
基于语义元数据的医养数据融合研究与实现
2020-05-16 06:33季文飞蒋同海唐新余
计算机应用与软件 2020年5期
季文飞 蒋同海 王 蒙 唐新余 陈 光
1(中国科学院新疆理化技术研究所 新疆 乌鲁木齐 830011)2(中国科学院大学 北京 100049)3(中国科学院新疆民族语音语言信息处理重点实验室 新疆 乌鲁木齐 830011)4(江苏中科西北星信息科技有限公司 江苏 无锡 214135)
0 引 言
医养融合是国务院《关于加快发展养老服务的若干意见》中提出的创新养老服务模式,指将养老服务同医疗资源相结合,从而更好地服务老年人群[1]。医养融合首先是数据融合,即打通医疗、养老信息系统的数据壁垒,统一相关系统业务和数据模型,共享相关系统数据。数据融合技术能够对海量数据进行融合处理,提高“数据质量”[2],减少数据中的错误,为后续数据处理分析提供可靠的数据支持[3]。通过融合,一方面可以整合各自系统的就医、用药、养老等老年人生活数据[4],让老年人享受更加便捷的老年生活服务,另一方面可以提高政府对老龄问题的洞察能力,提高决策科学水平[5]。我国现有的医疗、养老系统数据模型复杂,重复较高,无法共享相关的老人就医和养老数据,存在严重的“信息孤岛”问题[6]。传统的医养融合系统一般采用硬编码技术实现,根据具体项目制定数据模型、清洗融合模型、可视化和访问模型,在灵活性、可扩展性方面表现较差。
本文针对医养数据融合中相关问题进行研究,提出使用语义元数据模型解决医养数据融合中的统一建模问题、清洗和融合问题、可视化和访问问题,并实现了相应的数据融合系统。该系统支持动态数据建模、支持融合规则建模和可视化模型建模,具有较好的灵活性和可扩展性,能满足区域内养老、医疗数据融合处理响应时间的要求。
1 相关工作及面临的问题
