
深度神经网络的对抗样本攻击与防御综述
2020-04-09 04:01王兴宾
广州大学学报(自然科学版) 2020年4期
王兴宾, 侯 锐, 孟 丹
(中国科学院信息工程研究所 信息安全国家重点实验室, 北京 100093)
近年来,深度神经网络(DNN)已经获得了巨大的成功,并且引起了工业界和学术界的广泛关注.尤其是以卷积神经网络为代表的深度神经网络模型也已经被广泛地应用到了安全敏感的任务处理场景上,例如金融(人脸支付)、医疗(Artificial Intelligence (AI)问诊)和自动驾驶等领域中.然而,研究已经证明存在对抗样本可以轻易地愚弄机器学习系统[1].攻击者可以通过施加精心设计的细微扰动构建对抗样本来愚弄深度神经网络模型,使其产生错误的预测结果,甚至能够使该模型将毫无意义的噪音识别为特定的类别.例如,攻击者可以通过构建对抗样本来混淆自动驾驶车辆交通标志识别系统中的停车标志,使得系统判别为加速或者限速标志.
Szegedy等[1]第一次在图像分类应用中发现了深度神经网络存在内存在脆弱性,虽然这些深度神经网络模型具有很高的识别准确率,但是它们很容易受到经过很小扰动处理的图像的对抗攻击,这些经过扰动处理的图像能够使得人类视觉系统无法察觉.最近的研究显示,对抗样本攻击已经从理论研究发展到了真实的物理世界上.例如,利用对抗补丁的攻击方法[2]可以被恶意地利用来绕过监视系统,入侵者只要将一小块贴有对抗补丁图像的硬纸板放在身体前面,面向监视摄像头,就能不被监视系统发现.
从对抗样本的攻击范围角度看,对抗样本攻击已经从机器视觉领域发展到了语音识别和自然语言处理等领域.在机器视觉领域中,文献[3-4]可以在目标识别系统中把某一行人的分割给去除掉.在语音识别领域中,攻击者可以对自动语音识别模型和语音控制系统发出对抗性命令,使得这些语音识别系统产生错误的操作,例如苹果的Siri[5],亚马逊的Alexa[6],以及微软的Cortana[7].在自然语言处理领域中,Jia等[8]是第一个对文本的深度神经网络制作对抗样本攻击,他们的工作迅速引起了自然语言处理(NLP)领域的研究者关注.
从机器学习算法的角度看,对抗样本攻击不仅能对深度神经网络产生对抗样本攻击,而且还能对最近的图神经网络进行攻击,甚至是增强学习也能被制作的对抗样本攻击.图深度学习模型(如图卷积网络)在图数据处理上实现了最先进的性能.然而,与其他深度学习模型相似,图深度学习模型同样容易受到对抗样本攻击[9].为了误导一个图深度学习系统,同样地,向特定产品添加虚假评论可以欺骗网站的推荐系统.与对抗样本攻击图像分类系统一样,深度强化学习(RL)策略也容易受到对抗干扰.在当前的工作中,文献[10]提出了一种新的对抗攻击策略对深度强化学习发起攻击.
针对对抗样本的攻击,研究者提出了许多的防御方法,Luo等[11]提出用中央凹(Foveation)机制防御L-BFGS 和 FGSM 生成的对抗扰动;Dziugaite等[12]使用 JPG 图像压缩的方法,减少对抗扰动对准确率的影响;文献[13]使用输入梯度正则化以提高对抗攻击鲁棒性; 文献[14]使用类似与生物大脑中非线性树突计算的高度非线性激活函数以防御对抗攻击.Feature squeezing通过平均滤波器和数据位宽压缩来检测对抗样本[15], DeepCloak通过在分类层前增加一层特意为对抗样本训练的层来检测对抗样本[16].SafetyNet通过额外增加一个CNN模型和SVM算法来对对抗样本进行检测[17].MagNet通过训练一个分类器对图片的流行(Manifold)测量值进行训练,从而分辨图片是否带有噪声,即对抗样本[18].
