
基于软投票融合模型的消费信贷违约风险评估研究
2020-04-30 06:41:06任师攀彭一宁
金融理论与实践 2020年4期
任师攀,彭一宁
(1.国务院发展研究中心办公厅,北京100010;2.申万宏源证券有限公司,北京100033)
一、问题提出
消费金融是指金融机构向消费者提供消费贷款的一种服务方式,是关系到国计民生的核心金融业务[1]。据国家统计局公开数据,2018 年我国全部金融机构人民币消费贷款余额377903 亿元,占全部金融机构本外币各项贷款余额的26.65%,这一比例比2014 年提高约8.95 个百分点,较2010 年提高约11.9个百分点。居民消费贷款需求不断提高,消费金融的重要性逐步凸显。
(一)优势与风险并存
邢天才和张夕(2019)[2]通过实证研究验证了互联网消费金融的产生和快速发展对我国城镇居民的消费水平和消费行为有极强的带动作用。许文彬和王希平(2010)[3]对比分析了英美两国消费金融公司的模式,指出消费信贷拉动经济增长,我国消费金融公司在业务上应侧重发掘银行信贷难以覆盖的客户群体,同时由于平台承担的违约风险更高,所以需要更严格的风险控制。钟鼎礼(2018)[4]指出消费金融面临的风险具有复杂性、隐蔽性和滞后性等特点。2018 年,上海交通大学凯原法学院进行的中国消费金融行业问卷调查结果显示,我国消费金融市场的主要风险是用户信用风险、欺诈与套现风险、法律滞后纠纷频发风险等。尹振涛和程雪军(2019)[5]分析这是由于忽视行业风控、监管体系不健全、征信体系不完善等导致的,我国消费金融公司必须加强与人工智能的结合,提高风险识别和防范能力,更好完善风控体系。
(二)机器学习助力风险控制
随着互联网金融和人工智能的蓬勃发展,机器学习算法在违约风险评估领域的应用越来越多。Khandani 等(2010)[6]基于2005 年1 月至2009 年4 月某大型商业银行的用户交易数据和征信数据,采用决策树算法构建消费信贷风险评估模型。陆爱国等(2012)[7]将改进的支持向量机算法应用于信用评分中,在公开数据集上验证了该方法的有效性。张国政等(2015)[8]基于商业银行个人消费信贷的实际操作数据和Logistic 回归模型构建个人信用评分系统。Guégan和Hassani(2018)[9]分别采用支持向量机、Logistic 回归、神经网络、随机森林等模型进行信用评估研究,实验结果表明随机森林AUC 指标最大,预测效果最优。He 等(2018)[10]采用随机森林和XGBoost作为基学习器设计融合模型用于信用评估,实现了更优的预测性能。马晓君等(2018)[11]采用P2P平台Lending Club 的借贷数据,构建基于LightGBM算法的个人信用评级模型,并指出在选取指标时需要重点关注贷款金额、利率、年收入、月还款金额、居住地、贷款年份等因素。
现有文献在实证分析中普遍只基于平台自身数据构建模型,对第三方征信数据关注较少,数据存在体量小、维度低的问题;在评价模型时仅采用AUC、准确率等数学指标,没有从实际应用场景出发进一步分析;而且现有文献多关注P2P 信贷违约风险评估,对消费金融的相关研究有较大空白。本文基于大规模消费信贷数据和征信数据,将软投票融合模型应用于消费信贷违约风险评估,在有效降低违约率、减少损失的同时,合理控制误拒率,更好发挥平台的普惠金融作用,为消费金融健康发展提供保障。
