
基于随机森林算法的95598 投诉预测方法研究
2020-05-06 14:46:58李鹏鹏周丹阳姜朝明喻湄霁
浙江电力 2020年4期
李鹏鹏,周丹阳,姜朝明,喻湄霁,刘 伟,王 涛
(1.国网浙江省电力有限公司台州供电公司,浙江 台州 318000;2.西华大学 电气与电子信息学院,成都 610039)
0 引言
用户评价是企业内部评估自身服务状况,改善用户体验的重要渠道。国家电网有限公司(以下简称“国网公司”)作为供电服务类企业,对投诉工单尤为敏感。如何减少投诉工单,已成为国网公司的重要课题之一。在实际生产中,投诉工单有较少部分为直接投诉工单,更多的则是由其他非投诉工单向投诉工单转化的转化投诉工单。直接投诉工单能够利用投诉行为特征被预测,但很难在直接投诉发生之前采取有效措施,因此直接投诉工单的预测结果可作为国网公司后期分析服务漏洞的重要参考。而转化投诉工单占比较大,实现转化工单的有效预测既可以对投诉风险提前预警,通过采取有效措施减少潜在投诉风险,又可以发现服务过程中的薄弱环节。但转化投诉工单成因复杂,受技术发展、工单数据采集等因素制约,难以实现对其有效预测。人工智能技术的发展使复杂的投诉工单预测成为了可能。而本文所关注的投诉工单预测问题本身也是一种分类问题,适合用人工智能技术中的分类算法进行建模与求解。因此,以95598 历史工单数据为基础,借助于人工智能算法构建投诉风险预警模型,对于提升电力公司的服务水平意义重大。
目前,部分基于人工智能的经典数据挖掘算法已被应用于投诉风险预警领域,如文献[1]在考虑文本词频权重的情况下,提出了一种TFIDF 特征加权优化算法对95598 投诉工单进行分类,但其仅局限于通过词频选取各投诉工单的关键因素,未能实现有效预警。文献[2]采用了深度学习模型来识别疑似投诉工单,进而实现投诉工单风险预警,但尚未考虑转化工单导致投诉的情况。此外,就模型而言,由于深度学习模型复杂,需要大量的计算性能来构建,而对于小数据集的简单问题,在计算开销和时间相同的情况下,深度学习方法并没有比其他数据挖掘方法体现出足够的优势。文献[3]提出了一种基于多模型的投诉风险预警方法,通过分析客户历史诉求和停电相关数据,利用了多种模型进行预测,并采用加权方法融合决策结果,以实现良好的预测效果。该方法虽然具有良好的计算开销与时间开销,但是不同模型之间的权重设置具有主观性与不可解释性。此外,支持向量机[4]、神经网络[5]、随机森林[6]和贝叶斯网络[7]等人工智能算法在预测领域都较为活跃,其中随机森林作为一种优秀的分类算法,在分类预测应用领域具有较为突出的综合性能[8-11]。
