
基于DEA和遗传BP神经网络的电网技术改造造价预测
2020-04-15 09:39王艳芹容春艳
河北电力技术 2020年1期
董 祯,王艳芹,王 勇,赵 贤,容春艳,聂 婧
(1.国网河北省电力有限公司,石家庄 050021;2.国网河北省电力有限公司经济技术研究院,石家庄 050021)
1 概述
目前,国内外对电网工程的造价预测研究主要集中在新建电网工程造价的预测[1-2],新建电网工程的工程造价指数估算电力造价灵敏度分析[3],以及一些造价体系、指标的研究[4];文献[5]研究了通过相关项目实例,对建筑工程的整体造价进行预测。而在工民建、甚至是电厂的造价预测研究相对较多,文献[6]采用回归分析、神经网络等预测方法对工民建行业进行了预测与对比,文献[7]通过资金时间价值的理念对火电厂工程造价的控制方法进行了研究。
以上的大多数研究主要侧重点是在指标构建和算法更新上,对数据的处理方法还未有相关研究,针对电网技术改造项目的造价预测更是国内研究空白。本文提出更符合实际的数据预处理和预测方法,即基于数据包络分析(Data Envelopment Analysis,DEA)和经过遗传算法(Genetic Algorithm GA)优化后的BP神经网络的电网工程技术改造项目的造价预测。
目前电网技术改造项目主要包括交流变电工程、变电站全站综合自动化改造工程、交流继电保护工程、交流输电工程、通信设备工程、通信光缆工程和调度自动化系统工程7项。造价管理作为技术改造项目建设管理的重要环节,直接影响企业的经济效益和社会效益。技术改造项目种类繁多,分类复杂。因此,合理的指标体系,精确的预测模型都是目前电网生产技术改造项目造价预测亟需解决的问题。根据电力工程定额编制要求中的平均先进水平,通过DEA将存在投入冗余或者产出不足的数据剔除,将这些可能存在较大人为原因导致项目成本过高的数据剔除后,再对遗传BP神经网络进行训练,用以精确预测模型。
2 电网技术改造造价预测建模分析
2.1 DEA模型
2.1.1 决策单元
任何经济系统或生产过程都可以被看作是某个单位(或部门)在一定可能范围内,通过投入不同数量的生产要素同时产出不同数量的产品的活动。每一个需要对投入到产出进行决策的单位(或部门)被称为决策单元(Decision Making U-nits,DMU)。因此,可以认为,每个DMU(第i个DMU常记作DMU i)都代表或表现出一定的经济意义,其基本特点是具有一定的输入和输出,并且再配比投入的转化成产出的过程中,努力实现自身的决策目标——利润最大化。
生产活动可以表示为:

式中:x为DMU中的输入向量;y为输出向量。可以用(1)式来表示这个DMU的整个生产活动。
2.1.2 生产等可能集
以上说的配比,是DEA的一个假设,即生产等可能集T={(x,y)y能用x生产出来},同时满足以下假设:
凸性:对任意(x,y)∈T和[(x',y')∈T]及u∈[0,1]有u(x,y)+(1-u)(x',y')∈T。
锥性:若(x,y)∈T及k≥0,则k(x,y)=(kx,ky)∈T 。
无效性:设(x,y)∈T,及x'≥x,则(x',y)∈T;若y'≤y,则(x,y')∈T。
2.1.3 BCC模型
文中选择BCC模型来筛选电网生产技术改造项目的数据样本。DEA方法构造一条非参数的包络前沿线,有效点位于生产前沿线上,无效点位于前沿线下方。CCR模型见公式(4)、(5),BCC模型见公式(6)、(7)。关于DEA松弛变量的计算规则以及效率的分析方法见参考文献[6-9]。

