
WebRTC降噪算法在RT1052芯片的实现与优化
2020-04-09 04:01:38郑泽鸿张承云
广州大学学报(自然科学版) 2020年4期
郑泽鸿, 张承云
(广州大学 电子与通信工程学院, 广东 广州 510006)
降噪算法广泛应用于实时通信、扩声、声音监控和现场录音等场合,由于应用环境各异,噪声类型较多,因而降噪算法开发难度较大[1-3].WebRTC是Google公司以VoIP等多项核心技术为基础建立的开源项目,用于PC端或移动端的实时音视频通信,其降噪算法的效果较好.本文对WebRTC降噪算法在低成本嵌入式芯片上的实现进行探讨.
NXP公司的RT1052芯片性价比高,基于ARM Cortex-M7内核,采用6级流水线,带双精度硬件浮点运算单元(FPU),有串行音频接口(SAI),支持CMSIS-DSP信号处理库[4].选择以RT1052为主控制器的开发板作为硬件实现平台,分析WebRTC降噪算法并移植和优化代码,采用VAD算法解决了原代码中噪声参数在静音转为有声时的收敛问题,最后对代码性能进行测试.
1 WebRTC降噪算法简述
WebRTC降噪算法支持的音频采样率为8 kHz、16 kHz、32 kHz及48 kHz,每隔10 ms处理一帧数据.对于8 kHz和16 kHz的输入信号直接进行降噪处理,而对于32 kHz和48 kHz的输入信号则分别通过正交镜像滤波器和余弦调制滤波器进行子带分离,低频部分按16 kHz情况进行处理,所得的语音概率作为高频部分增益的参考,最后子带合成得到降噪后的信号,WebRTC降噪算法的处理流程[5]见图1.
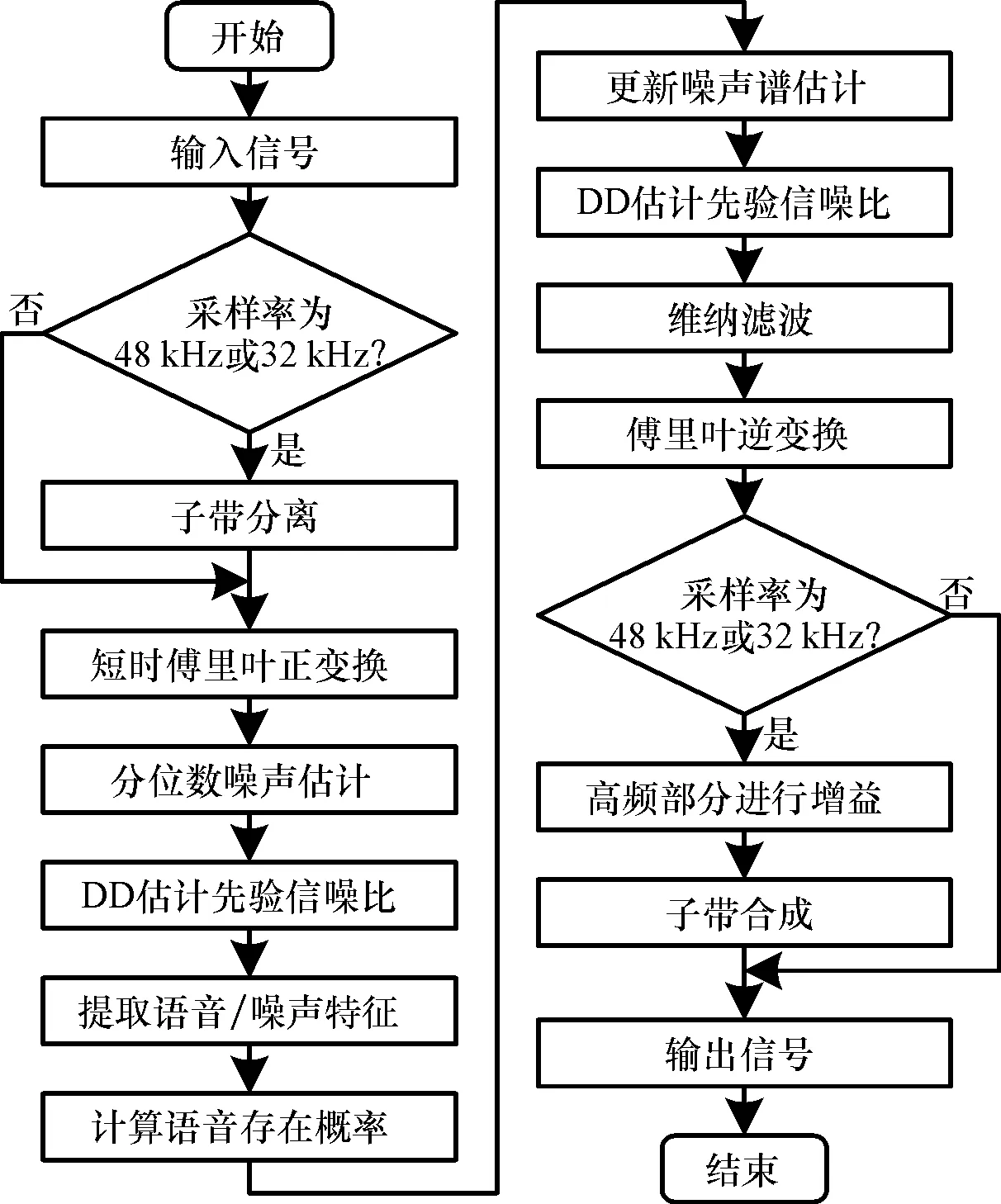
图1 WebRTC降噪算法流程图Fig.1 Flow chart of WebRTC noise reduction algorithm
以16 kHz处理为例,算法主要分为四个步骤:
ξ1(,
(1)
其中,k为频点编号,X(-1,k)为上一帧降噪后的幅度谱,D2(-1,k)为上一帧的实际噪声谱估计.
假设语音和噪声的傅里叶变换系数为零均值的复高斯分布,由式(2)求出各频点的似然比Λ(,k),它表征着语音存在与不存在的概率比[8].
Λ(,
(2)
式中γ1(,
(2)分别计算平坦度κf()、偏差度κd()和似然比均值κΛ().
κf(
(3)
κd()=var{Y(,
(4)
κΛ(,

