
基于Kubernetes的云原生海量数据存储系统设计与实现
2020-04-09 14:49刘福鑫李劲巍王熠弘
计算机应用 2020年2期
刘福鑫,李劲巍,王熠弘,李 琳
(武汉理工大学计算机科学与技术学院,武汉430070)
0 引言
云计算已成为互联网未来的趋势之一,拥有不可估量的潜力[1]。云应用和云平台的普及使开发者能够将更多的精力投入于应用程序本身的开发与维护上,不用再关心硬件架构、服务器资源与日常硬件维护等与业务本身无关的杂项工作。近年来,越来越多的业务开始从传统的服务器架构迁移到云上,同时我们也看到有更多的业务从设计之初即计划运行在云端。这些业务通常被称作云原生业务,意指其与云的高度结合。云原生业务相对传统业务通常会更加充分且频繁地应用例如微服务、弹性计算和服务编排等云平台所提供的先进技术帮助业务更稳定、高效地运行。部分前沿实践甚至尝试使用更加轻量的操作系统(如Alpine Linux 等)来适应容器化和虚拟化技术[2]。
当前较为典型的云原生业务是移动互联网时代的社交平台,这些平台大多充分利用了云计算的优势,比如微博广泛使用阿里云作为其计算后端,构建大规模混合云,将部分高频业务运行于公有云平台上,以灵活处理热点事件的突发负载[3]。社交平台的用户量不断增加,且对计算和存储的需求极大,这不仅需要灵活而稳定的基础架构来保障其稳定性,还要利用自动化扩容与灾备等高级功能使其在突发负载下依旧为用户提供良好的体验[4]。
早在2010 年,Facebook 就已发表了其应对大规模照片与文件存储的方案,这一方案被称为Haystack。Haystack是一个专注于海量文件存储的对象存储系统,它充分满足Facebook对文件的存储需求。它使用文件块将小文件打包进名为Superblock的物理卷中,并将元数据缓存在内存里以获得极高的索引和查询性能。它同样支持集群化部署,能够将存储负载进行分散,以有效提升性能与可扩展性[5]。
随着近些年来云计算的普及,互联网展现出了整体向云上迁移的趋势,以便充分享受云平台所带来的高效与稳定。但Haystack 及其大多数相似实现却依旧被设计为运行在传统硬件架构上,需要相对复杂的配置才能使其运行于云端,这与云原生开箱即用、轻量部署的理念有一定差距。若出现热点事件或用户量极速增长,手动扩容集群规模往往不能及时应对突发压力,甚至在扩容过程中还会由于节点拓扑无法在线修改,引发不可避免的闪断,降低服务可用性。此外,上述存储方案在缓存与资源利用上的缺失,同样导致了它们大多并不能充分利用云所能提供的资源与环境,所提供的性能依旧不够理想,这一问题也影响了该类存储方案的普及。
综上所述,无论是传统的文件系统还是当前的对象存储系统,其设计与优化都不能充分满足数据密集型业务在云上不断扩张的需求,原因主要在于上述存储方案大多都无法充分利用云平台所提供的调度功能,适应负载的波动并利用以上功能实现自动化调度,进一步实现自我优化、自我管理。
