
基于多空间混合注意力的图像描述生成方法
2020-06-01 10:55林贤早徐小康
计算机应用 2020年4期
林贤早,刘 俊,田 胜,徐小康,姜 涛
(杭州电子科技大学通信信息传输与融合技术国防重点学科实验室,杭州310018)
(∗通信作者电子邮箱lilcore_lxz@163.com)
0 引言
随着近些年人工智能的高速发展,近海地区也在跟进构建智能化船舶监测系统。而自动化的情报生成就是其中至关重要的一环,也是极为困难的一环。船舶监测系统中关于情报的生成不仅需要船舶类别、位置等信息,还需要描述船舶图像内容的语义信息作为数据支撑。得益于深度学习在计算机视觉中的广泛应用,计算机通过训练可以自动生成对图像的文本描述,同样可以对船舶图像的运动状态和四周场景进行描述。
视觉作为人类的主要感官,发挥着巨大的作用。人们通过在短时间快速地浏览图片就能在脑海中生成符合语言学且与内容相符合的图像描述。由此可知,图像描述生成领域关联两个基础问题,也就是视觉理解和语言处理。换而言之,解决图像描述生成问题需要连接计算机视觉和自然语言处理两个社区,这项任务不仅需要高度理解图像语义内容,还需要用人类化的语言表达出该信息。从以往的研究得知,确定图片中的物体的存在、属性还有之间的关系本身就不是一个轻松的工作,进一步用符合语法的语句去描述此类信息则更加提升了这项工作的难度。
深度学习在计算机视觉和自然语言处理等人工智能领域表现优越,可知深度神经网络能同时为视觉模型和语言模型[1]提供支撑。受到神经机器翻译中编解码框架的启发,图像描述生成任务也可以分解成两个步骤:对图像内容和语义进行编码,使用语言模型对该特征进行解码。卷积神经网络(Convolutional Neural Network,CNN)[2]现如今已成为目标检测和识别的主流方法,而循环神经网络(Recurrent Neural Network,RNN)在自然语言处理也拥有着卓越表现,两者的有机结合刚好为图像描述生成提供了有效的解决方案。
1 相关工作
早期在图像描述生成方面的工作主要集中在基于检索的方法和基于模板的方法。这些方法要么通过关键词直接套用现有的描述文字[3],要么依靠严格编码的语言结构完成文字描述[4],因此早期工作中这两种方法产生的图像描述在很大程度上十分晦涩而又低效。现如今,许多基于循环神经网络的深度学习模型已经广泛应用于图像描述生成。而这些使用深度学习的方法大多数采用编码/解码框架。这个框架的流程是先通过预训练好的卷积神经网络将图像编码成能够表征图像内容的特征,然后结合部分完整描述文字提供的语义输入到循环神经网络中将该特征解码成句子。这是Vinyals等[5]率先提出的,该模型是受到最近神经机器翻译[6]在序列生成中的成功应用所启发,与神经机器翻译的区别就是图像描述生成的输入不是句子而是卷积网络得到的特征,特征进行解码时采用了长短时记忆(Long Short-Term Memory,LSTM)单元。