
基于深度学习的三维点云头部姿态估计
2020-06-01 10:55肖仕华王旭鹏
计算机应用 2020年4期
肖仕华,桑 楠,王旭鹏
(电子科技大学信息与软件工程学院,成都610000)
(∗通信作者电子邮箱xsh115@qq.com)
0 引言
头部姿态信息是研究人类行为和注意力的重要指标。在人际交往中,人们通过改变头部姿态传达信息,例如同意、理解、反对、迷惑等。头部姿态估计可以为许多人脸相关任务提供关键信息,比如人脸识别、面部表情识别、驾驶姿势预测等,因此,头部姿态估计成为了计算机视觉和模式识别领域的一个热门的研究方向[1-4]。
在计算机视觉领域,头部姿态估计[5]是指计算机通过算法对输入图片或者视频进行分析和预测,从而确定人物的头部在三维空间中的姿态信息,即俯仰角(pitch)、侧倾角(roll)和偏航角(yaw)。可靠的头部姿态估计算法具有以下特点:对大尺度的姿态变化保持鲁棒,能够有效地处理遮挡,实时性较高,资源消耗低等[6]。
现有算法主要采用RGB 图像进行头部姿态估计。其中,Hsu 等[1]提出采用RGB 作为输入的深度网络,网络针对四元素和欧拉角的不同输出方式给出了联合的多元回归损失函数。Patacchiola 等[2]研究了自适应梯度法和Droupout 法相结合的卷积神经网络(Convolutional Neural Network,CNN)模型,该模型直接为输入头部RGB 图像建立姿态估计回归模型。Ruiz 等[3]把回归问题转化为分类与回归相结合的问题处理,训练了一个深度CNN 直接从图像强度预测头部姿态。他们首先用分类的结果去映射一个可以回归的区间范围,再利用multi-loss 来进行回归预测。Ahn 等[7]提出了一种利用RGB 估计头部姿态的高效CNN 模型,并采用基于粒子滤波的后处理方法提高了模型在视频应用中的稳定性。Drouard 等[8]提出了方向梯度直方图(Histogram of Oriented Gradients,HOG)特征和高斯局部线性映射模型相结合的方法来进行头部姿态估计,将人脸描述符映射到头部姿态空间,从而预测头部旋转角度。然而,这类估计方法往往会受到光照变化的影响,很难适用于夜间光线较差或白天光照持续变化等环境[9]。
为此,基于点云数据描述的方法被提出。点云数据描述的是场景的三维几何结构信息,不受光照变化的影响,能够有效地应对RGB 彩色图像存在的问题。Fanelli等[6]考虑到随机回归森林处理大型训练数据的能力,通过该方法来估计鼻尖的三维坐标和头部距离图像的旋转角度,从而实现姿态预测。Padeleris 等[10]根据相机获取的深度图重建头部的三维几何模型,然后使用粒子群优化算法进行头部姿态估计。Papazov等[11]引入了一种新的三角曲面描述符来编码三维曲面的形状,训练阶段合成头部模型,通过对比输入深度图与头部模型的描述符进行头部姿态估计。