
68个大豆品种(系)遗传多样性分析
2020-04-18 12:50:48白志元杨玉花武国平卫一超张瑞军
中国农业大学学报 2020年3期
白志元 杨玉花 武国平 卫一超 张瑞军*
(1.山西省农业科学院 农作物品种资源研究所/农业农村部黄土高原作物基因资源与种质创制重点实验室/杂粮种质资源发掘与遗传改良山西省重点实验室,太原 030031;2.山西省农业科学院 园艺研究所,太原 030031;3.山西省农业科学院 农业资源与经济研究所,太原 030031)
大豆起源于中国,已有五千多年的种植历史,是人类食用植物性优质蛋白质和植物油的重要来源[1]。2011—2017年,中国大豆总进口量逐年递增,严重影响着中国大豆产业的可持续发展,造成当前局面主要原因是中国大豆单产较低,种植效益低,引起农民种植大豆的积极性不高。杂种优势现象在生物界普遍存在,自花授粉作物水稻和谷子等已利用杂种优势大幅度提高了产量[2-4]。相对上述作物来说,大豆杂种优势利用研究相对滞后[5],然而,中国在大豆杂种优势利用领域处于世界领先水平,多家单位实现了三系(不育系、保持系和恢复系)配套,审定了多个杂交大豆品种[6-8]。本课题组在大豆杂种优势利用中也进行了有效的突破,审定了山西省首个杂交大豆品种-‘晋豆48号’[9],筛选得到一批三系材料[10]。为了能更好地选育出强优势组合,亲本材料的改良显得尤为重要,杂交育种研究表明,亲本的亲缘关系对杂种优势有着重要的影响[11]。基于此,有必要在三系亲本改良中有目的地使其遗传差异和亲缘关系保持一定的距离。开展品种间遗传多样性的研究,检测其遗传背景,明确品种间的亲缘关系,可对大豆杂种优势的应用提供重要的参考依据。
SSR标记具有简单快速、稳定性好、多态性高、而且呈共显性遗传等优点,被广泛应用于大豆种质资源遗传多样性研究[12-15]。然而,应用SSR对杂交大豆育种中亲本改良方面的研究鲜有报道。本研究选用64对覆盖大豆20条染色体的SSR标记,对本课题组的68个大豆品种(系)进行遗传多样性分析,旨在明确其间的遗传差异及亲缘关系,以期为山西省三系杂交大豆育种中三系亲本的遗传改良提供理论参考。
1 材料与方法
1.1 供试材料
选用山西省农业科学院农作物品种资源研究所大豆杂优课题组征集的68个大豆品种(系)作供试材料(表1),其中,序号1~53为中国品种(系),54~68 为美国品种。
1.2 基因组DNA的提取
