
通过标点恢复提高机器同传效果
2020-06-01 10:55陈玉娜史晓东
计算机应用 2020年4期
陈玉娜,史晓东
(厦门大学信息学院,福建厦门361005)
(∗通信作者电子邮箱mandel@xmu.edu.cn)
0 引言
近年来,随着自动语音识别(Automatic Speech Recognition,ASR)[1-3]和 神 经 机 器 翻 译(Neural Machine Translation,NMT)[4-6]技术的快速发展,机器同传(Machine Simultaneous Interpretation,MSI)越来越受到人们的重视。微软、腾讯、搜狗、科大讯飞等公司为多语种会议推出MSI系统,以方便使用不同母语的参与者从演讲者处获取信息。
目前主流的MSI系统先将源语言语音用ASR系统进行识别,然后将输出结果直接输入到NMT 中,最后得到目标语言文本。然而在实际应用中,由于演讲过程中的停顿、重新思考以及话语重组等现象会影响ASR 系统的性能,ASR 系统可能产生语义不完整的句子和不流畅的句子。同时目前的ASR系统并不完善,可能会输出包含错字的句子。这些问题都会影响NMT的性能,进而导致MSI输出让人难以阅读和理解。
MSI系统的NMT收到的文本中包含的错误大体可以分为语义不完整、不流利及语音识别错误三大类问题,其中语义不完整问题可归结为标点恢复任务,即将ASR 系统生成的几个文本片段连接,然后恢复这段话的标点。标点恢复方法一般分为三类:基于声学特征的、基于词汇特征的及两者结合的。Levy 等[7]采用基于声学特征的方法,利用音强、暂停时间等特征预测标点符号。Cho等[8-9]使用序列到序列神经网络处理基于词汇特征的标点恢复,将不含标点文本翻译为含标点的文本。虽然该方法取得一定成效,但是该方法比较复杂,需要先将文本进行编码再进行解码。Che 等[10]采用基于卷积神经网络(Convolutional Neural Network,CNN)的序列标注模型直接预测标点符号。同时基于循环神经网络(Recurrent Neural Network,RNN)的序列标注模型也被应用到标点预测任务中:例如Tikl 等[11]使用了长短期记忆(Long Short Term Memory,LSTM)网络;Tikl 等[12]又使用了基于注意力的双向循环神经网络;李雅昆等[13]使用了双向LSTM 同时训练中文分词和标点恢复任务。虽然上述方法都取得了良好效果,但是由于卷积网络更注重局部信息,循环神经网络存在长距离依赖问题,而标点符号与上下文联系紧密,因此这些方法的预测效果都有待进一步提高。Tikl等[12]采用了基于两个特征结合的方法进行标点符号预测,该方法可以综合声学特征和文本特征进行标点预测,从而提升正确率,但是同时拥有这两个特征的训练语料非常匮乏。对于不流利问题,Cho 等[14-16]用带有BIO(Begin,Inside,Outside)标签的序列标注方法,并分别使用条件随机场、基于RNN的模型和基于CNN的模型进行处理。在ASR 识别错误方面,Sarma 等[17]构建了基于上下文的ASR 检测器,并使用共现和基于语音的分析来纠正错误,该方法会产生累积错误。Guo等[18-19]提出一种基于注意力机制的编-解码器循环神经网络直接纠正错误的词。
