
基于深度学习和特征融合的人脸活体检测算法
2020-06-01 10:55王洪春
计算机应用 2020年4期
邓 雄,王洪春*
(1. 重庆师范大学数学科学学院,重庆401331;2. 智慧金融与大数据分析重庆市重点实验室(重庆师范大学),重庆401331)
(∗通信作者电子邮箱wanghc@cqnu.edu.cn)
0 引言
随着人类社会进入数字时代,生物识别技术越来越多地被应用于身份认证,其中人脸识别技术因其安全性和非接触性等优点,已成为学术界和工业界的一个重点研究方向[1]。然而人脸识别系统容易受到欺骗攻击,如照片攻击、视频攻击和3D 面具攻击等,严重威胁了系统的安全性。针对欺骗攻击,设计一个检测精度高、耗时短、鲁棒性强、泛化能力强的人脸反欺骗系统至关重要。
面向人脸识别系统的反欺骗检测又称为人脸活体检测。真实人脸图像和欺骗人脸图像在图像纹理信息、图像光谱信息、图像运动信息、图像深度信息等方面存在一定的差异。利用这些差异可以设计不同的活体检测方法,对真假人脸作出判断。近年来,有关人脸活体检测方面的研究发展迅速,取得了许多有价值的研究成果,主要集中在三个方面:基于手工设计特征表达的方法、基于深度学习的方法和基于融合策略的方法[2]。
基于手工设计特征表达的人脸活体检测方法包括基于纹理信息分析的方法[3-5]、基于深度信息的方法[6-7]、基于光谱信息的方法、基于运动信息的方法[8],以及其他方法(如基于热红外图的方法[9]、基于图像质量的方法[10]和基于上下文线索的方法[11]等)。虽然基于手工设计特征表达的方法也可以取得不错的精度,但往往由于特征描述子的层次较低导致模型的泛化能力较弱。
随着深度学习方法广泛地应用于计算机视觉领域,它以数据驱动方式学习到的特征与手工设计特征表达的方法相比更具优势,可以学习到更多一般性特征,以适用于各种欺骗类型,这对于提高算法的鲁棒性和泛化能力都有益。Yang 等[12]首次提出将卷积神经网络(Convolution Neural Network,CNN)用于人脸欺骗检测,文献[13]提出了采用迁移学习的方法,Manjani 等[14]提出的方法针对面具攻击,Gan 等[15]利用三维卷积神经网络(Three-Dimensional CNN,3DCNN)从短视频中提取连续视频帧的时空特征来用于活体检测。值得注意的是,当有大量的训练图像可供训练时,深度学习可以获得更好的效果。
单个信息具有一定的局限性,为了克服单个信息的局限性,弥补单个信息的不足,可以将不同的信息进行融合,这不仅提高活体检测的准确度,而且对于提高算法的鲁棒性和泛化能力也意义重大。Tronci 等[16]提出一种融合纹理信息和运动信息的活体检测方法;Komulainen 等[17]对文献[16]方法加以改进,检测效率进一步得到提升;Wang 等[7]利用深度信息和纹理信息,也取得了很好的效果;Tang 等[18]提出使用CNN从人脸图像的不同信息中学习多个深层特征(包括时间特征、颜色特征、局部特征等)来进行活体检测。
