
基于领域词典的民宿评论情感分析
2020-04-22 10:38杨云帆朱东霖郑绍阳袁中玉杨秀璋罗子江
科学技术与工程 2020年7期
杨 鑫, 杨云帆, 焦 维, 朱东霖, 郑绍阳, 袁中玉, 杨秀璋, 罗子江
(贵州财经大学信息学院,贵阳 550025)
随着人们生活水平提高,大众精神层次上的需求也在不断增加,旅游逐渐成为一种重要的娱乐方式,其中民宿作为一种新型住宿业态,受到大量游客青睐。近几年中国民宿市场飞速发展,2017年民宿市场营业收入达到145亿元,同比增长70.6%;民宿占住宿市场规模由2015年的2.7%上升到2017年的9.1%;民宿参与者人数达1.67亿人,其中在线用户规模1.47亿人[1]。同时,随着互联网技术飞速进步,人们更愿意在网络平台上通过评价来表达对民宿服务的态度及情感倾向,在这些民宿评论中包含着影响民宿管理者决策和用户购买的有用信息。因此从用户生成的民宿评论中准确地分析其情感状态具有重要价值。
然而当前中外对民宿评论进行情感分析的研究相对较少,张培等[2]通过计量分析和问卷调查的方法对游客选择民宿的意愿倾向进行了研究。房孟春等[3]对民宿评论实施词语聚类,提取出民宿在线信誉评价指标。这些研究方式较为单一且很难挖掘出数据内更深层次的规律。Pang等[4]通过机器学习对评论进行情感分类,但事先需要大量人力物力标注数据。Taboada等[5]利用情感词典和语法规则计算文本内情感词分值,从而判断文本情感,该方法过于依靠词典质量,不具有普遍性。
针对以上问题,提出了一种基于领域词典的情感分析方法,通过SO-PMI(semantic orientation and pointwise mutual information)算法进行情感词扩展,增强词典的领域适用性;利用梯度下降公式赋予程度副词不同强弱的权重值,提高情感计算精度;将LDA(latent dirichlet allocation)主题模型应用于情感分析,实现对民宿用户关注点的有效提取;详尽分析民宿评论中的正负面主题并分析其内在原因,以期为民宿管理者做出更好决策提供数据支持和理论支撑。
1 相关工作
1.1 文本数据情感分析
文本情感分析是指通过计算机对文本中的观点、情感、主客观性、极性进行识别、提取、处理、分类、归纳及推理的研究,是自然语言研究领域中的一个重要分支[6-7]。目前文本情感分析的方法主要有两种:基于机器学习的研究方法和基于情感词典的研究方法[8]。
机器学习是一种属于监督学习的方法,过程中会将文本转化为数字特征,并使用分类器分类。2002年Pang等[4]首次将机器学习应用于影评文本情感分类的研究中,但事先需要对特定领域内的海量数据进行人工标注,时间、人力和设备成本高,且不能适用于非特定领域。