LSTM 作为RNN 的变种,由于其门控单元的设计,能够很大程度改善RNN 在长时间序列上的梯度弥散,因此后续的模型大多都是用LSTM 或其变种来解决句子生成这类序列结构问题。后续的研究则分别在编码和解码上对其进行改良,近来备受关注的注意力机制就广泛应用于该任务。Xu等[7]使用带有空间信息的卷积图像特征作为输入,在二维空间上使用注意力对位置进行选择,他采取了两种注意力方式,分别为只选取固定数量位置的“硬”注意力和给所有的空间位置分配不同权重的“软”注意力。这种空间注意力能够有效地对特征再编码,从而提高了语言模型生成句子的正确性。You等[8]将注意力转向语义集合中,基于语义特征集合解码生成图像描述。Chen 等[9]甚至还对不同的特征通道使用了注意力,将注意力延伸到三维空间。
图像描述生成方法在解码阶段一般使用交叉熵函数进行训练,但是测试阶段评价使用的是不可微的自然语言评价指标,比如BLEU(Bilingual Evaluation Understudy)[10]、ROUGE(Recall-Oriented Understudy for Gisting Evaluation)[11]、CIDEr(Consensus-based Image Description Evaluation)[12]等,因此使用交叉熵函数无法直接优化评价指标,而只能拟合模型去生成与数据集相近的语言描述,容易在解码阶段过拟合,无法对语言表达进行有效的学习。不止于此,测试阶段的图像描述生成是通过已训练好的模型生成的单词结合图像特征,迭代地预测后续的单词,所以这种预测方式容易对错误进行积累,这种现象叫作exposure bias,Rennie 等[13]1提出加入强化学习策略可以弥补交叉熵损失函数无法优化指标的缺陷,该策略可以在训练中通过采样的方式计算奖励期望的梯度,进而更新模型权重,使得评价指标作为直接优化的目标。
图像描述生成还受益于图像描述生成数据集不断扩大,比如原先的Flicker 8K、Flicker 30K 到现在MSCOCO(MicroSoft Common Objects in COntext)caption 提供十几万张图片和对应的文字描述,使得深度神经网络的训练得到了有效的数据集支撑。为了将该方法应用于船舶监测中,本文自建船舶描述数据集对船舶的运动状态和四周场景进行标注。
2 本文算法
本文提出的基于多空间混合注意力的图像描述方法,使用预训练好的检测网络提取感兴趣区域的特征编码,在解码阶段对该特征施加多空间注意力和视觉选择,引入强化学习的策略梯度对优化目标进行重塑,从而使得训练和测试阶段的解码统一,直接针对评价指标进行优化。整体框架如图1所示,这种模式本质上属于端到端的设计,但是由于实际训练中无法同时优化卷积神经网络和LSTM,图像和文字虽然能表征同样的事件或者事物,但是在表达形式上存在着鸿沟。本文将编码解码分成两个步骤分开训练,在得到丰富的语义特征之后,将该特征作为解码模型的输入。如图1 所示,为了得到图像的感兴趣区域特征,算法总体框架中的卷积编码器选用的是目标检测网络。具体采用的感兴趣区域特征提取方案是以ResNet-101[14]为卷积骨干的Faster-RCNN[15]。为了感兴趣区域特征能够表征图像中的相关属性,在损失函数中添加属性分类交叉熵损失。训练数据集使用的是带有属性、坐标、类别标签的Visual Genome 数据集。编码采用的具体卷积结构如图2所示。