深度神经网络算法的安全性本质上就是对抗样本攻击与防御的博弈,其安全性的研究一方面是发展高效的对抗样机算法,设计出不同的白盒或者黑盒的对抗攻击方法;另一方面是提高深度神经网络的鲁棒性,这包括研发更为鲁棒的对抗防御算法,以及设计出多种多样的对抗样本检测方法.
本文对这些对抗样本攻击方法进行了研究,总结了对抗样本防御的方法和对策,也探索了对抗样本攻击的特点和可能存在的原因.首先,系统地分析和归类多种多样的对抗样本攻击方法,从而能够从不同的角度以方便、直观的形式展现出这些方法特征;然后,从硬件部署计算的角度对现有的对抗样本防御方法进行归纳总结;最后,基于对抗样本的可迁移性、对抗样本存在的机理和它的鲁棒性,讨论未来对抗样本攻击和防御的主要挑战及潜在方向.
1 对抗样本的概述
为了理解人工智能的安全问题,首先,应确定人工智能的威胁模型(对抗样本);然后,需要思考对抗样本的产生机理和对抗样本的设计空间,以及对应的防御策略.
1.1 威胁模型
基于不同场景、假设和质量需求,攻击者需要决定对抗样本的属性,然后,部署特定的对抗样本攻击方法.为此,把威胁模型分解为四个方面:对抗的证伪(Adversarial falsification)、对抗的知识(Adversary’s knowledge)、对抗的属性(Adversarial specificity),以及对抗攻击的频率(Adversarial attack frequency).
1.1.1 对抗的证伪
(1)假正例攻击(False positive attacks)是指一个伪造的假样本被分类为一个真样本.例如,在图像分类任务中,一个假阳性的对抗样本(对人类肉眼是不可见的)会被深度神经网络模型预测为一个概率很高的类型.
(2)假反例攻击(False negative attacks)是与假正例攻击相反的一种攻击,也就是说,一个真的样本会被神经网络模型识别为一个假的样本.这类攻击通常也被称为逃避攻击(ML evasion),这种情况人类很容易进行识别判定,但是深度神经网络模型却无法正确地识别它.
1.1.2 对抗的知识
(1)白盒攻击(White-box attacks)是假设攻击者已知神经网络模型的架构和权重信息.在实际的对抗样本攻击中,攻击者已知模型的全部信息是不可能的,但是能够通过侧信道攻击、API函数询问等方法窃取到模型的架构信息.
(2)黑盒攻击(Black-box attacks)是假设攻击者无法获取训练好的深度神经网络模型.事实上,攻击者仅知道模型的输出包括标签或者某一类的概率值.但是通过这些信息攻击者能够生成替代模型,利用对抗样本的迁移性发起对原来神经网络模型的攻击.
1.1.3 对抗的属性
(1)目标攻击(Target attacks)是指误导神经网络模型预测为一特殊的分类结果.目标攻击通常发生在多目标分类问题中.例如,在人脸识别系统中,攻击者试图伪装成为一个拥有授权权限的人脸用户.
(2)非目标攻击(Nontargeted attacks)是指不对神经网络模型指定一个特殊的分类结果,也就是说,对抗攻击输出的类别可能是任何一种(除了原始的、正确的分类).
1.1.4 对抗攻击的频率
(1)单步攻击(One-time attacks)是从对抗样本生成的角度来讲的,它是只花一次时间来优化生成对抗样本.
(2)迭代攻击(Iterative attacks)是多次更新和迭代生成对抗样本.
1.2 对抗样本的理解
对抗样本攻击的现象自从发现以来,就已经获得强劲的发展势头.它们主要集中在三个方面:
第一个方面是探索对抗样本的搜索空间,如图1所示.文献[19]首先给出了一个对抗样本空间探索的全面分析,并且提出了一种基于梯度符号扰动的快速计算方法.而文献[20]通过采用遗传算法替代基于梯度的攻击,实现了非常好的攻击效果.更精细的方法是采用不同种类的优化来使得神经网络模型最大化的错误分类,与此同时,最小化抖动的范数,这种方法超越了对梯度空间的贪婪迭代.这些方法都是在探索神经网络模型的一个决策边界,使得他们能够收敛到一定的程度,模型能够产生误判.

