
基于集成DE-NRS的肺部肿瘤影像组学计算机辅助诊断模型
2020-05-16 06:45任海玲霍兵强
计算机应用与软件 2020年5期
任海玲 周 涛,2,3* 霍兵强
1(宁夏医科大学公共卫生与管理学院 宁夏 银川 750004)2(宁夏医科大学理学院 宁夏 银川 750004)3(宁夏智能信息与大数据处理重点实验室 宁夏 银川 750021)4(北方民族大学计算机科学与工程学院 宁夏 银川 750004)
0 引 言
据2018年世界卫生组织下属国际癌症研究机构(IARC)发布的《全球癌症报告》[1]:肺癌是人类发病率及死亡率最高的癌症,对人类的生命健康造成巨大威胁。医学影像是肺部肿瘤诊断的重要参考依据,能为肺部肿瘤良恶性识别等提供全面的评估信息,辅助医生提高肺部肿瘤良恶性识别精度。其中,CT[2]通过血管的对比造影清晰地显示纵隔和肺门部的解剖结构,能够精确定位病灶及显示病灶细微结构变化;PET采用正电子核素作为示踪剂,通过病灶部位对示踪剂的摄取了解病灶功能代谢状态,可以从分子水平反映全身各脏器功能、代谢等病理特征[3];PET/CT[4]将CT解剖成像和PET功能成像进行融合,能够全面发现病灶,精确定位及判断病灶良恶性。
粗糙集理论(rough set,RS)是波兰学者Pawlak[5]提出的处理不精确、不一致数据的工具,它能够基于各类数据本身所提供的信息利用等价关系、上下近似等对知识进行划分,具有优良的知识提取和属性约简能力。经典粗糙集利用绝对等价关系对知识进行获取,容错性差。变精度粗糙集[6]通过引入分类错误率β,具有一定的容错能力,但仅凭人的经验来指定某个值,具有随机性。贝叶斯粗糙集[7]、决策粗糙集[8]等RS扩展模型对错误率进行了泛化,具有客观性。但是,以上粗糙集模型都只能处理离散数据,对于现实生活生产存在的连续型数据不能直接处理。在医疗、金融、科研等领域,如基于医学影像图像的计算机辅助诊断领域,存在着大量连续型数据,包括属性约简处理的诸如粗糙度、周长、面积、方差、均值等。通常的解决手段是采用离散化算法把数值型转换为离散型[9],但数据的转换会导致其信息的丢失,而计算处理的结果很大程度上取决于数据转换的效果。针对上述问题,文献[10]基于邻域粒化和粗糙逼近,提出了邻域粗糙集(Neighborhood Rough Set ,NRS),可以直接处理连续型数据,且具有一定的容错能力。近年来,徐久成等[11]提出一种基于邻域粗糙集和粒子群优化的特征基因选择算法;王效俐等[12]为提高医疗决策的效率和有效性,建立了邻域粗糙集融合贝叶斯神经网络的组合医疗决策模型,对智能医疗行业的发展有重要意义。
差分进化(Differential evolution,DE)算法[13]是解决实值变量问题的有效算法之一,群体搜索与协同搜索相结合,具有结构简单易于使用的优点[14]。集成学习[15]通过一定的规则生成多个具有同性质且又存在差异的个体学习器,然后采用某种集成策略整合所有个体学习器的预测结果,最后综合判断并获得比单个个体学习器更为客观、准确的预测结果。