为了更好地研究上述问题在MSI 中的影响,本文在实际的MSI 数据上对比分析了语义不完整、不流利和语音识别错误这三个问题(见第1 章)。实验结果表明,语义不完整问题是影响MSI 性能最普遍的问题,约占MSI 总错误的44.58%。因此,本文将语义不完整问题作为主要研究内容。首先缓存由ASR 系统生成的几个片段,并将它们组合成一个词串;然后使用基于BERT(Bidirectional Encoder Representation from Transformers)[20]的序列标注模型恢复该词串的标点符号,并且使用了Focal Loss[21]作为训练过程中的损失函数来缓解类别不平衡问题,即无标点样本比有标点样本多的问题;最后将标点恢复后的词串输入NMT中。
本文的主要工作为:
1)对真实场景下的MSI 数据进行分析,评估并论述了MSI 系统所存在的语义不完整、不流利和语音识别错误三类问题及这些问题对MSI 系统性能的影响,其中语义不完整问题是最迫切需要解决的问题。
2)提出了基于BERT 和Focal Loss 的标点恢复方法。通过BERT 学习较强的上下文特征,使用Focal Loss 缓解标点恢复任务的类别不平衡问题,提高了模型在标点恢复任务中的准确性。
3)本文提出的标点恢复模型缓解了MSI系统中的语义不完整问题,比使用基于注意力机制的双向循环神经网络标点恢复模型的MSI,该模型的翻译质量也有显著提升。
1 MSI流水线系统问题
为了提高MSI 流水线系统的性能,本文对从网页抓取的中文音频片段的ASR 输出结果进行分析,部分示例如图1 所示。主要研究将ASR 的输出直接输入到NMT 过程所存在的三类问题,即语义不完整、不流利和语音识别错误。该输出结果总共包含1 500条数据,数据大小为441 KB。

图1 包含语义不完整、不流利和ASR错误问题的例子及其对应的机器翻译Fig. 1 Examples containing problems of semantic incompleteness,disfluency and ASR errors and their corresponding machine translations
1.1 语义不完整问题
由于标点符号无发声因素,通常ASR 系统对声音识别只输出文字,不输出标点符号,因此一般没有对输出内容进行句子分割,或者只根据静音段进行简要的分割(例如说话者停顿时),ASR 输出有的是很短的片段,有的是很长一串文字。这些文本通常未按语义分割成句,导致了明显的语义不完整问题。如图1 中的例1 原本属于一句话,被分割成了两个片段,例2 的几个句子则被合成一个片段。由于机器翻译的训练数据来自于完整的且含有标点符号的句子,因此该问题会影响机器翻译的质量。从图1 中可以看到,具有语义不完整问题的例子的翻译结果不仅不能表达完整的意思,而且还存在错误(用下划线标出)。该问题存在于大部分例子中,约占MSI错误总数的44.58%,是影响MSI流水线系统性能的最普遍的问题。
1.2 不流利问题
通常情况下,由于演讲者的重复、犹豫和语言重组,其演讲内容会包含重复词、填充词和话语标记语,因此ASR 系统可能产生不流利的句子,如图1的例3所示。由于机器翻译的训练数据来自流利的书面文本,因此训练数据与ASR 输出之间的不匹配可能导致翻译质量下降。不流利问题约占总MSI错误的22.21%。
1.3 语音识别错误
如图1中的例4所示,ASR输出中的一些单词会被ASR系统识别为发音相似的其他单词,该错误会被传输到下游NMT中,产生累积错误。从例4 可以看出,虽然有些识别出来的单词是错误的,但在一定程度上可以根据字的发音来猜测其原义。然而,翻译后的意义不仅被曲解,而且令读者难以理解。语音识别错误问题约占33.20%,ASR 输出的字错误率为4.34%。