图2 卷积网络结构Fig. 2 Convolution network structure
沿用Faster-RCNN 的框架,网络的改动部分如下:首先将区域候选网络(Region Proposal Network,RPN)结构接在分类网络的第4 个卷积模块之后,得到候选区域;然后将候选区域与第4 个卷积模块的特征结合,得到感兴趣区域特征;最后利用第5个卷积模块接的图像特征分别对401个属性进行分类,对于1 601 个目标种类进行目标检测。该目标检测网络的设计方式是为了与ResNet-101 分类网络结构保持一致,提高网络迁移的稳定性,使得网络可训练。
除此之外,当引入强化学习目标作为训练的优化函数之后,增加了模型的不稳定性,通过实验可知,直接优化平均期望奖励这一目标,会使得模型无法训练。而交叉熵损失函数往往能构成凸函数,使得模型易于收敛,所以本文先通过交叉熵模型得到性能较好的解码模型,再使用策略梯度优化模型时就可以稳定地提高评价指标。
2.1 多空间注意力
在人类的视觉系统中,注意力信号大致可以划分为两种:一种是自顶向下的注意力,这类信号受当前的任务的驱动,由人的主动意识所控制;另外一种是外界新奇或者显著的激励因子组成的自底向上的信号,一般是被动地接收。这两种注意力信号都与视觉元素的内容相关联。
由于卷积操作本身的特性,特征图的每一通道都由一组卷积核对上一层特征块卷积后得到,可将其对应为自底向上的局部空间特征提取器,因此特征块的通道可以认为是图像的不同语义部分。换而言之,卷积核能够在局部感受野中融合空间和通道信息。既然卷积的作用是对图像进行特征编码,那么注意力编码的设计可以认为是对不同位置、不同通道的特征进行解耦。添加注意力后得到的特征图,可以看作是对空间、通道信息的重新校准,可以对后续的解码过程产生积极的影响。本文在解码阶段采用多空间注意力,如图3所示。
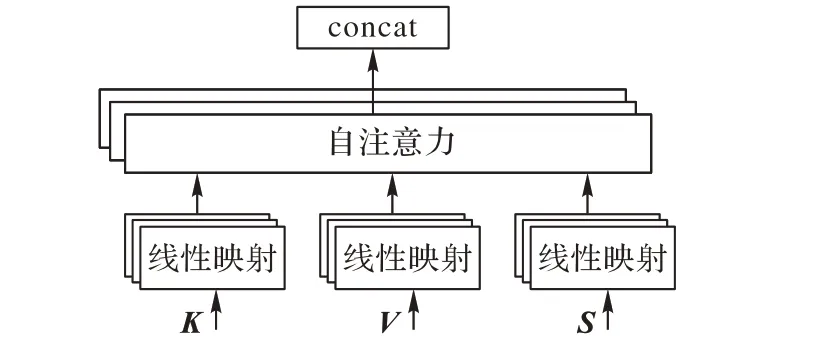
图3 多空间注意力Fig. 3 Multi-spatial attention
这种注意力也同样属于自注意力。此自注意力本质是对特征进行重新编码。回顾之前的框架,本文通过卷积神经网络得到了图像的特征向量表达,这一环节就是结合解码输出构成的上下文语境引导特征的重新编码。具体的操作为:
att = softmax(αhTV)V (1)其中:h 为循环神经网络的隐层状态;V 为感兴趣区域特征。与一般注意力不同的是,本文将这种注意力扩展到了多个空间中。假设隐层状态长度为k 维,每个空间位置的图像特征也为k 维,先将其扩展成N 个子空间后,通过式(1)计算子空间注意力的权重,然后将其重新拼接成最后的注意力特征。