基于情感词典的分析方法,是一种属于无监督学习的方法,过程中需通过情感词典对文本内情感词进行匹配并根据语法规则计算出文本的情感倾向值。相比机器学习,情感词典不仅不需要数据标注,使用成本低,而且易进行词典扩展,被应用于多个领域。如李琴等[9]基于情感词典实现在线评论的情感分类,并对游客满意度进行监测,证明了门票浮动制方法的可行性;张鹏等[10]将扎根理论与情感词典应用于微博突发事件中,并进行了相应的情感分析与舆情引导策略的研究;吴江等[11]通过构建金融情感词典和语义规则对Web金融文本进行了情感分析;王晰巍等[12]基于情感分析对移动图书馆用户生成的内容进行了评价效果研究;樊振等[13]将情感词典与用户评分的弱标注信息相结合对豆瓣电影评论进行了情感分析;安璐等[14]利用情感词典对“魏则西事件”中的利益相关者进行了社会网络情感图谱的研究;崔彦琛等[15]针对消防突发事件提出了一种网络舆情情感词典的构建方法。因此,选择基于情感词典的方法,并在原有基础上扩展了民宿领域词典。
1.2 LDA模型
LDA是一种由文档层、主题层和主题词语层构成的贝叶斯概率模型,可用于文档主题的生成。自从2003年Blei等[16]第一次提出LDA后,人们便将其迅速应用于各个领域[17-21]。但是目前将情感分析方法与LDA主题挖掘相结合的研究还较为少见。王树义等[22]虽在情感分类的基础上对新闻文本进行了主题识别,但未能对文本中不同部分的情感权重加以细致地计算和区分。
2 基于领域词典的情感分析模型
构建了基于领域词典的情感分析模型,其研究的技术思路如图1所示。

图1 情感分析模型技术思路图Fig.1 Technical idea map of emotional analysis model
具体研究步骤如下:
(1)利用八爪鱼Web爬虫完成贵阳民宿评论数据的爬取,并存储到本地,获取的数据包括用户ID、评论时间和评论内容三个特征。
(2)对所获的评论数据进行预处理操作,包括数据清洗、结巴分词、停用词过滤、词性标注等处理。
(3)构建基础情感词典,包括基础词典调用、否定词构建、程度副词构建、语法规则构建等步骤。
(4)采用情感倾向点互信息算法(SO-PMI)对基础情感词典进行专属领域的扩展,包括挑选情感种子词、候选词的获取、筛选、情感倾向值归一化等环节。
(5)对构建的领域词典进行性能检测,并基于领域词典对民宿评论进行情感分析、分类和LDA主题挖掘,最后利用pyLDAvis、词云等技术使分析结果可视化。
2.1 基础词典构建
2.1.1 基础词典选用