为了解决以上问题,本文提出了一种新的存储系统,称之为Kubestorage,指运行在Kubernetes 上的存储系统。该系统基于Haystack,但在服务发现和自动容错等宏观调度方面进行了专门优化,使其更符合云原生技术的定义,更适合部署在云端,也更适合于在存储方面驱动数据密集型的云业务高效稳定运行;此外还针对Haystack 于磁盘方面的性能瓶颈,在缓存与易用性方面进行了优化。
1 相关工作
学术界在对象存储方面的研究要远早于云计算。早在1996 年,卡内基梅隆大学就开始了由Garth Gibson 领导的相关研究,并于1998 年首次提出了对象存储的概念与基础架构[6]。此后,对象存储在各存储公司的支持下持续蓬勃发展。据统计,在1999 年到2013 年之间,在对象存储方面的风险投资已突破3 亿美元[7],这使得对象存储技术得到了极大的发展,并迅速应用于大量成熟的产品中。
美国亚马逊公司旗下的AWS(Amazon Web Services)早在2006年初就将对象存储作为开放服务,开发了亚马逊S3对象存储服务。仅2012年一年,S3对象存储系统就新增了超过一万亿个对象,而在短短一年后,甚至增加到每年新增两万亿个对象。此外,S3 还能确保这些数据可以随时被访问与随机读写。据亚马逊官方报告,S3 中的任意一个文件都可以承载每秒最高110万次的读取[8]。
另一个相对较为知名的对象存储解决方案是由Weil、Brandt、Miller、Long 和Maltzahn 在2006年USENIX 操作系统设计会议(OSDI 2006)中提出的Ceph[9]。Ceph 在软件层面进行大量优化,能使用普通硬件实现大规模的文件存储,相对于来自IBM、EMC等大型存储方案公司的产品拥有更好的兼容性。
Facebook 公司在2010 年通过论文的形式提出了一种专注于大量小文件的存储、更实用且更灵活的对象存储模型,称之为Haystack。Haystack 的独特之处在于将小文件合并到一个称为物理卷的文件块中,以便在存储大量小文件的同时保持较为理想的索引速度。文件索引则包含了文件的基础信息、文件在文件块中的偏移量等元数据。此外,文件索引被读入内存中,以此提升索引速度,降低磁盘负担。
2 Kubestorage存储系统的架构
Kubestorage存储系统由三部分组成:
1)目录服务器,用于节点信息的存储、文件到存储节点的映射、节点自动管理与负载均衡等功能。
2)存储服务器,用于文件存储、元数据管理和存储一致性的自动维护。
3)缓存服务器,用于缓存高频访问的文件,以获得更好的性能。
整个存储系统运行在以Docker 为容器后端的Kubernetes集群之上,通过Kubernetes 配置文件的方式进行快速部署,Kubernetes负责提供管理、服务发现与故障恢复等功能。
Kubestorage 为解决Haystack 和其他存储解决方案的缺点,进行了以下改进:
1)使用Raft 一致性算法[10]实现了对多目录服务器的支持,使目录服务器更稳定、可靠,避免单点故障造成整个存储系统失效。
2)相较于Haystack,Kubestorage 并未将存储服务器直接暴露给外部用户或业务,而是使用反向代理由目录服务器与业务进行读取与写入操作以提升安全性,同时增强目录服务器对整体的控制能力。鉴于Kubernetes 环境下虚拟交换机带宽大于传统服务器互联带宽,且可以通过负载均衡器实现集群部署,因此相对于带宽瓶颈,相对应的安全性与简便性提升更有价值。