医养融合需要汇聚来自各种医疗系统、养老系统的数据,需要支持物联网设备、长护险结算系统及其他第三方数据产生端的系统接入,同时需对汇聚的数据进行清洗和融合,并提供数据可视化和访问服务。
文献[7]介绍了利用FHIR进行医疗信息集成,通过构建一个RESTFUL协议访问的应用系统,利用基于XML的HL7协议对医疗信息进行建模,实现不同医疗系统之间的数据集成和共享。
文献[8]介绍了基于本体理论进行医学数据建模及其应用,首先利用本体进行医疗建模,然后利用算法进行数据检测和本体识别。文献[9]则在本体建模形成的医疗数据模型基础上进行了医疗知识抽取和可视化工作。
文献[10]介绍了基于字符串模式匹配的数据交互集成方法,即利用人工干预进行多次迭代的方式生成全局统一的中介模式,并介绍了其在二手房数据集成上的应用。
文献[11]介绍了使用新技术框架如Apache Hadoop、Apache Storm进行医疗、护理数据集成和计算,并建立了一个能够支持实时进行医疗、护理数据计算的系统。
上述的研究一般以项目的形式,由编程人员在某一些医疗、养老系统之间,利用XML或者本体建模技术,进行少量的数据清洗和融合,限于较低的灵活性和扩展性,未能进行大范围推广和使用,其主要原因是当前医养数据融合面临以下问题:
(1) 统一数据建模问题[12]。医、养相关的系统纷繁复杂,每个系统对医疗、养老业务的抽象能力参差不齐,导致所建的数据和业务模型不尽相同,需要对业务和数据进行标准化和统一化建模,抽取出全局标准模型;另外这些系统在建模时使用的工具各不相同,需要提供统一的数据建模描述工具并支持动态建模。
(2) 清洗和融合问题[13]。不同来源的医疗、养老数据产生和采集方式不同存在数据缺失、异常、冗余等问题,为后续的处理带来很大困难,需要对数据进行数据清洗和融合处理。不同的数据一般采用不同的清洗和融合策略,且需要动态修改,因此需要对清洗和融合进行建模,并提供相应的过程描述工具。
