
基于注意力机制的社交垃圾文本检测方法
2020-04-15 03:47曲强于洪涛黄瑞阳
网络与信息安全学报 2020年1期
曲强,于洪涛,黄瑞阳
基于注意力机制的社交垃圾文本检测方法
曲强,于洪涛,黄瑞阳
(国家数字交换系统工程技术研究中心,河南 郑州 450002)
在社交网络中,大量的垃圾文本严重威胁用户的信息安全与社交网站的信用体系。针对噪声性与稀疏性问题,提出一种基于注意力机制的卷积神经网络检测方法。在经典卷积神经网络的基础上,该方法增加了过滤层,并在过滤层设计基于朴素贝叶斯权重技术的注意力机制,解决了噪声性问题。并且,它改变了池化层原有的策略,采用基于注意力机制的池化策略,缓解了稀疏性问题。结果表明,相对于其他检测方法,所提方法的检测准确率在4个数据集上分别提高了1.32%、2.15%、0.07%、1.63%。
社交网络;信息安全;垃圾文本;注意力机制
1 引言
随着移动互联网技术的广泛应用,在线社交网络由于具有便捷、灵活、内涵丰富的特性而快速成为人们生活重要的组成部分,如Facebook、Twitter、Google、新浪微博、微信等流行社交网络。目前,在线社交网络的用户数量呈指数级别增长,据统计,2018年春节期间微信和WeChat的合并月活跃账户数超过10亿。社交网络由于蕴含的巨大用户隐私信息及其广阔的商业价值,成为不法分子图谋不轨的目标。大量发送垃圾文本是不法分子攻击社交网络的重要手段之一。其中,本文中的垃圾文本指:以为商品营造虚假事实、威胁网络安全等为目的,大量发送的商品推销文本、虚假评论文本、热点事件的谣言等文本内容。根据2013年的社交网络垃圾文本统计报告,2013年1–6月,社交垃圾文本数量增长355%,每200条社交文本中有1条是垃圾文本,它们对5%的社交应用App造成一定程度的威胁。社交网络的垃圾文本不仅恶化社交网络环境,影响用户体验,危害用户信息安全,而且对社交网络的可用性以及安全性造成一定程度的影响[1]。
针对社交网络垃圾文本的危害,国内外学者对社交网络垃圾文本检测方法进行了大量的理论研究。Ratkiewicz等[2-3]提出基于关键词的检测方法,该类方法利用统计的方法提取垃圾文本中频繁出现的关键词,并根据这些关键词检测垃圾文本。该方法计算复杂度较低,并且取得了一定的检测效果,但存在以下两个问题:①该方法需要人工设计提取的关键词,不具有普适性;②该方法提取关键词特征表示,在计算机中表示为0/1,并且其维度大小为关键词数目,因此关键词特征表示存在稀疏性问题[4]。