二、数据解释与描述性统计
(一)数据解释
捷信集团(Home Credit Group)1997 年成立,致力于为缺乏信用记录的用户提供贷款,是国际领先的消费金融服务提供商。2010 年,捷信集团在中国成立全资子公司——捷信消费金融有限公司。截至2019 年7 月,捷信在中国的业务覆盖了29 个省(自治区)和直辖市,是国内净利润最高的消费金融平台(根据国内各消费金融公司2018 年的财报分析,捷信消费金融公司净利润为13.96 亿元,排名第一)。由于捷信平台业务覆盖范围广、盈利能力强且数据公开,选择其贷款数据进行研究具有较强的代表性和现实意义。
本文采用的数据是捷信集团2018年8月公开的贷款数据集(https://www.kaggle.com/c/home-creditdefault-risk/data)。如图1 所示,数据集共包含7 个数据表,记录了用户贷款申请信息、第三方机构征信数据和平台历史贷款数据。
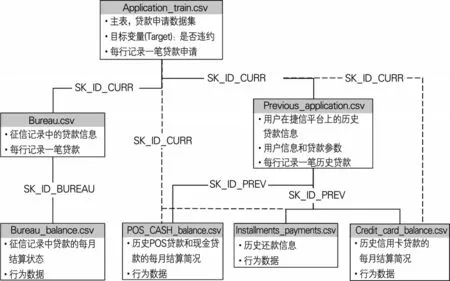
图1 数据集结构
Application_train 是整个数据集的主表(下文简称“主表”),记录用户贷款申请数据,主键是“SK_ID_CURR”(每笔贷款的唯一标识号)。目标变量是“TARGET”,取值为0 代表正常还款,取值为1代表违约。主表共307511行、122列,每行记录一笔贷款。主要列属性有贷款类型、金额、分期付款额、申请人性别、年龄、受教育程度、当前工作从事时间、收入、车产、房产、居住环境、最近一次更改身份证明文件的时间、外部数据源的标准化评分、申请人社交环境中违约的观测数等。
Bureau 记录了用户征信记录中的贷款信息,主键是“SK_BUREAU_ID”(征信记录中每笔贷款的唯一标识号),外键是“SK_ID_CURR”,共1716428 行、17 列,主要列属性包括贷款金额、类型、申请时间、贷款状况、逾期天数、剩余期限、逾期最大金额等。
Bureau_balance 记录了用户征信记录中贷款的每月结算状态,外键是“SK_BUREAU_ID”,共27299925 行、3 列,列属性分别是外键、结算月份和贷款结算状态。
Previous_application 记录了用户在捷信平台上的历史贷款信息,主键是“SK_ID_PREV”(捷信平台历史贷款的唯一标识号),外键是“SK_ID_CURR”,共1670214 行、37 列,主要列属性包括申请贷款金额、最终贷款金额、贷款类型、利率、分期付款额、贷款期限、贷款目的、合同状态等。
POS_CASH_balance 记录了用户在捷信平台上的历史POS 贷款和现金贷款的每月结算简况,外键是“SK_ID_CURR”和“SK_ID_PREV”,共10001358行、8 列,主要列属性包括结算月份、贷款期限、剩余还款周期、还款状态、贷款逾期天数等。