取大豆幼嫩叶片,在液氮中研磨后,采用CTAB[16]法提取基因组DNA,采用紫外分光光度仪检测DNA质量及浓度。
1.3 引物,扩增与产物检测
根据公布的SSR标记信息(http:∥www.soybase.org/),选用分布在大豆20条染色体上的64对SSR引物(表2)进行分析,引物由上海生工生物工程技术服务有限公司合成。
采用10 μL反应体系,其中:0.5 μL dNTP(2.5 mmol/L),2 μL Primer(10 μmol/L),1 μL 10×PCR buffer,0.1 μLTaqPolymerase(5 U/μL),5 μL 模板DNA(10 ng/μL),1.4 μL ddH2O。PCR反应程序为:94 ℃ 5 min;94 ℃ 1 min,温度退火30 s,72 ℃ 30 s,34个循环;72 ℃ 10 min;4 ℃保存。每对SSR引物具有特定的退火温度,根据实际Tm值设定引物适合的退火温度,其他程序不变。PCR扩增产物经8%变性聚丙烯酰胺凝胶电泳分离、银染、拍照记录。
1.4 数据的统计分析
根据SSR电泳银染结果统计数据,在相同的迁移位置,有扩增条带赋值为“1”,无条带赋值为“0”。SSR引物位点的多态性信息量PIC(Polymorphism information content),计算公式为:
式中:PIC表示位点i的PIC值,pij表示位点i的第j个等位位点出现的频率。材料间的遗传相似系数(Genetic similarity,GS)按Nei等[17]的方法计算。根据GS值,以不加权成对算术平均法(UPGMA)进行遗传相似性聚类。统计分析在NTSYS-PC 2.1软件系统下进行。
2 结果与分析
2.1 SSR标记的多态性分析
本研究用分布于大豆20条染色体的64对SSR标记对68个大豆品种(系)包括53个中国品种(系)和15个美国品种进行扩增。表2可见,共检测到375个等位基因变异,平均每个位点检测到的等位变异数为5.86个,变化范围为2.00~12.00个。位点的多态性信息含量(PIC)变化范围为0.366~0.900,平均为0.677,其中,引物Satt380最高,为0.900,引物Satt211最低,为0.366。
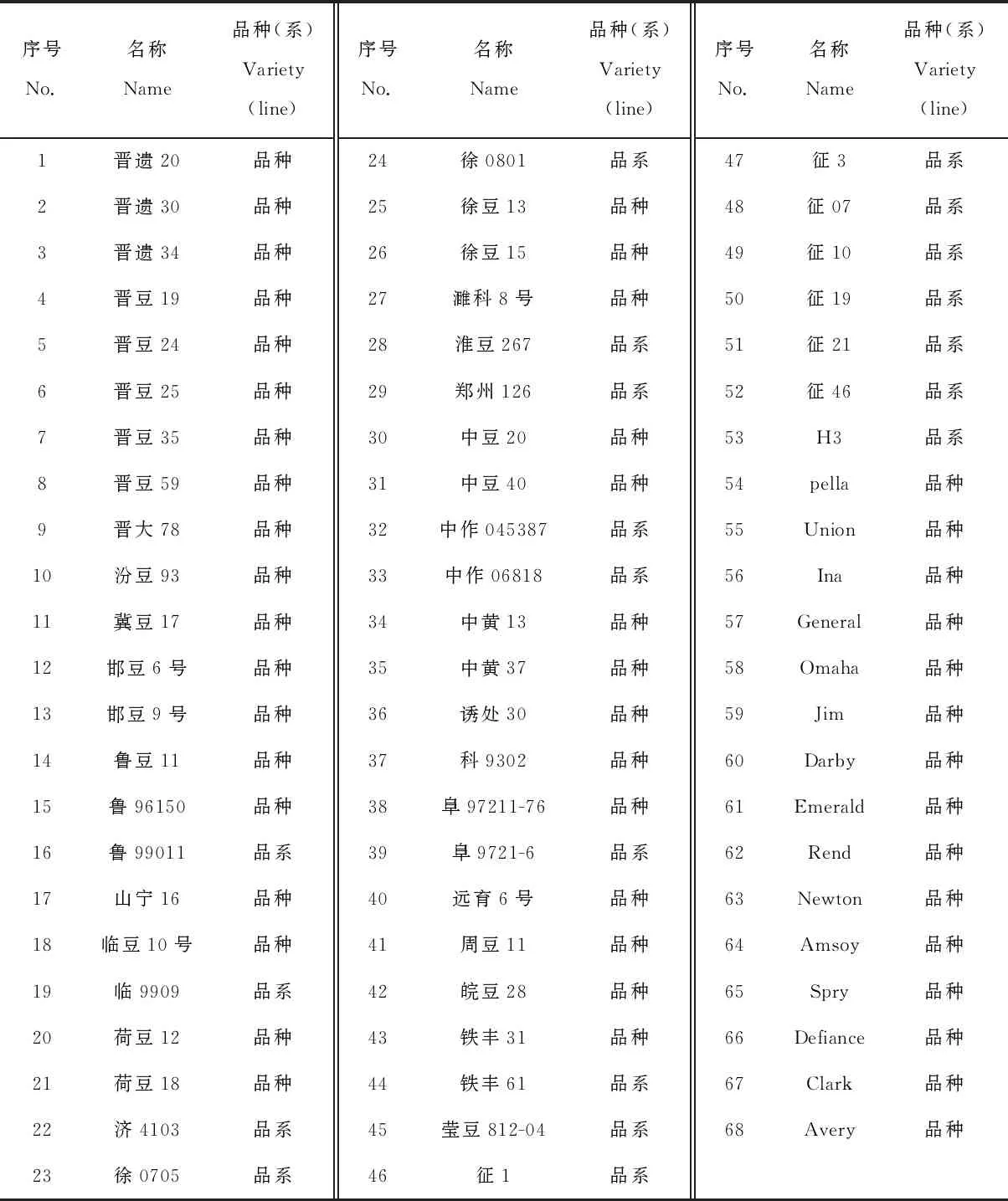
表1 供试大豆品种(系)名称Table 1 The name of tested soybean varieties (lines)