为解决基于关键词方法存在的非普适性问题与稀疏性问题,研究者提出基于神经网络的检测方法。例如,CNN[5]、RNN[6]、LSTM[7]、GRU[8]等神经网络方法。其中,CNN模型利用卷积核与池化核可以有效提取文本的深层认知特征;RNN等模型利用时序神经单元提取文本的时序特征。但它们都存在以下2个问题:①该方法对原始文本进行检测,缺乏合理的处理文本噪声单词的机制;②该方法池化层策略虽然选取了具有显著区分能力的特征,如最大池化策略选取最突出的特征,平均池化策略选取平均的特征等,但这些池化策略目的单一,并且不能动态地进行优化,即不能自动选取贡献最大的文本特征。
为实现自动选取贡献最大的文本特征,研究人员提出注意力机制模型,即根据句子中每个单词对于分类结果的贡献程度,赋予每个单词不同的权重,以此表示模型对于每个单词的注意力。目前,基于注意力机制的深度神经网络方法根据利用信息类型的不同可以分为两类:利用外部信息的方法和不利用外部信息的方法。①在利用外部信息的方法中,AHNN[9]、AP-CNN方法[10]利用CNN模型提取文本整体含义,辅助LSTM模型进行注意力表示,但模型中的CNN模型仅起到辅助生成作用,并且使用文本信息的外部信息帮助,计算复杂度较高。②在不利用外部性信息的方法中,Semantic-CNN方法[11]在过滤层加入注意力机制,提出利用语义特征进行初始化过滤,来提升文本分类的实验精度。AP-BiRNN[12]、AP-BiLSTM方法[13]在特征表示层与分类层间加入注意力机制,进一步识别有效特征单词,提升了文本分类精度。虽然基于注意力机制的神经网络方法利用注意力机制可以提取足够的特征表示,缓解稀疏性,但是依旧存在噪声性[4]问题。
针对基于关键词方法面临的稀疏性问题,基于神经网络与注意力机制方法面临的噪声性问题,在不借助外部信息的情况下,本文提出基于注意力机制的卷积神经网络(MA-CNN)检测方法,主要内容如下。
1) MA-CNN在原始CNN模型基础上增加过滤层,并且在过滤层融合关键词提取的思想,设计基于朴素贝叶斯权重技术[14]的注意力机制。通过提取具有检测效果的关键词,该方法有效降低了文本中噪声含量,解决了噪声性问题。
2) MA-CNN在池化层融合注意力机制的思想,采用基于注意力机制的池化策略。通过注意力机制给具有检测效果的单词赋予较高的权重,有效提取文本的特征表示,缓解稀疏性问题。需要说明的是,本文中的注意力机制池化策略与目前流行的RNN注意力机制不同,不同之处在于RNN注意力机制是基于每个时刻单元重新赋予权重,而本文中的注意力机制池化策略是基于每个核内部单元重新赋予权重。
