
触发词与属性值对联合抽取方法研究
2020-05-15 08:11汪瀛寰包先雨吴共庆
计算机工程与应用 2020年9期
汪瀛寰,薛 婵,包先雨,吴共庆
1.合肥工业大学 计算机与信息学院,合肥230601
2.深圳市检验检疫科学研究院,广东 深圳518045
1 引言
属性值对抽取属于信息抽取领域,是指从文本中识别出实体的属性和属性值并对二者进行关系匹配,它是文本结构化处理的核心关键技术。给定一个文本,传统属性值对抽取的任务在于从中识别出属性字符串xi和属性值字符串xj,并根据一些规则将它们匹配成属性值对(xi,xj),以将文本转化成结构化的形式,帮助用户快速获取语义信息。
属性值对抽取成功地应用在医学[1-2]、电子商务[3-5]等领域。属性值对抽取是推理应用的基础,如医学上的诊断解释[6-7]和智能化疗效分析[8],又如电子商务中常见的商品推荐系统[9-10]。此外,属性值对抽取也是知识库构建的基础[11-12]。然而,这些成功应用中所涉及的数据大都是短文本。
随着Web技术的发展,网络上出现大量的长文本数据。长文本中包含较多的冗余信息,这些冗余信息在帮助解释说明的同时,带来的是阅读效率降低。本文提出通过抽取属性值对完成长文本的结构化处理,以快速捕获核心内容。然而,冗余信息的存在造成传统属性值对抽取方法效率低下。此外,传统属性值对抽取方法仅限于抽取字符串属性,难以抽取二元语义属性。这里的字符串属性是指属性或属性值以字符串形式存在于文本中的属性,二元语义属性是指属性值为“是”或“否”的属性。
为此,引入触发词的概念,本文的触发词是指出现在描述属性句子中的关键词。反之,如果句子中不包含触发词,则其不可能描述属性信息。将含有触发词的句子定义为候选信息语句,将描述属性的句子定义为(真实)信息语句。因此,本文属性值对抽取主要包括两个任务。
(1)触发词识别:识别触发词,判定候选信息语句是否为(真实)信息语句。
(2)属性-值识别:从(真实)信息语句中识别出属性和属性值。
对于二元语义属性,只需要确定文本中存在信息语句即可确定属性值为“是”,故抽取任务只包括任务(1)。对于字符串属性,需要继续从信息语句中识别字符串属性和属性值,故抽取任务包括任务(1)和(2)。若将任务(1)和(2)看成顺序的过程,则(1)中出现的错误会延续至(2),致使触发词识别的效果决定了字符串属性值对抽取的总效果。考虑触发词、字符串属性和属性值在信息语句中的共现性,本文将三者的识别过程看作序列标注任务,基于条件随机场(Condition Random Field,CRF)建立字符串属性的联合标记模型。本文的主要贡献如下:
(1)将触发词引入属性值对的抽取方法中,考虑触发词、字符串属性和属性值间的相互依赖关系,基于CRF 建立触发词、字符串属性和属性值的联合标记模型,用于抽取长文本中的字符串属性-值对。
(2)通过建立触发词识别模型判断是否存在信息语句,以确定二元语义属性的取值,用于抽取长文本中的二元语义属性-值对。
(3)利用基于熵的特征排序方法挑选种子触发词,构建初始触发词表;并利用模型每次标注结果中新识别的触发词对触发词表进行迭代扩展。
2 相关工作
这一部分,将分别介绍属性值对抽取和触发词扩展的相关工作。
2.1 属性值对抽取
属性-值对抽取是指从文本中识别实体的属性和属性值并进行关系匹配的过程,它是处理碎片化知识并将其结构化的基础。目前已有的属性-值对抽取工作可以分为两类:基于规则的方法和基于机器学习的方法。
基于词汇-句法模式的抽取方法是典型的基于规则的方法。Raju 等[13]针对英文实体提出了“attribute of entity is value”的抽取模式。Bergsma 等[14]设计“my attribute is”的抽取规则,用于从社交媒体中抽取用户的属性-值对信息。Qiu 等人[15]根据Web 页面中数据的半结构化特征,提出“表格左列为属性,剩下列的合并为属性值”的抽取规则。基于规则的方法依赖领域专家建立规则表达式或要求数据以特定的结构出现,因此该方法缺乏兼容性和灵活性。