表3可见,53个中国品种(系)共检测出373个等位变异,平均每个位点检测到的等位变异数为5.83个,变化范围为2.00~12.00个,其中,引物Satt380和Satt358这2对等位变异数最多,均为12个,引物Satt211和Satt684这2对等位变异数最少,为2个;位点的多态性信息含量(PIC)变化范围为0.370~0.909,平均为0.682,引物Satt380最高,为0.909,引物Satt211最低,为0.370。15个美国品种共检测到288个等位变异,平均每个位点检测到的等位变异数为4.50个,变化范围为2.00~9.00个,其中,有10对引物的等位变异数为2个,Satt380等位变异数最多,为9个;位点的多态性信息含量(PIC)变化范围为0.309~0.817,平均为0.590,引物Satt266最高,为0.817,引物Satt460,Satt511最低,为0.309。
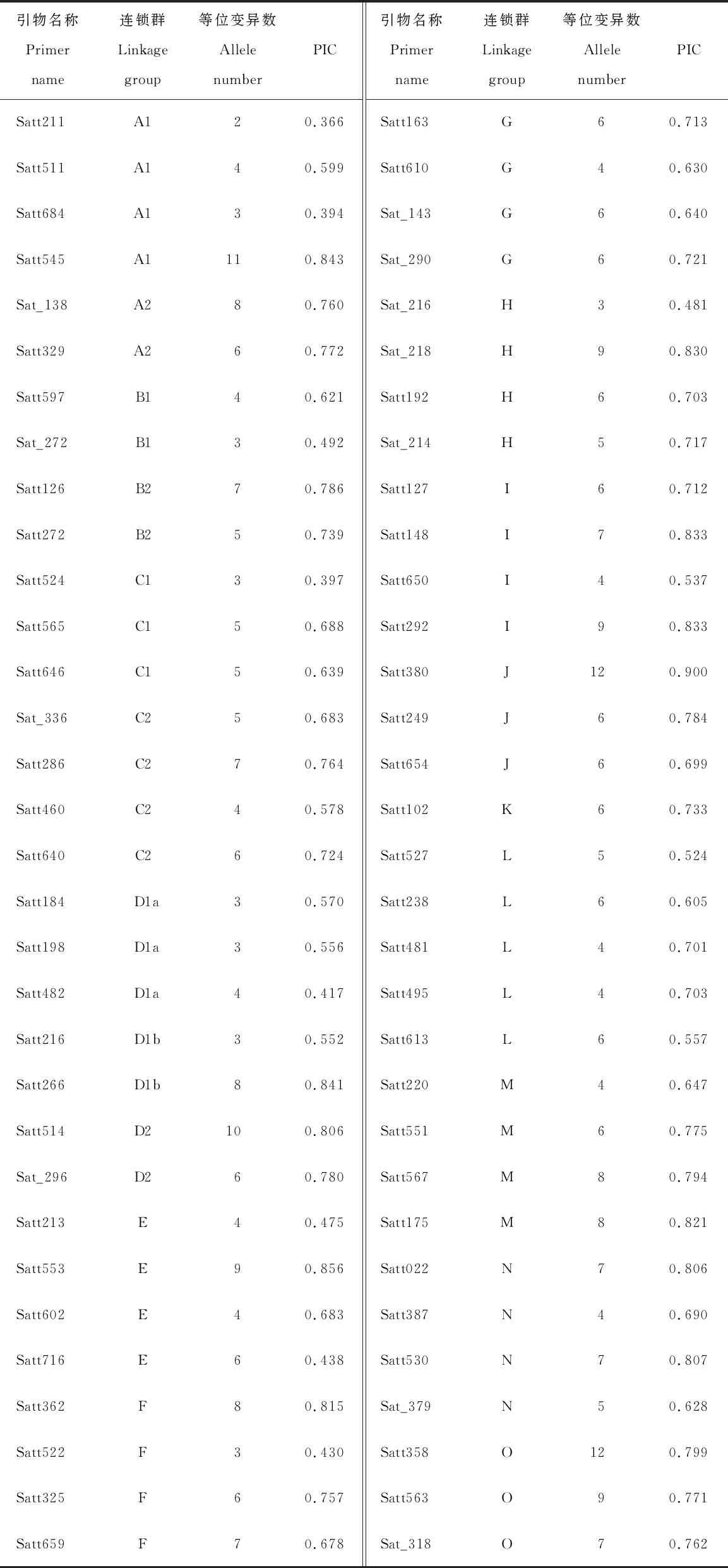
表2 64对SSR引物及所在连锁群、等位变异数和PIC值Table 2 Linkage groups, amplified allele numbers and PIC value of 64 SSR primers
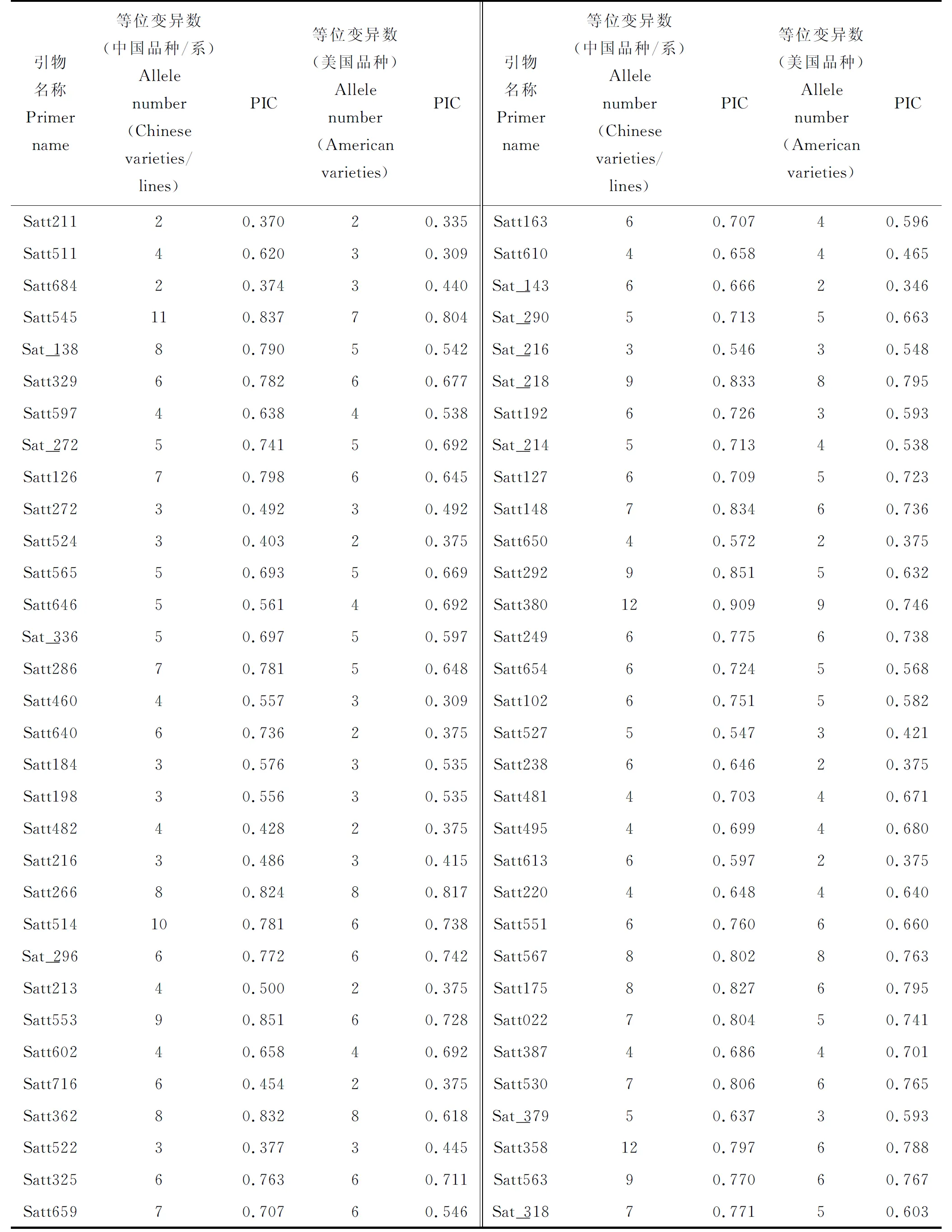
表3 64对SSR引物分别在53个中国品种(系)、15个美国品种中等位变异数和PIC值Table 3 Allele numbers and PIC value of 64 SSR primers in 53 Chinese varieties (lines) and 15 American varieties
2.2 供试大豆品种(系)间的遗传差异与遗传关系
68个大豆品种(系)的遗传相似系数(GS),其变幅为0.529~0.973,平均GS值0.707。其中,53个中国品种(系)间的变幅为0.529~0.973,平均GS值0.690,9(‘晋大78’)和30(‘中豆20’)的遗传相似系数最小为0.529,50(‘征19’)和51(‘征21’)的遗传相似系数最大为0.973;15个美国品种的变幅为0.714~0.870,平均GS值0.772,56(‘Ina’)和66(‘Defiance’)、61(‘Emerald’)和64(‘Amsoy’)、62