3) 最后,本文在Youtube、Opinion、Telephone与E-mail这4个数据集上进行实验,结果表明,相比于传统深度神经网络方法与基于注意力机制的深度神经网络方法,本文提出方法的检测准确率在4个数据集上分别提高了1.32%、2.15%、0.07%、1.63%。
2 MA-CNN模型
针对社交网络文本的噪声性与稀疏性问题,本文提出基于注意力机制的卷积神经网络模型,该模型分为5层,分别是过滤层、嵌入层、卷积层、池化层以及分类层。
2.1 过滤层
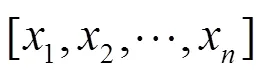
基于朴素贝叶斯权重技术的注意力机制:根据式(1)计算每个单词的朴素贝叶斯权重,然后按照条件选取一定数量的关键词,从而过滤噪声。
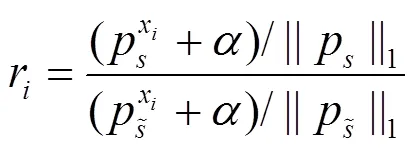
2.2 嵌入层
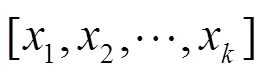
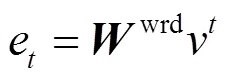
2.3 卷积层
2014年,YoonKim提出新的CNN模型[5],解决了文本分类问题并且取得了良好的效果。本文提出的MA-CNN模型在卷积层沿用了YoonKim设计模型的卷积核结构,但在池化层放弃了原来的最大池化策略,采用新的注意力机制池化策略,图1展示了仅带有大小为2卷积核的MA-CNN模型的卷积层、池化层以及分类层设计。
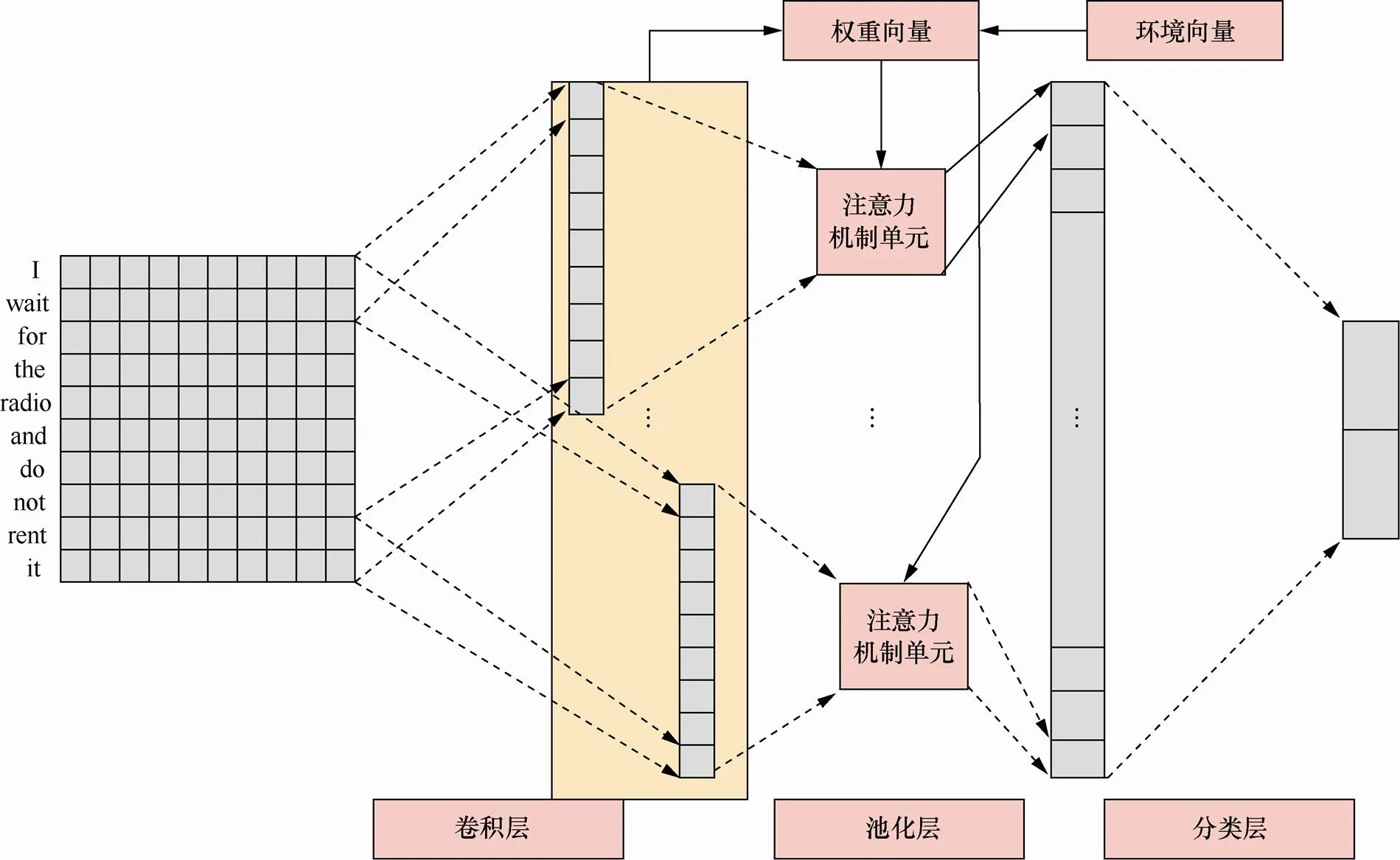
图1 卷积核为2的MA-CNN模型
Figure 1 The MA-CNN model with convolution kernel size of two
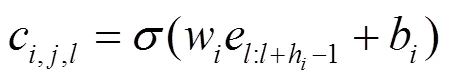
2.4 池化层
针对CNN池化策略单一并且不能动态更新的问题,MA-CNN模型在池化层放弃了原来的最大池化策略,根据注意力机制的思想,提出基于注意力机制的池化策略。
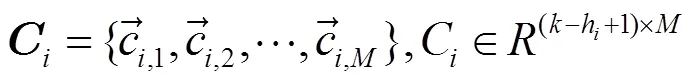
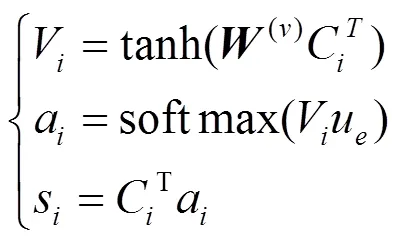
2.5 分类层
