
基于相似论文增广的深度学习专利质量评估
2020-06-01 10:55李小娟
计算机应用 2020年4期
韦 伟,李小娟
(中国科学院计算技术研究所,北京100190)
(∗通信作者电子邮箱lixiaojuan@ict.ac.cn)
0 引言
我国一直积极深入实施知识产权战略保障国家的技术安全,知识产权保护已经成为经济发展的重要依托。围绕知识产权的交易已经逐渐变成知识产权保护与服务的重要内容。在知识产权保护不断完善的过程中,专利交易作为知识产权的交易核心,其对经济活动的作用也更加突出,它的重要性也日益凸显。但是,如何确定专利的实际价值一直是研究的重点和难点,长久以来专利交易过程中存在的一个突出问题是如何保证专利的交易价格能够与专利的实际价值对等。
针对如何评价专利的实际价值的问题,国内和国外专家均进行了广泛的研究,并取得了一定的效果。文献[1]使用多个指标的组合来评价专利质量,如专利被引用的次数、专利引文的数量、权利要求的数量和专利维持水平;世界上最大的国际联机情报检索系统Dialog 提出了专利强度来评价其质量的方法,专利强度是多个技术指标的综合,包括专利引证、诉讼数目、权利要求数、审查时间等12 项指标;文献[2]利用层次分析(Analytic Hierarchy Process,AHP)法构建专利质量评估模型,所构造的模型同时考虑了专利的技术特征、技术市场、成本以及产品市场4 个指标的特征;文献[3]依据国内专利发展现状,提出单件发明专利质量评价指标体系,同时使用层次分析法计算相应指标的权重;文献[4]考虑技术、市场、竞争和法律因素对专利质量的影响,建立专利质量评价模型;文献[5]研究了4 项专利质量指标与企业市场市值之间的关系,通过回归分析用企业市场价值和专利质量之间的关系评价专利质量;文献[6]考虑神经网络具有强大的学习能力,通过构建神经网络模型进行高质量专利筛选;文献[7]针对犹豫模糊软集能够更加准确地描述事物本质的特性,提出使用犹豫模糊软集进行专利技术质量评价的方法;文献[8]提出运用直觉模糊层次分析法计算各专利指标权重,同时依据模糊评价法对专利质量进行评估的联合评价方法;文献[9]采用文献分析法,通过对现有研究文献的梳理和分析,从专利的技术性、法定性和商业性对专利质量作出预测,提出专利技术质量评价综合指标体系;文献[10]从法律、技术和市场三个角度出发构建专利质量评价模型,同时组合AdaBoost 算法构建的多个决策树模型,最终得到专利质量评价模型。