图1 对抗样本搜索边界Fig.1 Adversarial example search boundary
第二个方面是集中在对抗抖动特性的理解,也就是对抗样本可解释性的研究.文献[19]的工作已经指出,深度神经网络的线性特性是产生对抗样本攻击的一个重要原因.这不仅可能扰乱看起来完全不同的自然的图像,也有可能导致使用噪声图像能够使得神经网络模型产生一个高置信度的预测值.对抗样本攻击具有迁移性,例如,在一个网络上制作的对抗样本,可以用来愚弄其他的神经网络分类器.然而,可迁移的攻击通常会受限于更简单的方法,例如,迭代型的工具会倾向于利用每一种特定特性的神经网络模型,因此,采用这种特定特性模型的攻击手段会使该方法的可迁移性效率降低.事实研究表明,对抗样本的噪声不仅可以在模型之间进行迁移,也可以对单个数据集中所有样本的普遍对抗性扰动,使其都具有一定的迁移性,从而使它们能够达到较高的误分类率.
第三个方面主要集中在如何设计对抗样本防御方法来抵御对抗样本的攻击.防御的策略包括优化对抗搜索空间、探测对抗样本、进行数据增强(包括对抗样本)来提高模型的鲁棒性,或者进行梯度模糊的方式来阻止攻击者进行对抗的扰动攻击.
2 对抗样本攻击方法
在人工智能安全中,对抗样本已经成为了AI系统的一个最重要的威胁.表1列举了目前一些流行的攻击方法和原理.这些方法能够在不同的应用场景中生成强大的对抗样本,无论是攻击频率还是攻击强度都各不相同.对抗样本的生成方法随着技术的进步,也在不断地演变发展.
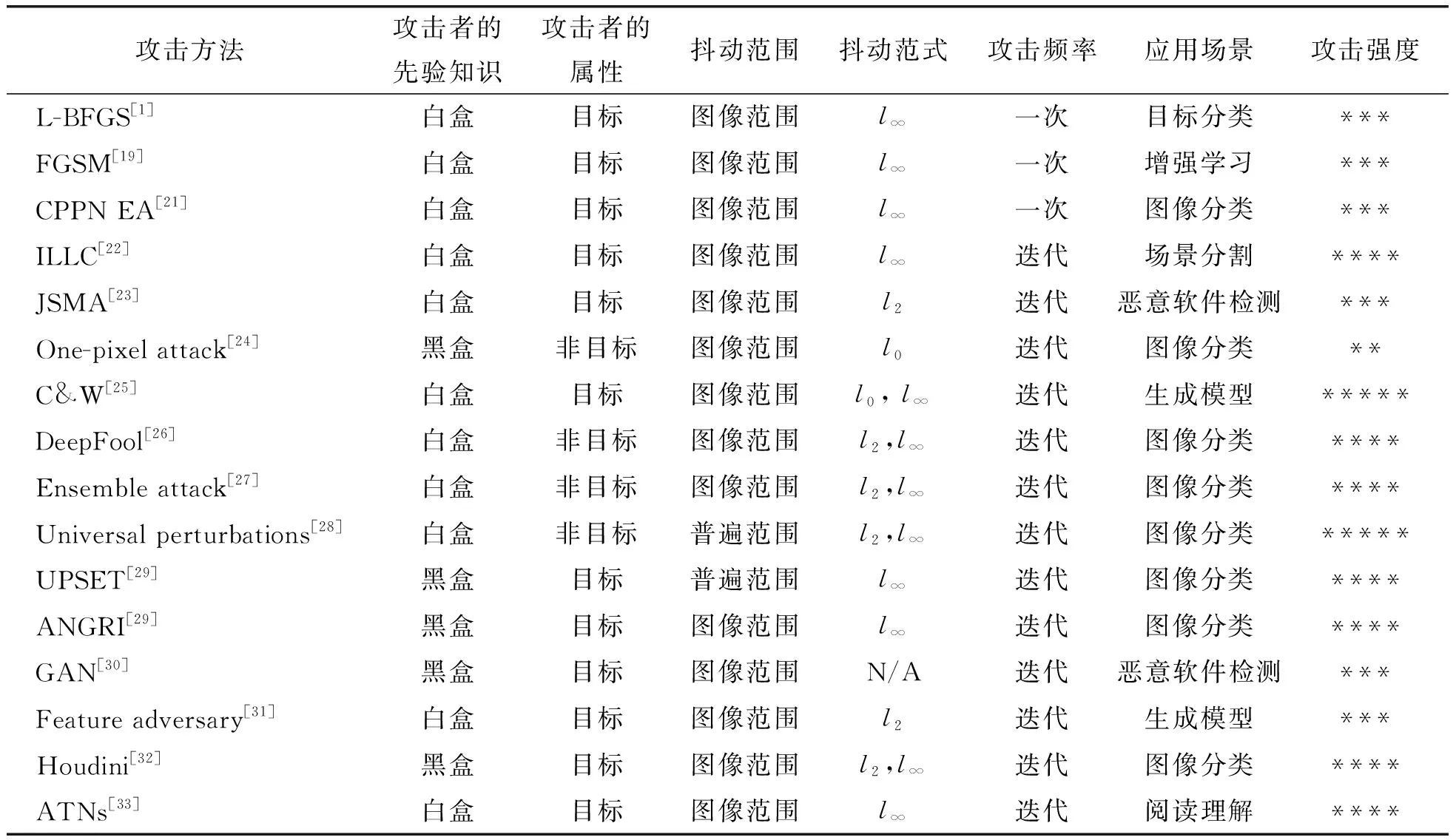
表1 主流的攻击方法及其原理总结Table 1 Summary of mainstream adversarial example attack methods and their principles