(5)
由于噪声信号的频谱相对均匀平坦,所以噪声帧的平坦系数偏大[9].偏差度是用相关系数衡量Y(,k)与噪声模板Dd(,k)的线性相关程度,噪声信号的幅度谱更接近模板,所以噪声帧的偏差系数较小.似然比均值,即频点似然比Λ(,k)经对数平滑得到Δ(,k)求几何平均值,是指示语音/噪声状态的可靠指标,语音帧的似然比均值较大.
(3)通过tanh函数对上述3个特征量指标化,分别以wf、wd、wΛ加权得到总体语音指标ρ(),并由时间平滑得到语音帧概率值p().
(6)
根据贝叶斯定理求得各频点的语音存在条件概率ζ(,k)[10].
ζ(,k)=P[H1Y(,
(7)

(4)最后根据语音存在概率重新获得噪声谱,由式(8)得到实际噪声谱估计D2(,k).
D2(,k)=
(8)
其中,D′(,k)=[1-ζ(,k)]·Y(,k)+ζ(,k)·D2(-1,k).
再次使用式(9)的DD估计修正先验信噪比ξ2(,k),带噪幅度谱Y(,k)经过式(10)维纳滤波后,即为纯净语音幅度谱X(,k),保持相位谱不变并反变换回时域得到降噪信号.
ξ2(,
(9)
X(,k)=Y(,
(10)
2 WebRTC降噪算法移植
2.1 声音数据接口
选用广州市星翼电子科技有限公司(正点原子)的号令者I.MX RT1052开发板作为硬件平台.主处理芯片RT1052是NXP公司的一款高性价比微处理器,基于Cortex-M7内核,600 MHz工作主频,自带双精度硬件浮点运算单元(DP-FPU),适合实时算法处理.开发板的声音codec是Wolfson公司的WM8978[11].RT1052芯片通过I2C配置WM8978的寄存器,开启线路输入输出通道,16位量化精度,采样率根据需求设为8 kHz、16 kHz、32 kHz或48 kHz.
使用MDK5.23作为软件开发环境,建立一个声音直通程序.将发送请求和接收请求分别映射到DMA的两个通道上,利用乒乓缓冲实时接收和发送声音信号,数据输入指针为shBufferIn,数据输出指针为shBufferOut,每帧数据长度为10 ms.
2.2 算法移植与测试
WebRTC项目代码(https://webrtc.googlesource. com/src/+log,2019-9-28)的开发环境为Microsoft Visual Studio 2015,降噪算法位于modules的audio_processing/ns文件夹中,正交镜像滤波器对应common_audio/signal_processing的splitting_filter.c文件,余弦调制滤波器对应modules/audio_processing 中的three_band_filter_bank.c文件.将上述文件添加到声音直通程序的工程中,直通程序中的数据指针shBufferIn、shBufferOut分别作为噪声处理程序的数据输入输出.