从上述的分析可以看出,语义不完整问题是影响MSI 流水线系统性能最普遍的问题,本文主要解决句子中所存在的语义不完整问题。在ASR 和NMT 之间引入标点恢复层,为NMT提供完整的句子单元以提高MSI流水线系统的性能。整体框架如图2所示。

图2 机器同传流水线系统整体框架Fig. 2 Overall framework of MSI pipeline system
2 标点恢复层
本文在标点恢复层使用基于BERT 的序列标注模型,并使用Focal Loss 来缓解模型训练过程所存在的类别不平衡问题。
2.1 模型输入和输出
本文将标点恢复任务转化成序列标注任务,只考虑最重要和最常见的标点符号类型:逗号、句号、问号,因此共有四种类别:“,”类、“。”类、“?”类和“O”类(其中“O”表示无标点符号)。在数据处理阶段,首先将训练数据的感叹号和分号当作句号处理,冒号则映射到逗号,并将其他标点符号移除。然后将由训练数据转化成的不含标点的文字作为模型输入,令每个文字其后所跟的标点符号作为模型输出。例如对于输入句子:
“是的,他来了。”
转化后的模型输入为:
“是的他来了”
模型输出为:
“O,O O。”
2.2 BERT
BERT 是一种基于自注意力机制(self-attention)的预训练语言模型,使用多层Transformer编码器框架,并利用屏蔽语言模型(Masked Language Model,MLM)任务(屏蔽一些词让BERT 进行预测)实现深层双向,利用下一句预测(Next Sentence Prediction,NSP)任务学习句子间关系,具有较强的表达能力。

图3 Transformer编码器[6]Fig. 3 Encoder of Transformer[6]
BERT包含多层Transformer编码器组件,如图3[6]所示,每层由多头自注意力层和前馈网络全连接层组成。Transformer编码器先将词转化为词嵌入,并加入相对位置信息,然后输入多头自注意力层。自注意力机制可以为:
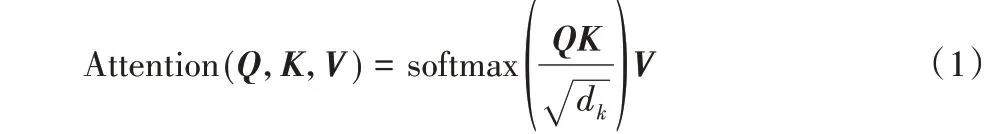
其中:Q代表查询;K-V是文本向量键值对;dk表示维度。该过程先将查询和每个key 进行相似度计算从而得到权重,再使用softmax 函数对权重进行归一化;最后将权重和相应的键值value进行加权求和。多头自注意力机制表示为:

2.3 基于BERT的序列标注模型
循环神经网络被应用于序列标注任务与标点恢复任务中,但该网络存在长距离依赖问题,即在训练过程中随着序列长度的增加会产生梯度消失,不能保存有效信息的问题。为了解决这一问题,本文采用自注意力网络。自注意力网络能够对全局信息进行有效处理,词间距离缩小为1,更容易获取文本内部依赖关系,表现出比RNN 更强的表达能力与效果。基于此,本文提出使用基于BERT 的序列标注模型来解决标点恢复任务,该模型由BERT和Softmax层组成,如图4所示。
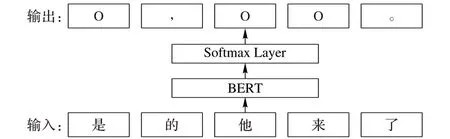
图4 基于BERT的标点恢复模型Fig. 4 BERT-based model of punctuation recovery