在本节中,笔者回顾计算机视觉方面的相关文献来介绍对抗性攻击方法.文献综述主要是在“实验室设置”的环境下愚弄深层神经网络,而这些对抗样本攻击方法主要是为典型的计算机视觉任务开发的,例如,图像分类与识别、场景分割和目标检测等.并且主要是通过标准的数据集中来展示这些对抗样本攻击方法的有效性,典型的数据集主要包括MNIST、CIFAR10和ImageNet等开源的数据集.虽然这些对抗样本攻击方法有些是仅限于理论研究,但是它们对对抗样本领域的发展起到了重要的推动作用,而且这些对抗样本攻击方法构成了对现实世界攻击的基础,它们中的每一个对抗样本攻击方法都对该领域的发展产生了深远的影响.下面选择一些主流的、典型的攻击方法进行介绍.
2.1 FSGM
快速梯度符号方法(Fast Gradient Sign Method,FSGM)是由Goodfellow等[19]提出的一种最简单、最快速的方法,用于创建对抗样本.通过在梯度方向上添加一个扰动生成的图像,能够使得神经网络模型被误分类.通过FSGM生成的对抗样本是利用深度网络模型内高维空间的线性特征,然而当时这些模型被认为是高度非线性的.在相关的文献中,这个想法通常被认为是线性假设,这也是被FSGM方法所证明.FSGM与后来的基于迭代的方法(Basic Iterative Method,BIM)成为了非常受欢迎的两种对抗样本生成方法.
2.2 JSMA
Papernot等[23]提出了基于雅克比行列式的显著图攻击(Jacobian-based Saliency Map Attack,JSMA),它是基于l0距离范数的攻击方法.该方法的基本思想是构造一个梯度显著图,然后根据每个像素的影响对梯度进行建模.梯度是与图像被分为目标类的概率成正比,也就是说,改变较大的梯度值将显著地增加图像分类为目标类的可能性.当模型对输入的变化非常敏感时,与其他攻击方法相比,该方法更容易计算出最小扰动值,使被扰动的样本难以被人眼感知.虽然JSMA的效率较低,但是它有更微小的扰动,而且成功率和转移率相对较高.