鉴于深度学习算法和融合算法在人活体检测方面表现出的优势,为了满足检测精度和实时性的需求,本文基于轻量化卷积神经网络MobileNetV2 设计一个特征融合算法,在NUAA(Nanjing University of Aeronautics and Astronautics)和Siw(Spoof in the Wild)数据集上进行验证,并与目前最新的算法进行对比,分析其优势和不足。
1 基于MobileNetV2和特征融合的算法
1.1 融合策略
模式分类算法一般基于特征,一种特征一般只对图像部分特性的变化较为敏感,而对其他特性的变化不敏感,如:方向梯度直方图(Histogram of Oriented Gradients,HOG)特征、尺度不变特征变换(Scale-Invariant Feature Transform,SIFT)特征等。当两类图像在某种特征敏感特性上差异不大时,基于单一特征训练的分类器很难给出正确的分类[19]。因此,为了提高活体检测算法的鲁棒性和泛化能力,需要把不同的信息进行融合。常见的融合方法有数据融合、特征融合、分类器融合(决策层的融合)等,这些融合方式分别对应于分类问题的数据预处理、特征提取、分类器设计等环节。融合策略包含一些具体的方法,如图1所示。
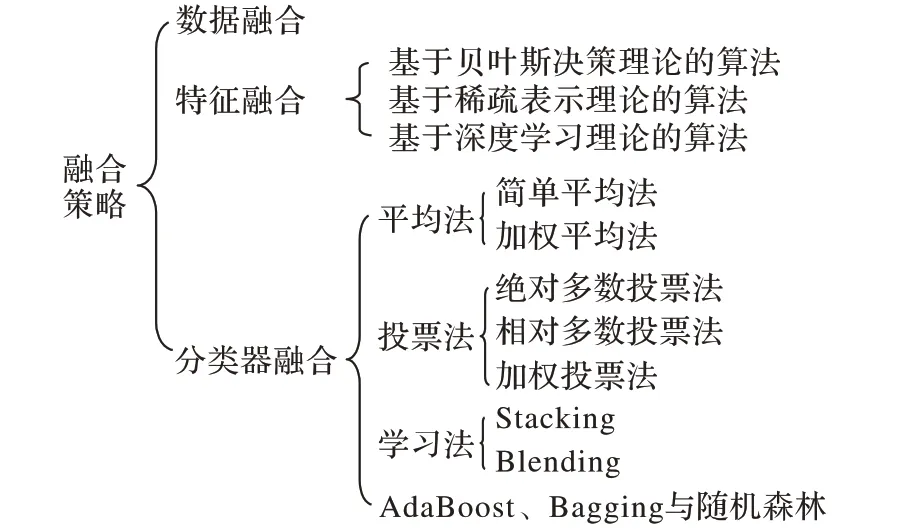
图1 融合方法分类Fig.1 Classification of fusion methods
不同的融合方法具有各自的优缺点。数据融合发生在最底层,优点是保留了原始数据的所有信息,缺点是初始数据中通常含有冗余信息和噪声,不利于计算。数据融合广泛应用于深度学习领域,主要表现在数据集的扩充。分类器融合发生在高层语义层次,算法简单高效,对分类精度和泛化能力有一定的提升,但是高层的融合不可避免地会造成初始数据信息的丢失,具有一定的局限性。特征融合发生在中层,数据特征保留了显著的、必要的信息,既比数据融合降低了原始数据的冗余和噪声,又比决策层的融合有更充分的数据信息,计算量适中。
随着深度学习理论的发展,融合方法变得越来越灵活且易于实现,同时表现出了不错的效果,基于深度学习的融合方法受到越来越多的关注。Feichtenhofer 等[20]提出了空间特征融合算法和时间特征融合算法,不仅可以在Softmax 层融合(决策级融合),还可以在卷积层融合(特征级融合)。
基于上述分析,本文将采用深度学习算法设计特征融合的卷积神经网络,即在卷积层利用级联融合函数将不同的特征图进行融合,以充分利用互补的信息。
1.2 HSV颜色空间
HSV 色系与RGB 色系具有以下不同:1)RGB 色系基于三原色(红、绿、蓝),是一种不均匀的颜色空间;而HSV 色系基于颜色的色调H、饱和度S和亮度V,是一种均匀的颜色空间。2)RGB 空间中的三个分量的相关性较高;而HSV 空间消除了三个分量的相关性,亮度和色度可分离。因此,HSV颜色空间有时更有利于图像处理[21]。图2(a)、(b)展示了RGB 和HSV颜色空间的差异。