下面给出该标点恢复模型的总体描述。将输入序列表示为X = x1,x2,…,xT,其中:xt代表第t个词的one-hot表示;T 代表输入序列的长度。对于给定的输入序列X,BERT 首先将其转化成词嵌入,并加入位置嵌入和分割嵌入,然后再进行特征抽取,表示为H = h1,h2,…,hT:

其中:ht表示第t个词的特征抽取结果。最后将H输入softmax层,并输出标点预测概率,第t个词标点预测概率分布为:

其中:Wo和bo为softmax层的参数。
2.4 损失函数
在深度神经网络训练任务中,一般使用交叉熵作为模型训练的损失函数,但是当样本不平衡时,就导致神经网络的训练容易倾向于样本数量多的类别或者倾向于易分的样本,从而使得神经网络学习不到更多有用的信息。在标点恢复任务中,由于无标点(“O”)样本远多于其他标点样本,所以模型在训练时更倾向于输出无标点类别,网络学习不到足够的标点特征,从而降低了有标点类别的查全率。为了解决该问题,本文采用在交叉熵上改进的Focal Loss[21]作为模型的损失函数,它可以在训练过程中平衡类别,并增加难分样本的相对损失。由于它是在二分类的基础上进行改进,因此本文将其扩展为多分类。下面给出Focal Loss的更具体的描述。
二分类的交叉熵为:
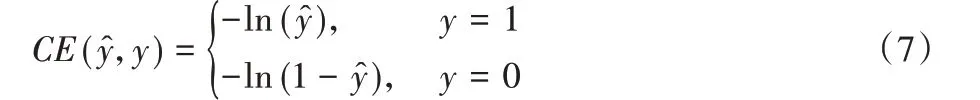
因为类别不平衡,Lin等[21]为类别1引入了一个系数α,类别0为1- α。改进的交叉熵公式可以表示为:
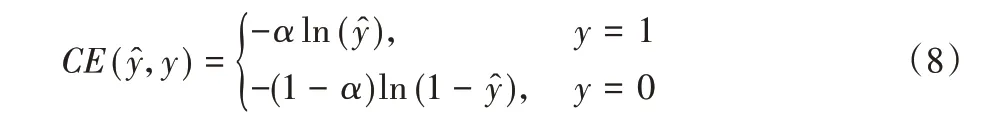
概率越高,说明样本越容易分类。为了可以平衡类别并且区分难易样本,因此Lin 等[21]为交叉熵增加了一个调制系数(1-来降低简单样本的关注度,并增加难分样本的关注度。它表示为:
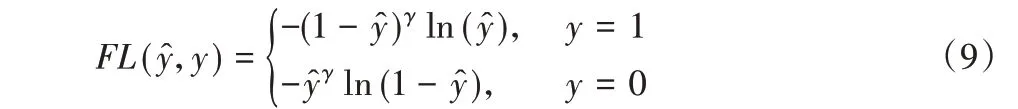
最后改进的交叉熵公式Focal Loss表示为:

由于本文分类任务不是二分类,因此将其扩展成多分类,表示为:

其中:n代表类别数;αi代表第i个标签的可调因子;表第i个标签的预测概率;yi代表真实标签。
3 实验与结果分析
本章首先评估本文标点恢复模型在中文和英文数据集的准确性;然后将该模型集成到机器同传中,以展示本文标点恢复模型对英-德和汉-英同传翻译任务的影响。
3.1 标点恢复准确性
3.1.1 训练细节和数据集
本文选择BERT-base 模型,它包含12 层Transformer 编码器组块,768个隐藏单元,12个自注意头和110 MB参数。训练时,将模型的批大小设置为32,英语端学习率为5× 10-5,训练轮数为5;中文端学习率为3× 10-5,训练轮数为3。对于Focal Loss,英语端将所有类的α 值设置为1.0,γ 值设置为1.5。中文端将逗号、句号和问号类的α值设置为0.2,将其他类的α 值设置为0.1,γ 值设置为0.5。所有超参数都在开发集上调优。英语数据集来自国际口语机器翻译评测比赛IWSLT (International Workshop on Spoken Language Translation),其数据主要来源于TED 演讲语料。本文选择IWSLT2012 机器翻译训练数据作为训练集和开发集,数据大小分别为12.8 MB 和1.8 MB。IWSLT2011人工转录集和ASR输出测试集用于测试,数据大小分别为78.1 KB 和76.9 KB。对于中文数据集,本文将网上爬取的中文新闻语料进行噪声过滤后作为训练集,数据大小为11.3 MB;开发集和测试集为从网页抓取的中文音频片段的ASR 输出,开发集数据大小为507 KB,测试集数据大小为441 KB。
