
基于自注意力机制的中文标点符号预测模型
2020-05-18 11:08段大高梁少虎赵振东韩忠明
计算机工程 2020年5期
段大高,梁少虎,赵振东,韩忠明
(北京工商大学 计算机与信息工程学院,北京 100048)
0 概述
汉语是当今世界上最主要的语言之一,全球有超过15亿人使用汉语。在汉语书面语中,标点符号是不可缺少的组成部分,是辅助文字记录语言的符号,用来表示停顿、语气以及词语的性质和作用,它可以帮助人们确切地表达思想感情和理解书面语言。在语音转化文本的过程中,没有添加标点符号,或者只是依据时间停顿来添加特定的标点符号,这样不符合标点符号规范,因此标点符号预测(Punctuation Prediction,PP)是一项重要的自然语言处理任务。标点符号预测指利用计算机对文本进行标点符号添加,使文本符合标点符号使用规范。
标点符号预测问题最初工作主要集中在语音识别领域,标准的语音识别系统识别出的序列既没有将输出正确地分割为句子,也没有标点符号。经语音识别系统识别后的文本没有标点符号和句子边界,带来许多理解上的问题,因此,在实际应用中,对长文本进行分割,添加标点符号是必要的。标点符号预测问题吸引了语音处理领域和自然语言处理领域学者的关注,研究人员利用统计模型中的局部特征进行预测,如词汇、韵律特征和隐藏事件的语言模型(HELM)[1-2]。HELM对于输入用一个较小窗口的采样,这样由于上下文信息有限而不能达到满意的性能[3]。对于标点符号预测,研究全局的上下文信息是必要的,尤其是长期依赖关系,已有研究试图合并语法特征拓宽标点符号预测的视野[4]。
基于循环神经网络(Recurrent Neural Networks,RNN)的标点符号预测模型技术取得了一定的进展,但由于标点符号预测任务需要对输入文本结构进行信息提取,而RNN不适用于处理树状结构的输入。为解决该问题,本文提出一种基于自注意力机制的多层双向LSTM标点符号预测模型DABLSTM。
1 相关研究
近年来,基于文本的标点符号预测逐渐获得人们的关注,文本的标点预测不能提取声学方面的信息,需要寻找其他的特征。文献[5]基于英文文本特征,在断句中将标点插入句子。文献[6]将标点符号进行分类,提出了一种自动提取表示句末标点的线索词方法。文献[7]为了解决线索词的“远程依赖”问题,使用F-CRF模型,同时选取词级别特征和句子级别特征。以上方法在英语文本中取得了较好的效果,但在中文文本中效果并不理想,部分原因在于中文标点符号种类更多,较为复杂多变,中文线索词的提示性并不十分准确。只利用浅层的词法特征并不能体现中文标点符号的应用特点,因此一些学者尝试更深层次的句法特征。为了在标点预测中融合更深层的句法特征,文献[8]以网络文本为测试语料,融合多种特征,训练CRF模型,缺点是局限于特征的设计,当特征维度大时,容易出现过拟合现象。以上基于规则、统计以及传统机器学习模型的性能依赖于特征的选择,模型的输入是基于人为设定的特征。
神经网络具有优异的建模能力,不需要人工构建特征工程,被广泛地应用于序列标注问题上。文献[9]将神经网络模型应用到自然语言处理(NLP)。由于标点符号类别有限,中文分词任务可以看作序列标注问题,因此中文分词模型也可以应用于PP。文献[10]提出了基于神经网络的中文分词模型。文献[11]使用LSTM神经网络来解决中文分词任务,一定程度上解决了传统神经网络无法长期依赖信息的问题。传统的单向LSTM神经网络只能处理过去的上文信息,中文句子结构复杂多变,有时需要结合下文的信息才能做出判断。文献[12]提出了一种双向LSTM-CRF模型,并用在序列标注问题上,取得了理想的效果。文献[13]把中文分词和标点符号预测任务用双向LSTM网络同时训练,得到分词和标点符号预测模型。但是由于分词标注的数据集过小,难以扩展到实际文本应用中。