2.3 DeepFool
Moosavi-Dezfooli等[26]提出了一种基于l2距离范数的非目标攻击方法,叫做DeepFool.它假设深度神经网络是完全线性的,存在一个超平面能将这种分类与另一种分类分开.基于这个假设设计优化方法来构建对抗样本.相比于其他方法,DeepFool效率更高,攻击更强大.它通过寻址对抗样本存在的决策边界,然后利用该边界来愚弄分类器.在高维非线性空间的神经网络中,直接解决这一问题是非常困难的.为此,通过线性化逼近方法迭代求解该问题,从而构造微小扰动的对抗样本.
2.4 One pixel attack
对抗样本攻击的一个极端案例是只需要修改图像中的一个像素就能够愚弄分类器,这就是著名的单像素攻击(One pixel attack)[24].该攻击宣称他们可以只改变图像中的一个像素就能够成功地愚弄三种不同的神经网络模型,并且在测试图片上的成功率达到了70.97%.他们也报道了网络模型在错误标签上的平均置信度最高达到了97.47%. 即使采用简单的遗传策略,单像素攻击同样能够对愚弄神经网络展现出巨大的成功.该方法可以攻击更广泛的神经网络模型的种类,并且不需要访问任何的对抗信息.但是,这种简单的扰动可以被人类的眼睛识别.
2.5 C&W
Carlini等[25]通过利用防御性的蒸馏提出了三种对抗攻击,这些对抗攻击通过约束L0和L2范数制作人类肉眼无法察觉的对抗扰动,并且表明防御性蒸馏产生的对抗扰动使得目标网络完全无法对付这些攻击样本.而且这类攻击也表明通过使用不安全的网络生成的对抗样本也能够迁移到安全的网络上,这使得这类计算的扰动非常适合黑盒攻击.
通过利用对抗样本的可迁移性来生成黑盒攻击是非常普遍存在的.也有相关的研究工作受到C&W攻击的启发提出了零阶优化,这种优化方法是直接通过评估目标网络模型的梯度来生成对抗样本.
2.6 其他的攻击方法
上面讨论的对抗样本攻击方法要么是最近相关研究中比较流行的,要么是具有一定代表性研究方向的.正如表1所示,本文也总结了这些对抗样本攻击的主要特征.为了进行一项全面的研究,本文也对其他的对抗样本攻击方法进行了简要的描述.另外,笔者发现对抗样本的研究领域现在是热点,虽然笔者已经尽可能收集相关的对抗样本攻击方法,但是仍然做不到全面、详尽的记录,这是因为这一领域发展速度异常迅猛,今天提出新的攻击方法,可能明天就会有研究人员设计出对应的防御策略.因此,在不久的将来会产生越来越多的攻击方法.
3 对抗样本防御方法
自从Szegedy等[1]首次证明了深度神经网络存在着对抗性扰动的问题以后,深度神经网络图像分类器对抗样本的鲁棒性问题便获得了极大的关注.为了应对早期对抗样本的攻击方法,研究者通过生成对抗样本数据对目标网络进行重新训练,以提高模型的鲁棒性.虽然这种方法不改变原模型的计算方式,但是再训练需要消耗大量的计算资源和更多的训练数据,并且很难抵抗新的对抗样本攻击.由于对抗样本是在原有图像上加入人眼能看见的噪声或者扰动产生的噪声,对抗样本研究者提出了许多采用传统机器学习方法来对输入图像进行去噪或变换的方法,以检测对抗样本.
最近研究表明,高维空间线性特性猜测被认为是产生对抗攻击的根本原因,研究人员从神经网络的模型本身出发提出了FSGD、C&W等攻击方法.同样地,很多的对抗样本防御方法通过添加子网络(对抗网络需要与目标网络的中间特征图)来对对抗样本进行检测.
随着对抗样本攻击方法的不断演进,对抗样本防御方法也在不断的变化.越来越多的研究人员尝试采用对抗网络与传统机器学习算法相结合的方法,对对抗样本进行检测.到目前为止,还没有一种现存的对抗样本防御方法能够防御所有的攻击方法,笔者认为在实际部署的时候,需采用多种方法组合的形式来检测对抗样本.