本文首先以肺部肿瘤医学影像组学[16]为基础,结合DE与NRS算法,分别搭建了属性约简模型(CT-DE-NRS、PET-DE-NRS、PET/CT-DE-NRS);其次,利用SVM分类器分别对三个单一属性约简模型得到的属性约简结果进行肺部肿瘤良恶性识别准确率检测;最后采用相对多数投票决策策略整合三个SVM个体分类器的预测结果,从而得到较为客观的肺部肿瘤良恶性识别预测结果。
1 基础知识
1.1 差分进化算法
DE是一类基于种群的启发式全局搜索技术,具有原理简单、受控参数少、对于连续型参数的优化有较好的鲁棒性等优点[17]。首先,从初始化种群中随机选择两个个体向量进行差分处理得到差分向量;其次,差分向量对第三随机目标向量进行扰动得到变异向量;然后,变异向量与目标向量进行杂交得到试验向量;最后选择目标向量和试验向量中较优者保存在下一代群体中,即:初始化、变异、交叉、选择。
1.2 邻域粗糙集
Pawlak[5]提出的RS以离散数据为研究对象,对于连续型数据需先进行离散化预处理,而经离散化后的数据存在信息丢失问题。邻域粗糙集利用邻域关系代替等价关系,有效地避免了数据离散化对数据精准性的影响。基本定义如下:
定义1 邻域。给定决策信息系统DS=(U,C,D,V,F),论域U={x1,x2,…,xn},条件属性集C={c1,c2,…,cn},决策属性D={d1,d2,…,dn},∀B⊆C,∀xi∈U,xi的B邻域δB(xi)表示如下:
δB(xi)={xj|xj∈U,ΔB(xi,xj)<δ}
(1)
式中:ΔB(xi,xj)用于计算xi与xj之间的距离,表示对象xi与xj之间的相似程度;Δ表示对象属性距离的计算函数。常见的距离计算函数是曼哈顿距离函数,如下:
(2)
式中:f(xi,ak)表示xi的第i个属性的值;N表示属性个数;xi的B邻域是指在论域U中,所有与xi之间距离小于邻域大小δ的样本集合。
定义2 邻域的上、下近似。任意样本子集X⊆U,X在B上的上近似和下近似如下:
(3)
(4)
由此得出X的边界域BN(X)为:
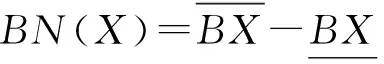
(5)
依据经典粗糙集定义规则,X的下近似定义为正域,与X完全无关的域为负域,即:

(6)
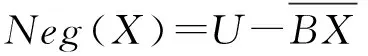
(7)
定义3 邻域决策系统的上近似和下近似。给定邻域决策信息系统NSD=(U,C∪D),决策属性D将论域U划分为N的等价类(X1,X2,…,Xn),∀B⊆C,则决策属性D关于子集B的上、下近似分别为:
(8)
(9)
式中:
(10)
(11)
同样可以得到邻域决策系统的边界域为:
(12)
邻域决策系统的正域和负域分别为:
(13)
(14)
决策属性D对条件属性C的依赖度为:
(15)
由式(15)可得依赖度KD是单调的,若B1⊆B2⊆…⊆A,λB1(D)≤λB2(D)≤…≤λA(D)。
属性ci在属性集C相对于决策属性D的重要度可定义为:
SIG(ci,C,D)=rC(D)-rC-{ci}(D)
(16)