基于机器学习的方法是将属性或属性值看成命名实体,将识别过程视为分类或标注任务。文献[16]采用BIO 标签(Beginning-Inside-Outside tagging)标记训练集,并基于CRF 训练标注模型,成功地从产品标题中抽取了产品属性值。文献[1]利用CRF 标注模型在已知属性词语的上下文中识别属性值词语。刘倩等[17]将全局特征引入属性值的抽取问题中,通过捕获属性值边界分布等全局信息提高属性值的抽取精度。上述方法均在属性已知的前提下进行,未考虑从文本中直接抽取属性。文献[18]考虑属性和属性值的共现性,将属性和属性值的识别过程看作序列标注任务,训练序列标注模型,直接从产品说明中抽取字符串属性及属性值。文献[19]采用同样的方法,结合用户对产品的评价,抽取用户感兴趣的属性。以上工作所涉及的数据均是短文本数据。对于长文本的数据,文献[2]先借助SVM(Sup‐port Vector Machine)模型从文本中区分描述属性的语句和普通语句,然后利用CRF模型从描述属性的语句中识别出属性和属性值。但该方法的不同属性聚集在少数句子中,而长文本中不同属性分布在不同句子中,因数据特征离散化,难以借助SVM 进行区分。由于训练模型需要手工标注大量数据,文献[20]利用主动学习降低手工标注训练集的压力,同时提出一种基于递归神经网络捕获上下文及语义特征和基于CRF 模型进行序列标注的联合模型。Shen 等[21]基于属性和属性值的共现性,将语料库构建成一个共现图,借助领域知识库对共现图进行迭代更新,同时抽取新的属性和属性值。这些工作为后续研究提供思路。
以上工作都是针对字符串属性所做的研究,而对于二元语义属性不具备抽取能力。本文将触发词引入属性值对抽取方法中,通过匹配触发词获取长文本中的候选信息语句,借助触发词识别来确定二元语义属性的取值。此外,与传统字符串属性值对抽取方法相比,本文考虑触发词与字符串属性和属性值在信息语句中的共现性,构建基于触发词、字符串属性和属性值的联合标注模型,借助触发词识别对属性-值对识别的促进作用,提高字符串属性值对的抽取性能。
2.2 触发词扩展
事实上,触发词是事件抽取中的概念,用来指示事件的发生。在事件触发词扩展中,已有的工作大都利用预定义或自动聚类的同义词集推测新的触发词。Chen和Ji[22]结合自举框架,利用从英文事件系统中捕获的额外信息来扩展触发词。He 等[23]应用“同义词林”扩展触发词。Li 等[24]结合中文词语的组合语义提出一个用于识别新触发词的推理机制。这类扩展方法并未考虑词语所在上下文特征或者不同上下文中词义的差异问题,因此引入很多伪触发词。
本文将触发词识别看作序列标注任务,引入触发词的上下文特征,建立序列标注模型;并利用模型对真实数据集进行标注,由于模型的泛化能力可以识别到新触发词,以扩展原始触发词。
3 触发词与属性值对的联合抽取方法
针对长文本中存在的冗余信息和二元语义属性,本文将触发词引入属性值对抽取方法中,构建触发词识别模型,并设计一种触发词与属性值对的联合抽取方法TAVPE。该方法不仅具备二元语义属性值对的抽取能力,而且提高了传统字符串属性值对抽取方法的性能。该方法分为训练(TAVPE-Training)和抽取(TAVPEExtracting)两个阶段,如算法1和算法2所示。
算法1 TAVPE-Training
输入:TrainTxtSets
输出:TriggerTable,Models
1.TriggerTable←createTriggerTable();//触发词表Trigger-Table 结构如(Attribute,Type,TriggerSet),其中Type 指属性为“二元语义属性”还是“字符串属性”,TriggerSet初始化为空;
2.Models←∅//记录属性和相应的模型,形如(Attribute,Model)
3.InfoSens←manuallyLabelInfoSensbyAttributes(TrainTxt‐Sets);
4.InfoSenSets←classifybyAttribute(InfoSens)//InfoSenSets记录属性和信息语句集合的对应关系,形如(Attribute,Info-SenSet)
5.for eachrow in InfoSenSets
6.Attribute←row.getAttribute();
7.InfoSenSet←row.getInfoSenSet();