目前中国研究成熟的词典有大连理工大学情感词汇本体库[23]、知网的HowNet情感词典及台湾大学中文情感极性词典等。选择的基础词典是大连理工大学情感词汇本体库,此词典将情感分为“乐”“好”“怒”“哀”“惧”“恶”“惊”7个大类和21个小类,其情感词的初始情感强度被设置为1、3、5、7、9五个等级,较其他词典而言,强度划分得更为细致。情感词的情感极性有中性、褒义、贬义3类,分别对应值0、1、2。为便于计算机作情感计算,文中将代表贬义的极性值2修改为-1[24]。 词汇的情感值公式为
s(w)=v(w)p(w)
(1)
式(1)中:s(w)表示词汇的情感值;v(w)表示词汇的情感强度;p(w)表示词汇的情感极性。
2.1.2 否定词构建
否定词的出现往往会使评论的情感极性发生反转。针对情感词前有否定词的这种情况,在算法设计时将情感词的强度乘以-1,并整合常用的否定词,见表1所示。

表1 否定词表
2.1.3 程度副词构建
程度副词会使评论中情感词的情感强度发生改变,如在“房东非常热心”中,程度副词“非常” 增加“热心”的情感强度。使用的程度副词被分为6个级别,分别代表不同强弱的情感倾向。根据实际情况按梯度下降公式分别对每一级别赋予不同权重值,如表2所示。
梯度下降公式为
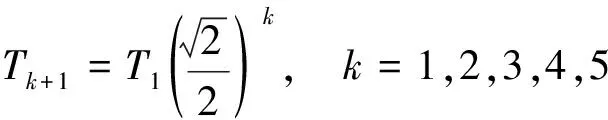
(2)

2.1.4 语法规则构建
针对情感词典进行相应语法规则的构建,主要包括以下3个步骤。
(1)使用python对情感词典、否定词表和程度副词表进行读取。
(2)遍历每条评论中情感词之间的否定词和程度副词,并对其相应的权重值进行计算。评论中每个情感词类的情感值计算公式为
l(w)=d(w)a(w)s(w)m(w)
(3)
式(3)中:l(w)表示情感词类的情感值;s(w)表示情感词汇的情感值;d(w)表示否定词的权重值;a(w)表示情感词前所有程度副词权重值的累加和;m(w)表示情感词前否定词和程度副词间的相对位置。如果程度副词前有否定词修饰时,m(w)赋值为0.5,反之m(w)赋值为1。
d(w)=(-1)n
(4)
(5)
(6)
式中:n表示情感词前否定词的个数;t为该情感词前程度副词的个数;agi为第i个程度副词的权重值。
(3)每条评论包含多个情感词类,其最终的情感值计算如式(7):
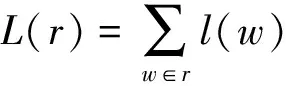
(7)
式(7)中:r为每条评论中情感词类集;L(r)为每条评论的最终情感值,L(r)≥0表示评论情感为正面,反之评论情感为负面。
2.2 领域词典构建
