
多层特征图堆叠网络及其目标检测方法
2020-04-28 05:47杨爱萍鲁立宇
天津大学学报(自然科学与工程技术版) 2020年6期
杨爱萍,鲁立宇,冀 中
多层特征图堆叠网络及其目标检测方法
杨爱萍,鲁立宇,冀 中
(天津大学电气自动化与信息工程学院,天津 300072)
随着深度卷积神经网络的快速发展,基于深度学习的目标检测方法由于具有良好的特征表达能力及优良的检测精度,成为当前目标检测算法的主流.为了解决目标检测中小目标漏检问题,往往使用多尺度处理方法.现有的多尺度目标检测方法可以分为基于图像金字塔的方法和基于特征金字塔的方法.相比于基于图像金字塔的方法,基于特征金字塔的方法速度更快,更能充分利用不同卷积层的特征信息.现有的基于特征金字塔的方法采用对应元素相加的方式融合不同尺度的特征图,在特征融合过程中易丢失低层细节特征信息.针对该问题,本文基于特征金字塔网络(feature pyramid network,FPN),提出一种多层特征图堆叠网络(multi-feature concatenation network,MFCN)及其目标检测方法.该网络以FPN为基础,设计多层特征图堆叠结构,通过不同特征层之间的特征图堆叠融合高层语义特征和低层细节特征,并且在每个层上进行目标检测,保证每层可包含该层及其之上所有层的特征信息,可有效克服低层细节信息丢失.同时,为了能够充分利用ResNet101中的高层特征,在其后添加新的卷积层,并联合其低层特征图,提取多尺度特征.在PASCAL VOC 2007数据集上的检测精度为80.1%mAP,同时在PASCAL VOC 2012和MS COCO数据集上的表现都优于FPN算法.相比于FPN算法,MFCN的检测性能更加 优秀.
特征金字塔网络;目标检测;特征图堆叠;语义信息
目标检测是计算机视觉中最基本和最具挑战性的问题之一,其目的是检测图像中特定目标的位置,已广泛用于人脸检测、自动驾驶、行人检测、视频监控等领域.
现有的目标检测方法可分为传统方法和基于深度学习的方法.传统目标检测方法主要包括区域选择、特征提取和分类回归.其中特征提取使用手工提取特征的方法,如通过提取图像颜色连通区域的共生矩阵来描述图像特征[1];通过结构元素描述符(structure elements’ descriptor,SED)来提取和描述图像的纹理和颜色[2];通过基于自适应强边缘提取的方法估计模糊核[3].但是,上述方法特征提取方式单一,检测准确率低,且计算复杂.
随着深度卷积神经网络的快速发展,基于深度学习的目标检测方法由于其无需进行人工特征设计、具有良好的特征表达能力及优良的检测精度,已经超越传统检测方法,成为当前目标检测算法的主流.基于深度学习的目标检测方法主要通过卷积神经网络提取图像特征,主流的网络结构有DenseNet[4]、ShuffleNetv2[5]、MobileNetv2[6]等.另外,有些方法将手工提取特征和神经网络方法相结合,如文献[7]和文献[8].在现实场景中存在大量小目标物体,尤其是对于低分辨率图像,很难提取到其中的小目标特征,造成检测效果较差.为了解决目标检测中小目标漏检问题,提出了基于卷积神经网络的多尺度处理方法.多尺度检测方法可以分为两类:一类是基于图像金字塔的方法,如R-CNN[9]、Fast R-CNN[10]、Faster R-CNN[11]等,上述方法通常将输入图像重采样得到不同尺度,并将这些不同尺度的图像分别输入到网络中训练,但是,随着输入数据量增大,基于图像金字塔的方法复杂度很高;另一类是基于特征金字塔的方法,与基于图像金字塔的方法相比,特征图金字塔方法可充分利用不同卷积层的特征信息,并且速度更快,因此,基于特征金字塔的方法越来越流行.MS-CNN[12]在不同尺度的特征图上生成候选框,SSD(single shot multibox detector)[13]采用了类似结构.但是,它们仅将低层特征图用于小目标检测,而低层特征图中只拥有较少的语义信息,造成小目标检测性能低下.为了解决这个问题,特征金字塔网络(feature pyramid network,FPN)[14]和RON[15]设计了一种自顶向下的连接结构,其通过对应元素相加融合高层和低层特征图.但是这种对应元素相加的方式,很容易丢失低层细节特征.
