
基于卷积神经网络的电力操作票文字识别方法
2020-05-06 14:47:00
浙江电力 2020年4期
(国网浙江省电力有限公司舟山供电公司,浙江 舟山 316021)
0 引言
随着移动设备新技术的发展,文档图像获取途径突破了扫描仪的限制,手机拍摄越来越受到欢迎。在电力运维检修现场,手机拍摄操作票更方便快捷。与扫描仪得到的干净规整图像不同,手机拍摄的文档图像存在光照变化强烈、清晰度低、笔迹潦草等特点。手写字体与印刷字体差异性大,书写习惯因人而异,缺乏规范性,横竖不直、撇捺不斜、笔画不清等加大了文字识别的难度[1]。OCR(传统光学字符识别)技术能够准确识别清晰成像的操作票印刷文字,但在其他场景,尤其是手写字体的识别上存在较大困难,为实现操作票电子化管理带来了挑战。20 世纪90 年代,深度学习神经网络模型受到了学术界的重视,逐渐发展成熟,在自然语言处理、模式识别、图像识别等领域涌现了大量前沿方法。DBN(深度信念网络)[2]、SAE(堆叠自动编码器)[3]、CNN(卷积神经网络)[4-5]、RNN(循环神经网络)[6]等方法为文字识别难题提供了新的解决思路。近年来,研究者提出了很多基于深度学习的文字识别方法。针对卷积神经网络,本文将文字识别方法归纳为以下3 类。
一是直接基于CNN 的文字识别方法:使用手写汉字图片样本集,通过CNN 方法直接训练得到文字分类模型,用于文字识别。
Ciresan 等人[7]第一次提出使用CNN 方法训练文字分类模型,实现了其在大类别手写汉字识别应用,准确度远高于SVM,Boosting,MLP 等传统机器学习方法。Ciresan 等人后续进一步改进文字识别方法[8],训练7 个CNN 模型构建的委员会方法,在MNIST 数据集上降低识别错误率到0.27%,取得了很好的结果。MCDNN 方法是一种多列CNN 模型[9],其与多CNN 模型集成方法类似,但调整了CNN 网络结构(每个CNN 网络含4个卷积层、4 个池化层和1 个全连接层),仅训练获胜者神经元,多列CNN 模型以不同的方式预处理样本输入,以简单平均法计算最终分类结果。
此类方法仅使用CNN 方法直接训练文字分类模型,训练高效、设计简单。但是,CNN 方法在训练的过程中仅能学习到图像表面特征,无法学习笔迹方向变化、起笔落笔状态等特征。此类方法的识别性能有待进一步提高。
二是结合领域知识的CNN 文字识别方法:从书写的角度考虑手写字体存在的笔迹变化等特征,解决CNN 方法无法学习获得的问题。
文献[10-13]为了克服训练CNN 模型过拟合问题,提出了一系列文字变形方法,丰富训练样本,提升文字识别能力。LeCun 等人提出一种GTN(图像变形网络),处理平面图像的平移、缩放、旋转、拉伸等特征,能够有效识别变形字体[10]。Simard 等人[11]提出仿射变形与弹性变形两种文字变形方法,扩增训练样本,最终构建出一种简单通用的CNN 文字分类模型。提出了分别沿X轴、Y 轴等角度文字变形方法,实验证明了其对文字识别模型训练的有效性[12]。Bastien 等人提出了一种强大的文字随机变形与噪声生成器方法,不仅包括仿射变换,还包括倾斜的局部弹性变形,厚度变化,灰度变化,对比度变化等各种噪音类型干扰[13]。与传统机器学习方法相比,深度学习方法从图形变换中增益较大。