本文提出一种基于自注意力机制的多层双向LSTM标点符号预测模型DABLSTM,模型基于自注意力机制,直接提取输入的全局依赖关系,相比RNN,自注意力的优点是直接提取输入文本任意两个位置的关系。因此,远程关系可以通过直接的路径解决(自注意力机制中任意两个词的距离总是1),而远程关系对于标点符号预测是有帮助的。自注意力还可以提供更灵活的方式选择、表示和综合输入信息。双向LSTM网络增加了模型的表征能力,DABLSTM模型同时利用LSTM和自注意力机制,捕获文本序列重要信息,联合学习文本词性与语法信息,实现准确的中文标点符号预测。
2 Bi-LSTM序列标注模型


图1 Bi-LSTM序列标注模型结构
3 DABLSTM标点符号预测模型
本文基于Bi-LSTM,提出DABLSTM模型,即深度自注意力双向LSTM模型,其框架如图2所示。

图2 DABLSTM神经网络模型结构
DABLSTM主体堆叠N个相同的子层,每个子层由一个Bi-LSTM层和Self-Attention层堆叠。最上层是一个Softmax标签预测层构成,如图2所示,相比通用的Bi-LSTM模型,DABLSTM模型添加了自注意力层,可以跨位置提取词之间的关系,有很强的表征句意信息。模型堆叠多次,网络更深,充分提取了句意信息来预测标点符号,实验结果表明了改进DABLSTM模型是有效的。
3.1 标点符号标注集
本文把标点符号标签分为13个类别,如果一个词的直接后继是某个类别的标点符号,则把此词标注为对应标点符号的标签,如果一个词的直接后继不是标点符号,则把此词标注为标签“0”,标点符号标签集如表1所示。

表1 标点符号标签集
在表1中,标签“1”表示逗号,标签“2”表示句号,“无”表示无标点符号……“$”表示段落结束标志。
3.2 自注意力层
自注意力机制是Google团队[14]在2017年提出的编码序列方案,它与一般的RNN、CNN同样都是一个序列编码层。自注意力机制是一种特殊的注意力机制,它只需要单独的序列来计算此序列的编码,自注意力在很多NLP任务中表现优异。文献[15]把自注意力机制应用在中文阅读理解任务上取得了较好的效果。文献[16]把注意力机制应用在方面级别情感分类问题上,实验结果显示了方面级别注意力机制的有效性。文献[17]提出一种融合注意力机制对评论文本深度建模的推荐方法,通过仿真实验验证了注意力机制的有效性。
本文采用文献[14]提出的多头注意力机制,图3所示为多头注意力机制的计算过程。

图3 多头注意力机制计算过程
(1)
其中,d是网络隐藏层神经元数,Softmax()为非线性激活函数。
(2)
最后,将所有并行计算出的头拼接成一个矩阵。同样一个线性映射用来从不同的头混合不同的通道:
M=Concat(head1,head2,…,headn)
(3)
Y=MW
(4)
自注意力机制和RNN或CNN相比具有很多的优势。首先,它从根本上解决了远程依赖问题,任何位置的输入和输出的距离为1,而在RNN中可能是n(输入序列长度)。与CNN相比,自注意力不局限于固定窗口的大小,它可以学习序列任意两个位置的关系信息。其次,自注意力机制使用加权和计算产生输出向量,它的梯度传播比RNN或者CNN更容易,不会出现RNN梯度弥散或膨胀问题。最后,点乘注意力可以高度并行,矩阵乘法可以在GPU上优化,而RNN由于递归机制难以并行处理。