定义4 相对约简。邻域决策系统NDS=(U,C∪D),B⊆C,如果满足以下条件,则称属性子集B是C的一个相对约简。
(1)rB(D)=rC(D),即PosB(D)=PosC(D),子集B与C具有相同的分类能力。
(2) ∀C⊆B,rB(D)>rB-{c}(D),属性子集B中没有冗余属性。
1.3 集成学习
集成学习[18]通过一定的规则生成多个具有同性质且又存在差异的个体学习器,然后采用某种集成策略整合所有个体学习器的预测结果,最后综合判断并获得比单个个体学习器更为客观、准确的预测结果,且在大多数情况下可以显著提高学习系统的泛化能力。
2 诊断模型构建
2.1 模型算法流程
首先获取肺部CT、PET、PET/CT医学影像图像;其次,对图像进行病灶区(region of interest,ROI)截取与分割预处理;再次,对预处理后的图像进行特征提取,形成CT、PET、PET/CT特征库;然后,基于DE与NRS构建属性约简模型,得到CT、PET、PET/CT特征子集;基于SVM分类器模型,搭建肺部CT、PET、PET/CT个体分类器;最后,采取相对多数投票准则对三个个体分类器做集成学习,得到该模型的最后结果。具体模型流程如图1所示。
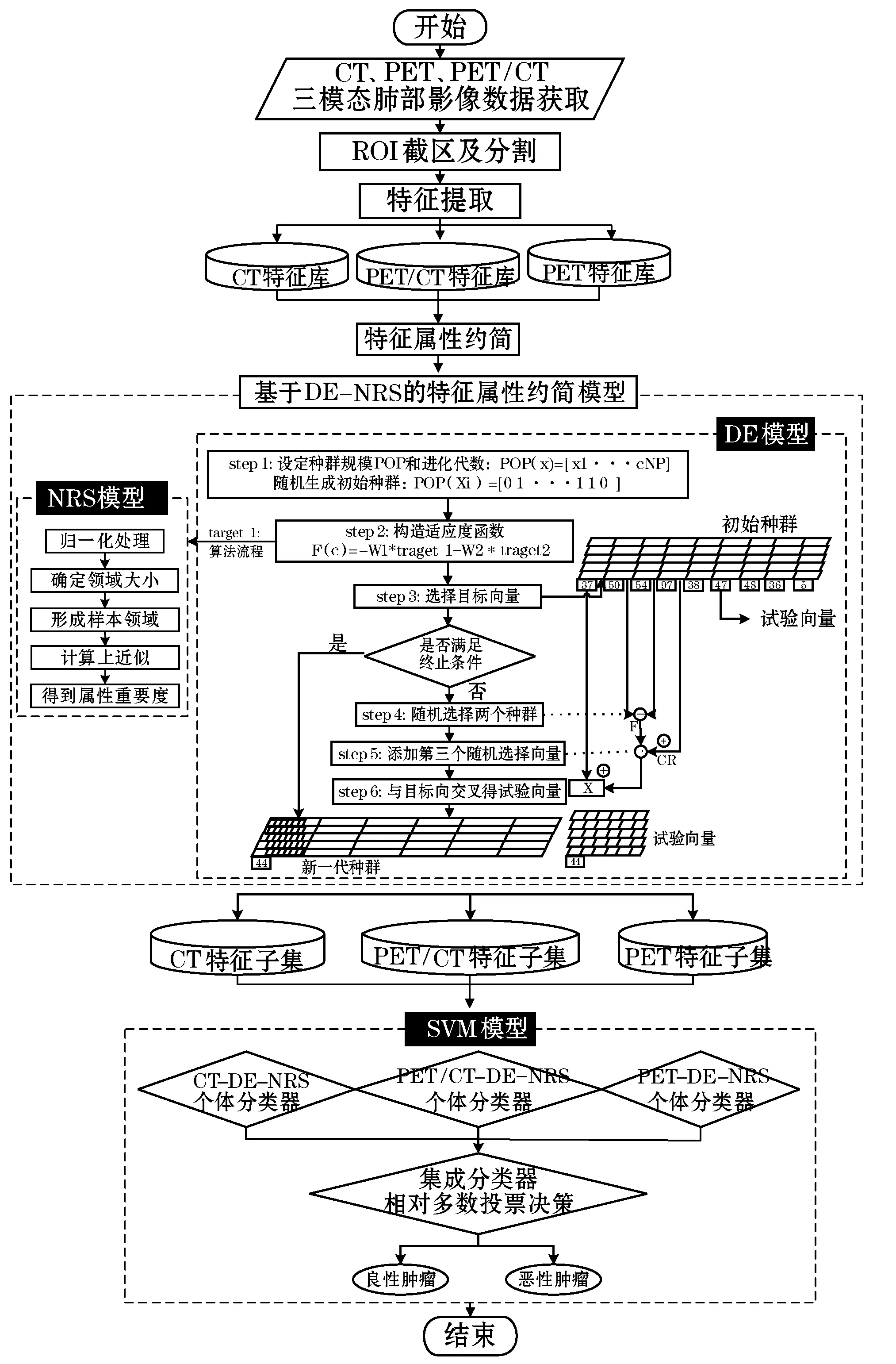
图1 本文功能流程图
2.2 诊断模型算法实现
2.2.1 算法步骤
Step 1 获取数据。从宁夏某三甲医院获取带有良恶性标记的肺部肿瘤患者的肺部CT、PET、PET/CT影像图像各3 000例,其中:良性1 500例,恶性1 500例。
Step 2 ROI截取。以同一患者的三模态(CT、PET、PET/CT)医学影像图像为研究样本,将具有较强区分能力的子图处理为50×50像素的ROI区域。
Step 3 图像分割。为准确测量肺部肿瘤的周长、面积、纹理等特征,选择不受图像对比度和亮度影响且具有准确、稳定优点的OTSU算法对ROI区域进行图像分割预处理。肺部肿瘤CT、PET、PET/CT医学影像图像分割前后的对比如图2所示。
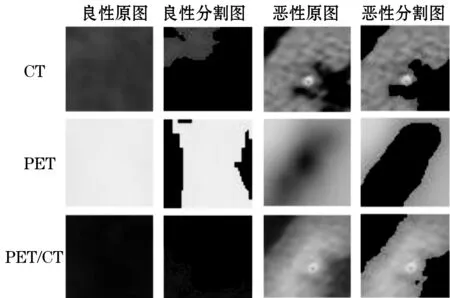
图2 分割前后的对比如图
Step 4 特征提取。对分割后的肺部肿瘤CT-ROI、PET-ROI、PET/CT-ROI进行形状、角点、Hu矩阵、小波、统计、几何、灰度共生矩阵等特征的提取,其中:CT和PET/CT分别共提取104维条件属性特征和1维决策属性特征;PET是功能成像,难以提取周长、面积等几何特征,故共提取98维条件属性特征和1维决策属性特征。基于肺部肿瘤三模态医学影像图像的特征提取集合见表1。

表1 CT、PET、PET/CT三模态肺部影像特征集合
Step 5 基于DE与NRS的属性约简。属性约简的基本思想是在不影响决策信息系统的分类和决策能力条件下,删除其中不相关或不重要的属性,得到最优属性约简子集。基于经典粗糙集的属性约简算法是通过绝对等价关系对知识进行处理,容错性差;经典粗糙集只能处理离散数据,不能处理本文的连续型数据。基于以上原因,本文结合DE与NRS进行属性约简,降低特征属性的维度,提高分类学习算法的性能,简化数据描述和避免过拟合。具体步骤如下:
(1) 设定种群规模和进化代数:本文种群规模520,进化代数取值200。
(2) 随机生成初始种群:随机生成NP个初始种群。
(3) 构造适应度函数:合理且有效的适应度函数决定DE搜索方向和进化结果的好坏,适应度值是判断个体性能的重要指标。本文从属性重要度和约简数量两方面考虑,构造适应度函数进行DE寻优,找到最优属性约简子集,适应度函数为:
F(x)=-w1×target1-w2×target2
(17)
式中:target1=SIG(ci,C,D)是基于NRS计算的属性重要度;target2=(|C|-|Lr|)/|C|,|C|表示由0、1构成的条件属性个数,|Lr|表示条件属性中值为1的个数。适应度函数值越小越好。
(4) 变异:变异操作使用差分策略,即从初始化种群中随机选择两个个体向量进行差分处理得到差分向量,再利用差分向量对第三随机目标向量进行扰动得到变异向量。例如对目标向量σ的变异操作:从当前种群中随机选择三个向量xr1(t)、xr2(t)、xr3(t),对其中两个向量的差值进行缩放,并与第三个向量相加得到一个变异向量Vi(t):
Vi(t)=xr1(t)+F(xr2(t)-xr3(t))
(18)
式中:F为DE的缩放因子,取值范围为[0,1]。
(5) 交叉:差分进化算法中的杂交算子采用目标向量和变异向量进行操作:
(19)
式中:j∈{1,2,…,D};rand[0,1]是[0,1]之间的随机数;CR是交叉概率,取值范围[0,1]。
(6) 选择:DE的选择策略是一种基于贪婪的选择机制。若试验向量ui(t) 的适应度值优于目标向量Vi(t)的值,则保留到下一代种群,否则保留Vi(t)。
Step 6 基于DE-NRS构造个体分类器。将上述基于DE、NRS得到的属性约简结果, 基于三个模态(CT、PET、PET/CT)肺部肿瘤医学影像图像构成的样本空间建立三个相对独立的DE-NRS个体分类器(CT-DE-NRS、PET-DE-NRS、PET/CT-DE-NRS)。
Step 7 基于DE-NRS的集成学习计算机辅助诊断模型。采用相对多数投票法集成三个DE-NRS模型得到的肺部肿瘤识别结果。从灵敏性、特异性、识别精度、马修相关系数四个方面比较三个单一DE-NRS模型个体分类器和集成DE-NRS在肺部肿瘤计算机辅助诊断中的整体性能。
2.2.2 算法伪代码
基于DE-NRS属性约简算法的伪代码如下:
算法输入:决策信息表(其中:CT和PET/CT包括104维条件属性特征和1维决策属性特征;PET包括98维条件属性特征和1维决策属性特征);测试样本parnum;邻域半径lambda;权重值weight;种群数目popsize;进化代数maxgen;交叉系数CR;变异系数F;
算法输出:约简后属性值features;约简后属性长度fnum;适应度值。
算法步骤:
Main
//主函数
For k=1:dim
Dis=bsxfun(@minus,data_scale(:,k),data_scale(:,k)’);