图2 RGB图、HSV图与LBP图的例子Fig.2 Samples of RGB,HSV and LBP images
Boulkenafet 等在文献[5]中已经证明了使用HSV 和YCbCr颜色空间的色彩信息比RGB空间的色彩信息在人脸活体检测中更加具有区分性。不同的是文献[5]采用的是手工设计的特征提取和表达的算法,而本文将采用卷积神经网络分别从RGB 和HSV 空间学习高层次的图像特征,进而对真假人脸进行判断。
1.3 LBP算法
局部二值模式(Local Binary Pattern,LBP)由Ojala等[22]提出,用来描述图像局部纹理特征。LBP 算法计算复杂度低且具有灰度不变性和旋转不变性,因而得到了广泛的应用,且出现了不少改进算法。Liu 等[23]对局部二值模式的发展作了详细的调查研究,并对各种LBP算法进行了阐述。
传统的LBP算子具体流程是:在3× 3的窗口内,将周围8个像素点的像素(灰度值)与中心像素点的像素比较:若周围像素比中心像素大,则将该像素点的位置标注为1;反之则将其标注为0。通过这种方式得到8位二进制编码,然后以一定的方式可以得到该中心点的LBP 值,该过程如图3 所示。最后统计图像全部像素点的LBP值即可得到最终的LBP纹理特征,以反映所在区域内的纹理信息。
上述过程可以用公式表示为:
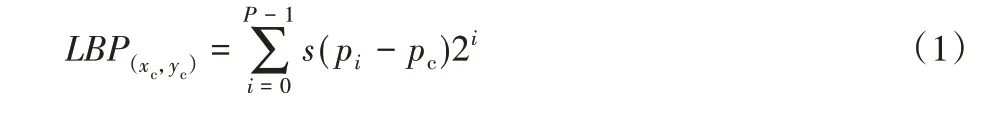
其中:(xc,yc)表示中心;pc表示中心点的像素;pi表示周围点的像素;P表示周围像素点的个数
LBP 算法对光照有较强的稳健性,本文首先从真假人脸的RGB 图像中获取LBP 图像(如图2(c)所示),然后输入CNN,学习更高层次的具有区分性的图像特征,对真假人脸作出判别。
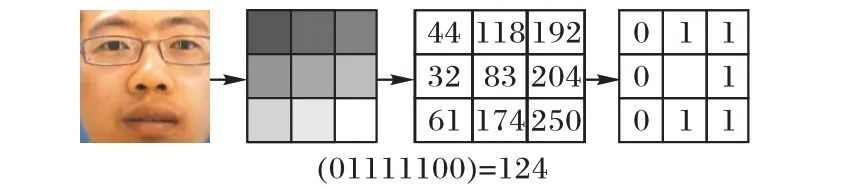
图3 LBP算子的计算过程Fig.3 Calculation process of LBP operators
1.4 MobileNetV2
MobileNetV2[24]是一种轻量化的卷积神经网络,采用的依然是深度可分离卷积[25],主要是在MobileNet[26]的基础上进行两点改进。首先,MobileNetV2借鉴了ResNet[27]的残差结构但又有所不同,具体体现在:在ResNet 中残差块对输入图像先降维、卷积、再升维,而MobileNetV2中残差块则是对输入图像先升维、深度分离卷积、再降维(如图4 所示),这个过程被称作倒残差。深度分离卷积在特征提取过程中通常期望在高维度的输入中进行,倒残差模块的作用是将输入数据变换到高维度后再经过深度分离卷积提取特征,这样能够提高模型的表达能力。其次,ReLU激活函数通常应用于高维空间能够有效增加模型的非线性表达能力,而在低维空间则会破坏特征,而第二个1× 1 卷积用于降维,降维后为了不破坏特征,MobileNetV2 去掉了第二个1× 1卷积后的ReLU 激活函数,这种做法被称为线性瓶颈。