(3) 可视化和数据访问问题[14]。不同的医疗、养老业务场景对数据的访问和可视化能力具有不同的要求,需要提供对数据不同粒度的查询访问和可视化访问建模和描述工具。
2 基于语义元数据的医养融合研究
语义元数据作为资源描述框架表现形式,具有结构紧凑、表达直观、语义丰富等特点,在数据集成、知识抽取得到大量研究和应用[15]。语义元数据具有不同表示方法,例如元组、XML_DTD[16]、RDFa[17]、JSON-LD[18]等方法。由于元组具有较好的可读性、紧凑性,是最直观的方法之一,能够灵活地对数据进行建模和表述,支持数据模型的扩展,因此本文使用五元组表示的语义元数据,对上述医养数据融合的问题进行研究,并设计出灵活性好并可扩展的数据融合系统。
语义元数据用一个五元组
2.1 语义元数据与统一数据建模
当前的医疗、养老系统具有不同的数据模型定义,需要事先使用语义元数据进行统一的数据建模,原有系统的数据模型也使用语义元数据进行描述,并把原有的数据模型与统一的模型在语义层面进行关联。例如针对老人基础模型,f的一个函数可以是原系统老人基础模型的“姓名”属性映射转换到统一模型的“name”属性。
考虑到当前大部分医疗、养老系统基于关系型数据进行建模和存储,需要找到原数据与模型之间的关系,如算法1所示。
算法1 数据模型适配算法
输入:cur_rules:语义元数据规则集合
data:需要匹配的数据
输出:adapt_rules:适合此数据的语义元数据规则集合
for rule in cur_rules
data_keys=data.keys()
needed_keys=rule.Q
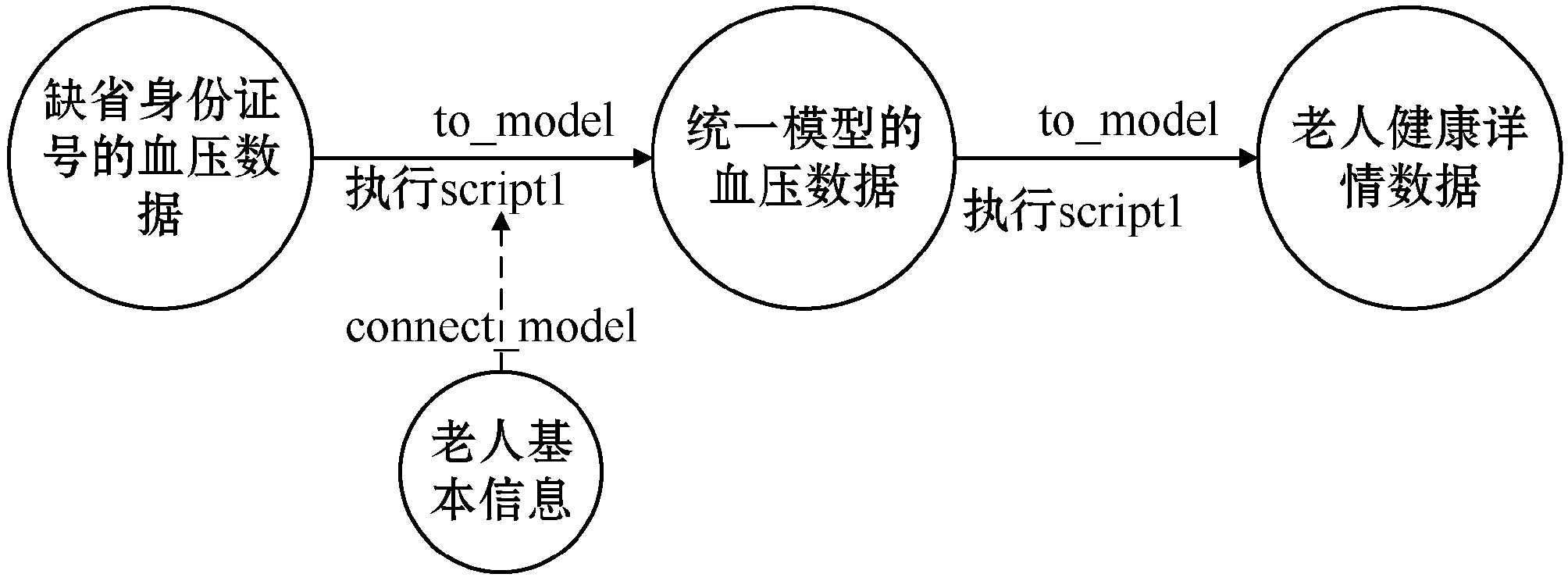
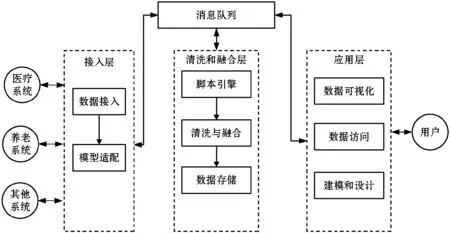
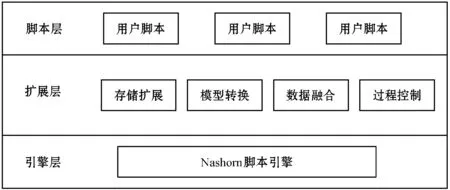
