
基于边缘计算的分支神经网络模型推断延迟优化
2020-04-09 14:48樊琦,李卓*,陈昕
计算机应用 2020年2期
樊 琦,李 卓*,陈 昕
(1.网络文化与数字传播北京市重点实验室(北京信息科技大学),北京100101;2.北京信息科技大学计算机学院,北京100101)
0 引言
近年来,深度学习在一些领域取得巨大成功,其中的深度神经网络(Deep Neural Network,DNN)方法在各种任务上取得了很好的效果。越来越多的推断任务譬如自动驾驶[1]、智能语音[2]、图像识别[3]等都需要用到神经网络。深度神经网络主要由多个卷积层、全连接层组成。其中的每一层都对输入数据进行处理,并传输到下一层,在最终层输出推断结果。
高精度的DNN 模型有更多的网络层数,也需要更多的计算资源。目前智能应用任务中,通常将DNN 部署在计算资源充足的云端服务器[4]。在这种方式下,需要数据源把任务数据传输至云端的模型中执行推断任务;云计算模式存在着延迟高、隐私性低和通信成本高等问题[5],无法很好地满足任务需求。还有的做法尝试将推断模型部署至移动设备端[6],但由于移动设备受限的资源情况,只能运行简单的机器学习方法,最终得到精度不高的推断结果。
边缘计算作为一种新型计算模式,其核心原则之一是将计算能力推向边缘,得到了研究人员广泛关注[7]。在边缘计算场景下,将DNN 模型部署在设备周围的边缘计算节点上。相对于到云服务的距离,边缘计算节点到数据源近得多,所以低时延特性能轻松实现。但目前的边缘计算设备处理能力有限,单个边缘计算节点可能无法很好地完成复杂网络模型的推断任务,因此需要多个边缘计算节点共同部署DNN 模型。在边缘计算场景下部署DNN的主要挑战是如何挑选出合适的计算节点来部署模型,要考虑到神经网络模型的切分、模型的计算需求及边缘计算节点的网络状况,以此来优化多个计算节点协同运行神经网络模型时的延迟。图1 展示了分别在云计算和边缘计算下进行深度学习的场景。云计算场景下用户设备发送的数据通过网络上传到云服务器进行推断任务。而边缘计算场景下云服务器只进行延迟容忍的模型训练过程,然后将训练好的模型部署在边缘节点,数据源将推断任务数据传输至边缘节点,DNN模型进行推断后再为数据源返回推断结果。
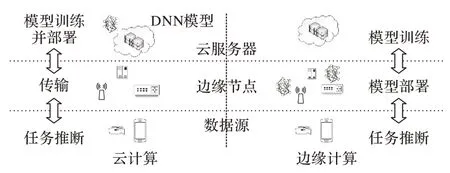
图1 云计算与边缘计算的深度学习模型对比Fig.1 Deep learning model comparison of cloud computing and edge computing