目录服务器为业务提供单点API,涵盖所有的读写与管理操作,以便简化业务开发,避免存储服务器暴露所导致的安全隐患。
3)定期巡检所有文件,并自动压缩长时间未访问的数据,以节省存储空间.
4)使用多级缓存机制以最大限度地降低检索文件以及从磁盘中读取文件造成的性能损失。
5)自动将经常访问的文件复制到多个存储服务器中,以分散文件读取压力,实现负载均衡。
此外,Kubestorage 还充分利用了容器化的特性和Kubernetes 所提供的丰富功能,保证了在不同软硬件上运行环境的一致性,并在此基础上使其具有如下更多功能:
1)动态监测所有Kubestorage 节点的状态,并在磁盘空间、CPU配额、内存空间不足时自动扩容。
2)自动运行状况检查,其中包括一致性检查、有效性校验、延迟检查、压力测试与硬件健康检查。
3)基于kube-apiserver 与kube-dns 的自动服务发现,可在服务不中断的情况下动态修改存储集群拓扑,提升Kubestorage的可用性。
Kubestorage 的详细架构如图1 所示,主要由目录服务器、存储服务器和缓存服务器三个部分组成。
2.1 目录服务器
目录服务器主要承担以下工作:
1)管理逻辑卷和物理卷之间的映射;
2)管理目录服务器级别缓存;
3)当某个文件访问量激增时,开启自动文件冗余,在多个存储服务器上建立该文件的副本以提升吞吐能力;
4)作为负载均衡器,对存储服务器进行反向代理,并向外部业务提供统一的API。
同时,Kubestorage还具有以下功能,使其更适合自动化集群部署,并提供一致性与可靠性保障:
1)使用Raft 一致性算法提供较高的一致性与可靠性,避免单点故障导致整个存储系统失效,外部业务对附属节点的访问将会被转发到主节点。该算法保证了数据的一致性与可靠性,使得在每个轮换周期内有且仅有一个目录服务器负责响应用户请求。
2)Kubernetes 将会对每台目录服务器设置3 个预设标签:角色、状态和健康度。例如角色为kube-storage-directory,状态为leader 或slave,运行状况将是以下4 种类型之一:正在运行(Running)、正在初始化(Initializing)、忙碌(Busy)或离线(Offline)。当每个目录服务器需要知道其他目录服务器的状态和数量时,可以使用这3 个标签作为选择器,向kubeapiserver 询问目录服务器列表,kube-apiserver 将返回集群内满足所选择条件的服务器。
3)为了保障数据一致性,避免使用读/写锁造成系统逻辑复杂化,所有目录服务器将会共享一个数据库后端。数据库后端的种类可以根据实际需求自由决定,但以Redis为例的内存数据库通常可以提供最佳的性能。
