
采用Wallace树优化的分像素运动估计插值滤波算法
2020-04-07 06:11施隆照洪晓剑严丹钰
福州大学学报(自然科学版) 2020年2期
罗 隆,施隆照,洪晓剑,严丹钰
(福州大学物理与信息工程学院,福建 福州 350108)
0 引言
智能手机和数码设备的快速发展,推动了视频影像的大量传播.HEVC/H.265是目前最新的视频编码标准,其中的帧间预测通过减少时域冗余能够有效地压缩视频大小.分像素插值作为帧间预测中的一部分,在提高运动估计精度的同时引入较多的计算量,增加了编码器的复杂程度.据统计,在编码端分像素插值模块占据了约1/4的复杂度,在解码端则占据了约50%的复杂度[1].
当前有不少降低分像素插值模块复杂程度的研究,普遍做法是将乘法计算转换成移位和加法操作,加法器的数量很大程度反映了模块硬件资源的使用情况.减少加法器数量的方法可以归纳为以下几类: 一是复用滤波器中公有因式,这是HEVC编码标准初定时期许多文献都会采用的一种方法,以文[2-4]等为代表;二是对滤波系数进行拆分,在加法器前级加入选择器对滤波器类型进行选择,使3种滤波器共用1种硬件架构,以文[5]等为代表;三是将滤波器系数进行一定程度的缩放,甚至是忽略一些权重影响较小的滤波系数,从而减少插值过程中需读取的参考像素点数,同时也减少了滤波系数拆分成2的幂次项的个数,以文[6]等为代表.
上述研究虽然采用按行流水的插值架构,在减少硬件面积的同时维持了一定的吞吐率,但在面积与性能上都达不到人们的期望值.在分像素搜索过程中需要进行多次分像素插值操作,若插值模块的最高工作频率太低,将严重影响编码器的工作效率.针对此问题,本研究在采用按行流水插值架构的基础上,使用Wallace树压缩算法对分像素插值计算过程中的各项进行压缩,只在最终输出结果的一级使用加法器.相比于传统方法不仅减少了硬件面积,而且提高了模块可工作的最高频率.所提算法在硬件上得到验证,硬件设计以Verilog HDL语言进行描述,使用Modelsim进行功能仿真验证,在Synopsys Design Compiler上使用SAED 32 nm标准单元库进行综合.
1 系统概述
1.1 分像素搜索过程

图1 分像素搜索Fig.1 Sub-pixel accuracy search
分像素搜索的示意图如图1所示,图中标识了其中的9个整像素点,8个1/2像素点以及8个1/4像素点.
分像素搜索过程中以PU(prediction unit)为单元求残差,对残差进行SATD(sum of absolute transformed difference)变换后,结合编码比特数以及拉格朗日算子进行率失真代价计算,取率失真代价最小的像素点为最优点.
分像素搜索的流程如下: 1)在最优整像素点(以序号0像素点为例)周围的8个1/2分像素位置依次对参考像素块进行插值操作,取8个搜索点以及0像素点中率失真代价最小的点为最优点.假设图1中序号1分像素点为1/2分像素位置的最优点.2)对1/2分像素位置最优点周围的8个1/4像素点继续进行1/4最优点的搜索,搜索过程与1/2分像素位置最优点类似,最终得到率失真代价最小的1/4像素点为最优点,保存其运动矢量及率失真代价.至此,一个PU的分像素搜索过程结束.
1.2 按行流水插值架构
HEVC中PU大小从4 px × 4 px至64 px × 64 px[7]分布,故选择合适的最小插值PU单元实现硬件的最大程度复用是需要仔细考虑的问题.文[4]和文[8]从参考像素利用率、硬件面积等方面考虑了最小插值PU单元的选择,最终论证了选择8 px × 8 px大小PU作为最小插值单元最为理想,PSNR的损失极小同时有利于硬件实现.本研究同样选择8 px × 8 px PU作为最小插值单元.对于大于 8 px × 8 px PU的插值,可通过多次复用8 px × 8 px PU插值单元实现.以16 px × 8 px大小PU为例,可划分为两个8 px × 8 pxPU块进行插值.
以行输入一次可以插值8个像素的分像素插值滤波处理器如图2所示.将分像素插值过程分解为水平方向插值和竖直方向插值,实现的滤波模块由8个8抽头的水平方向滤波器hf0~hf7、8个8抽头的竖直方向滤波器vf0~vf7组成,中间用了8 ×8个寄存器作缓冲.为插值8 px × 8 px PU,需要在左边和上边多读入3个参考像素,右边和下边多读入4个参考像素,即共读入15×15个参考像素.这些参考像素将在每个时钟周期以行为单位输入分像素插值滤波处理器.其中水平滤波器hf0将读入Y0~Y7共8个参考像素,hf1读入Y1~Y8,…,hf7读入Y7~Y14.在读入对应的参考像素后水平滤波器将通过选择器选择某1个分像素位置块进行滤波,分像素位置的控制信息来自于上层模块.每个时钟周期所有水平滤波器共产生8×1个分像素并存入中间的寄存器组,寄存器组整体向下移一个单元.8个时钟周期后所有寄存器都被填满,竖直滤波器读入寄存器中的分像素并开始工作.竖直滤波器计算过程需2个时钟周期,流水操作除第1个时钟周期外,每列每1个时钟都可以完成1组数据计算.在竖直分像素计算的同时,水平分像素依旧每个时钟周期更新一行.在输出最终结果前,水平分像素和竖直分像素会通过选择器进行筛选,插值过程结束将得到8×8的分像素.因此,本方案有9个时钟周期处于等待状态.在此之后,如果参考像素持续不断地输入,每17个时钟周期将计算192个分像素,吞吐率可以达到11.3 px/时钟周期.