针对上述问题,本文在FPN基础上,提出一种特征图堆叠网络及其目标检测方法.通过不同特征层之间的特征图堆叠融合高层语义特征和低层细节特征,并且在每个层上进行目标检测,保证每层可包含该层及其之上所有层的特征信息.同时,为了充分利用ResNet101[16]高层特征图信息,在ResNet101后面添加了一个conv6层,将上述融合后的特征图和ResNet101的conv5、conv6层输出特征图共同输入到权重共享的区域建议网络(region proposal net-work,RPN)和R-CNN网络.
1 特征金字塔网络
FPN是一种基于候选窗口的目标检测算法,其在Faster R-CNN的基础上,通过对应元素相加融合特征提取网络的不同语义特征图.针对Faster R-CNN检测尺度单一的问题,FPN充分利用了特征提取网络不同特征层的多尺度特点,在不同特征层上进行目标检测,该设计对于多尺度目标检测更有效.
FPN的架构主要分为两部分:一部分是特征提取网络的自顶向下连接结构,采用的特征提取网络是ResNet101;另一部分是候选框生成网络和分类回归网络,采用RPN网络和R-CNN网络.FPN框架结构如图1所示.

图1 FPN框架图

2 特征堆叠网络及其目标检测方法
FPN虽然在一定程度上改善了MS-CNN和SSD在小目标检测方面性能较低的问题,但是其通过对应元素相加的方式融合高层特征图和低层特征图,易丢失低层细节特征信息.因此,本文提出将高层特征图和低层特征图通过特征图堆叠的连接方式进行融合,将融合后的特征图输送到权重共享的RPN网络和R-CNN网络进行候选框生成、分类预测和位置回归,具体结构如图2所示.
与FPN相比,MFCN保留了低层细节特征信息.同时,为了充分利用特征提取网络的高层语义特征,在ResNet101后添加了conv6层,将ResNet101的conv5和conv6输出特征图也融入到RPN网络.
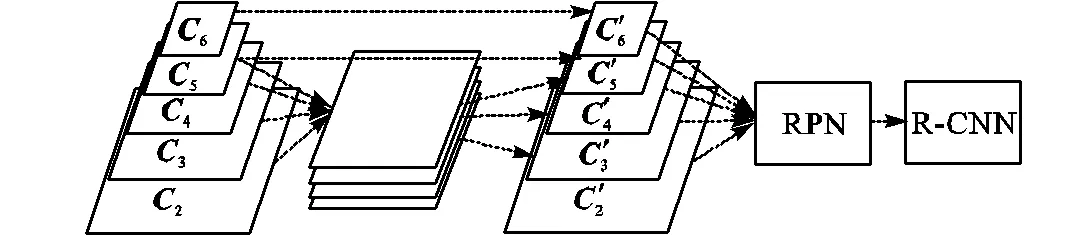
图2 MFCN框架图
2.1 基于特征图堆叠的特征融合
低层特征图中包含了对小目标检测有益的细节信息,高层特征图中包含了对小目标检测有帮助的语义信息.对于大目标来说,无需关注过多细节信息,所以无需将低层细节特征融入到高层.但是,对于小目标来说,在对其进行检测时需要更多的语义信息,需将高层语义特征融入到低层细节特征中.
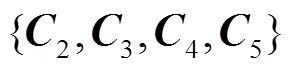

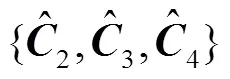
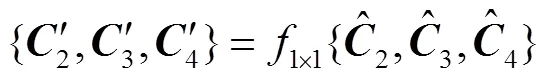
MFCN网络通过特征图堆叠的方式融合不同语义的特征图,可保留低层细节特征信息,使得MFCN网络的特征融合过程更合理.