在实际操作中,一个专利的实际价值评估过程通常需要考虑市场、法律、技术等多方面的因素,不同的质量评价方法对不同因素的考量也不尽相同。但无一例外,专利本身的技术质量都是各个评价方法中的重要一环。目前,针对专利质量评价的方法多采用专家打分或者采用行业领域专家所设计的打分及评价体系。然而,这种方法受到专家个人主观因素的限制较多,难以客观地描述专利的技术质量。上述文献所述方法虽然提出了客观质量评价方法,但在技术质量评价时,考虑的因素仍然没有摆脱传统评价体系,忽略了一个重要的因素,即论文与专利的关系,论文与专利具有很大的相似性,可以利用与专利相似的多篇论文间接地映射专利的技术质量。而现阶段,论文质量评估方法相对健全,客观评价指标已被广泛接受,论文质量的评估是学术界一直关注与探讨的核心问题之一。文献[11]通过分析科技论文的质量评价体系和评价准则,选择论文被引频次、评价指标指数、影响因子作为评价指标,并利用链接分析法和引文分析法进行论文质量的评价。文献[12]依据层次分析法和模糊数学理论的评价方法,将论文质量的评价进行定性分析到定量分析的转化,利用论文质量评价指标建立判决矩阵,同时进行一致性检验,计算各个指标的单层权重值和合成权重值,最终实现论文质量评估。文献[13]主要对反映学术型硕士学位论文质量的5 个指标,即论文选题、论文创新、论文写作、论文成果及论文评阅和答辩进行综合考量,然后基于模糊综合评判模型提出判定论文质量的模糊综合评价方法。文献[14]考虑以下6 个维度的因素:论文选题来源、文献收集能力、专业知识水平、指导教师水平、知识创新能力和论文写作质量,构造科学、客观的论文质量评价模型,使用离散Hopfield 神经网络进行论文质量评估。经过多年的发展,论文质量的评估的多种判定方法已经被大家广泛接收。目前,主要的评价参数包括论文的引用数量及论文引用H-index,期刊、会议影响因子,作者影响因子等,这些参数已被认为能够广泛客观地反映论文质量。
虽然已有成熟的论文质量评价已经能够反映专利的质量,但是如何建立专利和论文之间的联系,是关乎专利质量评价的关键问题。本文提出使用文档相似度计算来构建专利与相似论文的集合,通过计算文档距离,筛选出最相似论文集合,作为专利技术质量评估的增广数据集,并利用该数据集合构建专利质量评估模型,用于评估专利质量。