本文主要研究了如何在边缘计算环境下减少DNN 的推断延迟。利用BranchyNet深度学习框架在云端服务器上训练好具有多个分支的DNN 模型,证明了分支神经网络的分布式部署问题是NP难的,设计并实现了基于分支定界思想的部署算法(Deployment algorithm based on Branch and Bound,DBB),来为DNN 模型找到有最小运行延迟的边缘节点部署方案。针对数据源推断任务的延迟要求、地理分布特性,提出选择节点退出(Select the Node Exit,SNE)算法,为不同的推断任务数据源选择合适的边缘计算节点返回推断结果。实验结果表明,与在云端部署神经网络模型的方法相比,基于边缘的神经网络模型推断方法平均降低了36%的延迟消耗。
1 相关工作
深度学习任务主要分为训练和推理两个阶段。神经网络层数的增多带来的是训练和推断延迟以及成本的增大。为使DNN 更好服务于应用,目前有研究关注神经网络的分布式训练方面,比如:文献[8]提出的参数服务器框架,用并行的方式,使用参数服务器在训练时更新节点参数,以缩短大数据环境下深度学习的训练时间;文献[9]考虑了训练DNN 模型时分布式服务器之间的通信开销,研究了多种通信算法来提高DNN模型的训练效率。
在优化神经网络推断延迟方面,文献[10]提出了一种BranchyNet 分支网络结构,在普通DNN 模型中间添加多个分支网络模型并部署早期退出点,当系统对推断任务有把握时,可将任务在模型中间添加的分支中退出,不必使样本经历DNN 模型的所有层数,从而减少推断延迟;文献[11]利用DNN 模型中卷积层和全连接层广义矩阵乘积操作的特性,将DNN 模型中这两部分计算需求划分为可以并行执行的片段,并部署到多个移动设备上,使用并行计算的方法来减少推断过程中的延迟;文献[12]研究了本地与边缘服务器协同进行DNN 推断的场景,提出了Edgent 终端-边缘协同推理框架,将DNN 模型划分为两个部分:将资源需求大的部分部署在边缘服务器上,而资源需求小的模型部分则部署在本地终端设备上;文献[13]提出了Neurosurgeon 系统,研究了计算机视觉、语音等多种DNN架构的计算和数据特性,设计了DNN模型在移动设备与云服务器上共同部署时的分区方案。对边缘计算场景中的深度学习推断任务,有效的任务调度算法也可以提高模型推理性能,文献[14]中将DNN 模型分别部署在网络边缘的网关与远程云服务器上,通过为深度学习任务设计了一种新的任务卸载策略来提高推断性能。
此外,还有研究关注减少DNN 模型的计算工作量。文献[15]中通过剪接、训练量化和哈夫曼编码三阶段对DNN 模型进行深度压缩,在不影响DNN 模型精度的前提下,降低了DNN 模型的存储需求;文献[16]针对在资源有限的嵌入式设备中进行卷积神经网络计算所需内存空间和资源过大的问题,提出了结合网络权重裁剪及面向嵌入式平台的动态定点量化方法,有效地压缩了神经网络模型并降低了计算消耗。
在边缘计算场景下进行深度学习推断任务,需要考虑DNN 模型计算特性以及边缘节点的网络状况和计算能力,因此本文综合考虑这两点提出分支神经网络在边缘计算场景下的分布式部署问题,通过选择最优部署方案以及优化推断结果的传输来减少推断任务的延迟。
2 部署模型与问题定义