Credit_card_balance 记录了用户在平台上历史信用卡贷款的每月结算简况,外键是“SK_ID_CURR”和“SK_ID_PREV”,共3840312 行、23列,主要列属性包括结算月份、当月最低还款金额、当月还款金额、已还款总额、已还款分期数、贷款逾期天数、信用卡额度、当月提取金额、当月购物次数等。
Installments_payments 记录了用户在捷信平台上的历史还款行为,外键是“SK_ID_CURR”和“SK_ID_PREV”,共13605401行,8个属性,主要列属性包括还款分期数、还款方式、应还款时间、实际还款时间、本期应还金额、本期实际还款金额等。
(二)描述性统计
主表中共包含307511 笔贷款信息,其中正常还款标的282686 笔,违约标的24825 笔,违约率为8.07%。
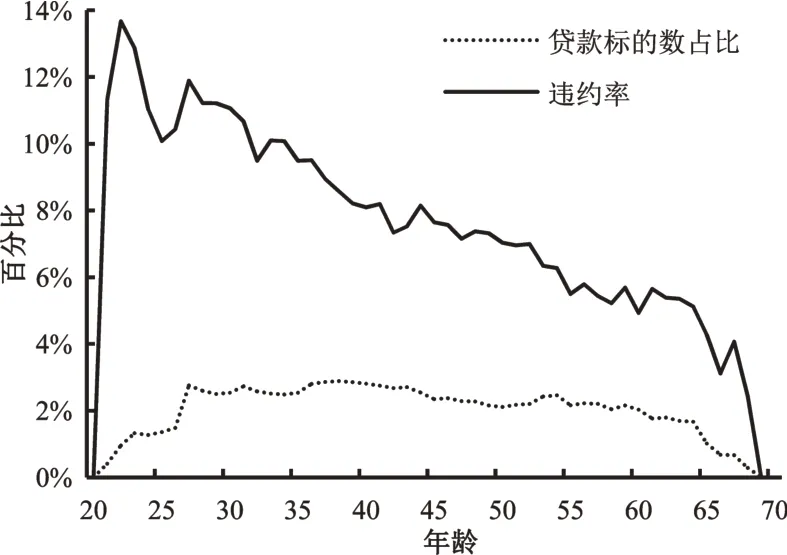
图2 各年龄贷款标的数占比及违约率
贷款类型方面,现金贷款、循环贷款标的数分别占比90.48%、9.52%,分别对应8.35%、5.48%的违约率。性别方面,女性贷款标的数接近男性的二倍,违约率为7%,比男性低3.14 个百分点。由此可见,女性对消费信贷的需求更多,整体上比男性更重视信用,履约能力更强。
如图2 所示,平台用户的年龄在20 岁至70 岁之间;27 岁至64 岁,各个年龄对应的贷款次数分布比较均匀,其他年龄的用户贷款次数较少;整体来看,违约率随年龄的增长逐渐下降。
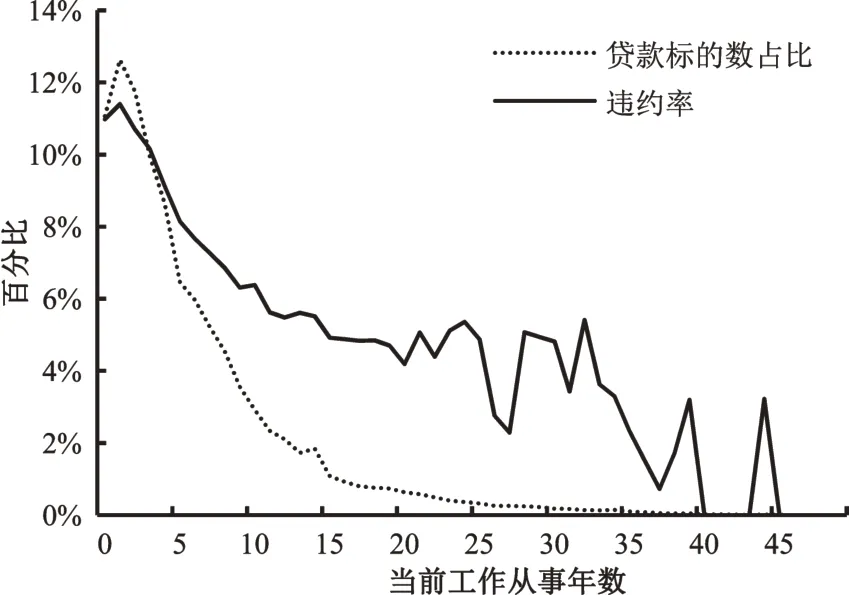
图3 各从事年数的贷款标的数占比及违约率
如图3所示,贷款用户大多从事当前工作0年至15 年,贷款标的数随着当前工作从事年数的增长逐渐下降;违约率和当前工作从事年数呈负相关趋势。
借款人学历方面,初中学历仅占1.24%,高中学历占71.02%,高等教育占27.74%,三种学历分别对应10.93%、8.94%、5.73%的违约率,表明平台的主要服务对象是受过高等教育或高中教育的人群,而且学历层次越高,贷款的违约率越低。
资产实力反映借款人的偿债能力,与违约率呈负相关关系。拥有房产或公寓的借款人占总数的69.3%,违约率为7.96%;没有房产或公寓的借款人群体违约率为8.32%。拥有汽车的借款人占总数的34%,违约率为7.24%;没有汽车的借款人群体违约率为8.5%。居住条件方面,租住公寓、与父母同住的借款人群体违约率分别是12.31%、11.7%,远高于其他群体。居住环境方面,10.5%的借款人居住地被评定为一级,73.8%为二级,15.7%为三级,三个等级分别对应4.82%、7.89%、11.1%的违约率。
三、模型构建
(一)数据预处理
1.缺失值和异常值处理
由于XGBoost 和LightGBM 具备缺失值处理能力,所以数据预处理阶段没有对数值型变量进行缺失值填充;对于类别型变量中的缺失值,将其作为“nan”类进行独热编码(One-Hot)处理。数据集中“DAYS_EMPLOYED”(当前工作从事天数)等涉及时间距离的字段存在异常值,用空值将其代替。
2.衍生变量