3.3 位置编码层
自注意力机制不能处理序列位置信息,因此对输入序列向量位置信息编码是极为重要的。位置编码有很多方式可以训练得出位置向量,也可构造位置编码得出位置向量,本文使用文献[14]提出的位置编码方式:
(5)
其中,表达式将编号为p位置映射为一个k维位置向量,向量的第i个元素数值为PEi(p)。
3.4 Bi-LSTM层
自注意力通过加权和得到输出向量,有着很强的表征序列能力,但不能表示序列顺序信息,循环神经网络(RNN)[20]在近些年来被广泛应用于语音识别和自然语言处理领域。文献[21]使用循环神经网络对天气等时间序列进行预测,相比传统方法预测准确度有很大提升。文献[22]提出一种基于双向LSTM的结构识别方法,对流式文档进行结构识别,实验结果表明双向LSTM具有更好的识别效果。RNN这种基于时间序列的循环计算方式使得模型能够捕捉输入序列中长距离的特征信息,具有十分强大的信息记忆能力。由于RNN适用的时间序列与文本序列有着相同的特性,因此RNN网络相对于其他深度学习模型更适用于文本处理。在RNN中,每个处理单元在t时刻的隐藏状态均由其外部输入xt和上一时刻的隐藏状态ht-1共同决定,表示如下:
(6)
然而这种强大的记忆能力在模型的训练过程中会导致梯度消失和梯度爆炸问题,一个简单的RNN并不能有效处理序列的长距离依赖关系。为了解决该问题,一种RNN的变体长短时记忆网络(LSTM)[23]应运而生。LSTM神经网络模型通过引入门机制和细胞状态来解决长期依赖问题。
LSTM网络能够按需要决定模型对于历史信息所要记忆的长度,但该模型中默认序列最后元素所记忆的信息最多,因此序列最后元素占有较重要地位。而序列标注问题要求序列中每个单元都应是平等的,因此本文采用双向LSTM(Bi-LSTM)作为基础模型。Bi-LSTM包含了输入序列中来自双向的信息,正向LSTM捕获了上文的特征信息,而反向LSTM捕获了下文的特征信息,所以相对单向LSTM来说能够获取到更多的序列信息,因此在通常情况下,Bi-LSTM的表现比单向LSTM或者单向RNN要好。
给定输入序列向量{xi},Bi-LSTM分别以正向、反向方向处理输入序列,然后通过两个方向表示的向量之和来得到输出向量:
(7)
(8)
(9)
3.5 输入层
本文采用三类特征作为模型输入:词向量,词性向量,句法向量。通过对词向量、词性向量、句法向量联合学习,可以得到多模态的语义句法信息,对标点符号预测有提高作用。
输入层由三部分构成:
1)词向量和位置编码,词向量是用word2vector工具在搜狗新闻语料库上预训练得到[24],词向量包含当前词的语义信息,本文中词向量维度设置为300。按照上文给出的编码方案把位置信息编码为位置向量维度为300,然后将词向量和位置向量加和作为网络部分输入。
2)词性向量,表示当前词在语义环境中的词性,可以是名词、动词、形容词与副词等,由于标点符号大多出现在名词后,因此将词性作为模型的输入特征之一。
3)句法向量,表示当前词在语境中的句法作用,包括主语、谓语、宾语等,句法信息对提升标点符号预测有巨大提升作用。将词向量和位置向量加和后的词性向量、句法向量拼接在一起作为网络的最终输入。
4 实验结果与分析
4.1 数据集