文献[14-16]从训练样本中学习手写字体笔迹特征,包括方向变化等特征,此类笔迹特征作为CNN 方法的附加输入参与训练。Okamoto 等人引入假想笔画特征,提取笔画方向变化特征,以提升手写字体的识别性能[14]。Graham 提出了一种通过数学微积分计算笔迹的梯度特征方法,有效获取了手写字体位移、曲率等信息[15]。Bai 和Huo扩展汉字横、竖、撇、捺4 个方向到8 个方向,分别提取手写字体方向特征[16]。上述3 种笔迹特征方法被广泛应用于文字识别领域。
三是其他改进的CNN 文字识别方法:优化CNN 的网络结构、训练方法和参数设置,提升CNN 模型的识别准确度。
Graham 提出了一种FMP(分数池化方法)[17]。常规CNN 大多使用α×α(一般情况下,α=2)最大池化矩阵,而FMP 方法则可以使用取值为分数的α。FMP 的想法是将图像的空间尺寸减小到1<α<2。与随机池化类似,FMP 在池化过程中也引入了一定程度的随机性。不同的是,FMP 的随机性与池区域的选择有关,而不是每个池化区域内执行池化。FMP 方法有效减少了CNN 在各种数据集上的过度拟合几率。Yang 等人提出了一种新的深度学习模型训练方法DropSample[18]。Drop-Sample 方法定义了一个配额函数,此函数根据CNN 的全连接层(softmax 输出层)给出分类置信度。经过学习迭代后,低置信度样本将大概率地被选择为训练数据,而高置信度样本将较少地参与后续训练。最后,随着学习迭代进行,模型训练将变得更加高效。Wu 等人提出了一种R-CNN(基于松弛卷积神经网络)和ATR-CNN(交替训练的松弛卷积神经网络)的手写字体识别方法[19]。与传统方法的卷积层不同,R-CNN 中采用的松弛卷积层不需要特征图中的神经元共享相同的卷积核,赋予了神经网络更多的表达能力。由于松弛卷积大大增加了参数总数,作者使用ATR-CNN方法来规范化神经网络。ATR-CNN 方法在MNIST数据集上取得了较低的错误率(0.25%)。
上述三类方法从CNN 的应用、笔迹特征提取、训练方法等不同角度出发,提出了适用于手写字体识别的有效方法。但是,这些方法均未考虑低质量样本图像、笔迹特征集成对文字识别带来的影响。为解决操作票样本图像质量,融合多笔迹特征问题,本文提出了一种CBTR(基于卷积神经网络的文字识别)方法。本文主要工作如下:
(1)提出了一种基于CNN 的图像增强方法,其仅包含三层卷积层网络,无池化层、全连接层,该模型的训练目的是学习得到非线性映射函数,输出PSNR(高峰值信噪比)图像[20]。
(2)提出了一种基于笔迹特征的集成卷积网络模型,该模型结构参考DeepCNet 网络[22],主要区别是本文模型精简了网络层次,以提升模型训练效率;同时引入多种笔迹特征,代替原图输入,克服CNN 受限于原图的空间特征学习,提升手写字体识别的准确度。
(3)在实际运维检修中操作票图像样本集上进行实验,实验结果证明了本文方法的有效性。
1 基于CNN 算法的电力操作票文字识别
本文提出的CBTR 是一种基于CNN 算法的电力操作票文字识别方法,其总体流程如图1 所示,分为4 个步骤:
(1)样本图片作为训练数据集,构建自定义三层卷积网络模型,训练输出非线性映射函数。
(2)测试图片作为非线性映射函数输入,得到具有高PSNR 值的测试图片。
(3)样本图片作为训练数据集,构建基于假想笔画、路径签名与8 方向特征的集成CNN 模型,训练得到分类模型。
(4)测试图片作为分类模型的输入,使用简单平均法计算分类结果。
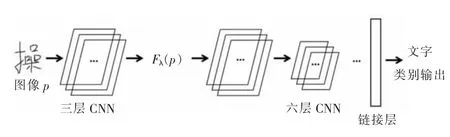
图1 CBTR 方法流程
1.1 基于CNN 的图像增强
手机拍摄电力操作票时,光线、角度、像素均会影响图像成像的清晰度。若图像的清晰度较低,将严重影响文字识别的准确度。针对低清晰度图像文字识别困难问题,构建特殊的CNN 模型,即基于CNN 的图像增强方法,其仅包含三层卷积层网络,无池化层、全连接层,并选择激活函数ReLU[21],步长设置为1,不对卷积运算填充0,网络架构如表1 所示。
该模型的训练目的是学习得到非线性映射函数Fλ(pi),若给定一张低清晰度图像pi,使用Fλ(pi)得到高清晰度图像Pi的PSNR 值,与真实图像Ti的PSNR 值相比较,能够获得最小F 范数。因此,该模型的损失函数定义为:

表1 基于CNN 的图像模型架构
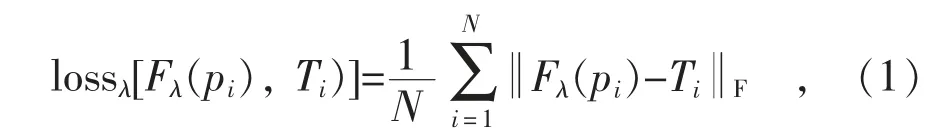
式中:N 是训练集图片样本总数,1≤i≤N。
本文选择PSNR 指标评价图像质量,即通过非线性映射函数Fλ(pi)可以得到拥有高PSNR 值的输出图像。若定义训练数据集S={(pi,Ti):1≤i≤N},则该模型可表示为λ={Wj,bj}。其中Wj={:1≤k≤nj},为卷积网络第j 层的卷积矩阵,bj为偏差值,nj为卷积网络第j 层的卷积核个数。表2 给出了本文图像增强方法的伪代码。给定一个低清晰度图像pi,具体执行步骤如下:
(1)1-5 行:对于任意一个低清晰度图像pi,通过卷积运算得到中间结果,再使用ReLU 函数计算得到高PSNR 值图像Zj。
(2)6-7 行:结束三层卷积网络运算,返回高PSNR 值图像结果Fλ(pi)。

表2 基于CNN 的图像增强的伪代码
1.2 基于笔迹特征的集成卷积网络模型
电力操作票存在较多手写字体,包括发令人、受令人签字,时间、操作项目等内容。手写字体书写风格因人而异,字体结构复杂、种类繁多,加大了电力操作票文字识别的难度。针对手写字体特点,本文提出一种基于笔迹特征的集成卷积网络模型,模型结构参考DeepCNet 网络,主要区别是本文模型精简了网络层次,以提升模型训练效率;同时引入多种笔迹特征,代替原图输入,克服CNN 受限于原图的空间特征学习,提升手写字体识别的准确度。
集成CNN 模型架构如表3 所示,表中N 的含义是笔迹特征的维度。该模型包含6 层卷积网络,前5 层卷积网络下一层均配置池化层,第6 层卷积网络的下一层配置全连接层。第1 层卷积网络的卷积核大小设置为3×3,卷积核个数为80,且依次递增80;第2~6 层卷积网络的卷积核大小设置为2×2;选择补0 卷积运算,步长取1。池化层矩阵大小均为2×2。需要学习的参数约有400万,小于DeepCNet 网络的590 万,提升了模型训练效率。