如表1 所示,为了更多角度地描述借款人信息,本文构建了9个衍生变量。
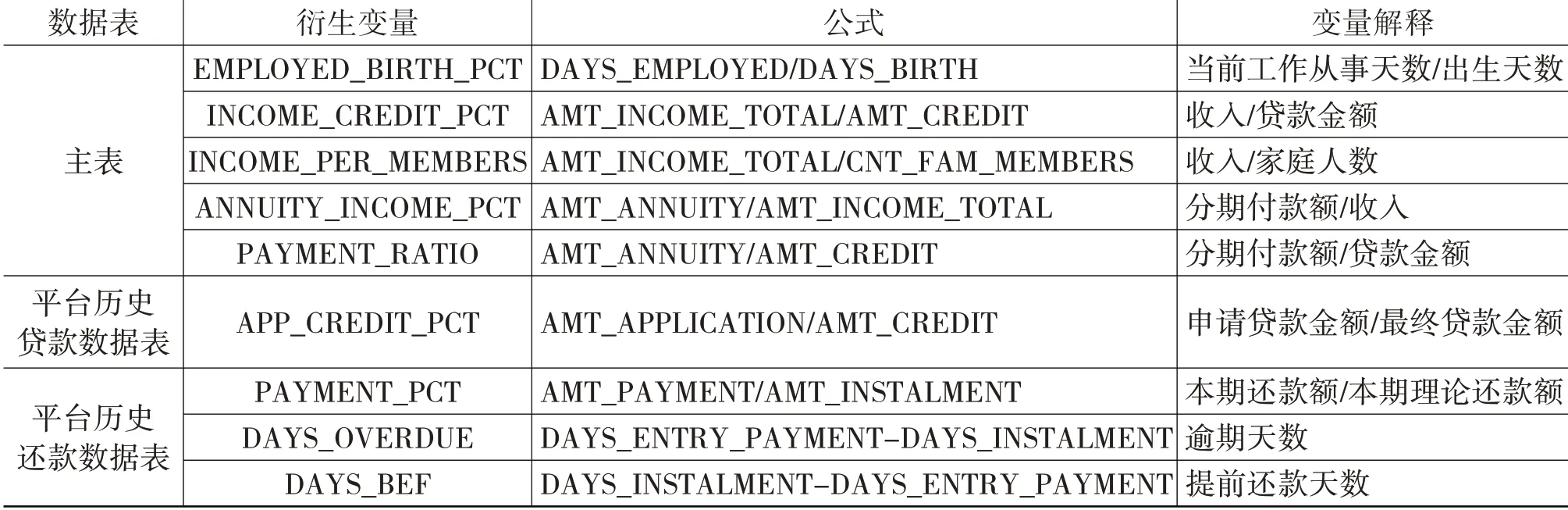
表1 衍生变量
3.数据集构建
为了更直观地分析征信记录和历史贷款信息的重要性,本文在原始数据基础上构建了app、app_bureau、app_pre、app_bureau_pre 四个数据集(如表2 所示),分别训练软投票融合模型,对比分析不同数据集下模型的预测能力。
将其他原始数据表的统计信息连接到主表中,并且划分出训练集(用于训练模型、调优超参数)和测试集(用于评价模型的预测能力),主要有以下步骤。
处理Bureau_balance 表:对分类变量进行独热编码,按照“SK_ID_BUREAU”(信用记录中贷款的唯一标识号)分组后统计“MONTHS_BALANCE”(结算月份)变量的最小值(首个还款月)、最大值(最近还款月)、元素个数(已还款周期数),以及“STATUS”(贷款状态)变量生成的各个哑变量字段的平均值(各个贷款状态的出现次数占已还款周期数的比例),生成以“SK_ID_BUREAU”为主键的征信记录结算信息统计表。通过“SK_ID_BUREAU”列将生成的信息统计表连接到Bureau表中。

表2 数据集描述
处理Bureau、Previous_applications、POS_CASH_balance、Credit_card_balance、Installments_payments表:首先对分类变量进行独热编码,然后按照“SK_ID_CURR”(主表中贷款申请的唯一标识号)分组后,统计数字型变量的最大值、最小值、平均值等,并且计算分类变量生成的各个哑变量字段的平均值,生成以“SK_ID_CURR”为主键的征信信息统计表、平台历史贷款信息统计表、POS贷款和现金贷款的每月结算信息统计表、信用卡贷款每月结算信息统计表、平台历史还款信息统计表。
处理主表:将分类变量进行独热编码后,通过“SK_ID_CURR”列连接其他原始数据表生成的信息统计表,然后以19:1的样本比例划分得出训练集(含292131个样本)和测试集(含15376个样本)。
(二)模型设计
1.梯度提升决策树
梯度提升决策树(gradient boosting decision tree,GBDT)以决策树为基学习器,利用损失函数的负梯度值作为近似残差拟合模型,是统计学习中性能最好的方法之一。
如式(1)所示,GBDT 可以表示为若干决策树的加法模型:

其中,T(x;θn)表示决策树,θn为决策树的参数,x表示特征变量,N表示决策树的个数。
GBDT 的训练是一个多轮迭代的过程,初始决策树f0(x)=0。第n次迭代中,模型如式(2)所示,其中fn-1(x)在第n-1轮已经得出。

损失函数如式(3)所示,其中y是目标变量值。

GBDT 利用损失函数loss 的负梯度值作为近似残差拟合模型。当N轮迭代后,得到最终模型fN(x)。
目前,GBDT 有许多不同的实现,其中最具代表性的是XGBoost和LightGBM。
2.XGBoost