3.1.2 实验结果
标点恢复预测效果使用查全率R(Recall)、查准率P(Precision)和F1 值衡量。表1 是不同模型在英文人工转录集(Ref.)及ASR输出(ASR)测试集的标点恢复结果,表2是不同模型在中文ASR 输出测试集的标点恢复结果。显然,本文模型在英汉数据集中都显著优于使用基于注意力机制及预训练词向量的双向循环神经网络模型(T-BRNN-pre)[12]。
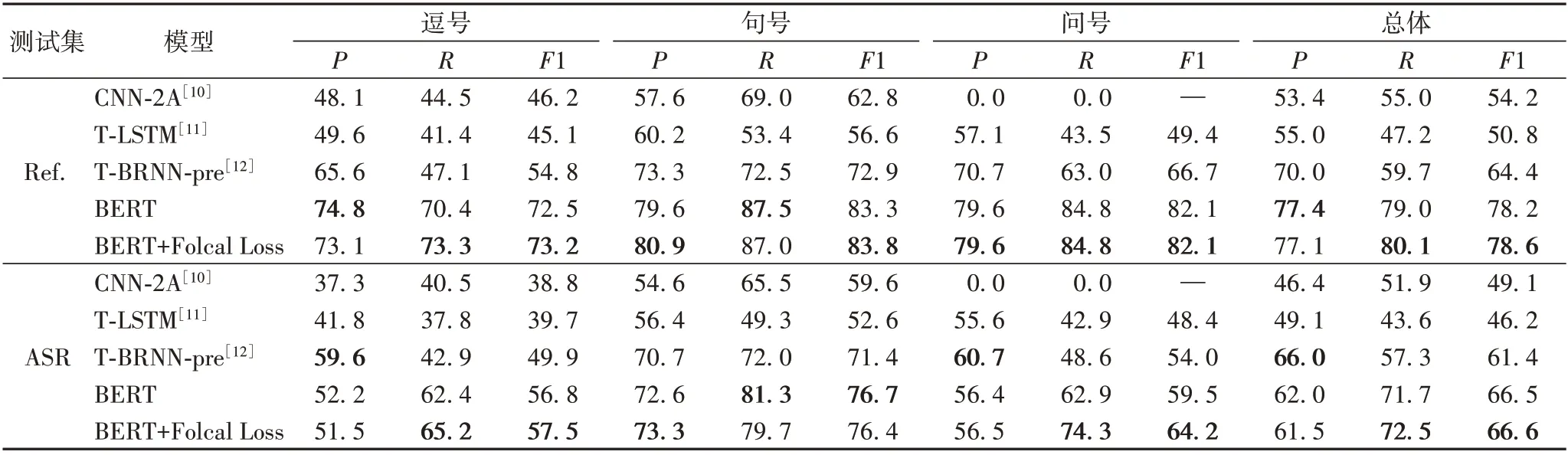
表1 英文标点恢复效果对比 单位:%Tab. 1 Comparison of English punctuation recovery performance unit:%

表2 中文标点恢复效果对比 单位:%Tab. 2 Comparison of Chinese punctuation recovery performance unit:%
在英文测试集中,与T-BRNN-pre 相比,总体F1 值在英文人工转录集上提高了14.2个百分点,在英文ASR 输出上提高了5.2个百分点。在英文人工转录集中,相对于T-BRNN-pre,本文模型在所有标点符号的查准率、查全率都显著提升。在英文ASR 输出中,逗号以及问号在提高查全率的同时,也降低了一定的查准率,但总体F1值都是提升的。
在中文测试集中,与T-BRNN-pre 相比,总体F1 值在中文ASR 输出上提高了9.9 个百分点。句号和逗号相对于T-BRNN-pre,查准率和查全率都显著提升,但问号的查准率有所降低。
在英文人工转录集中,本文模型在所有标点符号上查准率、查全率都显著提升,但是在英文ASR 输出及中文ASR 输出中,逗号或者问号的查准率相对于T-BRNN-pre模型有所降低,本文认为该问题是受训练集与测试集数据域不匹配的影响。在训练时,用于英文和中文标点恢复模型的训练语料是符合正常语法规范的文本;而测试时,英文ASR 输出及中文ASR 输出则是包含不流利及语音识别错误等问题的文本;同时因为本文模型在正常文本上拟合得更好,因此本文模型的查准率相对于T-BRNN-pre模型受到干扰的影响更大。
从实验结果也可以看出,在英文人工转录集、英文ASR输出及中文ASR输出中,使用Focal Loss虽然使总体查准率降低,但是由于总体查全率相对提升更多,因此总体F1 值也有所提升。由此看来Focal Loss可以提升标点恢复模型效果。
3.2 机器同传
本节将上述训练的标点恢复模型应用到机器同传中。首先将ASR 输出用提出的标点恢复模型进行标点恢复,再将标点恢复后的ASR 输出输入机器翻译中。本文使用的机器翻译是线上系统,该系统基于Transformer架构,编码器和解码器各包含6 层,隐藏维度为1 024,自注意力头个数为16。本文使用BLEU[22]作为机器同传结果的评价指标。
对于英语-德语翻译,使用英-德IWSLT2015 的口语翻译(Spoken Language Translation,SLT)任 务 的 测 试 集:IWSLT2015 人工转录集和ASR 输出,数据大小分别为97.6 KB 和109 KB。对于汉英翻译,测试集与上文用于中文标点恢复模型的测试集相同,但删除了一些包含不流利和语音识别错误的句子,数据大小为78.5 KB。
