
从图片到衣服:快速虚拟角色服饰生成方法
2020-04-07 10:49:28张姝洁郑利平
计算机工程与应用 2020年7期
张姝洁,郑利平,韩 清,张 晗
合肥工业大学 计算机与信息学院,合肥230001
1 引言
随着计算机技术的发展和人们精神生活的丰富,在影视动画、城市规划和游戏等领域,人们不再满足于单纯的平面图像,对图像三维化的需求日益增多。在需要大规模仿真人群的场景中,使用单一的人物模型会降低场景的真实感,而使用人工精细建模的人力和时间成本太高,精细的人物模型也会降低渲染场景的效率[1]。本文提出了一种可以从单张图片直接快速生成相似人物角色及其服饰的三维模型的方法。
在通过人物图片生成三维人物模型的研究方面,大部分研究的着眼点在于通过对一个人物不同面向的多张图片进行处理,从而生成三维模型。例如立体视觉法,这种方法应用两台及以上的相机从不同角度拍摄同一物体,通过计算视角的视差来恢复物体的深度信息,从而进行建模[2];例如纹理形状恢复法,它是通过分析多张图像的面向不同而导致的纹理变化,来恢复三维物体的形状[3]。
在利用单张人物图片生成相似人物三维模型的研究方面,多采用人工使用建模软件辅助生成衣物服饰的具体模型,再通过技术手段结合到人体模型的方法。张恒[4]使用基于CAD 的建模系统,将手绘草图作为输入,采用了从草图到三维几何重构的方法。他通过计算草图的特征线,将其与人物模型进行拟合,由此生成服装的曲面来进行服饰表面的建模,使用的辅助技能手段较多且流程较为复杂。在由图片生成较为精细的人物服饰模型方面,刘雅琪研究的是从古代人图片还原古代人模型的方法[5],使用了手动选取服饰的关键信息点与OpenCV自动扫描功能相结合的操作,提取图片中服饰信息的数字模型,然后再将数字建模与物理建模相结合得到初步的模型轮廓,最后使用Maya 的脚本编程对建模进行优化得到最终的古代人服饰,使用了多种工具,流程和系统较为庞大。Chen 等人[6]的方法首先使用kinect 扫描服装,再用检测器和分类器从扫描得到的RGB 图像中分别识别出服装部件及其属性,然后将各个部分分别匹配自己的服装组件库,最后缝合各个组件。关于人物服饰系统的研究方面,文献[7]提出基于单张图片的服装试穿系统,首先获取服装衣片,网格化衣片后通过网格的形变匹配用户的图片来达成试穿的效果。成俊燕[8]使用了基于SVM 的HOG 行人检测算法,并与KNN 相结合,通过网格刚性形变匹配服装样板,模拟服饰,达成实现虚拟试衣系统的目的。这种试衣方式得到的结果只有人物穿着服饰的正面图片,而无法形成人物的完整三维模型。Berthouzoz等人[9]提出了自动解析现有服装片面图案并将其缝合转换为3D服装的技术,以方便用户的试衣操作。
纵观前人在生成与图片相似的人物三维模型方面的研究,大多需要软件和较多人工人力的辅助,而当前依托人工智能的生成人物模型的方式,虽然有些能够大致达成分步骤的自动化,但每一步都需要大量训练库的支持。本文聚焦于从单张图片到相似的虚拟三维角色服饰的快速仿真,使用轻量级的方法流程,通过简单的人机交互,从图片中提取出角色服饰的关键信息并进行计算,将服饰信息应用到模型库中所选取的合适模型上,再经过编程渲染即完成了从单张人物图片到相似角色服饰的三维模型的快速生成。
本文使用方法虽然轻便快捷,但是不能较好地保存并展示人物图片中服饰的细节纹理信息,图片处理中的人机交互也使系统自动化流程不够完善,这些将在后续工作中继续进行完善。
2 相关背景知识
从图片到角色服饰模型的第一步是进行图片信息的识别处理,以获取图片中人物的服饰部分。基于人工智能的图像分割与识别法是近年来热门的研究方向,且分割识别效果最好的,但是若要取得良好的效果,需要构建大规模的训练集作为基础,且处理耗时较长。而其余的传统算法大多对图像的背景要求较高,复杂的背景会影响分割识别的效果,所以本文选取了相对来说效果较好的基于图论的GrabCut分割算法,在背景复杂情况下,可以使用额外的交互操作来避免背景处理效果不佳。
2.1 GrabCut算法
GrabCut 算法是2004 年Rother 等人提出的一种优秀且高效的交互式的图像分割算法,结合基于Graph Cuts[10]的优化迭代和Border Matting[11]来处理目标边界处图像模糊和像素重叠等问题,能在较复杂的图像中通过简单的交互操作得到较高精度的分割效果。GrabCut是一种基于图论的分割方法,首先定义一个Gibbs 能量函数,然后求解这个函数的min-cut,这个min-cut就是前景和背景的分割像素集合。
交互部分,通过用户框选目标,得到一个初始的方框图,方框外的像素全部作为背景像素,方框内的像素全部作为“可能是目标的像素”。
首先使用高斯混合模型(Gaussian Mixture Model,GMM)来建立彩色图像数据模型。每一个GMM 都可以看作是一个K 维的协方差。为了方便处理GMM,在优化过程中引入向量作为每个像素的独立GMM 参数,相应像素点上的不透明度an=0或1。使用的Gibbs能量函数定义为公式(1):
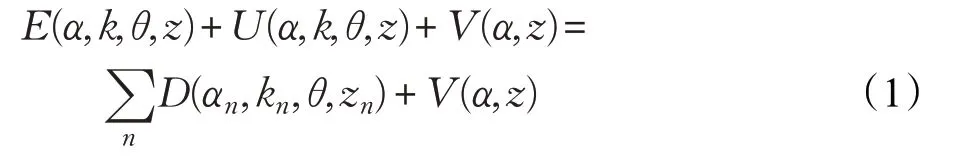
其中,D(αn,kn,θ,zn)=-log p(zn|αn,kn,θ)-log π(αn,kn),p是高斯概率分布,π 是第高斯函数对概率贡献的权重系数(累积和为常数)[12]。
其次能量最小化是通过迭代不断更新,修正GMM参数,利用初始三元图的TU像素中重新确定的像素来校正彩色模型GMM 的参数θ。再采用border matting对分割的边界进行平滑等后期处理,由此可以降低交互过程的工作量,实现了图的分割。
2.2 UV图及展开
UV图是U、V纹理贴图坐标的简称,它是在多边形网格的定点上的二维纹理坐标点。它精确定义了纹理图片文件上,每个点与3D模型上的点互联的位置信息,以决定表面纹理贴图对应的三维模型的位置。如果没有UV,多边形网格将不能被渲染出纹理[13]。
三维角色模型创建完成后如需添加表面纹理,第一个任务就是进行UV 展开,一般使用的工具是Maya 和3DMax 自带的工具,本文使用的是操作更方便快捷的UVLayout工具[14]。使用此工具,加载模型的obj格式文件后,按流程操作展开,并排布好展开的UV 片面。布局后的UV图呈现为一张布局均匀的二维平面图(如图1),在其上附上不同的颜色和纹理就可实现生成不同的纹理贴图并改变模型外观的目的[15]。