随着深度学习在计算机视觉领域取得巨大的成功,研究人员开始采用基于深度学习的方法解决头部姿态估计问题。Venturelli 等[12]采用深度图作为输入,将CNN 用于头部姿态估计。Chen 等[13]提出CNN 与随机森林相结合的方式,采用CNN 来获取关节信息,再通过随机森林将之细化,进而实现姿态估计。但是,传统的深度学习网络架构只能处理高度规则的数据格式,比如二维图片或三维网格,而点云数据是点的集合,通常被转化为多视角下的深度图或三维网格,这导致了数据的冗余,计算复杂度高,无法满足实时性的要求[14-15]。
针对上述问题,本文直接采用点云数据作为输入来进行头部姿态估计,提出了一种新的深度学习框架——HPENet。主要思想是,将头部姿态估计抽象为回归问题,对于输入的无序排列和非均匀分布的点云,通过深度网络提取鲁棒的头部特征,用于头部姿态的估计。为了解决点云数据存在的非均匀采样和无序排列问题,HPENet分别引入了分组采样层和特征提取层,从而提高三维头部姿态估计特征提取的准确性。HPENet能够直接处理点云数据,结构简单,准确度高,更能适用于快速、可靠的人脸分析任务。
1 基于点云的深度学习
点云数据是三维几何信息的一种表示方式,是由一系列的点组成的集合{ pi=(xi,yi,zi)|i = 1,2,…,N }。其中:pi代表点云中的元素;(xi,yi,zi)为其三维空间坐标;N 表示点的数目。此外,点云也可以用一个N × 3 维的矩阵来表示。与三维网格(mesh)相比,点云数据结构简单,对几何信息的表示统一,更适用于深度网络的学习[14-15]。
传统的深度学习以规则的数据为输入,比如二维图像网格或三维体素,能够实现网络权重共享,进行卷积操作。卷积神经网络在各种任务中成功的关键在于,卷积算子能够有效地利用规则数据的空间局部相关性[16]。
而点云数据是一系列无序点的集合(见1.1 节),无法直接应用卷积操作;同时,点云采样密度不均匀(见1.2 节)增加了将深度学习应用于点云数据的难度。因此,需要解决将深度学习应用于点云存在的问题,以提高头部姿态估计的准确性。
1.1 点云无序性
点的顺序不会影响点云在空间中的整体几何表示,相同的点云可以由两个不同的矩阵表示,如图1(a)所示。因此,深度网络架构提取的特征需要对点云的无序性保持鲁棒,即对于点云的不同矩阵表示A 和B,在特征提取时需保证提取的特征是相同的,如图1(b)所示。

图1 点云的无序性Fig. 1 Randomness of point cloud
1.2 在非均匀采样密度下的鲁棒性
点云非均匀采样密度是指在数据采集过程中,由透视变换、径向密度变化、目标运动等引起的点云数据的不规则分布。在这种非均匀的采样密度下,很难保证点集特征学习的鲁棒性。例如,针对稀疏点云区域训练的模型可能无法识别到密集区域更加细微的特征。