2.2 融合高层语义特征
为了能够充分利用ResNet101中的高层特征图,在ResNet101后添加了新的conv6层,conv6层通过在conv5层后添加一个大小为3×3、步长为2的卷积得到,该过程可以表示为
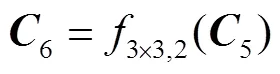
为了保证高层特征图的输出维度与低层特征图的输出维度一致,将conv5和conv6的输出通过1×1卷积进行降维,该过程可以表示为

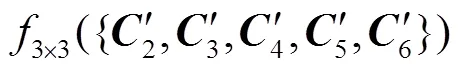
2.3 损失函数
设计MFCN网络的损失函数为
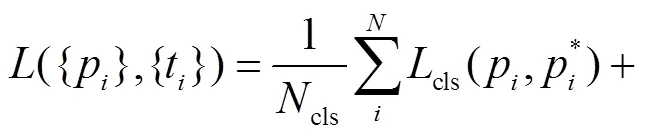
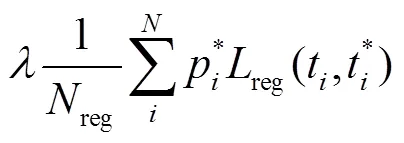
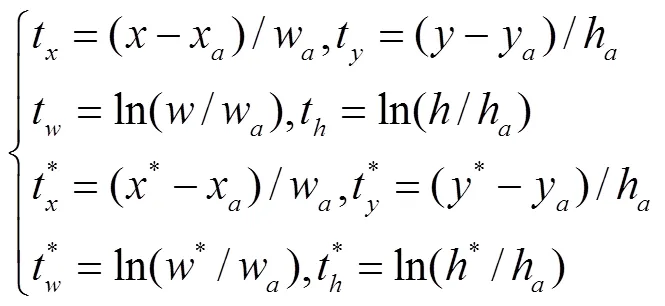
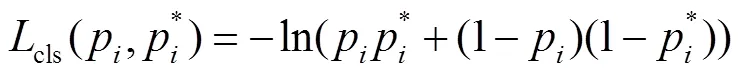

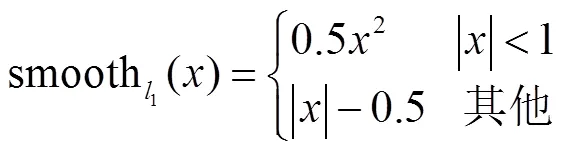
3 实验与结果分析
3.1 实验平台
实验平台配置如下:CPU为Intel i7-7700k;内存为6G DDR4;GPU为Nvidia Geforce GTX TITAN X;操作系统为64位Ubuntu16.04 LTS;实验框架为MXNet开源框架;编程语言为Python 2.7;第三方库OpenCV和CUDA9.0.
3.2 实验数据集
实验数据集为使用最广的3个公开数据集:PASCAL VOC 2007、PASCAL VOC 2012[17]和MS COCO[18].VOC 2007和VOC 2012数据集都包含20个类别的物体.VOC 2007包含了拥有标签的 trainval(5011张图片)和test(4952张图片).VOC 2012包含了拥有标签的trainval(11540张图片)和没有包含标签的test(10991张图片).MS COCO数据集中目标检测任务包含80类物体.使用COCO Challenge 2017作为实验数据集.训练集包含115×103张图片.使用包含20×103张图片的test-dev作为测试集.
3.3 评价指标
在PASCAL VOC 2007和PASCAL VOC 2012的实验中,使用的评价指标是平均精度(mean average precision,mAP).对于每张图片,使用交叉比(IoU)来标记预测框是否正确.用召回率衡量检测出的正确目标占总正确目标的比率,用准确率衡量检测出的目标中正确目标中总目标的比率,在不同的召回率下对准确率进行平均,得到精度AP.最后按照不同类别物体所占的比重对相应的AP加权,最后得到mAP.在实验中采用的IoU为0.5.

3.4 实验结果对比
在PASCAL VOC 2007数据集的实验中,训练集包含VOC 2007 trainval和VOC 2012 trainval,测试集为VOC 2007 test.在训练阶段,总的迭代次数为112×103.学习率在首个64×103为2.5×10-3,接着在剩余的32×103和16×103迭代中衰减到2.5×10-4和2.5×10-5.采用的优化函数是SGD,动量因子设置为0.9,使用的基础网络是在ImageNet上预训练的ResNet101.实验结果如表1所示.