本文实验采用以下两个数据集:
1)搜狐新闻数据(SogouCS)版本,此数据集包含来自搜狐新闻 2012年6月—7月期间国内、国际、体育、社会、娱乐等18个频道的新闻数据,数据集大小为648 MB。
2)当代文学作品50部,数据集大小为58 MB。首先对两个数据集依据标点符号标注规则进行标注,过滤掉在标注集之外的标点,然后以去除标点符号得到纯文本序列X和相对应的标签序列Y作为训练数据。按照8∶2的比例把数据集划分为训练集和测试集,实验结果在测试集上得到。
在对中文标点符号预测任务中,使用分类问题的评价指标精确度(Precision)、召回率(Recall)和F1值来评价模型整体性能,以F1值作为主要评价指标。
4.2 实验设计
在实验中,使用分词工具HanLP对文本进行分词处理、DABLSTM神经网络进行实现,使用python3.6和深度学习框架TensorFlow 1.50来构建深度网络。所用工作站参数:CPU为Inter Core i7 6800K,GPU为Nvidia GTX1080Ti图形处理卡,操作系统为Ubuntu16.04。

表2 实验参数设置
将网络深度N设置为7,即有7层重复的非线性子层,输入词向量维度K设置为300,位置编码维度Posi_d设置为300,LSTM相关模型输入长度Len_LSTM设定置为100,即在网络输入层有100个LSTM处理单元,LSTM输出维度LSTM_d设置为200,多头注意力Head设置为4。通过在词嵌入层和自注意力层添加Dropout[25-26]层来使隐藏层节点不工作,增强网络的泛化能力,丢弃率Drop_prob设置为0.2。采用随机梯度下降法来优化网络参数,训练的Batch_size设置为64。具体地,本文采用Adadelta[27]作为参数优化器。
4.3 实验结果
本文为探究网络结构、自注意力机制对实验结果的影响,分别进行两个实验。
实验1为了验证DABLSTM网络模型的优越性,首先将本文模型与传统CRF、LSTM、Bi-LSTM模型分别在搜狗新闻数据和当代文学数据两个数据集上进行对比实验,如表3所示。

表3 4种模型的识别性能对比
本文对比实验模型介绍如下:
CRF:模型使用的特征包括线索词、句型特征、句法特征及主题词特征。
LSTM:传统的LSTM网络,将PP问题看作序列标注问题,模型的输入包括词向量和位置向量。
Bi-LSTM:双向LSTM网络,将PP问题看作序列标注问题,模型的输入包括词向量和位置向量。
DABLSTM:深度自注意力双向LSTM网络,有多个子层堆叠而成,每个子层包括一个双向LSTM层一个自注意力层,模型的输入包括词向量和位置向量。
实验2为了验证自注意力机制在解决序列长期依赖的有效性,在DABLSTM网络中用前馈网络层代替自注意力层,前馈网络层定义为:
FFN(X)=f(XW1)W2
(10)
其中,W1、W2为可学习的参数矩阵,f()为非线性激活函数,本文选用RELU。
为研究位置向量编码对自注意力机制影响,本文做了对比实验,在网络结构超参数都相同的情况下,一组输入为词向量与位置向量的加和,另一组输入仅为词向量。为确定网络深度是否能够提高评价指标,设置了不同的网络深度N,为探究隐藏层神经元个数即网络宽度对评价指标的影响,进行了对照实验。以上实验都是在新闻数据集上,用搜狗新闻语料库训练的300维词向量进行的对比实验。不同参数对比结果如表4所示。
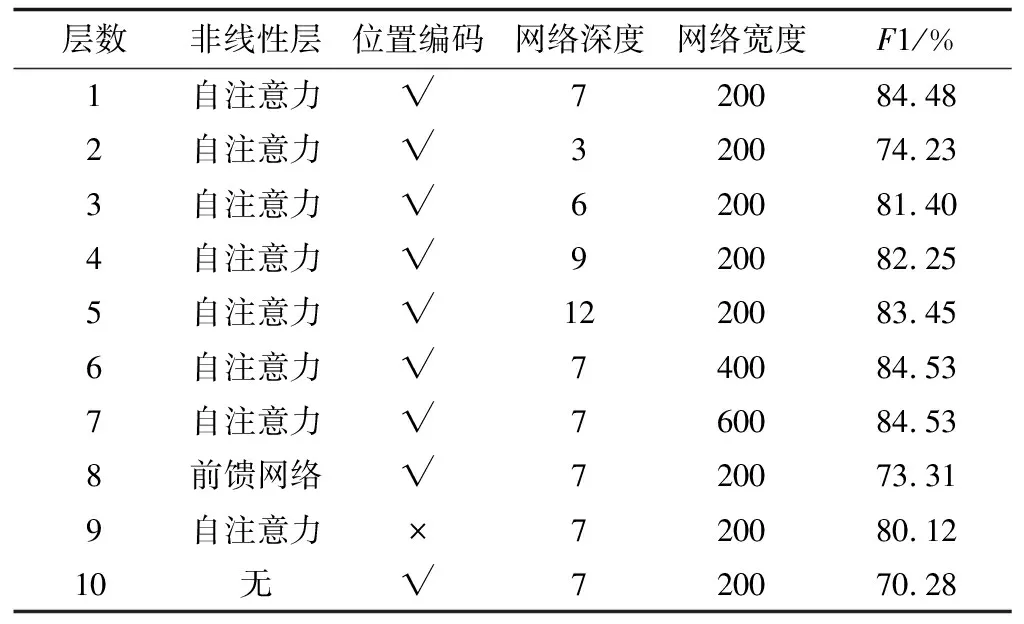