不同领域都有独特表达情感的词语,这类词语所表达的情感往往不能忽略,且在基础词典中并没有被收录。因此,需对基础词典进行专属领域的扩展。用情感倾向点互信息算法(SO-PMI)从实际民宿评论中挑选要扩展的情感词。
2.2.1 情感倾向点互信息算法
SO-PMI[25]是点互信息(pointwise mutual information,PMI)在情感分析领域的更深应用,是用PMI来评估待分析词语的情感倾向(semantic orientation,SO)。PMI用来衡量两个词语w1和w2之间的相互依存关系,计算公式如下:

(8)
式(8)中:P(w1w2)表示w1和w2的真实共现概率,P(w1)和P(w2)分别表示w1和w2单独出现的概率。如果PMI(w1,w2)值越大,则说明w1和w2相关性越紧密,情感倾向越一致。PMI(w1,w2)有3种情况,如式(9)所示:
PMI(w1,w2)

(9)
SO-PMI的计算需要极具代表性且有明显情感倾向的情感种子词,对评论中情感词按词频从高到低进行挑选,选出积极和消极情感种子词各50个,并用Pwi和Nwi来分别表示第i个积极和消极情感种子词,则评论中某词语w的情感倾向值计算公式为
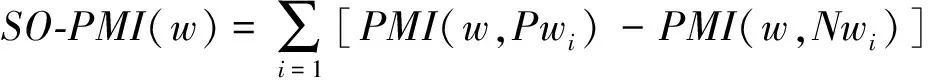
(10)
针对SO-PMI(w)出现的3种情况,做了以下规定:

(11)
通过基础情感词典对获得的候选词进行重复值筛选,最后得到积极情感词164个,消极情感词225个。
2.2.2 情感倾向值归一化
为了与基础情感词典中情感词的强度值相互适应,需要对候选词的情感倾向值进行归一化处理,其归一化公式如下:
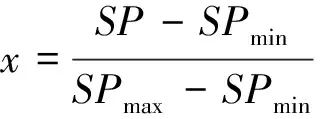
(12)
式(12)中:x表示情感词经归一化处理后的情感倾向值;SP表示候选词的情感倾向值;SPmax表示候选词集中情感倾向极大值;SPmin表示候选词集中情感倾向极小值。
把归一化后的值区间[0,0.2)、[0.2,0.4)、[0.4,0.6)、[0.6,0.8)、[0.8,1]分别赋予相应的情感强度值1、3、5、7、9。最终将候选词和相应的情感强度加入基础情感词典,完成本研究中民宿领域情感词典的构建。其中,扩展的领域情感词如表3所示。
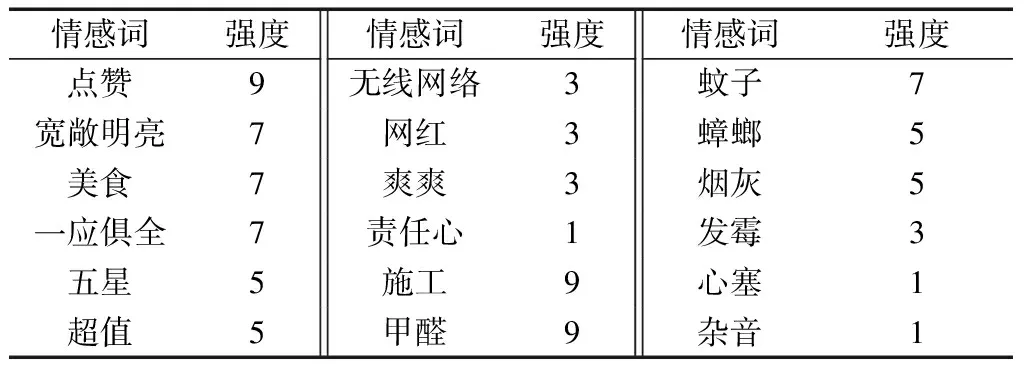
表3 民宿领域词典(部分)
3 实验及结果分析
3.1 实验数据
实验数据选取中国领先的短租民宿在线预定平台——蚂蚁短租作为文本来源,借助八爪鱼数据采集器来实现对贵阳民宿评论的获取,采集从2014年10月到2019年3月共5 074条评论文本,去掉重复及无效评论,如“该房客只打了分,暂无文字内容”“系统默认好评”等句子,得到有效评论3 663条,并调用Python对所获评论进行数据清洗、结巴分词、停用词过滤及词性标注等预处理操作。