图2 按行流水插值架构Fig.2 Pipeline architecture for interpolation by row
2 基于Wallace树压缩算法的分像素插值单元
2.1 Wallace树压缩器
Wallace树压缩算法的提出最初是服务于乘法器的部分积计算的,基本的思想是采用树形结构减少累加进位的传递,充分利用诸如全加器3-2压缩的特性,随时将可利用的所有输入和中间结果及时并行计算,大大减少了计算延时[9].
本设计考虑了多种压缩器结构,权衡了压缩级数与硬件资源的关系,使用3-2压缩器,4-2压缩器,7-2压缩器[10].
2.1.13-2压缩器

图3 3-2压缩器Fig.3 3-2 compressor

图4 k位数进行3-2压缩的过程Fig.4 The process of 3-2 compression of k bits
3-2压缩器的核心单元是全加器[11].3-2压缩器的功能是将3个1位输入d0、d1、d2压缩成2个1位的sum和carry,其功能示意图如图3所示.如果用逻辑表达式可以表示为
sum=d0⊕d1⊕d2
(1)
carry=d0·d1+d1·d2+d0·d2
(2)
对于k位(k=2,3,4,…)的3个数相加,则使用k个3-2压缩器并行处理,如图4所示,方格里的序号表示对应数据用二进制表示时的各个位.3个数相同权重的位用一个3-2压缩器压缩得到各个的{carry,sum},记为Cn与Sn(n=0~k-1),则可构成2个新的数S与C,C的权重比S大一倍,为了方便最后两数相加,C最低位补0,S最高位补0,各形成k+1位的数.
2.1.24-2压缩器
4-2压缩器可用两个3-2压缩器组成,4-2压缩器的示意图如图5所示.因为4个1位数相加结果最大为4,二进制表示为3’b100,占据了3位,需要传递进位,否则无法满足最后只有两个数相加的规则.
从图5中可以看出,向高位的进位Cout与结果中的carry权重是一样的,sum的权重则低于carry一级,与1位输入d0~d3以及低位的进位Cin是同一级.
2.1.37-2压缩器
7-2压缩器是文[10]里提出的,由5个3-2压缩器组成,如图6所示.其中:d0~d6表示外部的7个1位输入;Cin1和Cin0分别表示来自邻近低位和次低位的进位;Cout0和Cout1分别为权重高于sum 1位和2位的进位;Sn和Cn(n=0,1,2)表示不同3-2压缩器压缩后的sum和carry.文[10]相比同类型其他Wallace树结构组成的压缩器,具有3%的速度优势[12],有利于减少分像素插值过程中的延时.

图5 4-2压缩器Fig.5 4-2 compressor
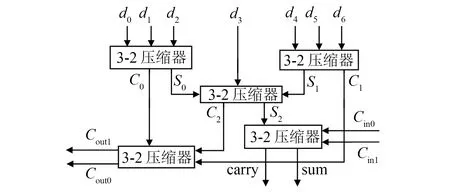
图6 7-2压缩器Fig.6 7-2compressor
2.2 使用压缩器进行插值单元设计
2.2.1滤波系数优化