XGBoost(extreme gradient boosting)是一个开源的高度可扩展的梯度提升树系统,已经在许多机器学习和数据挖掘任务中得到广泛应用[12]。XGBoost受到广泛欢迎的重要原因是它可以扩展到风险预测、网络文本分类、恶意软件识别、顾客行为预测等众多应用场景中。
XGBoost 的主要特点有:采用稀疏感知算法处理稀疏数据;采用加权分位数草图近似实现树模型的学习;采用缓存感知块结构,实现了树模型的核外学习;并行和分布式计算加速模型的训练。
3.LightGBM
当数据维度高、数据量大时,GBDT 对于每个特征都需要扫描所有数据点,计算所有可能的分割节点的信息增益,导致效率较低。LightGBM(light gradient boosting machine)分别采用基于梯度的单侧采样(gradient-based one-side sampling,GOSS)和互斥特征捆绑(exclusive feature bundling,EFB)来解决数据量大和特征维度高的问题[13]。其中,GOSS方法减少了梯度较小的样本的比例,仅仅采用具有较大梯度的样本计算信息增益;EFB 方法通过捆绑互斥的特征减少了特征数量。多个公开数据集上的实验结果表明,LightGBM 可以使传统GBDT 的训练过程加速20倍以上,同时实现了几乎相同的精度[13]。
4.软投票(soft voting)融合模型
本文设计的软投票融合模型(下文简称“融合模型”)如图4所示。训练阶段,采用贝叶斯优化和5折交叉检验方法对模型进行参数调优,求解最优参数组合;测试阶段,以特征变量作为XGBoost 和Light-GBM 的输入,并且对它们输出的类别概率进行软投票得出预测结果。如式(4)和式(5)所示,软投票是指对XGBoost 和LightGBM 输出的类别概率取平均值后,根据阈值(默认为0.5)确定最终结果。其中,Pm是指模型m 预测的当前贷款申请违约的概率,“threshold”代表阈值,“Result”为融合模型的预测结果,1表示违约,0表示正常还款。

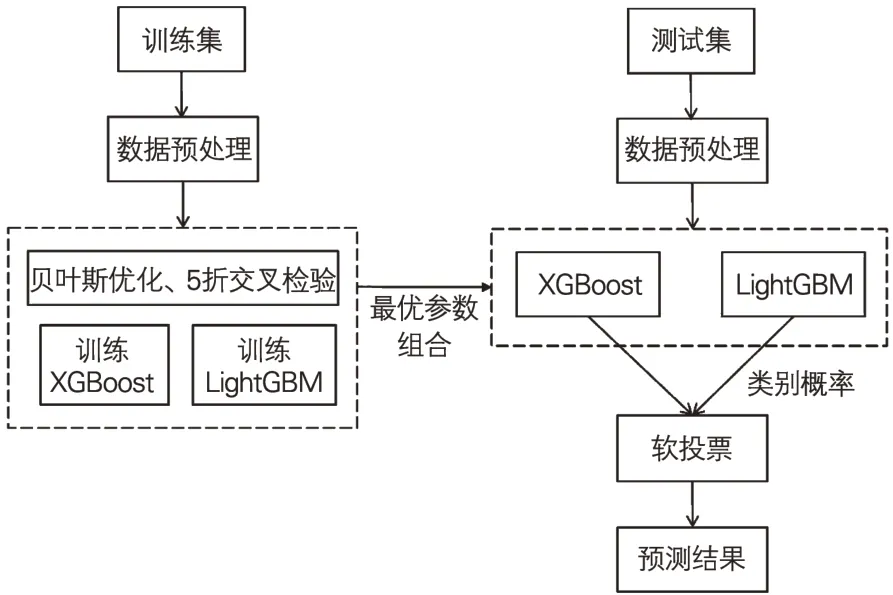
图4 模型设计
四、实证分析
(一)评价指标
二分类任务中常用的评价指标有AUC(area under the curve)、KS(kolmogorov-smirnov)值、准确率等,它们均可由混淆矩阵(如表3所示)计算得出。
准确率(accuracy)是指分类正确的样本数占总样本的比例。
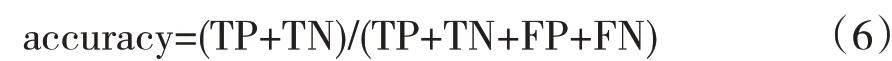
真正例率(True Positive Rate,TPR)是指1 类(违约)样本被正确预测的比例。

假正例率(False Positive Rate,FPR)是指0类(正常还款)样本被错误预测的比例。


表3 混淆矩阵
分类模型在结果预测时,首先得出各个类别的概率值,然后根据阈值做出分类判断。由此可见,设定不同的阈值会得到不同的分类结果,模型的准确率、真正例率等指标都会随之变化。