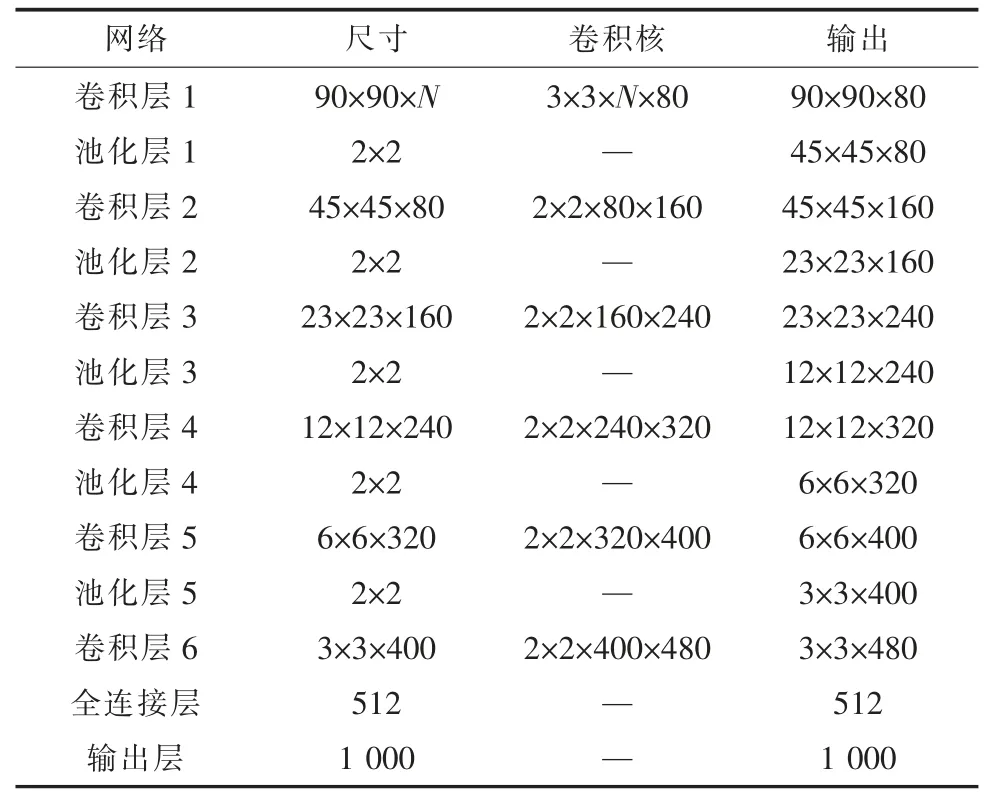
表3 基于CNN 的图像模型架构
笔迹特征矩阵是该模型第1 层卷积网络的输入,下文将详细介绍假想笔画、路径签名与8 方向特征3 种笔迹特征矩阵的计算方法。
1.2.1 假想笔画
汉字在书写过程中会涉及起笔、落笔、不同笔画相连等特点。同一汉字的笔形运动轨迹相似,方向变化一致。假想笔画[14]提取同一汉字不同笔画起落笔之间的方向变化特征,达到识别手写字体目的。该方法使用方向变化程度计算不同笔画之间的相关度。若相连笔画越短、方向变化越大,则为强特征。强特征能够有效标识汉字的书写特征。方向变化程度dcd 计算公式为:

式中:θ 为不同笔画之间相连构成的夹角度数(180≤θ≤180),l 为笔画长度,ml=64,w=1/8。比较不同像素点dcd 的值,计算得到假想笔画矩阵,并作为集成卷积神经网络模型的输入。电力操作票中的“操”字,笔画多且结构复杂,图2 给出其笔画变化特征示例,特征像素点由黑色小矩形框标出。
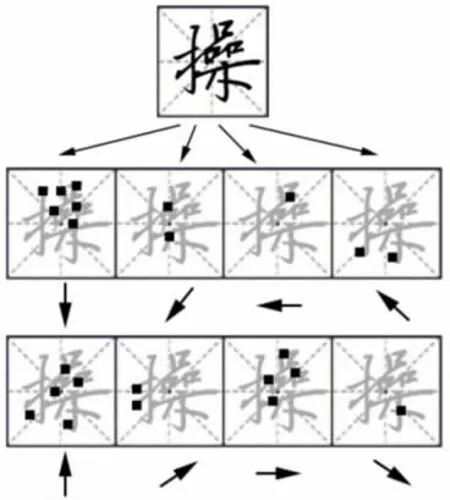
图2 “操”字笔画变化特征示例
1.2.2 路径签名
路径签名特征[15]从数学微积分的角度,计算手写字体的连续曲率,以捕获笔画轨迹特征。文献[16,24]等指出路径签名特征提取的笔迹方向信息及梯度变化信息更为丰富完整。因此,本文选择路径签名特征作为集成卷积网络模型的重要输入,提升CBTR 方法的泛化能力。
假设给定一个手写汉字,笔迹起止区间为[s,t],其k 重积分特征定义为:
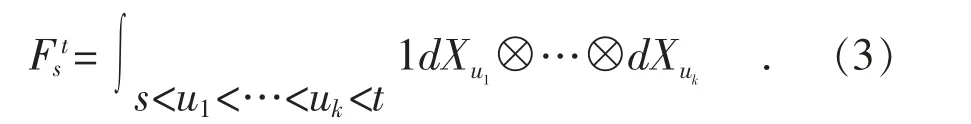
若k=0,则0 重积分特征计算结果为1,表示笔迹的二值图像特征;若k=1,则1 重积分特征表示笔迹的位移特征;若k=2,则2 重积分特征表示笔迹的曲率特征。k 值可取任意值,正常情况下不宜取值太大,否则会导致计算复杂度指数级增加,却不能获取更多有效笔迹特征。路径签名特征还可拼接两条有限长路径,得到一条长路径多重积分特征,计算示例如图3 所示。
1.2.3 8 方向特征

图3 “操”字路径拼接计算示例
汉字主要由横(—)、竖(|)、撇(/)、捺()构成,与英文等字母类构成的文字不同,汉字有明显的方向特征。8 方向特征[16]能够出色地拟合汉字的横、竖、撇、捺等笔画。假设给定一个二维坐标,8 方向特征分别从0°,45°,90°,135°,180°,225°,270°,315°计算笔迹梯度大小。给定一段笔迹的起止坐标(x1,y1)与(x2,y2),梯度计算公式为:
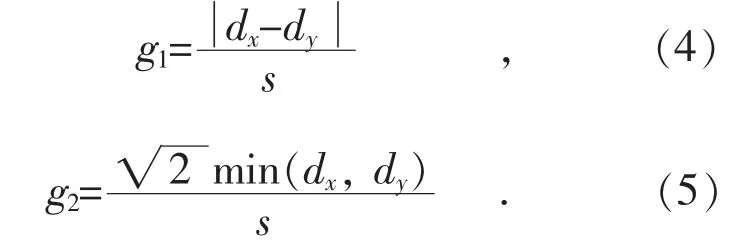

图4 “操”字8 方向特征计算示例
2 实验验证
2.1 数据集
本文使用的测试数据集来自国网浙江省电力有限公司某供电公司在运维检修中采集到的电力操作票图像。测试数据集共计10 万张高清晰度图像和经过压缩后的10 万张低清晰度图像,高清晰度图像与低清晰度图像一一对应,高清晰度图像的PSNR 值是本文图像增强方法的学习标签,低清晰度图像作为本文图像增强方法与CBTR 方法的输入。测试数据集包含1 000 个常用汉字,分别来自100 位书写者。本文在Tensorflow 框架下实现CBTR 方法,算法运行的硬件配置如表4所示。