本文在考虑转化投诉工单的情况下,提出一种基于随机森林算法的投诉风险预测方法。在完成95598 历史工单数据预处理的情况下,利用历史工单的供电地区、时间、天气、前期工单事因、重复来电和投诉倾向等因素构建投诉行为特征。通过提取历史工单数据中的投诉行为特征,完成对基于随机森林的投诉风险预警模型训练,最终实现对直接投诉工单与转化投诉工单的预测。
1 随机森林理论
1.1 随机森林理论概述
随机森林[12]作为数据挖掘技术中的一种集成分类器,其旨在从数据样本中构造随机决策树模型以获得单个分类器结果,再综合单个随机决策树模型,获得随机森林模型。随机森林的构造过程如图1 所示,其主要步骤包括[13]:
(1)抽取子样本。采用bootstrap 抽样方法,随机可重复取样,形成新的子样本数据集。
(2)建立子决策树。对每个含有M 个特征变量子样本训练集,随机方法抽取m(m<M)个特征,构造建立分类回归树。
(3)建立随机森林模型。重复步骤(1)和(2),得到K 个决策树,形成随机森林。
(4)投票分类。结合K 个决策树的预测结果,采用投票方式选出最优分类。
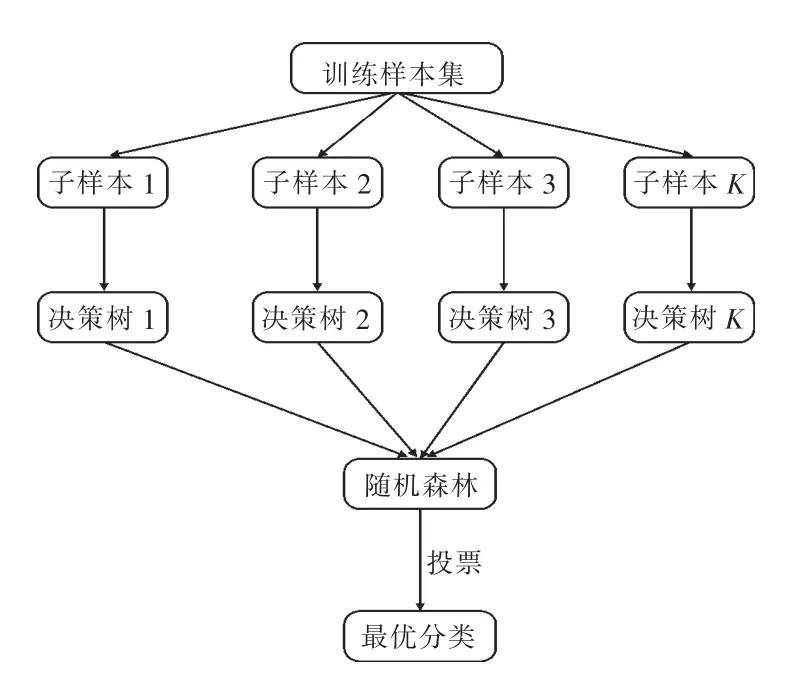
图1 随机森林的构造过程
1.2 随机森林算法
随机森林预测算法的实现过程见表1。

表1 随机森林算法
2 基于随机森林的95598 投诉预测方法
为实现对95598 投诉工单的“先知先觉”,增强电力服务部门对投诉工单的预警能力,并基于此开展针对性更强的服务改善,以提高电力服务水平,本节根据95598 各类工单成因的特点,提出一种基于随机森林算法的95598 投诉预测方法。该方法主要步骤如下:
步骤一:95598 历史工单数据预处理。对历史工单数据进行数据预处理,其主要步骤包括:数据投诉工单、数据清洗与数据集成。通过对目标城市历史工单生数据进行处理,提供投诉工单成因挖掘模型所需的数据。
步骤二:投诉行为特征提取。对步骤一中经过预处理的历史工单数据,进行数据分析并提取投诉行为特征。
