
基于小波分析的a-多样性k-匿名大数据自适应延迟调度算法
2020-05-29 06:32:54程正兴
吉林大学学报(理学版) 2020年3期
王 慧, 程正兴
(1.南阳理工学院 师范学院, 河南 南阳 473000; 2.西安交通大学 数学与统计学院, 西安 710049)
在网络信息存储空间中, 大量的个人数据通过云存储和分布式网络数据库方式存储在网络系统中, 因此需对大数据进行数字化整合与分析[1].许多数据持有者以去除识别字段等方式公布微观数据, 导致客户隐私泄露.在噪声干扰环境下对数据信息进行调度, 易使资源发生蜕变, 导致调度的自适应均衡性能较差.利用小波分析对数据进行去噪, 结合构建a-多样性k-匿名[2]大数据自适应延迟调度模型[3], 可防止个人隐私泄密, 对提高网络用户的隐私保护具有重要意义.
k-匿名大数据自适应延迟调度算法主要通过泛化和抑制实现k-匿名处理, 调度模型有能量均衡调度模型、优先级列表a-多样性分布式调度模型、负载均衡调度模型[4]、基于神经网络控制的a-多样性k-匿名大数据自适应延迟调度模型等.上述方法通过构建大数据时间序列的循环堆栈控制信息列表, 采用数据信息融合方法进行任务分配调度和负载均衡设计, 调度效果较好.文献[5]提出了一种延迟传输调度算法, 通过检测相邻节点传播延迟及其预期信息进行传输调度, 降低了节点暴露冲突的可能性, 提高了通信无线自组织网络吞吐量, 该算法可显著提高整体吞吐量, 有效处理由物理位置和传播延迟引起的空间不公平性, 但该模型在进行数据调度的敏感属性表征方面具有延迟性, 且计算的开销较大.文献[6]提出了一种延迟满足的路由选择和调度更新方法, 从控制平面路径选择和数据平面的更新调度两方面联合优化, 降低路由更新的延迟, 路径选择阶段只选择部分数据流进行路由更新, 更新调度阶段通过建立更新关系图挖掘数据流的更新先后顺序, 进一步加快调度速度, 但该调度方法在受到较大信息特征干扰影响下的调度性能较差.
为提高大数据调度控制的准确性, 本文提出一种基于小波分析的a-多样性k-匿名大数据自适应延迟调度算法, 并通过仿真实验进行性能测试.实验结果表明, 该方法在提高a-多样性k-匿名大数据自适应延迟调度性能方面具有优越性.
1 算法设计
为提高大数据环境下a-多样性k-匿名调度的性能, 首先需采用小波分析方法对调度数据进行消噪处理, 得到去噪后的数据, 并将其用于a-多样性k-匿名大数据自适应延迟调度优化算法上, 结合动态变化的资源及通信信息特征, 通过特征提取进行大数据调度的优先级列表控制.
1.1 基于小波分析的数据去噪方法
小波变换[7]具有较强的数据相关性去除功能, 可将数据信号的能量在小波域内集中在一些大的小波系数中, 而噪声能量却分布于整个小波域内.经小波分解后, 信号的小波系数幅值要大于噪声的小波系数幅值, 幅值较大的小波系数一般以信号为主, 而幅值较小的系数很可能是噪声信号.因此, 选择合适的阈值对小波系数进行阈值处理, 可将信号系数保留, 从而使大部分噪声系数减少至零, 达到去噪的目的.
基于小波分析的去噪方法[8]需基于阈值去噪原理, 根据变换系数阈值处理方法, 将信号小波变换系数的绝对值与阈值比较, 小于阈值的小波系数变为零, 大于阈值的小波系数不变, 再根据小波系数进行信号筛选.基于小波分析的消噪算法步骤如下:
1) 选择小波和小波分解的层数i, 计算含噪声信号的小波分解系数;
2) 对每层系数选择一个阈值, 并用阈值处理高频系数;
3) 根据第i层的低频系数和从第一层到第i层的高频系数, 计算信号的小波重构.
阈值处理的数学表示为