在此基础上,通过团队在多年知识产权服务工作中积累的大量被广泛认可专利质量评估数据作为样本。本文进一步使用了神经网络作为训练方法,实现利用论文相似性与专利技术质量评价之间的映射。深度神经网络(Deep Neural Network,DNN)[15]通过加深网络的层次,使其性能进一步增强,通过建立含有大量节点的深度网络模型,完成各种分类和预测任务,能够完全胜任专利或论文的质量评估工作。
综上,本文提出了一种结合论文质量评估的针对专利技术质量评价的方法,所提方法在文档相似度计算和深度神经网络的基础上,通过论文客观质量来评价专利的技术质量。
1 专利质量评估方法设计
1.1 专利质量评估架构
本文所提出的专利质量评估的架构如图1 所示,该方法首先从专利出发,以专利核心关键词及所属领域为出发点,获取与专利相关的论文集合,并以论文与专利之间的相似性计算为筛选方法,筛选相似论文作为专利评估的增广数据集。然后将论文数据集中的相似性计算结果与论文的引用情况、论文发表时间、论文发表期刊、论文作者等多个因素输入深度神经网络进行训练,形成论文与待评估专利间的质量评估模型。在形成上述质量评估模型后,在实际专利质量评估时,通过对所测试专利最相似的论文分别应用该质量评估模型,计算出每篇论文对专利的质量评估指数,并最后计算评估质量指数的算术平均为最后的专利质量评估结果。
论文与专利的相似性计算主要通过关键词匹配的方法,采用词移距离(Word Mover's Distance,WMD)算法[16-17],用来度量文档距离,而最相近论文的筛选规则是取文档相似度值大于0.8的文档(0.8为实际测试所得阈值)。
论文的质量特征指标包括论文的发表时间、论文发表期刊的影响因子、论文的引用因子、论文的作者因子,其中,如果是同作者的论文则没有论文的作者因子这个指标。
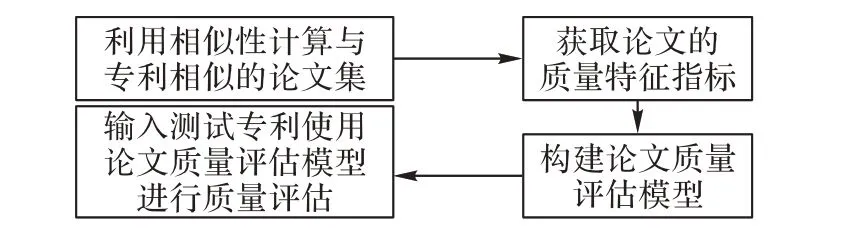
图1 专利质量评估的架构Fig. 1 Patent quality evaluation framework
1.2 论文与专利相似度计算