8.TriggerSet←generateTriggers(InfoSenSet);
9.addToTriggerTable(Attribute,TriggerSet);//依据属性将触发词集合加入触发词表中
10.model←buildModel(InfoSenSet);
11.addToModels(Attribute,model);
12.End for
13.return TriggerTable,Models
算法2 TAVPE-Extracting
输入:TriggerTable,Models,TestTxt
输出:AVPs
1.AVPs←∅
2.CanInfoSenSets←∅//记录属性和候选信息语句集合的对应关系,形如(Attribute,CanInfoSenSet),
3.TrueInfoSenSets←∅//记录属性和真实信息语句集合的对应关系,形如(Attribute,TrueInfoSenSet)
4.SensSet←splitSentences(TestTxt);
5.for each sentence in SensSet
6.for each row in TriggerTable
7.if sentence contains word∈row.getTriggerSet()
8.addToCanInfoSenSets(row.getAttribute(),sentence);
9.End for
10.End for
11.for eachrow in CanInfoSenSets
12.CanInfoSenSet←row.getCanInfoSenSet();
13.if CanInfoSenSet≠∅
14.Attribute←row.getAttribute();
15.preProcess(CanInfoSenSet)anduseModels.getModel(Attribute)to label it;
16.if(TriggerTable.getType(Attribute)==“二元语义属性”)
17.addToTrueInfoSenSets(Attribute,标注结果中包含“T”类标签的候选信息语句);
18.if(TriggerTable.getType(Attribute)==“字符串属性”)
19.addToTrueInfoSenSets(Attribute,标注结果中同时包含“T”、“A”和“V”类标签的候选信息语句);
20.End for
21.AVPs←extractAndExtension(TrueInfoSenSets,Trigger-Table);
22.return AVPs;
训练阶段的目的在于获取抽取阶段所需的触发词表及模型。对于给定的训练文本集,首先以属性为标签,手工标注文本中的信息语句,并依据属性对信息语句进行分类,形成各属性的信息语句集合;然后利用信息语句集合,结合基于熵的特征排序方法生成种子触发词,构建初始触发词表,具体如3.1 节所述;接着对信息语句集合进行预处理,并手工给预处理后的每个分块一个标签,构建各属性的训练集,最后基于CRF 训练各属性的序列标注模型,具体如3.2节所述。
抽取阶段的目的在于从给定的测试文本中抽取属性值对集合。首先对给定的测试文本进行分句处理,通过遍历并匹配触发词表中的触发词,获得各属性的候选信息语句集合;然后对候选信息语句集合进行预处理,并利用训练阶段获得的模型进行标注;挑选标注结果中包含触发词标签的句子加入真实信息语句集合;基于启发式规则从真实信息语句中抽取属性值对,并利用真实信息语句中新识别的触发词扩展初始触发词表,具体见3.3节所述。
3.1 生成触发词
本节对应算法1中的generateTriggers函数,本文选用文献[25]中基于熵的特征排序方法帮助生成种子触发词。
令P(p1p2… pN)表示一个属性的信息语句集合,考虑触发词中动词所占比例较大,令W(w1w2…wM)表示所有出现在P 中的动词集合,集合P 的熵定义如下:

其中,Si,j=-exp(α×Di,j)表示pi与pj间的相似度,Di,j表示pi与pj间的欧几里德距离,α=-ln 0.5/Dˉ,表示集合P中所有信息语句的平均距离。