因此,本文方法应该能适用于不同密度下的特征提取,即对点云密集区域进行特征提取时,网络应该尽可能小范围地检查点集,以捕获密集采样区域中最细微的特征。然而,对于稀疏区域应该禁止这种检查,因为此时区域内的点数过少,容易导致采样不足,此时,应该在更大的区域内寻找更大的尺度提取特征。
2 头部姿态估计
本文提出了一种新的基于深度学习的三维点云头部姿态估计算法——HPENet。HPENet 以点云数据为输入,输出头部的姿态,用欧拉角(Euler angles)表示,包括俯仰角、侧倾角和偏航角。
2.1 整体结构说明
如图2 所示,方法的整体结构由数据预处理和HPENet 网络构成。数据预处理给出了头部三维点云数据的生成方法(见2.2 节)。HPENet 网络实现了对头部点云数据的姿态估计,其中特征提取模块采用PointNet++[15]网络模型。PointNet++直接处理点云数据,并被成功应用于目标分类、检测和场景分割。
HPENet 网络直接以点云数据作为输入,其维度为B ×N × C,其中,B 是输入batch 的大小,N 为输入点云的点数,C为点云的通道数。本文只采用点云的三维空间坐标作为输入,即C 的值为3。网络输出的是预测的头部姿态角度,其维度为B × 3。
HPENet 网络主要由分组采样层(见2.3 节)、特征提取层(见2.4节)和全连接层三部分组成。
分组采样层主要实现对点集进行特征点采样和分组,两个分组采样层的特征点数目选取分别为512和128,区域半径分别为0.2 和0.4。特征提取层主要实现对分组后的点云进行特征提取。该层依赖于特征提取对称函数,该函数由3 个核为1× 1 的卷积层和一个最大池化层组成。PHENet 递归调用了三次该特征提取对称函数,每次卷积层输出通道数分别为(64,64,128)、(128,128,256)和(256,512,1 024)。全连接层主要实现对输出的特征向量进一步处理,以预测头部姿态。其维度分别为512、256 和3。同时,为了防止过拟合,加入了Dropout操作(σ=0.5)。
由于头部姿态估计可看作一个多元回归问题,因此网络损失函数采用均方误差(Mean Square Error,MSE):

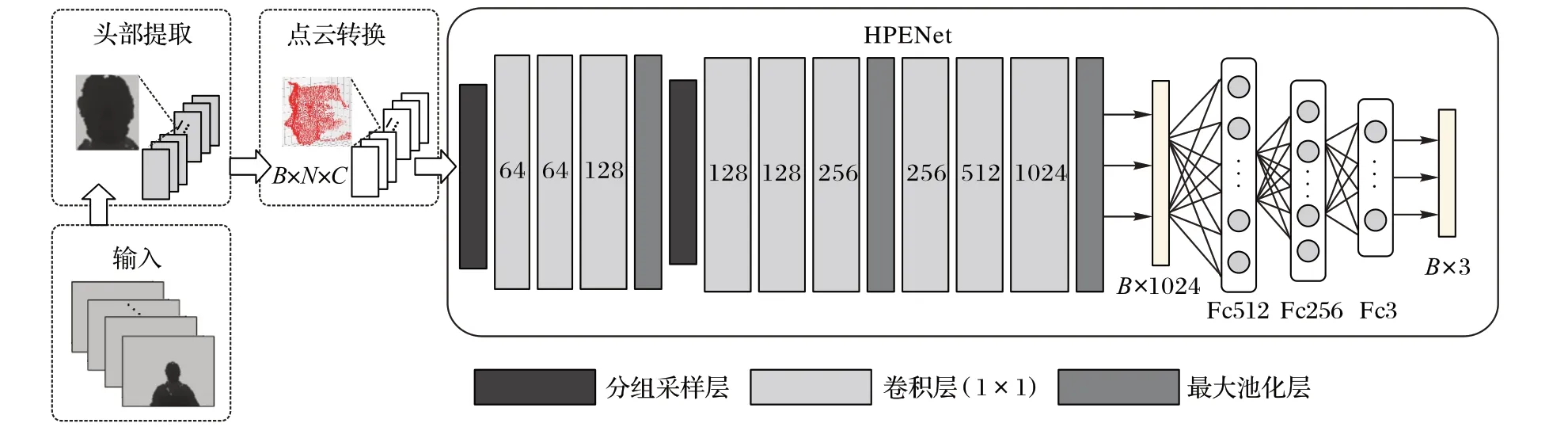
图2 头部姿态估计整体框架Fig. 2 Overall framework of head pose estimation
2.2 数据预处理
深度传感器采集的是场景在某一视角下的三维几何信息,以深度图的形式保存。因此,需要对传感器采集的数据进行处理,以获得三维点云数据[17]。
本文遵从文献[9]的做法,假定经过人脸检测已经获取到头部中心点(xH,yH),则头部的深度图片可由中心点为(xH,yH)、宽和高分别为w、h 的矩形框提取。w、h 的计算公式如下:

其中:fx、fy是传感器的内部参数,分别为水平和垂直焦距;Rx、Ry表示人脸的平均宽度和高度(其值均设为300 mm);D为头部中心(xH,yH)的深度值。