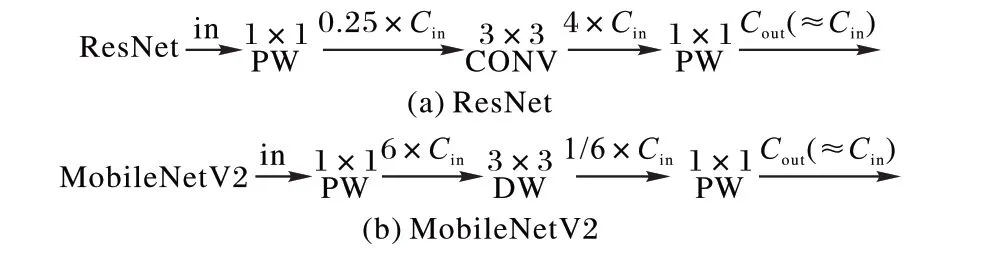
图4 ResNet与MobileNetV2的残差块Fig.4 Residual blocks of ResNet and MobileNetV2
MobileNetV2网络结构的参数如表1[24]所示,其中:Conv2d是标准卷积;bottleneck 是由卷积层组成的倒残差块;Avgpool是平均池化;t表示第一个1× 1卷积对通道数“扩张”的倍数;c 表示输出通道数;n 表示残差块重复的次数;s 表示重复的残差块中第一个残差块中深度卷积的步长;k 表示分类的类数。该网络中间各层用于提取特征,最后一层用于分类。
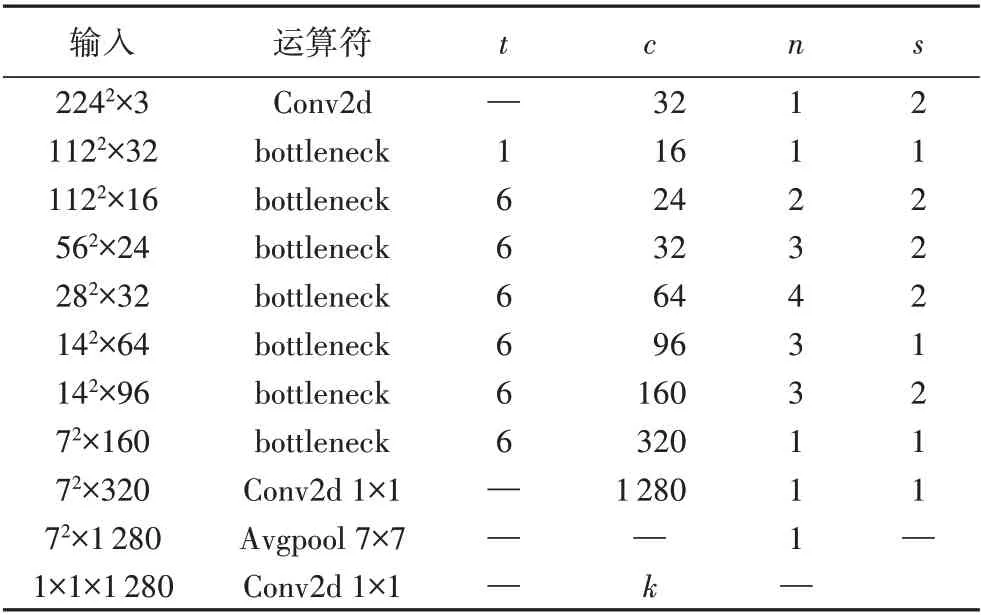
表1 MobileNetV2结构[24]Tab.1 Architecture of MobileNetV2[24]
1.5 本文算法
为了确保人脸活体检测的准确性、实时性和泛化能力,网络结构的确定是重中之重。影响网络结构的因素有很多,如卷积层的个数、输入图片的尺寸等。MobileNetV2虽然在多分类问题上体现出了良好的性能,但在二分类问题上的性能还需要验证,而且特征融合后的MobileNetV2参数量和运算量也会增多,不利于实时性的需求。因此,针对人脸活体检测的实际需求,以MobileNetV2模型为基础网络,对其结构进行微调,并加入特征融合思想,设计一个适用于人脸活体检测的轻量化网络模型十分有必要。
首先需要确定单路卷积网络的输入尺寸和卷积层数量。本文基于MobileNetV2 的结构,设计了一个“瘦身”后的网络(其结构如表2 所示),并以NUAA 数据集上80%的数据作为训练集,另20%的数据作为测试集来验证微调后的模型性能。实验的对比结果如表3所示。
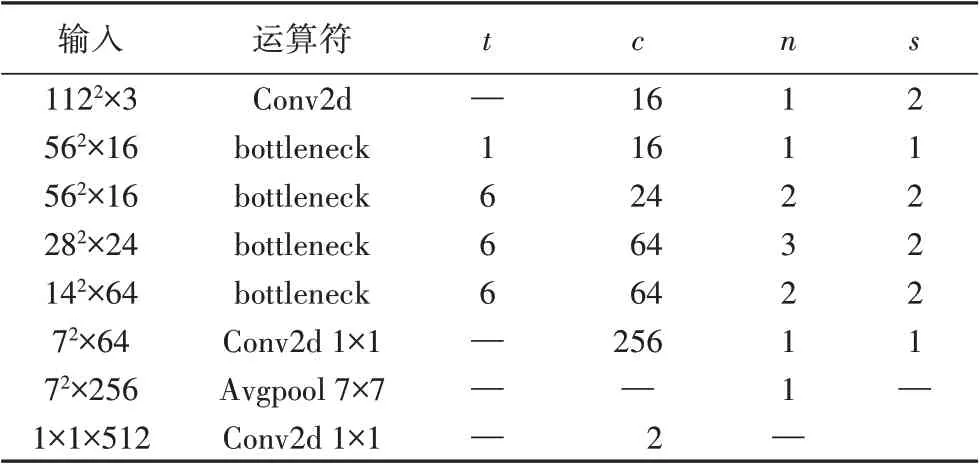
表2 微调后的MobileNetV2结构Tab.2 Architecture of fine-tuned MobileNetV2

表3 MobileNetV2与微调后的网络在NUAA数据集上的性能对比Tab.3 Performance comparison between MobileNetV2 and improved network on NUAA dataset
由表2 可知,“瘦身”后的结构与原始的MobileNetV2 相比,卷积层减少了很多。在表3 中:等错误率(Equal Error Rate,EER)反映人脸活体检测的错误率水平;浮点运算次数(FLoating point Operations Per second,FLOPs)可以理解为计算量大小,参数量和FLOPs 用来衡量模型的复杂度。由表3可知,“瘦身后”的结构在参数量和计算量都大量减少的同时,模型的性能基本上没有变化,因此本文将采用微调后的网络结构,并加入特征融合思想,设计用于人脸活体检测的模型,网络结构如图5所示。