步骤三:建立基于随机森林的投诉预测模型。基于步骤二中提取的各投诉行为特征,建立基于随机森林的投诉预测模型。
步骤四:实时预测。将无标签的95598 实时工单的相关行为特征送入步骤三所建立的投诉预测模型中,获得预测结果。
2.1 95598 历史工单数据预处理
95598 历史工单数据主要包含文字数据和时间数据,其中文字数据主要指描述供电地区、工单事由等相关数据,本文采用数字编码的方法对其进行全部编码;时间数据主要指工单受理日期,本文采用时间距离法将时间数字化,其主要思想是将1900 年1 月1 日作为基准时间,且记为1,以当前时间与基准时间的数学距离作为时间数据;此外,为分析天气因素对投诉工单造成的影响,还应对工单受理时间的近期天气数据进行提取,考虑到投诉可能存在时间延迟性,成单时间可能与投诉成单当天的天气并无关系,故针对天气数据,本文考虑利用将成单时间近5 天中最严重的天气情况作为成单的天气因素。上述工作主要是完成数据投诉工单,目的是将工单中计算机无法直接识别的文字、天气和日期投诉工单转化为计算机可以识别的数据。
对经过数据投诉工单的数据进行数据清洗和数据集成。数据清洗主要是将历史工单数据中的无效工单作删除处理;数据集成是将投诉工单已有的成单时间、事由、地区和业务类型等因素与外部天气数据集成,其所有成单因素作为一个数据库参与后续建模。
2.2 投诉行为特征提取
投诉行为特征是描述投诉行为可能成因的重要因素,预测准确程度大部分取决于提取投诉行为特征的好坏。通过对历史工单数据的预处理,可初步提取业务类型、工单时间、受理地区和天气类型等因素作为投诉行为特征。实际投诉工单投诉行为表明:重复来电、前期的投诉倾向等对于投诉工单形成关系重大。故提取95598 历史工单中用户来电次数及来电时话务员判断该用户的投诉倾向数据,作为投诉行为特征。数据预处理及投诉行为特征提取见图2。
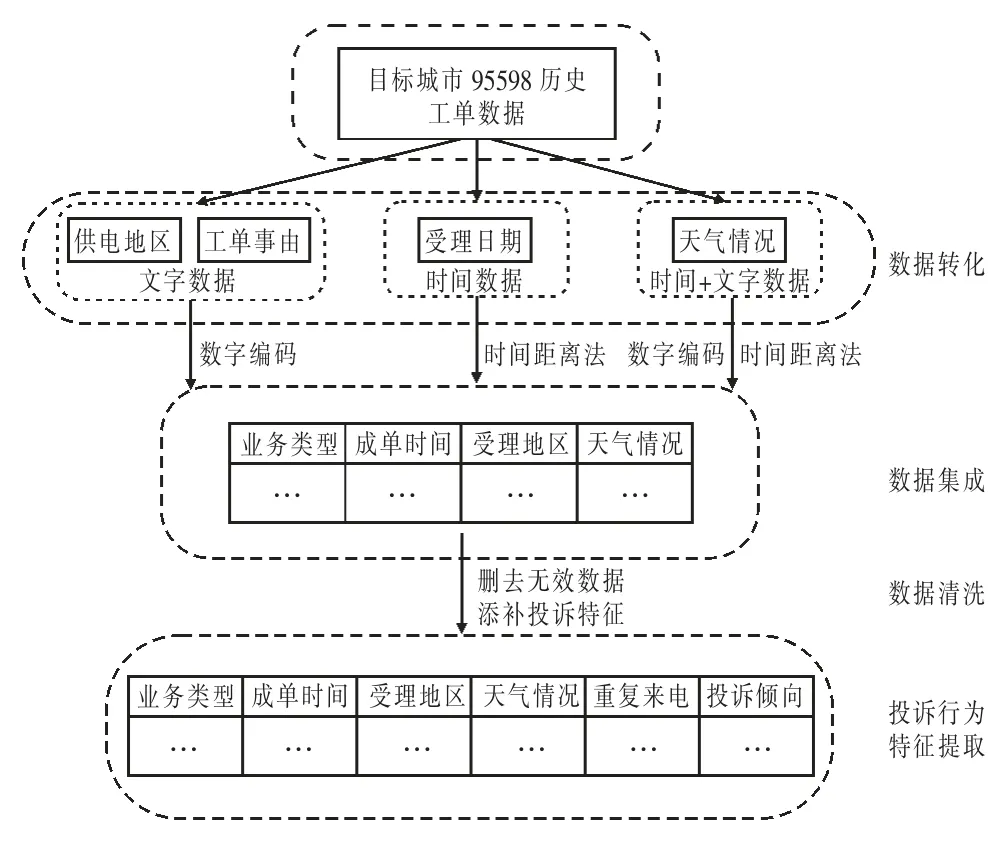
图2 数据预处理及投诉行为特征提取
2.3 95598 电力服务投诉工单预测模型
通过对历史工单数据的预处理,发现95598电力服务投诉工单成因可能与成单时间、成单事由、成单地区、业务类型和天气因素等密切相关。基于随机森林的95598 电力服务投诉工单预测模型P 可表述为:
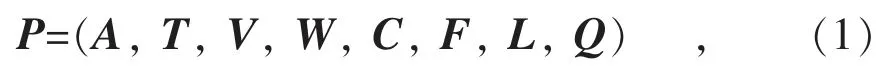
式中:A为投诉工单的成单地区向量;T 为投诉工单的成单时间向量;V 为投诉工单的前期业务类型向量;W 为投诉工单的天气类型向量;C 为投诉工单的温度类型向量;F 为投诉工单的风速类型向量;L 为用户重复来电向量;Q 为用户投诉倾向向量。
3 实例分析
以某市供电公司的95598 电力服务历史工单数据为分析对象,建立基于该市的95598 投诉工单预测模型。
3.1 数据预处理
对该市供电公司历年的95598 电力服务工单数据进行预处理后,共获得数据样本54 681 例。该市有供电辖区10 个,成单时间类型共有12 个月份,前期工单业务类型共9 种(表扬、服务申请、故障报修、建议、举报、信息查询、业务咨询、意见和综合业务),业务类型中受理类型共37个,天气类型有阴、晴、多云、阵雨、小雨、中雨、大雨和暴雨8 类,气温类型有高温、低温2种,风速类型有强风1 种,雷电类型有出现雷电1 种。
3.2 建立95598 电力服务投诉工单预测模型
基于随机森林的95598 电力服务投诉工单预测模型可由式(1)表示。将完成预处理的数据导入Weka 平台中,得到该预测模型的属性分布,见图3。
图3 预测模型数据集
选用Weka3.8 平台中的随机森林算法,采用10%交叉验证,对其进行模型建立。完成模型建立后,可得到各因素与投诉之间的关系,其中业务类型与投诉工单之间的关系尤为密切,二者之间关系的预测结果见图4。
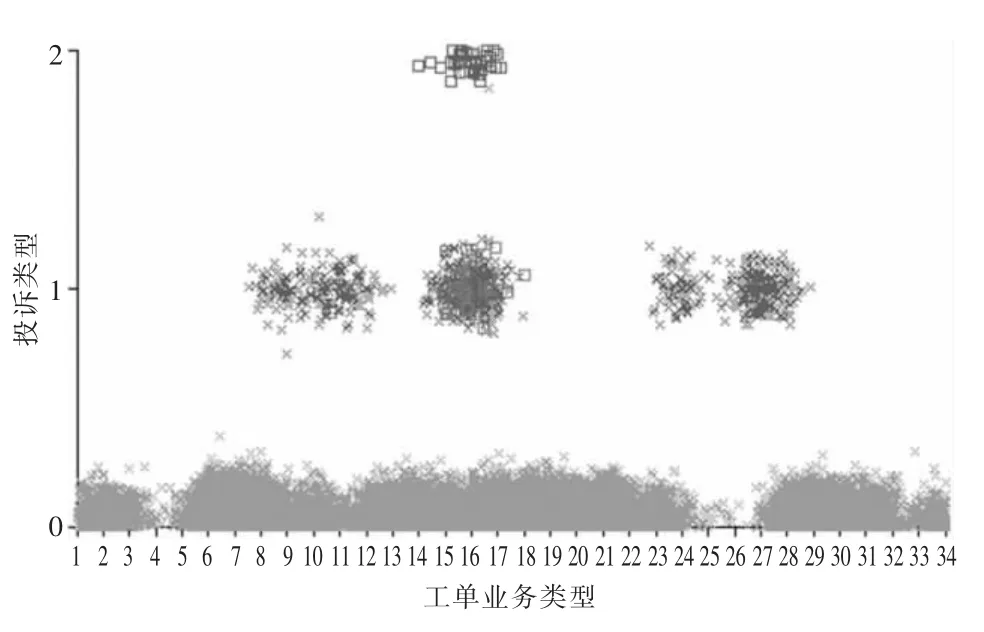
图4 业务类型与投诉之间关系的预测结果
图4 中横坐标为工单业务类型,纵坐标为投诉类型(0 为无投诉;1 为转化工单投诉;2 为直接工单投诉),图中“×”表示正确预测样本;“□”表示错误预测样本。
图4 投诉预测样本结果的分析表明:当发生业务类型16(供电业务)和17(供电质量)时,易产生直接或间接投诉。当发生业务类型为29(营业业务)时,易发生转化投诉。
ROC 曲线是以假阳率和真阳率为轴的曲线,其是描述预测性能的重要参数曲线,与横轴围成的面积越大,说明性能越好,即曲线越靠近A 点(左上方)性能越好,越靠近B 点(右下方)性能越差。根据模型建立结果,导出该预测模型的ROC曲线,见图5。由图5 可知,ROC 曲线几乎完全接近A 点,因此本文方法所得到的预测模型性能良好。