表1 在PASCALVOC 2007测试集上的检测结果
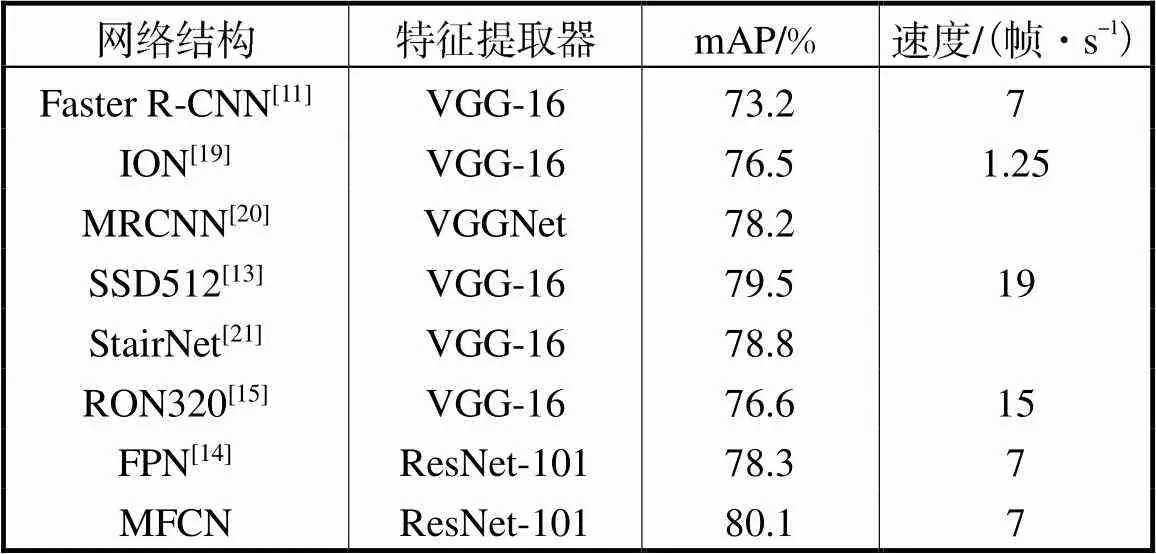
Tab.1 PASCAL VOC 2007 test detection results
由表1可以看出,在PASCAL VOC 2007数据集上的测试结果MFCN比FPN高1.8%mAP,并且检测速度和FPN相当.
在PASCAL VOC 2012数据集的实验中,使用VOC 2007 trainval、VOC 2007 test和VOC 2012 trainval作为训练集,使用VOC 2012 test作为测试集.在训练阶段,总的迭代次数为150×103.学习率在首个86×103为2.5×10-3,接着在剩余的43×103和21×103迭代中衰减到2.5×10-4和2.5×10-5.实验结果如表2所示.
表2 在PASCALVOC 2012测试集上的检测结果
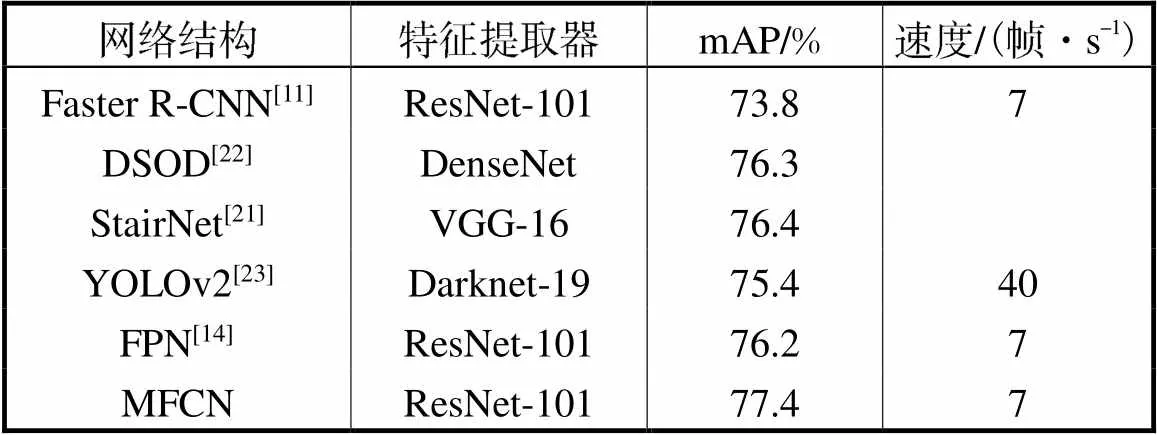
Tab.2 PASCAL VOC 2012 test detection results
由表2可以看出,在PASCAL VOC 2012数据集上的测试结果MFCN比FPN高1.2%mAP,并且检测速度与FPN一致.
为了进一步证明MFCN在大型数据集上的有效性,在MS COCO数据集上进行了测试.在MS COCO的实验中,使用trainval作为训练集,使用test作为测试集.在训练阶段,总的迭代次数为805×103. 在开始的460×103迭代设置的学习率是2.5×10-3,接着在剩余的230×103和115×103迭代中衰减到2.5×10-4和2.5×10-5.实验结果如表3所示.