在边缘计算场景下部署分支DNN 模型,首先需要在云服务器上完成模型的训练过程,这个过程是延迟容忍的,本文重点关注模型进行任务推断的过程。DNN 的结构是层与层之间的有序序列,每一层接收到上一层输出数据并处理,然后传输至下一层。利用这个特性可将DNN 构造为具有多个分支的DNN 模型,每一个分支都由具体的神经网络层组成,多个分支又共同组成一个完整的DNN 模型。边缘计算场景中的边缘计算节点由多种计算性能不同的设备组成,这些设备数量众多,相互独立,分散在用户周围[17]。单独的边缘计算节点只能运行精度不高的简单模型,自然想到将带有分支的DNN模型分布式部署到多个边缘计算节点上,由这些节点共同完成模型的推断过程。因为各分支有着不同的网络层结构,这会导致各分支对部署节点的计算资源要求不同,即同一模型部署到不同节点上会导致不同的运行延迟;又考虑到不同边缘计算节点之间有着不同的网络状况,因此分支神经网络的分布式部署问题需要综合考虑到节点计算能力、分支模型结构以及节点之间的数据传输,不同的部署方式会使得推断样本经历不同分支出口点、DNN 层数,即会导致精度和运行时的延迟不同。因此,需要为给定的DNN 分支模型结构选择最佳的边缘计算节点部署。同时数据源到不同边缘计算节点的距离、网络状况也是影响推断任务效果的因素。因此,问题的研究可以分为两个阶段:第一阶段是为训练好的DNN 分支模型选择合适的边缘节点部署,目标是使模型运行时的总延迟最小;第二阶段是为不同的数据源选择满足其延时要求的边缘计算节点退出推断结果,并返回数据源。
在边缘计算场景中,给定边缘计算节点集合E={e1,e2,…,ei,…,em}以及有n 个分支的DNN 模型集合D={d1,d2,…,dz,…,dn},其中dz表示第z 个分支,且这n 个模型分支有运行顺序的要求;fij表示分支模型i 和j 部分的运行顺序;mij表示边缘节点i与j之间延迟;cij表示将di部署在ej上运行时的延迟;xij表示将第i个模型部分部署到第j个节点上。
问题1 分支神经网络的分布式部署问题。给定边缘计算节点集合E 与DNN 分支模型集合D,要求确定一个部署方案,使得在该部署方案下,每一个分支模型都部署到一个边缘计算节点上,使DNN模型运行时所需总延迟最少。
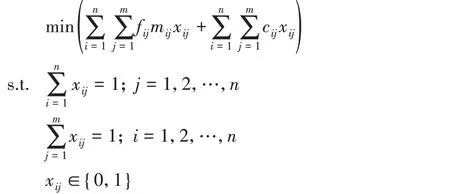
定理1分支神经网络的分布式部署问题是NP-难问题。
证明 首先介绍二次分配问题(Quadratic Assignment Problem,QAP)。QAP 可描述为:给定n 个设备和n 个地点,三个n×n 矩阵F=(fij)n*n,D=(dij)n*n与C=(cij)n*n,其中,fij表示设备i与j之间的流量,dij表示地点i与j之间距离,cij表示设备i部署在位置j的花费,fij与dij之间的乘积为通信费用,要求给每个设备分配一个位置,并使设施之间的通信费用与设施到地点上的部署费用之和最小。
