据集中挖掘出自驾车游客人群,并分析了游客的基本特征,结果说明了游客群体数据的可靠性。然后,鉴于现有轨迹聚类算法不能解决加油轨迹过于稀疏的问题,提出一种基于语义表示的加油轨迹聚类算法,最终的可视化结果表明该方法很好地还原了游客的旅行路线。但是本文方法仅仅考虑了轨迹点的语义信息,没有将轨迹点本身的空间信息考虑在内,后续的研究工作将考虑把空间与语义信息进行结合,学习更好的站点及轨迹分布式向量表示。另外,本文挖掘出的流行路线为长途自驾游路线,后续的工作将结合节日、季节等信息进一步挖掘短途的自驾游路线。
猜你喜欢
疯狂英语·读写版(2020年11期)2020-12-21
疯狂英语·新阅版(2020年3期)2020-09-22
学苑创造·B版(2019年11期)2019-12-05
党的生活·党员电教与远程教育(2019年9期)2019-12-02
小太阳画报(2019年7期)2019-08-08
小猕猴智力画刊(2018年3期)2018-06-12
党的生活·党员电教与远程教育(2017年9期)2017-10-17
故事会(2016年21期)2016-11-10
小学生导刊(低年级)(2016年8期)2016-09-24
幼儿园(2016年10期)2016-06-22