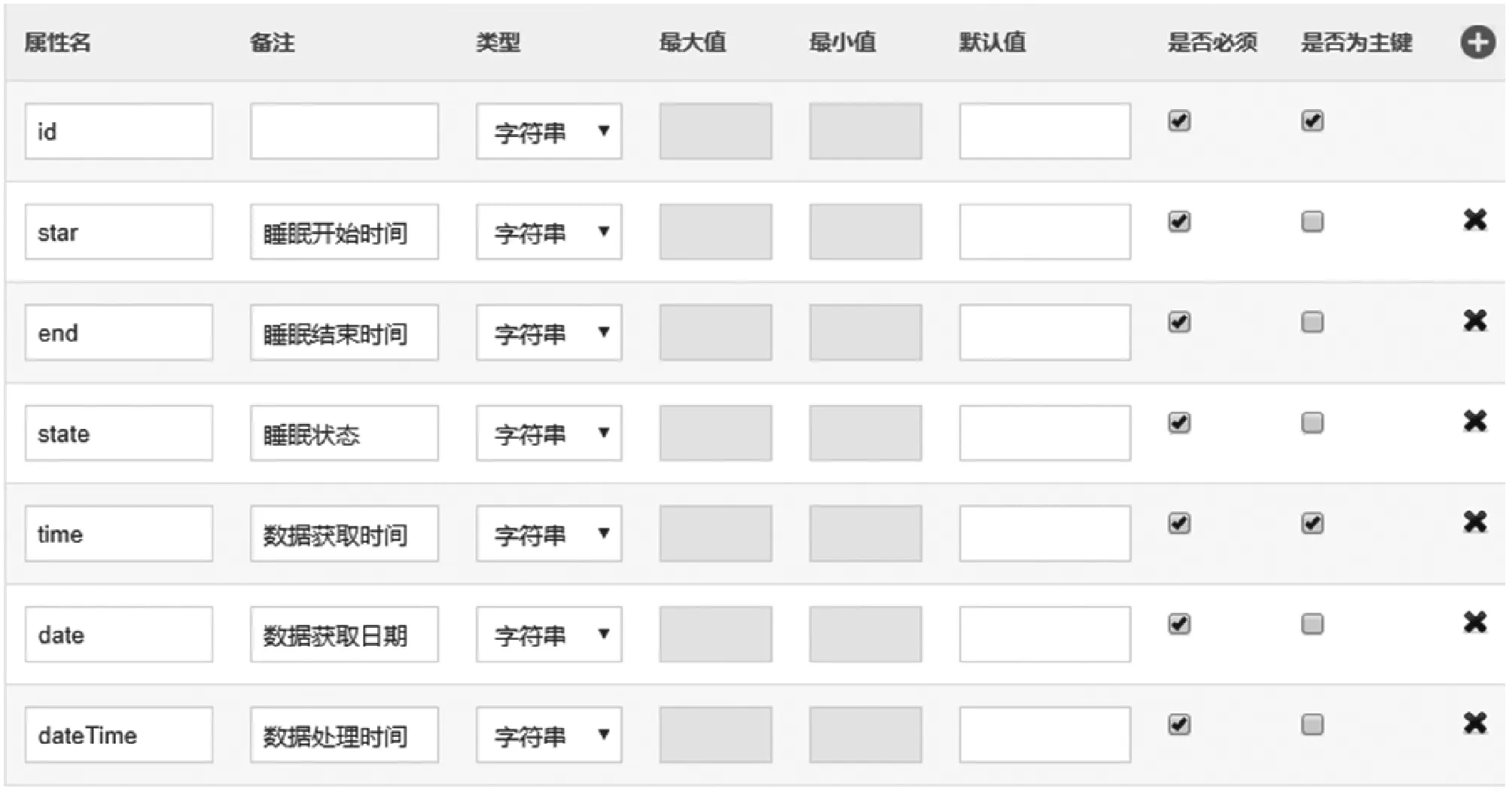
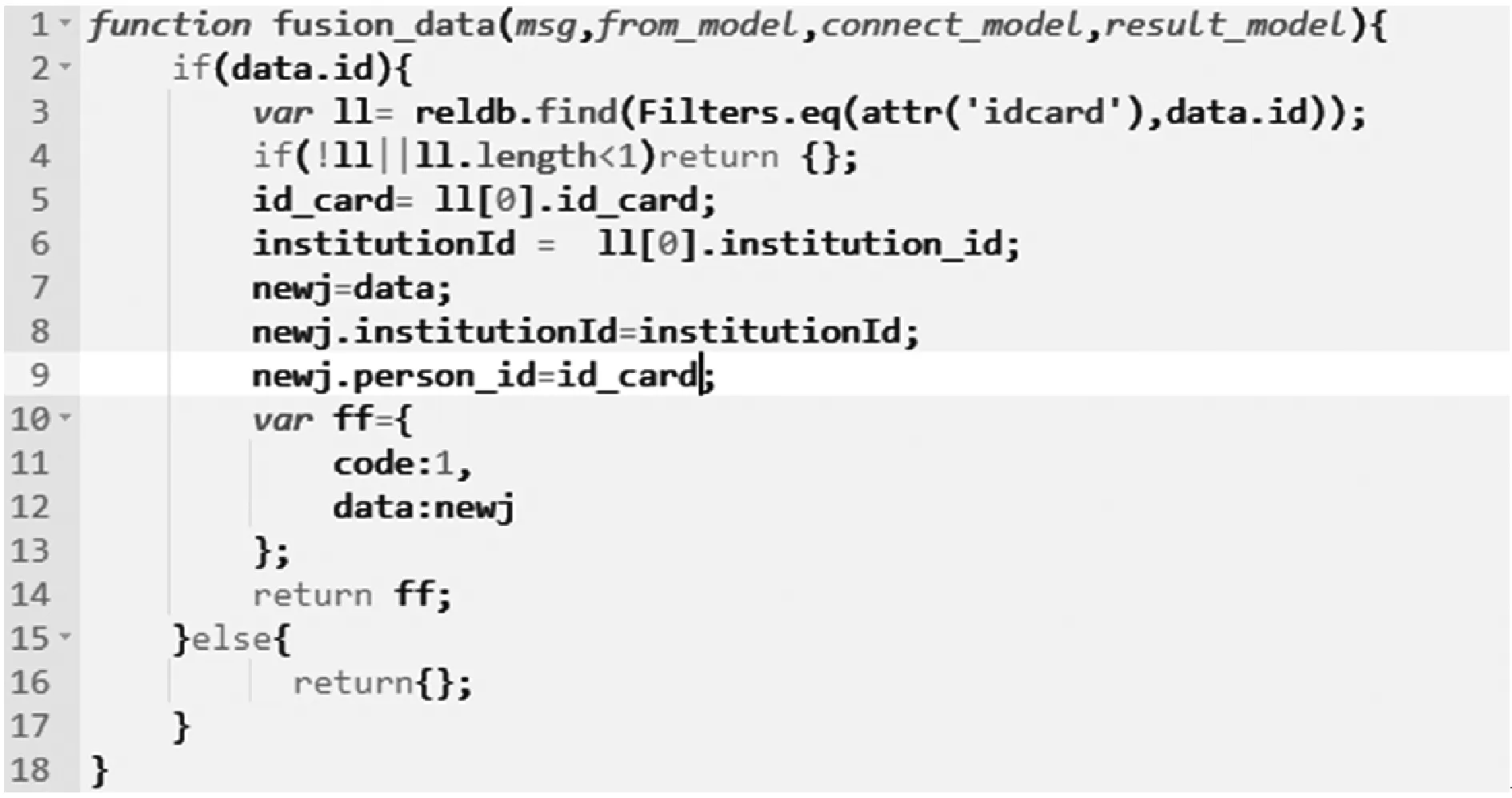
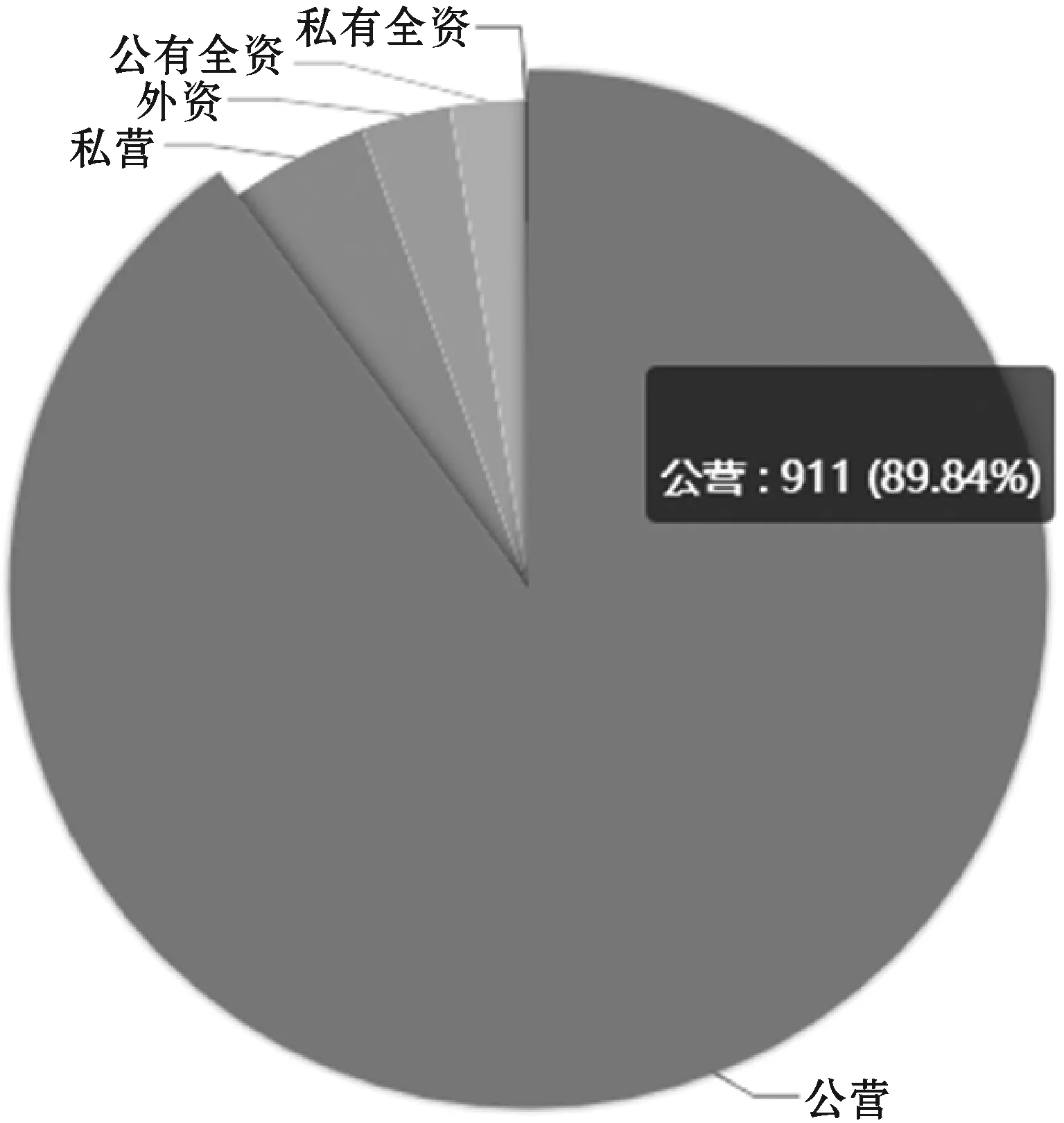
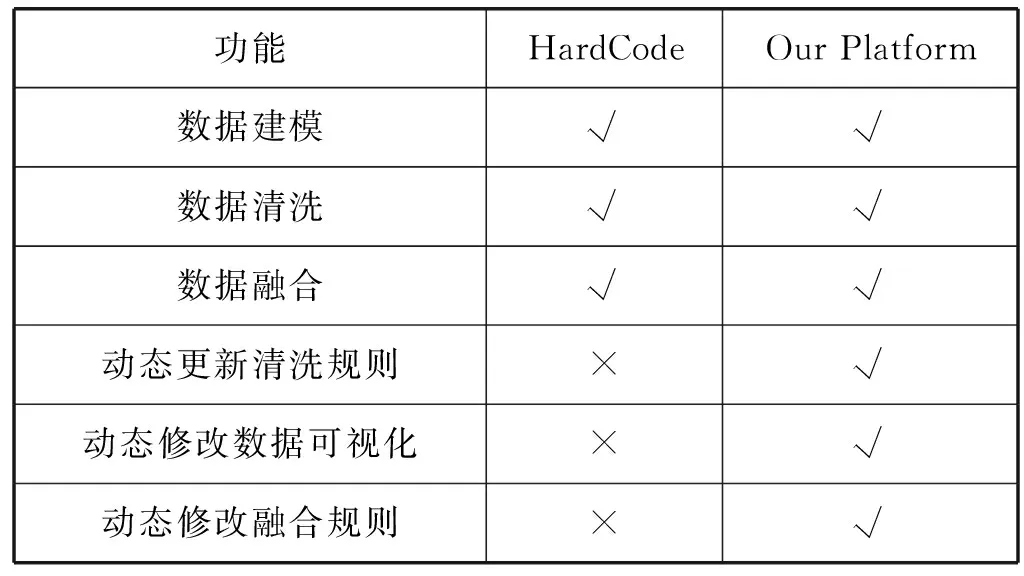
if data_keys.length Continue check_rule_flag=true for key in needed_keys if data_keys.index(key)<0 check_rule_flag=false break if check_rule_flag==true adaptive_rules.add(rule) 该算法不仅能够给数据找到适合的模型,而且能够把数据按照模型进行划分,这在实际工程实践中具有重要意义。因为传统的应用系统一般以关系型的形式存储相关数据,具有完善的模型之间关系,该算法能够捕捉这种模型之间的关系并把数据任意组合到相关模型中,如针对老人的详细信息,通过算法可以切分为老人基本信息、健康信息、生活信息,这非常便于存储和检索。 数据清洗和融合的主要步骤包含:模式对齐、实体识别、冲突消解及数据追踪。利用语义元数据对清洗和融合规则进行定义,并通过执行该规则达到清洗和融合的目的。 针对清洗和融合规则,使用五元组定义,x=“cleanandfusion”,A=[id,name,description,condition,operation,from_model,to_model,connect_model,script,type],K=[id],Q=[id,name,condition,operation,type,script],f=[],其中:id是规则编号,具有唯一性;name是该处理规则的名称;description