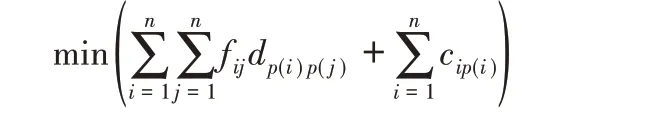
其中p(i)表示设施i被分配的地点。
在分支神经网络的分布式部署问题中,需要将n 个模型分配到m 个节点中的n个节点上(n ≤m),表示为问题规模n×m,而在QAP 中,是将n个设备分配到总数为n的节点上,问题规模为n×n。为了解决规模为n×m 的部署问题,至少需要解决一个规模为n×n的QAP。可以构造m-n个虚拟分支模型,此时部署问题变为规模为m×m 的QAP,再将m 个设备分配到m 个位置上;或是将m 个可用节点位置分为n 组,再将n个设备分配到n 个节点上,此时部署问题变为规模为n×n 的QAP。因此分支神经网络的分布式部署问题至少与n×n 规模的QAP 一样难。已知QAP 已经被证明为NP-难问题[18],因此分支神经网络的分布式部署问题是NP-难问题。
3 模型部署算法设计
3.1 基于分支定界思想的部署算法
本文基于分支定界思想设计了分布式神经网络模型的部署算法。DBB 采用单赋值策略,在每一个步骤选择一个未分配的模型分配到一个空闲的位置。每次分配都会计算当前已分配问题的下界,若当前下界大于已知的最优解下界,则表明对当前解分支继续探索不会得到更好的解下界,则将上一次分配的位置移除,为当前模型分配其他空闲位置;若当前计算下界小于已知最优解下界,算法则会继续采用单赋值策略继续为当前解分配其他的对象。在为模型分配节点过程中,算法为每个节点定义节点性能:每个边缘节点到其相邻节点的延迟与当前模型部署延迟之和越小,则节点越有可能被部署,以此提升下一次分配得到更好下界的可能性。若模型已被全部分配至节点上,计算此时下界,若小于已知最优解下界,则记录当前解并更新下界。此时算法再通过回溯至解空间树上一层,为已分配模型选择其他节点部署来寻找下一个可行解。
算法1 DBB。
输入 DNN 模型集合D 以及边缘计算节点集合E,代表n 个分支模型分别部署在m 个边缘计算节点上的n×m 延迟矩阵C,边缘计算节点之间通信的延迟矩阵M,记录已部署的模型与设施集合为I与J,模型ik不允许被放置的节点集合记为P(ik),C*为初始下界。
输出 部署模型对应的节点序列。
1) C*=∞,i1=d1
2) for j ←1to m:
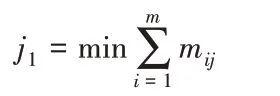
3) 集合I ←i1,集合J ←j1
4) for k ←1 to n-1
calculate B
if B ≥C*
go to 6)
else if B的值未改变
go to 5)
else ik+1=dk+1
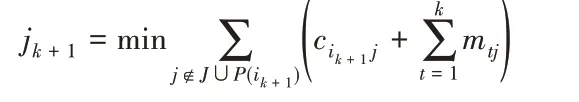
replace I by I ∪{ik+1},J by J ∪{jk+1}
此时C1即完整分配的花费
if C1<C*,C*=C1,存储已分配对(in,jm),k=n
else k=n
6) 将ik与jk分别从I与J中移除