数据集的熵描述数据集的聚集程度,聚集程度越高,可分性越好,熵值越小。因此基于熵的特征排序方法基于一个假设:如果一个特征提高数据可分性的程度越高,则该特征越重要。特征空间W 中每个词语Wi的重要性由从特征空间中移除特征Wi后数据集的熵定义。如果移除某个特征后造成数据集的熵最大,则这个特征是最重要的。因此利用以下方式计算每个词语的重要性:依次从特征空间W 中移除一个词语,利用公式(1)计算此时数据集的熵。依据数据集的熵由大到小的顺序对所移除的特征词语进行排序,抽取排名靠前的三个词语作为种子触发词。
3.2 建立模型
本节对应算法1 中的buildModel 函数。就二元语义属性而言,属性值由是否存在描述二元语义属性的信息语句决定,故属性值对抽取任务的核心在于判断由触发词定位的候选信息语句是否为真实信息语句。为此,本文将构建触发词识别模型,用于从候选信息语句中识别触发词以确定真实信息语句。考虑到触发词的上下文特征对于触发词识别具有促进作用,可以将触发词识别看作序列标注问题。就字符串属性而言,属性值对抽取任务包括触发词识别和属性-值识别。因触发词、字符串属性和属性值在信息语句中的共现性,三者互为局部上下文,本文将从信息语句中同时识别三者的过程看作序列标注问题。
CRF 是判别式概率模型,常用于解决序列标注问题。当给定输入节点的值时,通过计算并比较输出节点值的条件概率,确定最终的输出值。将输入序列看作单元节点X,输出序列表示成Y(Y1Y2…Yn),即构成图1所示为线性链条件随机场。根据公式(2)挑选使条件概率P(Y|X)最大的Y 作为输出序列。

其中,tk表示局部特征,sl表示节点特征,λk和θl分别表示两类特征的权重。

图1 线性链条件随机场模型
本文基于CRF 构建属性的序列标注模型。为获取模型的训练集,首先对各属性的信息语句集合进行预处理,将触发词词语标记为T(Trigger)。对于二元语义属性,将其他所有非触发词词语标记为N(Neither)。对于字符串属性,创建BME 标签,即根据预处理后的分词是词语的开始、中间和结尾分别手工标记为B(Begin-of)、M(Middle-of)和E(End-of),然后组合分词的类别标签,包括属性标签A(Attribute)和属性值标签V(Value),故字符串属性的标签包括{T,B-A,M-A,E-A,B-V,M-V,E-V,N}。利用训练集,对于二元语义属性,基于CRF训练触发词的序列标注模型,即触发词识别模型;对于字符串属性,基于CRF 训练触发词、属性和属性值的联合标注模型。
3.3 抽取及扩展
本节对应算法2 中的extractAndExtension 函数,目的在于完成属性值对的抽取及触发词的扩展工作。对于二元语义属性,若真实信息语句集合(TrueInfoSenSet)不为空,表示存在这类二元语义属性的信息语句,那么该二元语义属性的取值为“是”,否则取值为“否”。对字符串属性,遍历真实信息语句集合中的每个信息语句;从信息语句中抽取类别标签为“A”的词语按照“B-A+M-A+E-A”组合成属性,抽取类别标签为“V”的词语按照“B-V+M-V+E-V”组合成属性值,在以“,”或“;”为分隔的短句中完成属性和属性值的匹配。
此外,对于各属性的信息语句中标签为“T”的词语,如果该词语不在触发词表该属性对应的触发词集合中,说明是新识别出的触发词,则将其加入触发词集合中,完成触发词表的一次迭代更新。并且每次利用TAVPE-Extracting 进行属性值对抽取时,都使用最新的触发词表。
3.4 时间复杂度分析
CRF在训练阶段借助向前-向后算法,其时间复杂度为O(TSL2)[26],在预测阶段借助维特比算法,其时间复杂度为O(SL2)[27],其中S表示待标记序列的长度,T表示待标记序列每个位置上的特征数,L表示类别标签种类数。
算法1 的时间复杂度依赖于generateTriggers 函数和buidlModel 函数。假定Num 为InfoSenSets 的行数,N 为属性所对应的信息语句数,M 为信息语句中的动词个数,如果将两个句子的相似度计算看作一个单元,则generateTriggers 函 数 的 时 间 复 杂 度 为O(MN2);buidl‐Model函数建立触发词识别模型时L=2,建立联合标记模型时L=8,与N 相比数量级较小,可忽略不计。故算法1 的时间复杂度取决于generateTriggers 函数,为O(NumMN2)。