为了检验算法的实时性,测试语音选取NOIZEUS语料库[12]中纯净语音sp01~sp05拼接成15 s的信号,用Cooledit软件将采样率从25 kHz升为48 kHz,与白噪声以0dB信噪比混合,得到audio1信号.在计算机上播放该信号并将声卡的输出作为开发板的输入,通过RT1052芯片的定时器测量降噪算法在不同采样率时处理单帧信号需要的时间.结果只有采样率为8 kHz时才能实时处理,采样率为48 kHz时噪声处理时长约为输入数据时长的3倍,远远不能达到实时处理的要求,这是因为CPU对大量浮点运算的执行效率较低.针对这种情况,开启RT1052内置的FPU可提高算法的运算效率,将协处理器控制寄存器(CPACR)的CP11和CP10置位即可,同样对单帧信号的处理时间进行测量,由表1可知四种采样频率都能实时处理.
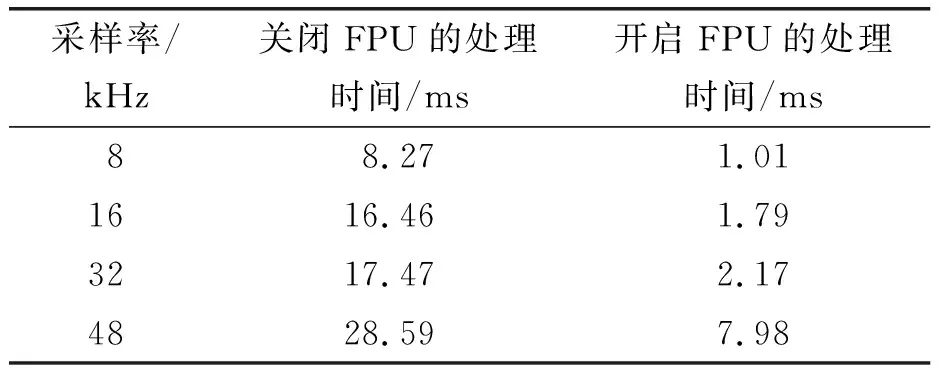
表1 原算法对单帧信号的处理时间Table 1 The processing time of the original algorithm for single frame signal
3 降噪算法的优化
3.1 使用CMSIS-DSP库函数
RT1052芯片支持ARM公司的CMSIS-DSP库函数,能更快地执行信号处理运算[13],将库文件arm_cortexM7lfdp_math.lib添加到工程中.
对于32 kHz采样率的音频降噪处理,需要通过正交镜像滤波器进行子带分离.WebRTC的分析滤波器组由基于全通滤波器的多相网络实现,所引起的相位失真几乎被综合滤波器组所平衡,实现信号的完全重构,其结构如图2所示[14-15].

图2 两通道正交镜像滤波器结构图Fig.2 Structure of two-channel quadrature mirror filter
每帧共需要执行4次滤波运算,即H0、H1与G0、G1,其传递函数为
(11)
(12)
其中,kj,i为源码给出的滤波器系数.
WebRTC项目中开源降噪代码的级联全通滤波通过WebRtcSpl_AllPassQMF函数实现,对输入信号在数字频率0.5π处进行分频,在RT1052中,每帧执行4次滤波共需要204 μs.在CMSIS-DSP库中有arm_biquad_cascade_df1_f32函数,用于实现直接I型双二阶级联IIR滤波.用它替代WebRtcSpl_AllPassQMF函数,每帧执行4次滤波只需134 μs.
对于48 kHz采样率的音频降噪处理,需要通过余弦调制滤波器进行子带分离(图3),由线性相位低通原型滤波器进行余弦调制来实现[16-17].

图3 三通道余弦调制滤波器流程图Fig.3 Flow chart of three-channel cosine modulation filter
每帧共需要执行24次稀疏FIR滤波运算,即Hj,i和Gj,i,原降噪代码中通过SparseFIRFilter函数实现,在RT1052中执行24次滤波共需要3.27 ms.CMSIS-DSP库中的arm_fir_sparse_f32函数也能实现稀疏FIR滤波,用该函数替代SparseFIRFilter函数后,执行24次滤波只需2.09 ms.
此外,原降噪代码中针对数组的数学运算,也用CMSIS库函数进行替换.48 kHz音频信号的降噪结果见图4,优化前后的处理结果一致.