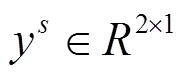
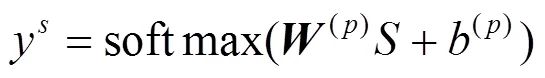
基于交叉熵的定义,本文中Loss函数定义如式(6)所示,根据损失函数的梯度求导,可以进行反向传播学习。
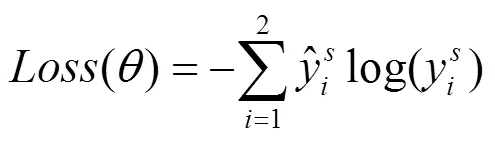
3 实验
3.1 实验设置
(1) 数据集
为验证MA-CNN方法的检测效果,本文通过在4个数据集上进行实验,进一步评价MA-CNN的检测效果。本文使用的4个数据集情况如表1所示。

表1 实验数据集
1) Youtube数据集
该数据集是利用Youtube的API爬取形成的,包含2015年1−3月的5个访问次数最多的视频的评论数据,共1 005条垃圾评论信息和956条正常评论信息。
2) Opinion数据集
该数据集由几个网站的数据集组成,包含400条来自TripAdvisor网站的可信积极评论,400条来自Expedia、Hotels.com、Orbitz、Priceline、TripAdvisor、Yelp等网站的可信消极评论,400条来自Amazon Mechanical Turk的虚假积极评论,400条来自Amazon Mechanical Turk的虚假消极评论。
3) SMS数据集
该数据集由4个SMS数据集组成,包含来自Grumbletext Web Site的425条垃圾信息,来自NUS SMS中心的3 375条正常信息,来自Caroline Tag's PhD论文的450条正常信息,来自SMS Corpus 0.1的1 002条正常信息和433条垃圾信息。
4) E-mail数据集
该数据集通过邮件系统采集形成,包含1 813条垃圾邮件信息与2 788条正常邮件信息。
(2) 实验环境
本文使用的实验环境为Ubuntu16.04系统,8个CPU处理器以及23.5 GB内存,编程语言为Python3.6,编程框架为Tensorflow。
(3) 实验设置
在过滤层,MA-CNN使用基于朴素贝叶斯权重技术的注意力机制。在嵌入层,MA-CNN使用随机化的表示方法,单词表示向量维度为128维。在卷积层,MA-CNN使用核大小为3、4、5的3种卷积核,每种卷积核数目为100个。在池化层,MA-CNN采用基于注意力机制的池化策略。在分类层,MA-CNN采用softmax函数。在实验中,训练集与测试集的比例为9:1,实验过程进行10次,取10次检测准确率的均值作为最终的结果。