式中:λj是权重向量。
本文对所有样本数据根据技术改造项目来分类。以静态投资费为输入,以主变压器电压等级:智能化、改造台数、单台容量、单台价格为输出(以更换主变压器为例),分别进行DEA分析,将纯技术效率最低的5%、对神经网络训练会产生噪声的样本剔除。
2.2 遗传算法
本文用遗传算法优化BP神经网络的权值和阈值。具体步骤如下。
2.2.1 初始化种群
产生一个种随机群Xm×n,每个个体X1×n代表神经网络初始权值分布,单个基因值作为一个链接权值和阈值,即个体长度等于神经网络权值加阈值的个数。见公式(7)
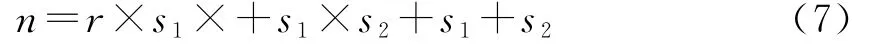
式中:n为个体的长度;r为输入层神经元数;s1为隐含层神经元数;s2为输出层神经元数。本文选择浮点数编码方式对权值和阈值进行编码。
2.2.2 适应度函数
依据适应度函数值对个体进行评价,对所有个体解码得到BP神经网络输入样本,计算输出误差值En,适应度函数f如下:

其中,适应度最大的个体将直接进入下一代种群。
2.2.3 选择算子与交叉算子
本文采用轮盘赌法选择算子。设第i个个体的适应度为fi,则被选中的概率为:

式中:m为种群规模,一般设50~100。
本文的交叉算子选择算术交叉法,交叉概率为pc,交叉算子见式(10):
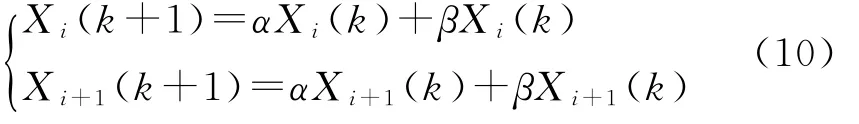
式中:Xi(k)和Xi+1(k)分别为第i个和第i+1个个体在第k位子上的基因;α、β∈[0,1]。
2.2.4 变异算子
本文选择均匀变异算子,对全部基因值以变异率pm在基因域内作随机替换。

式中:q为第P+1个基因值对应的阈值宽度。
2.2.5 判别输出
计算适应度函数f,判断是否满足精度或达到最大遗传次数,并确定输出最优个体或者返回第2步。
2.3 BP神经网络
文献[10]利用改进的BP神经网络对光伏发电功率进行了组合预测。
神经网络的基本单元是神经元,通常情况是多个输入、单个输出的非线性阈值器件。其最基本的McCulloch-Pitts模型结构如图1所示。

图1 McCulloch-Pitts模型结构
传入et层第j个神经元的信号强度为Net,j,其信号强度遵守公式(12)。

式中:wij为第i个神经元作用于第j个神经元的权值。xi是输入信号,或者是上一层神经元对该神经元的输出信息。
θ对于神经元起阈值作用,若Net,j大于θ,则该神经元才能被激活。由此可得出McCulloch-Pitts模型的数学表达公式为

为了对非线性信号传输模拟地更加准确。本文所用的BP神经网络的函数f为S型转换函数(Sigmoid转换函数)。
隐含层神经元数由经验公式获得。

式中:n为输入神经元数量;l为输出神经元数量;a为常数,起调节作用,a∈[1,10]。
本文使用正切的S型函数,见(10)式。

2.4 DEA-遗传神经网络模型构建
遗传算法的全局搜索能力强,而BP神经网络在求解局部最优的时候作用突出。文中通过DEA筛选和优化样本数据,再通过遗传算法优化神经网络的权值和阈值,最后通过神经网络对电网生产技术改造项目的工程造价进行了预测,文中算法简称DEA-GA-BPNN算法,其技术路线见图2。