由头部的深度图片生成相应的三维点云结构,就是将图像中的任意一点(u,v)从图像坐标系映射到世界坐标系,如下所示:

其中:(x,y,z)表示世界坐标系下的坐标值;(u0,v0)是传感器的内部参数,分别表示图像坐标系在x和y方向相对于世界坐标系的偏移量;d为点(u,v)处的深度值。
此外,神经网络要求输入数据的维度保持一致,为了将生成的头部三维点云数据用于深度网络架构,本文采用最远点采样算法处理生成的三维点云,使得采样后的点数相同。同时,为了加快网络训练的收敛、减少运算时间,分别对点云数据的三个通道进行标准化,使得数据的均值为0、方差为1。
数据采用SPSS 22.0软件进行统计处理。首先进行正态分布检验,符合正态分布的计量资料以x±s表示,多组间比较采用方差分析,两组间比较采用t检验。P<0.05为差异有统计学意义。
2.3 下采样和分组
如1.2 节所述,在对点云数据进行特征提取时,网络需要有效地处理非均匀采样密度的问题,以提高网络学习的特征的鉴别力。本文在HPENet深度网络中引入分组采样层,将点云数据进行分层表示,用于后续点云由整体到局部的特征描述。
分组采样层由下采样和分组操作组成,下采样提取点云数据中的特征点,分组操作借助关键点将点云数据进行分组表示。HPENet通过递归调用分组采样层,实现了点云数据的分层表示。
下采样采用最远点采样算法[18]。对于一个给定的点集{ p1,p2,…,pn},从中随机选取一点pi,找到距离该点最远的一个点pij放入新的集合。迭代上述过程,便能获指定数目的采样点集{ pi1,pi2,…,pij},并将该点集中的点作为当前点云数据的特征点。与随机采样相比,最远点采样算法获得的点能够更好地覆盖整个点集[15]。
分组操作以提取的特征点{ pi1,pi2,…,pij}为球心、按照特定的半径将不同区域的点进行分组,获得一个新的分组集合{g1,g2,…,gj},gj表示由pij为球心特定半径内的所有点的集合,将该集合用于后续特征提取(见2.4节)。
迭代上述下采样与分组操作,实现了点云的分层表示,如图3 所示。分组采样层能够有效地解决点云数据存在的非均匀采样问题,使得网络能够学习到点云整体到局部的特征。
2.4 点云特征提取
本节首先给出了特征提取对称函数的公式及定理描述,通过该对称函数解决点云数据存在的无序性问题(见1.1节)。然后,对于2.3 节提出的分组采样,后续给出了详细的分层特征提取说明。
定义离散空间χ =(P,d)∈ℝN,其中点集P ⊆ℝN,d 是距离度量。对于给定一个无序点集{ pi∈ℝN|i = 1,2,…,n },通过分组采样获得新的分组集合{g1,g2,…,gj},定义一组函数f:χ →ℝ将一组点映射到向量:

定 理1 假 定f:χ →ℝ 是 一 个 对 于Hausdorff 距离dH(⋅,⋅)的连续函数,∀ε >0,存在一个连续μ和一个对称函数υ ∘max,使得∀P ∈χ都有:
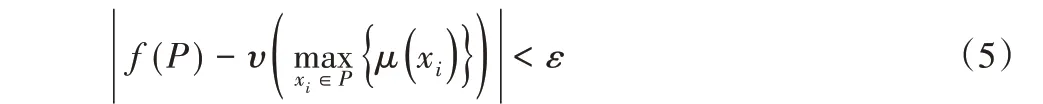
其中:x1,x2,…,xn是任意顺序点集P 的完整点云序列;υ 是一个连续函数;max 是一个向量最大值操作,即输入n 个向量并返回一个元素最大值的新向量;符号“∘”是映射乘法,也就是应用了映射max后,再应用映射υ。
上述定理1 表明,如果最大池层有足够多的神经元,f 可以被该网络任意近似,即式(4)中M 足够大。通过这种近似,无序的点云能够被一个一般函数表示,从而解决点集的无序性问题。
此外,承接2.3 节提到特征分层提取。对分组后的点云数据,本文通过对称函数中的多层感知机进行特征提取,提取示意图如图3 所示。点集的特征由两个特征向量组成:特征向量a 由Li层所有点特征提取汇总而成,该层所有点特征由Li-1层中每个分组特征获得;特征向量b是直接处理Li-1层区域内所有原始点而获得的特征。对于点集稀疏区域,每个分组内包含较少的点,容易导致采样不足,使得第一个向量不如第二个向量可靠。因此,在训练时第二个向量学习到的权重会更高。另一方面,当对点集密集区域提取特征时,在分组内提取特征具有更高的检测分辨率,能够获取到点云更精细的特征信息,所以在这种情况下,第二向量学习到的权重会更高。训练时,网络按上述方式不断学习、调节权重,找到适合不同点云密度下提取特征的最优权重,从而有效地解决在非均匀密度下采样的问题。
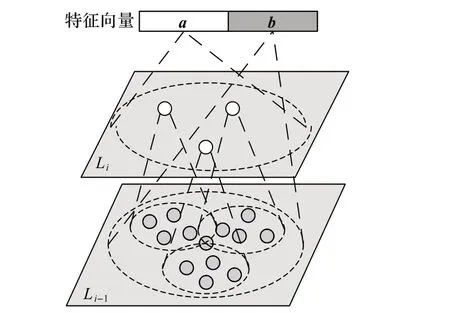
图3 分层特征提取示意图Fig. 3 Schematic diagram of feature extraction of different layers
3 实验与结果分析
为了验证本文提出的三维点云头部姿态估计网络HPENet的有效性,进行了一系列的实验。本章首先介绍了用于实验的公共数据集Biwi Kinect Head Pose[6](见3.1 节);然后,测试了HPENet 在头部姿态估计上的准确性,验证了不同密度下的点云输入对姿态预测鲁棒性的影响,还测试了方法的时间消耗(见3.2节)。
为了定量地评价头部姿态估计的准确性,本文遵循文献[9]的做法,采用评价指标S如下:

其中:α 为所有真实值与预测值之差的绝对值的均值;β 为所有真实值与预测值之差的绝对值的标准差。
在超参数的选取上,batch 的大小为32,输入点云的点数为4 096,学习率为0.001,衰减率为0.9,衰减步长为20 000。实验在Ubuntu16.04 操作系统下运行,CPU 为Intel Core-i7(3.40 GHz),内 存 为16 GB,显 卡 为NVIDIA GTX1080TI 11 GB。
3.1 数据集