7) P(ik)=P(ik)∪{jk}
calculate B
8) if B ≥C*,then go to 9)
else 分配ik到位置t,t ∉J ∪P(ik)
Jk=t,replace I byI ∪{ik},J by J ∪{jk}
go to 4)
9) 此时ik-1与jk-1从I与J中移除
replace p(ik-1)by p(ik-1)∪jk-1,k=k-1
else 得到最优解(in,jm)
通过分析,该算法复杂度主要体现在计算问题每一阶段的下界部分,下界的定义方法会影响到算法的搜索效率。当问题规模n×n 中n 不超过20 时,可以很快得到问题最优解。而问题所考虑的有n个分支的神经网络模型中,n的规模不会很大,这也是未采用启发式方法,而使用分支定界思想设计部署算法的原因。算法中边界定义如下:假定模型i被放置到位置j,计算当前解的下界B=C1+C2+C3。
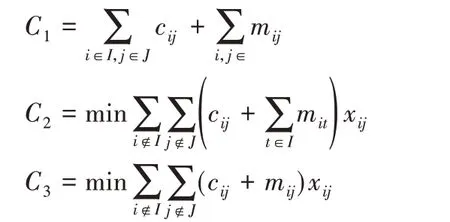
其中:C1表示已分配模型的延迟成本,C2表示已分配与未分配模型之间传输的延迟成本,C3是未分配位置的模型的延迟成本。对本文问题来说,C3的计算策略是将未分配计算节点与其余未分配节点延迟按升序排列,再将需要分配的模型部分依次放置上去。
3.2 选择节点退出算法
部署模型任务完成之后,得到边缘节点上运行分支神经网络模型的最小延迟部署方案。而在推断任务的实际情况中,还需考虑数据源到边缘节点之间的距离、网络状况。推断样本经历不同的边缘节点会导致结果延迟与精度的改变。边缘计算应用具有软实时特征,用户请求需要在一定的期限内返回[19],且推断结果的精度同样影响用户的体验质量。为给推断任务选择合适的出口点返回推断结果,本文设计了选择节点退出算法。对给定延迟要求的推断任务,从已部署的边缘节点集合D 中选出目标节点d 返回推断结果,在保证推断满足延迟要求情况下,使推断样本经历更多的边缘节点,最终为数据源返回符合延迟要求且保证精度的推断结果。
如图2 中,图中央分布的是边缘计算节点,标有数字的是已部署神经网络模型的节点。当数据源1 与2 有任务需推断时,首先将数据发送至部署了神经网络模型第一层的边缘节点1,随后为数据源1 选择符合任务要求的边缘节点2 返回推断结果,为数据源2选择边缘节点5返回推断结果。
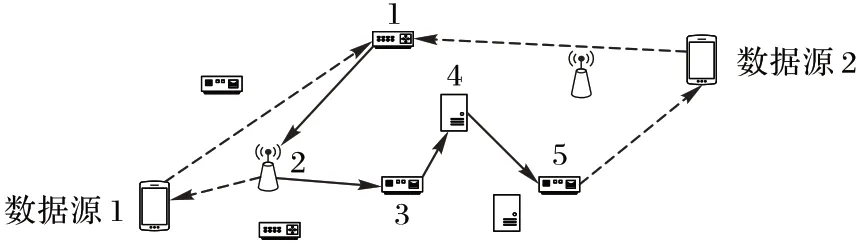
图2 推断任务运行场景Fig.2 Running scenario of inference task
算法2 SNE算法。
输入 已部署的DNN 模型网络拓扑;需推断任务的延迟要求latency;数据源距离第一个边缘节点延迟B1;第i 个边缘节点距数据源延迟Bi;任务退出点N;预测延迟f();推断任务从第1 个到第i个边缘计算节点上推断所用延迟
输出 符合任务t延迟要求的N。
1) For k ←1 to n
2) ELk←f(ELk)