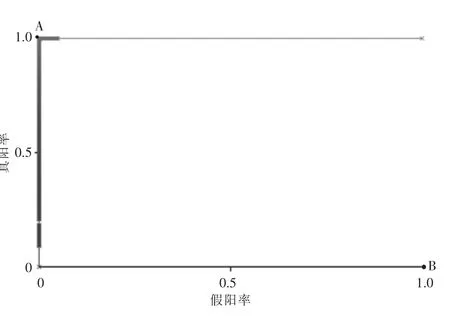
图5 本文方法的ROC 曲线
3.3 算法比较
将本文方法与常见方法进行性能比较。首先给出比较中会涉及的预测模型测试参数定义。
均方误差MSE:
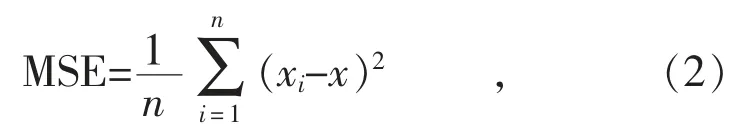
式中:xi为预测值;x 为真实值;n 为预测样本总数。MSE 用以描述预测结果的好坏,如果该值越大,则说明预测效果越差,反之越好。
若将预测模型的真阴类、真阳类、假阴类、假阳类分别用TN,TP,FN,FP 来表示,则召回率R 可定义为:

召回率R 描述了预测模型正确判定的正例占总正例比重。
F1值可定义为:

式中:F1值是预测模型的一个综合指标,F1越大说明该模型预测效果越好。
为了充分说明本文方法的优越性,继续以weka3.8 软件为测试平台,采用本文数据集完成对SVM(支持向量机)、MLP(多层神经网络)、RT(随机决策树)、BN(贝叶斯网络)和逻辑斯蒂方法的预测模型测试,测试结果见表2。
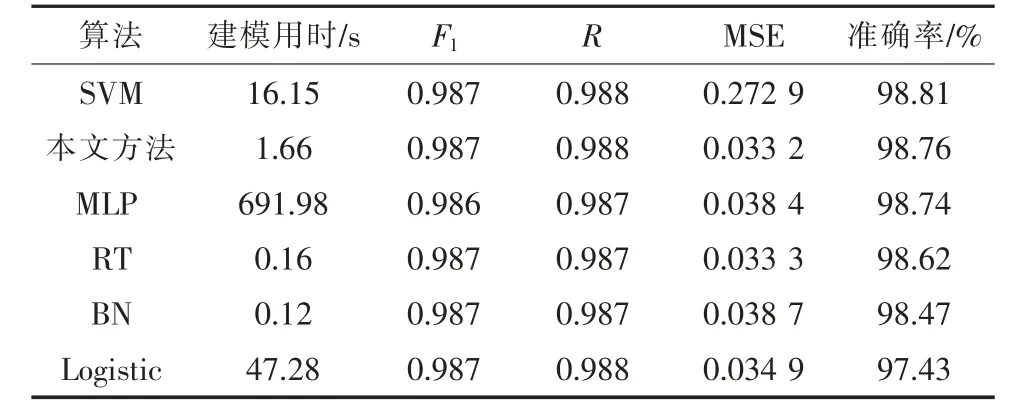
表2 各预测算法比较
由表1 可知:
(1)各模型对于本文数据集均有较好的准确率,本文方法与准确率最高的SVM 模型几乎相当,但SVM 方法的均值误差大了约8 倍。
(2)在建模用时方面,由于投诉风险预测并不是在线预测,完成建模的时间处于完全可接受的范围内;而BP 神经网络建模用时最长,很难适用于工程实际;贝叶斯网络模型在建模用时方面优势明显,但其准确率与MSE 均不及本文方法。可见,虽然本文方法在某些单项指标方面并不是最佳的,但从综合性能的角度考虑,本文方法较其他模型具有较大优势。
3.4 其他实际数据集测试
为评估本文方法对于其他实际数据集的预测性能,继续用本文方法做测试实验。所选用的数据集为该目标城市最新获得的2019 年1—5 月95598 工单,共计16 497 例,经过数据预处理获得有效测试数据为16 218 例。该实验在配置为windows 8.1 Intel(R)Core(TM)i5-4460 CPU@3.20 GHz 的计算机上通过MATLAB 编程实现,其预测分布结果见图6。