在算法2 中,令Ntt表示TestTxt 的句子总数,Col 表示TriggerTable 的行数,C 表示其中的触发词总个数,步骤5~10 是为了获取CanInfoSenSets,其时间复杂度为O(NttC);CanInfoSenSets 的行数≤Col,CanInfoSenSet 的集合大小≤Ntt,步骤11~20 利用算法1 所训练的CRF 模型对CanInfoSenSets 中的每个CanInfoSenSet 集合进行标注,已知CRF 在预测阶段的时间复杂度为O(SL2),故此时算法2的最坏时间复杂度为O(Col×Ntt×SL2)。
4 实验结果与分析
本文挑选法律领域的司法判决书作为实验语料。司法判决书是基于判决结果书写的文书,其主要包括六个部分:基本信息、法律角色、起诉书、案情信息、证据和判决结果。其中案情信息富含丰富的法律知识,但也包含冗余信息,因此可以将司法判决书中的案情信息看作一类长文本数据。
考虑当前不存在“司法判决书”的公开训练语料,本文利用爬虫技术从“中国裁判文书网(http://wenshu.court.gov.cn)”爬取不同地区不同法院发布的与机动车事故相关的司法判决书。随机选取1 200 篇,借助抽取规则对司法判决书进行篇章拆分,保留其中的案情信息部分,形成本文的实验语料,并按照10∶2 的比例分成训练语料和测试语料。
利用1 200篇机动车事故司法判决书的“案情信息”和“证据”部分,分别对两部分内容中用于描述属性的句子进行统计。发现包含描述“投保类型”句子的“案情信息”占总量的89.5%,包含描述“主体责任”的占88.33%,包含描述“伤残等级”的占40.75%,这3个属性是机动车事故司法判决书案情信息部分最常出现的字符串属性;包含描述“是否造成死亡”的占15.75%,是常见的二元语义属性;此外,这4 个属性的描述句在“证据”部分也较为常见,可以认为这4 个属性是法院对机动车事故类型案件进行判决的重要依据,因此本文以从案情信息中抽取这4 个属性为例,验证所提方法的有效性。首先以属性为标签手工标记训练语料中的信息语句;抽取信息语句并依据属性分类;利用基于熵的特征排序方法获得触发词表,如表1 所示;借助哈工大的LTP 工具[28],对训练语料进行分词、词性标注和依存句法分析,得到特征向量集合;给每个特征向量手工标记一个标签,形成本文的训练集。对于诸如“投保类型”、“主体责任”和“伤残等级”等字符串属性,标签包括:{T,B-A,M-A,E-A,B-V,M-V,E-V,N};对于“是否造成死亡”等二元语义属性,标签包括:{T,N}。

表1 初始触发词表
4.1 实验设置
本文利用“CRF++(https://taku910.github.io/crfpp/)”工具训练模型,该工具需要指定特征模板。从预处理获得的训练集来看,现有的特征类型包括词语、词性和依存句法关系。根据分析这些特征类型,本文确定以下特征:(1)当前词语;(2)前后两个词语;(3)当前词语的词性;(4)前后两个词语的词性;(5)依存句法关系;(6)前后两个词语的依存句法关系。本文从一元特征开始,先后添加了特征(1)、(3)、(5);又将特征扩展到多元,先后加入特征(2)、(4)、(6)。此外,本文尝试了加入词性联合依存关系特征,构成多元交叉特征模板。表2 为本文所设计的5个特征模板。

表2 特征模板
CRF++工具利用参数c来平衡拟合程度。为了提高序列标注模型的标注效果,本文基于不同模板,选择不同的特征和参数进行实验,采用十倍交叉验证的方法,将训练集均分为10 份,选取一份作为验证集检测模型性能。图2 是实验结果,从图中可以看出,当选用模板5且参数c=1.5时错误率最低。
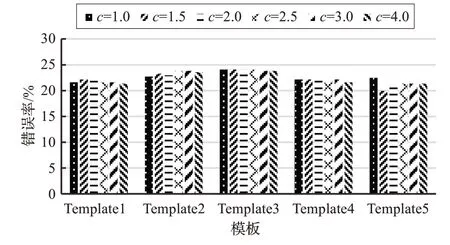
图2 模板及参数调整
4.2 评估准则
本文通过准确率(Precision)、召回率(Recall)和综合指标F值(F-measure)评估系统的处理效果。

Nr是正确抽取的司法判决书案情信息文本数,Nc是错误抽取的文本数,Nnum是处理的案情信息文本总数。