3.2 领域词典效果分析
在完成预处理后的评论集中随机抽取1 000条评论作为测试集,由3人对其进行情感倾向标注,并从标注结果中统计标注人数最多的结果作为评论的最终情感倾向。选用准确率、召回率、F特征值3个指标对基础词典和领域词典进行性能对比,对比结果见图2所示。
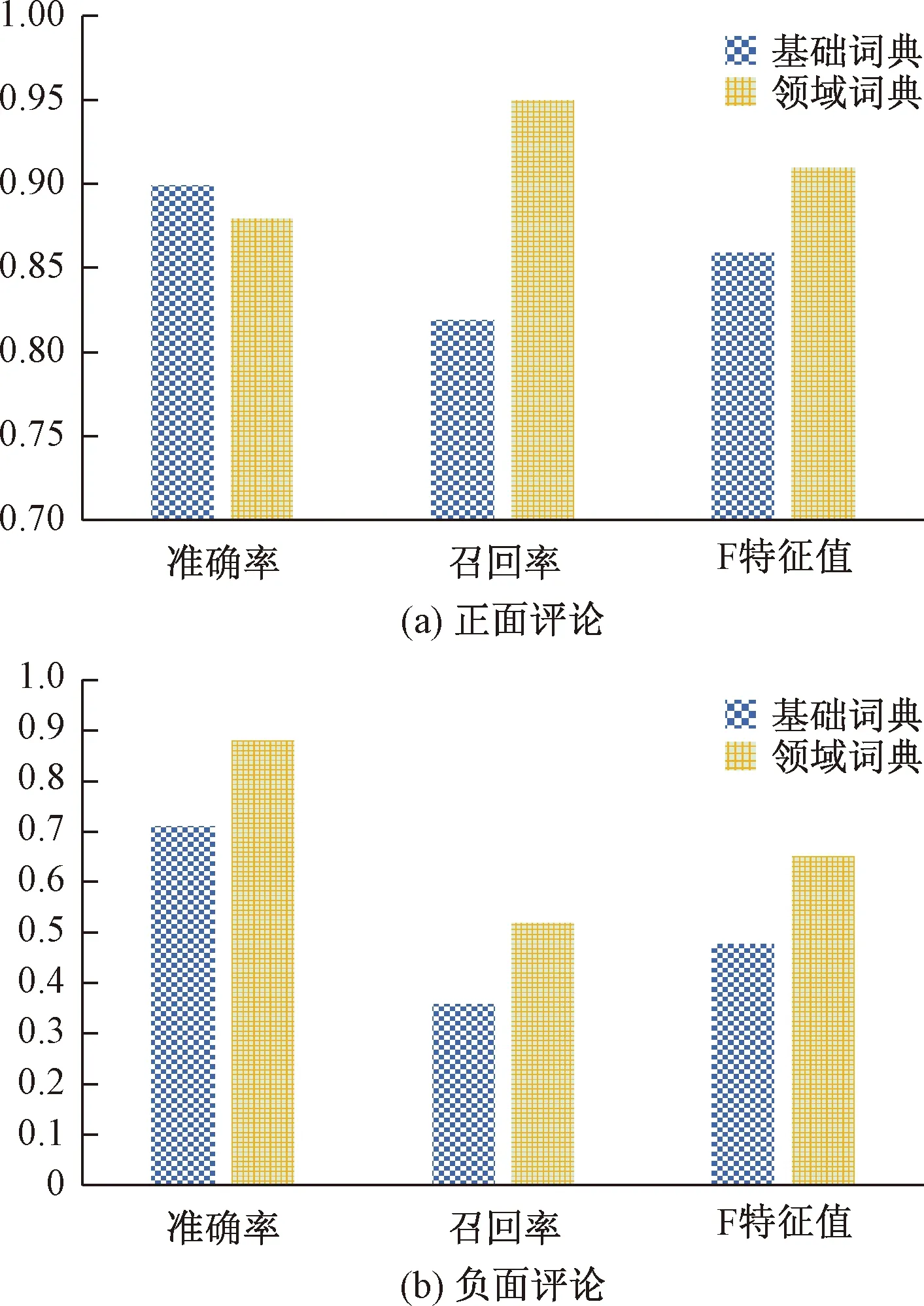
图2 两种情感词典的性能对比Fig.2 Performance comparison of two sentiment dictionaries
从图2中可以看出,领域词典对正面评论[图2(a)]和负面评论[图2(b)]的情感分析性能都有较大提升。就正面评论而言,领域词典在准确率方面与基础词典基本保持一致,但召回率和F特征值分别达到95%和91%,提升幅度为13%和5%;就负面评论来看,领域词典的分类效果良好,相较于基础词典在准确率、召回率和F特征值3项指标上均有不同程度的提高,其中准确率和F特征值提升明显,由71%和48%提高到88%和65%,均提升了17%,这是前期词典构建及扩展过程中程度副词情感倾向梯度设置和负面情感词扩充的缘故。构建的领域词典在针对贵阳民宿领域的实际情感分析中有较优的分类性能,对民宿管理中评论正负情感倾向观测具有一定的实际意义。
3.3 情感分类的主题挖掘
用领域词典对评论集中所有评论进行情感值计算并情感分类,分为正面和负面情感评论集。以正面情感评论集为例,使用LDA模型对其主题挖掘,其中设定迭代次数为50,最佳主题数通过调整动态参数和观测pyLDAvis可视化效果来确定,获得的结果可视化见图3。
图3中,代表3个主题的圆圈相隔较远,说明主题凝聚的效果良好。当鼠标移动到主题2范围内时,该主题中的关键词会在右侧以柱状列表的形式显示出来,红色柱条的长短表示主题2中该关键词的词频大小。这有助于民宿管理者更直观地查看生成主题内关键词的分布情况。
负面情感评论集按同样的方法进行主题挖掘,并结合正面情感评论集的挖掘结果,得出主题及其对应的核心关键词见表4。
通过表4可以看出贵阳民宿的优势即正面主题,包括周边环境、房间设备和房东服务。其中,主题周边环境包含“交通”“公园”“环境”“景点”等核心关键词;主题房间设备包含“房间”“空调”“设施”等核心关键词;主题房东服务包含“老板”“热情”“周到”“接待”等核心关键词。正面主题词的挖掘有利于民宿管理者能更准确地把握已有优势,发展自身特色,从而打造出极具魅力的民宿服务。