图1 模型切分及其UV图
3 虚拟角色服饰快速生成
本文所采用的实验系统流程如图2,输入人物图片后,首先使用图像分割算法GrabCut 分割识别人物图像,通过分割从图片中直接获取服饰的上衣和下衣的图片前景信息。将获取的服饰信息经过极值剔除的计算后,分别获得上衣和下衣的颜色均值。然后从事先准备好的人物模型实验库中,选取和图片相似的人物模型作为人物模板,模板需通过软件预先处理获取其UV展开图及对应的表面纹理图。随后将从图片中获取的上衣下衣的颜色均值信息,填充到库模型的服饰片面上,再将处理后的纹理图向人物模型贴合即获得和原图片相似的人物模型。
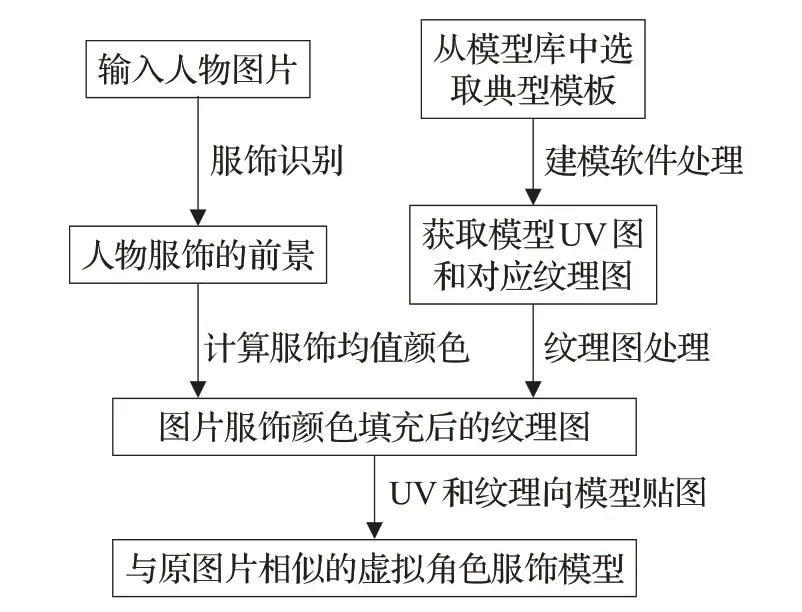
图2 从图片到角色服饰系统流程图
3.1 服饰识别
对输入的人物图片使用GrabCut 的算法进行初步处理,分别识别出人物的衣服和裤子的具体区域,并提供服饰的前景图像供后续步骤使用。
读取人物图片之后,需要进行简单的人机交互,人为选择出需要分割的服饰的大致区域,选择的区域在操作中以绿色方框标记。在服饰颜色和背景颜色复杂时,可以为了取得更好的分割效果,进行额外的交互步骤操作。算法运行时使用提示的按键可以进行相对应的操作,即可以手动标注部分前景和背景色。如图3,前景色标记为浅蓝色,背景色标记为深蓝色。适当的人机交互处理后即可进行图像的分割操作,研究者可自行选择迭代次数,直到获取到所需的前景图像,一般情况下,三次迭代以内即可得到较为满意的结果。衣服区域分割完毕后,需要再进行一次裤子区域的分割识别,对下衣区域进行同样的交互操作后,可分割得到人物衣服和裤子的前景图像,保存并进行下一步操作。