(4) 评价指标
本文采用检测准确率评价实验各个方法的实验效果,这里的检测准确率是所有社交文本的检测准确率,不仅包含垃圾文本的检测准确率,而且包含正常文本的检测准确率。因此,检测准确率的计算方法如式(7)所示。
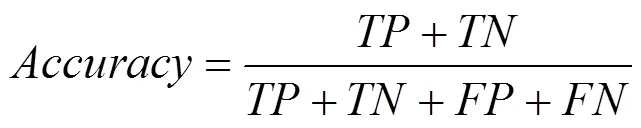
其中,TP表示真实类别为正常文本,模型预测类别仍为正常文本的文本数目;表示真实类别为垃圾文本,模型预测类别仍为垃圾文本的文本数目;表示真实类别为垃圾文本,模型预测类别却为正常文本的文本数目;表示真实类别为正常文本,模型预测类别仍为垃圾文本的文本数目。
3.2 实验结果
在实验部分中,本文首先将提出的MA-CNN方法与6种方法进行对比,包含4种传统的深度神经网络方法与2种目前流行的基于注意力机制的深度神经网络方法(semantic-CNN、AP-BiLSTM),验证MA-CNN方法的检测性能效果。其次,在CNN模型的基础上,分别对嵌入层表示方法、卷积层激活函数以及池化层注意力机制对检测结果的影响进行了探讨。
实验1 不同检测方法的检测性能对比
根据表2的实验结果,在4个经典的深度神经网络算法中,CNN模型在Youtube、Opinion与SMS这3个数据集上的检测准确率比较高,而LSTM模型在E-mail数据集上的检测准确率比较高,可以看出CNN模型在文本分类与检测的效果一般好于循环神经网络模型。因为卷积神经网络更加注重文本内容的深度语义特征,而循环神经网络更加注重文本字符的时间序列特征,所以对于文本分类与检测这种偏向于区分语义特征的任务而言,卷积神经网络,即CNN模型的检测效果表现得更好。由于CNN模型良好的检测效果,因此在后续对于各个层次的机制与方法的实验中,实验选取的基础模型是CNN模型,不是循环神经网络模型。
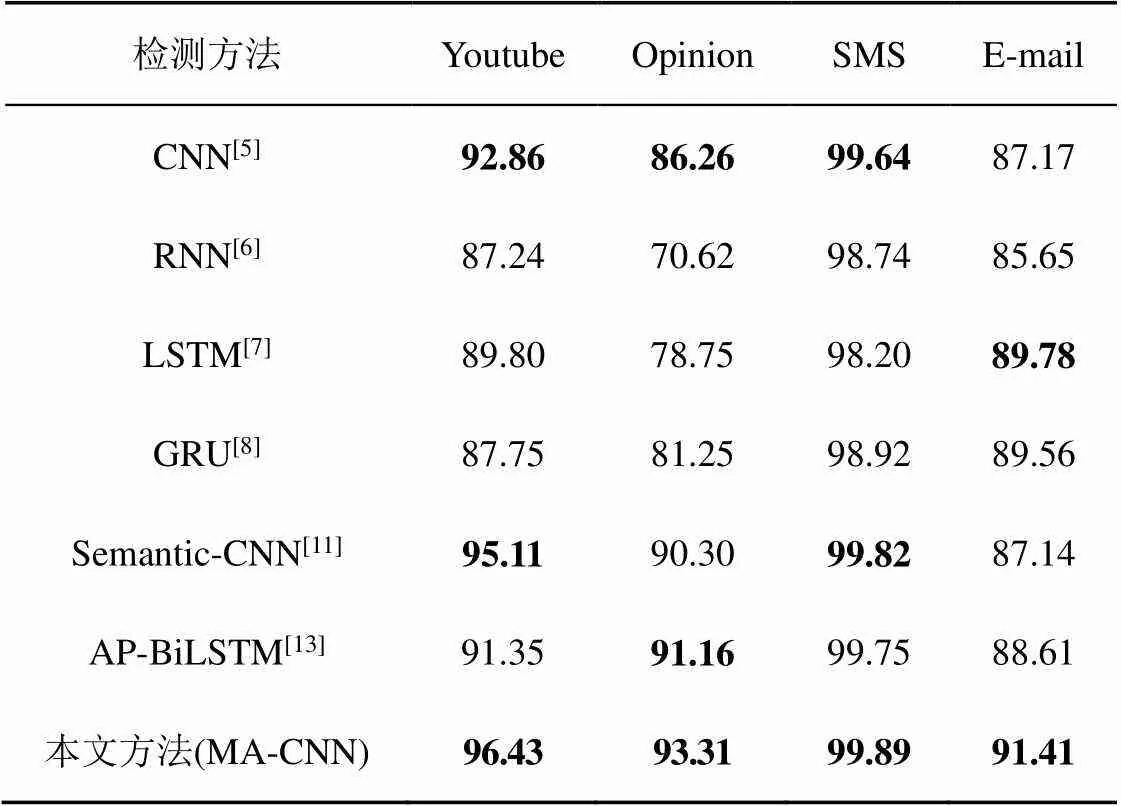
表2 不同检测方法的检测性能对比
另外,将6种方法在各个数据集上检测效果比较好的方法与本文提出的MA-CNN模型进行对比,相对于每个数据集上的最佳算法,MA-CNN模型在4个数据集上分别有1.32%、2.15%、0.07%、1.63%的提升,验证了MA-CNN模型可以有效检测社交网络垃圾文本。
实验2 嵌入层表示方法的影响
在CNN模型的基础上,本部分实验由嵌入层表示方法对检测准确率的影响进行探究,分别采用4种表示方法:随机化方法、SkipGram方法、CBOW方法与Glove方法。