表4 算法运行硬件配置
2.2 实验设置
表3 给出了6 层集成卷积神经网络模型,实验过程中设置每个卷积层后的dropout 比率为:0,0,0,0,0.05,0.1,训练过程的mini-batch 大小为96,路径签名中k=2。训练数据集与验证数据集分别按80%,20%分配。
2.3 评价指标
评价指标是针对将相同的数据输入不同的算法模型,或者输入不同参数的同一种算法模型,而给出这个算法模型或者参数好坏的定量指标。本文分别选择峰值信噪比和精度作为评价指标。峰值信噪比,即原图像与处理图像之间均方误差的对数值。对于2 张灰度图像K 和L,则二者之间的均方误差定义为:
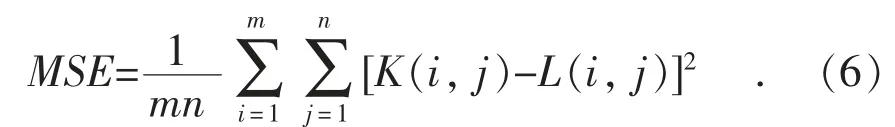
峰值信噪比定义为:
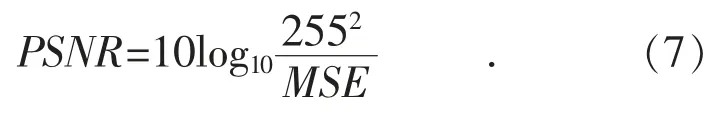
精度,即分类正确的样本数占总样本书的比例[23]。对样例集D,xi∈D(i≤m),fxi,yi分别表示预测分类值与实际分类值,则精度定义为:
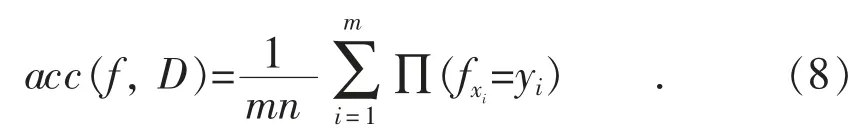
2.4 实验结果与分析
2.4.1 图像增强方法有效性验证
表5 给出了图像增强方法实验对比结果,对比所有验证集原始图像的平均PSNR 值与增强后图像的平均PSNR 值。本文提出的图像增强方法简写为CBIE,未使用图像增强方法处理低清晰度图像的原始方法记为Low-input。实验结果表明CBIE 方法能够提升PSNR 值8.35 dB,有效提升了图像质量,降低图像噪声对文字识别准确度造成的影响。

表5 图像增强方法实验对比结果
2.4.2 CBTR 方法有效性验证
DLQDF[25]和MCDNN[9]方法是经典的文字识别方法,DeepCNet[22]方法是近年表现较好的一种基于CNN 的文字识别方法。因此,本文选择上述3 种方法作为实验基准方法。其中CBTR-none 表示仅使用CNN 模型训练学习;CBTR-ie 表示仅包含图像增强方法的CNN 模型;CBTR-ps 表示包括路径签名的CBTR 方法;CBTR-ps-8dir 表示不包括假想笔画特征的CBTR 方法;CBTR-ps-is表示不包括8 方向特征的CBTR 方法;CBTR 方法则为本文完整集成CNN 模型,包括假想笔画、路径签名和8 方向特征。实验结果如表6 所示,表中最后一列为模型评价指标精度。

表6 文字识别方法实验对比结果
从表6 可以看出,CBTR 方法显著优于各基准方法。相较于DLQDF,MCDNN 与DeepCNet 方法,CBTR 方法的精度分别平均提升了5.82%,5.38%与3.24%。DeepCNet 与CBTR-ie 方法明显优于另外两个基准方法,表明深度学习方法在文字识别领域具有优越性。其中,CBTR-ie 方法的精度仅稍好于DLQDF 与MCDNN 方法。与CBTR-none 方法相比,CBTR-ie 方法的精度提升了1%,证明了本文提出的图像增强方法的有效性。CBTR-ps-8dir 方法的精度略高于CBTR-ps 方法。虽然路径签名方法通过数学微积分的计算,已经得到了笔迹特征的方向信息,但其无法涵盖更多方向,如8 个方向的所有笔画方向特征。因此,路径签名方法与8 方向特征方法的融合,能够相互互补,精度提升了0.14%。此外,路径签名方法与假想笔画的融合,精度提升了0.31%,表明假想笔画得到的起笔、落笔特征在文字识别中提供了较高的区分度。最后,通过结合所有这些笔迹特征,CBTR 方法实现了高精度93.41%。