利用bottleneck1 和bottleneck2 分别从RGB 图、HSV 图和LBP 图中提取特征,将各自的特征图堆叠在一起进行特征层的融合,然后利用bottleneck3 和bottleneck4 从融合后的特征图中进一步提取具有区分性的信息,最后经过卷积层和Softmax 层,给出真假人脸的判断。通过特征层的融合,可以充分利用上述三种信息,克服单一信息的不足,而且有助于提高模型的准确率和泛化能力。MobileNetV2属于轻量级网络,在保证其性能的同时,较少的运算量使其能够实时在嵌入式平台运行。
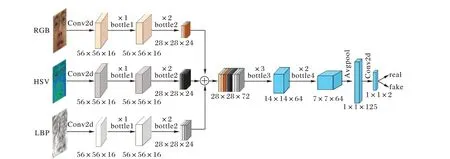
图5 融合算法结构Fig. 5 Structure of fusion algorithm
2 实验与结果分析
2.1 数据集
NUAA 数据集是被公认为第一个公开的用于人脸活体检测的数据集,该数据集由南京航空航天大学Tan 等[28]于2010年发布。该数据集包含15 个人的照片数据,使用普通的摄像头分三次采集得到。该数据集包括丰富的外观变换,如光照、性别、有无眼镜等。在真实图像捕获期间,为了使真实图像和打印的照片图像更相似,志愿者被要求正面直视摄像头,保持自然表情,且没有明显的移动(如眨眼和头部移动等)。在欺骗图像制作期间,首先利用佳能相机为每个志愿者拍摄高清照片,印刷在相纸上(共三种:6.8 cm×10.2 cm、8.9 cm×12.7 cm的相片纸和普通A4纸上打印的彩色照片),然后在摄像头下模拟如下五类攻击手段:
a)水平和垂直的进行前后移动;
b)沿垂直轴旋转照片;
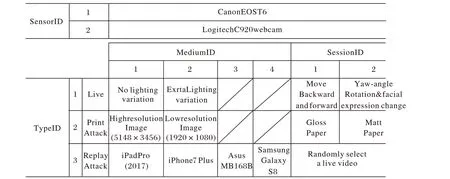
图6 Siw数据集的采集方式Fig.6 Collection mode of Siw database
c)沿水平轴旋转照片;
d)沿垂直轴弯曲照片;
e)沿水平轴弯曲照片。
NUAA 数据集共采集了3 491 张真实图像和9 123 张欺骗图像,且每张图像保存大小为640 × 480。
随着传感器技术的进步,现有的反欺骗系统可能容易受到新兴的高质量欺骗介质的影响。使系统对这些攻击具有鲁棒性的一种方法是收集新的高质量数据集。为了满足这一需求,Liu 等[29]收集了一个命名为Siw 的人脸反欺骗数据集。该数据集提供了165 个人的真实和欺骗视频。对于每个志愿者,有8 个真实和最多20 个欺骗视频,总共4 478 个视频。所有视频均为30 frame/s,长度约为15 s,1 080P HD 分辨率。真实视频分为四个场景,包括距离、姿势、光照和表情的变化。欺骗攻击视频包括多种形式的照片攻击和视频攻击。具体采集格式如图6所示。