是该规则的描述信息;condition是该规则的执行条件;operation是该规则对应的操作,如:模式对齐、实体识别、冲突消解和数据追踪;from_model是指该规则对应来源数据的模型;to_model是处理完成后返回的数据的模型;connect_model是处理时所需要的额外的数据模型;script中定义了怎么进行处理相关操作的脚本;type是该脚本的类型,目前可支持JavaScript脚本。 往往一个数据完成清洗和融合操作,需要经过多次清洗和融合规则处理,需要保证不同规则之间处理顺序,借助语义元数据可以实现不同规则之间的链式处理,即在五元组f中指定下一步清洗和融合的规则id。如果满足规则中condition的条件则执行编号为id的规则,不断重复上述步骤便可实现链式执行。例如,如图1所示,从物联网设备中采集的缺省身份证号码的血压数据,在script1中通过与connect_model指定的老人基本信息模型关联操作,并把补充了身份证号信息的血压数据输出到to_model指定的统一血压数据模型中;同理执行script2便可以把统一血压模型的数据更新到老人最新健康数据模型中。 图1 缺省身份证号的血压数据处理过程 数据可视化和数据访问需要对数据进行查询,并把结果以可视化或者接口的形式呈现出来。使用语义元数据,对数据可视化和数据访问过程进行建模。 数据可视化定义为五元组 数据访问定义为五元组 本文系统根据实际项目情况,选用SpringCloud作为基础框架进行开发,使用kafka作为消息通信队列,使用redis进行缓存,使用mongdb存储语义元数据,使用mysql存储用户数据,使用vue2.0和echarts.js、d3.js作为前端框架。在部署和测试时采用10台阿里ECS云服务器[19],其配置全部为4核CPU、16 GB内存、200 GB普通硬盘。 