由表3可以看出,在MS COCO数据集上的测试结果MFCN比FPN高0.4%AP.在小目标的检测上MFCN要比FPN高2.1%AP,这说明特征层堆叠方式可有效保留低层细节特征.在中目标检测上和大目标的检测上,MFCN分别比FPN高1.5%AP和1.2%AP,这说明通过在ResNet101后添加conv6层可更充分地提取网络的高层特征.同时,在检测速度上MFCN和FPN保持一致.
表3 MSCOCO测试集上的检测结果

Tab.3 MS COCO test-dev detection results
4 结 语
针对FPN高层特征图和低层特征图在融合的过程中会造成低层细节特征丢失问题,提出特征图堆叠方式进行特征融合,从而设计特征图堆叠网络并用于目标检测.在PASCAL VOC 2007、PASCAL VOC 2012和MS COCO这3个公开数据集上的测试结果表明,所提算法对于小目标、中目标和大目标均可获得较好的检测效果.
[1] Wang X,Chen Z,Yun J. An effective method for color image retrieval based on texture[J]. Computer Standards & Interfaces,2012,34(1):31-35.
[2] Wang X,Wang Z. A novel method for image retrieval based on structure elements’ descriptor[J]. Journal of Visual Communication and Image Representation,2013,24(1):63-74.
[3] 杨爱萍,张 越,王金斌,等. 基于暗通道先验和多方向加权TV的图像盲去模糊方法[J]. 天津大学学报:自然科学与工程技术版,2018,51(5):497-506.
Yang Aiping,Zhang Yue,Wang Jinbin,et al. Blind image deblurring method based on dark channel prior and multi-direction weighted TV[J]. Journal of Tianjin University:Science and Technology,2018,51(5):497-506(in Chinese).
[4] Huang G,Liu Z,van der Maaten L,et al. Densely connected convolutional networks[C]//IEEE Computer Vision and Pattern Recognition(CVPR). Hawaii,USA,2017:4700-4708.
[5] Ma N,Zhang X,Zheng H T,et al. Shufflenet v2:Practical guidelines for efficient cnn architecture design[C]//European Conference on Computer Vision(ECCV). Munich,Germany,2018:116-131.
[6] Sandler M,Howard A,Zhu M,et al. Mobilenetv2:Inverted residuals and linear bottlenecks[C]//IEEE Computer Vision and Pattern Recognition(CVPR). Salt Lake City,USA,2018:4510-4520.
[7] Unar S,Wang X,Zhang C. Visual and textual information fusion using Kernel method for content based image retrieval[J]. Information Fusion,2018,44:176-187.
[8] Unar S,Wang X,Wang C,et al. A decisive content based image retrieval approach for feature fusion in visual and textual images[J]. Knowledge-Based Systems,2019,179:8-20.
[9] Girshick R,Donahue J,Darrell T,et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]// IEEE Computer Vision and Pattern Recognition(CVPR). Columbus,USA,2014:580-587.
[10] Girshick R. Fast r-cnn[C]// IEEE International Conference on Computer Vision(ICCV). Santiago,Chile,2015:1440-1448.
[11] Ren S,He K,Girshick R,et al. Faster r-cnn:Towards real-time object detection with region proposal networks[C]//Neural Information Processing Systems(NIPS). Montreal,Canada,2015:91-99.
[12] Cai Z,Fan Q,Feris R S,et al. A unified multi-scale deep convolutional neural network for fast object detection[C]//European Conference on Computer Vision (ECCV). Amsterdam,The Netherlands,2016:354-370.
[13] Liu W,Anguelov D,Erhan D,et al. Ssd:Single shot multibox detector[C]//European Conference on Computer Vision(ECCV). Amsterdam,The Netherlands,2016:21-37.
[14] Lin T Y,Dollár P,Girshick R,et al. Feature pyramid networks for object detection[C]// IEEE Computer Vision and Pattern Recognition(CVPR). Hawaii,USA,2017:2117-2125.
[15] Kong T,Sun F,Yao A,et al. Ron:Reverse connection with objectness prior networks for object detection[C]// IEEE Computer Vision and Pattern Recognition(CVPR). Hawaii,USA,2017:5936-5944.
[16] He K,Zhang X,Ren S,et al. Deep residual learning for image recognition[C]// IEEE Computer Vision and Pattern Recognition(CVPR). Las Vegas,USA,2016:770-778.