flagMat(:,:,k)=abs(dis)<=delta(k);
end
myDE
//差分进化算法
for gen=1:maxgen;
for p =1:popsize;
r = randperm(popsize,3);
while any(r == p)
r = randperm(popsize,3);
end
trailVar = popVar(r(1),:) + F*(popVar(r(2),:)-popVar(r(3),:));
trailVar = min(max(trailVar,low),up);
idx = rand(1,dim) < CR;
idx(randi(dim))=1;
mutVar=trailVar.*idx+popVar(p,:).*(1-idx); mutObj=myfun(mutVar);
if mutObj<=popObj(p,:)
popVar(p,:)=mutVar;
popObj(p,:)=mutObj;
end
end
myfun
//基于邻域粗糙集的属性重要度求解算法
if(isempty(C));
gama = 0;
return;
end
posCD = PositiveRegion(U,C,D);
gama = length(posCD)/length(U);
end
肺部肿瘤良恶性识别SVM个体分类器算法的伪代码如下:
算法输入:经DE-NRS属性约简模型约简后的属性约简子集决策信息表。
算法输出:时间time; 灵敏度sen;特异度spe;识别精度acc;马修相关系数mcc。
算法步骤:
indx1=find(features(:,1000)==1); indx0=find(features(:,1000)==-1);
test_data_index=[indx1([1*1000-199:1*1000]);indx0([1*1000-999:1*1000])];[1*1000-999:1*1000];
[train_final,test_final]=scaleForSVM(train_data,test_data,-1,1);
[bestCVaccuracy,bestc,bestg]=SVMcgForClass(train_data_labels,train_final,0,6.5,-1.5,2,5,0.5,1,0.9);
cmd = [′-c′,num2str(bestc),′-g′,num2str(bestg)];
model = svmtrain(train_data_labels, train_final,cmd);
[ptrain_label2, train_accuracy]=svmpredict(train_data_labels, train_final, model);
[ptest_label2,accuracy,decision_values]=svmpredict(test_data_labels, test_final, model);
3 实 验
3.1 实验环境与数据