如图5 所示,受试者工作特征曲线(receiver operating characteristic,ROC)呈现了不同阈值设定下真正例率和假正例率间的关系。真正例率越高,假正例率越低(ROC 曲线越向上弯曲),模型的预测能力越强。AUC,即ROC 曲线下区域的面积,一般在0.5和1之间,值越大表明模型预测越准确。
KS值反映了模型区分正负样本的能力。如图6所示,以阈值为自变量,真正例率、假正例率为因变量得到的两条曲线,即KS 曲线。KS 值是指两条曲线之间的最大间隔距离,值越大表明模型区分正负样本的能力越强。借助KS 曲线,可以选择最优阈值。例如,图6中KS值为0.44,最优阈值为0.39。
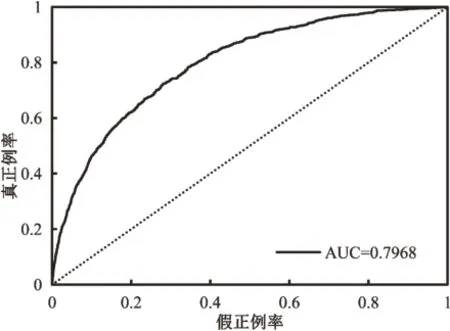
图5 ROC曲线
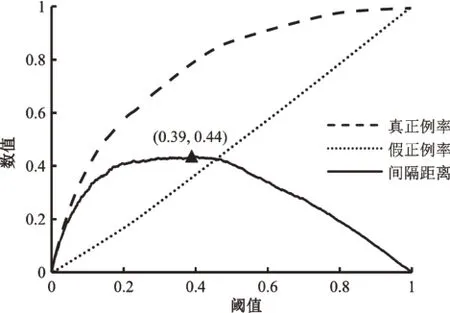
图6 KS曲线
在二分类模型评价中,AUC、KS 值通常比其他指标更有效,主要原因有:一是相较于准确率、真正例率等依赖阈值的指标,AUC、KS 值综合评价了不同阈值设定下模型的预测能力;二是AUC、KS 值对正负样本比例不敏感,适用于样本不平衡问题。
实际应用中,模型预测为0 类(正常还款)的贷款申请会被通过,预测为1 类(违约)的申请则会被拒绝。为了更全面地评价模型,除采用AUC、KS 值和准确率指标外,本文还结合实际场景,设置了违约率和误拒率两个指标。如式(9)和式(10)所示,违约率是预测正常还款的贷款标的中实际违约的样本比例,误拒率是预测违约但实际可以正常还款的贷款标的数占样本总数的比例。误拒率越低,平台因错误拒绝具备偿债能力的申请人而导致的用户流失越少,盈利能力越强,越有能力发挥普惠金融作用。
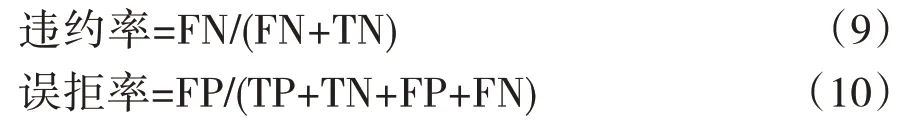
(二)结果分析
表4、表5 中,准确率、违约率、误拒率是在默认阈值(0.5)下得出的。从app_bureau_pre 数据集上三个模型的实验结果来看,融合模型的AUC、KS 值和准确率指标最高,表明其预测最准确,区分正负样本的能力最强;违约率和误拒率最低,表明其不仅可以更好地降低坏账损失,而且更少误拒用户的贷款申请,保障平台的用户规模。
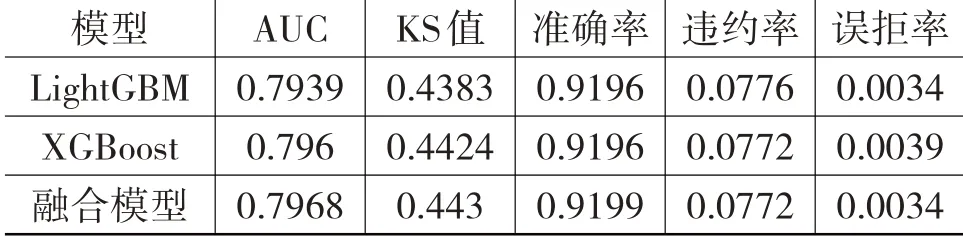
表4 app_bureau_pre 数据集上三个模型的各项指标对比
从不同数据集上融合模型的各项指标来看,征信记录、历史贷款记录的引入均提高了模型的AUC、KS 值和准确率,即提高了模型的预测准确性和区分正负样本的能力;误拒率虽然略有增高,但是仍处于较低的水平。以app 数据集(仅含主表)为基础,引入征信记录后,违约率降低0.08%;引入历史贷款记录后,违约率降低0.18%;引入征信记录和历史贷款记录后,违约率降低0.28%,充分证明了征信记录和历史贷款记录的重要性。
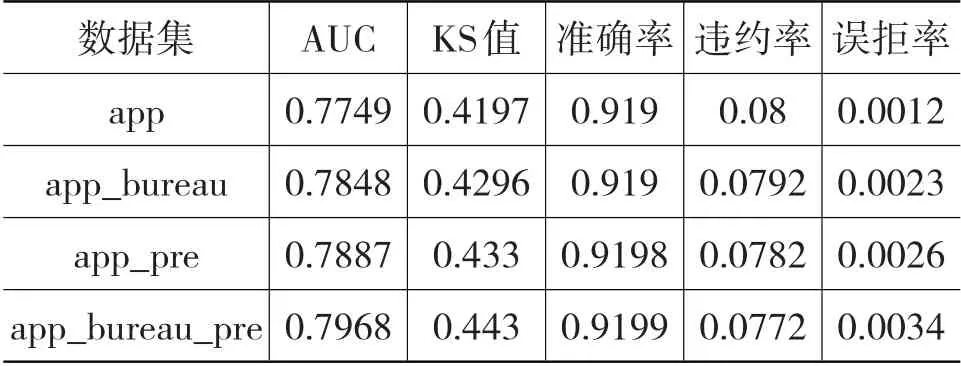
表5 不同数据集上融合模型的各项指标对比