图4 48 kHz音频信号的降噪结果Fig.4 Noise reduction results of 48kHz audio signal
开启FPU并测量单帧信号的处理时间,由表2可知优化算法执行时间更少.
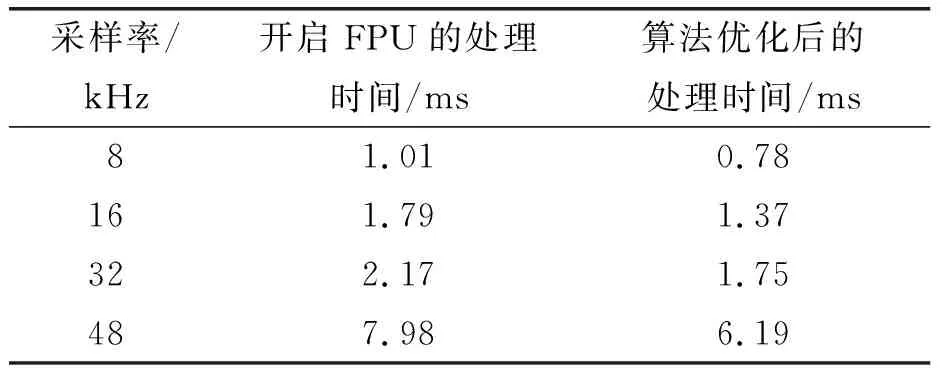
表2 优化算法对单帧信号的处理时间Table 2 The processing time of the optimization algorithm for single frame signal
3.2 降噪算法的静音处理改进
静音时没有噪声信号,此时降噪算法理论上不能更新噪声参数,而WebRTC降噪代码对静音的判断依据是输入信号的能量为0.但在实际应用中由于存在电路噪声,关闭音频输入设备时并不能满足能量为0的条件,仍会更新噪声参数,导致当音频输入设备重新开启时,需一段时间重新收敛噪声参数.
为解决这个问题,在原有算法的基础上增加语音活动检测器(VAD),若判定为静音状态,则不更新噪声参数,算法的处理流程如图5所示.

图5 语音活动检测器的处理流程Fig.5 Flow chart of voice activity detector
语音活动检测主要从功率谱的角度进行分析,对上述的带噪信号幅度谱Y(,k)平方得到带噪信号功率谱P(,k),并通过式(13)的平滑得到S(,k).
S(,k)=

(13)
采用Martin[18]提出的最小值搜索法,在r个连续的平滑功率谱密度估计S(,k)中寻找最小值Pmin(,k).该方法每帧每个频点只需要做一次比较,但在噪声增大的过程中,最小值搜索最多会有2r帧的延迟.
当某频点的S(,k)小于Pmin(,k)的5倍时,则根据式(14)对该频点的噪声估计D(,k)平滑更新.
D(,k)=max{0,[(1-β)·D(-1,k)+
β·P(,k)]}
(14)
其中,β为权重因子,β=max{0.03,1/(+1)},随着帧数的增加,噪声谱D(,k)的变化逐渐稳定.
结合判决引导法估计先验信噪比ξ(,k)有
ξ(,k)=[1-α(,
α(,
(15)
其中,α(,k)为权重调节因子,由式(16)得到信噪比越大,则越增加当前先验信噪比最大似然估值的权重,减少ξ(,k)的估计偏差.
α(,
(16)
其中,A(-1,k)为上一帧的纯净语音功率谱估计,采用幅度u次方的最优MMSE估计器[19],得到纯净语音幅度谱估计为
(,
(17)
根据Ephraim等[20]提出的语音幅度期望估计,并采用高斯统计模型得
E{Cu(,k)|Y(,k)}=
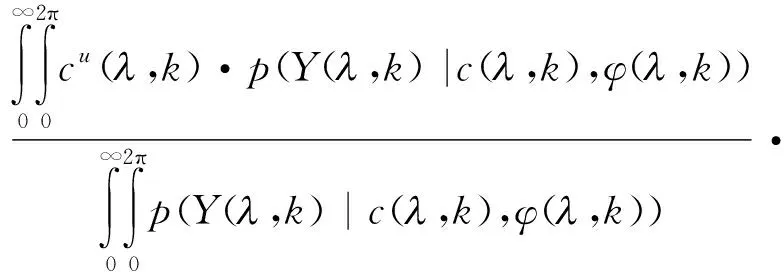
(18)
其中,c(,k)和φ(,k)分别是随机变量C(,k)的幅度和相位的实际值,ε(,k)和υ(,k)的定义式为
(19)
其中,γ(,k)为后验信噪比,γ(,k)=P(,k)/D(,k).
联合式(17)和式(18)并化简得
(20)
其中,Γ(·)为伽玛函数,Φ(·)为合流超几何函数.
文献[19]指出,幂指数u影响纯净语音幅度谱(,k)的估计,u值越大,则(,k)的估计越大,当u=1时为线性MMSE幅度估计器,(,k)的估计偏大,而u趋近于0时接近对数MMSE估计器,(,k)的估计偏小,因此,折中选取u=0.5,则有
Φ(-0.25,1;-υ(,k))2=