此外,目录服务器还会记录最近的文件读取请求并存储在数据库内该文件对应的记录中,然后定期读取上一个巡检周期内各文件访问次数。对于频次超过设定阈值的文件,目录服务器会使用存储服务器的冗余写入API 进行自动冗余,依靠在多个服务器上建立该文件的副本以提升性能,若下一次巡检发现已冗余的文件访问量低于阈值,目录服务器则会使用冗余删除API进行已冗余文件的移除。
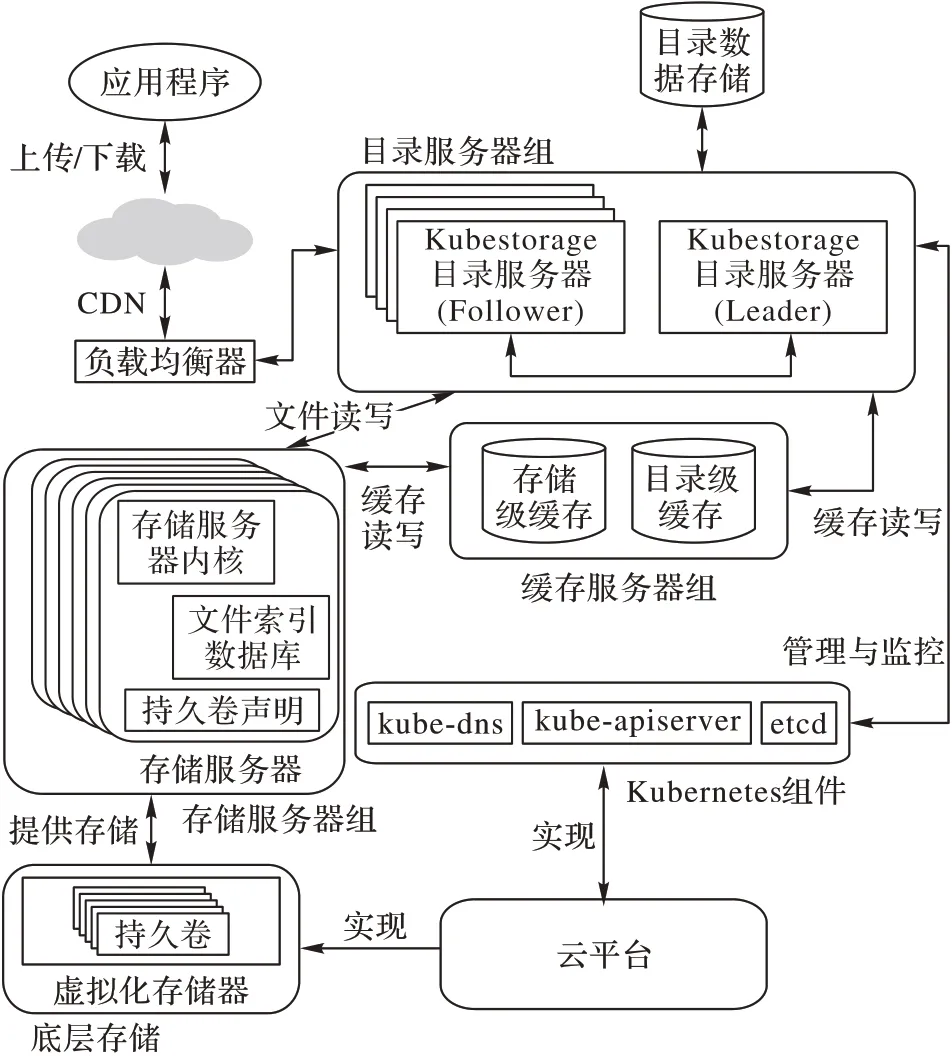
图1 Kubestorage的架构示意图Fig.1 Schematic diagram of Kubestorage architecture
2.2 存储服务器
存储服务器主要承担以下工作:
1)负责管理存储在其中的文件、文件的元数据以及文件的写入和读取;
2)管理存储服务器级别缓存;
3)执行数据压缩、解压缩与有效性校验;
4)定期向目录服务器报告其状态,以便根据统计信息进行自动化管理。
存储服务器的技术实现如下:
1)元数据和物理卷的底层存储与Haystack 基本一致,但Kubestorage 在此基础上增加了对压缩文件的支持,文件是否被压缩的状态被存储在元数据中,并在写入时压缩存入,读取时解压读取。
2)Kubernetes所提供的持久卷(Persistent Volume)将用作存储服务器的存储后端。它具有高度抽象的特性,独立于特定的操作系统、存储架构和硬件,可以与现有的存储方案良好兼容,并可避免计算与存储的强耦合。为了使Kubestorage 尽可能简洁,冗余和高可用由实际的存储后端自主实现,以充分利用磁盘/网络存储行业中长期的技术积累。
3)Kubestorage 选择了较为松散的元数据存储后端结构,以接口方式实现,使其能充分利用云平台中所提供的数据库服务进行元数据的存储。此外,为了简化部署和使用,Kubestorage搭载了leveldb[11]作为其默认数据库。该数据库在存储量较小但访问频次较高、数据结构单一的情况下可以实现用很少的资源消耗提供相对理想的性能,避免普通文件数据库频繁磁盘读写与复杂存储结构造成的性能瓶颈。
4)每个存储服务器将定期运行自检服务,获取当前存储容量、并发读写状态、文件数量、硬件健康状态、网络情况以及其他所需信息,并提供API,便于外部查询服务器状态。自检服务使得目录服务器、Kubernetes、甚至运维人员可以随时了解到当前每个节点的状态并及时进行管理。
5)当具有副本标记的文件写入请求到达存储服务器时,存储服务器会首先在本地存储该文件。然后存储服务器会根据写入请求中所指定的地址向对应的其他存储服务器发送副本创建请求,其他存储服务器收到请求后同样将文件写入。副本创建请求同样也可以被目录服务器所触发,以根据访问频次进行副本数的动态变化,实现动态负载均衡。
6)删除文件时,存储服务器会立即删除元数据,但此时文件尚未被物理删除。巡检程序会定期启动,以比较物理卷和元数据中的文件对应情况。如果发现当前物理卷有已删除文件或损坏的文件,巡检程序将创建新的临时物理卷,并根据元数据将物理卷中的每个文件复制到临时物理卷。
2.3 缓存服务器
缓存服务器负责统一的数据缓存,由于需要存储文件,因此使用Redis作为其存储后端,从内存中进行文件读写以保障性能。缓存服务器使用了目录/存储两级缓存设计,以提升缓存性能,尽量降低响应时间与服务器负载。