Biwi Kinect Head Pose 数据集[6]采用Kinect 传感器采集,具有15 000 多张头部姿态图像,包括深度图和相应的RGB图,分辨率均为640×480。数据集记录了20 个不同人物(6 名女性和14 名男性)的24 个序列,其中一些人被记录了两次。因为深度图像的质量较低,头发、眼镜等对数据造成了一定干扰,使之成为一个具有挑战性的数据集。数据集给出了头部姿态的真实值,并提供了人物的头部中心位置和传感器的内置参数。为了与其他优秀算法作对比,并保证对比结果的有效性,本文实验遵循文献[9]的做法,将数据集分为训练集和测试集。其中:测试集包括序列11 和12,约1 000 张图片;训练集包含剩余的22个序列,约14 000张图片。
3.2 结果分析
从图4 所示的损失函数训练变化曲线可看出:在训练开始阶段损失值下降幅度很大,说明学习率合适梯度下降过程;在学习到一定阶段后,损失曲线逐渐趋于平稳,说明网络逐渐收敛。
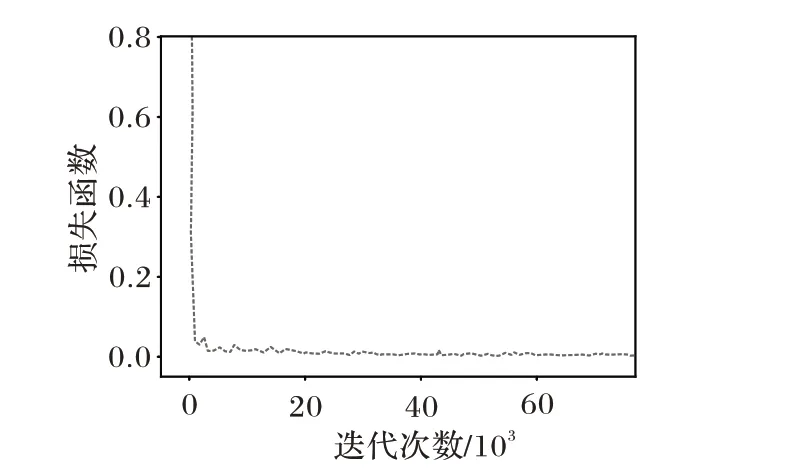
图4 损失函数训练变化曲线Fig. 4 Curve of loss function
图5 给出了本文方法在测试时,每帧图片的俯仰角、侧倾角和偏航角的真实值和预测值的变化曲线。从图5 可以看出,预测的头部姿态角度和数据集提供的真实值极其接近,即本文方法能够精确预测头部姿态角度。此外,当曲线中的角度值增大时(如图5(a)角度大于40°),预测的误差略有增加。这是因为当头部偏转或俯仰角度增大时,所遮挡的头部区域变大,该区域具有的特征变少,从而使得预测更加困难。
表1 列出了本文方法和其他优秀算法在公共数据集Biwi Kinect Head Pose 上实验的结果对比。表1中给出了方法的数据类型、俯仰角、侧倾角和偏航角的性能指标以及平均性能,其中部分方法只提供了三个角度的误差的均值。从表1 可以看出,与其他方法相比,本文方法具有更小的误差,俯仰角、侧倾角和偏航角的误差均值分别为2.3°、1.5°、2.4°。同时,HPENet 的平均标准差为1.6°,小于其他方法,说明该方法预测结果趋于准确值且波动更小。
表2 列出了在1 024、2 048 和4 096 三种不同输入点数下进行头部姿态估计的实验结果。从平均值来看,三种输入点数,平均的误差值分别为2.4°、2.2°、2.1°,三者差异极小,即输入点的数目变化对本文方法在头部姿态估计上的结果影响不大。点数越多所包含几何信息更多,点云分布更稠密。这也说明了本文方法在非均匀采样密度下进行特征提取,具有较好的鲁棒性。
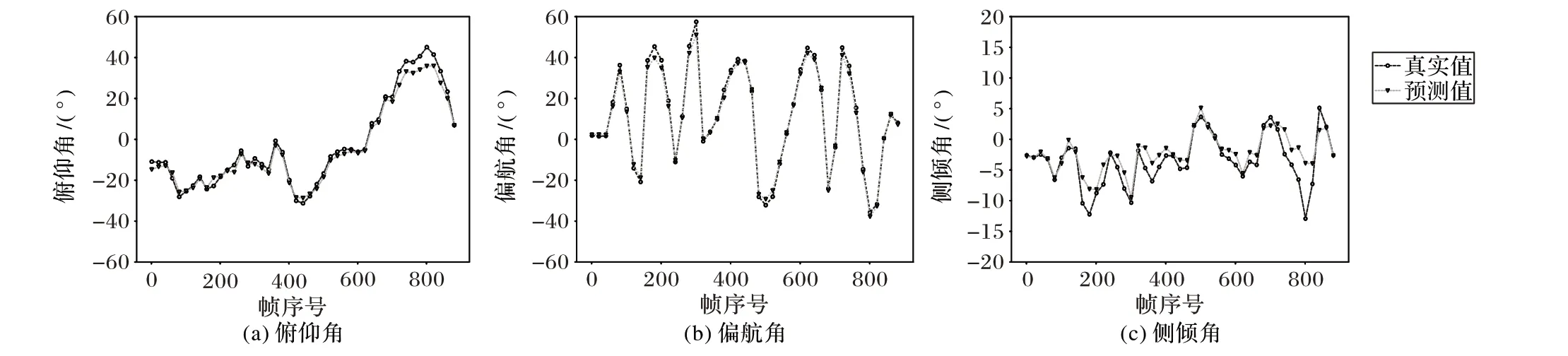
图5 姿态角度预测示意图Fig. 5 Schematic diagram of prediction of pose angles
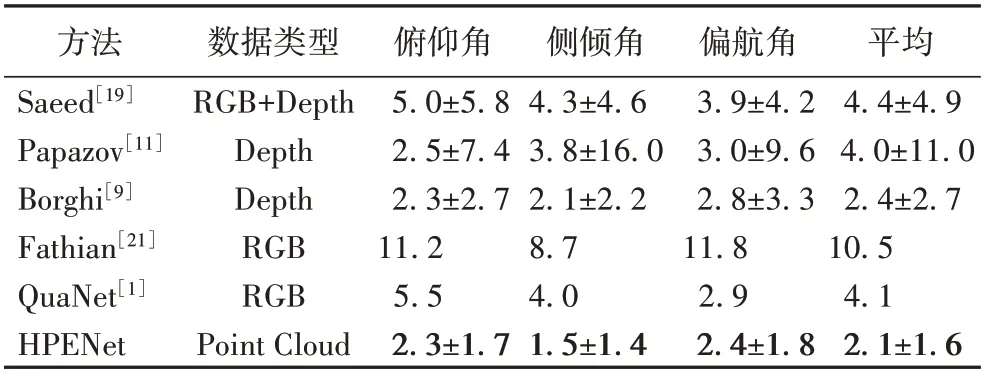
表1 不同方法在Biwi数据集上的误差比较 单位:(°)Tab. 1 Comparison of errors achieved by different methods on Biwi dataset unit:(°)