从对抗样本防御方法部署需要的计算需求来讲,对抗样本防御方法可以归结为三类:一类是采用DNN网络作为附属网络模型来验证输入图像是否为对抗样本或恢复出原始图像;第二类是采用传统的机器学习方法,通过对输入数据去噪或者变换的方式来检测对抗样本;最后一类是上述两类的混合,也就是采用DNN网络和机器学习相结合的方法进行对抗样本防御.其中,采用DNN作为附属网络模型又可分为修改目标网络的模型,包括添加特殊的层或操作来提高对对抗样本检测的鲁棒性,添加的对抗网络需要目标网络的中间特征图,对抗网络模型独立(大的网络和小的网络).这三种类型的对抗样本防御方法有各自的优缺点,在实际部署中,经常会采用多种防御方法相结合的方式来增强机器学习系统的防御能力.笔者从计算的角度对对抗样本防御方法进行了总结和归类,如表2所示.

表2 对抗样本防御方法总结Table 2 Summary of adversarial example defense methods
为了更好地理解对抗样本防御方法的多样性及其防御原理,笔者选取了三个典型的对抗样本防御方法进行详细的阐述.
案例1:去噪方法. Liang等[34]通过一个计算输入图像的熵来实施自适应滤波器(包括标量量化和空间平滑滤波)处理输入图像,并把处理后的图像送入目标网络中进行分类预测,如果处理后的输入图像与未处理的输入图像通过目标网络得到一致的分类结果,则说明该输入图像不是对抗样本,反之则认为是对抗样本,处理流程如图2.该方法需要计算熵、空间滤波和标量量化,而现有DNN加速器不能满足此类对抗样本防御方法的计算需求.

图2 对抗样本防御方法与目标网络部署方式Fig.2 Adversarial example defense methods and target network deployment model
案例2: 子网络和中间特征图.文献[35]训练一个增强的可扩展的神经网络分类器,并且该对抗网络的训练需要与目标网络训练同时进行,对抗网络需要目标网络中间层的特征图进行计算.对抗网络是由中间层为128个神经元、一个Relu激活层和阈值为0.5的dropout层组成.该方法需要与目标网络同时计算,且与目标网络计算的中间特征图有数据交互.通过两片DNN加速器能够实现该对抗样本防御方法的部署,但是这样的系统增加了成本并降低了计算效率,而且通过额外的数据接口使得两个网络模型进行数据交互也存在着安全问题.
案例3: 子网络和传统的机器学习相结合.文献[17]训练一个增强的CNN分类器提取ReLU层的输出阈值作为对抗探测器的特征,然后由分散基准函数SVM来检测对抗样本.该作者声称他们的方法很难被击败,即使对手知道探测器也是如此.该方法需要一个额外的DNN加速器来运行对抗网络,但是采用两个DNN加速器也不能满足该方法对量化SVM的计算需求,即使采用增加CPU处理器来解决量化SVM的计算问题,也会使系统的成本增加和计算效率降低,整个系统存在着巨大的安全问题.
不管采用DNN网络还是传统的机器学习方法来设计对抗样本防御方法,或是两者之间的混合,其防御策略大致可以分为两类:探测对抗样本和重构出原始图像.与目标网络之间的数据流向关系如图2所示.对抗样本检测方法通常与目标网络串行执行,对抗样本防御方法放置到目标网络前面,对输入图像进行检测或重构出原图像(Benign image).检测到对抗样本输出警告信息,或者去掉对抗扰动,恢复原图像发送给目标网络重新计算.另外,一部分对抗样本防御方法是和目标网络并行执行.例如,案例1是把经过滤波处理后的输入图像和原始图像同时送到目标网络进行计算,最终比较两者输出的标签是否一致以判断对抗样本.