2.2 视觉选择
因为评价标准依据的是生成句子的内容和流畅性,因此仅仅关注图像的视觉部分还不够,还需要考虑将图像内容串联起来的一些非视觉词语,所以本文在原有的LSTM 中加入视觉选择门控机制。带有视觉选择的解码模型可以自动决定什么时候关注视觉信号,什么时候依赖语言模型。当依赖视觉信号时,模型同样会决定对视觉区域的选择作出判断。一般的LSTM模型如下:

其中:xt是输入向量;mt-1是t - 1 时刻的记忆细胞向量。通过在该向量上进行扩展,得到可供非视觉词产生的信息,形成视觉选择门控机制。

其中:Wx和Wh是需要被学习的权重;xt是LSTM 在t 时刻的输入;gt向量对记忆细胞施加影响;mt包含了时刻t 及其之前的语义信息;“⊙”是点乘操作。
基于非视觉词的信息st和注意力的特征attt来重新组合得到自适应语义向量c′。

其中μt是一个标量,它决定了对视觉信息的选择,它的取值是先将st和ht映射到嵌入空间,将其进行组合后再投射到一维空间得到标量值,具体实现如下:
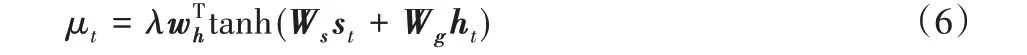
视觉选择与多空间注意力构成了多空间混合注意力,既能关注视觉方面的信息,也能对图像中的非视觉信息进行选择。多空间混合注意力同时还得益于编码特征中将图像之间的属性关系融合到优化目标中,使得感兴趣区域特征融合进了图像的属性信息。
2.3 策略梯度优化指标
如图4 所示,循环神经网络模型可以看作一个智能体与外部环境(单词和图像特征)进行交流。这个网络模型的参数θ定义了策略π。策略π 会产生一种动作,对应的就是句子的预测。在每个动作之后,这个智能体即LSTM 会更新它的状态。这个状态指的是LSTM 中的记忆细胞状态和隐层状态。这个过程迭代生成句子描述,直到生成句子结束标识符。智能体通过观测环境可以获得回报,动作的选择就是通过最小化这个回报的负期望得到的。回报的产生就是依赖常用的评价指标,比如CIDEr-D,计算生成句子的得分值,本文将这种回报记作r。
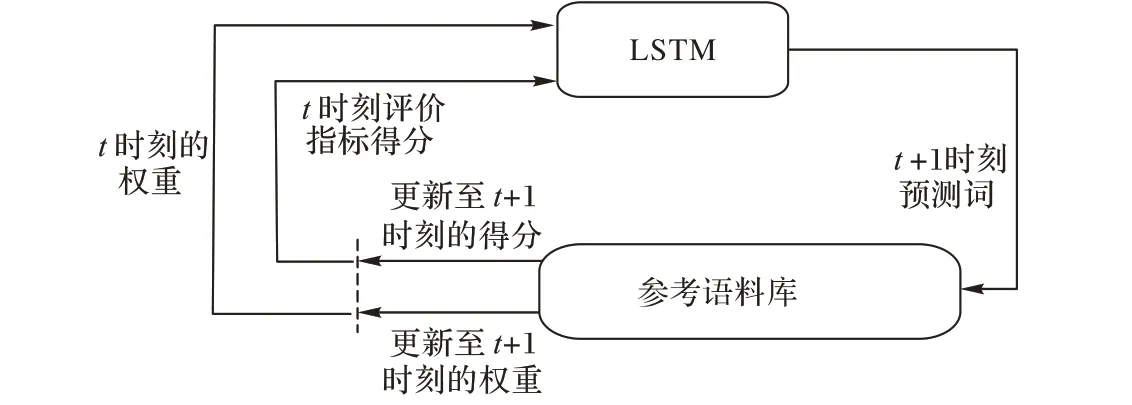
图4 强化学习优化过程Fig. 4 Optimization process of reinforcement learning
目标函数就从原来的交叉熵函数重新塑造成回报的期望:
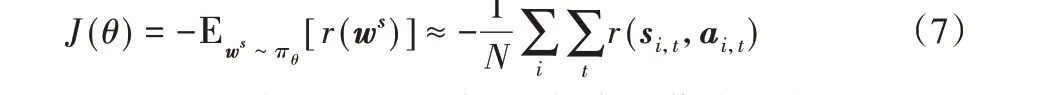
由于无法得知回报的分布,一般常用蒙特卡洛方法经验平均来作为模型期望的无偏估计。此方法主要的限制是在强化学习下使用小批量样本会使需要优化的回报这一随机变量产生高的方差,从而使得训练过程十分不稳定,难以收敛,并且无法选择学习率。除了适当地增加批尺寸外,为了稳定性的需要还可以加入合适的偏差修正baseline。
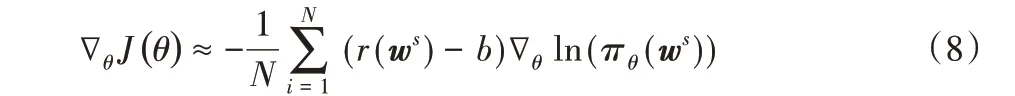