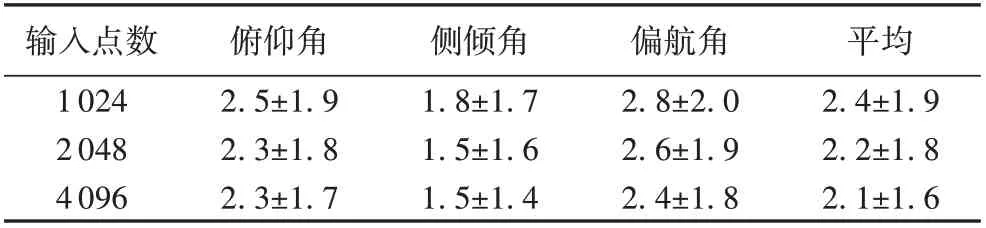
表2 HPENet在Biwi数据集上输入点数对误差的影响单位:(°)Tab. 2 Influence of different number of input points on errors achieved by HPENet on Biwi dataset unit:(°)
为了更加直观地体现本文方法的性能,给出了测试中两个姿态角度较大的姿态预测示例,如图6 所示。图6(a)是测试输入的截取后的头部深度图片,图6(b)是头部点云真实姿态图,图6(c)是头部点云预测姿态图。为了便于观察姿态角度,图6(b)、(c)中在鼻尖用圆柱体标出。由于角度较大,面部遮挡更加严重,使得预测更加困难。但从图6 中可以看出真实姿态角度和网络预测的姿态角度差距不大,说明HPENet对遮挡、姿态角度较大的图片依然具有鲁棒性。
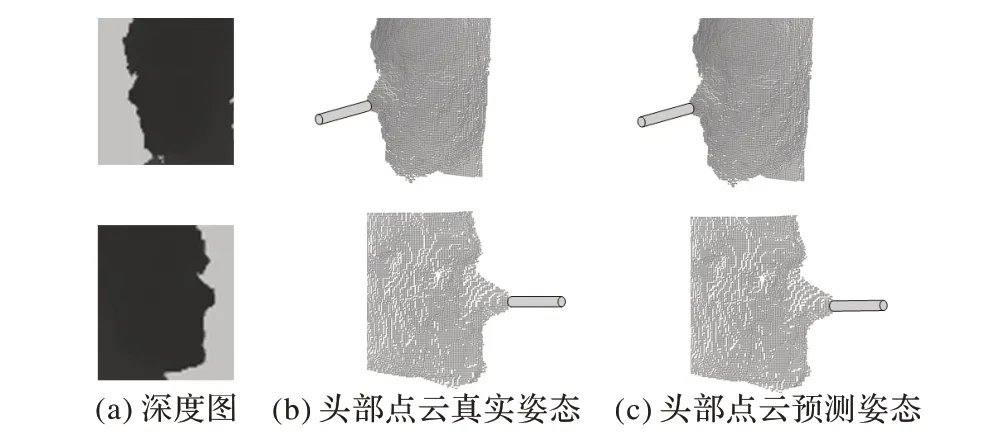
图6 姿态预测示例Fig. 6 Examples of head pose prediction
表3 列出了几种方法在时间消耗上的比较。从表3 中可以看出,在同种数据集和实验环境下,本文方法的时间消耗为8 ms/frame,远低于其他对比方法。这是由于本文提出的网络结构相比于其他采用RGB 或深度图作为输入数据的网络更加简单;同时,本文方法直接处理点云数据,避免了将点云转化为多视角下的深度图或三维网格所带来的数据冗余和计算复杂度高的问题。

表3 时间消耗比较 单位:msTab. 3 Comparison of time cost unit:ms
4 结语
为了解决头部姿态估计问题,本文提出了一种新的深度学习网络架构HPENet,能够直接处理点云数据。在公共数据集Biwi Kinect Head Pose 上的实验结果表明,相对于目前大多采用传统RGB 图和深度图片的方法,HPENet 具有更高的准确性。同时,本文方法结构简单、时间消耗低,能够应用在许多人脸相关任务中。后期我们将对网络进一步优化,以获得更好的效果,并应用于三维人脸检测、识别等任务中。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
汽车零部件(2021年9期)2021-09-29
军事文摘(2020年22期)2021-01-04
学生天地(2020年3期)2020-08-25
北京航空航天大学学报(2019年9期)2019-10-26
电机与控制学报(2018年9期)2018-05-14
计算机应用(2016年10期)2017-05-12
诗选刊(2015年4期)2015-10-26
电影新作(2014年5期)2014-02-27
早期教育(美术教育)(2010年7期)2010-06-28