Siw 数据集不仅在个体数以及活体人脸的变化方面丰富了数据集,而且提供了三个测试协议:协议1 旨在评估模型的基本性能,要求用训练视频的前60 帧训练模型,并测试所有测试视频。协议2 旨在评估相同欺骗类型(视频攻击)下的泛化能力,采用留一法的策略:在三个重放媒体上训练并在第四个上进行测试,记录四个分数的均值和标准差。协议3 旨在评估未知欺骗攻击时的性能,从照片攻击中选择数据进行训练,从视频攻击中选择数据进行测试,反之亦然。
2.2 评价标准
错误接受率(False Acceptance Rate,FAR)表示欺骗人脸图像中预测为真实人脸的概率;错误拒绝率(False Rejection Rate,FRR)表示真实人脸图像中预测为欺骗人脸的概率;等错误率(Equal Error Rate,EER)表示利用验证集数据进行测试得到的ROC 曲线上FAR 和FRR 相等时的值;半错误率(Half Total Error Rate,HTER)表示以验证集上FAR 等于FRR时的阈值为测试集上的阈值计算测试集上FRR 与FAR 的均值。为了与其他实验结果进行对比,本文在NUAA 数据集上的实验采用的指标为EER。
Siw数据集上提供的协议中使用的是另一套评价指标,来自于生物识别防假体攻击方面的标准文件ISO/IEC 30107-3[30],包 括APCER(Attack Presentation Classification Error Rate)、BPCER(Bona Fide Presentation Classification Error Rate)、ACER(Average Classification Error Rate),定义如下:
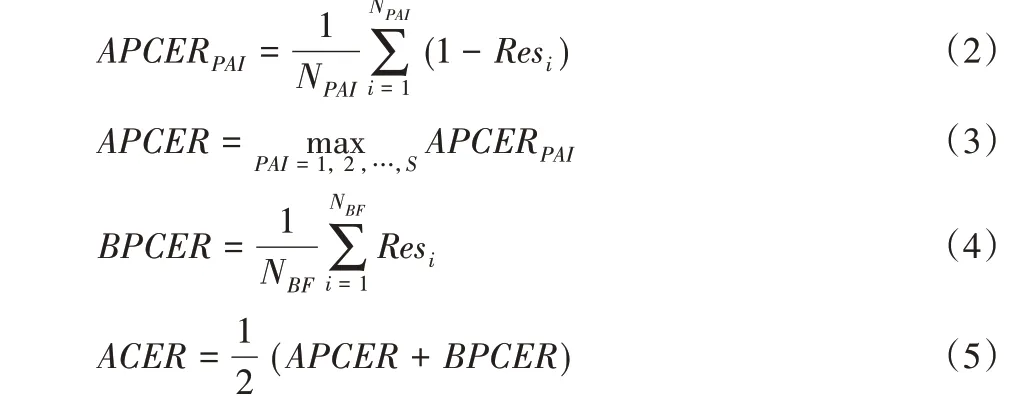
其中:NPAI表示第PAI类欺骗攻击的攻击次数;S表示欺骗攻击的类别数;NBF表示活体人脸检测的次数;APCERPAI表示第PAI类欺骗攻击的错误识别率;APCER 表示所有类别的欺骗攻击中最大的错误识别率。若第i 次检测判断为假体人脸,则Resi为1;若判断为活体人脸,则Resi为0。为了与其他实验作对比,本文在Siw数据集上的实验也将采用这套指标。
2.3 实验设置及结果
本文人脸数据集在使用人脸检测算法从视频中提取的过程中已经对齐,网络中输入的HSV 图和LBP 图为112×112 的RGB 图转换得到,故不需要再作对齐处理,batchsize 设置为10;反向传播的优化算法采用随机梯度下降(Stochastic Gradient Descent,SGD)算法,学习率设为0.000 1,衰减率为0.000 5;实验使用tensoflow-gpu 1.10.0,keras 2.2.2搭建的环境进行训练和测试,硬件设备的处理器为Inter Core i7-8700 CPU@3.2 GHz,内存为16.0 GB.