图2 技术路线
3 应用实例分析
3.1 指标确定和参数选择
文中以技术改造交流变电工程中的更换变压器子项为例,设置遗传BP神经网络的最初输入变量(主变压器电压等级,改造台数,单台容量,单台价格,户址类型)和最初输出变量(静态投资)。在DEA分析的过程中,对调神经网络中的输入变量与输出变量。通过引入松弛变量的DEA模型,将综合效率最低的5%的样本剔除。剔除样本后,探究松弛变量均值以优化神经网络输入指标,删去松弛变量过大的指标(在本例中为户址类型)。DEA样本效率分析结果见表1。
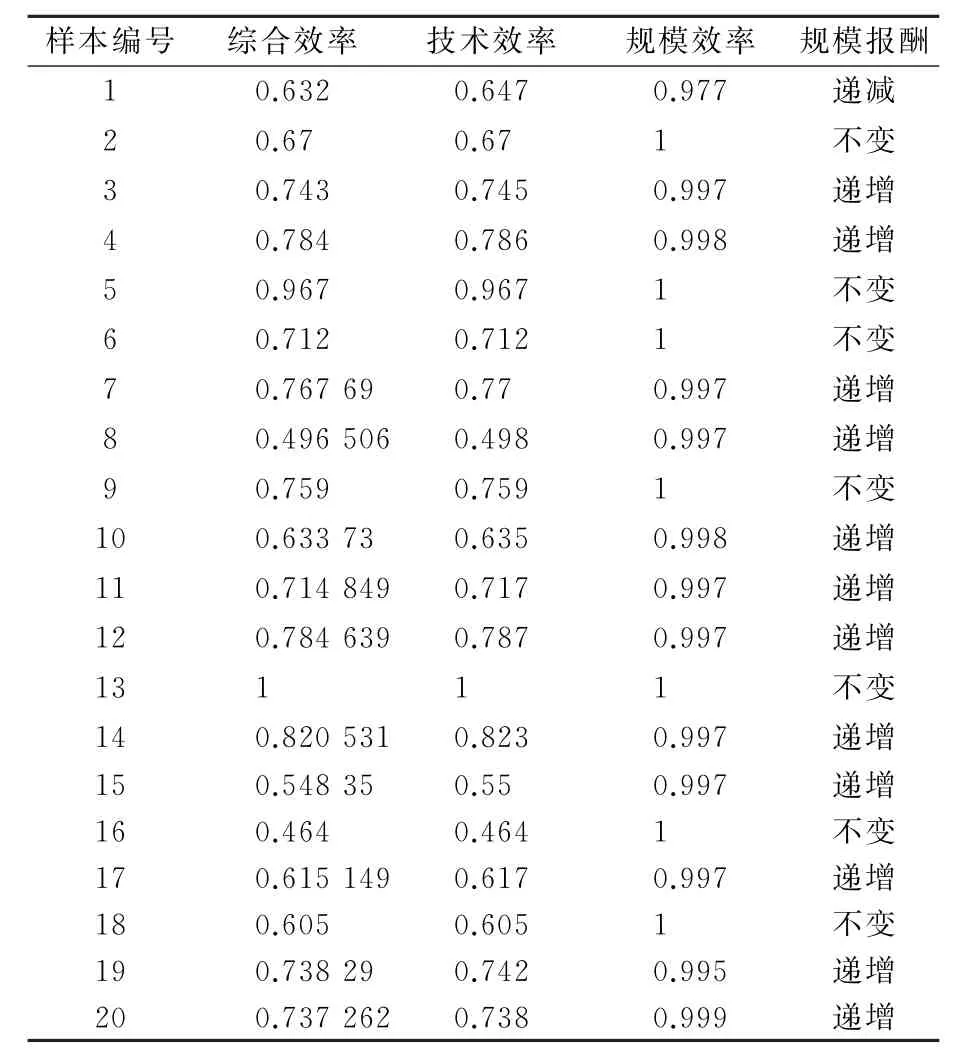
表1 DEA效率分析
在剔除后的数据矩阵中,将DEA的输出变量作为神经网络的输入层神经元,将静态投资作为神经网络输出层的神经元进行训练。GA-BPNN算法主要参数设置见表2。经过反复试验,进化次数在少于100次的情况下,已经能足够搜索到全局最优了,因此本文进化次数选择100。种群规模一般取50~100,种群规模越大,个别的最优解就越不容易主导全体解的进化方向,但是计算时间较长。种群规模越小,找到最优解的速度就越慢。并且有局部优化的问题,本文取80。
3.2 造价预测
在利用遗传算法优化的过程中,权值和阈值的平均适应度函数见图3。由图3可以看出,适应度在进化100次以后已经达到了1.52。获得了较好的初始权值和阈值,可以认定从全局里找到了近似最优解,剩下的可以交给神经网络进一步获得局部最优解。