Y(,k)=G(,k)·Y(,k)
(21)
那么,平滑的纯净语音功率谱估计A(,k)为
A(,k)=0.2×A(-1,k)+0.8×
G2(,k)·Y2(,k)
(22)
最后,由式(23)得到平滑的先验信噪比ζ(,k),其平均值)代入到式(24)得到语音帧的概率值p().若语音概率小于0.25,则判定为静音段,不更新噪声参数,反之则执行原降噪算法.
ζ(,k)=0.7×ζ(-1,k)+0.3×ξ(,k)
(23)
p(,k)
(24)
以RT1052开发板作为测试平台,调节音频输入设备的音量,通过多次实验,静音段的平均能量大约为非静音段的10-2~10-4倍.
用Cooledit软件产生一段5 s的白噪声信号,其平均能量为前述audio1信号平均能量的0.01倍,用于模拟音频输入设备处于关闭状态时的电噪声.以“audio1+电噪声+audio1”组合成audio2信号,并作为输入信号,通过软件仿真得到的降噪处理结果见图6.原算法在第20~24 s处需要进行参数收敛,而改进算法则不需要重新收敛.
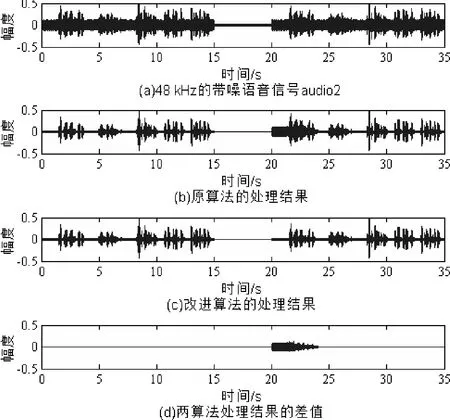
图6 48 kHz音频信号的测试结果Fig.6 Test results of 48 kHz audio signal
对处理结果进行PESQ评分[21],其结果见表3,说明增加静音判断算法后的处理效果更好.

表3 算法处理结果的PESQ评分Table 3 PESQ score of algorithm evolution
当然,对输入信号增加静音判断也会加大运算量.同样以线路输入的方式将audio1音频信号传给开发板,开启FPU并测量单帧信号的处理时间,结果见表4.

表4 改进算法对单帧信号的处理时间Table 4 Processing time of improved algorithm for single frame signal
相比于增加静音判断前的情况,只是略微增加了执行时间,却有效地解决了算法重新收敛的问题.
4 结 语
本文实现了将WebRTC降噪算法移植到RT1052微处理器上.通过开启硬件FPU和使用CMSIS-DSP库优化,缩短算法运算时间,再结合VAD检测静音段,避免算法在静音段更新噪声参数,静音段结束后算法无需重新收敛.测试结果证明了方法的有效性.
猜你喜欢
文萃报·周五版(2024年11期)2024-04-09 17:59:20
广东通信技术(2023年9期)2023-10-29 07:09:32
橡胶科技(2022年11期)2022-03-01 22:55:23
石油沥青(2021年3期)2021-08-05 07:41:08
家庭影院技术(2018年11期)2019-01-21 02:20:52
电子制作(2018年19期)2018-11-14 02:37:08
电子制作(2017年9期)2017-04-17 03:00:46
发明与创新(2016年34期)2016-08-22 03:01:04
人间(2015年8期)2016-01-09 13:12:42
电信工程技术与标准化(2015年10期)2015-12-22 09:08:10