1)实验一。
为了验证特征融合的有效性,在NUAA 数据集上测试单特征、两特征融合和三特征融合的性能。首先分别单独输入RGB 图、HSV 图和LBP 图,验证单特征的性能,然后与两特征融合和三特征融合的结果作对比。以NUAA数据集上80%的数据作为训练集,另20%的数据作为测试集,实验的对比结果如表4所示。
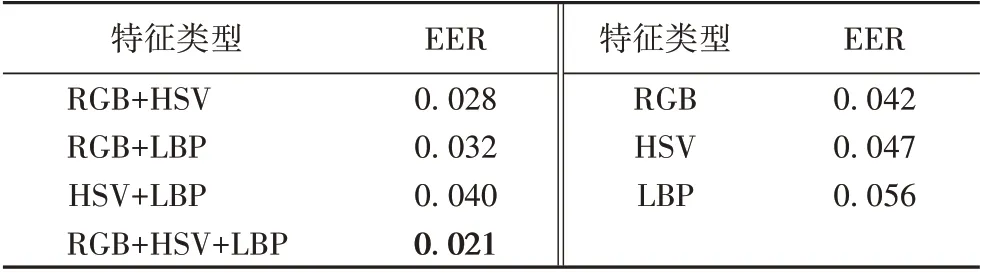
表4 不同特征在NUAA数据集上的EER对比 单位:%Tab.4 EER comparison of different features on NUAA database unit:%
实验结果表明,RGB颜色信息、HSV颜色信息和LBP纹理信息都可以用于活体检测,其中RGB 信息的效果最好;两特征融合比单特征取得了更好的结果,三特征融合比两特征融合取得了更好的结果,从而说明了融合不同的特征信息可以克服单一信息的不足,能有效地提高活体检测的准确率,降低错误率。
2)实验二。
为了验证本文提出的基于深度学习和特征融合算法的有效性,利用本文方法在NUAA 数据集上测试,并与其他一些代表算法对比,实验对比结果如表5所示。
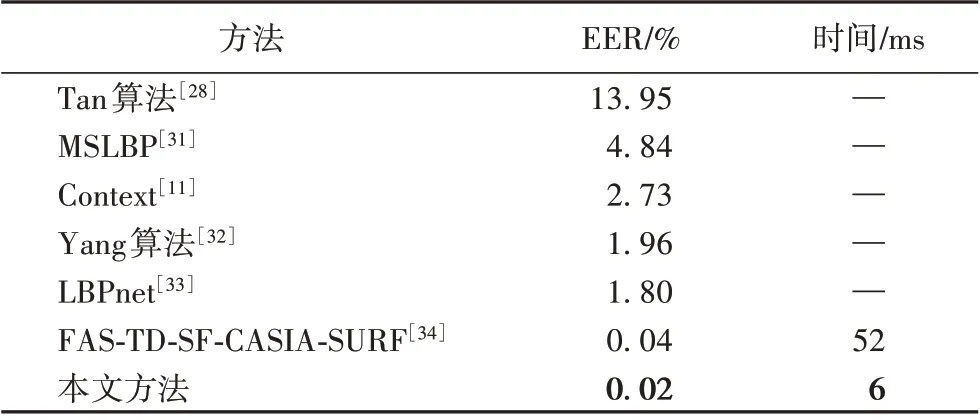
表5 与其他方法在NUAA数据集上的性能对比Tab.5 Performance comparison with other methods on NUAA database
实验结果表明,基于MobileNetV2的特征融合方法在人脸活体检测方面表现出了不错的效果,更重要的是本文设计的网络在检测单张人脸图像时所使用的时间仅为6 ms,在实际应用时具有不可比拟的优势。
3)实验三。
为了验证本文算法在复杂数据集上的性能以及在同一个数据集上的泛化能力,利用本文方法在Siw 数据集上测试,并与其他方法(包括特征融合方法)作对比,实验对比结果如表6所示。
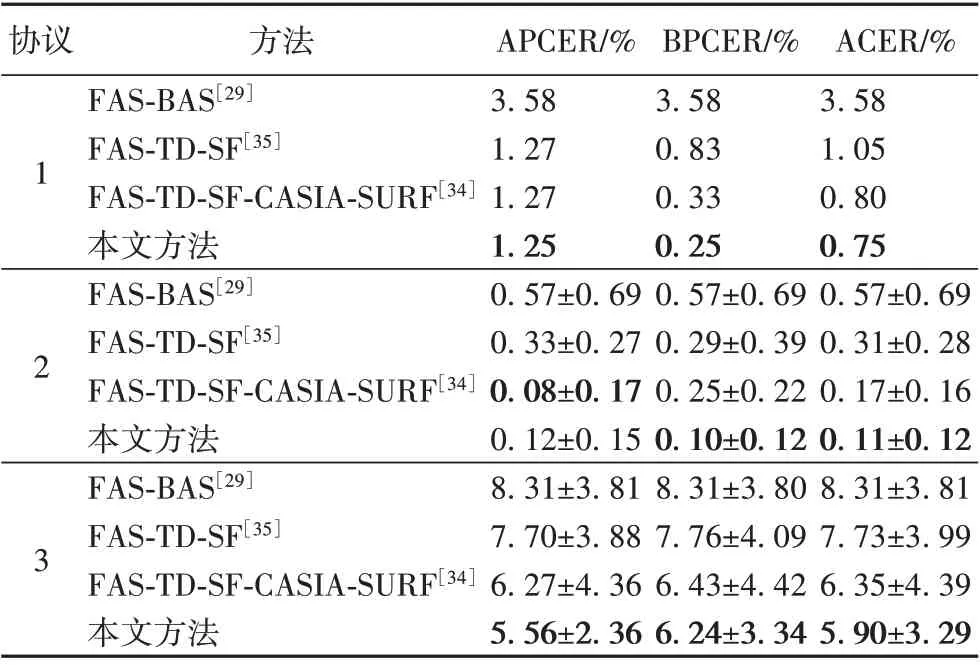
表6 与其他方法在Siw数据集上的性能对比Tab.6 Performance comparison with other methods on Siw database
上述结果表明,在复杂的数据集下,基于MobileNetV2 的特征融合方法在人脸活体检测方面同样表现出了很好的性能。MobileNetV2借鉴了ResNet的短路连接思想,每个支路可以提取得到充分的特征信息,再融合不同支路的特征信息无疑会进一步提高检测准确率。文献[34]采用的是基于ResNet-18 和特征融合的方法,与其结果相比,本文算法获得了更优的结果,同时MoboleNetV2 使用了深度分离卷积,计算量较文献[34]方法减少了很多,速度更快。从协议2和协议3的实验结果来看,基于MobileNetV2的特征融合算法的泛化能力同样经得起考验。