本文通过专利与论文间的文档相似性计算来筛选相似论文,从而构成论文集合。本文使用的文档相似度计算主要通过WMD 算法计算文档距离,WMD 算法核心思想是将EMD(Earth Mover's Distance)和词嵌入(word2vec)相结合。EMD算法实际上解决线性规划中运输问题的最优路线问题,用来测量某分布之间的距离。而将EMD 算法应用于自然语言处理领域与词嵌入技术相结合,通过词嵌入,可以得到词语的分布式低维实数向量表示,可以计算词语之间的距离,即可完成文档相似度的计算。
文档相似度计算流程如图2 所示。首先需要使用初始关键词检索与专利相关的论文,组成初始论文集。然后,为了对整篇文档进行文档相似度计算,需要统计出文档中的关键词,关键词的统计采用两步进行提取:首先,通过专利所属领域方向提取核心技术关键词,相关核心专业关键词根据领域标引数据生成,相关生成方法超出本文讨论范围,不在此具体讨论;其次,对非核心专业关键词通过文档词频的统计方法,由于停用词的词频会更多,所以在统计文档词频时,需要去除停用词。文档的相似度计算核心采用word2vec,通过word2vec,将所有关键词转换为一定维度的向量,向量中元素的初始值通过领域专业词库结合词频进行确认。在生成向量的基础上,进而通过式(1)计算不同文档关键词间的欧氏距离来计算关键词i到关键词j的相似度:

得到不同文档的关键词间的距离后,即可得到两个文档间的距离:

在这里定义转换矩阵Rij(Rij≥0),表示文档1 中的词i有多少转化为了文档2中的词j。
因此,需要将累计的代价最小化,即求如下公式:

为了保证文档1 能转化为文档2,需要保证词i 转化为文档2 中所有词语的量之和为di,同理,也应该满足文档1 中转化到文档2中的词j的总量为d′j。
由于需要使用语料来训练词向量,而不同领域的语料训练出的词向量能够侧重于在不同的领域使用,为了提高文本相似度计算的效果,使用不同领域的语料来训练词向量。
最终计算出所有与专利距离最近的论文(而最相近论文的筛选规则是取文档相似度值大于0.8 的文档),组成专利评估的增广论文数据集,经过筛选后的论文质量评价被用于反映专利技术质量。
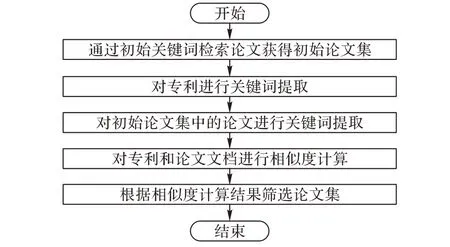
图2 文档相似度计算流程Fig. 2 Process of document similarity calculation