(1)
其中:λ表示阈值;Ri表示小波系数;Rik表示处理后的小波系数.将处理后的小波系数作为信号系数保留条件对数据进行筛选, 最终筛选结果为去噪后数据.
1.2 构建a-多样性k-匿名大数据自适应延迟调度机制体系
基于上述步骤获取去噪后的数据, 减少无效数据的干扰, 在此基础上, 对a-多样性k-匿名大数据进行调度, 调度方法主要采用纵向和树形网络结构进行时隙控制, 如图1所示.
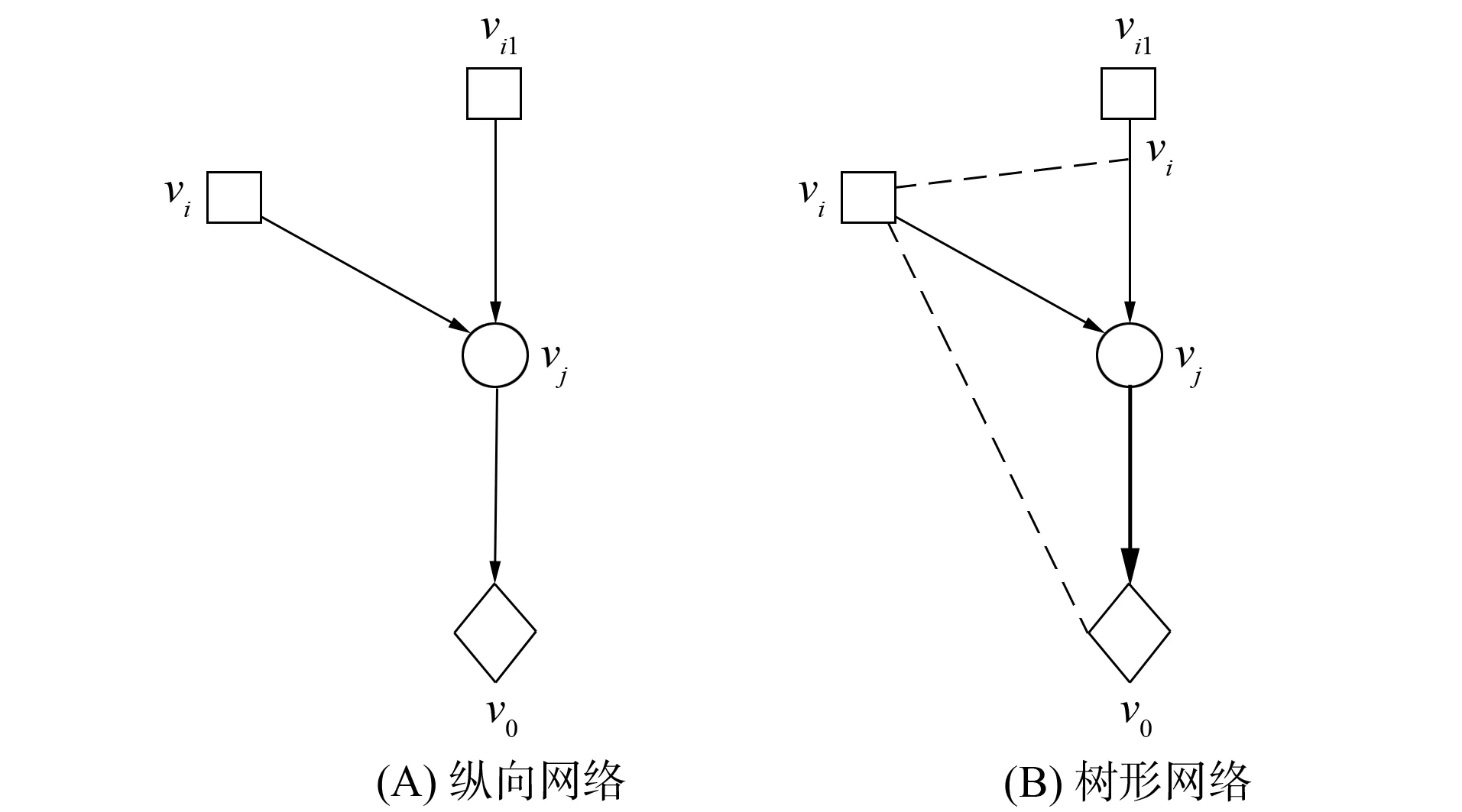
图1 a-多样性k-匿名大数据调度的网格结构模型Fig.1 Grid structure model of a-diversityk-anonymity large data scheduling