3) For i ←1 to n
return i,store i to set I
5) return N=max I
6) else return null
4 实验结果与分析
4.1 实验环境
本文使用NS2 网络模拟器仿真边缘计算的网络场景,将基于边缘计算的分支网络部署模型与基于云计算的DNN 模型推断进行对比。在深度学习框架BranchyNet下训练了一个具有多个分支的DNN 模型,用于Cifar-10 数据集上的图像分类任务。在NS2 网络模拟器中仿真了以数据源、边缘节点与云服务器为主的网络分布场景。图3 说明了具有5 个分支、6个出口点的分支神经网络模型B-AlexNet。为了便于说明,仅绘制卷积层和全连接层。
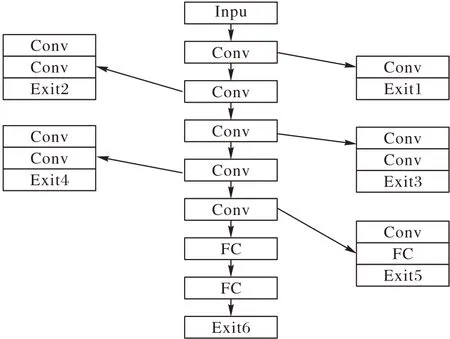
图3 分支神经网络模型主要结构Fig.3 Main structure of branchy neural network model
实验中为设置异构的边缘节点网络环境,采取将JetsonTX1、JetsonTX2、JetsonTK1 和JetsonNaNo 四种不同的边缘设备在每次生成网络拓扑时随机分配到边缘节点上的方法。参考四种设备不同的计算性能参数,使用文献[20]中的Paleo 框架预测了模型各分支在边缘节点上的模型运行延迟,如表1。
4.2 实验结果
首先将本文提出方法与现有在云端部署神经网络模型的方法进行对比。将训练好的分支神经网络模型分别部署在边缘节点上和云服务器上。图4 实验中基于边缘计算的方法中延迟取的是模拟10 次不同网络分布后的延迟平均值,节点之间带宽设置为1 Mb/s。实验结果表明,两种方法中,当数据源的任务经模型推断后从同一出口点退出时,即此时两种方式对任务推断的精度相同,基于边缘计算的神经网络模型推断所用延迟比云端部署方式更短。且综合不同的推断精度考虑,本文方法所用推断延迟较云端部署方法平均降低了36%。
下面基于图5 的网络拓扑,分析边缘节点上神经网络模型对不同地理位置的数据源进行推断任务的性能。首先由DBB 从随机生成的边缘节点分布集合中选择了节点1、2、3、4、5、6部署分支神经网络模型。
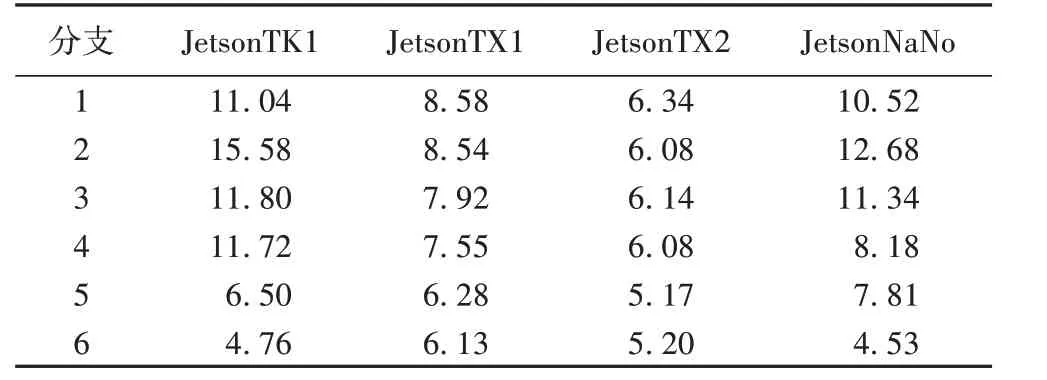
表1 分支模型在边缘设备上的运行延迟 单位:msTab.1 Branchy model running delay on edge devices unit:ms
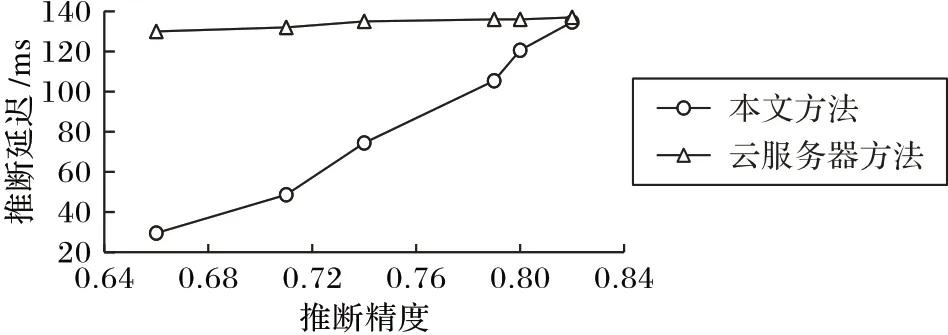
图4 本文方法与云服务器方法的推断延迟对比Fig.4 Inference delay comparison of the proposed method and cloud server method
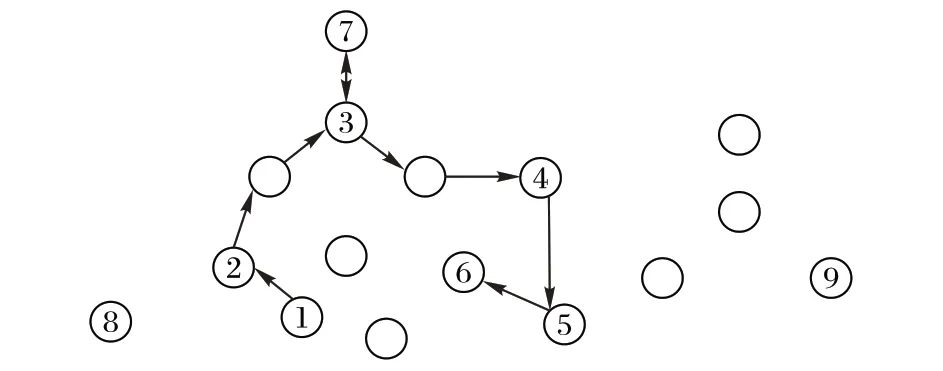