对比不同方法的运行效率,传统方法DLQDF的平均每张图像处理时间远低于其他基于卷积神经网络的方法,处理时间低至2.4 ms。这是由于DLQDF 仅依赖于笔迹特征计算,不需要模型训练,提升了方法的运行效率。DeepCNet 方法的处理时间高于其他方法,归因于其自身复杂的训练网络。CBTR 方法精简了DeepCNet 网络,平均每张图像处理时间为30.08 ms,比DeepCNet 方法的处理时间降低了13.44%,较好地兼顾了处理时间与精度。
假想笔画、路径签名和8 方向特征分别作为特征矩阵输入,将输出3 种CNN 结果。CBTR 方法采用结合策略计算预测结果。表7 给出了本文集成CNN 算法使用不同结合策略的实验对比结果。结合策略主要有3 种:平均法、投票法与学习法。本文实验则对比了简单平均法与简单投票法的对比结果,学习法将在未来进一步探索。其中,CBTR-avg 表示使用简单平均法的结合策略;CBTR-vot 表示使用简单投票法的结合策略。从实验结果可以看出,CBTR-avg 方法的精度高于CBTR-vot 方法,简单平均法更适用于本文场景。

表7 不同结合策略的CBTR 方法实验对比结果
3 结论
本文针对电力操作票图像文字识别,提出了一种基于CNN 的电力操作票文字识别方法,能够实现操作票图像“清晰度增强、文字准确识别”的功能。该方法具有如下特点:
(1)使用自定义三层CNN 训练得到非线性映射函数,输出高PSNR 值图像,便于后续文字的准确识别。
(2)通过融合假想笔画、路径签名与8 方向特征等笔迹特征,构建集成CNN 模型,最后通过简单平均法计算文字分类结果,提升了文字识别的准确度。
(3)在实际运维检修中操作票图像样本及数据集上进行实验,实验结果证明了图像增强、笔迹特征均能提升CNN 模型的性能。
猜你喜欢
学苑创造·A版(2024年5期)2024-06-10 21:55:57
故事作文·低年级(2021年12期)2021-12-21 23:04:39
——识记“己”“已”“巳”
小学生学习指导(低年级)(2020年12期)2021-01-16 08:28:52
学生天地(2020年14期)2020-08-25 09:21:06
作文成功之路·小学版(2020年7期)2020-08-24 08:19:18
电子制作(2018年18期)2018-11-14 01:48:08
小天使·二年级语数英综合(2018年10期)2018-10-15 09:20:10
创新作文(小学版)(2017年5期)2017-05-13 06:16:30
科学与财富(2017年4期)2017-03-18 11:14:32
职工法律天地·下半月(2015年9期)2015-11-17 10:28:02