表4 不同参数对比结果
在表4中,√表示自注意力层可以捕获序列的位置信息,×表示自注意力层不能捕获序列的位置信息。
4.4 结果分析
通过表3可以看出,在两个不同的数据集上,本文的DABLSTM网络模型在精确度、召回率和F1值上均是最优的,尤其是召回率和F1值,这是由于深度神经网络能够编码更多的潜在语义信息。纵观深度模型,Bi-LSTM在两个数据集上的F1值分别高于LSTM模型4.73%和4.87%,这是因为在LSTM网络中添加双向连接能够使模型学习到句中双向的语义信息,从而给模型带来更佳的预测结果。
1)网络深度的影响:通过表4的第1行~第5行可以看出,随着网络深度的增加,模型的效果增强显著,这也验证了文献[28-29]的工作,即深度是网络表征能力的关键。从第3层增加到第6层,效果提升9.6%比较显著,从第6层增加到第9层效果有较小提升,而在增加到一定层数后,再增加层数反而效果下降,原因是当模型太深时反向传播算法梯度难以传导,使用随机梯度优化参数的方法效果就要打折扣,另一部分原因是网络参数量大,出现了过拟合现象。对于深度网络难以训练问题,可以采用添加残差模块[29],跨层传导梯度来解决,这也是模型改进的方向,对于网络过拟合问题,可以在损失函数中引入参数正则化,这也是模型另一个改进的方向。对比第1、6、7行可以看出,网络宽度从200增加到400、600,网络提升并不显著。因此,网络的深度比宽度对模型的提升更有效。
2)自注意力的影响:通过表4的第1、8行可以看出,当自注意力层替换为前馈网络层时,模型F1相对下降13.2%,而当去掉自注意力层时,模型F1相对下降16%,这一结果充分证明了自注意力层的必要性和有效性,它是对Bi-LSTM的必要补充,从根本上解决了序列的长期依赖问题(任意两个位置距离为1)。
3)位置编码的影响:通过表4的第1行和9行看出,当输入没有编码位置信息时,模型F1值相对下降5.1%,可以看到位置信息对模型的重要性,不难理解,自注意力层不能捕获序列的位置信息,所以在词向量中融合位置信息会有较大提升,位置编码总是伴随自注意力。
5 结束语
本文建立一种基于自注意力机制的中文标点符号预测模型DABLSTM。通过自注意力机制构建DABLSTM网络,提取文本添加标点的信息,根据对词的词性信息和句法信息进行联合学习,利用词的词法信息和句法信息预测标点符号。实验结果表明,对比传统的CRF模型和Bi-LSTM模型,DABLSTM模型在中文标点符号预测上取得了较好的效果,大幅提升了预测正确率。DABLSTM网络是Bi-LSTM网络的增强,对序列标注问题有较好的建模能力,下一步将对该模型进行泛化能力验证,以避免出现过拟合现象。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
小雪花·成长指南(2022年1期)2022-04-09
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
小读者(2020年4期)2020-06-16
传媒评论(2017年3期)2017-06-13
快乐语文(2017年12期)2017-05-09
小学生必读(低年级版)(2017年12期)2017-03-08
第二课堂(课外活动版)(2016年2期)2016-10-21
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