1.3 专利质量评估模型
专利质量评估模型主要是映射专利相似论文的质量特征指标与论文质量之间的关系,此模型的构建使用深度神经网络,构建模型后主要进行模型的训练。模型训练的目的为获得单篇论文与目标评估专利之间的质量评估模型。
设定训练专利集合为Γ,训练专利评估模型的过程如图3所示。图3 中所示训练过程,根据论文属性,将增广论文集划分为两个不同的集合:与专利作者同相似论文集合Pa,以及非专利作者的相似论文集合Pna。对于任意专利T ∈Γ,获得其相似的论文集合,获取方法为:首先检索与目标专利具有相同作者或者是同一单位的论文,构成论文集合Pa;其次,获取专利T 的关键词集合Kt,利用关键词检索论文,获得其他作者的其他论文,所得到的论文集合为Pna。对于论文集合Pa和Pna分别进行不同操作。
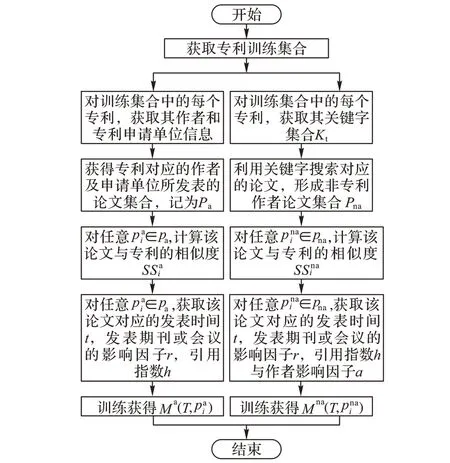
图3 训练专利评估模型流程Fig. 3 Process of training patent assessment model


针对上述两个论文集合Pa和Pna,分别利用图4 和图5 中所示的深度神经网络进行训练。深度神经网络具有输入层、多个隐藏层和输出层,主要特点是内部各层节点间的连接是全联接的,网络通过不断学习,逐渐调节网络各权重值,调节网络的最终输出逐渐接近期望输出,最终输出质量评估模型。深度神经网络的详细介绍可参考文献[13]。
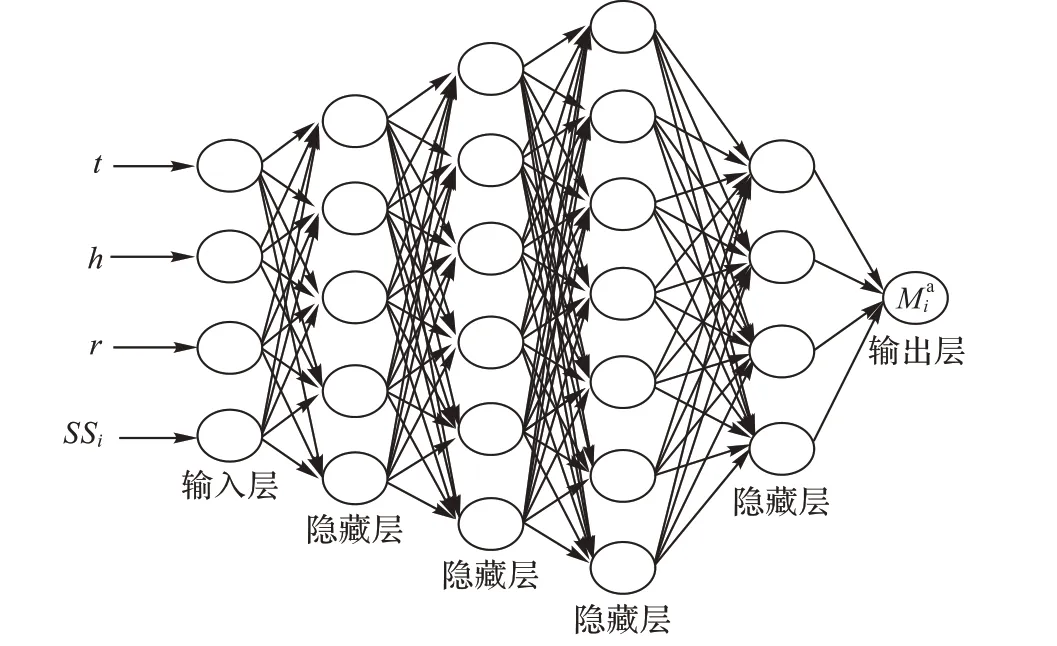
图4 同作者论文深度神经网络结构Fig. 4 Structure of deep neural network of papers with same author
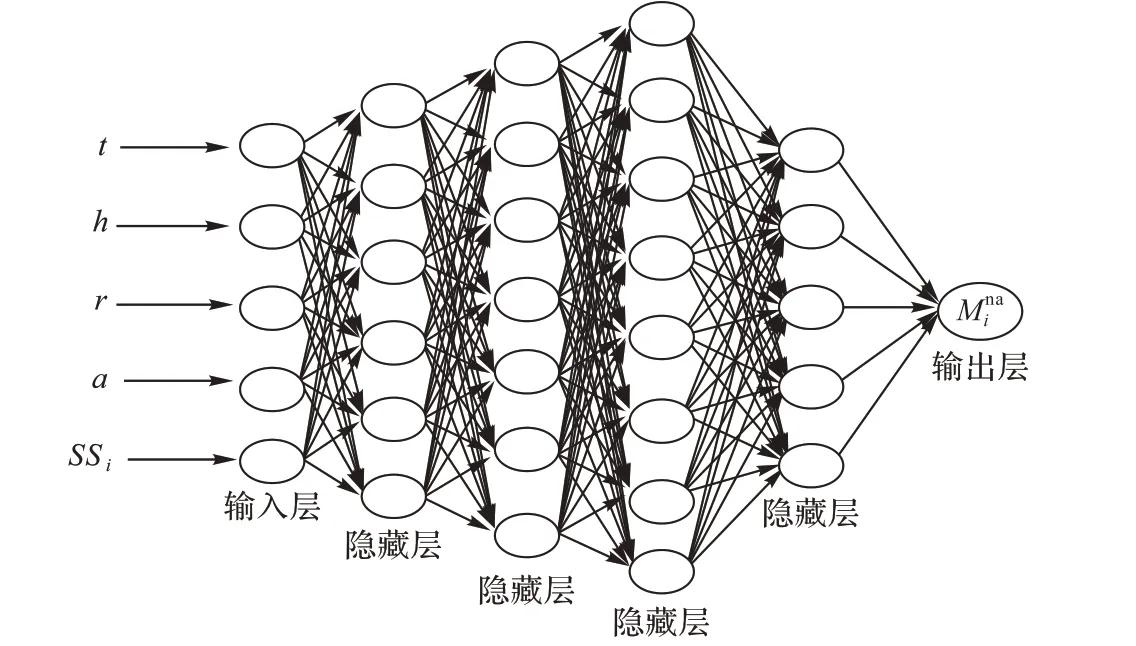
图5 其他作者论文深度神经网络结构Fig. 5 Structure of deep neural network of papers with other authors

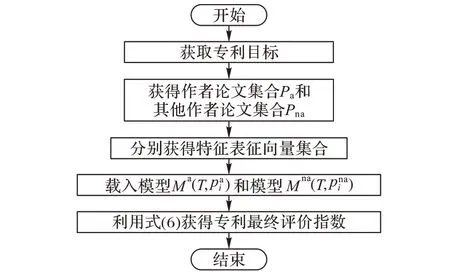
图6 专利质量评估流程Fig. 6 Process of patent quality assessment

2 仿真实验