本文系统的架构如图2所示,共分为三层:接入层,清洗融合层,应用层,各层之间通过消息队列进行通信。接入层主要负责各系统的数据接入、数据与语义元数据模型之间的转化。清洗和融合层主要用来根据用户设定的语义元数据模型对数据进清洗、融合和数据存储。清洗和融合模型中的script是在脚本引擎中进行执行。应用层主要提供数据可视化和数据访问服务,以及提供界面供用户设计基于语义元数据的数据模型、清洗融合策略、可视化和访问方式。 图2 医养数据融合系统架构 在数据进行清洗和融合时,为提高系统的灵活性和扩展性,使用脚本引擎链式执行相关的脚本。Nashorn是Java语言中最新的脚本引擎,用于取代Rhino,相比于后者具有较好的执行效率[20]。本文使用Nashorn作为清洗融合脚本的执行器,同时又在此基础上封装了相关的数据清洗、融合、存储等方面的API,用于简化清洗融合的开发,其架构如图3所示,主要包含三层:引擎层、扩展层和脚本层。引擎层主要包含能够执行Javascript脚本的Nashorn引擎。扩展层主要是把存储、模型转化、清洗、融合和过程控制等功能封装成相应的语义元数据模型,并提供脚本API,供上层的脚本层调用。脚本层主要是使用者编写的脚本,用以进行数据清洗和融合以及过程的控制,其编写的脚本对应清洗融合模型中的script。使用者编写的脚本可以使用扩展层提供的API,进行数据关联、数据模型之间的转化、数据处理和过程控制操作。为了提高模型转换效率,对相关模型转换的结果进行缓存,已经缓存的模型在执行时无需再次转换。 图3 清洗融合引擎架构 本系统能够满足医养数据融合的需求,在全国多个区域进行了试用,已经接入各类系统二十余个,能够灵活地对医养数进行建模,涵盖了老人、养老机构、医疗等多种类型的数据,为政府机构提供了实时的数据可视化和查询服务。 图4为对老人睡眠数据进行建模的界面,说明该系统能够动态对数据模型进行扩展。