根据表3的实验结果,使用不同的表示方法的CNN模型在不同数据集上表现性能不一般。例如,对于SMS数据集,使用Random+CNN模型的检测准确率最高;对于Youtube与E-mail数据集,使用CBOW+CNN模型的检测准确率最高;对于Opinion数据集,使用Glove+CNN模型的检测准确率最高。尽管对于这4个数据集,使用SkipGram+CNN模型的检测准确率都不是最高,但检测准确率稳定在比较高的水平。
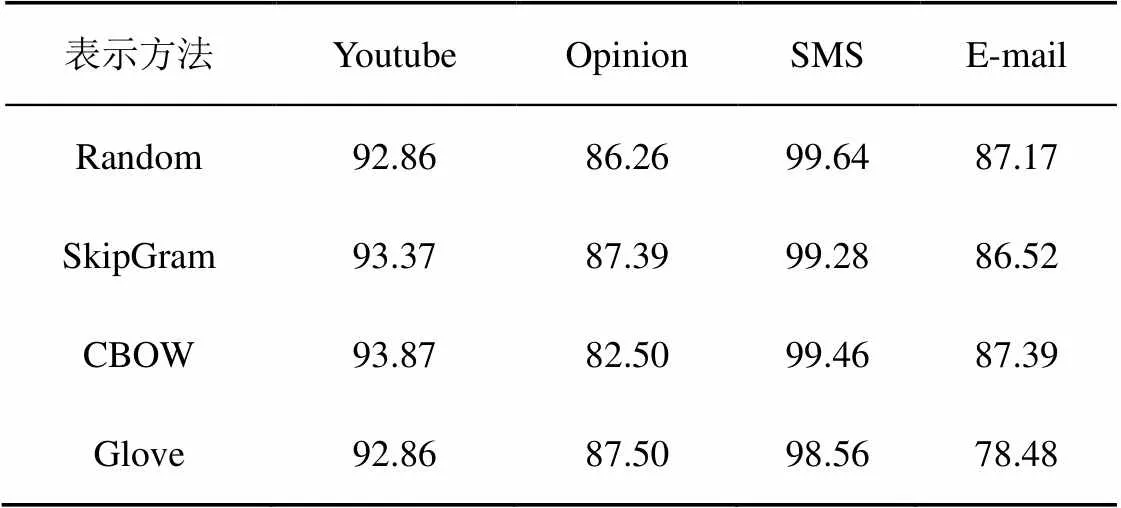
表3 嵌入层表示方法的影响
实验3 卷积层激活函数的影响
在CNN模型的基础上,本部分实验由卷积层激活函数对于检测准确率的影响进行探究,分别采用relu函数、sigmoid函数、tanh函数、softplus函数、softsign函数与leakly-relu函数这6种常用的激活函数。
根据表4的实验结果,使用不同的激活函数CNN模型在不同数据集上表现性能不一。总体而言,使用sigmoid函数、tanh函数与softsign函数的CNN模型表现性能很差,与每个数据集的最高检测准确率有比较大的差距。而使用relu函数、softplus函数与leakly-relu函数的CNN模型表现性能较好,其中,relu+CNN模型在Opinion与SMS数据集上表现最好,领先其他方法0.56%与0.41%;使用softplus+CNN模型在Youtube与E-mail数据集上表现最好,领先其他方法0.51%与0.22%。

表4 卷积层激活函数的影响
实验4 池化层池化策略的影响
在CNN模型的基础上,本部分实验对池化层池化策略对检测准确率的影响进行探究,分别采用最大池化策略、最小池化策略、平均池化策略与注意力机制池化策略这4种池化策略,如图2所示。
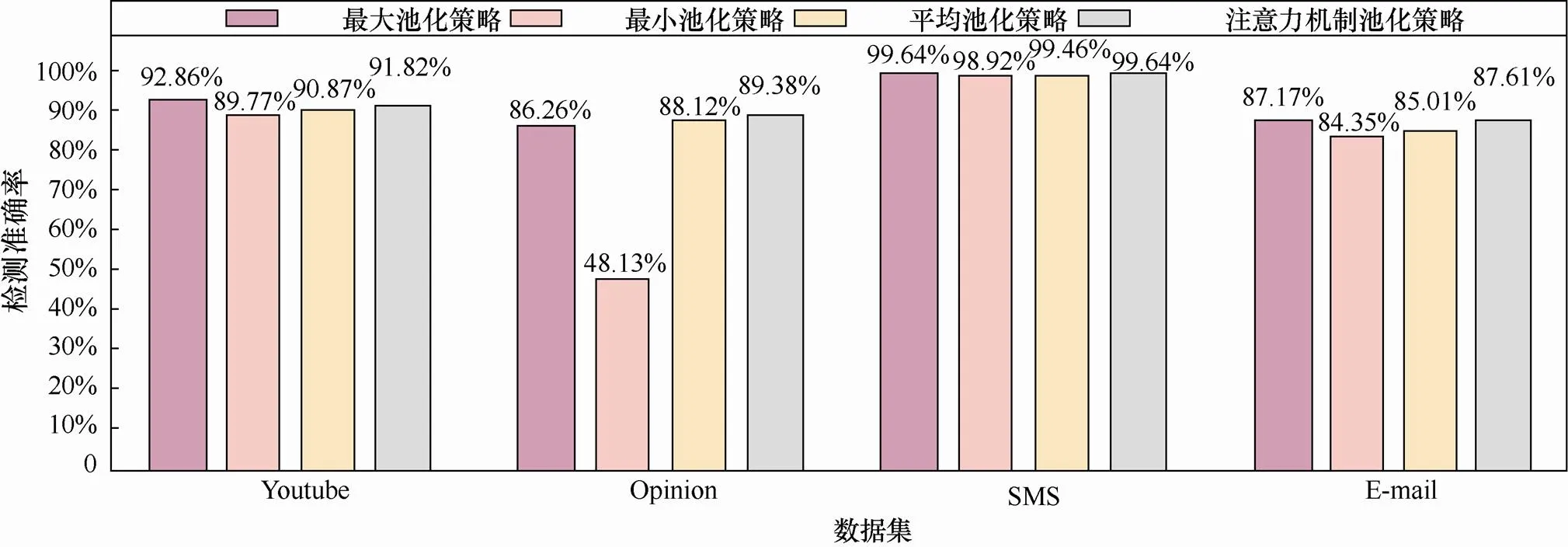
图2 池化层池化策略的影响
Figure 2 The influence of pooling strategies in the pooling layer
根据图2的实验结果,使用不同的池化策略在不同的数据集上表现性能不一。总体而言,相对于传统的3种池化策略,基于注意力机制的池化策略在Opinion、SMS、E-mail数据集上取得了最好的效果。但在Youtube数据集上,相对于最大池化策略,使用注意力机制策略的CNN的检测准确率下降了1.04%。