baseline 的设置为当前模型在测试阶段得到回报。那么式(8)可改写为:
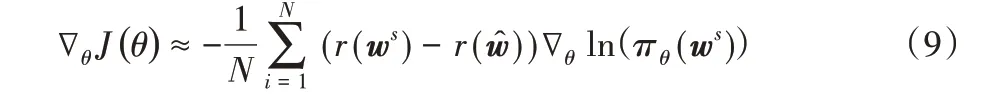
因为baseline是一个常数,所以并不影响梯度的大小。除此之外本文还使用限定采样方式为多项式分布来加速训练过程。
3 实验与结果分析
3.1 评价指标
针对图像描述生成任务,本文主要使用CIDEr-D 进行评分,其他评价指标有机器翻译工作中基于精确度的BLEU 和自动摘要工作中基于召回率的ROUGE。以下是CIDEr 的计算公式:
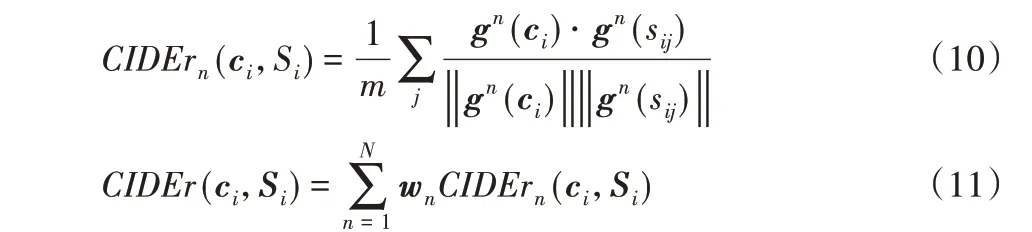
其中:ci是生成候选句子;sij是参考的句子;gn(ci)是一个向量,它的长度为候选句子和真实句子中n 元词组的个数之和,每个元素是计算n 元语法在候选生成句子中的TF-IDF(Term Frequency-Inverse Document Frequency);||⋅||是取模操作。同理gn(sij)即是将生成候选句子替换为参考句子后进行计算。wn一般设为1/N(N 一般设为4)。为了评价的公平性,微软官方重新对CIDEr 进行修改,加上了句子长度的差异的高斯惩罚和对大于参考句子的TF-IDF元素进行截断,记为CIDEr-D,重写为:
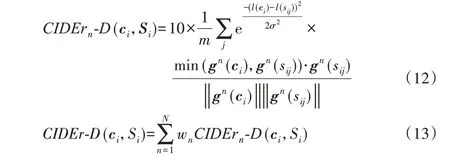
一般使用σ = 6,乘以10 是为了让这个分数与其他的评价的指标相近。
3.2 数据集和参数
本文选用在MSCOCO caption 数据集上验证算法的有效性。MSCOCO 是微软公开的图像描述数据集,包含着82 783张训练集、40 504 张验证集和40 775 张测试集。相对于其他小规模的图像描述生成数据集,COCO caption 数据集更有挑战力,也更加具有公信力,其中一张图片对应5句描述,由json格式提供。本文采取的验证模型优劣的方式分为两个步骤:先通过训练集和验证集在线下调节模型的参数,然后提交测试集的结果到服务器上获取对应指标的分数。最终的解码模型获取分为两轮,区别在于第一轮是对交叉熵损失函数进行优化,第二轮是通过策略梯度对模型进行调节。第一轮设置为学习率0.000 1,选用Adam 优化器降低交叉熵损失,收敛至平稳后,再降低学习率,直至交叉熵损失无法进一步优化,最大迭代轮数为30。得到较稳定的交叉熵解码模型后,再使用策略梯度替换交叉熵损失函数,采取相同的超参数进行优化,两轮训练的总迭代周期为70。沿用Karpathy等[16]的数据集设置,分别使用5 000 张图片用于线下的验证和测试。表1 列出训练时候的超参数设置。词嵌入向量设为1 024,LSTM 的隐藏层向量大小设置为1 024。为了防止过拟合对加入dropout,设为0.5。
3.3 结果与分析
为了使实验结果有说服力,本文将COCO 测试集在本地得出的图像描述提交到后台验证算法设计的有效性,并与近些年带有注意力机制的算法进行比较。主要实验内容如表2所示。