处理器:Intel(R)core(TM)i7-6800K CPU 3.40 GHz;内存:16 GB;系统类型:64位操作系统;运行环境:MATLAB 2018;实验数据来源:宁夏某三甲医院带有良恶性标记的肺部肿瘤患者的肺部影像资料CT、PET、PET/CT各3 000例,其中良性1 500例,恶性1 500例。
3.2 实验整体思路设计
为确保和验证模型的有效性和可行性,进行如下实验:1) 对邻域粗糙集的邻域大小σ确定方式进行探讨;2) 对差分进化算法中涉及的变异系数F、交叉系数CR、权重值ω等参数进行探讨;3) CT、PET、PET/CT集成实验; 4) 与变精度粗糙集、深度信念网络等算法进行对比实验。
3.3 实验结果分析
以下实验结果均为相同实验环境下5次实验结果的均值。
3.3.1 NRS的参数实验
NRS模型中,邻域大小σ对实验结果的准确性起着至关重要的影响作用,目前,邻域大小σ取值方式包括两种:(1) 点值式(即依据人的经验制定特定的值);(2) 通过σ=stda/λ计算所得,其中参数λ也是通过点值式确定。合适的σ取值能让算法得到个数较少且有效性较高的属性约简子集。属性约简子集的有效性体现在分类器根据其对数据进行识别后得到的识别精度上,识别精度越高,则属性约简子集的有效性越高。因此,本文使用控制变量法对邻域大小σ取值进行实验,探讨σ的两种计算方式对实验结果的影响,其中基于公式计算的实验通过控制变量λ进行。图3给出约简数量、识别精度随点值式σ取值的变化情况,其中,σ取值以0.05为步长,从0到1变化。图4给出约简数量、识别精度随λ的变化情况,λ的取值以0.1为步长,从2到4变化。

图3 约简数量、识别精度随邻域大小σ的变化情况
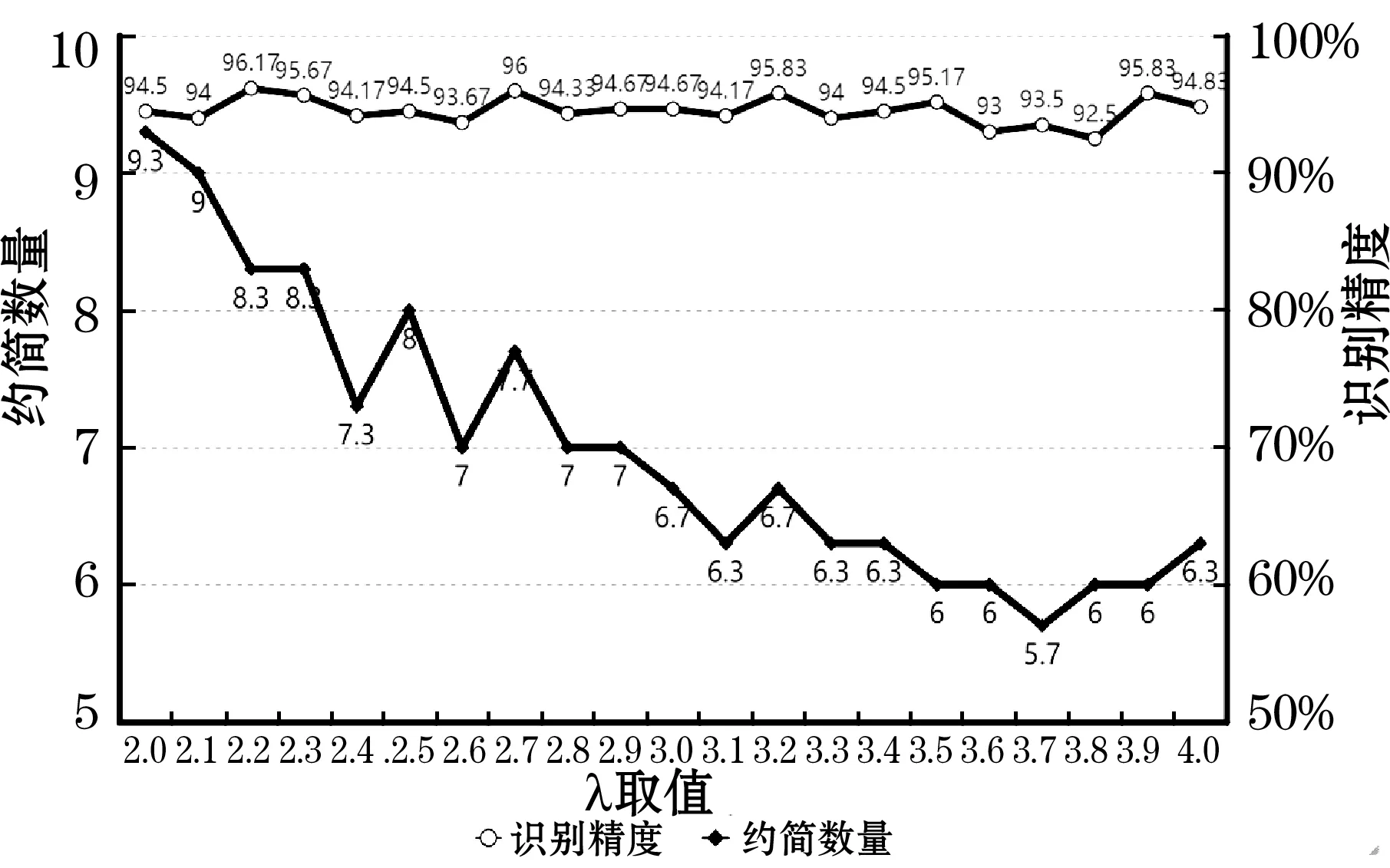
图4 约简数量、识别精度随邻域大小λ的变化情况
从得到的约简结果来看,以点值式方式直接确定邻域大小存在约简数量大的问题,得到约简数量均值为44.7,占总属性数目的44.23%,而以公式σ=stda/λ确定邻域大小得到的约简数量较为理想,为7。从识别精度来看,以点值式方式直接确定邻域大小与通过公式σ=stda/λ确定邻域大小得到识别精度均值相差不大。因此,综合约简数量和识别精度两方面因素,本文邻域大小选择使用公式σ=stda/λ计算确定,且λ取值为2.2。约简数量随σ和λ取值变化的对比如图5所示。
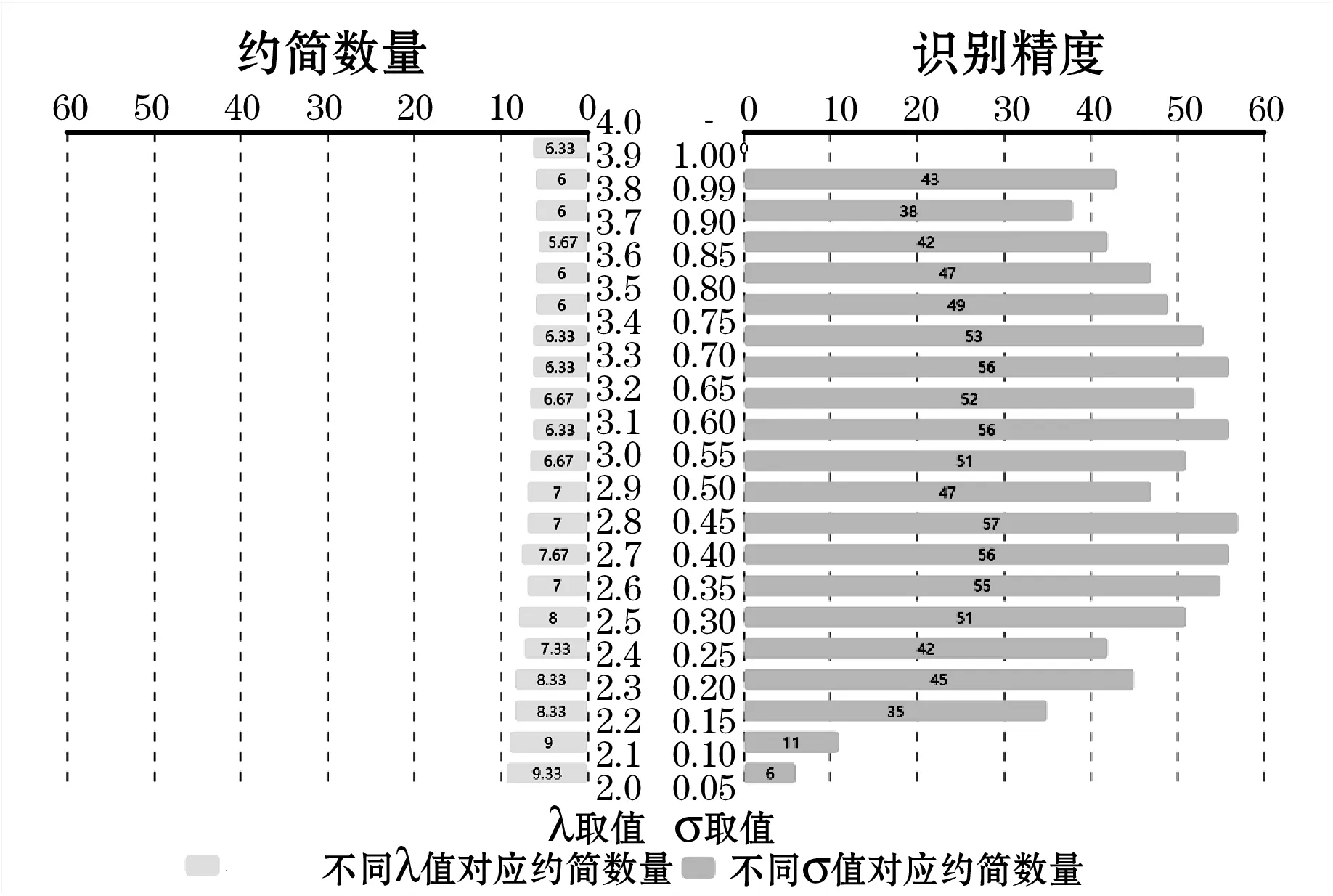
图5 约简数量λ、σ的变化情况
3.3.2 DE的参数实验
(1) 变异系数F与交叉系数CR参数研究。DE算法主要利用获选解间的不同性来搜索更多的可能的解。一个候选解当作一个个体,每个个体的更新需要利用不同个体间的差异来进行。但是获取个体间的差异性的方式需要进一步分析,以及怎样利用这些差异性,即设置其相关的参数来搜索更好的解需进一步研究。DE算法涉及的主要控制参数包括:种群规模、迭代次数、交叉系数CR、变异系数F。本文种群规模根据经验取值为520,迭代次数根据实验经验取值200,主要探讨交叉系数CR、变异系数F对约简数量和识别精度的影响。图6、图7展示了约简数量、识别精度分别随F和CR的变化情况;图8展示了约简数量、识别精度随(CR,F)组合值的变化情况。其中:CR的取值以0.1为步长,从0.8到1变化;F的取值以0.1为步长,从0.5到1变化。