4 结束语
针对卷积神经网络方法检测社交网络垃圾信息的噪声性与稀疏性问题,本文提出了一种注意力机制的卷积神经网络(MA-CNN)检测方法。该方法首先在过滤层融合了关键词提取的思想,采用了基于朴素贝叶斯权重技术的注意力机制,降低文本中的噪声含量,解决了稀疏性问题。其次,在池化层融合了注意力机制的思想,采用了基于注意力机制的池化策略,缓解了稀疏性问题。未来,将利用迁移学习的思想进一步解决社交网络垃圾文本检测中的标注瓶颈问题。
[1] ZAFARANI, REZA, HUAN LIU. 10 bits of surprise: detecting malicious users with minimum information[C]//The 24th ACM International on Conference on Information and Knowledge Management. 2015: 423-431.
[2] RATKIEWICZ, JACOB, et al. Detecting and tracking political abuse in social media[C]//ICWSM. 2011: 297-304.
[3] BENEVENUTO, FABRICIO, et al. Detecting spammers on twitter[C]//Collaboration, Electronic Messaging, Anti-abuse and Spam Conference. 2010: 12.
[4] SONG G E. Short text classification: a survey[J]. Journal of Multimedia, 2014, 9(5): 635.
[5] YOON K. Convolutional neural networks for sentence classification[J]. arXiv preprint arXiv:1408.5882, 2014.
[6] MIKOLOV, TOMAS, et al. Recurrent neural network based language model[C]//Eleventh Annual Conference of the International Speech Communication Association. 2010.