相比正面主题,人们更应留意贵阳民宿的劣势即负面主题,包括诚信问题、停车问题和室内问题。诚信问题包含 “骗人”“信任”“理解”“协商”等核心关键词;停车问题包含“停车”“停车场”“停车费”等核心关键词;室内问题包含“霉味”“蚂蚁”“脏乱”“隐私权”等核心关键词。这应该引起民宿管理者的注意,并有针对性地对自身服务进行改善。
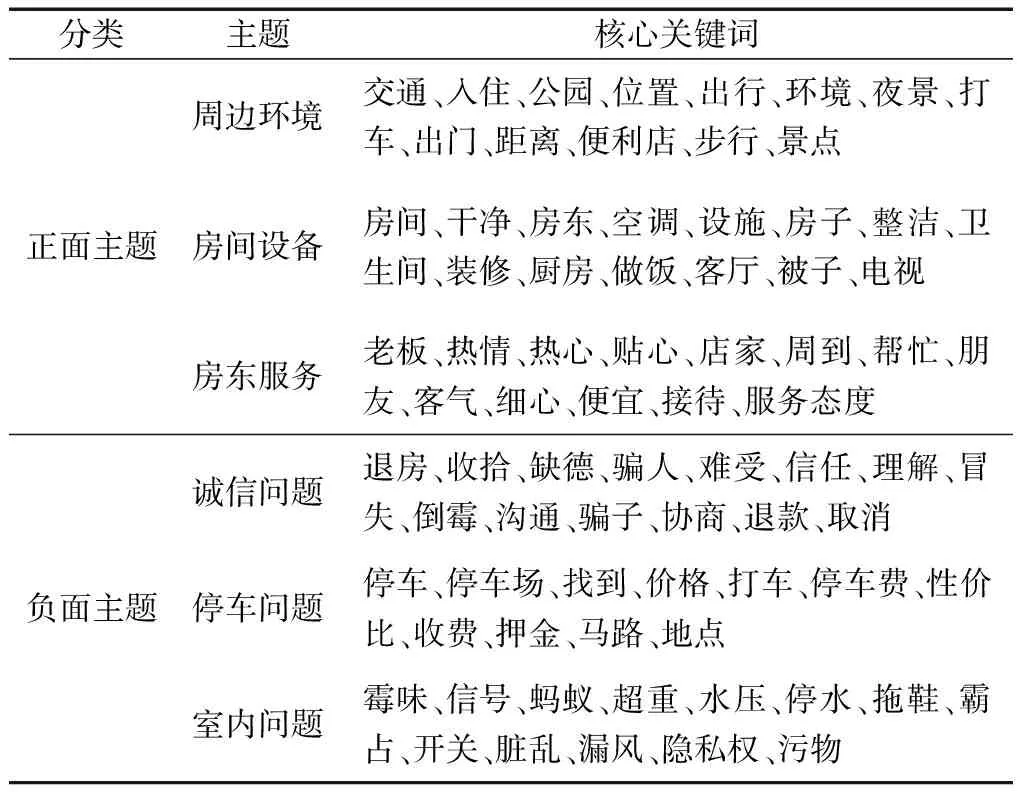
表4 贵阳民宿正负面评论主题挖掘结果
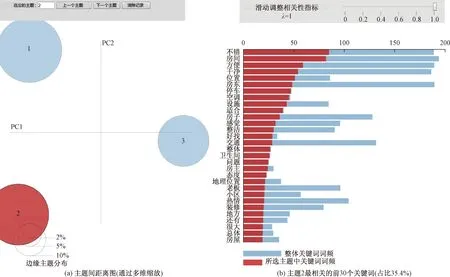
图3 正面评论主题挖掘可视化Fig.3 Visualization of positive comment topic mining
利用词云对贵阳民宿评论进行分析,分析结果如图4所示。图4(a)是基于所有评论的实体词生成,图4(b)和图4(c)分别为基于正面和负面评论中的情感词生成;从图4(a)可知,“房东”“房间”“设施”“环境”“交通”一直是人们的主要关注点;而图4(b)、图4(c)能很直观地展现出用户民宿体验中的感受,如图4(b)中“整洁”“干净”等词直接表达用户对于民宿卫生状况的满意程度,图4(c)中“潮湿”“嘈杂”“混乱”等词反映用户对于民宿环境的不满,这更利于获悉用户评价,从而便于民宿管理者做出更好的决策。

图4 贵阳民宿评论词云图Fig.4 Guiyang homestay comments word cloud
4 结论
提出一种领域词典和主题挖掘相结合的方法,对贵阳民宿评论进行情感分析。实验采用SO-PMI算法实现了基础情感词典的领域扩展,其性能有较大提高,在负面评论集上准确率和召回率分别提升了17%和16%,说明本词典扩展方法的有效性。同时,在情感分类的主题挖掘下,全面分析出民宿评论中所包含的正面主题和负面主题,并利用词云对评论情感词进行可视化展现,使管理者能够清晰地得到用户的情感诉求,有助于做出更适合的具体条件下的最优决策。当然,领域词典也存在不足,一方面本文数据数量有限;另一方面没有深入考虑文本词语间的语义关联,将在后续研究中逐步进行完善。
猜你喜欢
现代装饰(2022年2期)2022-05-23
现代装饰(2021年6期)2021-12-31
文苑(2019年24期)2020-01-06
文苑(2019年24期)2020-01-06
娃娃画报(2019年8期)2019-08-05
英语文摘(2019年5期)2019-07-13
瞭望东方周刊(2017年23期)2017-06-28
中关村(2014年5期)2014-05-15
高中生学习·高三版(2014年3期)2014-04-29
中学英语园地·初二版(2008年3期)2008-07-15