(‘Rend’)和65(‘Spry’)、64(‘Amsoy’)和68(‘Avery’)的遗传相似系数最小,皆为0.714,58(‘Omaha’)和65(‘Spry’)的遗传相似系数最大为0.870;53个中国品种(系)与15个美国品种两组间的变幅为0.566~0.854,平均GS值0.693,39(‘阜9721-6’)和66(‘Defiance’)的遗传相似系数最小为0.566,16(‘鲁99011’)和60(‘Darby’)的遗传相似系数最大为0.854。
图1可见,68个大豆品种(系)共聚成2类(以GS值0.65为标准)。其中第Ⅰ类包括1(‘晋遗20’)、3(‘晋遗34’)、5(‘晋豆24’)、53(‘H3’)、17(‘山宁16’)、2(‘晋遗30’)、4(‘晋豆19’)以及6(‘晋豆25’)8个品种(系),其余60个品种(系)被聚在第Ⅱ类。第Ⅱ类在相似系数0.69处又可分为5个亚类:第Ⅰ亚类含有5个品种,分别为12(‘邯豆6号’)、22(‘济4103’)、18(‘临豆10号’)、34(‘中黄13’)和35(‘中黄37’);第Ⅱ亚类含有14个品种,分别为23(‘徐0705’)、24(‘徐0801’)、26(‘徐豆15’)、25(‘徐豆13’)、29(‘郑州126’)、37(‘科9302’)、41(‘周豆11’)、42(‘皖豆28’)、38(‘阜97211-76’)、39(‘阜9721-6’)、49(‘征10’)、27(‘濉科8号’)、30(‘中豆20’)和46(‘征1’);第Ⅲ亚类含有31(‘中豆40’)和52(‘征46’)2个品种;第Ⅳ亚类含有32个品种(系),包含供试的全部美国品种,其余17个中国品种(系)分别为7(‘晋豆35’)、33(‘中作06818’)、16(‘鲁99011’)、48(‘征07’)、43(‘铁丰31’)、19(‘临9909’)、32(‘中作045387’)、47(‘征3’)、11(‘冀豆17’)、13(‘邯豆9号’)、21(‘荷豆18’)、40(‘远育6号’)、20(‘荷豆12’)、50(‘征19’)、51(‘征21’)、9(‘晋大78’)和10(‘汾豆93’);第Ⅴ亚类包括14(‘鲁豆11’)、28(‘淮豆267’)、8(‘晋豆59’)、36(‘诱处30’)、15(‘鲁96150’)、44(‘铁丰61’)和45(‘莹豆812-04’)7个品种。
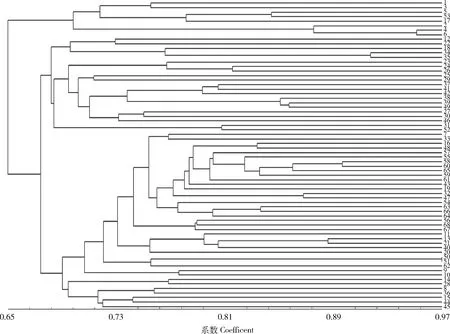