flowk={n1,n2,…,nq},q∈N,
(2)
其中:q表示簇头节点上的差异性特征函数;nq表示匿名数据集资源的传输单元数据序列;N表示调度任务总数.基于k-匿名保护模型, 在大数据环境中, 调度任务延迟相对差的方差为
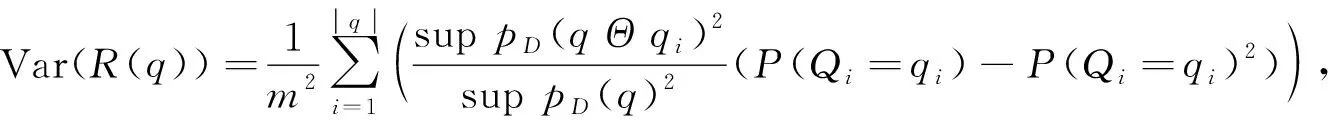
(3)
其中Var(R(q))与|q|之间呈线性关系, 随数据属性值组合|q|的增大而增大.
定理1[9]假设a-多样性k-匿名大数据库λ在每条调度信息记录中匿名属性的个数具有一致性.令q∈D,q′∈D′,q和q′是准标识符(QI)的时分多址协议的时间窗口子集|q|=|q′|≤m, 具有时滞相关性, 则P(q→q′)和P(q′→q)的自相关分布响应随λ的增大而增大.
假设a-多样性k-匿名大数据自适应延迟差异性特征q和q′相差η个属性,η≤λ.令AttrSetη+k(i=1,2,…,k,k≤|q|-η)为(η+k)个k-匿名保护模型的准标识符, 其中q为QI的敏感门限均衡控制属性集.令P(AttrSetη+k,q′)为(η+k)个时间轴划分的均匀窗口, 则属性集q′的传递概率为
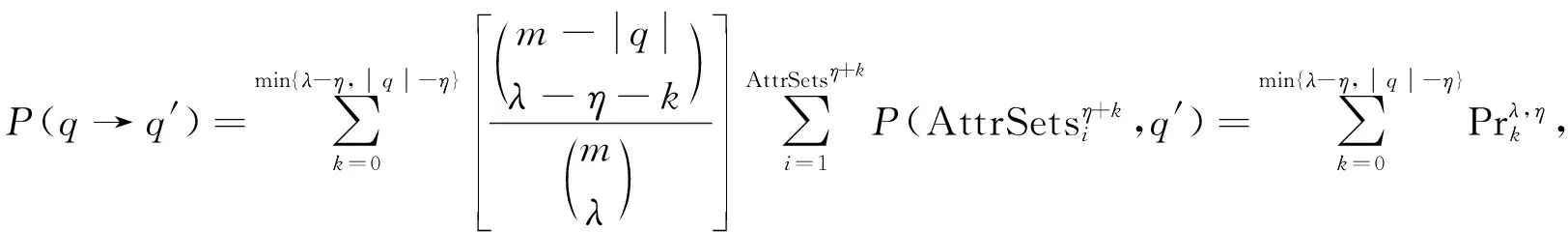
(4)

(5)
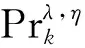

(6)

1.3 优先级列表控制
a-多样性k-匿名大数据自适应延迟调度的优先级列表控制模型由一个簇首、若干个协同簇首和分簇成员组成, 优先级列表控制的结构模型如图2所示.

图2 优先级列表控制的结构模型Fig.2 Structure model of priority list control
设a-多样性k-匿名大数据进程管理的测试集为pi, 执行大数据延迟调度任务nj所能获得的优先级属性DR(pi,nj)定义为
DR(pi,nj)=rwdik×PET(pi,nj),
(7)
式(7)描述了a-多样性k-匿名大数据自适应延迟调度的a-多样性输入控制参量, 采用调度任务之间传输时间的差异性进行延迟均衡处理, 利用PET(pi,nj)表示调度任务pi的时间窗口函数.根据属性优先级列表控制[11], 设M是d维列表的循环堆栈控制参数, 对于Φ:M→2d+1, 大数据自适应延迟调度的时隙节点分配特征空间满足
Φ(z)=(h(z),h(φ1(z)),…,h(φ2d(z)))T.
(8)
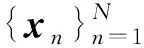
xn=(x(0),x(1),…,x(N-1))T.
(9)
计算大数据自适应延迟调度分簇节点与sink节点的差异性, 进行分簇节点[12]的紧密性度量, 则a-多样性k-匿名大数据调度的相对关联特征函数为