其具体的技术实现如下:
1)缓存服务器定期检查存储在其中的目录与存储级缓存,删除重复的缓存(即缓存文件都存在于目录级缓存和存储级缓存中),并自动清除一段时间内未访问的缓存以节省内存空间。
2)缓存服务器还会将频繁访问但只缓存在存储级缓存中的文件移动到目录级缓存中,以提升请求效率。
2.4 文件上传与下载的流程
将文件上传到Kubestorage 的过程分为以下几步:目录服务器首先接收来自业务的文件上传请求,其中包括文件的副本次数和文件的二进制数据。如果当前目录服务器不是Leader 服务器,则受理上传请求的目录服务器将向Leader 服务器发送一个反向代理请求。Leader 服务器将会核对数据库,以确保物理卷数量足够,然后创建区块和存储数据的请求将被发送到指定的存储服务器。目录服务器最后生成对应链接以便后续访问。
从Kubestorage 下载文件的过程则分为以下几步:首先业务将向目录服务器发送文件下载请求,请求中包含此前所生成的永久链接,目录服务器首先将检查文件是否存在于目录级缓存中,如果文件存在,数据将从内存中读取,并直接传输给业务;如果未命中缓存,则会将文件获取请求发送到相应的存储服务器,存储服务器同样将检查文件是否存在于存储级缓存中,如果在存储级缓存中则直接传输,如果缓存未命中,则存储服务器会将当前文件放在存储级缓存中,以此减少下次读取时间,如果频繁访问该文件,它还会被转移到目录级缓存进一步提高文件的访问速度。
2.5 缓存策略的实现
存储服务器会将接收到的每一次读取请求记录在数据库中(每次巡检周期结束后清空一次计数),并在下一次巡检周期开始时将满足访问次数阈值的文件放置于相对应的存储级缓存中。对于已缓存的文件,若下一次巡检的读取次数低于阈值,则将其从缓存中清除。若多次巡检发现缓存依然未被清除,则将该文件转移至目录级缓存。
若缓存服务器缓存体积超过最高安全阈值,则会按照上一个巡检周期内的缓存命中次数对文件进行排序,清除命中次数较低的文件直至缓存体积低于最低安全阈值。
上文所述所有阈值与巡检周期均可配置,以便平衡性能与成本,适配不同规模的存储需求。
2.6 对服务器节点故障的处理
Kubestorage 能容许服务器节点的故障并能实现自动恢复。每台目录服务器都会通过kube-apiserver 组件定时获取当前所有节点状态,若发现某台服务器出现异常(即Kubernetes 自检不成功,Pod 状态为NotReady 或状态标签为Offline),目录服务器会立刻调用kube-apiserver 清除故障节点并完成持久卷绑定、数据库初始化等操作,实现自恢复。该策略对目录服务器、存储服务器与缓存服务器均有效。
由于负载均衡的存在,所有请求均会被传递到正常的目录服务器中,若出现异常的目录服务器为Raft 集群的Leader,则剩余的所有Followers会重新进行选举。选举期间的请求将会被放入等待队列,并在对应存储服务器恢复后立刻继续任务。对故障缓存服务器的请求被视为缓存未命中,直接从存储服务器请求所需文件。
3 性能测试
3.1 测试环境