图中属性名对应语义元数据中的A集合,Q集合元素对应在是否必须列打勾的,K集合元素对应是否为主键列打勾的,其余的备注、类型、最大最小值、默认值则设定到f中。 图4 老人睡眠数据模型 图5展示的是缺省老人身份证号的老人血压模型的清洗和融合的脚本。图中首先到connect_model中查找身份证号码,然后形成带有身份证号的血压数据并返回。 图5 补充身份证编号的融合脚本 图6是统计某市养老机构性质占比图,只需配置数据的来源。图中对可视化模型的来源、类型、图例等进行了配置,配置完成后即可查看到相关的可视化界面,如图7所示。 图6 机构性质占比可视化模型 图7 机构性质占比 首先对比了本文设计的系统与传统硬编码系统(HardCode)在功能上的区别,传统的硬编码系统由研发人员根据项目需要,参照文献[11],基于Hadoop和Storm进行编码实现。如表1所示,本文系统支持融合规则的动态修改、数据清理规则的动态修改、动态修改数据可视化等功能,但传统硬编码系统不支持。 表1 功能对比 另外,为了满足系统在数据接入、清洗和融合以及数据访问在数据接入量较大时的实时性,需要保证系统在处理大数据量时具有较小的响应时间。因此对系统不同数据量下的响应时间进行了实验,结果如图8所示。 图8 不同数据量响应处理时间统计 本次测试的数据来自江苏某市2018年1月到2018年6月间的老人健康数据、生活数据、护理记录数据共8.34 GB。数据采集方式有三种:第一种通过可穿戴设备直接采集录入;第二种是第三方医疗、养老系统通过对接进行数据收集;第三种是护士、医生、护工等手工录入。 本次实验使用了开源的Apache JMeter测试工具编写测试脚本进行响应时间的测试。分别随机选取真实的老人健康数据500条、1 000条、1 500条、2 000条测试信息处理响应时间(单位为s)。