[7] PASCANU R, MIKOLOV T, BENGIO Y. On the difficulty of training recurrent neural networks[C]// International Conference on Machine Learning. 2013: 1310-1318.
[8] TANG D Y, QIN B, LIU T. Document modeling with gated recurrent neural network for sentiment classification[C]//The 2015 Conference on Empirical Methods in Natural Language Processing. 2015: 1422-1432.
[9] ZHANG X M, LI H, QU H. AHNN: an attention-based hybrid neural network for sentence modeling[C]//National CCF Conference on Natural Language Processing and Chinese Computing. 2017: 731-740.
[10] ZHANG Y, ER M J, WANG N. Attention pooling-based convolutional neural network for sentence modelling[J]. Information Sciences 373, 2016: 388-403.
[11] LI S, ZHAO Z, LIU T, et al. Initializing convolutional filters with semantic features for text classification[C]//The 2017 Conference on Empirical Methods in Natural Language Processing. 2017: 1884-1889.
[12] DU C S, HUANG L. Text classification research with attention-based recurrent neural networks[C]// International Journal of Computers Communications & Control. 2018: 50-61.
[13] ZHOU P, SHI W, TIAN J. Attention-based bidirectional long short-term memory networks for relation classification[C]//The 54th Annual Meeting of the Association for Computational Linguistics. 2016: 207-212.
[14] WANG S D, MANNING C D. Manning. Baselines and bigrams: simple, good sentiment and topic classification[C]//The 50th Annual Meeting of the Association for Computational Linguistics. 2012: 90-94.
[15] GOLDBERG Y, LEVY O. Word2vec explained: deriving Mikolov et al.'s negative-sampling word-embedding method[J]. arXiv preprint arXiv:1402.3722, 2014.
[16] PENNINGTON J, SOCHER R, MANNING C. Glove: global vectors for word representation[C]//The 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2014: 1532-1543.
Attention-based approach of detecting spam in social networks
QU Qiang, YU Hongtao, HUANG Ruiyang
National Digital Switching System Engineering & Technological R&D Center, Zhengzhou 450002, China
In social networks, a large amount of spam has seriously threaten users' information security and the credit system of social websites. Aiming at the noise and sparsity problems, an attention-based CNN method was proposed to detect spam. On the basis of classical CNN, this method added a filter layer in which an attention mechanism based on Naive Bayesian weighting technology was designed to solve the noise issue. What’s more, instead of the original pooling strategy, it adapted an attention-based pooling policy to alleviate the sparsity problem. Compared with other methods, the results show that the accuracy has increased by 1.32%,2.15%,0.07%,1.63% on four different data sets.
social networks, information security, spam, attention system
The National Natural Science Foundation Innovation Group Project (No.61521003)
TP309
A
10.11959/j.issn.2096−109x.2020002

曲强(1994− ),男,黑龙江齐齐哈尔人,国家数字交换系统工程技术研究中心硕士生,主要研究方向为网络空间安全、大数据分析与处理、复杂网络异常用户检测。
于洪涛(1970− ),男,辽宁丹东人,博士,国家数字交换系统工程技术研究中心研究员,主要研究方向为网络大数据分析与处理。

黄瑞阳(1986− ),男,福建漳州人,博士,国家数字交换系统工程技术研究中心助理研究员,主要研究方向为文本挖掘、图挖掘。
论文引用格式:曲强, 于洪涛, 黄瑞阳. 基于注意力机制的社交垃圾文本检测方法[J]. 网络与信息安全学报, 2020, 6(1): 54-61.
QU Q, YU H T, HUANG R Y. Attention-based approach of detecting spam in social networks[J]. Chinese Journal of Network and Information Security, 2020, 6(1): 54-61.
2019−03−25;
2019−07−11
于洪涛,yht_ndsc@139.com
国家自然科学基金创新群体基金资助项目(No.61521003)
猜你喜欢
计算机应用(2022年9期)2022-09-25
软件导刊(2022年3期)2022-03-25
北京航空航天大学学报(2021年9期)2021-11-02
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
计算机技术与发展(2019年1期)2019-01-21