4)实验四。
为了进一步验证本文算法在跨数据集训练和测试时的泛化能力,进行跨数据集测试。实验包括两个方案,方案1 是指在NUAA 数据集上训练,在Siw 数据集上测试;方案2 是指在Siw数据集上训练,在NUAA 数据集上测试。本文算法与其他算法的对比结果如表7所示。

表7 跨数据集测试EER对比 单位:%Tab.7 EER comparison of inter-test between NUAA and Siw datasets unit:%
为了验证算法的通用性,跨数据集测试是一个不错的途径:以一个数据集的数据训练模型,以另一个数据集的数据测试模型的性能。目前大部分的跨数据集测试大都在同类别欺骗攻击的数据集上测试,对于跨数据集、跨欺骗攻击类别的测试还比较少。本文做了NUAA 和Siw 两个数据集上跨数据集测试的实验,从表7 可知,跨数据集测试的结果并不理想,而且以NUAA 为训练集以Siw 为测试集的结果最差,原因是NUAA 数据集过于简单,包含的欺骗攻击手段比较单一,训练的模型在复杂的数据集上测试时效果较差,这也说明了建立一个大规模包含多模态欺骗攻击手段数据集的必要性。另一方面,为了提高算法跨数据集测试时的性能,有必要对融合算法作进一步的研究。
3 结语
人脸识别系统容易受到欺骗攻击,给系统的安全性能带来挑战。如何设计一个检测精度高、耗时短、鲁棒性强、泛化能力强的人脸反欺骗系统成为目前的研究热点。本文基于轻量级网络MobileNetV2 设计了一个用于人脸活体检测的特征融合算法,并在NUAA 和Siw 数据集上进行了验证,该方法都表现出了很好的性能,同时轻量化的网络为移动端的嵌入使用提供了可能。
随着深度传感器越来越多的应用于移动设备,基于RGBD 图像的人脸识别和活体检测算法值得进一步的研究,在设备允许的条件下,把本文方法中的LBP图替换为深度图,理论上可以取得更好的结果。本文作者接下来将进一步研究融合深度信息的活体检测算法;同时在特征融合算法、分类器融合算法、轻量化网络设计等方面也将深入研究。
猜你喜欢
模式识别与人工智能(2022年9期)2022-10-17
计算机研究与发展(2022年1期)2022-01-19
少儿美术·书法版(2021年9期)2021-10-20
文萃报·周五版(2021年4期)2021-09-13
奥秘(2021年5期)2021-06-15
华人时刊(2020年21期)2021-01-14
课外生活(小学1-3年级)(2018年2期)2018-02-10
米娜·女性大世界(2016年8期)2016-08-17
文苑(2015年9期)2015-09-10
奇闻怪事(2014年5期)2014-05-13