性能分析部分将使用阿里云的ECS 服务器作为测试平台,配置为Intel Xeon Platinum 8163 处理器(8 个虚拟核心),32 GB 内存,同时挂载6 TB 的SSD 云磁盘作为测试用数据盘(标称IOPS为25 000,吞吐量为读/写均256 MB/s)。
我们选择了EXT4、ZFS 和SeaweedFS 作为基准,分别代表传统文件系统、现代文件系统和传统对象存储系统。SSD 云磁盘将分别被格式化为EXT4、ZFS 文件系统,并对其进行一系列的测试。该云磁盘也将被格式化为EXT4,并在其上配置Kubernetes 单机集群(使用Flannel 虚拟网络),以便使用Kubestorage和SeaweedFS进行测试。
3.2 测试方法
测试方法如下:在测试服务器上运行使用Golang 开发的文件读写API,并使用另一台配置相同的服务器在局域网内远程访问此API,避免测试工具本身对测试造成的干扰。Kubestorage 将构建于Kubernetes 上,使用2 个目录服务器、8个存储服务器与1 个缓存服务器构成小型的Kubestorage 集群,物理卷大小为每文件1 GB,文件默认副本数为2。SeaweedFS 将保持与Kubestorage 相同的硬件配置与环境配置,并按照使用文档使其运行于Kubernetes上。
3.3 测试过程
测试过程如下:
1)提前分别将1 000 万个文件大小为4 KB、40 KB 与400 KB 的文件写入待测试的存储系统,文件内容为随机ASCII字符。为避免EXT4由于inode不足造成测试失败,已提前扩增inode容量。
2)在另一台服务器上(两台服务器之间网络带宽为10 Gb/s)通过测试软件分别启动足量线程直至测试服务器报告其正在执行的并发请求数量为50、500、1 000、5 000(避免由于发起线程数与测试服务器收到请求数不一致对测试造成干扰,使接收请求数尽量接近实际的并发读取数),使用上文所提及统一的API 从测试服务器中随机进行文件的读取和写入,在发起请求的服务器上记录每次读取和写入的响应时间以供后续性能分析。每轮读取测试中,1 000万个文件中的随机20 万个将被以随机的不同频次总共读取500 万次,以模拟云计算环境中真实业务中的负载场景。每轮写入测试中,将写入20 万个文件,每个文件大小分别为4 KB、40 KB 与400 KB,文件内容同样为随机ASCII。
3)从预写入的1 000 万个40 KB 文件中随机选取100 个40 KB 文件进行热点测试,模拟社交平台中常见的热点图片资源,对这100 个文件同时进行并发数为1 000 的随机读取,每个文件读取10 000次,记录读取过程中性能的变化、缓存的变化与文件分布的变化,以测试上文所述缓存策略与自动冗余策略是否有效。
4)在1 000个线程的40 KB随机读写测试过程中,手动将一半的目录服务器与一半的存储服务器状态配置为Offline(拒绝所有请求),以测试性能波动与服务稳定性。
由于Kubestorage 与SeaweedFS 均不支持目录功能,为保证测试的准确性与可信度,对于传统文件系统,所有读取与写入的文件均放置在同一目录下。