经过上述分析,app_bureau_pre数据集上训练的融合模型表现最优。由于模型违约率、误拒率与阈值的设定相关,本文对融合模型在不同阈值设定下违约率和误拒率的变化情况进行了探索。如图7 所示,随着阈值的增加,模型违约率先迅速增长后趋于稳定,误拒率则先迅速下降后趋于稳定。模型违约率和误拒率呈负相关关系,这意味着在降低违约率减小损失的过程中,不可避免地增高误拒率,影响用户规模。极端情况下,当阈值为0.05时,模型违约率为2.34%,但是误拒率却高达38.55%,导致大量拥有偿债能力的用户流失,对平台的发展极为不利。因此,选择一个合适的阈值非常重要。
本文采用反映模型正负样本区分能力的KS 曲线选择阈值。如图8 所示,KS 两条曲线最大间隔距离(KS值)为0.44,对应的阈值为0.32,即得出最优阈值。从图7 可以得出,当阈值为0.32 时,模型违约率为6.85%,误拒率为1.98%。与数据集中捷信平台8.07%的贷款违约率相比,软投票融合模型可以将违约率降低1.22 个百分点,仅以捷信集团2018 年总贷款额203 亿欧元测算,可以减少约2.48 亿欧元的损失。实际运营中,违约往往比误拒对平台造成的损失更大。与违约率1.22%的降幅相比,1.98%的误拒率处在合理水平。
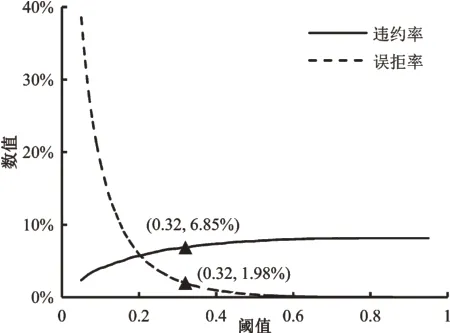
图7 阈值与模型违约率、误拒率的关系
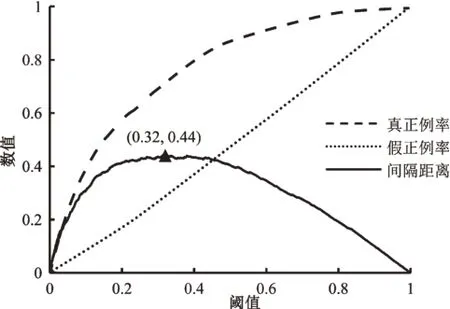
图8 融合模型的KS曲线
本文统计了重要度前50 位的特征变量的来源。如表6 所示,17 个特征来源于主表,重要度占比50.88%;17 个特征来自征信记录的统计信息,重要度占比24.27%;16 个来自平台历史贷款的统计信息,重要度占比24.85%。结果表明,在违约风险评估中,主表中的信息重要程度最高,征信记录和历史贷款信息重要程度基本相当。

表6 特征来源及重要度占比
图9 展示了融合模型重要度较高的部分特征,依次是分期付款额/贷款金额、3 个外部数据源的标准化评分、年龄、当前工作的从事年数、分期付款额、在捷信平台上的历史贷款还款期限的均值、最近一次在平台上还款的时间、最近一次更改身份证明文件的时间、征信记录中最近一笔活跃贷款的申请时间、用户历史还款平均逾期天数、当前工作从事年数/年龄、分期付款额/收入。
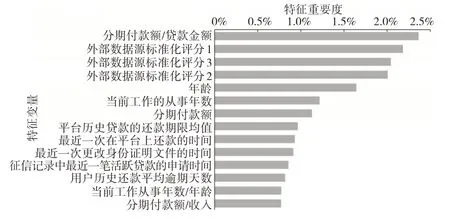
图9 融合模型特征重要度排序
综合上述分析,总结得出在消费信贷违约风险评估中最重要的七类因素。
第一,贷款基本情况,如贷款金额、分期付款额、还款期限。分期付款额与贷款金额的比值反映了利率的大小,利率、贷款金额越高,违约风险越高。还款期限可以反映借款人的偿债能力,还款期限越长,表明借款人偿债能力越弱,违约风险越高。
第二,外部数据源的标准化评分。完备的风控体系一般由多个子系统构成,其他子系统的评分对违约风险评估系统有重要的积极意义。
第三,借款人基本信息,如年龄、当前工作从事年数等。违约率随着年龄和当前工作从事年数的增长而降低。当前工作从事年数和年龄的比值反映了借款人收入的稳定性,比值越高,违约风险越低。