表2 GA-BPNN算法主要参数

图3 平均适应度曲线
经过遗传算法优化的神经网络的训练的均方误差(Mean Squared Error,MSU)见图4。由图4可知,在第3次训练以后,下降梯度锐减,开始进入局部最优寻解的过程。在第76~87次的迭代过程中,验证集MSU上升,训练集在出现过拟合的情况,因此神经网络跳出计算,判定第75次训练获得了最优解。

图4 均方误差(MSU)
在运行了75次以后开始呈近乎线性的趋势出现神经网络训练失败的情况,在单次训练失败次数超过12次的时候,跳出训练循环,认为已经获得了最优解。
不同训练集、验证集、测试集和全集的技术改造项目工程造价预测与实际数据回归情况见图5。以及技术改造项目预测系统输出结果见图6。发现DEA-GA-BPNN算法的精度非常高,训练集、测试集和验证集的回归检验的相关性都能达到0.968以上。
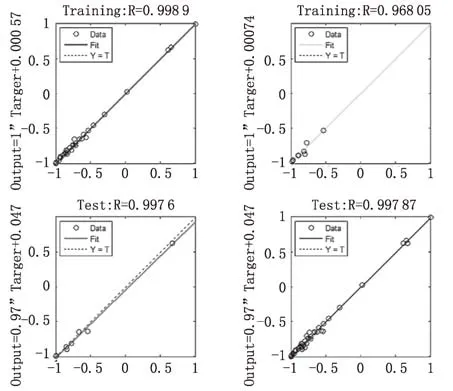
图5 不同集合的预测数据与实际数据的回归情况
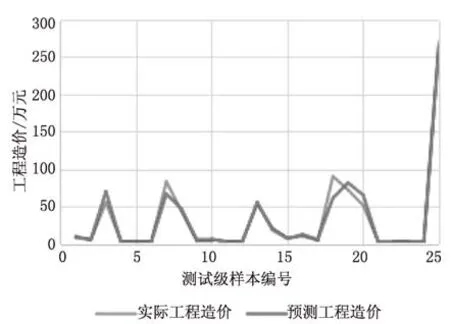
图6 技术改造项目预测系统输出结果
本文提出的预测方法能够进行电网工程技术改造项目的造价预测,预测曲线基本上与实测曲线变化规律一致,预测结果的均方根误差为8.30,对比文献[11-12],本文的均方根误差值属于较小的范畴。
4 结论
本文将DEA和遗传神经网络模型组合,并将其用于电网生产技术改造项目的造价预测,准确性较高,填补了技术改造工程的工程造价预测的研究空白。以技术改造交流变电工程中的更换变压器子项为例,所构建的DEA GA-BPNN模型能够优选输入指标和样本数据,并进行组合预测。合理运用模型中遗传算法和神经网络的部分参数,能够满足广义工程造价预测建模和工程实际仿真需要,对电网生产技术改造项目乃至电网工程的造价预测具有一定的参考价值。
猜你喜欢
计算机仿真(2022年8期)2022-09-28
成都信息工程大学学报(2022年3期)2022-07-21
邮电设计技术(2021年2期)2021-03-13
汽车工程(2021年12期)2021-03-08
电子制作(2019年16期)2019-09-27
电子制作(2019年24期)2019-02-23
计算机与数字工程(2018年5期)2018-05-29
计算机测量与控制(2018年3期)2018-03-27
当代旅游(2016年10期)2017-04-17
财经理论与实践(2015年2期)2015-04-16