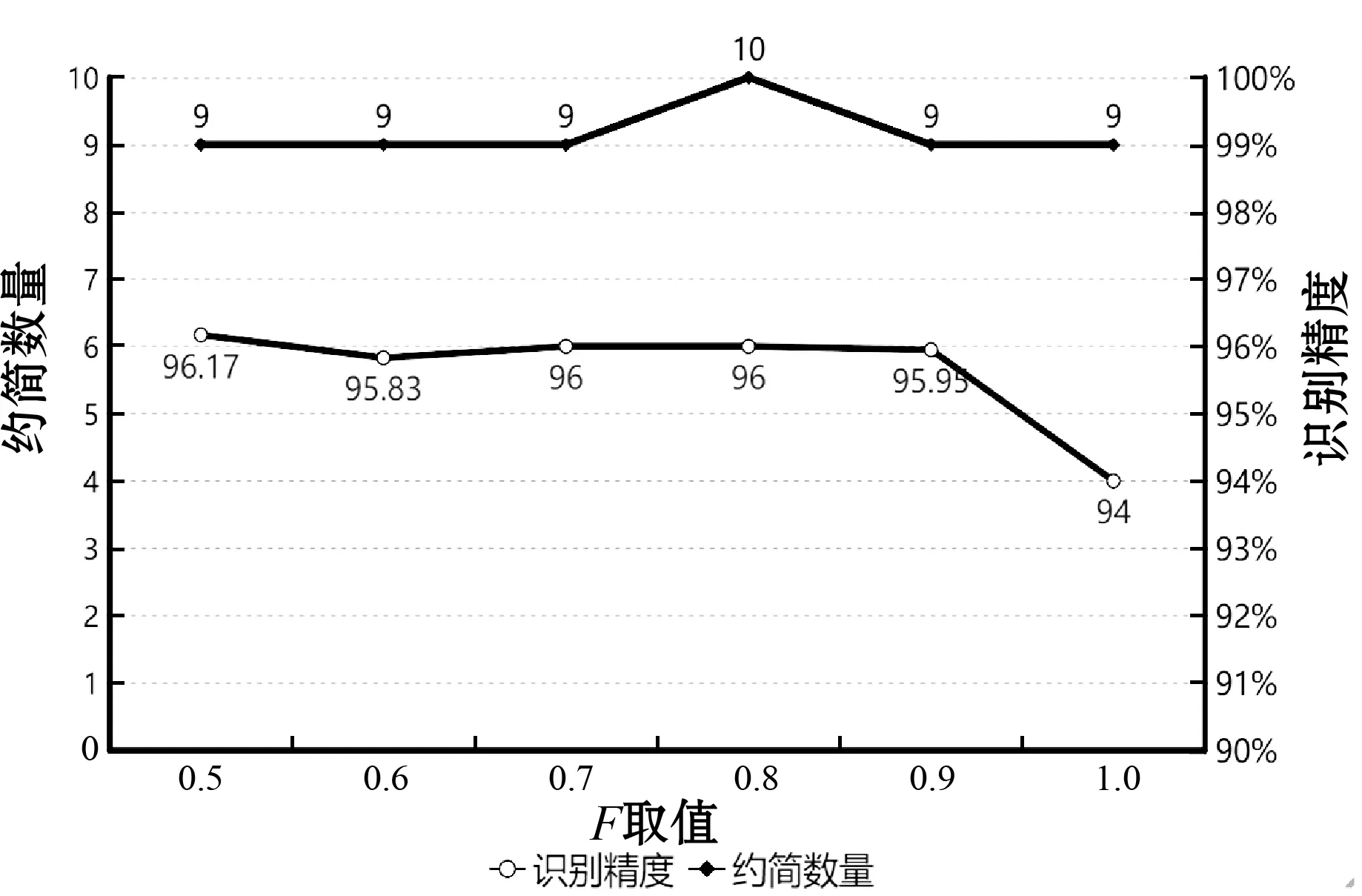
图6 约简数量、识别精度随F值的变化
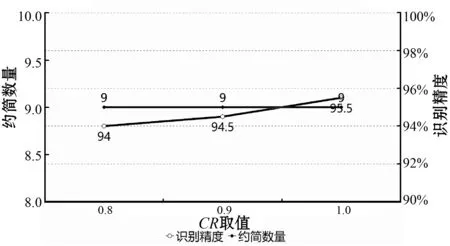
图7 约简数量、识别精度随CR变化

图8 约简数量、识别精度随(CR、F)组合值的变化
由实验结果可知:CR与F并非同时取最优值时,便能够得到最优约简数量和识别精度,在CR=0.8,F=1时,约简数量和识别精度达最优值,因此本文CR取0.8,F取1。
(2) 权重值参数研究。差分进化算法还涉及适应度函数的构造,针对本文构造的适应度函数,探讨了权重(ω1,ω2)组合值对约简数量和分类精度的影响。图9展示了约简数量、识别精度随(ω1,ω2)组合值的变化情况。通过实验结果对比,本文实验参数(ω1,ω2)取值(-0.3、-0.7)。
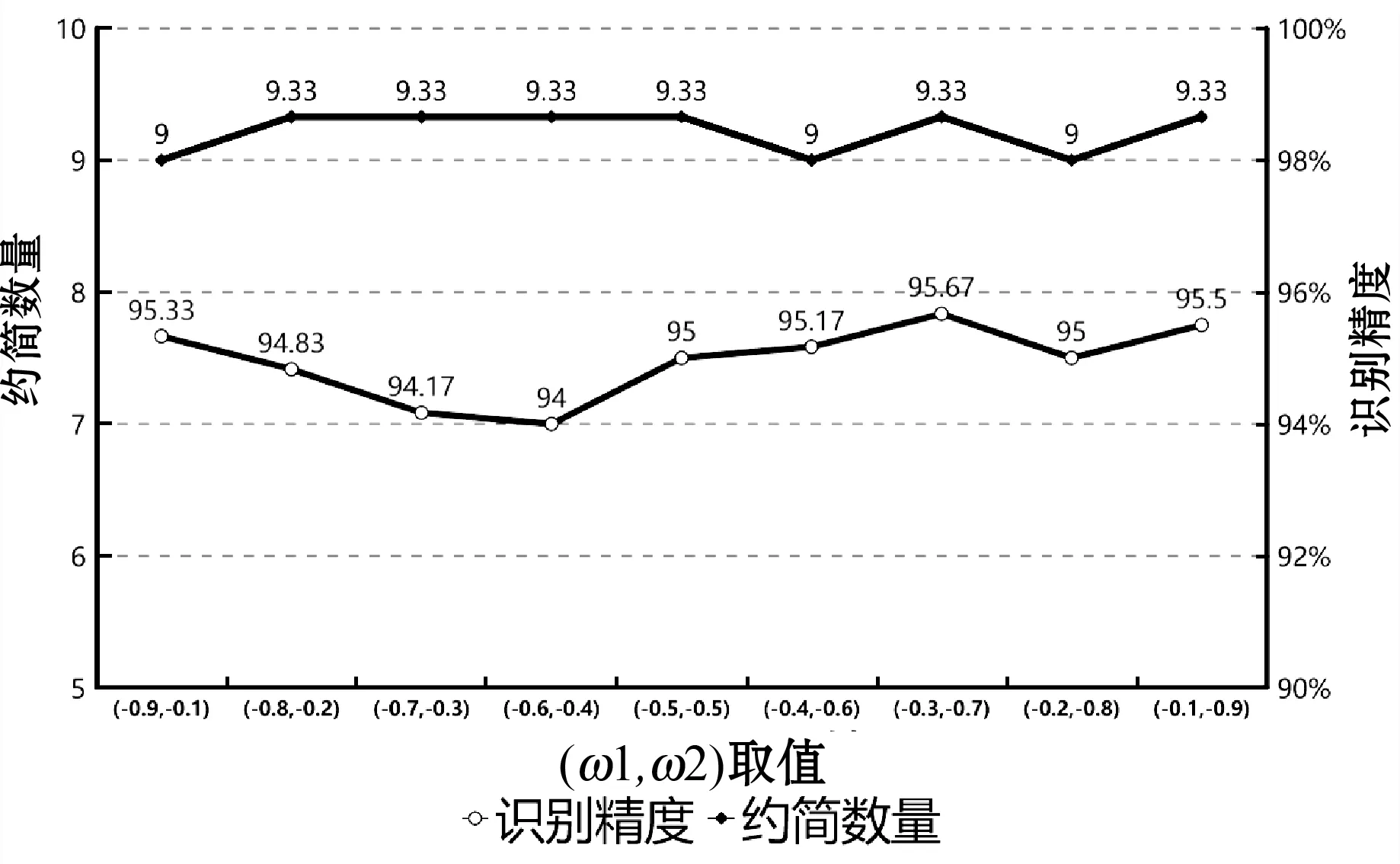
图9 约简数量、识别精度随(ω1,ω2)组合值的变化
3.3.3 个体分类器实验
本文选用五折交叉验证法分别计算基于CT、PET、PET/CT肺部肿瘤识别性能,具体评价指标为:灵敏度、特异度、识别精度、马修相关系数。
(1) 基于肺部肿瘤CT样本空间构造个体分类器。基于肺部肿瘤CT样本空间的104维特征构造CT-SVM个体分类器,利用五折交叉训练法(在1 500例良性肿瘤中,1 200例作为训练集,300例作为测试集。1 500例恶性肿瘤训练同理)得到肺部肿瘤良恶性识别性能,见表2。实验表明,CT图像肺部肿瘤识别精度为95%,灵敏度为97.8%,特异度为92.2%,说明在CT图像构成的样本空间里构造的个体分类器灵敏度高、特异度较低。
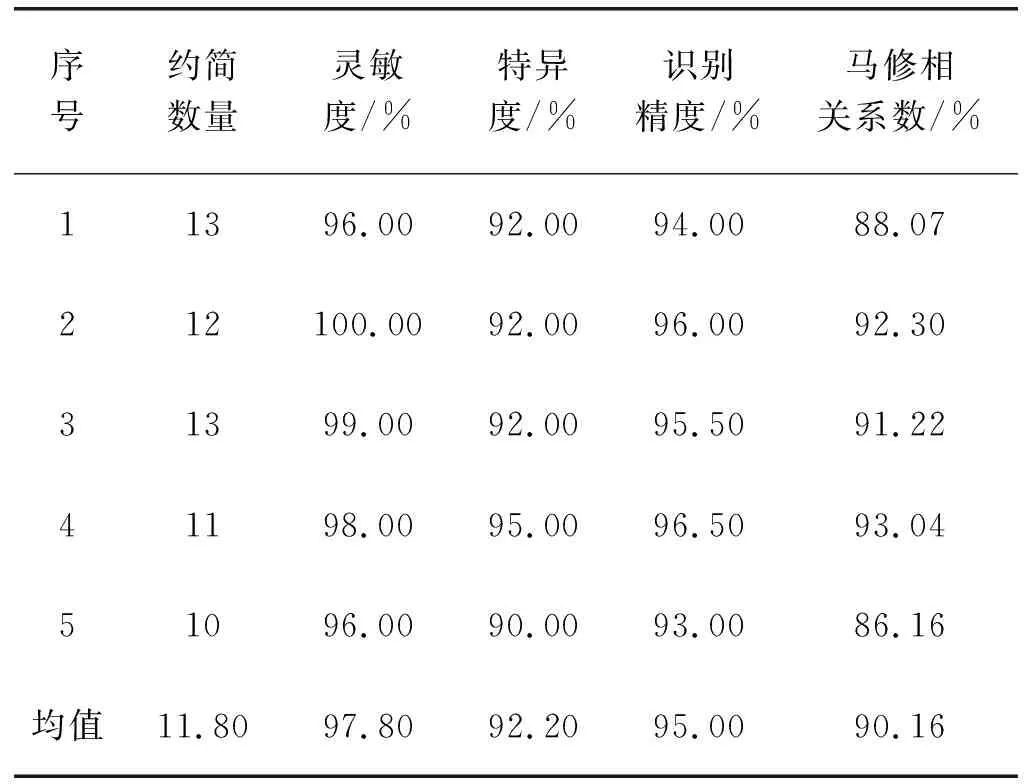
表2 基于肺部CT医学影像图像的肺部肿瘤识别精度
(2) 基于肺部肿瘤PET样本空间构造个体分类器。基于肺部肿瘤PET样本空间的98维特征构造PET-SVM个体分类器,利用五折交叉训练法(在1 500例良性肿瘤中,1 200例作为训练集,300例作为测试集。1 500例恶性肿瘤训练同理)得到肺部肿瘤良恶性识别性能,见表3。实验表明,PET图像肺部肿瘤识别精度为97%,灵敏度为1,特异度为98.2%,说明PET较CT图像在构成的样本空间里构造的个体分类器灵敏度高,特异度、识别精度较高。
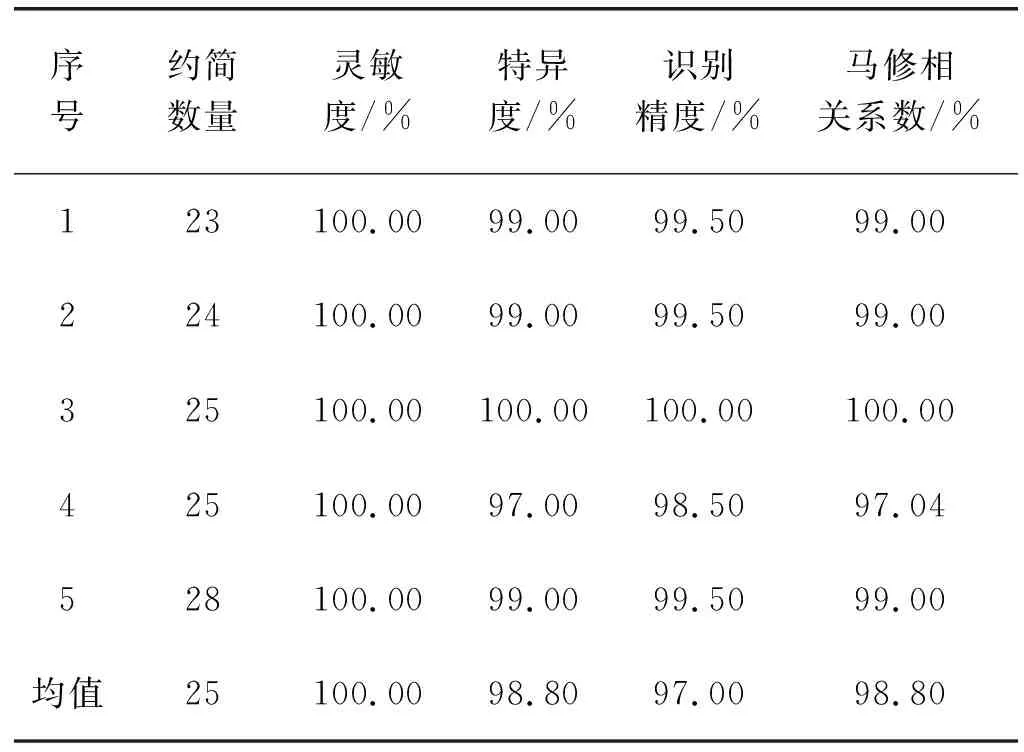
表3 基于肺部PET医学影像图像的肺部肿瘤识别精度
(3) 基于肺部肿瘤PET/CT样本空间构造个体分类器。基于肺部肿瘤PET/CT样本空间的104维特征构造PET/CT-SVM个体分类器,利用五折交叉训练法(在1500例良性肿瘤中,1 200例作为训练集,300例作为测试集。1 500例恶性肿瘤训练同理)得到肺部肿瘤良恶性识别性能,见表4。实验表明,PET/CT图像肺部肿瘤识别精度为98.9%,灵敏度为99.66%,特异度为99.04%,说明在PET/CT图像的样本空间里构造的个体分类器灵敏度、特异度、识别精度都较高。