图3 一次迭代分割结果
3.2 提取服饰颜色
为了生成与图片中近似的三维角色服饰,在分割识别出图片中人物的衣服和裤子区域后,需要对其各部分的前景图像计算出对应部位的颜色风格信息。事先从模板库中选取并处理好三维人物服饰模板的UV 和纹理图,将代表风格的颜色分别填充进纹理图中。这张重新生成的模型纹理图,因为色值和服饰样式与输入图片的人物相似,贴合到人物角色的模板模型后,能达到使新外表更接近原图的效果。
为获取图片中服饰的主色调,需要对获取的前景图像进行合适的计算。计算颜色色彩的表现是否相近时,效果较好的是采用HSV 色值空间[16]或LAB 色值空间[17],但原图在进行分割操作时,采用的色彩空间是RGB 色值空间,进行色彩转换的时间代价太大。在试验后发现,因为分割后的图像色彩已经较为一致,采用均值的方式得到颜色信息即可大致代表衣服色值风格。但是在一些分割不精确的情况下,与主色调差值很大的像素点会一定程度影响得到的颜色风格。在直接取均值之后,得到的服饰颜色虽然也接近原图,但是色泽略微泛白,剔除极端值之后,得到的服饰颜色更接近原图显示的服饰色泽。最终采用了剔除极端值后的计算颜色均值的方法,计算出当前服饰片面的颜色风格。此种方法得到的色彩效果,在肉眼辨别下与原图片服饰色调无明显差别,在速度表现上较转换色彩空间更快。
极端值的剔除采用的方法步骤如下所示。
(1)使用公式(2):
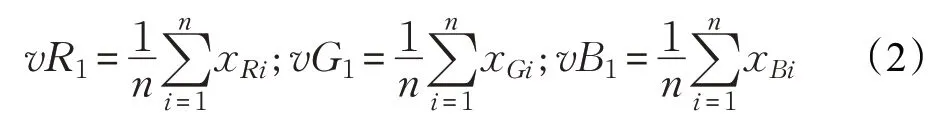
分别计算服饰前景的所有像素的RGB各颜色通道的初始均值为vR1、vG1、vB1。
(2)使用公式(3):
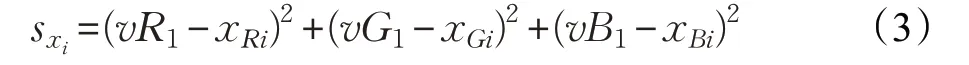
计算出每一个像素点xi的RGB值xRi、xGi、xBi,与初始均值vR1、vG1、vB1的差值sxi。经过实验,设定剔除像素点的阈值为300,将计算出的sxi超过此阈值的像素点x 视为极端值,从均值计算中剔除,将其是否参与计算的flag归0。
(3)剔除极端像素值后,对服饰前景中所留下的像素点再次使用公式(1)分别计算RGB通道的均值,得到最终的均值颜色RGB的值分别为vR、vG、vB。
分别计算衣服和裤子的颜色均值,得到的RGB 值分别存储进包含RGB 三值的Color 结构体中,记为C_COLOR和P_COLOR。
3.3 UV处理及贴图
此步骤是通过对人物模型的衣服和裤子对应的纹理图区域进行图像处理,从而改变原模板模型的外观。
首先对原模型进行UV 的展开。根据实验需要从模型库中选取的几个较为典型的人物模型,使用UVLayout软件进行UV的展开,得到模板中人物模型的UV 展开图,展开的UV 图中拥有模型与纹理图图片相对应的坐标信息。
其次对衣服和裤子的展开图区域,使用不同的鲜明的颜色,分别平滑填充展开后的UV图中衣服和裤子的片面。对每个作为人物样例的模型模板都进行相应处理。得到颜色区分后的UV图,我们就完成了程序运行前的UV准备。
最后将取得的衣服和裤子的颜色均值C_COLOR和P_COLOR,分别填充到UV 图用颜色区分后的对应区域中,将衣服的所有红色部分像素颜色值替换为C_COLOR,裤子的所有蓝色部分的像素颜色值替换为P_COLOR,即完成了UV图的处理部分。如图4所示。