图中序号见表1。See Table 1 for the serial number in the figure.图1 68个大豆品种(系)的SSR分子标记遗传多样性聚类图Fig.1 Dendrogram of 68 soybean varieties (lines) based on genetic similarity by SSR molecular markers
3 讨论与结论
SSR分子标记技术不易受环境影响,且多态性好,已成为研究作物遗传多样性的主要手段。王彩洁等[12]研究自20世纪40年代,中国大豆主产区不同年代大面积种植品种的遗传多样性进行分析。结果显示,平均等位变异数为5.48个,等位变异的变化范围为1.00~14.00个,黑龙江省北部及中南部、吉林省和辽宁省和黄淮海地区的位点多态性信息含量(PIC)依次为0.414,0.469,0.522和0.562。张海平等[14]研究山西省野生大豆种质资源遗传多样性分析结果,多态性信息含量(PIC)为0.201 9~0.858 4,平均0.679 7。Wang等[15]对山西省大豆育成品种、地方品种和野生资源遗传多样性分析结果,多态性信息含量(PIC)为0.585~0.850,平均为0.780。本研究结果表明,64对SSR标记所揭示的68个大豆品种(系)的等位变异数变化范围为2~12个,平均为5.86个,其中53个中国品种(系)平均为5.83个,15个美国品种平均为4.50个;总的位点多态性信息含量PIC变化范围为0.366~0.900,平均为0.677,其中53个中国品种(系)平均为0.682,15个美国品种平均为0.590。本研究位点多态性信息含量(PIC)介于二者之间,高于育成品种,低于地方品种,表明68个大豆品种(系)遗传多样性相对丰富,亲缘关系较远,作为种质资源利用及三系亲本的改良具有一定的价值。
利用聚类分析将不同来源的大豆品种(系)进行分类,明确其亲缘关系,可为三系杂交大豆亲本改良保持一定的遗传距离提供参考依据。本研究中68个大豆品种(系)聚为2大类,第Ⅰ类有8个材料,其中,三系亲本保持系有3个,分别为1(‘晋遗20’)、5(‘晋豆24’)和53(‘H3’),基于此可把该类品种(系)作为保持系改良亲本;第Ⅱ类在相似系数0.69处又可分为5个亚类,其中,第Ⅱ亚类38(‘阜97211-76’)与39(‘阜9721-6’)、第Ⅲ亚类52(‘征46’)、第Ⅳ亚类33(‘中作06818’)与32(‘中作045387’)和第Ⅴ亚类45(‘莹豆812-04’)为三系亲本的恢复系,在各自亚类的基础上参照聚类品种(系)进行恢复系的改良。