选取中国期刊全文数据库(China National Knowledge Infrastructure,CNKI)作为论文数据源,它包含中国学术期刊总数据库、中国博士及硕士学位论文数据库、中国重要学术会议论文数据库等数据资源,完全满足本文所提方法的需求。
所采用的专利质量打分取值为(0,100],该分值越高,表明待检测专利质量越好。与专利相似的论文质量特征指标分别为:论文的发表时间t、论文发表期刊的影响因子r、论文的引用因子h、论文的作者因子a(如果是同作者的论文则没有论文的作者因子这个特征指标)。
根据团队积累的专利评价数据,分别选取机械工程、物理、电学、化学4 个领域的专利,各自形成1 000 组训练数据集和100 组测试数据集,并给出每组样本的专利质量专家定性评价分数。首先分别使用4 个领域的语料训练各自领域的词向量,然后使用各自的1 000 组训练数据集分别对上述4 个领域的专利质量评价模型进行网络模型训练,分别生成4 个领域的专利质量评价模型,再分别使用各自的100 组测试数据进行专利质量模型的测试,并将测试结果与专家定性评价结果进行比较,所得误差对比结果如表1所示。
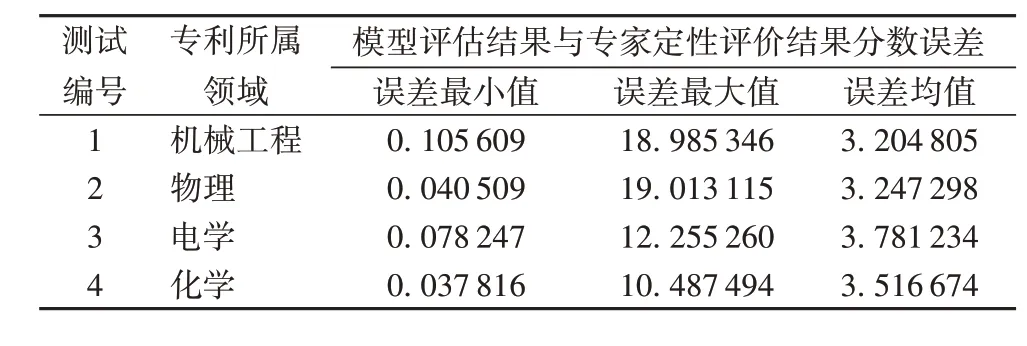
表1 专利质量评估模型测试误差对比Tab. 1 Test error comparison results of patent quality evaluation model
从表1 可以看出,本文提出的专利质量评价模型已经具有较好的学习能力,对于机械工程、物理、电学和化学4 个不同领域的专利,模型评估结果的误差均值分别为3.204 805、3.247 298、3.781 234 和3.516 674,能对专利质量和评分产生较好的反映,可以适用于专利质量评估。不同领域的专利质量评价结果误差最小值均能控制在1 以下。4 个不同领域的专利均能够得到与专家定性评价结果相一致的质量评分,说明本文方法已具有专利质量评价能力,且能较好地评价专利质量;同时,本文方法能够实现不同类型的专利的质量评价。
为了进一步验证本文方法的有效性,将本文方法与基于AHP 法构建的模型、基于反向传播神经网络模型构建的模型和基于犹豫模糊软集构建的模型进行对比。对比方法均采用直接对专利进行质量评价,使用的专利特征为专利的技术特征、技术市场、成本以及产品市场4 个指标,分别针对机械工程、物理、电学、化学四个领域的专利,各自100 组测试专利的质量评价和专家定性评价的对比结果如图7~10所示。