图4 UV对应的纹理图处理过程
得到自动处理好的UV 纹理图后,利用OpenGL 的图形接口结合OpenCV 的图形库进行编程,将UV 图中各个像素点的颜色信息根据每个点对应模型的坐标信息,贴合到人物的.obj 格式的多边形模型上,即完成相似人物模型的生成。
4 实验效果
实验环境为64位Win7 SP1操作系统,主机CPU为Intel Core i7-2600,内存8 GB。程序运行环境为Visual Studio 2013,采用的OpenCV 库版本为3.0.0,采用OpenGL的编程接口作为显示和交互平台。作为原始模型读取和格式转换的工具为3DMax 2015版。
实验选取的输入图像为几张较为典型的人物照片和古代绘画,选取的角色服饰模板是从模型库中匹配对应图片选择的典型模板,以展示输入和输出的模型结果作为验证。实验展示分别分为人物照片到模型和古代绘画到模型两个部分。
4.1 从照片到单个角色模型
本文选取了具有代表性的三张现代人物照片进行实验,为表普适性,分别展示了长袖长裤女性、短袖长裤男性、短袖短裤男性这三种服饰样式的模型生成。
实验输入及结果展示如图5,每一列的第一行数据是输入的人物照片,第二行是采用的人物服饰模型库中的原模型,第三行是经过实验的系统处理之后,生成的类似第一行人物角色服饰的虚拟模型。经过实验展示,可证明能够生成有一定相似度的人物模型。
4.2 从绘画到虚拟角色模型
为了展示本文方法在今后可能适用的更多虚拟场景,实验选取了具有代表性的一张多人古代绘画进行仿真的操作。
如图6 是从模型库中选取的典型古代女性模型。如图7 是输入的古代绘画——捣练图的局部截取图。因为古代人的服饰多为裙装,所以将图中女性的服饰分为上衣和长裙部分分别识别,用以代替现代人的上衣和下衣。原模型女性上衣和裙装的部分纹理图案较多影响仿真,预处理时将其图案平滑处理。

图5 输入图片与生成模型

图6 采用的典型古代女性角色三维服饰模型及其服饰纹理展开图

图7 捣练图局部
如图8是对图7这种典型的多人物古代绘画进行处理的效果。实验展示的是,对图中每个人物分别进行识别,最后分别生成对应每个人物的角色服饰模型的实验结果。图8(a)是古代画作中从左到右分别识别出的四个人物服饰上衣和下衣的图片前景,及其对应生成的单个人物角色服饰模型。图8(b)展示的是将生成的与原图相似的人物模型导入3DMax 的软件,通过3DMax 给角色模型赋予骨骼,从而改变角色的姿态动作以趋近于原图后再进行合并的多角色模型效果图。

图8 生成的古画角色模型
实验证明经过本文的实验方法处理,可以生成与原古代画作有一定相似度的古代角色服饰模型。
5 结束语
本文主要提出了一种简单便捷的由人物图片生成相似的三维人物模型的方法。结合了图像识别相关技术、三维人物模型建模的相关知识和OpenGL 编程技术,快速地生成近似的人物三维模型,并且得到的模型可用于多样化人物的生成。不同于以往的对图片上的每一个人物进行手动精细建模的方法,也不同于由二维图片更换人物头部模型而实验的二维试衣系统,本文系统虽然可以快速生成与图片相似的人物模型,但是在模型的相似程度和精细程度上还有待改善。进一步的工作主要有两个方面:一是在使用非人机交互的方式,采用深度学习中对抗网络的方式[18],自动识别并区分人物的衣服和裤子;二是如何将图片中衣饰的具体纹理细节一并贴到人物模型上。
猜你喜欢
艺术家(2023年8期)2023-11-02 02:05:28
小哥白尼(军事科学)(2022年2期)2022-05-25 13:19:30
小哥白尼(野生动物)(2021年3期)2021-07-21 02:28:28
学生天地(2020年22期)2020-06-09 03:07:44
软件(2020年3期)2020-04-20 01:45:18
娃娃乐园·综合智能(2019年12期)2020-01-15 00:40:08
红领巾·萌芽(2019年8期)2019-08-27 15:30:15
摄影之友(影像视觉)(2018年12期)2019-01-28 09:01:00
Coco薇(2017年8期)2017-08-03 15:23:38
Coco薇(2015年5期)2016-03-29 23:22:15