通过表2 可以得知,相比在解码阶段单纯使用LSTM,现今的方法都会加上注意力机制,注意力机制能够在解码阶段对于卷积得到的整体特征再次重新编码,使得特征得以映射到能与语言空间容易转换的嵌入空间,提升特征的表达能力。而本文使用的混合注意力,则首先将特征映射到不同的空间中,扩展注意力的表达,再使用视觉选择机制分配视觉信息与语言信息的权重,不仅提升了特征的表征能力,还能联系生成单词的语义,从而获得较好的指标结果。
在线下验证实验中,本文叠加多空间注意力和视觉选择模块进行训练,融合成本文所提出的混合注意力进行优化模型。从表3 的结果来看,在没有使用策略梯度微调模型的情况下,还是能够使结果达到比较好的效果。当加上策略梯度优化时能够极大地提升混合注意力模型解释特征的能力。这里的强化学习算是一种优化手段,本质上也是在复杂模型提供的参数空间中寻找最优的参数优化指标,最终还是混合注意力起到了作用,使得该模型的图像描述能力提升,获得了较高的评价分数。同时实验统计了编解码模型在前向的耗时,编码前向平均每帧平均耗时200 ms,解码前向每帧平均耗时40 ms。
除了在权威的COCO 数据集上进行模型验证实验之外,本文还自建船舶描述数据集,将船舶在海上航行的情况进行描述,为情报生成打下基础。如图5 所示,给出带有船舶的图片,可以自动输出语句来描述出其船舶明显的主体颜色及其在海上航行或岸边停靠等内容,并且语句的表述能够合乎语法规则。

图5 自动生成船舶图像描述Fig. 5 Automatic generation of ship image descriptions

表1 超参数设置Tab. 1 Hyperparameter setting
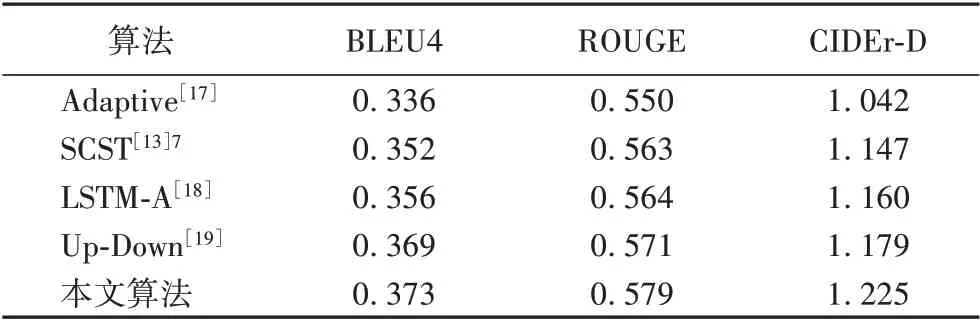
表2 不同注意力机制的算法比较Tab. 2 Comparison of algorithms with different attention mechanisms

表3 叠加不同模块的效果Tab. 3 Effect of adding different modules
4 结语
本文深入研究了图像描述生成方案,提出了基于多空间混合注意力的图像描述生成模型,并将该方法应用于船舶图像上,以填补近海船舶监测系统的情报生成的缺失。但是该模型还是有局限性,比如句子的长度是被限制在16 个单词,所以对于语义内容多的图片可能无法进行有效的描述。值得一提的优化方法有增大语料库来提高生成句子的丰富性,这种方式是最直接有效的提升指标,但是工作量较大。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
南方周末(2019-12-19)2019-12-19
中国外汇(2019年19期)2019-11-26
南方周末(2019-07-18)2019-07-18
南方周末(2019-05-09)2019-05-09
第二课堂(课外活动版)(2016年2期)2016-10-21