[17] Everingham M,Van Gool L,Williams C K I,et al. The pascal visual object classes(voc)challenge[J]. International Journal of Computer Vision(IJCV),2010,88(2):303-338.
[18] Lin T Y,Maire M,Belongie S,et al. Microsoft coco:Common objects in context[C]//European Conference on Computer Vision(ECCV). Zurich,Swit-zerland,2014:740-755.
[19] Bell S,Lawrence Zitnick C,Bala K,et al. Inside-outside net:Detecting objects in context with skip pooling and recurrent neural networks[C]// IEEE Computer Vision and Pattern Recognition(CVPR). Las Vegas,USA,2016:2874-2883.
[20] Gidaris S,Komodakis N. Object detection via a multi-region and semantic segmentation-aware cnn model[C]// IEEE Computer Vision and Pattern Recognition (CVPR). Boston,USA,2015:1134-1142.
[21] Woo S,Hwang S,Kweon I S. Stairnet:Top-down semantic aggregation for accurate one shot detection[C]// IEEE Winter Conference on Applications of Computer Vision(WACV). Nevada,USA,2018:1093-1102.
[22] Shen Z,Liu Z,Li J,et al. Dsod:Learning deeply supervised object detectors from scratch[C]// IEEE Computer Vision and Pattern Recognition(CVPR). Hawaii,USA,2017:1919-1927.
[23] Redmon J,Farhadi A. YOLO9000:Better,faster,stronger[C]// IEEE Computer Vision and Pattern Recognition(CVPR). Hawaii,USA,2017:7263-7271.
[24] Shrivastava A,Gupta A,Girshick R. Training region-based object detectors with online hard example mining[C]// IEEE Computer Vision and Pattern Recognition(CVPR). Las Vegas,USA,2016:761-769.
[25] Dai J,Li Y,He K,et al. R-fcn:Object detection via region-based fully convolutional networks[C]// Neural Information Processing Systems(NIPS). Barcelona,Spain,2016:379-387.
Multi-Feature Concatenation Network for Object Detection
Yang Aiping,Lu Liyu,Ji Zhong
(School of Electrical and Information Engineering,Tianjin University,Tianjin 300072,China)
With the rapid development of deep the convolutional neural network,mainstream methods for object detection have been based on deep learning owing to its superior feature representation and excellent detection accuracy.To omit small objects in object detection,a multi-scale algorithm is usually adopted.Existing multi-scale object detection methods can be categorized as image pyramid-based or feature pyramid-based.Compared with the image pyramid-based method,the feature pyramid-based method is faster and better able to take full advantage of the feature information of different convolution layers. The existing feature pyramid-based method fuses feature maps from different scales by adding corresponding elements,which often results in loss of some detailed low-level feature information.To tackle this problem,this paper proposes a multi-feature concatenation network(MFCN)based on a feature pyramid network(FPN). A structure-performing,multi-layer feature map concatenation was designed. Semantic high-level features and detailed low-level features were fused by concatenating feature maps from different feature layers.Objects on each layer were detected to ensure that each layer could contain the feature information of the layer and all layers above it,effectively overcoming the loss of detailed low-level information.To make full use of the high-level features in ResNet101,a new convolutional layer was added and combined with the low-level feature map to extract multi-scale features.Results of the new design showed that detection accuracy on the PASCAL VOC 2007 dataset was 80.1% mAP,and the performance on PASCAL VOC 2012 and MS COCO datasets was superior to that on an FPN.Compared with the FPN,the detection performance of MFCN is even better.
feature pyramid network;object detection;feature concatenation;semantic information
TP391
A
0493-2137(2020)06-0647-06
10.11784/tdxbz201904007
2019-04-04;
2019-08-26.
杨爱萍(1977— ),女,博士,副教授.
杨爱萍,yangaiping@tju.edu.cn.
国家自然科学基金资助项目(61771329,61632018).
Supported by the National Natural Science Foundation of China(No.61771329,No.61632018).
(责任编辑:王晓燕)
猜你喜欢
环球时报(2022-09-19)2022-09-19
热带气象学报(2022年2期)2022-08-24
计算机研究与发展(2022年1期)2022-01-19
计算机应用(2020年12期)2020-12-31
考试与评价·七年级版(2020年4期)2020-10-23
报刊荟萃(上)(2018年3期)2018-04-24
小学教学研究·新小读者(2017年9期)2017-10-25
妇女生活(2016年5期)2016-05-26
建筑工程技术与设计(2015年12期)2015-10-21
文苑(2015年9期)2015-09-10