表3 为英-德和汉-英的实验结果。第1~4 行表示机器翻译的输入来自ASR 输出,第5 行表示来自人工转录文本。BasePunc 的标点符号由ASR 系统提供,作为实验的基线;T-BRNN-pre 表示标点符号来自使用基于注意力机制的双向循环神经网络模型;BERT-FL 表示标点符号来自基于BERT和Focal Loss模型;GoldenPunc的标点符号是人工标注的。
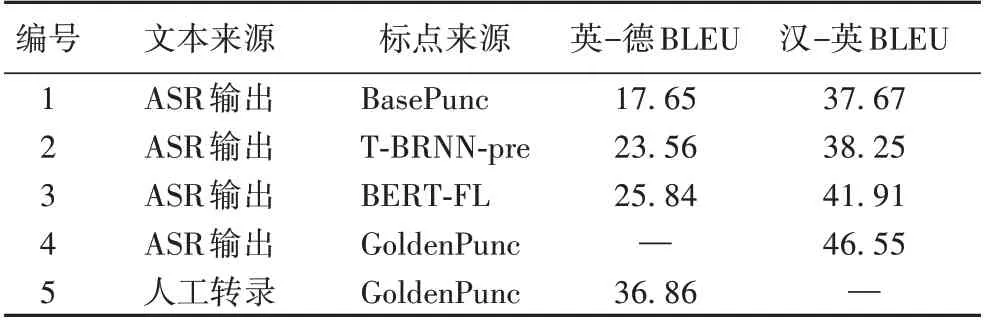
表3 英-德和汉-英翻译效果Tab. 3 Translation performance on English-German and Chinese-English
从英-德的同传翻译结果可以看到,当输入的单词和标点符号都是人工标注时,翻译质量为36.86 BLEU,即为上限。对ASR 输出使用本文模型进行标点恢复:与ASR 系统提供的标点符号基线相比,可以提高8.19 BLEU;与T-BRNN-pre 模型预测的标点符号相比,可以提高2.28 BLEU。结果表明,本文提出的模型可以显著提高英-德的翻译质量。
从汉-英的同传翻译结果可以观察到,当将本文模型应用于中文ASR 输出时,与ASR 系统提供的标点符号相比BLEU提高了4.24,与T-BRNN-pre模型预测的标点符号相比可以提高3.66 BLEU。由此看来提出模型可以显著提高汉-英的翻译质量。为了直接展示模型对翻译性能的影响,在图5 展示了从测试集中采样的一些翻译示例。显然,引入了标点恢复模型的MSI 系统的翻译不仅传达了完整和正确的信息,而且更加流畅,可读性也更强。此外,本文还进行了人工评估,以验证提出的标点符号恢复模型对机器同传的影响。本文在测试集中随机选择200 条数据进行人工翻译评价;得分范围为1~10(1 是最差,10 是最好)。人工评估结果无标点恢复为7.62分,使用本文标点恢复模型分数为8.37分,可以看出,引入本文的标点模型使得MSI系统比基线有更好的得分。

图5 标点恢复前和后的ASR输出的翻译Fig. 5 Translation of ASR outputs before and after punctuation recovery
4 结语
本文提出了一种基于BERT 和Focal Loss 的标点恢复模型用于MSI 流水线系统中。该模型既能利用BERT 有效提取句子的全局特征,又可以利用Focal Loss缓解标点任务的类别不平衡问题。实验结果表明,本文提出的标点恢复模型可以显著提升MSI 机器译文质量,且优于使用基于注意力机制的循环神经网络标点恢复模型的MSI流水线系统。
在未来的工作中会集中解决ASR 输出中的不流利和语音识别错误问题以提高MSI的总体性能。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
小学生学习指导(低年级)(2021年12期)2021-12-31
辽宁省博物馆馆刊(2021年0期)2021-07-23
小天使·一年级语数英综合(2020年11期)2020-12-16
小读者(2020年4期)2020-06-16
动漫界·幼教365(大班)(2019年7期)2019-10-09
小读者之友(2018年4期)2018-08-04
小天使·二年级语数英综合(2018年1期)2018-06-29
长江学术(2016年4期)2016-03-11
作文大王·低年级(2016年1期)2016-02-29