(10)
其中:A表示尺度幅度值; delay(v)表示大数据调度的延迟.在时间段T内,a-多样性k-匿名大数据属性为rk的随机变量集具有自相关性, 得到优先级列表控制模型为

(11)
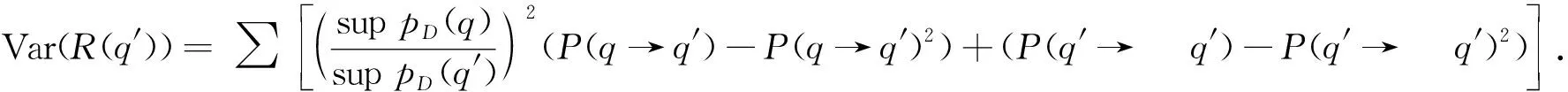
(12)
根据上述优先级列表控制, 改变λ值进行分簇调度的均衡性控制.
2 改进调度算法
2.1 负载均衡传输的信道模型
在大数据调度优先级列表控制模型构建的基础上, 进行大数据调度算法的改进设计, 提出一种a-多样性k-匿名大数据[13-15]自适应延迟调度算法, 采用高效时分多址协议进行a-多样性k-匿名大数据的负载均衡传输信道模型设计.通过时隙分配, 第i时刻传输分簇调度单元的负载满足:
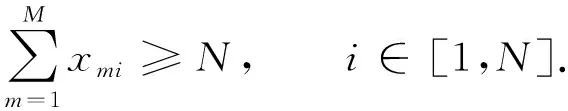
(13)
此时,a-多样性k-匿名大数据调度模型中能量分配控制函数满足:
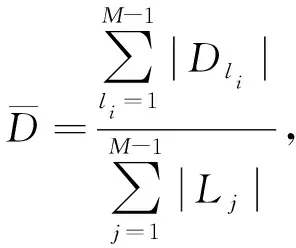
(14)
其中Dli为时隙分配控制的紧密性度量参量, 通过前导时隙分配, 将数据传输中继节点划分为k个数据子集, 得到a-多样性k-匿名大数据调度中的高效时分多址协议表达式为
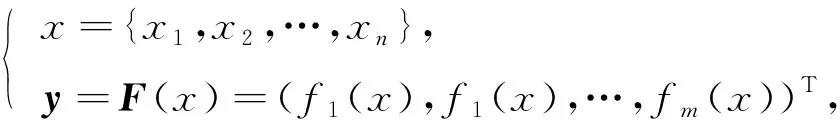
(15)
其中:x={x1,x2,…,xn}为分布式协同分簇单元集合;y=F(x)表示p-敏感属性函数.假设初始微观数据表的属性集ni的种类为rj, 则标识符属性采样集P(ni)={pk|Prkj=1,k=1,2,…,m}, 通过最小密度的冗余节点覆盖和信息重组, 得到数据调度过程中的负载均衡传输为

(16)
高效时分多址协议控制的适应度函数为
fij=wtδt+wcδc+wqδq+wsδs,
(17)
其中wt+wc+wq+ws=1.由此构建负载均衡传输的信道模型, 在此基础上进行自适应延迟调度设计.
2.2 自适应延迟调度实现
在采用高效时分多址协议进行a-多样性k-匿名大数据[16]负载均衡传输的信道模型设计基础上, 结合自适应加权控制方法进行大数据自适应延迟调度的控制目标函数构建, 公式为
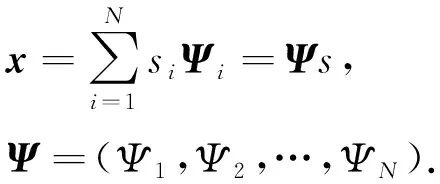
(18)
采用任务开销的最优化建模方法, 对大数据分配任务节点i进行延迟调度的时间窗口加权控制, 加权函数为