由图8可知,随着数据量的增加,数据处理响应时间缓慢增加,在处理2 000条数据的数据量时响应时间未超过2 s。本文设计的系统响应时间在处理较少数据量时响应时间高于硬编码系统的响应时间,因为需要进行语义元数据模型转换,而在数据量较多时,响应时间接近甚至少于硬编码系统的响应时间,当数据量较多时,本文平台可以发挥缓存模型的优势。综合来看,本文设计的系统能够满足平台在区域内数据融合响应时要求。 本文通过对医养数据融合中面临的问题进行分析,基于语义元数据对数据建模、清洗和融合、数据访问和可视化进行研究,形成灵活性好、可扩展的医养数据融合系统,并通过相关实验验证了该系统能够满足医养数据融合中对大数据量响应时间的要求。本文顺应医疗、养老数据不断融合的大趋势,为医疗、养老机构更好地服务老人提供技术层面支撑,同时为涉老医疗监管,民政养老监管提供数据支持。随着大数据分析技术的发展,同时考虑到监管机构对数据分析决策的需求,下一步将在清洗融合数据的基础上,重点研究基于医养融合的数据分析技术,并与本文系统进行结合,进一步提高支撑监管机构决策的智能化的水平。2.2 语义元数据与数据清洗和融合
2.3 语义元数据与数据可视化和访问
3 系统实现和验证
3.1 系统设计与实现
3.2 应用案例

3.3 综合性能对比

4 结 语
猜你喜欢
现代经济信息(2022年22期)2022-11-13
北京航空航天大学学报(2022年8期)2022-08-31
中国医院院长(2022年10期)2022-07-01
中国典型病例大全(2022年10期)2022-05-10
现代信息科技(2021年21期)2021-05-07
现代盐化工(2019年6期)2019-09-10
金色年代(2016年1期)2016-10-21
电脑知识与技术(2016年10期)2016-06-16
长江学术(2016年4期)2016-03-11
长江学术(2015年1期)2015-02-27