从图7~10 可以看出,所选测试专利的质量不等,本文方法和对比方法均能对机械工程、物理、电学、化学4 个领域的专利进行有效的质量评价,并且能够将不同质量的专利进行有效地区分。本文方法对某些专利的质量评价误差较大,如机械工程领域的编号为66 的专利,误差达到18.929 777,物理领域编号为34 的专利,误差达到19.013 115,而对比方法在处理这些专利时误差较小。造成这种现象的原因是由于专利质量和论文质量存在一定的差异,根本原因是待评价的专利并不一定能找到完全匹配的论文。但是,对比算法在处理某些专利时也存在误差较大的情况,比如使用AHP 模型处理机械工程领域的61 号专利时的误差达到了27.553 747,使用反向传播神经网络模型处理化学领域的98 号专利时误差达到17.025 602,使用犹豫模糊软集模型进行机械工程18 号专利的质量评价时误差达到16.831 319,而本文方法在处理这些专利时误差均较小。
为了能够更直观地分析不同算法的专利质量评价结果,使用平均绝对误差对图7~10所示结果进行分析,得到图11所示统计结果。使用反方向传播神经网络模型进行专利质量评价的结果误差较大,平均绝对误差基本在4 以上,使用犹豫模糊软集模型进行专利质量评价的结果误差小于AHP 模型得到的误差,而本文方法的结果误差相对较小。可见本文方法能够综合利用与专利质量相似的多篇论文进行专利质量计算的优势,这种机制为专利质量评价提供更有效的质量分析依据。
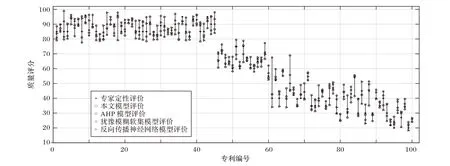
图7 机械工程领域专利质量评价对比Fig. 7 Comparison of patent quality evaluation in mechanical engineering field
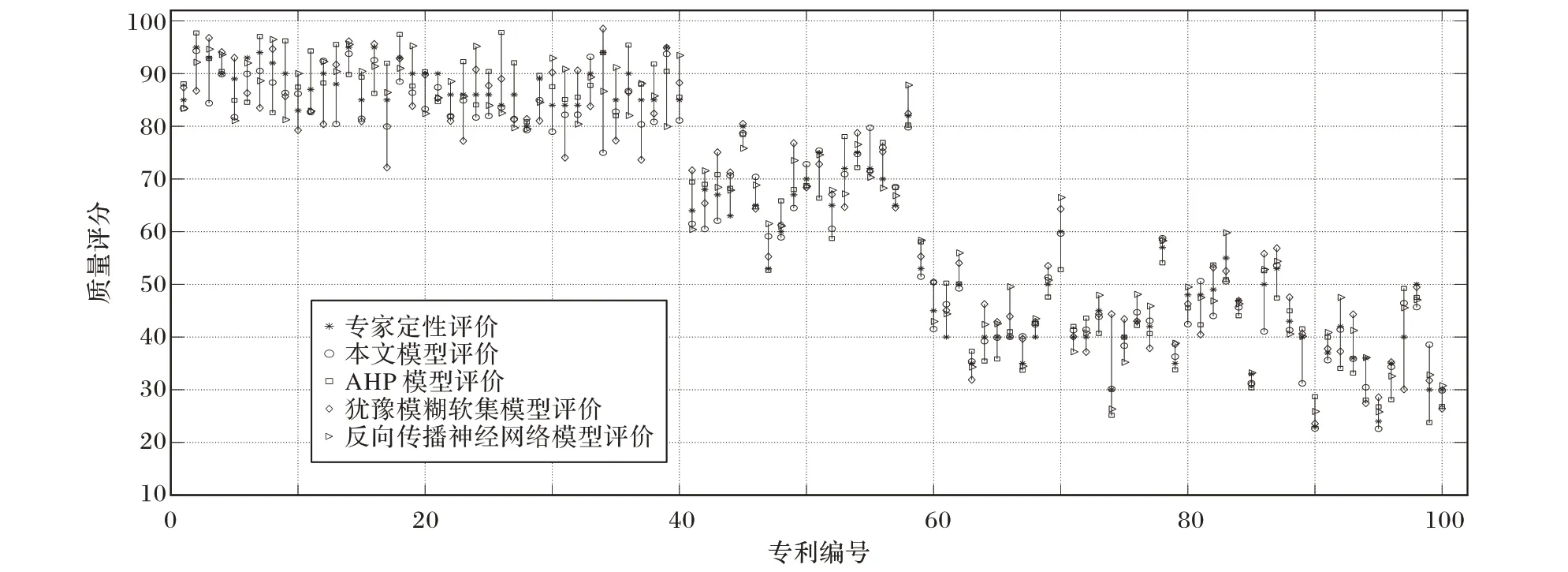
图8 物理领域专利质量评价对比Fig. 8 Comparison of patent quality evaluation in physical field