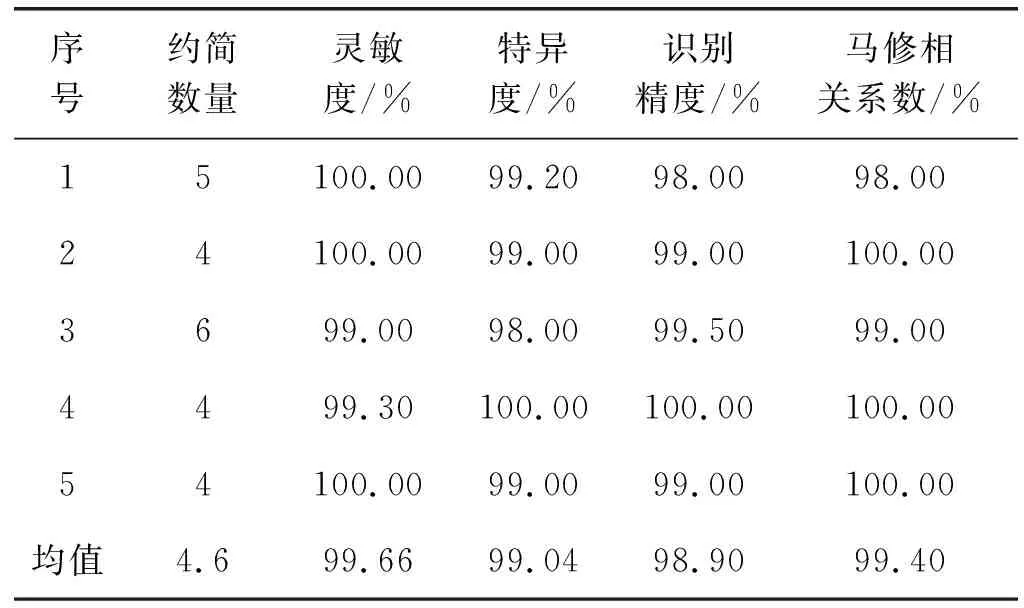
表4 基于肺部PET/CT医学影像图像的肺部肿瘤识别精度
3.3.4 诊断模型实验
上述实验结果表明:不同模态样本空间的SVM个体分类器对肺部肿瘤识别精度不同。本文利用相对多数投票准则对不同模态个体分类器的识别结果做集成学习,从而得到最终识别结果,具体见表5。可以看出:集成NRS-DE对肺部肿瘤的识别精度达99.72%,相对于单个CT、PET、PET/CT个体分类器在灵敏度、特异度、识别精度分别提高了4.72%、2.72%、0.82%。这说明集成DE-NRS比单个DE-NRS对肺部肿瘤识别效果更好,利于辅助医生对肺部肿瘤进行识别。
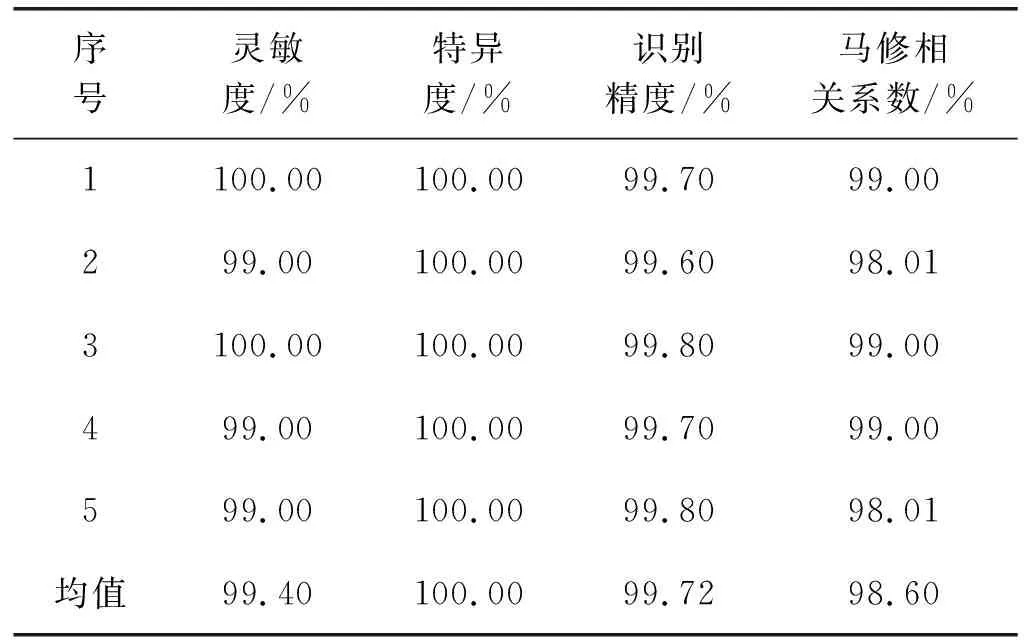
表5 基于集成学习的肺部肿瘤识别精度
3.3.5 不同模型识别精度的对比实验
为了验证本文模型的合理性及有效性,本文与集成SVM[19]、集成VPRS-RUGGA-SVM[20]进行相同数据不同方法的比较实验。实验结果表明,本文提出的模型在肺部肿瘤识别的灵敏度、特异度和识别精度上都得到一定程度的提高。实验对比结果见表6。
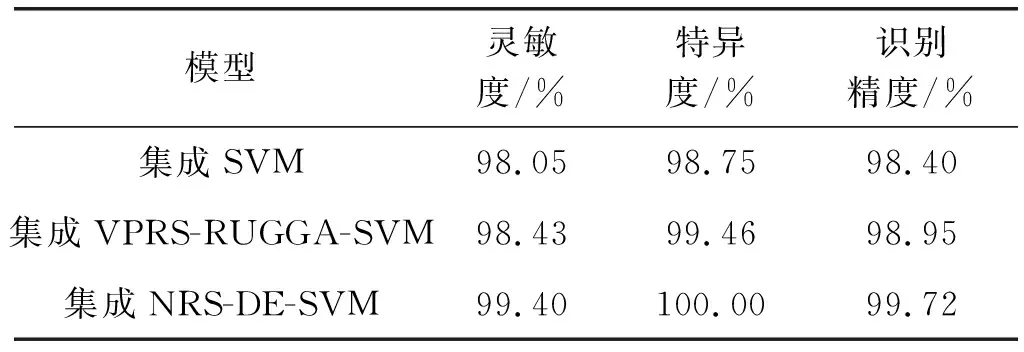
表6 不同集成算法对肺部肿瘤识别精度的比较
4 结 语
肺癌是人类发病率及死亡率最高的癌症,对人类的生命健康造成巨大威胁。计算机辅助诊断在肺癌的早期诊断中扮演着重要角色,但仍然存在着假阳性高等问题。本文结合DE提出基于集成NRS的肺部肿瘤影像组学计算机辅助诊断模型在肺部肿瘤良恶性识别上,整体性能较好,识别精度达到99.72%,具有较好的鲁棒性和可扩展性,为肺部肿瘤计算机辅助诊断提供了技术支持。若能将肺部肿瘤计算机辅助诊断系统应用于更多的基层医院、放射科室,将会拯救更多的肺癌患者。于家庭,早发现早治疗,更能为其节约昂贵的化疗等费用,进而减轻其经济压力和精神压力;于医院,降低医生的阅片时间,提高医生的阅片准确率,进而为医院节省大量的人力、物力、财力等成本;于社会,实现医疗资源均衡化,满足人民群众日益增长的医疗卫生健康需求。
猜你喜欢
现代电子技术(2022年15期)2022-07-28
农业工程学报(2022年7期)2022-07-09
电子产品世界(2022年4期)2022-04-21
计算机应用(2022年2期)2022-03-01
计算机应用与软件(2021年11期)2021-11-15
逻辑学研究(2021年3期)2021-09-29
计算机应用(2021年4期)2021-04-20
计算机系统应用(2021年2期)2021-02-23
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
软件导刊(2017年4期)2017-06-20