(19)
其中: {c1,c2}为最小执行开销系数; {r1,r2}为时间代价函数;w为惯性系数.在节点链路中进行自适应权重系数调整, 加权系数的更新机制为

(20)
通过时隙分配进行延迟调度目标函数的时间窗口和尺度参数的最优化求解, 则大数据自适应延迟调度的优化控制模型为

(21)
其中:dmean(t)为时隙分配的阈值均值;dmax(t)为时分多址时隙分配的最大跳数;k为信道均衡分配的取值因子.此时, 大数据自适应延迟调度的执行开销[17]为
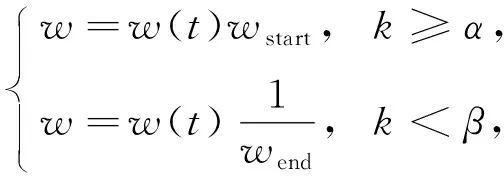
(22)
信道的利用率为

(23)
其中{α,β}为第m个时隙发送调度任务执行任务的指向性函数, 通过时隙分配进行延迟调度的时间窗口和尺度参数的最优化求解, 由此实现调度算法的改进设计.
3 仿真实验测试分析

图3 a-多样性k-匿名大数据时域波形Fig.3 Temporal waveform of a-diversityk-anonymous large data
为测试本文算法在实现a-多样性k-匿名大数据自适应延迟调度中的性能, 进行仿真实验.仿真实验建立在MATLAB 7仿真环境中, 用NS-2.27和NS软件进行a-多样性k-匿名大数据信息流模拟, 用随机函数发生器生成大数据信息, 采样的样本长度为1 024, 共用10个数据集进行实验, 选择a-多样性k-匿名大数据调度的相对误差
及数据召回率为测试指标, 进行数据调度仿真实验分析, 其中Ans(query,D)和Ans(query,D′)分别表示数据调度规模测得的测量值和真实值.得到采样的大数据信息流如图3所示.
以上述采样的数据集为测试样本, 结合自适应加权控制方法进行大数据自适应延迟调度的控制, 通过时隙分配进行延迟调度目标函数的时间窗口和尺度参数的最优化求解.为对比性能, 用文献[5]和文献[6]算法与本文算法进行对比, 以数据调度的相对误差和数据召回率为测试性能指标, 得到不同算法的调度性能对比结果如图4和图5所示.由图4和图5可见, 采用本文算法进行a-多样性k-匿名大数据调度, 通过自适应延迟调度, 有效降低了数据调度的相对误差, 误差收敛到零, 数据召回率远高于文献[5]和文献[6]算法, 证明了本文方法的优越性能.

图4 不同算法数据调度的相对误差Fig.4 Relative error of data scheduling by different algorithms

图5 不同算法调度数据召回率对比Fig.5 Comparison of recall rate of scheduling data by different algorithms
综上所述, 针对k-匿名大数据调度问题, 本文提出了一种基于小波分析的a-多样性k-匿名大数据自适应延迟调度算法.首先利用小波分析对数据进行去噪处理, 构建大数据自适应延迟调度的优先级列表控制模型; 然后采用高效时分多址协议进行a-多样性k-匿名大数据的负载均衡传输的信道模型设计, 结合自适应加权控制方法进行大数据自适应延迟调度的控制目标函数构建, 通过时隙分配进行延迟调度的时间窗口和尺度参数的最优化求解, 实现调度算法改进设计.实验结果表明, 采用本文方法进行a-多样性k-匿名大数据调度的自适应均衡性能较好, 准确控制的品质较高, 数据的召回率等技术指标优于传统方法, 具有较高的应用价值.
猜你喜欢
小学生学习指导(高年级)(2024年4期)2024-05-07 03:28:46
科技风(2021年19期)2021-09-07 14:04:29
小学生学习指导(中年级)(2021年4期)2021-04-27 10:14:56
课堂内外(初中版)(2020年5期)2020-06-19 08:11:11
电子制作(2019年13期)2020-01-14 03:15:32
铁道通信信号(2018年9期)2018-11-10 03:26:46
制造技术与机床(2017年10期)2017-11-28 05:20:43
舰船电子对抗(2016年3期)2016-12-13 05:15:55
广西大学学报(自然科学版)(2016年5期)2016-11-12 06:28:54
计算机工程(2014年10期)2014-06-07 05:53:21