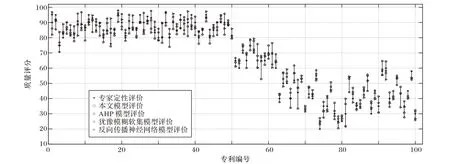
图9 电学领域专利质量评价对比Fig. 9 Comparison of patent quality evaluation in electricity field
3 结语
本文通过分析现有国内外专利质量研究方法,考虑专利和论文之间的相似性,通过文档相似度计算筛选出相似论文组成论文集,为专利质量计算提供可靠基础;同时,考虑深度神经网络拥有的较强的非线性映射性能,提出了一种以文档相似度计算和深度神经网络的使用论文质量来估计专利质量的评估方法。仿真结果表明,本文方法能够对不同领域的专利进行较好的质量评估。最后需要说明的是,本文所提评价方法可能具有一定的片面性,需要不断进行探讨和研究。但本文所提方法对专利质量评价技术的研究具有一定的启迪性。
此外,本文在进行文档相似度计算时依赖于提取的关键词的准确性,目前采用的通过词频提取关键词的方法存在不确定性的因素,比如,提取的关键词并不一定是论文核心关键词,因此,在接下来的工作中,需要解决提取关键词时的不确定性。
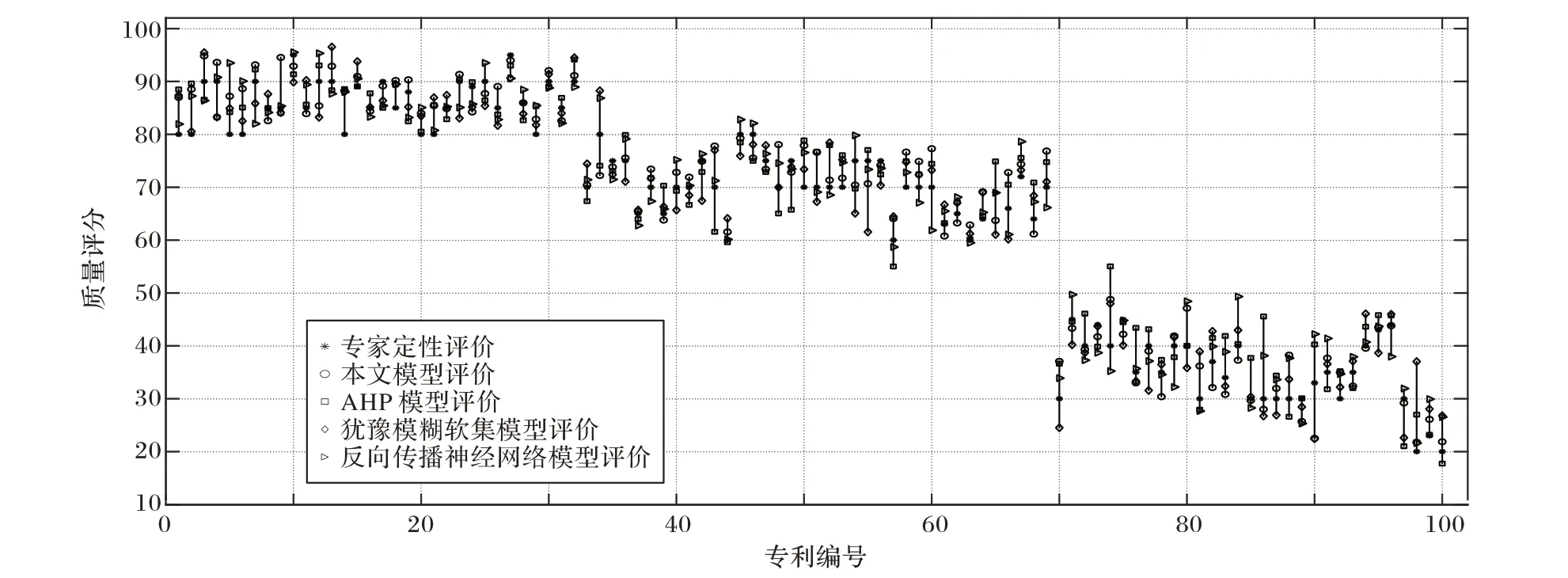
图10 化学领域专利质量评价对比Fig. 10 Comparison of patent quality evaluation in chemical field
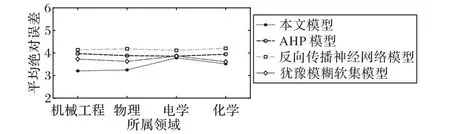
图11 专利质量平均绝对误差对比分析Fig. 11 Comparison and analysis of mean absolute error of patent quality
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
客联(2022年3期)2022-05-31
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年4期)2021-11-24
中国新闻周刊(2021年26期)2021-07-27
电脑爱好者(2021年9期)2021-05-12
软件(2017年6期)2017-09-23
电脑爱好者(2017年7期)2017-05-06
中国发明与专利(2007年7期)2007-08-09