在大豆种质类群划分研究上,已有很多的报道,SSR聚类结果与地理来源之间存在较大相关性,同一区域内大面积种植品种的同质化现象相当明显[12]。本研究发现,聚类结果与地理来源具有一定相关性,15个美国品种都聚在第Ⅱ类中的第Ⅳ亚类,4个来源于徐州市农业科学院的品种都聚在第Ⅱ类中的第Ⅱ亚类。然而,并不是同一地理来源的品种就会聚在一类,如山西省的10个品种,6个聚在第Ⅰ类,4个聚在第Ⅱ类,这也是通过SSR标记对大豆品种类群划分的意义所在。15个美国品种的位点多态性信息含量(PIC)低于53个中国品种(系)的PIC,表明中国的大豆种质资源的遗传多样性丰富,15个美国品种与17个中国品种(系)聚在了第Ⅱ类中的第Ⅳ亚类,产生该结果可能是中国品种选育中利用了美国品种,为验证该设想,对其中的育成品种进行了系谱信息查询,发现‘铁丰31’和‘冀豆17’等品种有美国品种的直接亲缘关系[18-19]。此外,对系谱来源不清的8个品系划分到相应的类群,53(‘H3’)划分在第Ⅰ类,46(‘征1’)和49(‘征10’)划分在第Ⅱ类中第Ⅱ亚类,52(‘征46’)划分在第Ⅱ类中第Ⅲ亚类,48(‘征07’)、47(‘征3’)、50(‘征19’)和51(‘征21’)划分在第Ⅱ类中第Ⅳ亚类。一些系谱来源不清的大豆种质被划分至不同类群中,依据此结果进行三系亲本改良,可以避免盲目测配,提高利用效率。
猜你喜欢
中国糖料(2023年4期)2023-11-01 09:34:46
作物学报(2022年6期)2022-04-08 01:26:24
草业学报(2022年3期)2022-03-26 02:27:28
国际医学放射学杂志(2021年5期)2021-10-22 07:26:20
中国果业信息(2019年11期)2019-01-05 20:47:24
麦类作物学报(2018年4期)2018-05-11 09:34:08
第一财经(2017年36期)2017-09-25 06:17:11
中国实验诊断学(2017年5期)2017-06-05 15:03:23
西南农业学报(2016年5期)2016-05-17 05:42:23
上海精神医学(2014年6期)2014-12-08 08:14:51