另外,值得注意的是对抗训练的防御方法,文献[19]是早期提出的防御思想之一,主要思想是通过在训练数据集中添加对抗样本进行训练以提高模型的鲁棒性.然而,早期的工作通常只是在训练阶段添加一些对抗样本进行训练.最近对抗训练[40]可以看作是解决最大最小的优化问题,训练算法的主要目的是在保证一定模型准确率的前提下最小化鲁棒损失.在此基础上,一种基于PGD攻击的干净的对抗训练程序被开发了出来,并且在强大的对抗样本攻击下取得了当前对抗样本防御最好的效果,这也激发了一些研究者对鲁棒误差理论的研究[41-42].从理论研究的角度,文献[43]考虑定量的评价对抗样本的收敛质量,从而能够保证神经网络模型的鲁棒性.
虽然对抗训练能够通过数据增强[44]和添加多种方法生成的对抗样本以提高模型的鲁棒性,从而能有效地抵御对抗样本的攻击,但是它需要进行重新训练,并且会消耗大量的计算资源,以及花费大量的时间对多种攻击模型进行迭代计算.
4 AI安全面临挑战与未来方向
虽然深度神经网络在高级智能应用中取得了显著的成功,但由于最近出现的对抗性攻击,其安全问题成为一个重要的关注.许多对抗样本防御方法虽然已经被证明是有效的,但是高昂的计算开销和大量的输入数据预处理或变换使其在实际部署中面临各种各样的问题.
(1)神经网络对抗鲁棒性.众所周知,通过对抗训练可以提高神经网络模型的鲁棒性,并且在诸多任务上表现出了良好的对抗防御性能.但是它们通常是基于经验主义的启发式算法,不具有可解释性.为此,设计出对特定的某一类攻击算法对抗鲁棒性的可证明防御方法,是未来的一个重要研究方向.
(2)神经网络对抗样本的可解释性.现在对抗样本的解释有多种说法,有学者认为神经网络的高维非线性空间是产生对抗样本的根本原因;也有学者认为对抗样本是神经网络模型的特征,而不是缺陷,是神经网络学习到的特征[45].对抗样本的可解释性问题是当前最难解决的一个问题.
(3)对抗样本防御轻量化.针对对抗样本防御方法的部署,仍然面临着许多问题与挑战,例如,仅采用DNN加速器的方案落地部署会导致许多机器学习对抗样本防御算法难以执行.而采用DNN加速器和CPU架构混合的方案,虽然能够适应各种各样的对抗样本防御算法,但是会受限于CPU的计算性能,拖累整个系统的执行性能.为此,设计出适用于现有硬件方案的轻量级对抗样本防御方法是一个很好的研究课题.
(4)硬件架构对防御方法的支持.最近,中科院信工所侯锐课题组为对抗样本的防御方法设计了专用硬件加速架构,使得这些防御方法能够高效部署[46].另外,上海交通大学过敏意团队开发了对抗样本防御框架[47],并且为此设计了专用的DNN加速器,从对抗学习理论框架到硬件部署实现搭建了完整的系统,为对抗样本防御方法的部署实现软硬件结合的统一.因此,联合对抗样本防御算法设计相应的软件框架和专用的硬件加速器架构是未来的一个重要发展方向.
5 结 语
随着深度神经网络被广泛地应用到各个领域,AI的安全性和自身的鲁棒性问题就对整个AI系统的应用变得愈发重要.本文整理和总结了对抗样本攻击和防御方法,并且对其进行了分类和归纳.从算法层面讲,对深度神经网络模型内部工作机理的研究,并且着手解决对抗样本存在的可解释性问题,已经成为检测对抗样本和提高AI模型鲁棒性的重要途径.从硬件架构加速的角度讲,AI的安全最终还是要落实到对抗样本的防御,以及对其各种防御算法的高效部署上.
猜你喜欢
数学物理学报(2022年4期)2022-08-22
数学物理学报(2021年4期)2021-08-30
北京航空航天大学学报(2021年7期)2021-08-13
农业机械学报(2020年2期)2020-03-09
电子制作(2019年19期)2019-11-23
数学物理学报(2019年4期)2019-10-10
中华建设(2019年7期)2019-08-27
电子制作(2019年24期)2019-02-23
项目管理技术(2016年12期)2016-06-15
西南交通大学学报(2016年6期)2016-05-04