3.4 度量标准
在测试过程中,将记录并比较平均响应时间、响应时间方差和1 000并发下响应时间占比(即小于特定响应时间的请求占比)。平均时间越短,表示性能越好;方差越小,表示越稳定;响应时间占比中低延时所占百分比越多表示性能越好。每组实验将在相同条件下重复5 次,并取所有数据的平均值。实验结果如表1~3所示。
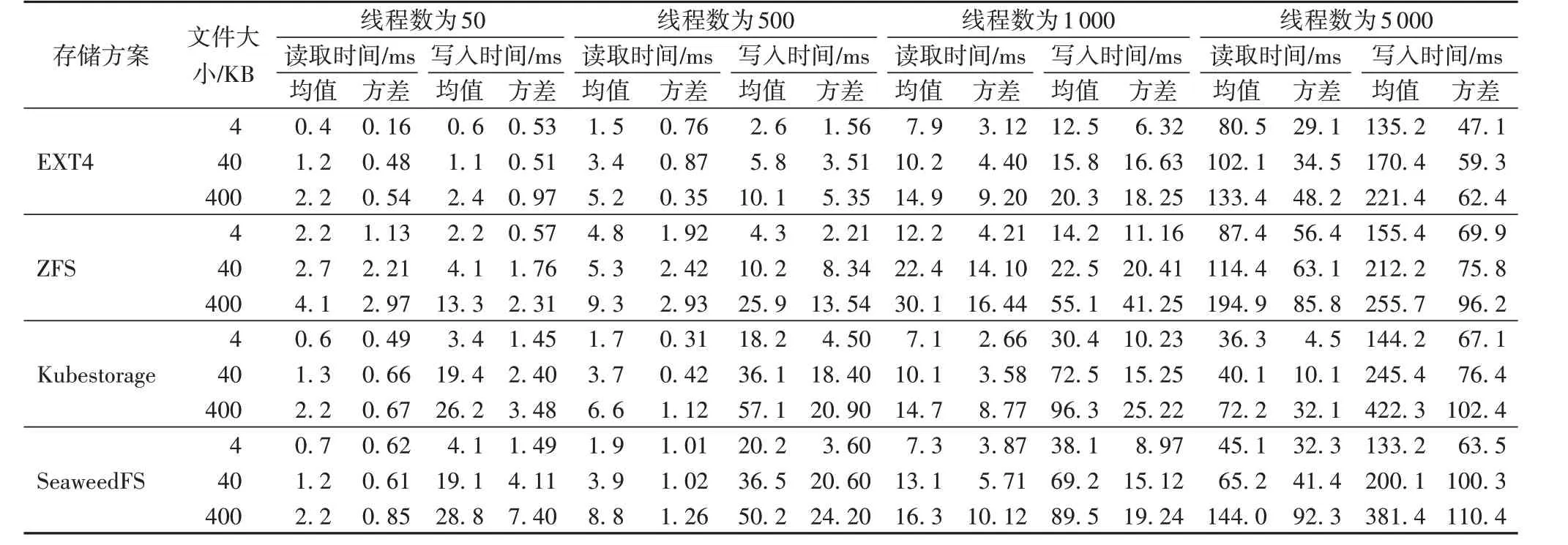
表1 不同线程数量下各存储方案的平均读取时间、平均写入时间与方差对比Tab.1 Comparison of average read time,average write time and their variances of different storage schemes under different thread number
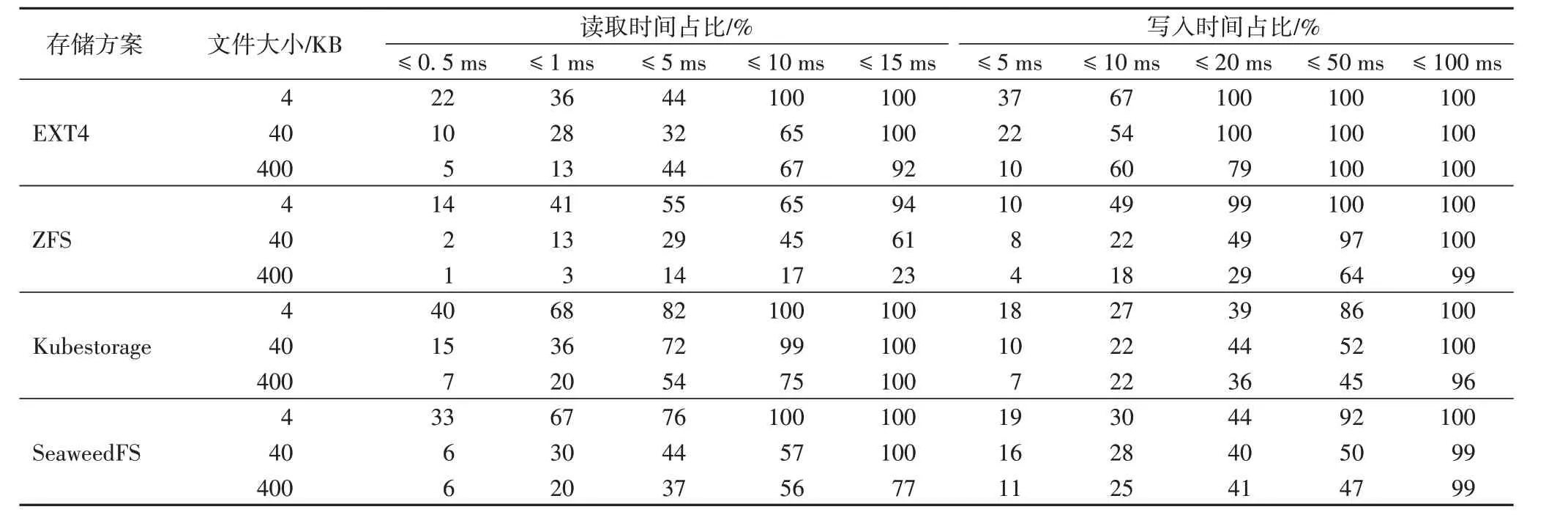
表2 1 000并发请求下各存储方案的读取与写入时间占比Tab.2 Average read and write time proportion of different storage schemes under 1 000 concurrent requests

表3 热点访问测试中平均响应时间与方差 单位:msTab.3 Average response time and variance in hot spot access test unit:ms
3.5 测试结果与分析
3.5.1 性能分析
从表1、2 中可以看出,ZFS 受限于其复杂的设计,响应时间与稳定性落后于其他存储方案,这是由于ZFS相较于性能,更侧重于可管理性与可扩展性,导致文件读写过程相对复杂,相应的资源耗费更多。当并发读取量较低时,Kubestorage、SeaweedFS 的读取性能与EXT4 大致相同。当并发读取量上升后,Kubestorage 开始逐渐展现出其优势,尽管Kubestorage和SeaweedFS 具有相同的存储模型,但在读取时,Kubestorage受益于其多级内存缓存与自动建立副本的设计,相对SeaweedFS 性能更占优势。从表中可以看出,Kubestorage 在1 000 与5 000 并发时的平均响应时间与稳定性相对于SeaweedFS 与EXT4 均占有一定优势。总体而言,采用Haystack 存储结构的Kubestorage 与SeaweedFS 性能均优于EXT4 和ZFS,其中Kubestorage 由于缓存与自动副本策略的引入,性能相对更优。
从表1、2 中还可以看出,由于创建元数据和将文件插入物理卷的开销较大,Kubestorage 和SeaweedFS 的写入性能均远低于其他文件系统,这一问题在请求数量增多时格外明显。
从表3 中可以看出,在热点访问测试过程中,由于EXT4、ZFS、SeaweedFS 均不带有文件缓存,在不同测试阶段的性能并无显著变化,但Kubestorage 随着访问计数的不断增加开始逐渐开启副本冗余(10 min 内500 次读取触发)、写入缓存(10 min 内1 000 次读取触发),以降低存储服务器的磁盘压力。表3数据充分证明了缓存策略为Kubestorage 带来的性能与稳定性提升。