图5 网络模拟状态Fig.5 Simulation state of the network
实验结果如图6 所示,可发现当推断样本返回的推断精度低时,即此时样本在部署早期分支退出点的节点退出(如节点1、2、3),此时数据源节点8距离退出点更近,因此获得了更好的延迟效果;随着推断样本精度的提升,边缘节点在分支神经网络模型后期的退出点为数据源返回推断结果,此时后期退出点距离数据源节点9更近,因此节点9的推断任务取得比节点8更好的延迟效果。
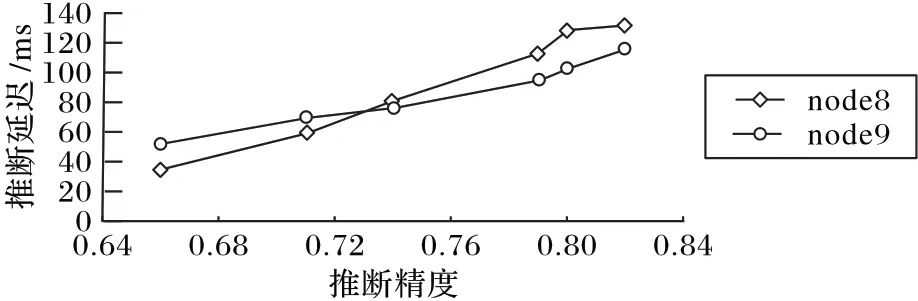
图6 边缘场景下不同数据源任务推断延迟对比Fig.6 Task inference delay comparison of different data sources in edge computing scenario
实验中还发现推断任务的运行延迟受到网络带宽的影响,因此在实验中考虑设置网络带宽为500 kb/s,此时的推断任务运行情况如表2 所示,精度为-1 时表示当前推断无法满足任务延迟要求。当推断任务延迟要求为50 ms 时,云服务器与边缘场景下的SNE 算法都无法满足任务的延迟需求;随着推断任务延迟要求降低,SNE 算法通过选择早期的分支模型进行任务推断,并输出中等精度的推断结果;当任务延迟要求达到350 ms 时,两种方式都可以满足推断任务延迟要求,为数据源返回最高精度分支模型的推断结果。
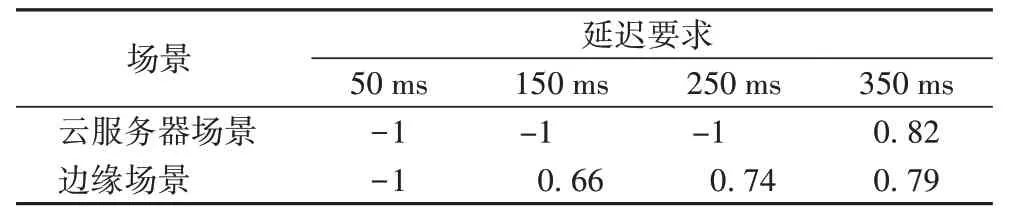
表2 网络受限情况下边缘与云场景下任务推断精度对比Tab.2 Comparison of inference accuracy in edge and cloud scenarios with limited network
5 结语
针对现有基于云的深度学习任务推断延迟过高问题,本文提出在边缘计算场景下部署分支神经网络模型以减小推断延迟,设计了基于分支定界思想的部署算法(DBB)来为给定的DNN 模型选择合适的边缘计算节点部署,降低了推断任务所需要的延迟;同时设计了选择节点退出算法(SNE)为不同延迟要求的推断任务满足选择合适节点返回推断结果。实验结果显示,与传统在云端部署神经网络模型的方法相比,本文提出的边缘计算场景下部署分支神经网络模型平均降低了36%的推断延迟。
猜你喜欢
黑龙江大学自然科学学报(2022年1期)2022-03-29
计算机系统应用(2021年10期)2022-01-06
学生天地(2019年28期)2019-08-25
电脑爱好者(2018年14期)2018-08-05
通信产业报(2016年44期)2017-03-13
电脑知识与技术(2016年8期)2016-05-19
科教导刊·电子版(2016年6期)2016-04-19
电脑爱好者(2015年20期)2015-09-10
疯狂英语·口语版(2013年1期)2013-01-31
雕塑(1999年2期)1999-06-28