4.3 对比实验
为了凸显触发词和联合标记模型的贡献性,本文设计了两组对比实验。
对比实验1(basicCRF):不使用触发词,针对字符串属性,训练基于属性和属性值的序列标注模型,直接利用模型对案情信息文本进行标注。这类方法对二元语义属性不具备抽取能力。
对比实验2(Trigger+CRF):将触发词识别和属性值对识别看作两个顺序的过程。针对字符串属性,分别训练触发词识别模型和基于属性和属性值的序列标注模型。借助触发词表定位文本中的候选信息语句后,利用触发词识别模型标记候选信息语句,从中识别真实信息语句;再利用序列标注模型对真实信息语句进行标注。针对二元语义属性,同本文所提方法一致。
4.4 性能分析
本节主要考察本文算法TAVPE 的两个实验性能,即TAVPE 算法在长文本中的属性值对抽取性能和时间开销。
表3给出TAVPE与对比方法的实验结果,由实验结果可知:
(1)与basicCRF 相比,引入触发词后的Trigger+CRF 和TAVPE 算法能够抽取二元语义属性,并且在抽取字符串属性时准确率、召回率和F 值都有提高。原因在于未使用触发词的basicCRF 方法不具备二元语义属性的抽取能力,此外由于利用模型对案情信息的全部内容进行标注,抽取到很多不相关的信息,从而导致准确率较低。
(2)与Trigger+CRF 相比,TAVPE 算法在抽取精度上有所改进。原因在于Trigger+CRF 方法使用了管道模型,使得触发词识别的错误延续至属性-值对识别。而TAVPE 方法中的联合标记模型考虑到触发词、字符串属性和属性值在信息语句中的共现性,借助触发词识别对属性-值对识别的促进作用,提高了字符串属性值对的抽取性能。

表3 实验结果
图3 给出三种算法的时间性能比较。由实验结果可知:
(1)相比于basicCRF 方法,TAVPE 算法的耗时明显缩短,并且随着数据量的增加,两者运行时间差距增大。原因在于basicCRF 没有引入触发词,需要对案情信息的全部内容进行预处理;而TAVPE 算法利用触发词获取案情信息中的候选信息语句集合,仅需对候选信息语句进行预处理,从而节省了运行时间。
(2)与Trigger+CRF 相比,TAVPE 算法的耗时稍有缩短。原因在于当抽取字符串属性-值对时,Trigger+CRF 方法将触发词识别和属性-值对识别看成两个顺序的过程,过程间存在时间延迟;而TAVPE 算法将触发词、属性和属性值识别视作一个序列标注过程,从而节省了运行时间。
由此可见,触发词与属性值对的联合抽取方法不仅具备二元语义属性的抽取能力,而且提高了字符串属性值对的抽取性能和抽取效率。

图3 不同数据集规模下的运行时间
5 总结
本文基于CRF 提出一种触发词与属性值对的联合抽取方法。该方法借助基于熵的特征排序方法构建触发词表,过滤长文本中的冗余信息,提高属性值对的抽取效率;不仅通过构建触发词识别模型识别信息语句,确定二元语义属性的取值,因而具备二元语义属性值对的抽取能力;而且利用触发词、字符串属性和属性值的共现性,借助触发词识别对属性-值对识别的促进作用,提高了字符串属性值对的抽取性能。
然而,随着触发词表的扩展,抽取阶段将定位到更多不相关的候选信息语句,使得预处理时间增加,抽取效率降低。另外,基于CRF 训练模型需要扩展训练集,而手工标注的过程是费时费力的。因此,未来计划从以下两方面扩展实验:(1)通过计算候选信息语句与信息语句的相似度排除不相关的候选信息语句;(2)借助半监督方法充分利用未标注的训练语料,降低手工标注的工作量。
猜你喜欢
无线互联科技(2020年11期)2020-12-01
新世纪智能(语文备考)(2020年4期)2020-07-25
开放教育研究(2020年2期)2020-03-31
中国修辞(2017年0期)2017-01-31
科教导刊·电子版(2016年30期)2016-12-26
中国社会历史评论(2016年2期)2016-06-27
长江学术(2016年4期)2016-03-11
中国信息技术教育(2015年21期)2015-09-10
小学生·多元智能大王(2014年6期)2014-07-09
通信学报(2014年12期)2014-01-01