3.5.2 稳定性分析
在手动关闭服务器的测试过程中,被关闭的目录服务器是当前Raft集群的Leader,Kubernetes 的负载均衡将所有请求移交给另一台Follower,Follower 在节点检测过程中检测到Leader 不可用,立刻开始新一轮选举,并将自己设置为Leader。期间正在处理的请求被放入目录服务器队列,并在选举完成后继续请求。随后新的Leader在选举完成后立即调用kube-apiserver 新建了一台新的目录服务器以填补空缺,该服务器成为Follower,服务恢复正常。
被关闭的一半存储服务器在节点检测过程中被目录服务器判断为不可用,并由目录服务器调用kube-apiserver 新建了4 台新的存储服务器,自动完成持久卷挂载与数据初始化操作,然后取出所需文件传输给客户端。由于存储服务器的初始化需要一定时间,关闭后约20 s内出现了一定的性能波动,这20 s 内的平均读取响应时间由10.7 ms 增加到1 466.1 ms,但由于默认副本数为2,只有少部分文件完全不可读。
4 结语
综上所述,本文所提出的Kubestorage 存储系统被设计为更适合存储云平台与云业务中的大量小文件,尤其是以社交网络为典型,即读远多于写的使用场景。上述测试充分展现了Kubestorage 在架构设计上的优势与潜力,且部署过程简单,使用预配置的脚本仅需数条命令即可搭建出任意规模的Kubestorage存储集群,这使其更为灵活,在云上拥有比传统存储解决方案更好的性能和更优秀的稳定性。Kubestorage开箱即用,更适合云原生业务部署,为云上的应用提供更快捷稳定的存储解决方案。
但同时我们也看到了目前Kubestorage 所存在的一些不足,将来还需要在以下方面进行改进,以提供更好的使用体验,进一步提升其实用性与易用性:
1)使用缓存服务器对文件写入进行缓存,以实现异步文件保存功能,提供更好的写入性能;
2)添加对目录、文件别名、软链接等高级特性的支持,以保持与传统文件系统的双向兼容和相互转换,提升兼容性与灵活度,便于让更多业务享受对象存储的便利;
3)考虑到目标应用场景内可能有大量重复的文件资源,因此可对散列相同的文件进行合并存储,以节省磁盘空间。
猜你喜欢
九江学院学报(自然科学版)(2022年2期)2022-07-02
计算机应用与软件(2021年10期)2021-10-15
小型微型计算机系统(2020年5期)2020-05-14
计算机与生活(2020年5期)2020-05-13
火力与指挥控制(2020年1期)2020-03-27
发明与创新·大科技(2019年12期)2019-03-17
传播与制作(2018年9期)2018-11-15
中国计算机报(2018年12期)2018-10-08
网络与信息(2009年4期)2009-04-26
中国计算机报(2009年21期)2009-04-22