第四,借款人行为信息,如最近一次更改身份证明文件的时间、最近一次修改注册信息的时间等。身份证明文件是校验借款人身份的重要依据,是提取借款人征信记录和历史贷款信息的重要媒介。身份证明文件、注册信息修改越频繁,违约风险越高。
第五,借款人资产实力,如收入、房产、车产等。资产实力直观地反映了借款人的偿债能力。收入越高,分期付款额和收入的比值越小,借款人还款压力越小,违约风险越低。另外,拥有房产、车产也会降低违约风险。
第六,历史贷款信息,如还款期限均值、最近还款时间、历史还款平均逾期天数等。借款人在平台上的历史贷款申请信息和行为信息是其信用记录的重要体现。还款期限均值越小,表明借款人偿债能力越强;历史还款平均逾期天数越低,代表借款人越重视信用,违约风险也越低。
第七,征信信息,如征信记录中最近一笔活跃贷款的申请时间、逾期次数等。征信记录反映了借款人在其他平台的历史贷款申请信息和行为信息。实验结果表明,征信记录在违约风险评估中相当重要。
五、结论与建议
本文基于大规模消费信贷数据和相关征信记录,构建软投票融合模型预测贷款申请的违约风险;除采用AUC、KS值、准确率三个数学指标外,还从实际场景出发提出了违约率和误拒率,完善模型评价体系;识别出违约率和误拒率的负相关关系,采用KS 曲线选择阈值,在降低违约率的同时,将误拒率控制在合理水平。实验结果表明,软投票融合模型预测能力优于XGBoost 和LightGBM,准确率高达91.99%,可以将违约率降低1.22%,仅以捷信集团2018 年总贷款额203 亿欧元测算,减少了约2.48 亿欧元的损失。本文总结了违约风险评估中需要关注的七类因素,供相关研究和实际应用参考。同时,对消费金融平台提出以下建议。
第一,利用数字化手段构建线上线下双向融合的反欺诈机制,确保输入违约风险评估模型的贷款基本情况、借款人基本信息、行为信息、资产实力等数据的真实性和有效性。
第二,充分利用第三方征信数据和历史贷款数据。目前,我国征信体系不断完善,国内消费金融公司可以通过与第三方权威征信机构合作扩充数据源,结合平台用户数据和历史贷款数据,构建具备自身特色的征信系统,有效控制违约风险。
第三,多角度评价模型。构建违约风险评估模型时,不仅要关注AUC、KS、准确率等技术指标,还要从场景出发,在降低违约率、减少损失的同时,也要保证误拒率处于合理水平,减少因模型“错误决策”而导致的用户流失。
猜你喜欢
制造技术与机床(2019年9期)2019-09-10 07:36:54
上海财经大学学报(2019年3期)2019-06-04 08:05:24
西南交通大学学报(2018年6期)2018-12-18 02:22:28
意林(绘英语)(2018年2期)2018-11-29 03:23:16
意林(绘英语)(2018年2期)2018-11-29 03:23:16
瞭望东方周刊(2018年4期)2018-02-01 16:56:21
河北遥感(2017年2期)2017-08-07 14:49:00
新农业(2016年16期)2016-08-16 03:42:08
衡阳师范学院学报(2016年3期)2016-07-10 07:16:27
黑龙江科学(2016年22期)2016-03-16 00:47:40