图6 中横坐标为用于测试的样本编号,纵坐标为投诉类型(0 为无投诉;1 为转化工单投诉;2为直接工单投诉),图中“※”表示预测结果,“□”表示真实结果。该实验获得正确预测的样本共15 781 例,其正确预测率约为96.93%。由图6 可知,在面对最新的实际95598 工单,本文方法依然有非常高的准确率。此外,2019 年上半年实测数据的准确率(96.93%)与表2 中的正确预测率(98.76%)之间存在一定的误差,这是由于构建模型时数据采用交叉验证方式,数据分布较为均匀,而2019 年上半年的95598 工单集中分布于1—5 月,故导致这种可容许的误差存在,该误差可以通过增加训练样本数来减小或规避。
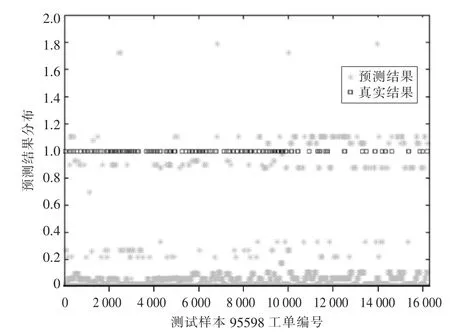
图6 某市2019 年上半年95598 预测结果分布
4 结论
为实现95598 投诉工单投诉风险预测,减少投诉风险发生,在充分考虑多种因素的情况下,提出一种基于随机森林算法的95598 投诉工单投诉风险预测方法。该方法与其他数据挖掘方法相比,具有以下优点:
(1)本文方法预测准确率较高,建模用时短,特别适合应用于工程实际中。
(2)本文方法所构造的模型均方误差小,预测性能优异。
在实验过程中也发现本文方法在建模速度上尚不及贝叶斯网络方法和随机决策树方法,因此在保证预测准确性的情况下继续提高建模速度,是未来研究的重点。
猜你喜欢
电子测试(2022年7期)2022-04-22 00:13:16
高技术通讯(2021年6期)2021-07-28 07:39:20
制导与引信(2017年3期)2017-11-02 05:16:56
中国核电(2017年1期)2017-05-17 06:09:55
作文大王·笑话大王(2017年1期)2017-02-21 16:08:53
作文大王·笑话大王(2016年10期)2016-10-18 14:58:58
作文大王·笑话大王(2016年7期)2016-08-08 11:28:43
工业设计(2016年11期)2016-04-16 02:50:19
作文大王·笑话大王(2016年2期)2016-02-24 11:27:15
环境科技(2015年6期)2015-11-08 11:14:26