表1 HEVC亮度插值滤波系数
HEVC亮度插值的滤波系数如表1所示.不难看出1/4、3/4分像素位置的滤波系数互为逆序关系,故它们的硬件结构可以复用.
本研究的滤波处理分成水平方向滤波和竖直方向滤波两步.由于计算1个竖直分像素前需要至少缓存8个水平分像素,且同一次竖直滤波过程中,计算同一列的3个分像素依赖的水平分像素是相同的,为兼顾系统吞吐率与硬件面积的平衡,对于水平方向滤波将使用选择器选择滤波1个分像素位置的像素,竖直方向滤波则同时输出3个分像素位置的像素.
对于滤波系数的处理,为避免使用乘法器产生高延时,将乘法计算转换成移位和加法操作.以A~H表示输入的8个整像素,首先考虑水平方向滤波系数的拆分,因为计算1/4和3/4分像素值的硬件电路可以复用,下面仅考虑1/4和1/2滤波系数的拆分:
F1/4=-A+4B-10C+58D+17E-5F+G
=-A+4B-(8+2)C+(32+8)D-F+(16+2)D+(16+1)E-4F+G
(3)
F1/2=-A+4B-11C+40D+40E-11F+4G-H
=-A+4B-(8+2)C+(32+8)D-F-C-(8+2)F+(32+8)E+4G-H
(4)
提取式(3)和式(4)公有子式
T=-A+4B-(8+2)C+(32+8)D-F
(5)
则式(3)、式(4)可变形为
F1/4=T+(16+2)D+(16+1)E-4F+G
(6)
F1/2=T-C-(8+2)F+(32+8)E+4G-H
(7)
非公有子式可以通过选择器进行处理,达到共用加法器的目的,如式(6)的(16+1)E可以与式(7)的(32+8)E通过选择器共用1个加法器.
竖直方向滤波系数的拆分思路与水平方向类似.
F1/4=-A+4B-10C+58D+17E-5F+G
=-A+4B-(8+2)C+(32+8)D-F-4F+(16+1)E+G+(16+2)D
(8)
F1/2=-A+4B-11C+40D+40E-11F+4G-H
=-A+4B-(8+2)C+(32+8)D-F-(8+2)F+(32+8)E+4G-H-C
(9)
F3/4=B-5C+17D+58E-10F+4G-H
=B-4C+(16+1)D+(16+2)E-(8+2)F+(32+8)E+4G-H-C
(10)
为了充分利用前文几种压缩器的压缩特性,对式(8)~式(10)做如下处理:
提取式(8)和式(9)公有子式
V12=-A+4B-(8+2)C+(32+8)D-F
(11)
提取式(9)和式(10)公有子式
V23=-(8+2)F+(32+8)E+4G-H-C
(12)
将式(8)~式(10)变形为
F1/4=V12-4F+(16+1)E+G+(16+2)D
(13)
F1/2=V23+V12
(14)
F3/4=V23+B-4C+(16+1)D+(16+2)E
(15)
对于负数项的运算需要使用补码.一个负数的补码等于它的反码加1,如果加1操作紧随取反操作,将增加滤波项生成的延时,故将所有加1操作统一相加成1项,和其他滤波项共同加入到压缩器的输入端.
2.2.2Wallace树压缩算法插值滤波单元
采用Wallace树压缩算法进行设计的插值滤波单元U1和U2如图7所示.其中U1是水平方向滤波器3种分像素的计算单元以及竖直方向滤波器1/2分像素的计算单元;U2是竖直方向滤波器1/4和3/4像素的计算单元.U2单元的“取反加1之和”部分包含在了7-2压缩器输入的7项之中.两种单元都只在最后一级使用到一个加法器.

图7 Wallace树压缩算法插值滤波单元Fig.7 Interpolation filter unit based on Wallace tree
3 实验结果

表2 本研究实验结果与其他文献对比
本设计使用Verilog HDL语言描述,功能仿真在Modelsim 完成.通过Matlab调用HM 16.7代码编译后的可执行程序,打印出分像素插值模块的输入输出数据,将输入数据送入待测模块,查看其输出是否与事先打印的输出数据一致即可验证模块功能是否正确.经过多个序列的测试,本设计的电路功能正确.
将本算法对应的硬件设计综合情况与其他同类型文献进行对比,结果如表2所示.为更好地说明本算法的优势,使用Verilog HDL语言编写了与本架构完全一致的加法器版本作为对照组.两个版本的设计均使用SAED 32nm的标准单元库在Synopsys Design Compiler平台完成综合.
由表2可知,与文[4]相比,本设计吞吐率为其2.65倍,同时逻辑门数减少66.6%;本设计吞吐率与文[8]相当,但逻辑门数比文[8]减少11.4%;与作为对照组的加法器版本相比,本设计最高工作频率提高40.1%,逻辑门数减少29.1%.
由此可见,本设计可在硬件面积更小的情况下达到更高的工作频率,这一点在与对照组的对比过程中尤为明显.加法器版本如果要达到更低的延时,电路结构会从以串行进位加法器等为代表的面积小但延时大的加法器转变成以超前进位加法器等为代表的延时小但面积大的加法器,而Wallace树压缩器由于并行程度高于串行进位加法器并且只在最后一级使用了加法器,故可以用更小的硬件面积达到更高的工作频率.
4 结语
提出基于Wallace树优化的HEVC分像素插值滤波算法的实现方案,不仅提高了模块可工作的最高频率,还有效减少了硬件面积.同时由于采用了按行流水插值架构,将插值过程分解为水平方向和竖直方向插值,使模块维持了较高的吞吐率.
本方案的分像素插值模块以8 px × 8 px大小PU为最小插值单元,使用Verilog HDL语言进行描述,在Modelsim上通过功能仿真验证,并在Synopsys Design Compiler上使用SAED 32 nm标准单元库进行综合,综合后模块的最高工作频率为636.9 MHz,逻辑门数为32 960,吞吐率为11.3 px/时钟周期,在同样采用按行流水插值架构的文献中具有明显的优势.
猜你喜欢
客联(2022年4期)2022-07-06
成都信息工程大学学报(2022年2期)2022-06-14
导航定位学报(2022年3期)2022-06-10
现代电子技术(2021年1期)2021-01-17
装备环境工程(2020年3期)2020-04-03
新生代(2018年16期)2018-10-21
现代电子技术(2018年18期)2018-09-12
电脑知识与技术(2018年35期)2018-02-27
城市地理(2017年9期)2017-11-02
科学家(2017年12期)2017-08-10
